LLMブループリントの構築¶
LLMブループリントは、LLMからレスポンスを生成するために必要なものの完全なコンテキストを表し、結果の出力は、その後プレイグラウンド内で比較できます。
LLMブループリントを作成するには、比較パネルまたはプレイグラウンドのようこそ画面から、該当するアクションを選択します。
作成ボタンをクリックすると、設定およびチャットツールが表示されます。
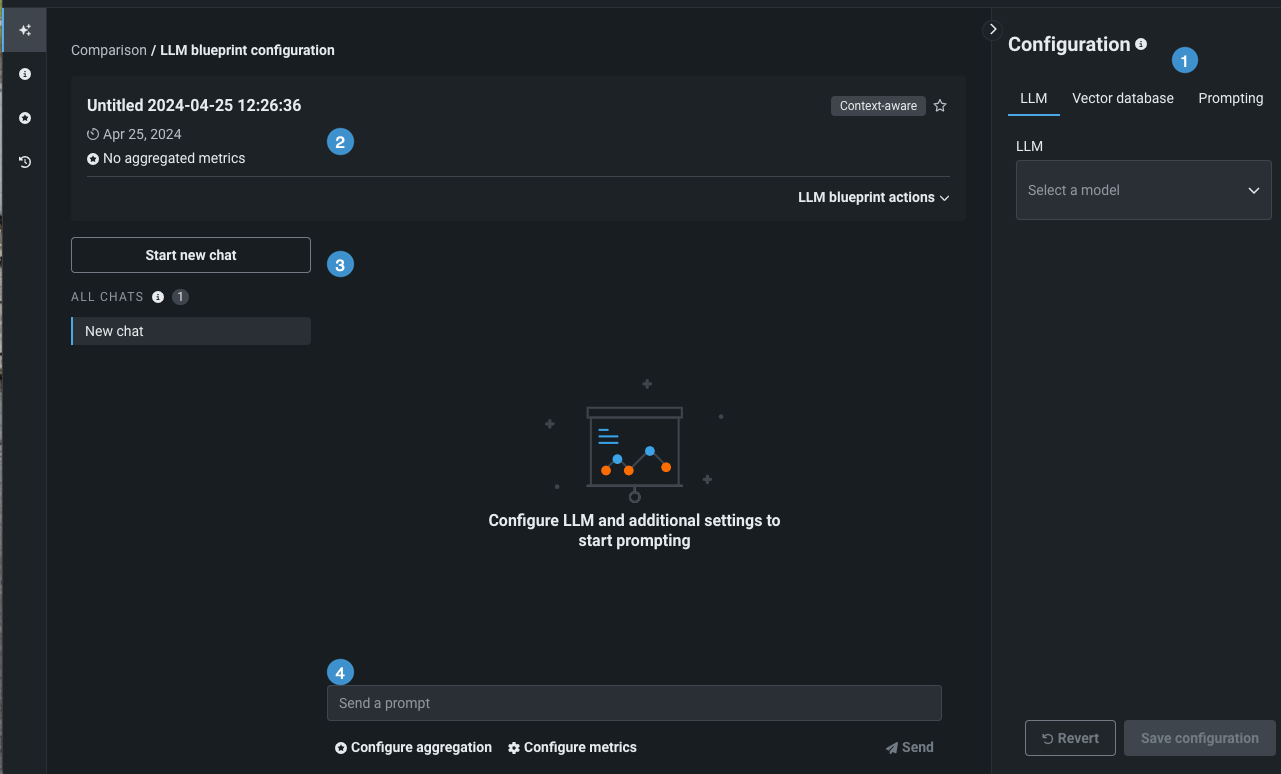
| 要素 | 説明 | |
|---|---|---|
| 1 | 設定パネル | LLMブループリントの作成から使用可能な設定の選択へのアクセスを提供します。 |
| 2 | LLMブループリントカードサマリー | LLMブループリント設定、指標、およびタイムスタンプのサマリーを表示します。 |
| 3 | チャットの履歴 | このLLMブループリントに送信されたプロンプトのレコードへのアクセスに加えて、新規チャットを開始するオプションを提供します。 |
| 4 | プロンプトエントリー | LLMブループリントとのチャットを開始するプロンプトを受け入れます。エントリーをアクティブにする前に設定を保存する必要があります。 |
既存のブループリントをコピーしてLLMブループリントを作成することもできます。
設定を行う¶
設定パネルでは、LLMブループリントを定義します。 以下の操作を行います。
LLMの選択と設定¶
DataRobotには LLMの選択機能があります。実際に何が利用可能となるかはクラスターとアカウントタイプによって異なります。
備考
LLMブループリントを作成する際には、使用非推奨またはサポート終了バッジの付いたLLMに注意してください。 これらのバッジは、今後または現時点でのサポート終了の通知を示します。 詳細についてはこちらを参照してください。使用非推奨のLLMとサポートが終了したLLMのリストについては、利用可能なLLMのページを参照してください。
または、プレイグラウンドにデプロイされたLLMを追加することもできます。このLLMは、検証されるとユースケースに追加され、関連付けられているすべてのプレイグラウンドで使用できます。 いずれの場合でも、ベースLLMを選択すると追加の設定オプションが表示されます。
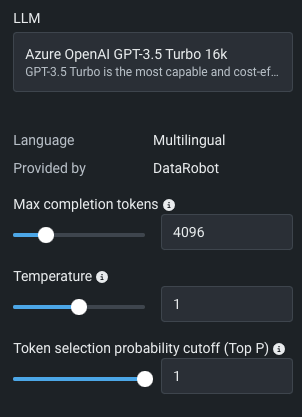
| 設定 | 説明 |
|---|---|
| 最大出力トークン数 | 完了時に許可されるトークンの最大数。 この値とプロンプトトークンの合計数は、モデルの最大コンテキストサイズ以下である必要があります。ここで、プロンプトトークン数は、システムプロンプト、ユーザープロンプト、最近のチャット履歴、ベクターデータベースの引用で構成されます。 |
| Temperature | Temperatureは、モデル出力のランダム性を制御します。 値を入力します(範囲はLLM依存)。値が大きいほど出力の多様性が高くなり、値が低いほど確定的な結果が高くなります。 値を0にすると、反復的な結果をもたらす可能性があります。 Temperatureは、出力でのトークン選択を制御するためのTop Pの代替です(以下の例を参照してください)。 |
| Top P | Top Pは、トークン選択の累積確率カットオフに基づいて、レスポンスに含まれる単語の選択を制御するしきい値を設定します。 たとえば、0.2では、上位20%の確率のかたまりだけが考慮されます。 数値が大きいほど、多様なオプションの出力が返されます。 出力でトークン選択を制御するためのTemperatureの代替として、Top Pがあります(以下の例を参照してください)。 |
TemperatureまたはTop P?
プロンプトの使用を検討してください。“完璧なアイスクリームサンデーを作るために、バニラアイスクリームを2回すくって上に乗せる...“。 推奨される次の単語の望ましいレスポンスは、ホットファッジ、パイナップルソース、ベーコンでしょう。 返されるものの確率を上げるには:
- ベーコンの場合、Temperatureを最大値に設定し、Top Pをデフォルトのままにします。 高いTemperatureでTop Pを設定し、ファッジとパイナップルの確率を高め、ベーコンの確率を減らします。
- ホットファッジの場合、Temperatureを0に設定します。
各ベースLLMにはデフォルト設定があります。 結果として、チャットを開始する前に必要な選択はLLMを選択することだけとなります。
デプロイ済みLLMの追加¶
DataRobotにデプロイされたカスタムLLMを追加するには、LLMブループリントの作成をクリックして、プレイグラウンドに新しいブループリントを追加します。 次に、プレイグラウンドのブループリントの設定パネルにあるLLMドロップダウン デプロイ済みLLMを追加をクリックします。
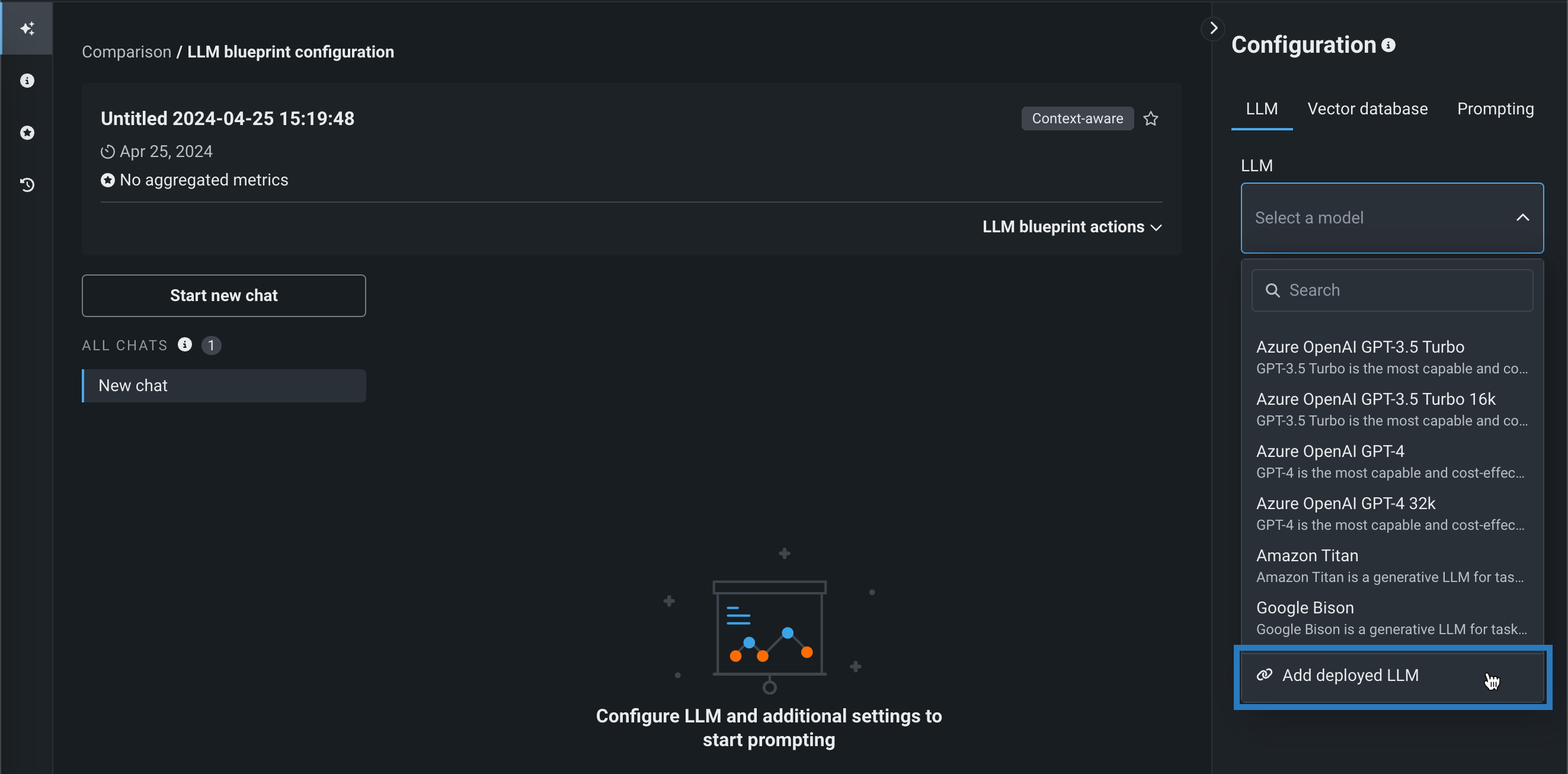
デプロイ済みLLMを追加ダイアログボックスで、デプロイ済みLLMの名前を入力し、デプロイ名ドロップダウンでDataRobotのデプロイを選択します。 選択したデプロイがボルトオンのガバナンスAPIに対応しているかどうかによって、以下の設定を行います。
chat関数を実装したデプロイ済みLLMを追加するする場合、プレイグラウンドは優先通信手段としてボルトオンのガバナンスAPIを使用します。 チャットモデルIDを入力して、プレイグラウンドからデプロイされたLLMへのリクエストにmodelパラメーターを設定し、検証して追加をクリックします。
チャットモデルID
デプロイされたLLMブループリントでボルトオンのガバナンスAPIを使用する場合、modelパラメーターの推奨値については利用可能なLLMを参照してください。 あるいは、予約値datarobot-deployed-llmを指定して、LLMプロバイダーのサービスを呼び出すときに、LLMブループリントが関連するモデルIDを自動的に選択するようにします。
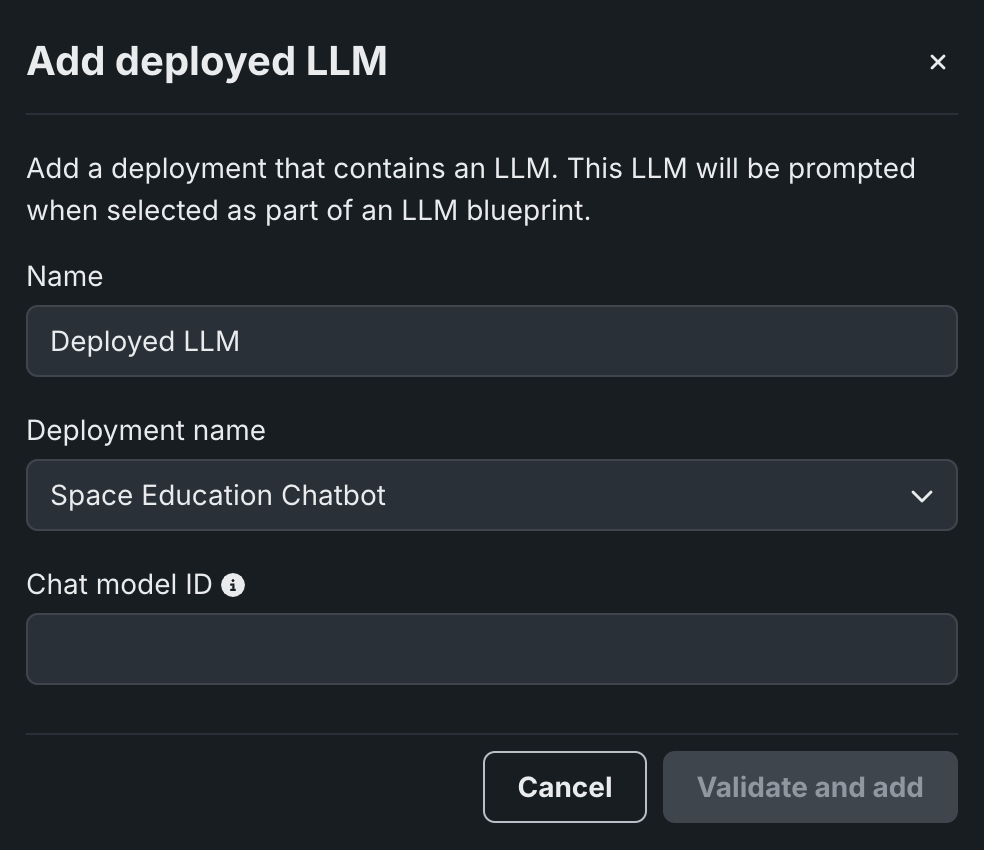
ボルトオンのガバナンスAPIを無効にして、代わりに予測APIを使うには、カスタムモデルからchat関数(またはフック)を削除して、モデルを再デプロイします。
ボルトオンのガバナンスAPIをサポートしていないデプロイ済みLLMを追加する場合、プレイグラウンドは優先通信手段として予測APIを使用します。 モデルワークショップでカスタムLLMを作成したときに定義したプロンプト列の名前および回答列の名前(promptTextおよびresponseTextなど)を指定して、検証して追加をクリックします。
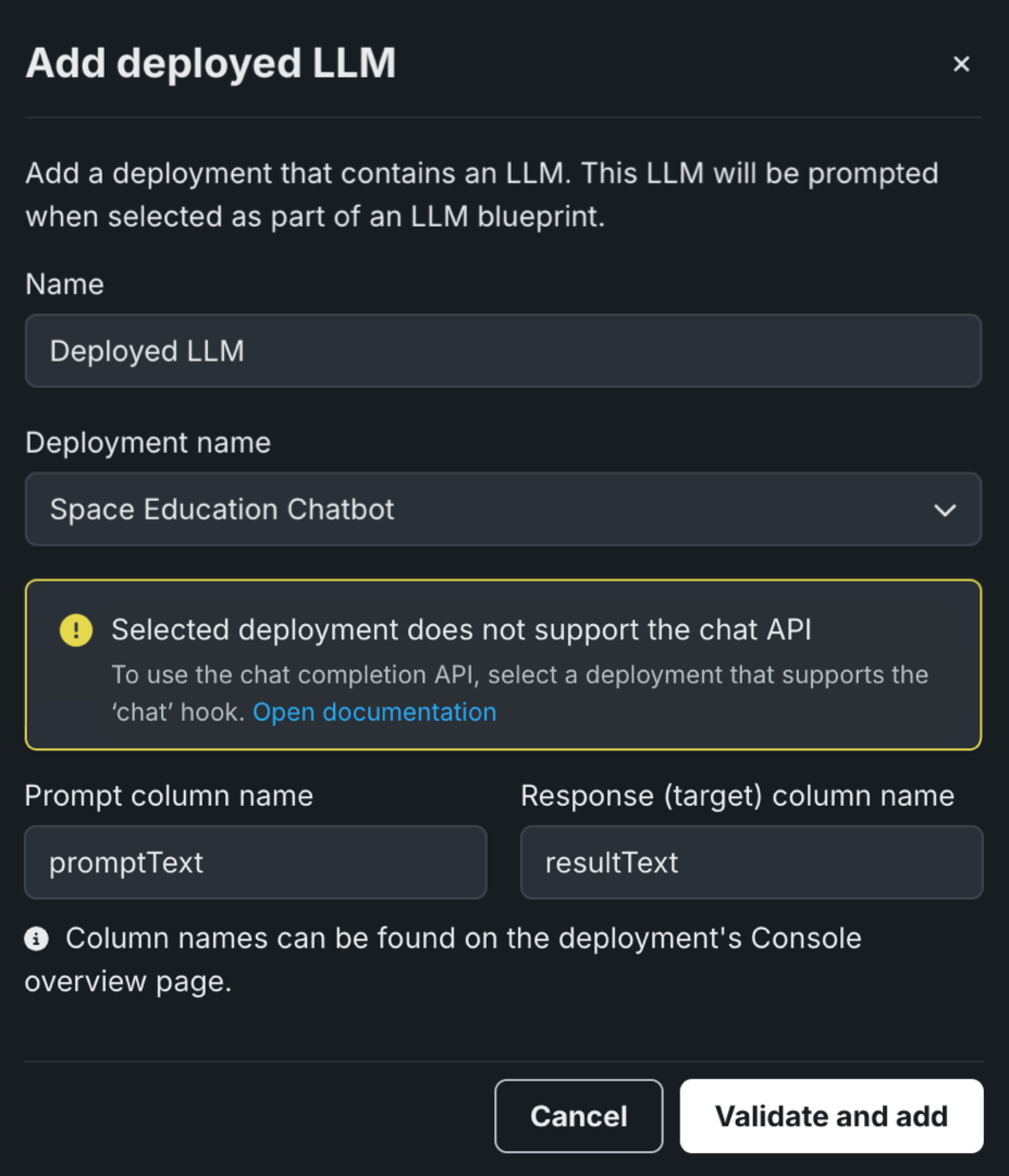
ボルトオンのガバナンスAPIを有効にするには、カスタムモデルのコードを修正して、chat関数(またはフック)を使用するようにし、モデルを再デプロイします。
カスタムLLMを追加し、検証が正常に完了した後、ブループリントの設定パネルにあるLLMドロップダウンでデプロイ済みのLLMをクリックし、追加したカスタムモデルの検証IDを選択します。

最後に、 ベクターデータベースおよび プロンプティングの設定を行い、設定を保存をクリックしてブループリントをプレイグラウンドに追加できます。
使用非推奨のLLMとサポートが終了したLLM¶
急速に進化するGenAIの状況において、LLMは常に改善されており、古いモデルは新しいバージョンで置き換えられ、無効になっています。 これに対処するため、DataRobotのLLM使用非推奨プロセスでは、LLMにバッジを付けて今後の変更を示しています。 その目的は、ベンダーの予期せぬサポート打ち切りからエクスペリメントやデプロイを守ることにあります。
使用非推奨のLLMのためのバッジは、LLMブループリントの作成パネルに表示されます。
![]()
あるいは、作成済みの場合、影響を受けるLLMブループリントには警告や通知が示され、カーソルを合わせると日付が表示されます。
![]()
-
LLMが使用非推奨プロセスにある場合、そのLLMのサポートは2か月後に終了します。 バッジと警告が表示されますが、機能は制限されません。
-
サポートが終了すると、そのモデルから作成されたアセットは引き続き表示できますが、新しいアセットは作成できません。 サポートが終了したLLMは、単一のプロンプトや比較プロンプトでは使用できません。
一部の評価指標、たとえば忠実度や正確性などは、その設定でLLMを使用します。 それらの場合、指標の表示または設定時、およびプロンプトの回答にメッセージが表示されます。
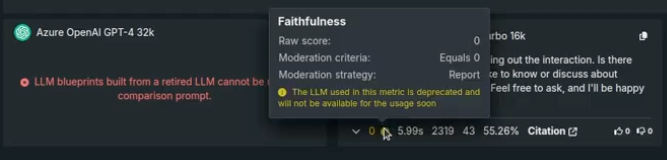
LLMがデプロイされている場合、DataRobotはベースとなるLLMに使用されている資格情報を制御できないため、デプロイは予測を返すことができません。 このような場合は、デプロイ済みのLLMを新しいモデルに置き換えてください。
使用非推奨のLLMとサポートが終了したLLMの全リストについては、利用可能なLLMのページを参照してください。
ベクターデータベースを追加¶
ベクターデータベースタブから、オプションで ベクターデータベースを選択できます。 この選択では、非構造化テキストの チャンクおよび各チャンクの対応するテキスト埋め込み(取得しやすいようにインデックス化済み)のコレクションで構成されたデータベースが識別されます。 ベクターデータベースはプロンプティングに必要ありませんが、回答を生成するためにLLMに関連データを提供するために使用されます。 ベクターデータベースをプレイグラウンドに追加して、指標を実験し、回答をテストします。
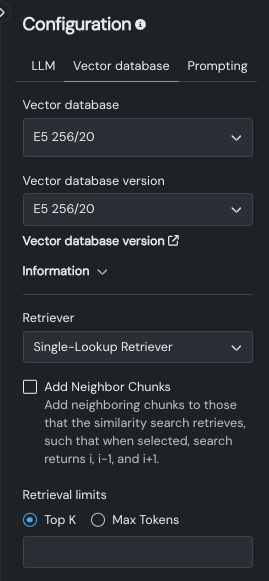
次のテーブルは、ベクターデータベースタブのフィールドを記述したものです。
ドロップダウン
| フィールド | 説明 |
|---|---|
| ベクターデータベース | ユースケースで使用可能なすべてのベクターデータベースを一覧表示します(したがって、そのユースケースのすべてのプレイグラウンドで使用できます)。 ベクターデータベースを追加オプションを選択すると、追加した新しいベクターデータベースが他のLLMブループリントで使用可能になりますが、適用するには LLMブループリント設定を変更する必要があります。 |
| ベクターデータベースのバージョン | LLMが使用するベクターデータベースの バージョンを選択します。 フィールドには、プレイグラウンドの作成時に表示していたバージョンがあらかじめ入力されています。 ベクターデータベースバージョン をクリックすると、プレイグラウンドを離れ、ベクターデータベースの詳細ページが開きます。 |
| 情報 | 選択したバージョンの設定情報を報告します。 |
| Retriever | LLMがベクターデータベースからチャンクを返す際に使用する方法、隣接チャンクの含め方、および取得制限を設定します。 |
Retrieverのメソッド¶
選択したRetrieverによって、LLMブループリントがベクターデータベースから最も関連性の高いチャンクを検索して取得する方法が決まります。 それらは、言語モデルに提供される情報を指示します。 以下のいずれかのメソッドを選択します。
| 方法 | 説明 |
|---|---|
| Single-Lookup Retriever | クエリーごとに単一ベクターデータベースのルックアップを実行し、最も類似したドキュメントを返します。 |
| Conversational Retriever(デフォルト) | チャット履歴に基づいてクエリーを書き換え、コンテキストアウェアな回答を返します。 つまり、このRetrieverは、最初のステップとしてクエリーの書き換えを追加したSingle-Lookup Retrieverと同様に機能します。 |
| Multi-Step Retriever | 結果を返すときは、次の手順を実行します。
|
詳細:Retrieverとコンテキスト
LLMへのプロンプトで使用されるコンテキストの状態とRetriever選択の関係性を理解することは重要です。 以下の表では、コンテキストなし(各クエリーが独立している)とコンテキスト認識(チャット履歴が考慮される)の両方について、各Retrieverに対するガイダンスと説明を提供しています。 各Retrieverについては上記を参照してください。
| Retriever | コンテキスト認識なし | コンテキスト認識 |
|---|---|---|
| 回答を返すプロセス | ||
| なし | LLMにクエリーを要求します。 | LLMにクエリーとクエリー履歴を要求します。 |
| Single-Lookup Retriever |
|
|
| Conversational Retriever | スタンドアロンクエリーを取得する履歴がないため、代わりにSingle-Lookup Retrieverを使用します。 |
|
| Multi-Step Retriever | 履歴がないため、このRetrieverは推奨されません。ただし、5つの新しい検索クエリーを使用することで、最終的な回答に最適なドキュメントを取得できる可能性があります。 |
|
隣接チャンクを追加を使用して、類似性検索が取得するチャンクに、ベクターデータベース内の近隣するチャンクを追加するかどうかを制御します。 有効にすると、Retrieverはi、i-1、およびi+1(たとえば、クエリーでチャンク番号42を取得すると、チャンク41と43も取得されます)を返します。

また、プライマリーチャンクにのみ類似度スコアが付与されている点にも注目してください。 これは、隣接チャンクが回答の一部として計算されるのではなく、追加されるためです。
「コンテキストウィンドウの拡張」または「コンテキストの強化」として知られるこの方法は、取得されたチャンクに隣接する周辺のチャンクを含めることで、より完全なコンテキストを提供します。 これを可能にする理由には、次のようなものがあります。
- 1つのチャンクが文の途中で切れてしまったり、重要な文脈を見逃してしまったりする可能性があります。
- 関連情報は複数のチャンクにまたがる可能性があります。
- 回答には、周囲のチャンクからのコンテキストが必要な場合があります。
返されるドキュメントの数を制御する検索の上限を設定する値を入力します。
Top K(近傍法)に設定した値は、ベクターデータベースから取得する関連チャンクの数をLLMに指示します。 チャンクの選択は、 類似性スコアに基づいて行われます。 以下の点に注意してください。
- 値を大きくすると、より広範囲をカバーできますが、処理のオーバーヘッドが増加し、関連性の低い結果が含まれる可能性があります。
- 値を小さくすると、より焦点の絞られた結果が得られ、処理も速くなりますが、関連する情報を見逃す可能性があります。
最大トークン数では、以下の内容を指定します。
- ベクターデータベースを構築するときにデータセットから抽出された各テキストチャンクの最大サイズ(トークン単位)。
- 埋め込みの作成に使用されるテキストの長さ。
- RAG操作で使用される引用のサイズ。
プロンプティング戦略の設定¶
プロンプティング戦略では、コンテキスト(チャット履歴)設定を行い、オプションでシステムプロンプトを追加します。
コンテキスト状態の設定¶
コンテキストには2つの状態があります。 チャット履歴をプロンプトと一緒に送信して、回答に関連するコンテキストを含めるかどうかを制御します。
| 状態 | 説明 |
|---|---|
| コンテキスト認識 | 入力を送信する際、以前のチャット履歴がプロンプトに含まれます。 この状態がデフォルトです。 |
| コンテキスト認識なし | チャットからの履歴をコンテキストに含めない。 |
備考
コンテキストの状態と、その状態が選択したRetrieverメソッドと連携してどのように機能するかを考慮します。
チャット内で、1回限り(コンテキストなし)とコンテキストアウェアを切り替えることができます。 これらはそれぞれ独立した履歴コンテキストのセットになります。コンテキストアウェアからコンテキストなし、そしてコンテキストアウェアに戻ると、プロンプトから以前の履歴がクリアされます。 (これが行われるのは、新しいプロンプトが送信されたときだけです。)
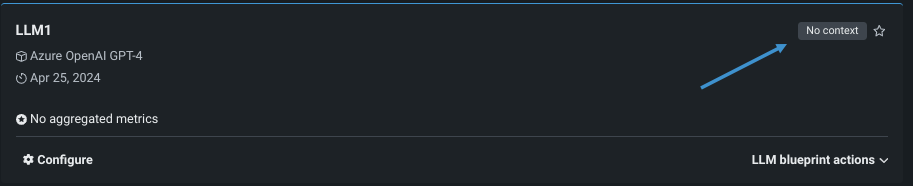
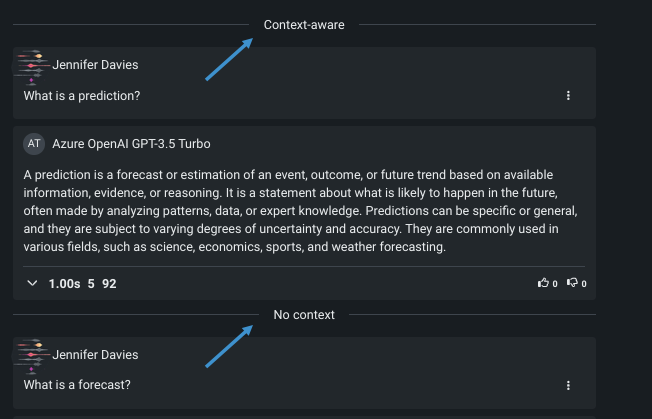
コンテキストの状態は2つの方法で報告されます。
-
バッジは、設定ビューと比較ビューの両方でLLMブループリント名の右側に表示され、現在のコンテキストの状態を報告します。

-
設定ビューでは、コンテキスト設定の状態がディバイダーによって示されます。
システムプロンプトの設定¶
オプションのフィールドであるシステムプロンプトは、このLLMブループリントの個々のすべてのプロンプトの先頭にある「汎用」プロンプトです。 LLMのレスポンスを指示およびフォーマットします。 システムプロンプトは、レスポンス生成中に作成される構造、トーン、形式、コンテンツに影響を与えることがあります。
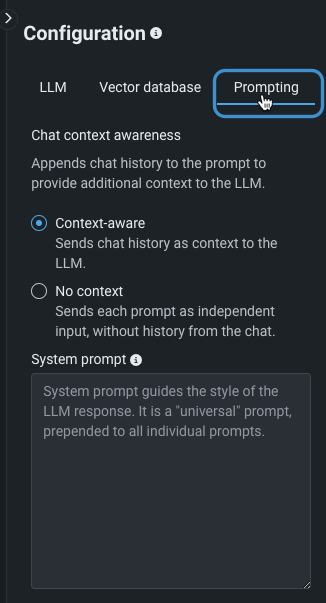
比較ドキュメントのシステムプロンプトアプリケーションの例を参照してください。
LLMブループリントのアクション¶
LLMブループリントで使用可能なアクションには、左側の比較パネルの名前の横にあるアクションメニュー 、または選択したLLMブループリントのLLMブループリントのアクションからアクセスできます。
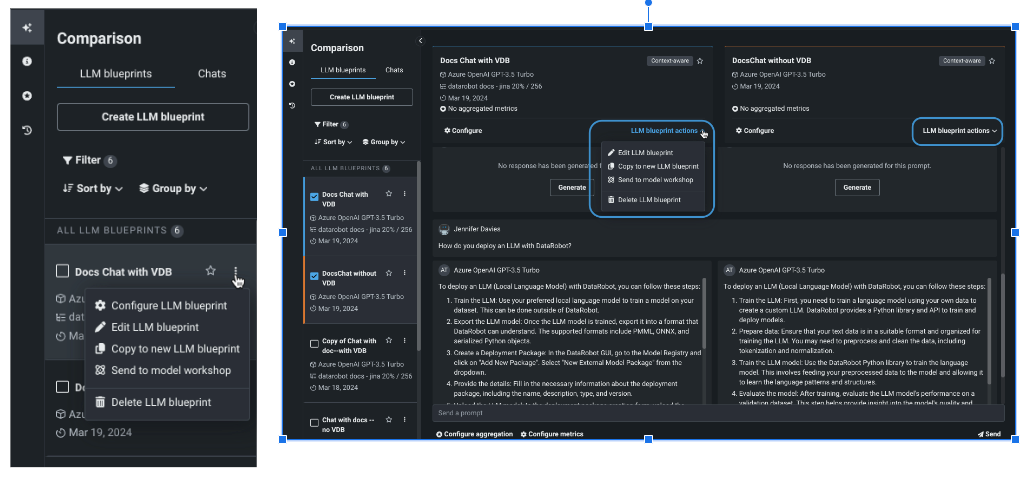
| オプション | 説明 |
|---|---|
| LLMブループリントの設定 | 比較パネルからのみ。 追加のチューニングを行うために、選択したブループリントの 設定を開きます。 |
| LLMブループリントの編集 | LLMブループリント名を変更するためのモーダルを提供します。 名前を変更すると、新しい名前と 保存された すべての設定が保存されます。 設定が保存されていない場合は、最後に保存されたバージョンに戻ります。 |
| 新しいLLMブループリントにコピー | 選択したブループリントのすべての保存済み設定から新しいLLMブループリントを作成します。 |
| モデルワークショップに送信 | LLMブループリントを レジストリに送信し、そこでモデルワークショップに追加されます。 そこからカスタムモデルとしてデプロイできます。 |
| LLMブループリントを削除 | LLMブループリントを削除します。 |
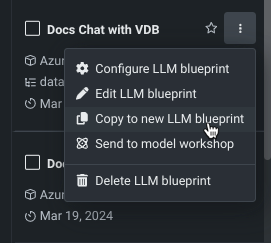
LLMブループリントをコピー¶
既存のLLMブループリントをコピーして、設定を継承できます。 このアプローチは、少し異なるブループリントを比較する場合や、自分が作成しなものでないブループリントを共有プレイグラウンドで使用する場合に適しています。
コピーは、次のいずれかの方法で作成できます。
-
左側のパネルにある既存のブループリントから、アクションメニュー をクリックし、新しいLLMブループリントにコピーを選択して、元のブループリントの設定を継承する新しいコピーを作成します。
新しいLLMブループリントが開き、追加の設定を行うことができます。 オプションで、名前を変更するLLMブループリントのアクションを選択します。
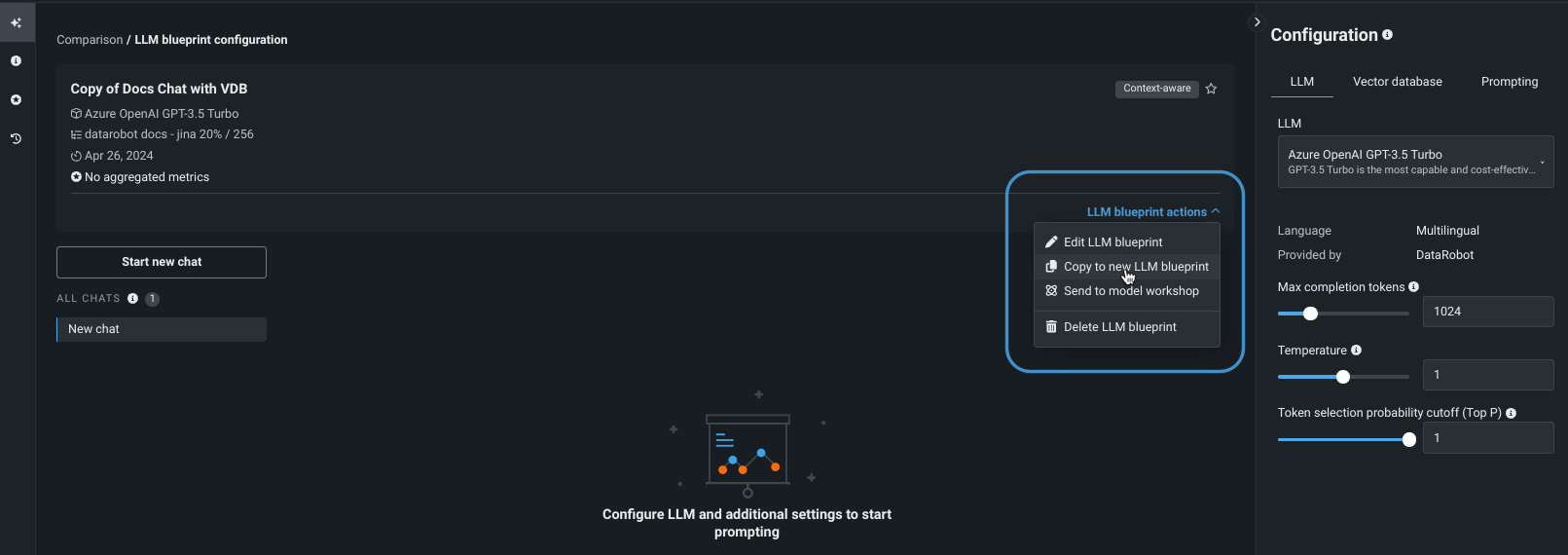
-
開いているLLMブループリントからLLMブループリントのアクションを選択し、新しいLLMブループリントにコピーを選択します。
LLMブループリント設定の変更¶
LLMブループリントの設定を変更するには、比較パネルのアクションメニュー からLLMブループリントの設定を選択します。 LLMブループリント設定とチャット履歴が表示されます。 設定を変更し、設定を保存します。
LLMブループリントを変更すると、それに関連付けられたチャット履歴も保存されます(設定がコンテキスト認識の場合)。 LLMブループリントを変更しても、チャット内のすべてのプロンプトは保持されます。
- プロンプトを送信したときに含まれる履歴は、最新のチャットコンテキスト内のすべての要素です。
- LLMブループリントをコンテキストなしに切り替えると、各プロンプトは独自のチャットコンテキストになります。
- コンテキスト認識に切り替えると、チャット内で新しいチャットコンテキストが開始されます。
設定ビューのチャットは、比較ビューのチャットとは別物です。履歴が混ざり合うことはありません。