埋め込みNVIDIA NIMを使用したベクターデータベースの作成¶
プレミアム機能
DataRobotでNVIDIA Inference Microservices (NIM)を利用するには、GenAIのエクスペリメントとGPUを使用した推論のためのプレミアム機能にアクセスする必要があります。 これらの機能を有効にするには、DataRobotの担当者または管理者にお問い合わせください。
レジストリから利用できるNVIDIA Inference Microservices(NIM)には、埋め込みモデルが含まれています。 デプロイされた埋め込みモデルをユースケースに追加して、チャンクに分割された非構造化テキストのコレクションを作成し、各チャンクに対して埋め込みを生成できます。 チャンクも埋め込みもベクターデータベースに保存され、検索に使用できます。 ベクターデータベースを必要に応じて使用することで、LLMの回答を特定の情報に基づいたものにすることができます。また、ベクターデータベースをLLMブループリントに割り当てて、RAGの運用時に活用できます。 ベクターデータベースの役割は、LLMに送信される前のプロンプトを関連性のあるコンテキストで強化することです。 利用可能な埋め込みNVIDIA NIMをそれぞれ以下に示します。
arctic-embed-lllama-3.2-nv-embedqa-1b-v2nv-embedqa-e5-v5nv-embedqa-e5-v5-pb24h2nv-embedqa-mistral-7b-v2nvclip
登録済みの埋め込みNIMを備えたベクターデータベースを作成する¶
埋め込みNIMを登録したら、それをベクターデータベースに追加することができます。 DataRobotでは、デプロイプロセスが自動的に処理されます。
登録済みの埋め込みNVIDIA NIMを備えたベクターデータベースを作成するには:
-
レジストリ > モデルタブで、モデルを登録の横にある をクリックし、NVIDIA NGCからインポートをクリックします。
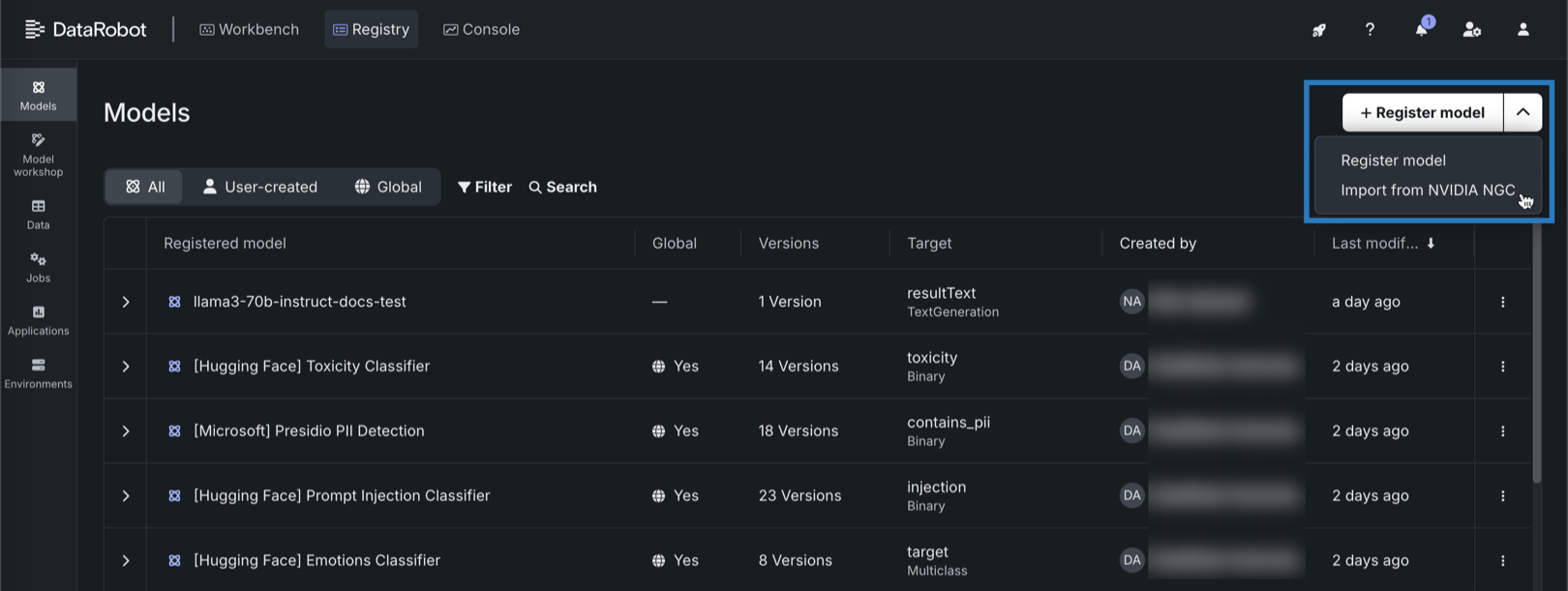
-
NVIDIA NGCからインポートパネルのNIMを選択タブで、ギャラリー内の埋め込みNIMをクリックします。
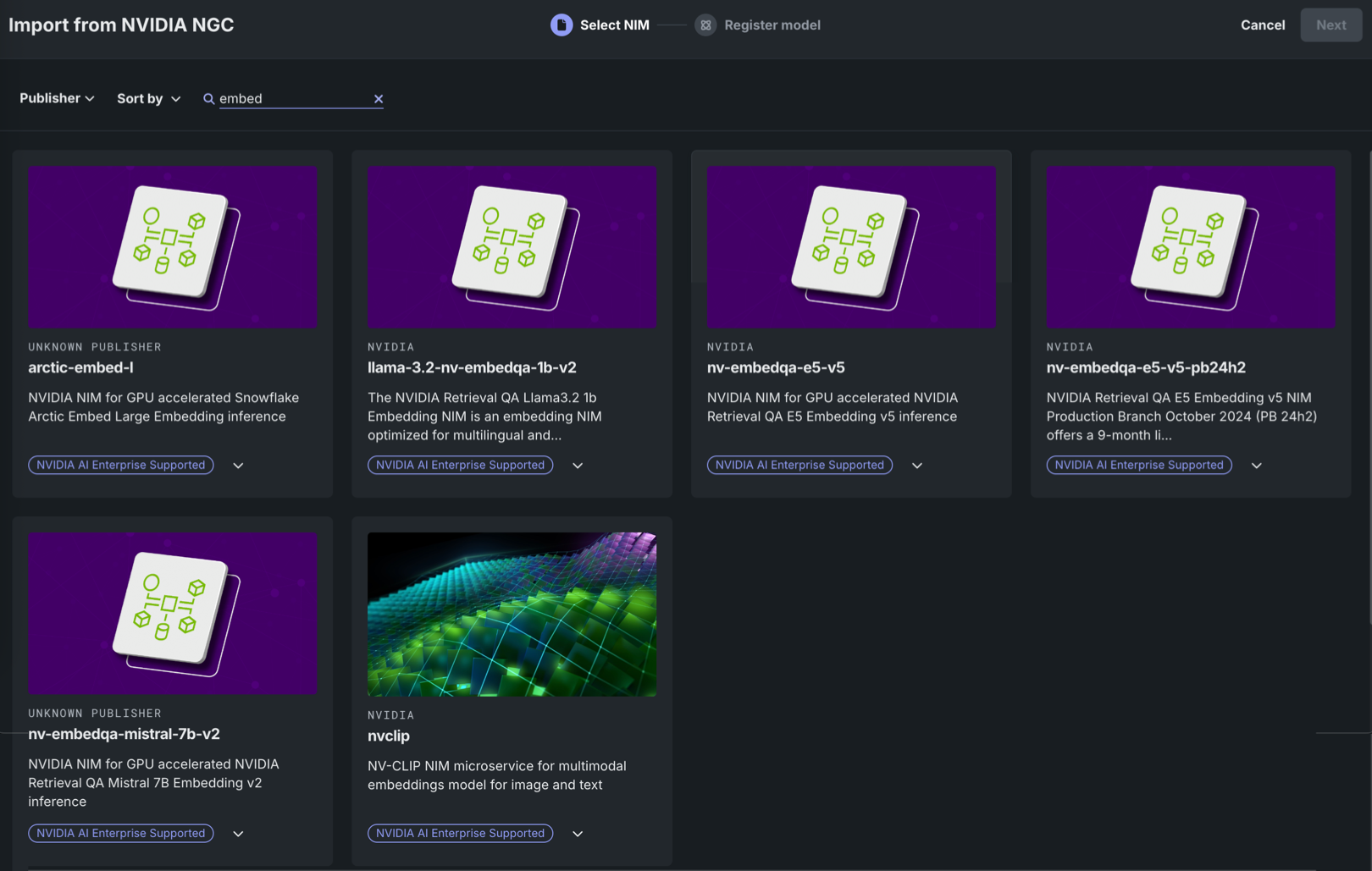
ギャラリーの検索
埋め込みモデルを検索するには、 検索、パブリッシャーでフィルター、またはソート条件をクリックして、ギャラリーを追加日順またはアルファベット順(昇順または降順)に並べ替えます。
-
NVIDIA NGCソースのモデル情報を確認し、次へをクリックします。
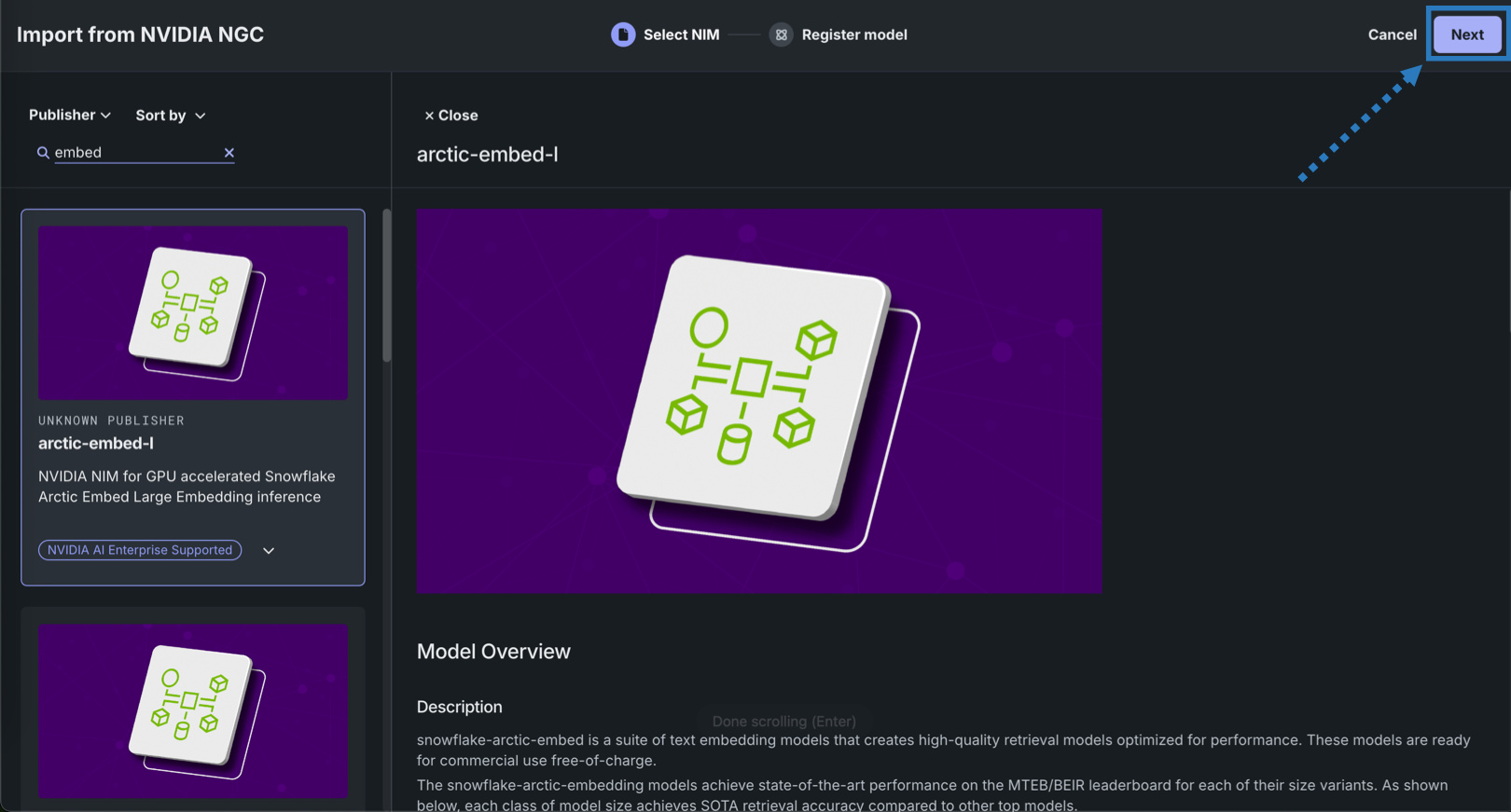
-
モデルの登録タブで、以下のフィールドを設定し、登録をクリックします。
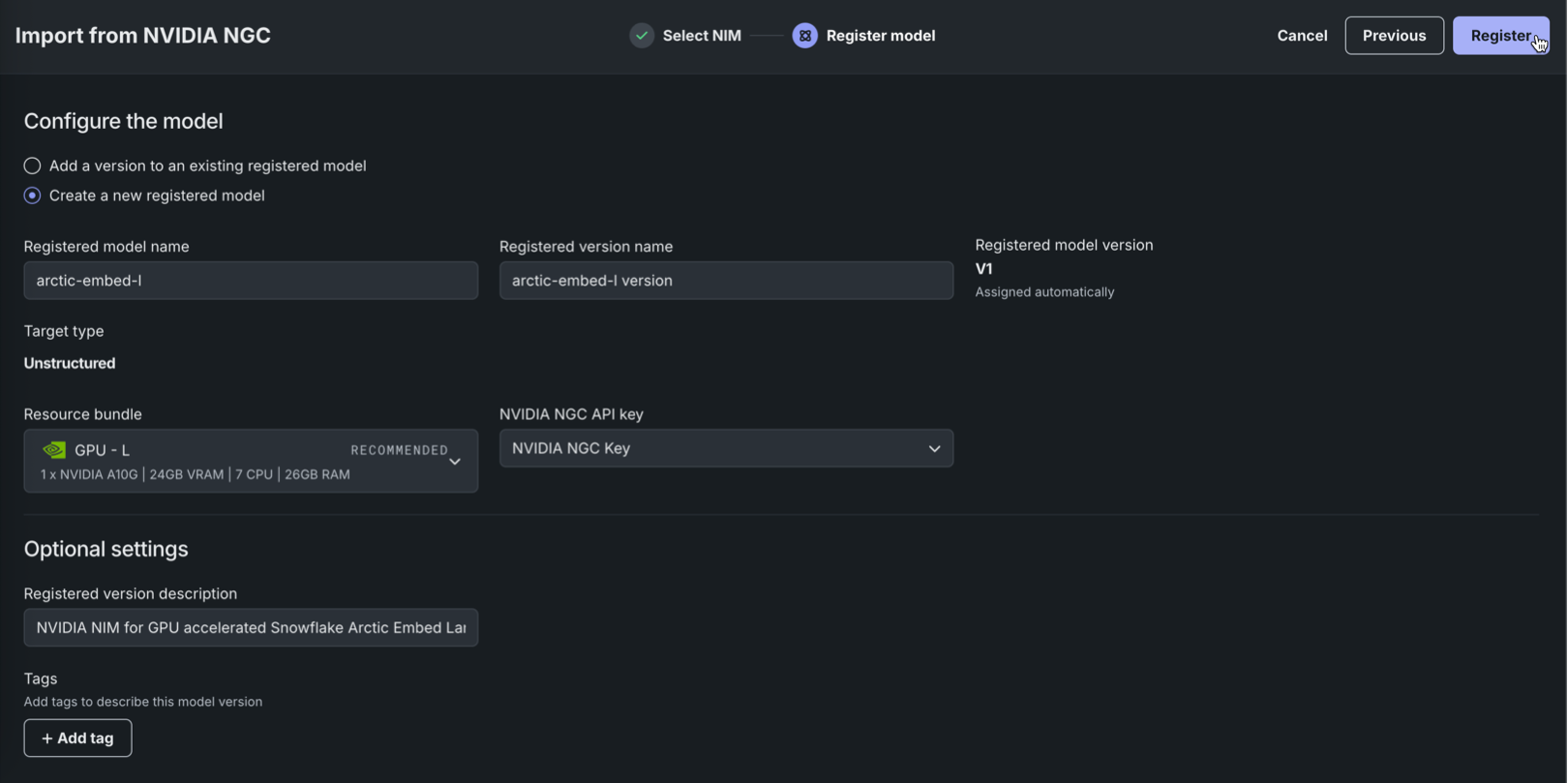
フィールド 説明 登録モデルの名前/登録済みのモデル 以下のいずれかを設定します。 - 登録モデルの名前:新しいモデルを登録するときは、その新規登録モデルに一意でわかりやすい名前を入力します。 組織内のどこかに存在する名前を選択すると、モデルの登録に失敗したという警告が表示されます。
- 登録済みのモデル:新規バージョンを追加する既存の登録済みモデルを選択します。
登録バージョンの名前 モデル名と versionが自動的に入力されます。 必要に応じて、バージョン名を変更するか、デフォルトのバージョン名を修正します。登録モデルのバージョン 自動的に割り当て済み。 作成するバージョンの予想バージョン番号(V1, V2, V3など)が表示されます。 新しいモデルとして登録を選択すると、これは常にV1になります。 リソースバンドル 自動的に推奨されます。 可能な場合、選択したモデルのGPU要件がリソースバンドルに置き換えられます。 ただし、互換性のあるリソースバンドルを検出できない場合があります。 十分なVRAMを備えたリソースバンドルを判別するには、そのNIMのドキュメントを参照してください。 NVIDIA NGCのAPIキー NVIDIA NGCのAPIキーに関連付けられた資格情報を選択します。 オプション設定 登録バージョンの説明 このモデルパッケージが解決するビジネス上の問題、またはより一般的に、このバージョンで表されるモデルについて説明します。 タグ + タグを追加をクリックし、モデルの バージョン にタグ付けするキーと値のペアごとに、キーと値を入力します。 新規モデルの登録時に追加されたタグがV1に適用されます。 -
登録モデルが構築されたら、ワークベンチに移動し、ユースケースを開きます。
-
ユースケースのベクターデータベースタブで、次のいずれかを実行します。
ユースケースに1つ以上のベクターデータベースを追加している場合は、右上の+ ベクターデータベースを追加ボタンをクリックします。
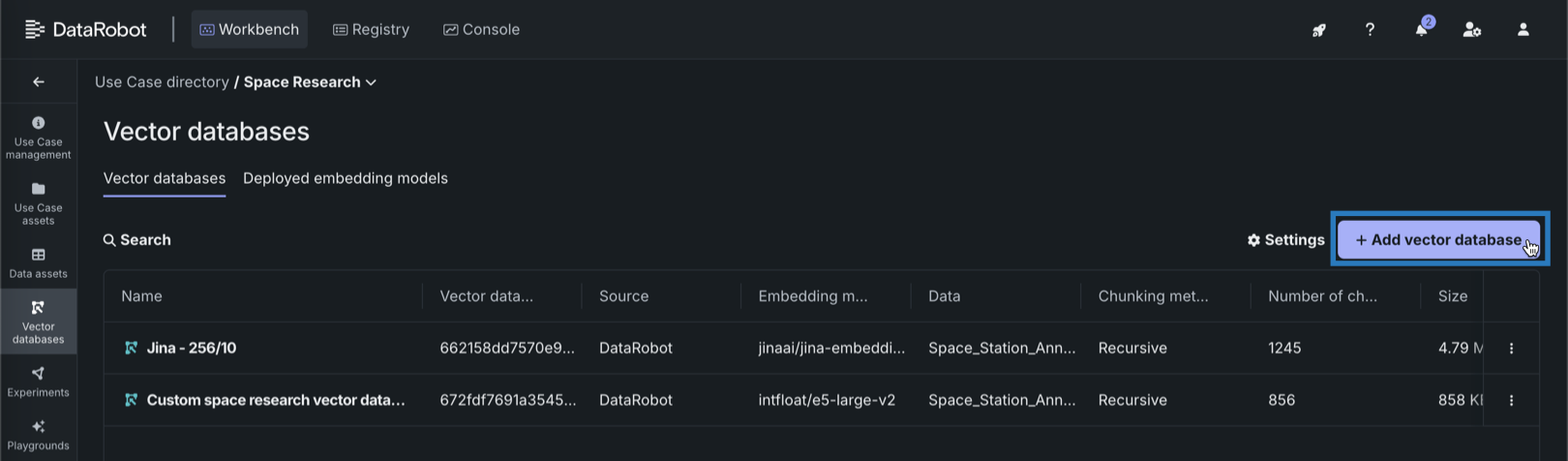
ユースケースにベクターデータベースを追加したことがない場合は、ページ中央のベクターデータベースを作成をクリックします。
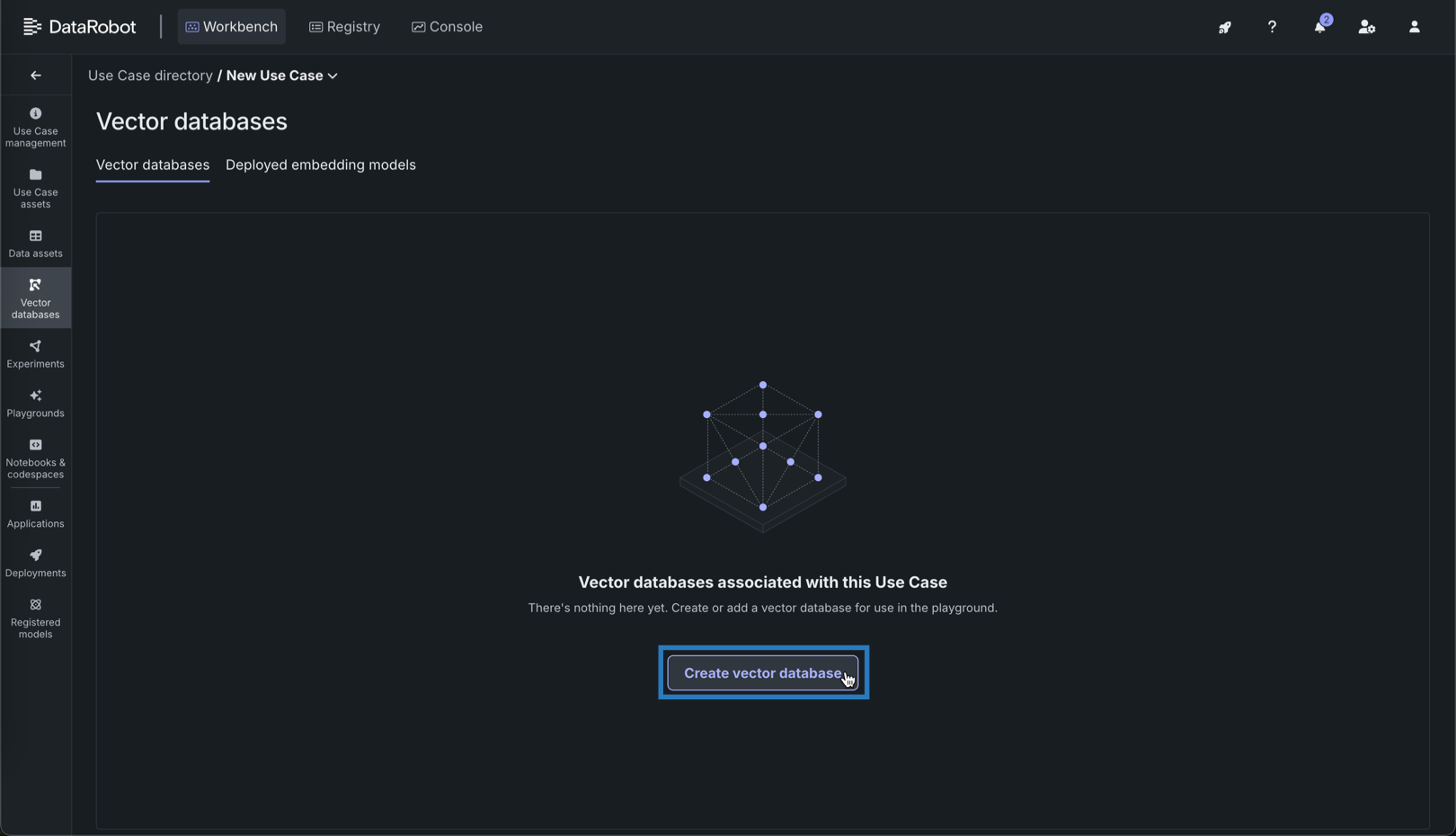
-
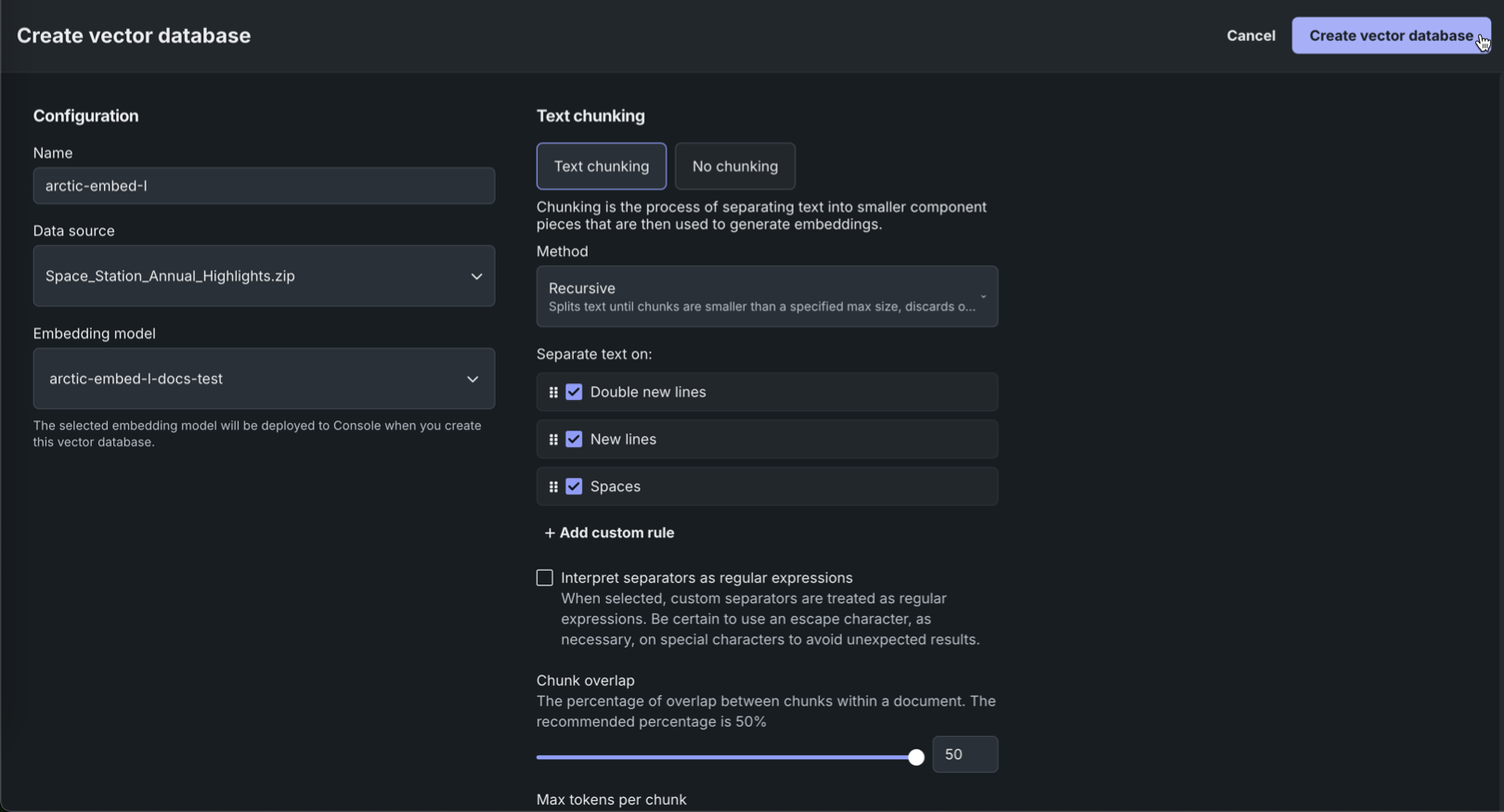
ベクターデータベースを作成パネルで、わかりやすい名前を入力します。 次に、データソースドロップダウンで、ユースケースに関連付けられているデータソースから選択するか、データを追加をクリックしてデータレジストリから新しいデータを追加します。
-
埋め込みモデルドロップダウンで、登録した埋め込みNIMをクリックします。 次に、ベクターデータベースのテキストチャンキング設定を行い、ベクターデータベースを作成をクリックします。
ベクターデータベースの作成時に、選択した埋め込みモデルがコンソールにデプロイされます。 必要に応じて、このプロセスでは、NIMの埋め込みに新しい予測環境が作成されます。
ベクターデータベースを作成したら、それを管理およびバージョニングしたり、プレイグラウンドのLLMに追加して回答を通知したりできます。
デプロイ済みの埋め込みNIMを備えたベクターデータベースの作成¶
すでに埋め込みNIMを登録し、かつデプロイしている場合は、デプロイ済みの埋め込みモデルとしてベクターデータベースに追加することができます。
登録およびデプロイ済みの埋め込みNVIDIA NIMを備えたベクターデータベースを作成するには:
-
ユースケースのベクターデータベースタイルで、次のいずれかを実行します。
ユースケースに1つ以上のベクターデータベースを追加している場合は、右上の+ ベクターデータベースを追加ボタンをクリックします。
ユースケースにベクターデータベースを追加したことがない場合は、ページ中央のベクターデータベースを作成をクリックします。
-
ベクターデータベースを作成パネルで、わかりやすい名前を入力します。 次に、データソースドロップダウンで、ユースケースに関連付けられているデータソースから選択するか、データを追加をクリックしてデータレジストリから新しいデータを追加します。
-
埋め込みモデルドロップダウンで、 デプロイ済み埋め込みモデルを追加をクリックします。
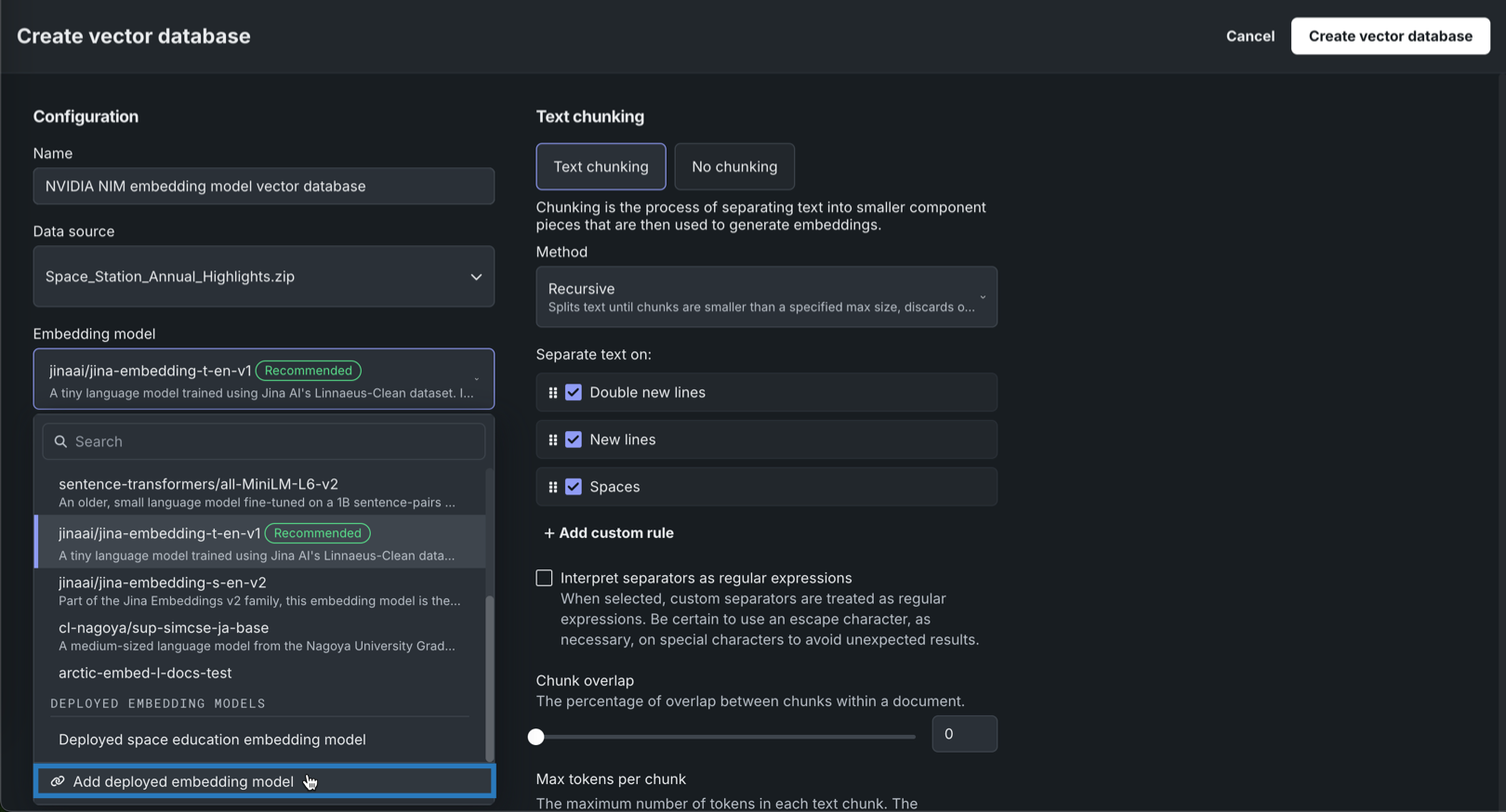
-
次のページで、NVIDIA NIMの埋め込みモデルを追加するために以下の設定を行い、検証して追加をクリックします。
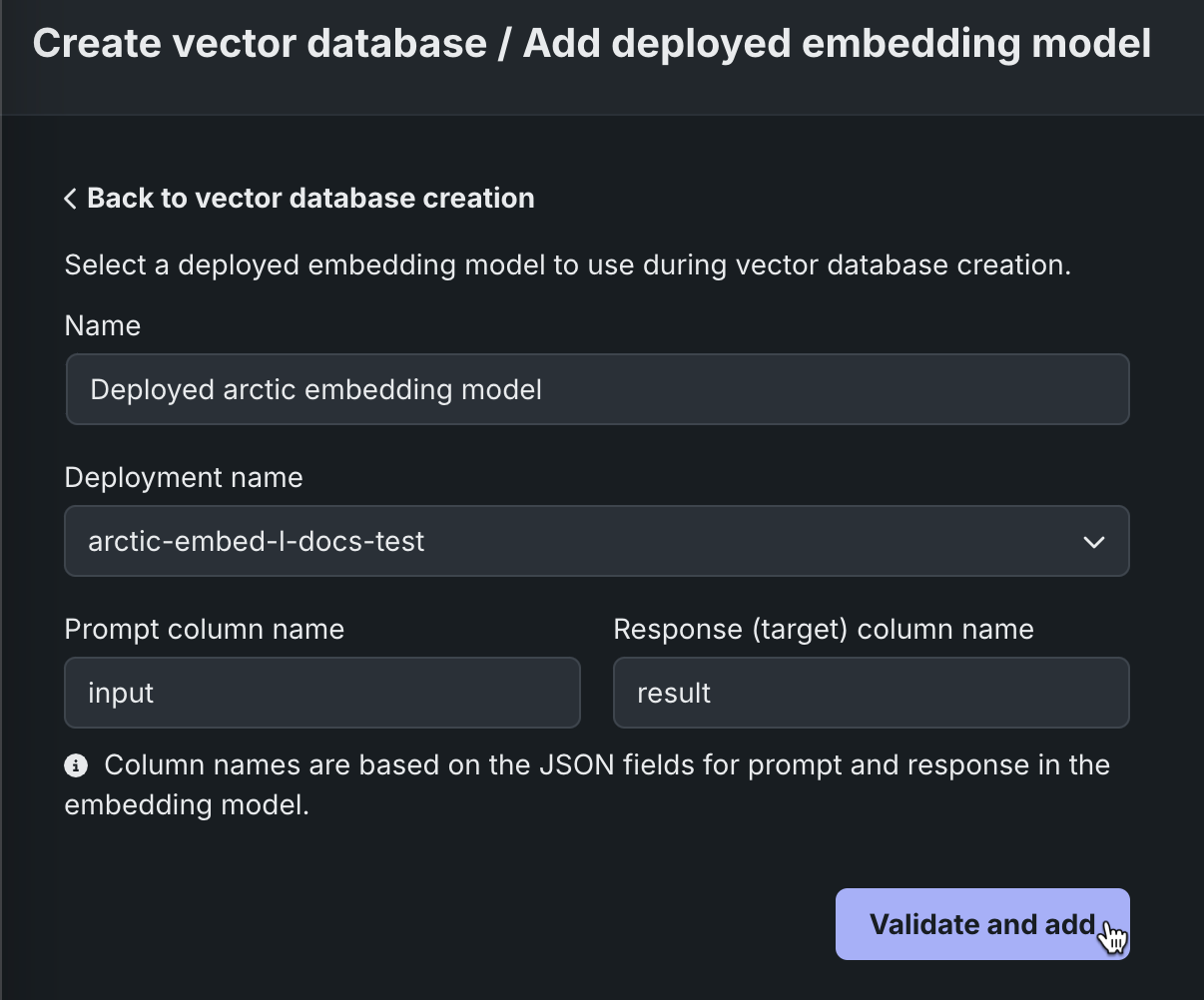
フィールド 説明 名前 作成する埋め込みモデルにわかりやすい名前を入力します。 デプロイ名 リストで、DataRobotに登録およびデプロイされているNVIDIA NIMの埋め込みモデルの名前を探し、デプロイ名をクリックします。 プロンプト列の名前 プロンプト列名として inputと入力します。回答列の名前 回答列名として resultと入力します。検証プロセス
検証プロセスには数分かかる場合があります。 プロセスが開始され、成功または失敗すると、通知が表示されます。
-
デプロイされた埋め込みモデルの検証が成功したら、埋め込みモデルメニューを開き、デプロイされた埋め込みモデルでNVIDIA NIMの埋め込みモデルを選択します。
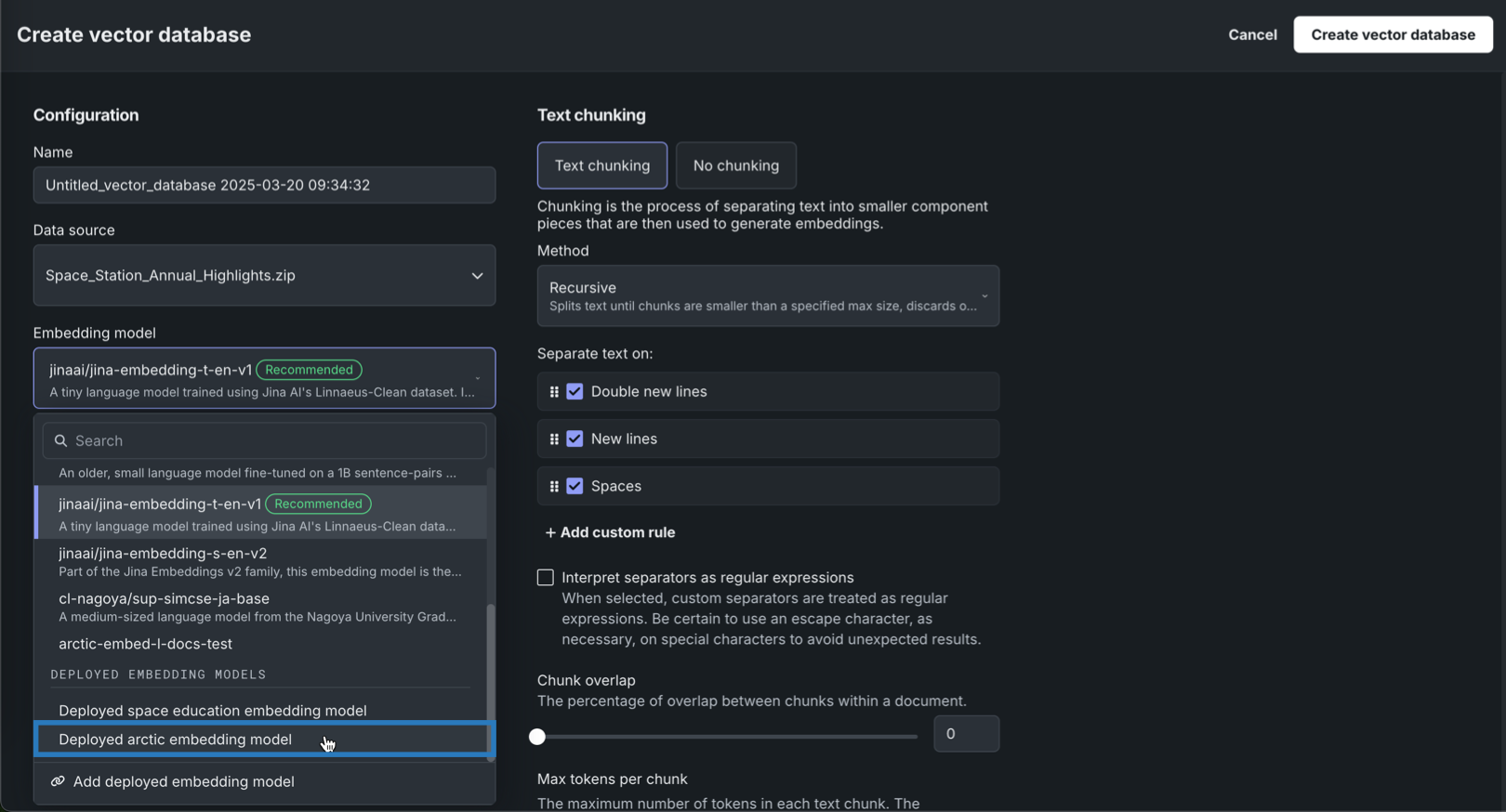
-
ベクターデータベースのテキストチャンキング設定を行い、ベクターデータベースを作成をクリックします。
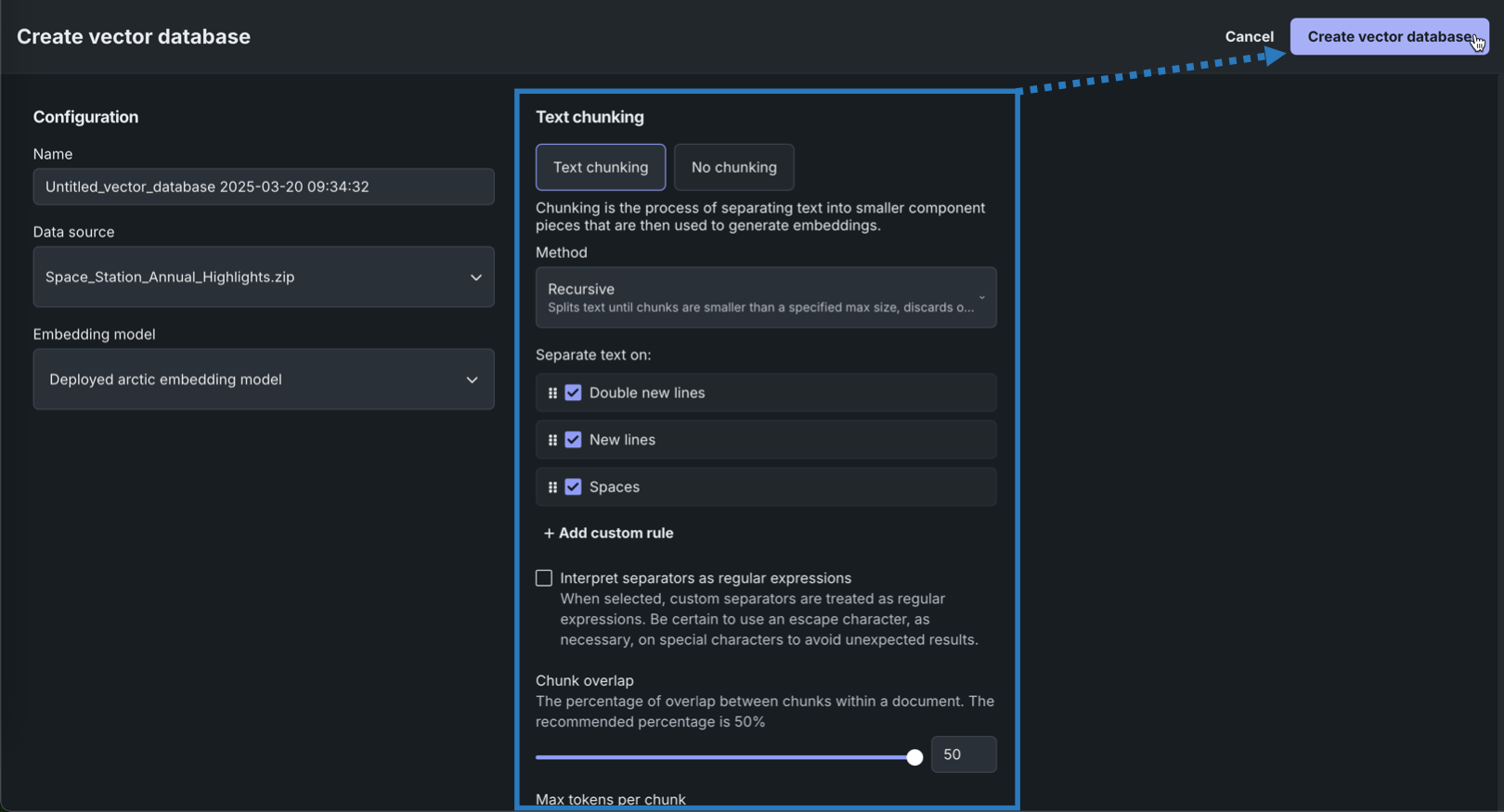
ベクターデータベースを作成したら、それを管理およびバージョニングしたり、プレイグラウンドのLLMに追加して回答を通知したりできます。