特徴量制約¶
特徴量制約タブには、制約を適用するための下表のツールが用意されています。 目的のフィールドに入力してモデルを構築したら、リーダーボードの説明 > 制約タブを使用して、制約付きでトレーニングしたモデルの結果を評価します。
| 制約 | 説明 |
|---|---|
| 単調性 | 特徴量とターゲットの間で影響の増減を制御します。 |
| ターゲットクラスを集計 | 多クラスモデリングでのクラスの集計方法を設定します。 |
| ターゲットラベルの一部削除 | 多ラベルモデリングでラベルの一部を削除する方法を設定します。 |
| 二項間の交互作用 | 一般化加法モデル(GA2M)の出力にどの二項間の交互作用を含めるかを制御します。 (教師なしプロジェクトや時系列プロジェクトでは利用できません。) |
単調性¶
単調性により、特徴量とターゲットの間に方向性のある関係を持たせます。 このタブでは、単調な特徴量セットの適用、モデルの選択、ポジティブクラスの割り当てを行います。
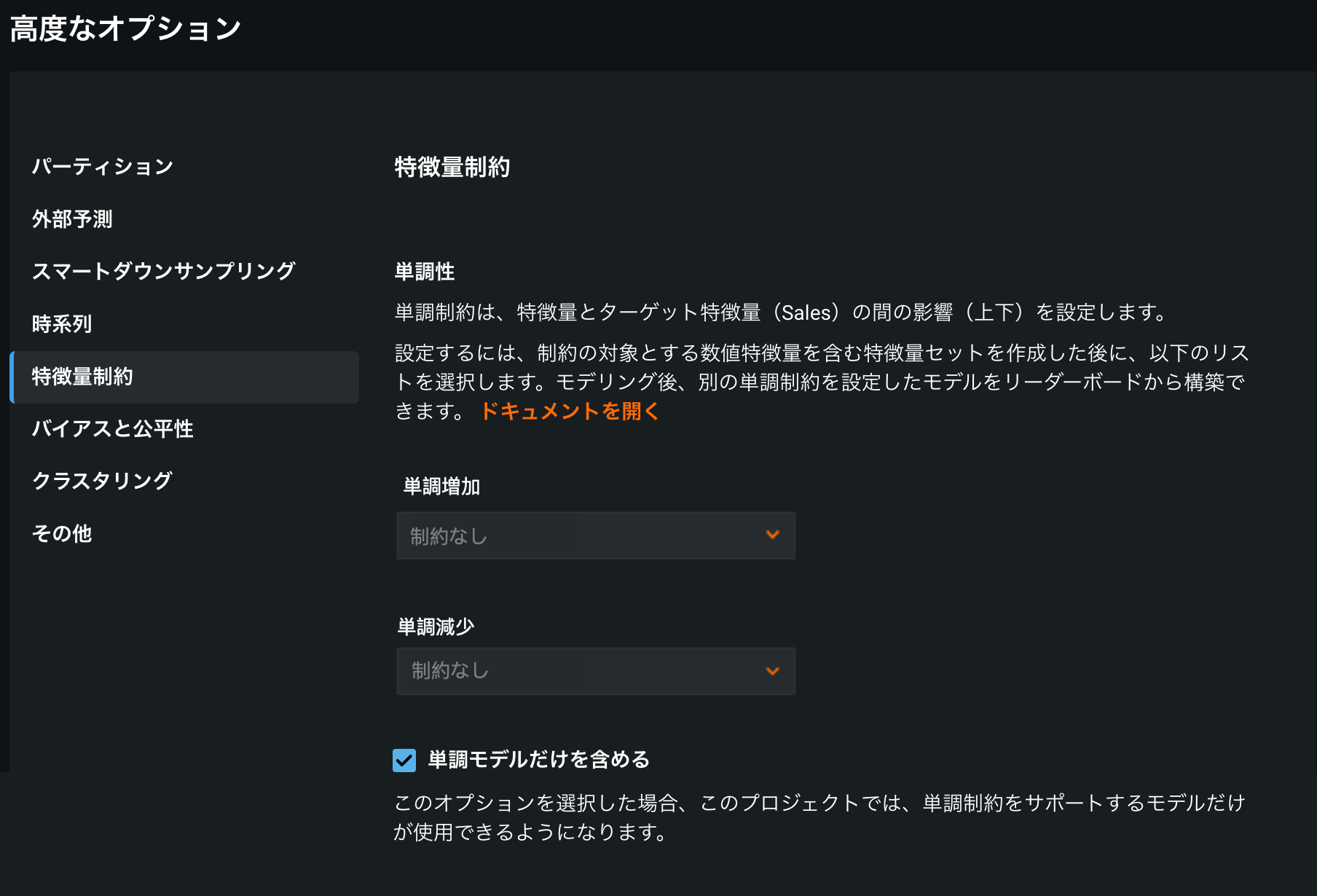
単調増加および単調減少¶
単調増加と単調減少では、単調モデリングを確実に行うためにDataRobotで適用する特徴量セットを設定します。 ドロップダウンから、単調増加や単調減少の制約を適用するために使用するセットを選択します。 これらは、モデル構築のために選択した特徴量セットに加えて適用されます。
このオプションは、プロジェクトに数値のみの特徴量セットが定義されている場合のみ利用可能であることに注意してください。 モデリングの前に適切な特徴量セットを作成できます。 また、モデルを初めて実行した後に、リーダーボードメニューから特徴量セットを作成し、モデルを再トレーニングすることもできます。
以下のオプションが用意されています。
| 特徴量セット | 説明 |
|---|---|
| 制約なし | このオプションを選択すると、トレーニング中に単調制約は適用されません。 |
| 元の特徴量 | このオプションは、元の特徴量セット内のすべての特徴量が数値、割合、長さ、通貨のいずれかの型である場合にのみ使用できます。 |
| 有用な特徴量 | このオプションは、有用な特徴量セット内のすべての特徴量が数値、割合、長さ、通貨のいずれかの型である場合にのみ使用できます。 |
| ユーザー定義の特徴量セット | プロジェクトで定義した、特徴量の型の要件を満たすすべてのセット。 |
単調モデルだけを含める¶
このオプションを選択すると、単調制約をサポートするモデルだけが(オートパイロットで)構築されるか、リポジトリから利用できるようになります。 さらに、オートパイロットではAVG Blenderだけが作成されます。
ポジティブクラスの割り当て¶
ポジティブクラスの割り当てオプションは、二値分類プロジェクトでのみ利用可能です。 予測スコアが分類しきい値よりも高い場合に使用するクラスを設定します。 単調制約を適用する場合、予測値とポジティブクラスの確率の間に制約が適用されます。
デフォルトでは、DataRobotは英数字順にソートし、2番目の値をポジティブクラスとして割り当てます。 たとえば、ターゲットが{1,0}、{Yes, No}、または{True, False}のデータセットを読み込むと、英数字によるソート後のそれぞれのケースで、ポジティブクラスは1、Yes、Trueになります。
集計および一部削除¶
クラス数やラベル数が多いプロジェクトのサポートをDataRobotがどのように管理するかを設定することができます。 プロジェクトのタイプに応じて表示される、適切なトグルを使用します。
ターゲットクラスを集計¶
集計の設定を行うには、ターゲットクラスを集計までスクロールします。

次の表では、各フィールドについて説明します。
| 要素 | 説明 | |
|---|---|---|
| 1 | ターゲットクラスを集計 | 集計機能を有効にします。 検出されたクラスが1,000個を超えている場合、選択がオンになり、変更はできません。 クラスが1,000個未満の場合、選択はデフォルトではオフですが、有効にすることもできます。 |
| 2 | 集計クラスの名前 | "Other" bin(この集計プランの設定に該当しないすべてのクラスを含むビン)の名前を設定します。 これはデータセットで除外された値のすべての行を表します。 列内の既存のターゲット値とは異なる名前を指定する必要があります。 |
| 3 | 非集計クラスでの最小頻度 | "Other" binでのバケット化を回避するために必要な、クラスに属する行の最小出現数を設定します。 つまり、インスタンスの数が少ないクラスは、1つのクラスに折りたたまれます。 |
| 4 | 非集計クラスの最大数 | 集計後のクラスの最終的な数を設定します。 最後のクラスは"Other" binです。 (たとえば、900と入力した場合、データからの899クラスのbinと、集約されたクラスの"Other" bin 1つが存在することになります。) 3から1,000までの値を入力してください。 |
| 5 | 集計から除外されるクラス | 集計から保護されるクラスのコンマ区切りリストを指定し、対象となる頻度の低いクラスについて予測できるようにします。 |
集計の例¶
あるデータセットのターゲット列に以下のパラメーターがあり、一意の値(クラス)が8つあるとします。
| クラス | 行数 |
|---|---|
| A | 1024 |
| B | 512 |
| C | 256 |
| D | 128 |
| E | 64 |
| F | 32 |
| G | 16 |
| H | 8 |
パラメーターは次のように設定されています。
| パラメーター | 値 |
|---|---|
| 集計クラスの名前 | DR_RARE_TARGET_VALUES |
| 非集計クラスでの最小頻度 | 50 |
| 非集計クラスの最大数 | 5 |
| 集計から除外されるクラス | [E、H] |
クラスマッピングでは、最初に最小頻度要件が次のように適用されます。
| クラス | 行数 | インパクト |
|---|---|---|
| A | 1024 | なし。最小頻度を上回る |
| B | 512 | なし。最小頻度を上回る |
| C | 256 | なし。最小頻度を上回る |
| D | 128 | なし。最小頻度を上回る |
| E | 64 | なし。最小頻度を上回る |
| Other bin | 48 | 上記FとGの行を結合。最小頻度に満たない |
| H | 8 | 集計から除外 |
クラスマッピングの結果、一意の値は7つになりました(FとGは削除され、集約されたクラスに置き換えられました)。 「最大クラス数」パラメーターで最大数を5に設定しているため、さらに2つ「削除」する必要があります。次に、DataRobotは、集計から除外されていない(EとHはすでに除外)低頻度のCとDを削除します。 その結果、最終的なターゲットクラスの値分布は次のようになります。
- クラスAとBが最も頻度が高い
- クラスEとHは集計から除外される
- クラスC、D、F、Gは、単一のクラス_RARE_TARGET_VALUESに集約される
最終的に、モデリング対象となるのは次の5クラスです。
| クラス | 行数 |
|---|---|
| A | 1024 |
| B | 512 |
| 集約されたクラス(C, D, Other) | 256 + 128 + 48 |
| E | 64 |
| H | 8 |
予測時のレスポンス時間
無制限の多クラスを使用する場合、予測データセットのクラス数と行数に比例してレスポンス時間が直線的に増加するため、予測を行う際には、より小さな「チャンク」サイズを使用することをお勧めします。
各クラスの予測では、小数点以下最大10桁(0.xxxxxxxxxx)まで生成できます。 これにより、各行で1クラスあたり13バイトになる可能性があります。 したがって、たとえば、10,000行の単一データセットに対して1,000クラスの多クラスで予測を行った場合、「13B * 1,000 classes * 10,000 rows」、つまり約130MBの応答を生成できます。
ターゲットラベルの一部削除¶
多ラベルモデリングに使用するラベルを設定するには、ターゲットラベルの一部削除までスクロールします。
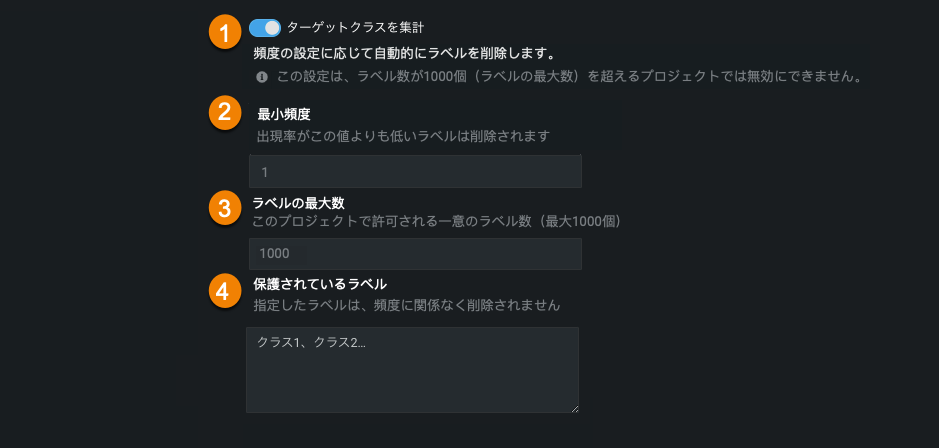
次の表では、各フィールドについて説明します。
| 要素 | 説明 | |
|---|---|---|
| 1 | ターゲットラベルの一部削除 | 一部削除機能を有効にします。 検出されたラベルが1,000個を超えている場合、選択がオンになり、変更はできません。 ラベルが1,000個未満の場合、選択はデフォルトではオフですが、有効にすることもできます。 |
| 2 | 最小頻度 | 削除を回避するために必要な、このラベルを含む行の最小出現数を設定します。 つまり、インスタンスの数が少ないラベルは(保護ラベルとして指定しない限り)削除されます。 |
| 3 | ラベルの最大数 | 一部削除後のラベルの最終的な数を設定します。 2から1,000までの値を入力してください。 |
| 4 | 保護されているラベル | 頻度に関係なく、削除から保護されるラベルのコンマ区切りリストを指定します。 これにより、対象となる頻度の低いラベルについて予測できるようにします。 |
二項間の交互作用¶
この設定では、GA2Mモデルのトレーニング時にどの交互作用を許可するかを制御します。 規制上の制約により、特定の特徴量で交互作用が許可されていない場合に、適用されることがよくあります。
備考
指定したペア単位の交互作用は必ずしもモデルの出力に表示されるとは限りません。 アルゴリズムに従ってモデルに信号を追加する交互作用だけが出力に表示されます。 たとえば、特徴量の交互作用グループA、B、およびCを指定した場合、モデルトレーニング中にAxB、BxC、およびAxCが交互作用とみなされます。 AxBだけが信号をモデルに追加する場合AxBだけがモデルの出力に含まれます(BxCおよびAxCは除外されます)。
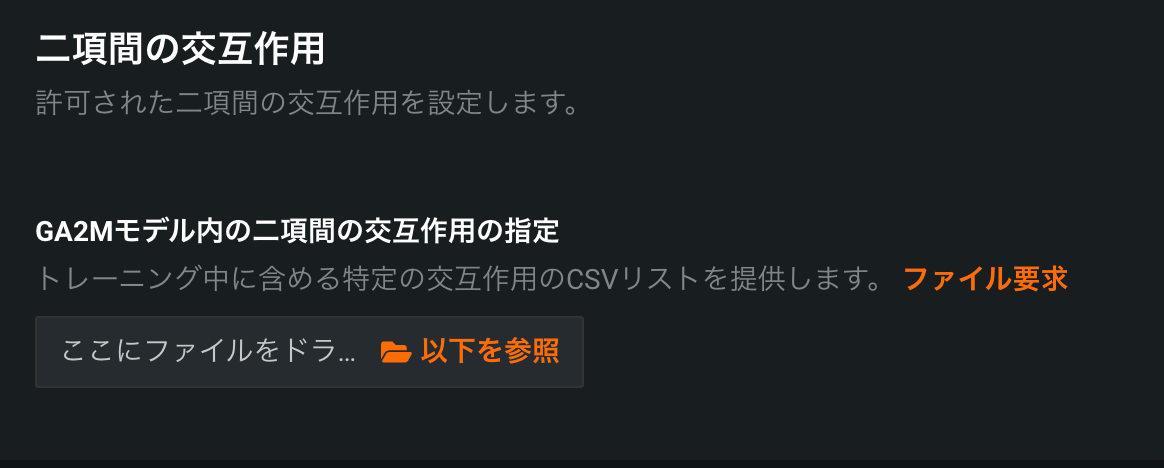
組み込む二項間の交互作用を指定したCSVファイルを提供する必要があります。 CSVに必要な制限と形式の詳細については、ファイルの要件リンクをクリックしてください。 ポップアップウィンドウには、二項間の交互作用で許容される2つのグループを指定する場合のCSVの設定例が示されます。
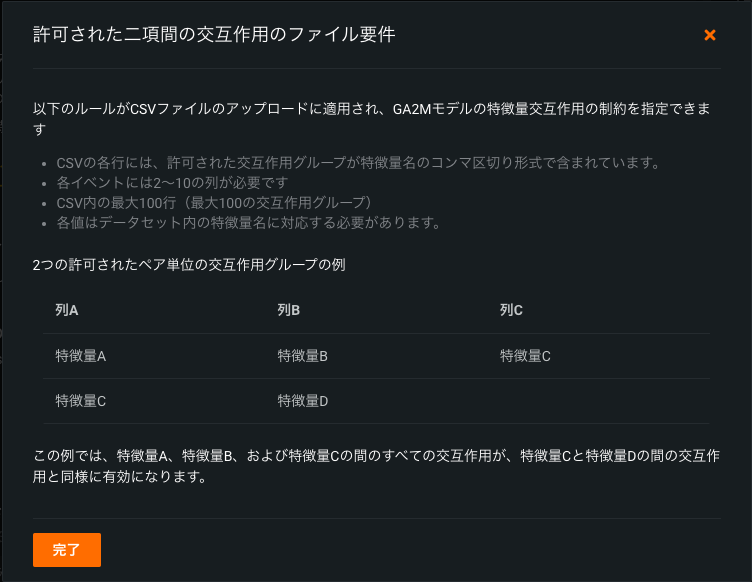
CSVに必要な形式と制限を適用し、参照をクリックしてアップロード(またはドラッグアンドドロップ)します。 DataRobotは、CSVがファイル要件に適合しているかどうかの検証を開始し、形式にエラーがある場合はメッセージで示します。

CSVのアップロードが成功したら、GA2Mモデルのトレーニングを開始できます。 モデルが構築されたら、その出力を格付表タブで確認します。 出力には、指定した二項間の交互作用が示されます。