マネーロンダリング防止アクティビティスコアリング(AML)¶
このユースケースでは、顧客情報や取引情報などの履歴データを使用するモデルを構築して、不審なアクティビティレポート(SAR)の原因となったアラートを特定します。 次に、このモデルを使用して、不審なアクティビティスコアを将来のアラートに割り当て、スコアによるランク付けを使用してAMLコンプライアンスプログラムの効率を向上させることができます。 このユースケースは、UI操作をベースにした基本ステップとして、以下で説明します。 また、 Jupyterノートブック としても提供しており、ダウンロードして実行することができます。
サンプルトレーニングデータセットは こちらからダウンロードしてください。
ビジネス上の問題¶
あらゆるAMLコンプライアンスプログラムの重要な柱の1つは、取引を監視して不審な行為がないかチェックすることです。 取引の範囲は、入金、出金、資金移動、購入、信販会社によるクレジット販売、支払いなど多岐にわたります。 通常、監視は、マネーロンダリングと一致するトランザクションについて注意を促すために、顧客の取引を精査するルールベースのシステムの活用から始まります。 トランザクションが所定のルールと一致すると、アラートが生成され、そのケースが銀行の内部調査チームに照会されて、手動による調査が行われます。 調査員がマネーロンダリングを示唆する行動であると結論づけた場合、銀行は金融犯罪取締ネットワーク(FinCEN)に疑わしい取引の報告(SAR)を提出することになります。
残念ながら、上記の標準的なトランザクション監視システムには、コストがかかるという欠点があります。 特に問題なのは、このルールベースのシステムによって生成される偽陽性率(誤って不審な活動としてフラグが付けられたケース)が、90%以上に達する可能性があることです。 このシステムはルールベースで柔軟性に欠けるため、マネーロンダリングの背後にある複雑なやり取りや行動を動的に把握することができません。 偽陽性が多発すると、ルールベースのシステムが誤って不審な活動とマークしたケースを手動で取り除く必要があるため、調査員の効率が低下します。
金融機関のコンプライアンスチームには数百人あるいは数千人の調査員が所属していることがありますが、現行のシステムは、調査員がより効果的かつ効率的に調査を行うことを妨げるものになっています。 アラートを調査するためのコストは$30~$70です。 1年で10万件のアラートを受信する銀行の場合、これはかなりの額になります。平均して、証明されたマネーロンダリングに対して科せられる罰金は、1件あたり$145万ドルになります。 偽陽性の削減は、年間$600,000~$4.2万ドルの節約につながる可能性があります。
ソリューションの価値¶
このユースケースでは、複雑なデータのパターンを動的に学習し、偽陽性アラートを減らすモデルを構築します。 その結果、金融犯罪コンプライアンスチームは、手動でのレビューを必要とするアラートの優先順位付けを行って、最も疑わしいケースに多くのリソースを割り当てることができるようになりました。 AIは、履歴データから学習してマネーロンダリングに関連するパターンを明らかにすることで、潜在的なマネーロンダリングのリスクが高いことを示している顧客データと取引行為を特定するのにも役立ちます。
以下に、このユースケースで対処する主な問題と、それに対応する機会を挙げます。
| 問題 | 機会 |
|---|---|
| 潜在的な規制上の罰金 | アラート調査の能力不足による不審な行為を見逃すリスクを軽減することができます。 アラートのスコアを使用して、より効果的にアラートを割り当てます—リスクの高いアラートは、経験豊富な調査員のいるチームに、リスクの低いアラートは経験の少ないチームに割り当てます。 |
| 調査の効率化 | 効果的で効率的な調査プロセスと、ケースを評価する際により全体的なビューを提供することで、調査員の効率を向上させます。 |
以下に具体例を示します。
-
戦略/課題:調査員がマネーロンダリングのリスクが最も高いケースに注意を向けながら、偽陽性のケースの調査にかかる時間を最小限に抑えられるようにします。
日常的に大量の取引がある銀行の場合、調査の効果と効率を高めることで、最終的にマネーロンダリングを見逃すケースを削減できるようになります。 これにより、規制コンプライアンスを強化し、銀行のネットワーク内で発生する金融犯罪を減らすことができます。
-
ビジネスドライバー:AML取引監視の効率を改善し、運用コストを削減します。
AIは、複雑なデータのパターンを動的に学習する機能により、SARの提出につながるケースを予測する精度が大幅に向上します。 マネーロンダリング対策のAIモデルを調査プロセスにデプロイすると、すべての新しいケースをスコアリングしてランク付けできるようになります。
-
モデルソリューション:各AMLアラートに不審な行為のスコアを割り当てて、AMLコンプライアンスプログラムの効率を向上させます。
所定のリスクしきい値を超えたケースは、調査担当者に回されて手動による調査が行われます。 一方、しきい値を下回るケースは、自動的に破棄されるか、より簡易な調査プロセスに回されます。 AIモデルを本番環境にデプロイすると、そのモデルを常に新しいデータで再トレーニングし、新たなマネーロンダリング活動を把握できるようになります。 このデータは、調査員のフィードバックから提供されます。
具体的には、このモデルでは、顧客が任意の金額の払い戻しを要求するたびにアラートをトリガーするルールを使用します。少額の払い戻しを要求する行動は、マネーロンダラーが返金のシステムをテストしているか、払い戻し要求を自分の口座での通常の取引に見せかけようとしている可能性があるためです。
次の表は、このユースケースの特徴をまとめたものです。
| トピック | 説明 |
|---|---|
| ユースケースの種類 | マネーロンダリング対策(偽陽性の削減) |
| 対象者 | データサイエンティスト、金融犯罪コンプライアンスチーム |
| 望ましい結果 |
|
| 指標/KPI |
|
| サンプルデータセット | https://s3.amazonaws.com/datarobot-use-case-datasets/DR_Demo_AML_Alert_train.csv |
問題のフレーミング¶
このユースケースのターゲット特徴量は、担当者による手動調査の結果、そのアラートからSARが作成されたかどうかであり、これは二値分類の問題になります。 分析の単位は個々のアラートです。つまり、モデルはアラートレベルで構築され、各アラートには0~1のスコアが付けられます。このスコアは、SARになる確率を示します。
このユースケースにモデルを適用する目的は、偽陽性率を下げることです。つまり、調査の結果、疑わしいと判断されなかったケースのレビューにリソースが費やされることはありません。
このユースケースでは、検証サンプル(1600件のレコード)でのルール エンジンの偽陽性率は次のとおりです。
SAR=0の数をレコードの総数で割った値 = 1436/1600 = 90%。
ROIによる見積もり¶
ROIは次のように計算できます。
Avoided potential regulatory fine + Annual alert volume * false positive reduction rate * cost per alert
ROI方程式の高レベルの測定は、2つの部分で構成されます。
-
avoided potential regulatory finesの総額は銀行のタイプによって異なり、ケースごとに個別に推測する必要があります。 -
方程式の2つ目の部分は、AIが調査効率の向上と運用コストの削減に及ぼす具体的な影響を示しています。 次の例を検討してみましょう。
- ある銀行では、毎年10万件のAMLアラートが発生しています。
- DataRobotは、過去の不審な行為を見逃すことなく70%の偽陽性削減率を達成しています。
- アラート1件あたりの平均コストは
$30~$70です。
結果:ソリューションを実装することによる年間ROIは
100,000 * 70% * ($30~$70) = $2.1MM~$4.9MMになります。
データの操作¶
結合された合成データセットは、クレジットカード会社のAMLコンプライアンスプログラムを示しています。 特に以下のマネーロンダリングシナリオを検出することを目的としています。
- 顧客はカードを使用しますが、クレジットカードの請求額を超えて支払ったため、差額の現金払い戻しを求めます。
- 顧客は、取引を相殺せずに小売店からクレジットを受け取り、その金額を使うか、銀行に現金の払い戻しを求めます。
このデータセットの分析単位は個別のアラートです。つまり、上記のシナリオと一致する潜在的に不審な行為を検出したときにアラートを生成するために、ルールベースのエンジンが導入されています。
データプレパレーション¶
データを使用する場合は、次の点に注意してください。
-
分析範囲の定義:まず、特定の分析期間からアラートを収集します。モデル構築には、12〜18か月間のアラートを使用することをお勧めします。
-
ターゲットの定義:ターゲットは、調査プロセスに応じて柔軟に定義できます。 このチュートリアルでは、アラートを
Level1、Level2、Level3およびLevel3-confirmedに分類します。 これらのラベルは、アラートがクローズされた(つまり、SARとして確認された)調査レベルであることを示します。 二値ターゲットを作成するには、Level3-confirmedはSARとして処理され(1で示される)、残りは非SARアラートとなります(0で示される)。 -
複数のデータソースからの情報を統合:以下は、このユースケースで使用されるデータテーブル間の関係性を示すエンティティ関係図の例です。
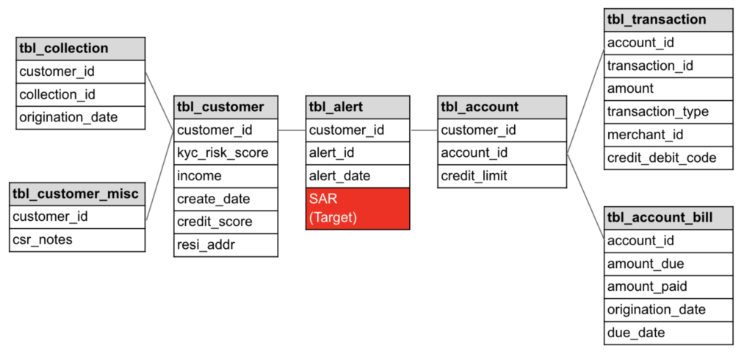
kyc_risk_scoreやstate of residenceなどの一部の特徴量は静的情報で、参照テーブルから直接取得できます。
取引行動と支払履歴については、アラート生成日より前の特定の期間から情報が取得されます。 このケースでは、動的な顧客行動(nbrPurchases90d、avgTxnSize90d、totalSpend90dなど)を取得するための時間ウィンドウとして90日間を使用します。
以下は、トレーニングデータがマージおよび集約された後の1行の例です(見やすくするために複数の行に分割しています)。

特徴量とサンプルデータ¶
サンプルデータセットの特徴量には、KYC(Know Your Customer(顧客を知る))情報、人口統計情報、取引行動のほか、顧客サービス担当者のメモから作成された自由形式のテキストが含まれます。 このユースケースを組織に適用するには、データセットに少なくとも次の特徴量を含める必要があります。
- アラートID
- 二値分類ターゲット(
SAR/no-SAR、1/0、True/Falseなど) - アラートの日付/時刻
- 口座開設時に使用する「Know Your Customer(顧客を知る)」スコア
- アカウントの有効期間(月単位)
- 過去90日間の小売店からのクレジット件数
- 過去90日間に顧客から払い戻しが請求された回数
- 過去90日間の総返金額
以下に役立つその他の機能を示します。
- 年収
- 信用機関スコア
- 過去1年間の信用調査の回数
- 過去90日間に銀行のウェブサイトにログインした回数
- 顧客が自宅を所有していることを示す指標
- リボルビングローンの上限金額
- 過去90日間の購入数
- 過去90日間の総支出額
- 過去90日間の支払回数
- 過去90日間に現金に準ずる支払い手段(郵便為替など)が使われた回数
- 過去90日間の総支払額
- 過去90日間に購入があった小売店の数
- カスタマーサービス担当者によるメモと、顧客との会話を元に作成したコード情報(累積)
サンプル特徴量セットを以下の表で示します。
| 特徴量名 | データ型 | 説明 | データソース | 例 |
|---|---|---|---|---|
| ALERT | 二値 | アラートの指標 | tbl_alert | 1 |
| 疑わしい取引 | 二値(ターゲット) | SARの指標(二値ターゲット) | tbl_alert | 0 |
| kycRiskScore | 数値 | 口座開設時に使用された口座との関係(顧客を知る)スコア | tbl_customer | 2 |
| income | 数値 | 年収 | tbl_customer | 32600 |
| tenureMonths | 数値 | アカウントの有効期間(月単位) | tbl_customer | 13 |
| creditScore | 数値 | 信用機関スコア | tbl_customer | 780 |
| state | カテゴリー | 口座の請求先住所の状態 | tbl_account | VT |
| nbrPurchases90d | 数値 | 過去90日間の購入数 | tbl_transaction | 4 |
| avgTxnSize90d | 数値 | 過去90日間の平均取引規模 | tbl_transaction | 28.61 |
| totalSpend90d | 数値 | 過去90日間の総支出額 | tbl_transaction | 114.44 |
| CSR備考 | テキスト | カスタマーサービス担当者によるメモと、顧客との会話を元に作成したコード情報(累積) | tbl_customer_misc | call back password call back card password replace atm call back |
| nbrDistinctMerch90d | 数値 | 過去90日間に購入があった小売店の数 | tbl_transaction | 1 |
| nbrMerchCredits90d | 数値 | 過去90日間の小売店からのクレジット件数 | tbl_transaction | 0 |
| nbrMerchCredits-RndDollarAmt90d | 数値 | 過去90日間の小売店からのクレジット件数(ドル単位) | tbl_transaction | 0 |
| totalMerchCred90d | 数値 | 過去90日間の小売店クレジット総額 | tbl_transaction | 0 |
| nbrMerchCredits-WoOffsettingPurch | 数値 | 過去90日間に相殺購入のない小売店クレジット件数 | tbl_transaction | 0 |
| nbrPayments90d | 数値 | 過去90日間の支払回数 | tbl_transaction | 3 |
| totalPaymentAmt90d | 数値 | 過去90日間の総支払額 | tbl_account_bill | 114.44 |
| overpaymentAmt90d | 数値 | 過去90日間の過払い総額 | tbl_account_bill | 0 |
| overpaymentInd90d | 数値 | 過去90日間に口座で過払いがあったことを示す指標 | tbl_account_bill | 0 |
| nbrCustReqRefunds90d | 数値 | 過去90日間に顧客から払い戻しが請求された回数 | tbl_transaction | 1 |
| indCustReqRefund90d | 二値 | 過去90日間に顧客が払い戻しを請求したことを示す指標 | tbl_transaction | 1 |
| totalRefundsToCust90d | 数値 | 過去90日間の総返金額 | tbl_transaction | 56.01 |
| nbrPaymentsCashLike90d | 数値 | 過去90日間に現金に準ずる支払い手段(郵便為替など)が使われた回数 | tbl_transaction | 0 |
| maxRevolveLine | 数値 | リボルビングローンの上限金額 | tbl_account | 14000 |
| indOwnsHome | 数値 | 顧客が自宅を所有していることを示す指標 | tbl_transaction | 1 |
| nbrInquiries1y | 数値 | 過去1年間の信用調査の回数 | tbl_transaction | 0 |
| nbrCollections3y | 数値 | 過去1年間の債権回収の回数 | tbl_collection | 0 |
| nbrWebLogins90d | 数値 | 過去90日間に銀行のウェブサイトにログインした回数 | tbl_account_login | 7 |
| nbrPointRed90d | 数値 | 過去90日間のポイント還元回数 | tbl_transaction | 2 |
| PEP | 二値 | 政治的に重要な人物であることを示す指標 | tbl_customer | 0 |
モデリングとインサイト¶
DataRobotでは、 ここで説明するように、データセットの処理や分割など、モデリングパイプラインの多くの部分が自動化されます。 この文書は、モデリングが開始された後に利用できる視覚化から開始します。
探索的データ解析(EDA)¶
データタブに移動し、 EDAと呼ばれるサンプルデータに基づくサマリー統計データの詳細を確認します。 各特徴量をクリックすると、特徴量とターゲットの関係を表す ヒストグラムなど、さまざまな情報が表示されます。
特徴量の関連性¶
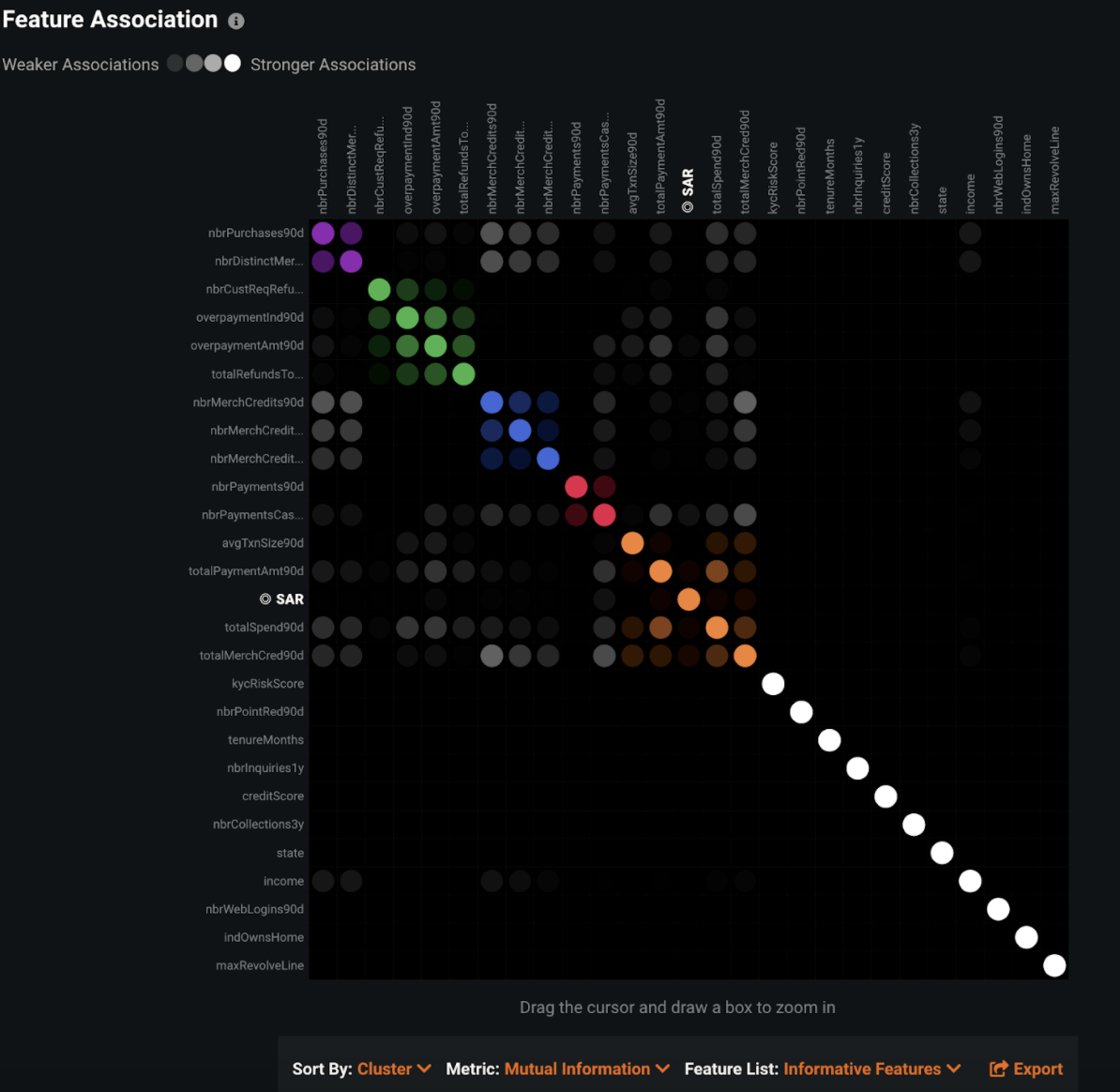
DataRobotがチャンピオンモデルを検出するためにオートパイロットを実行している間、 データ > 特徴量の関連性タブに移動すると、特徴量の関連性の行列を表示して、入力特徴量どうしの関連性を確認できます。 たとえば、nbrPurchases90dとnbrDistinctMerch90dの特徴量(左上隅)は強い関連があるため、1つの「クラスター」としてまとめられています(このマトリックスでは、各カラーブロックがクラスターを示しています)。
DataRobotが提供するさまざまなインサイトを使用して、 結果の解釈と 精度の評価を行います。
リーダーボード¶
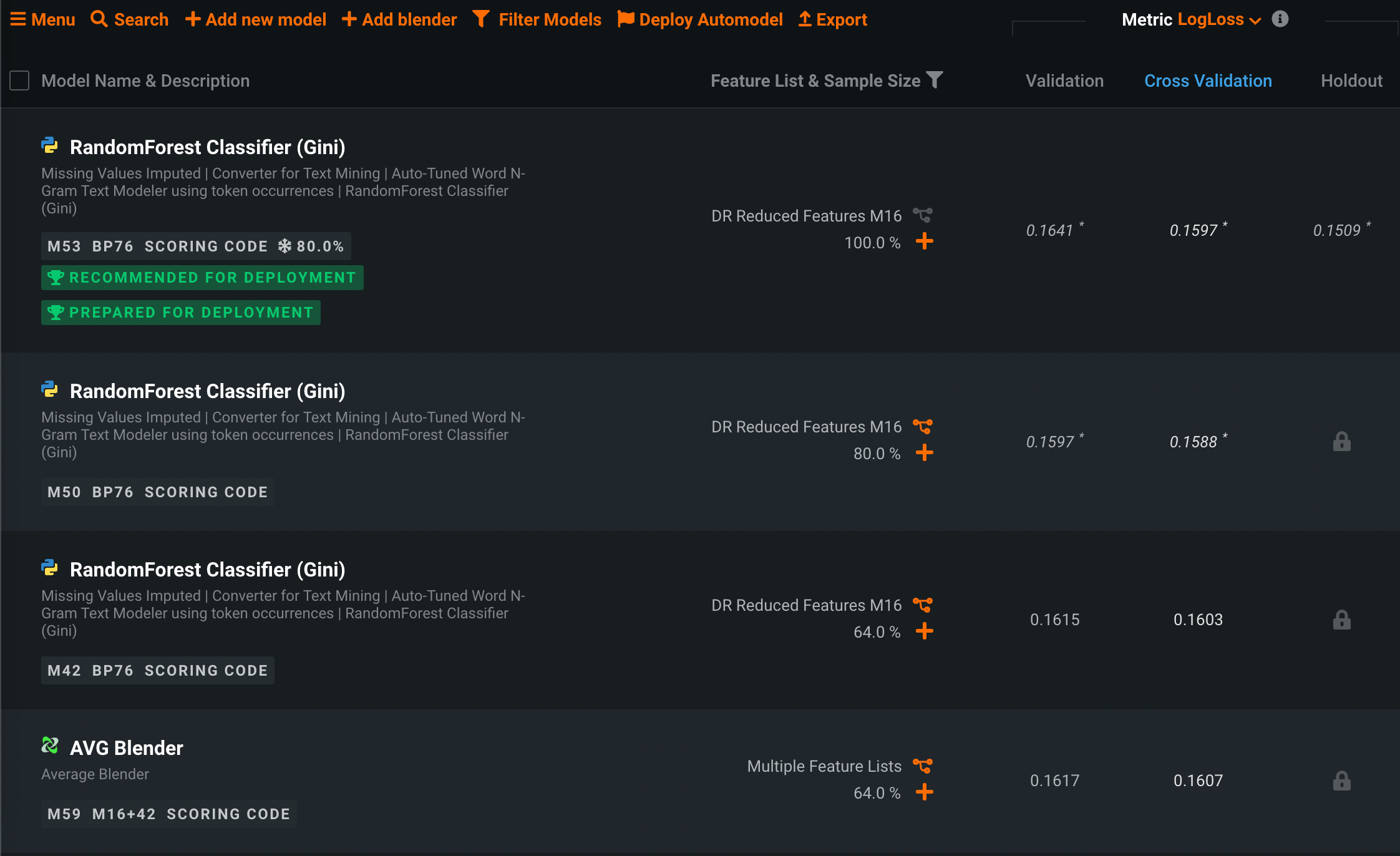
オートパイロットが完了すると、リーダーボードで各モデルは選択した最適化指標(ここではLogLoss)に基づいてランク付けされます。
オートパイロットの成果は、最適なモデルの選択だけでなく、推奨モデルの特定にも及びます。推奨モデルとは、ターゲット特徴量SARの予測方法を最もよく理解しているモデルです。 最適なモデルの選択では、精度、指標が示すパフォーマンス、モデルのシンプルさのバランスが考慮されます。 詳細については、 モデル推奨プロセスの説明を参照してください。
オートパイロットは、指定されたターゲット特徴量に最適な予測モデルが選択されるまで、モデルの構築を続けます。 このモデルはリーダーボードの一番上にあり、デプロイの推奨バッジ付いています。
偽陽性を減らすために、Gini Normなど他の指標を選択すれば、モデルによってどれだけのSARアラートが非SARアラートよりも高いランクが適切に付与されていることに基づいて、リーダーボードを並べ替えることができます。
結果の解釈¶
DataRobotでは、アラートがSARである理由についてのインサイトを提供する多くの視覚化を用意しています。 このユースケースに最も関連するものを以下に示します。
ブループリント¶
モデルをクリックすると、モデルの作成に使用される前処理ステップ、モデリングアルゴリズム、後処理ステップのパイプラインであるモデルの ブループリント—が表示されます。
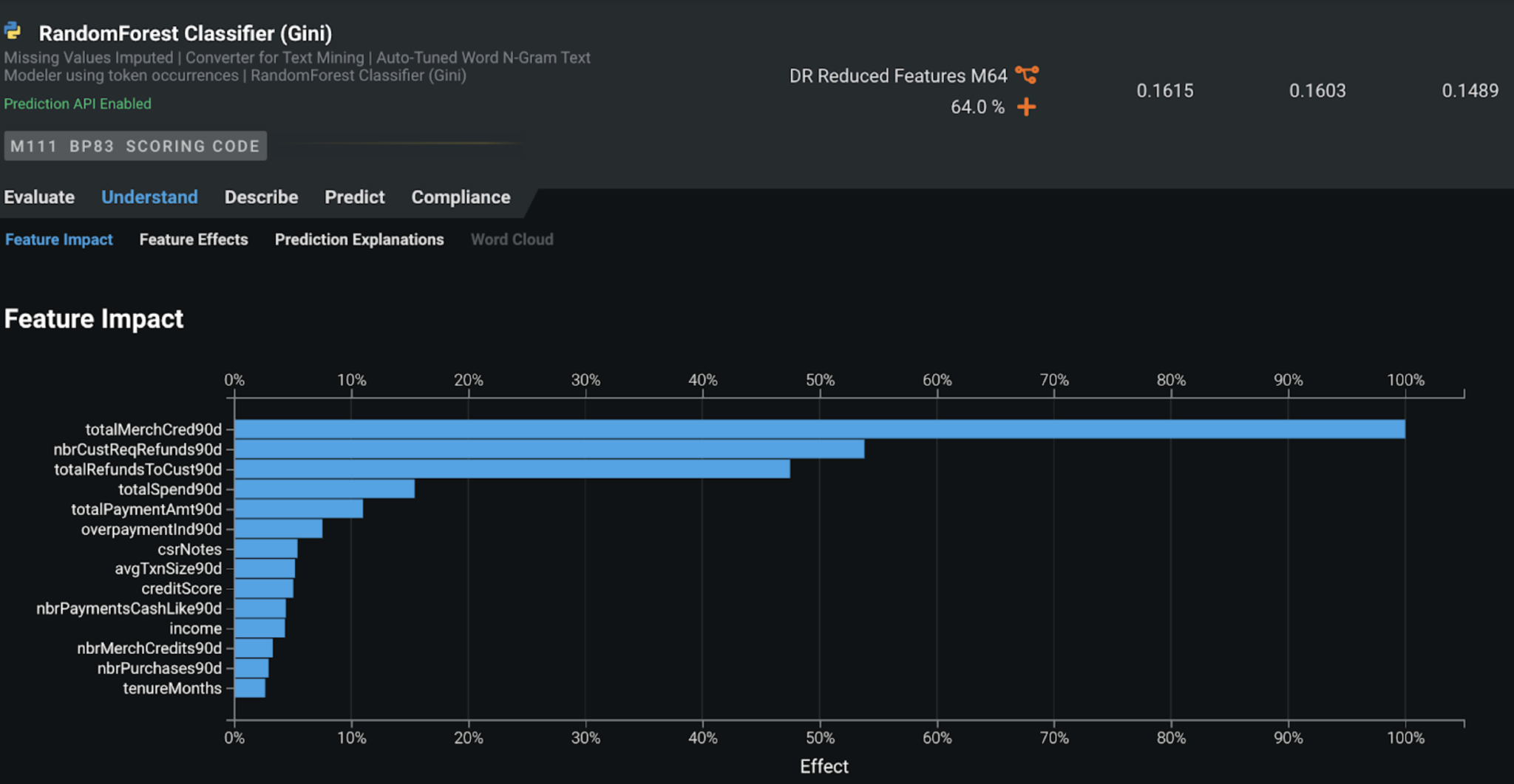
特徴量のインパクト¶
特徴量のインパクトでは、各特徴量とターゲットの関連が表示されます。 DataRobotは、最もインパクトの大きい3つの特徴量(機械がSARアラートと非SARアラートを区別できるようにする)を特定します。この例では、total merchant credit in the last 90 days、number refund requests by the customer in the last 90 days、total refund amount in the last 90 daysです。
特徴量ごとの作用¶
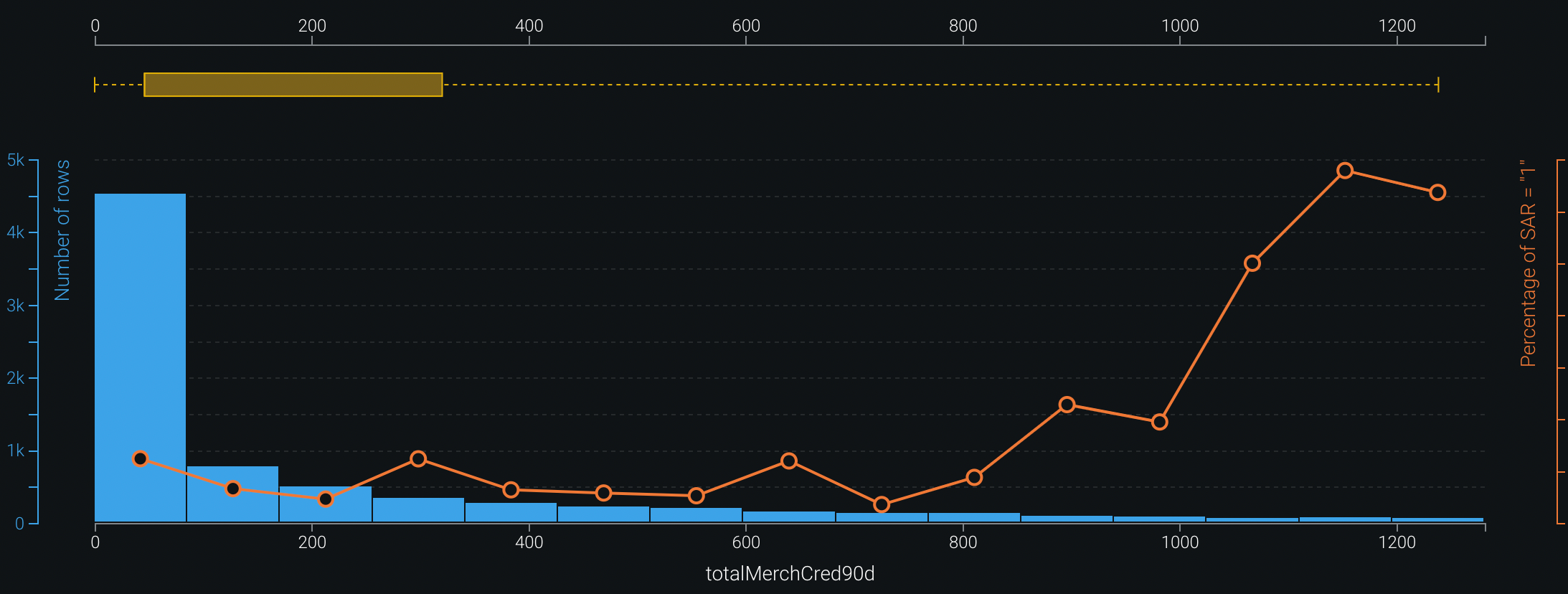
さまざまなレベルの入力特徴量でインパクトの方向性とSARリスクを把握するため、DataRobotは( 特徴量ごとの作用タブに)部分依存グラフを表示し、入力特徴量の値に応じてSARがどのように変化する可能性があるのかを示します。 この例では、過去90日間の小売店クレジット総額が最もインパクトの大きい特徴量ですが、そのSARリスクは金額の増加に合わせて直線的に増えるわけではありません。
- 金額が1000ドルを下回っている場合は、SARリスクは比較的低い水準のままです。
- 金額が1000ドルを超えると、SARリスクが大幅に増加します。
- 金額が1500ドルに近づくと、SARリスクの増加ペースが減速します。
- その後、SARリスクはピークに達するまで再び加速し、2200ドルあたりで横ばいになります。
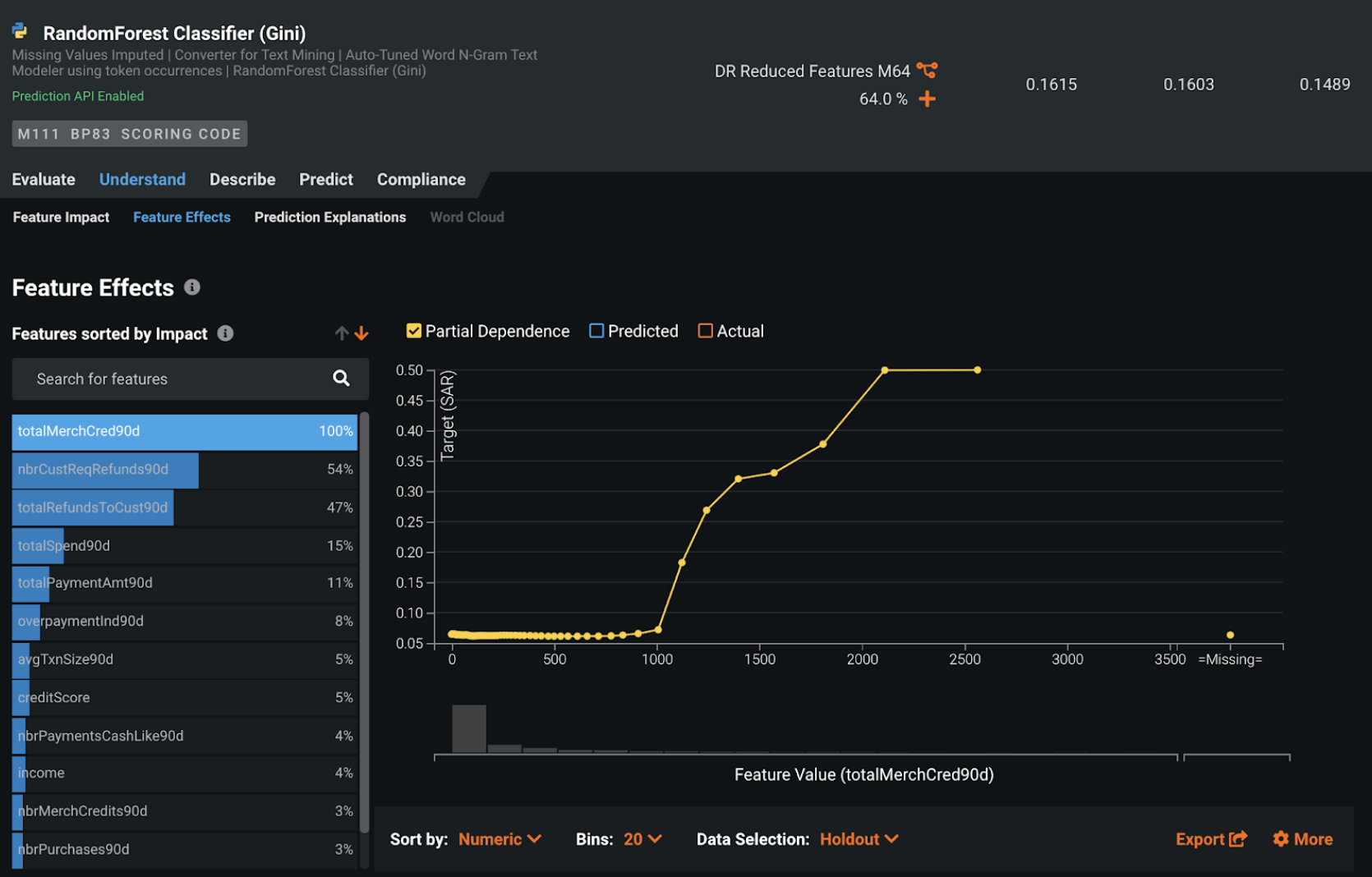
部分依存グラフを見ると、入力特徴量のさまざまなレベルでSARリスクを非常に簡単に判断できます。 また、従来のルールベースのシステムを強化するために、リスクベースのしきい値を設定するためのデータ駆動型のフレームワークに変換することもできます。
予測の説明¶
機械が行った決定を人間が解釈可能な根拠に変えるために、DataRobotは、機械学習モデルによってスコア付けされ、優先順位付けされた各アラートの 予測の説明を提供します。 以下の例では、ID=1269のレコードが不審な行為である可能性が非常に高く(予測=90.2%)、その理由は主に次の3つです。
- 過去90日間の小売店クレジット総額は、他のレコードよりも大幅に高くなっています。
- 過去90日間の総支出額が平均よりはるかに高くなっています。
- 過去90日間の総支払額が平均よりはるかに高くなっています。
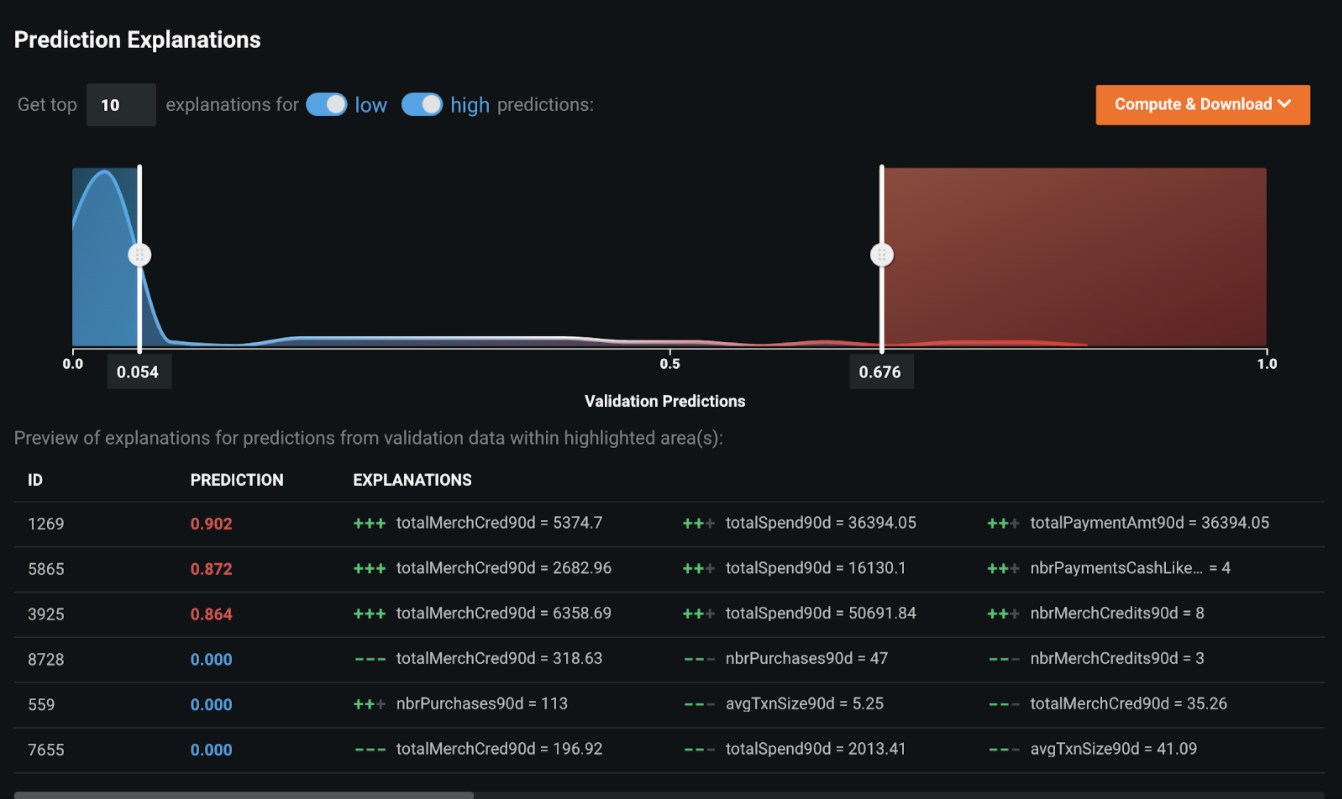
予測の説明を使用して、アラートを取引行為のタイプ別にサブグループにクラスター化することもできます。アラートをさまざまな調査手法にトリアージするのに役立ちます。
ワードクラウド¶
ワードクラウドを使用すると、テキストフィールドが予測にどの程度影響するかを調べることができます。 ワードクラウドは、カラースペクトルを使用して、予測に対する単語の影響力を示します。 この例では、赤色の単語はアラートがSARに強く関連付けられていことを示しています。

精度の評価¶
次のインサイトは、精度を評価する上で役に立ちます。
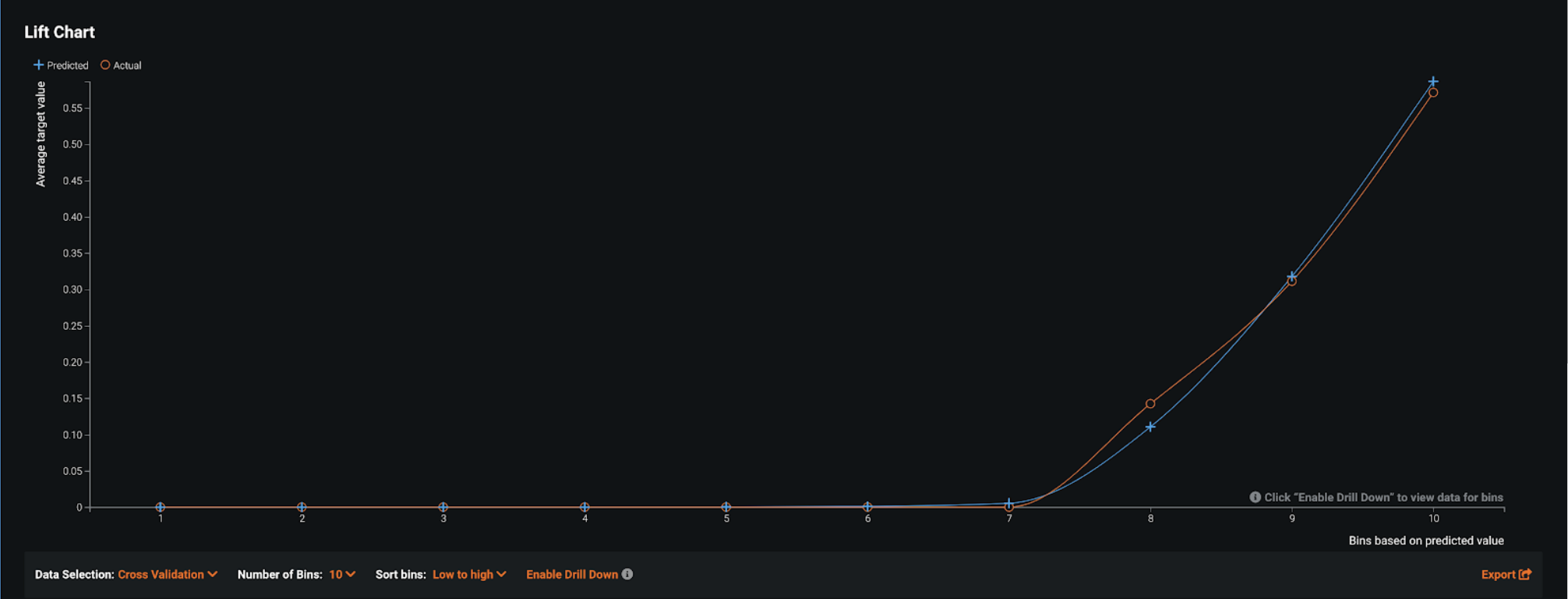
リフトチャート¶
リフトチャートには、SARアラートと非SARアラートを分離するモデルの効果が表示されます。 アウトオブサンプルのパーティション内のアラートがモデルによってスコアリングされると、アラートがSARリスクである、またはSARになる可能性を測定するリスクスコアが割り当てられます。 リフトチャートでは、アラートがSARリスクに従って並べ替えられ、10デシルに分類されて、リスクの低い順から高い順に表示されます。 デシルごとに、DataRobotはSARリスクの平均予測値(青色のプラス記号)と実際のSARイベントの平均値(オレンジ色の丸記号)を計算し、この2つのグラフを一緒に表示します。 この偽陽性削減ユースケース用に構築したチャンピオンモデルでは、最上位のデシルのSAR率は55%で、トレーニングデータのSAR率である10%から大幅に上昇しています。 上位3つのデシルでほとんどすべてのSARを取得しています。したがって、予測されたSARリスクが非常に低い70%のアラートでは、SARが発生する可能性はほとんどありません。
ROC曲線¶
モデルのパフォーマンスが良好であることがわかったので、次は DataRobotによって予測された連続的なSARリスクに基づいて二値決定を行うために、明確なしきい値を選択します。 ROC曲線ツールは、最適なしきい値の選択時に重要ないくつかの決定を下すのに役立つさまざまな情報を提供します。
-
偽陰性率をできるだけ低くする必要があります。 偽陰性とは、DataRobotがSARではないと判断したものの、実際にはSARと判明することです。 実際のSARを見逃すことは非常に危険であり、MRA(要注意事項)として扱われたり規制当局から罰金を科せられたりする可能性があります。
このケースでは、保守的なアプローチを取ります。 偽陰性率を0にするには、すべてのSARが取得されるまでしきい値を低くする必要があります。
-
アラート数をできるだけ抑えて、偽陽性を十分に減らします。 このコンテキストでは、過去に生成されたSARではないすべてのアラートは、事実上の偽陽性です。 機械学習モデルでは、こうした非SARアラートに低いスコアが割り当てられる可能性が高いため、偽陽性アラートを可能な限り減らすために高いしきい値を選択する必要があります。
-
選択したしきい値が、表示されているデータだけでなく、表示されていないデータに対しても機能していることを確認してください。これにより、スコアリングの実行中にモデルが取引監視システムにデプロイされたときに、SARを見逃すことなく偽陽性を減らすことができます。
交差検定データ(モデルのトレーニングと検証に使用されるデータ)を使用してさまざまなしきい値を選択してみた結果、最初の2つの基準を満たす0.03が最適なしきい値であると判断されました。 偽陰性率は0で、アラート数は8000から2142に減少しています。つまり、SARを見逃すことなく、偽陽性のアラートを73%(5858/8000)減らせるようになりました。
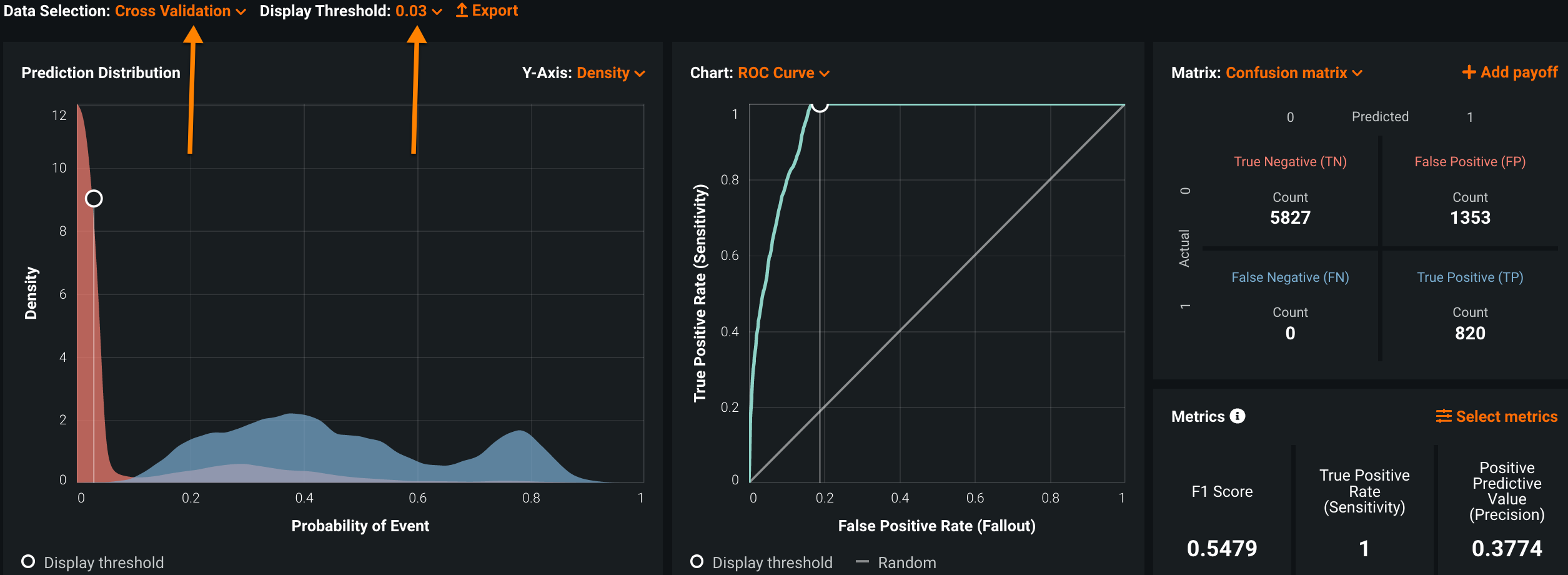
3番目の基準、すなわち表示されていないアラートに対してもしきい値が機能しているかどうかも、DataRobotですぐに検証できます。 データ選択を[ホールドアウト]に変更し、同じしきい値(0.03)を適用したところ、偽陰性率は0のままで、偽陽性の減少率はやはり73%(1457/2000)でした。 これは、このモデルが適切に一般化され、表示されないデータに対して期待どおりに動作することを示しています。
ペイオフ行列¶
収益曲線タブの ペイオフ行列を使用して、シミュレートされた収益に基づいてしきい値を設定します。 銀行が過去のSARのごく一部を見逃すリスクを許容できる場合は、ペイオフ行列を適用して、二値カットオフに最適なしきい値を選択することもできます。 例:
| フィールド | 例 | 説明 |
|---|---|---|
| False Negative | TP=-$200 |
検出されなかったSARを修正するためのコストを反映します。 |
| False Positive | FP=-$50 |
「誤警報」であることが証明されたアラートの調査コストを反映します。 |
| 指標 | 偽陽性率、偽陰性率、平均収益 | 選択した表示しきい値でのモデルのパフォーマンスを説明するのに役立つ標準統計を提供します。 |
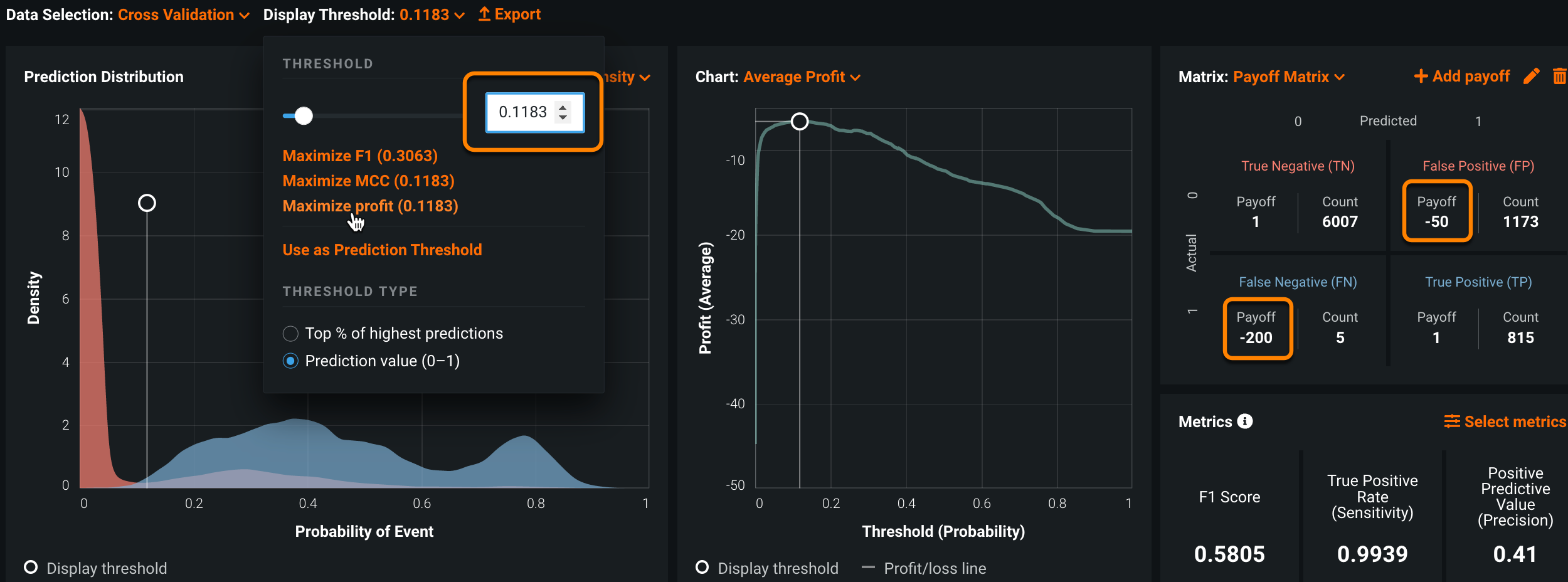
偽陽性1件あたりのコスト(アラート1件あたりの調査コスト)を$50に設定し、偽陰性1件あたりのコスト(検出されなかったSAR1件を修正するコスト)を$200に設定すると、しきい値は0.1183に最適化され、8000件のアラートのうち最小コストは$53k ($6.6 * 8000)、最大$347k ($50 * 8000 - $53k)のROIが得られます。
偽陰性率は低いまま(検出されなかったSARは5件だけ)で、アラート数は8000から1988に減少しています。つまり、調査件数が75%以上(6012/8000)減少したことになります。
しきい値は0.0619に最適化され、8000件のアラートから最大30万ドルのROIが得られます。 このしきい値を設定することで、銀行はわずか3件のSARを見逃すリスクと引き換えに、偽陽性を74.3%(5940/8000)削減します。
クラスの不均衡問題の処理に関する情報については、 詳細を参照してください。
後処理¶
モデリングチームがチャンピオンモデルを決定したら、モデルの コンプライアンスに関するドキュメントをダウンロードできます。 結果として得られるMicrosoft Word文書には、多角的視点でのモデル構築プロセス全体と、チャンピオンモデルと比較したすべてのチャレンジャーモデルが記載されています。 金融犯罪コンプライアンスの分野で使用されるほとんどの機械学習モデルには、モデルリスク管理(MRM)チームの承認が必要です。 コンプライアンスに関するドキュメントにより、モデル開発プロセスのステップごとに包括的な証拠と根拠を提示できます。
予測とデプロイ¶
データの最適なパターンを学習してSARを予測するモデルを特定したら、それを目的の意思決定環境にデプロイできます。 意思決定環境 これはユースケースを実装するための重要なステップです。なぜなら、予測を実際の環境で使用することにより、偽陽性を減らし、調査プロセスの効率を高めることができるからです。
偽陽性低減モデルのアラート優先度スコアには複数の用途があり、既存のルールベースの取引監視システムを自動化および強化します。
-
FCC(金融犯罪コンプライアンス)チームが、低リスクのアラート(優先度スコアが非常に低い)を調査対象から外しても問題ないと判断した場合は、モデル構築段階で選択した二値しきい値をカットオフとして、これらのリスクなしのアラートを削除することができます。 調査チームは、履歴データから学習した内容に基づいて、まだすべてのSARを捉えられるカットオフ上のアラートのみを調査します。
-
多くの場合、規制当局は、本番環境でのアラートへの積極的な対応として、自動終了または自動削除を検討します。 自動終了がモデルの出力を使用する理想的な方法ではない場合でも、アラートの優先度スコアを使用して、さまざまな調査プロセスでアラートをトリアージすることにより、運用効率を向上させることができます。
意思決定の関係者¶
次の表に、潜在的な意思決定の関係者を示します。
| 利害関係者 | 説明 |
|---|---|
| 意思決定の実行者 | 金融犯罪コンプライアンスチーム |
| 意思決定の管理者 | 最高コンプライアンス責任者 |
| 意思決定の作成者 | データサイエンティストまたはビジネスアナリスト |
意思決定プロセス¶
現在の調査プロセスは、調査員による詳細な分析が中心です。 ケースに関連するデータが調査用に提供されているため、調査担当者は、プロファイル、人口統計、取引履歴など、顧客を多角的に分析することができます。 サードパーティのデータプロバイダーとWebクローリングから得た追加データで補完することで、情報の全体像が完成します。
自動終了または自動削除されない取引の場合は、このモデルを利用して調査をトリアージすることで、コンプライアンスチームがより効果的で効率的な調査プロセスを作成できます。 予測とその説明は、ケースを評価する調査員により包括的な視点を提供します。
リスクベースのアラートのトリアージ:優先度スコアに基づいて、調査チームはさまざまな調査方法を取ることができます。
-
リスクのないアラートや低リスクのアラートについては、毎月ではなく四半期ごとに確認できます。 SARのリスクのないアラートの頻度が高い事業体については、3か月に1回の頻度で見直しを行うことで、調査期間を大幅に短縮します。
-
優先度スコアが高い高リスクのアラートについては、アラートのエスカレーションパスの最終段階に調査を進めることができます。 これにより、レベル1およびレベル2の調査に費やす労力が大幅に削減されます。
-
リスクが中程度のアラートの場合は、標準的な調査プロセスを引き続き適用できます。
スマートアラートの割り当て:地理的に分散しているアラート調査チームの場合、アラートの優先度スコアを使用して、より効果的な方法で各チームにアラートを割り当てることができます。 リスクの高いアラートは、経験豊富な調査員のいるチームに割り当てられ、リスクの低いアラートは経験の少ないチームに割り当てられます。 これにより、アラート調査時の能力不足による不審な行為の見逃しリスクを軽減することができます。
どちらのアプローチでも、高リスク、中リスク、低リスクの定義は、厳格なしきい値のセット(高:スコア>=0.5、中:0.5>スコア>=0.3、低:スコア<0.3)か、毎月のアラートスコアのパーセンタイルによって決定されます(高:80パーセンタイル以上、中:50〜80パーセンタイルの間、低:50パーセンタイル未満)。
モデルデプロイ¶
DataRobotで生成された予測をアラート管理システムと統合することで、調査チームはリスクの高い取引を把握できるようになります。
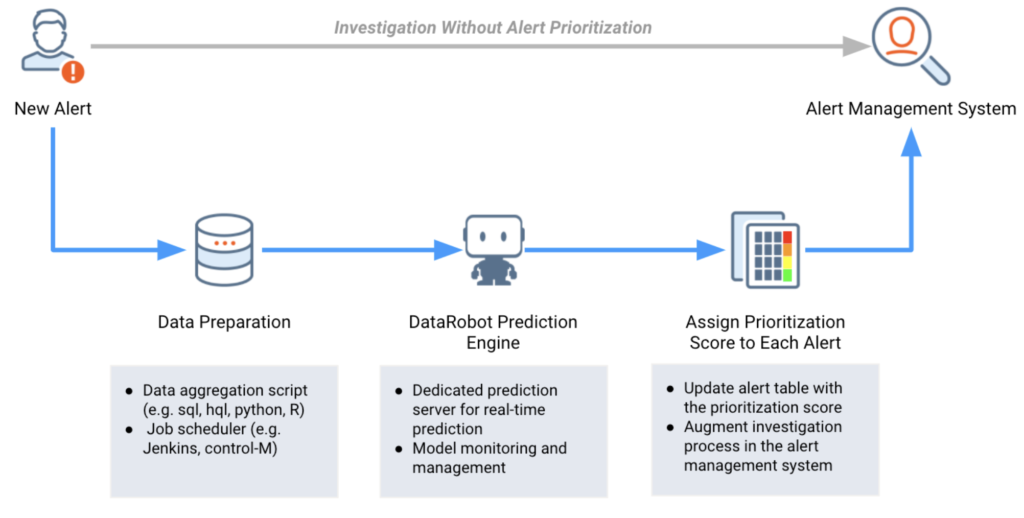
モデル監視¶
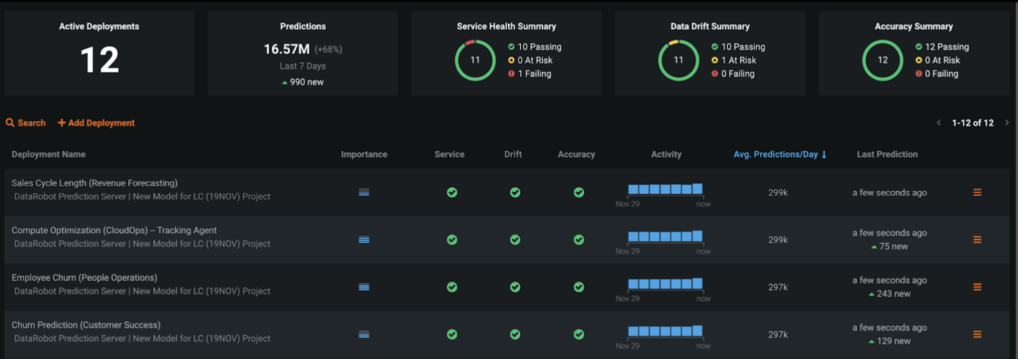
DataRobotは、専用の予測サーバーにデプロイされたモデルを継続的に監視します。 モデリングチームは、DataRobot MLOpsを使用することで、入力した特徴量のデータドリフトや時間の経過に伴うパフォーマンスの低下を追跡して、アラート優先順位付けモデルを監視および管理できます。
実装に関する考慮事項¶
このユースケースを運用する際は、結果に影響を及ぼし、モデルの再評価が必要になる可能性がある次の点を考慮してください。
- マネーロンダラーの取引行動における変化。
- 取引に利用されるようになった新しい情報、および機械学習モデルでは確認できない顧客記録。
AIアプリ¶
利害関係者が予測を活用して、調査結果を記録できるカスタムアプリケーションの構築を検討してください。 モデルがデプロイされると、予測を 意思決定プロセスで使用できます。 たとえば、この AIアプリは、ノーコードインターフェイスを使用して、簡単に共有できるAI搭載のアプリケーションです。
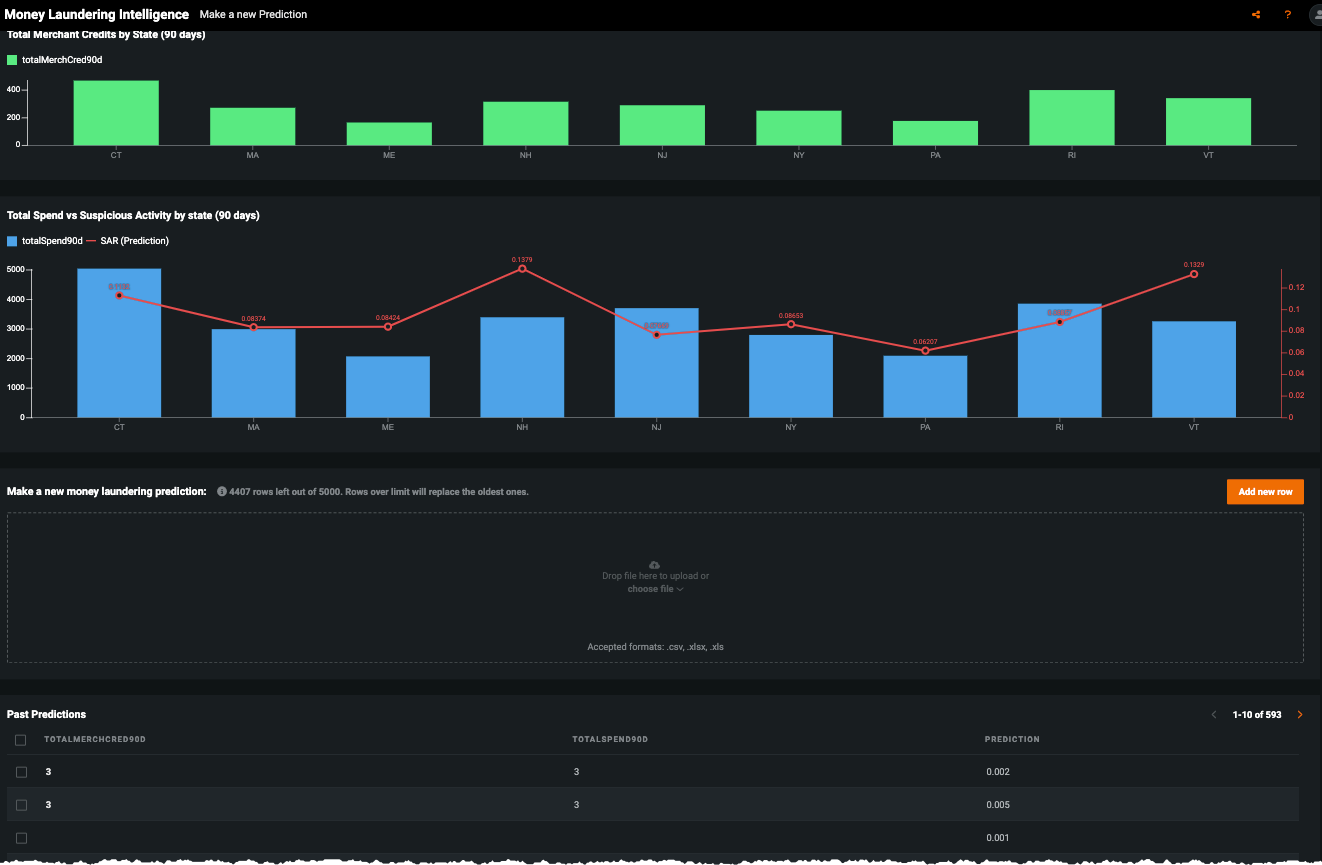

ノートブックのデモ¶
このアクセラレーターのノートブックバージョンは、 こちらを参照してください。
一歩進んだ操作:不均衡なターゲット¶
AMLおよび取引監視では、SAR率が非常に低いのが一般的であり(検出シナリオによって1%~5%)、非生産的なシナリオでは1%を下回ることもあります。 機械学習では、このような問題をクラスの不均衡と呼びます。 クラス不均衡のリスクを軽減し、限られた既知の不審な行為からできるだけ多くのことを機械に学習させるには、どうすればよいでしょうか。
DataRobotでは、クラス不均衡の問題に対応するためのさまざまなテクニックを提供しています。 いくつかのテクニック:
-
さまざまな指標を用いてモデルを評価します。 二値分類では(この例で構築している偽陽性低減モデルのように)、リーダーボード上のモデルをランク付けするためのデフォルトの指標としてLogLossが使用されます。 ルールベースのシステムは非生産的であることが多く、その結果SAR率が非常に低くなるため、優先順位付けリストのアラートの上位5%に含まれるSAR率など、別の指標を確認するほうが効果的です。 このモデルの目的は、高い優先度スコアに高いリスクアラートを割り当てることです。したがって、優先度スコアの上位に高いSAR率を設定するのが最適です。 下図の例では、優先度スコアの上位5%のSAR率が70%を超えていることから(元のSAR率は10%未満)、このモデルがSARリスクに基づいてアラートをランク付けするのに非常に効果的であることがわかります。
-
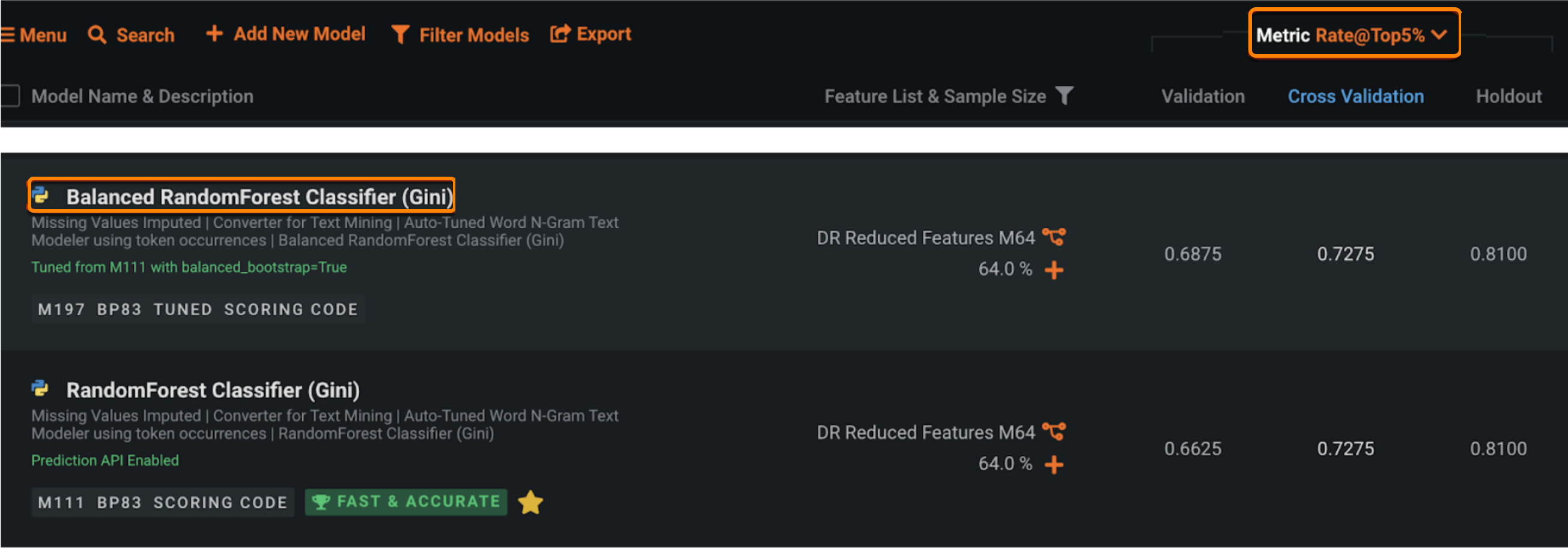
また、DataRobotでは、ハイパーパラメーターのチューニングも柔軟に行うことができ、クラス不均衡の問題解決にも役立つ可能性があります。 以下の例では、balance_boostrap(ランダムフォレスト内の各決定木でSARアラートと非SARアラートが同数のランダムサンプル)を有効にすることによって、ランダムフォレスト分類器モデルがチューニングされます。そのため、新しい「Balanced Random Forest Classifier」モデルの検定スコアが、親モデルよりわずかに優れていることがわかります。
- また、スマートダウンサンプリング([高度なオプション]タブから)を使用して、マジョリティークラス(非SARのアラートなど)を意図的にダウンサンプリングし、同様の精度で高速のモデルを構築することもできます。