ベクターデータベースのデータソース¶
DataRobotの生成モデリングは、2つのタイプのベクターデータベースをサポートしています。
- ローカル。「社内」構築されたベクターデータベース。
DataRobotとして識別され、データレジストリに保存されています。 - 外部。検定と登録のためにモデルワークショップでホストされ、ユースケースディレクトリリストでは
Externalとして識別されます。
データセットの要件¶
ベクターデータベースの作成に使用するデータセットをアップロードする場合、サポートされている形式は.zipまたは.csvです。 ファイルにはdocumentとdocument_file_pathの2つの列が必須です。 最大50のメタデータ列を追加して、プロンプトクエリーの際にフィルターに使用することができます。 メタデータのフィルターでは、document_file_pathがsourceとして表示されます。
.zipファイルの場合、DataRobotはファイルを処理して、関連するリファレンスID(document_file_path)列を持つテキスト列(document)を含む.csvバージョンを作成します。 テキスト列の内容はすべて、文字列として扱われます。 リファレンスID列は、.zipがアップロードされると自動的に作成されます。 すべてのファイルは、アーカイブのルート(root)、またはアーカイブ内の単一のフォルダーに配置する必要があります。 フォルダーツリー階層の使用はサポートされていません。
サポートされているファイルコンテンツの詳細については、 注意事項を参照してください。
内部ベクターデータベース¶
DataRobotの内部ベクターデータベースは、取得速度を維持しながら、許容可能な取得精度を確保するために最適化されています。 内部ベクターデータベースのデータを追加します。
-
データの準備:
- ナレッジソースを構成するファイルを単一の
.zipファイルに圧縮します。 ファイルを選択して、すべてのファイルを保持するフォルダーをzipまたは圧縮できます。 - 必須の
document列とdocument_file_path列、および最大50の追加メタデータ列を持つCSVを準備します。document_file_path列には、解凍された.zipファイルの個々の項目がリストされます。document列には、各ファイルの内容がリストされます。 メタデータのフィルターのために、document_file_pathはsourceとして表示されます。 - 以前に エクスポートされたベクターデータベースを使用します。
- ナレッジソースを構成するファイルを単一の
-
ファイルをアップロードします。 アップロードは、次のいずれかの方法で行うことができます。
-
ローカルファイルまたはデータ接続からの ワークベンチユースケース。
-
ローカルファイル、HDFS、URL、JDBCデータソースからの AIカタログ。 DataRobotは
.zipファイルを.csv形式に変換します。 登録したら、プロフィールタブを使用してデータを確認できます。
-
DataRobotでデータが利用可能になったら、それをプレイグラウンドで使用する ベクターデータベースとして追加できます。
ベクターデータベースのエクスポート¶
ベクターデータベースまたは特定バージョンのデータベースをデータレジストリにエクスポートして、別のユースケースで再利用できます。 エクスポートするには、ユースケースのベクターデータベースタイルを開きます。 アクション メニューをクリックし、最新のベクターデータベースバージョンをデータレジストリにエクスポートを選択します。
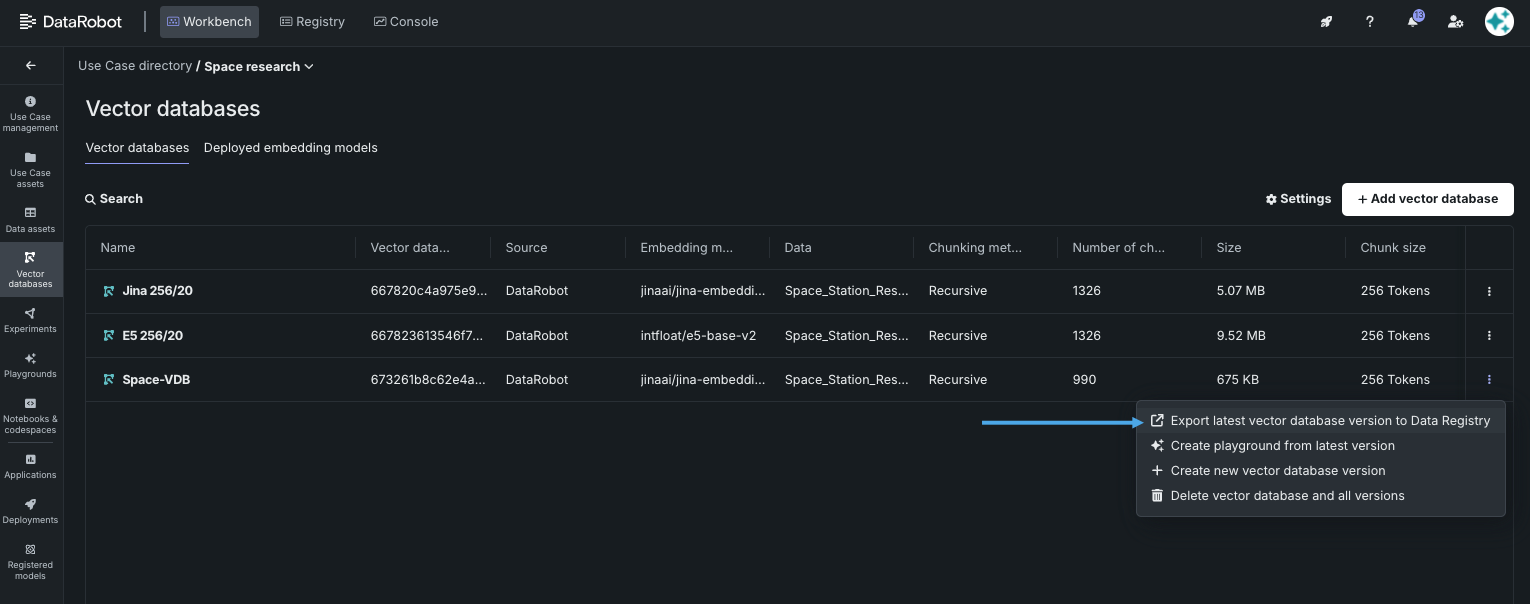
エクスポートすると、ジョブが送信されたことが通知されます。 データアセットタイルを開き、データレジストリから使用するために登録されているデータセットを確認します。 また、AIカタログにも保存されます。
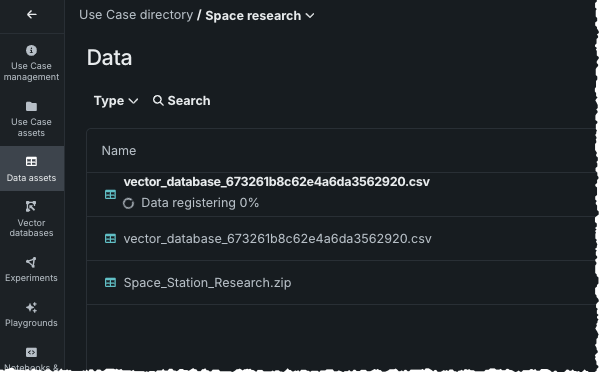
登録されると、データセットをプレビューしたり、このデータセットから新しいベクターデータベースを作成したりできます。
エクスポートから新しいベクターデータベースを作成する前にプレビューするには、データアセットタイルのアクション メニューからベクターデータベースを作成を選択します。 次に、データを追加を選択します。
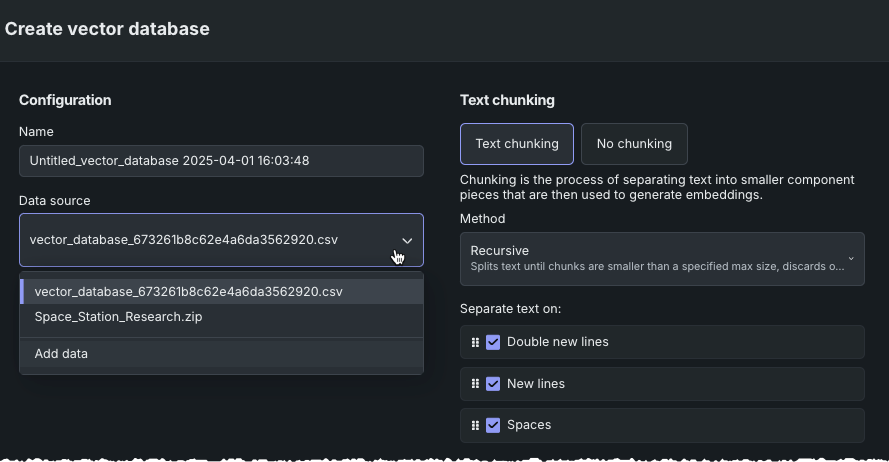
データレジストリが開きます。 新しくエクスポートされたベクターデータベースを選択します。 データプレビューでは、ベクターデータベースの各チャンクがデータセットの行になっていることが示されます。
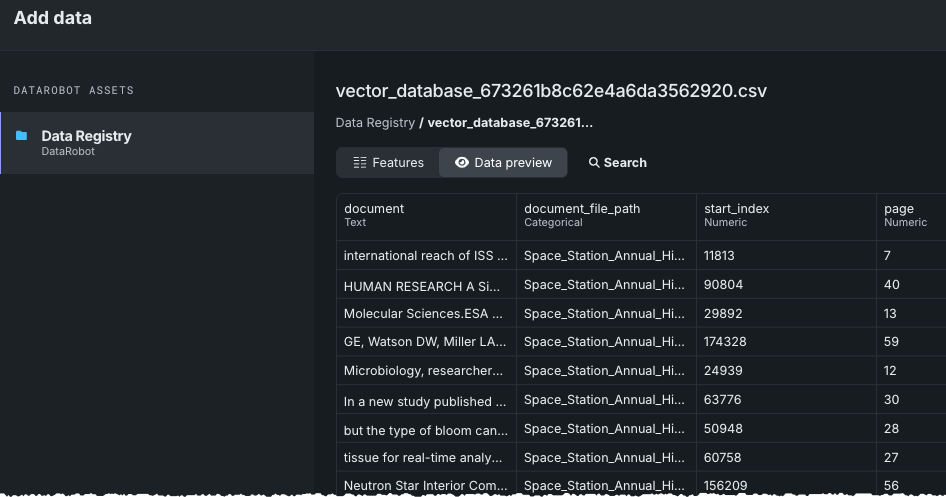
アクション メニューから、ベクターデータベースを作成を選択します。 データベースを設定するためのモーダルが開きます。
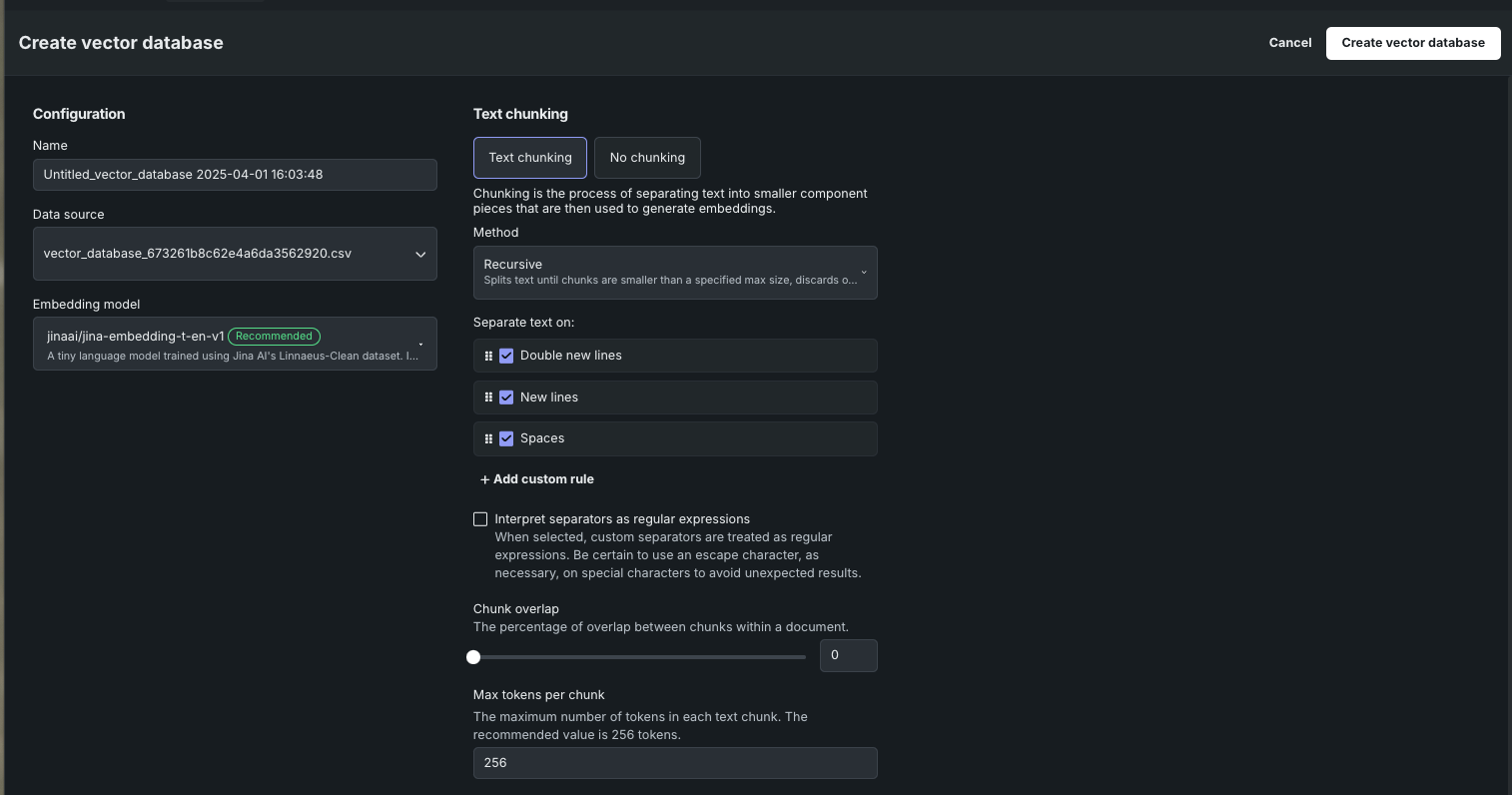
AIカタログからデータセットをダウンロードし、チャンクレベルで変更してから、再度アップロードして、新しいバージョンまたは新しいベクターデータベースを作成できます。
外部ベクターデータベース¶
外部"bring-your-own"(BYO)ベクターデータベースは、独自のモデルとデータソースを使用して、カスタムモデルデプロイをLLMブループリントのベクターデータベースとして活用する機能があります。 外部ベクターデータベースの使用はUI経由で行うことはできません。DataRobotのPythonクライアントを使用して外部ベクターデータベースを作成する手順を説明した ノートブックを確認してください。
外部ベクターデータベースの主な機能:
-
カスタムモデルの統合:独自のカスタムモデルをベクターデータベースとして組み込み、高い柔軟性とカスタマイズを可能にします。
-
入力および出力形式の互換性:外部BYO ベクターデータベースは、LLMブループリントとのシームレスな連携を確保するために、指定された入力および出力形式に準拠する必要があります。
-
検定と登録:カスタムモデルデプロイは、外部ベクターデータベースとして登録する前に、必要な要件を満たすように検定する必要があります。
-
LLMブループリントとのシームレスな統合:登録されると、外部ベクターデータベースをローカルベクターデータベースと同様にLLMブループリントで使用できます。
-
エラー処理と更新:この機能では、エラー処理と更新機能を使用して、LLMブループリントを再検定または 複製を作成して、カスタムモデルデプロイの問題や変更に対処できます。
基本的な外部ワークフロー¶
このノートブックで詳しく説明されている基本的なワークフローは次のとおりです。
- APIを介してベクターデータベースを作成します。
- カスタムモデルデプロイを作成して、ベクターデータベースをDataRobotに取り込みます。
- デプロイが登録されたら、ノートブックでのベクターデータベース作成の一部としてデプロイにリンクします。
ユースケース内のベクターデータベースタブから、ユースケースのすべてのベクターデータベース(および関連バージョン)を表示できます。 外部ベクターデータベースの場合、ソースタイプのみが表示されます。 これらのベクターデータベースはDataRobotによって管理されていないため、他のデータはレポートには利用できません。.