Enterprise architecture for deploying DataRobot in self-managed environments¶
Overview¶
This page provides guidance for enterprise architects on deploying DataRobot to meet high availability (HA), disaster recovery (DR), and performance/scale requirements within a self-managed environment.
DataRobot is committed to ensure continuous operation, data integrity, and business continuity for all clients.
The guide is structured according to the architectural layers in reverse (bottom-up) order:
- Kubernetes
- Persistent critical services
- DataRobot platform
Design considerations¶
This page assumes the core physical infrastructure has been deployed with multiple data centers that provide hardware and networking for workloads to be deployed across these failure zones.
The guidance provided here is learned from experience deploying and operating the DataRobot platform at scale across a diverse fleet of deployment options:
- Multi-tenant SaaS (MTSaaS) on AWS within three regions.
- Single-tenant SaaS (STSaaS) on AWS, GCP, and Azure in many regions.
- Self-managed VPC installations on AWS, GCP, Azure.
- Self-managed installations on a wide variety of data centers.
When deployed within a cloud VPC environment, DataRobot leverages cloud-managed services for achieving high availability (HA), disaster recovery (DR), and performance/scale.
HA focuses on keeping a system running with minimal interruptions, while DR focuses on recovering the workload after a major, destructive event.
The DataRobot platform was designed according to cloud-native principles and applies them to meet the needs of self-managed customers.
DataRobot adopts design guidelines from the major cloud providers’ Well-Architected Framework reliability pillar in combination with Kubernetes best practices for achieving HA and DR.
By applying these design guidelines and principles for all deployment options across the DataRobot fleet, the platform serves workloads that can recover from disruptions, meet demand, and mitigate failures.
Eliminate single points of failure (SPOFs)¶
- Use multiple Availability Zones (AZs): To mitigate the failure of a data center, workloads are distributed redundantly over multiple AZs within a cloud region. This is achieved in Kubernetes using zone-redundant node pools to deploy nodes across AZs, in conjunction with topology spread constraints that inform the Kubernetes scheduler to distribute pods across these nodes. This aims to keep workloads balanced across zones for fault tolerance to reduce the impact of outages.
- Use load balancing: To automatically distribute incoming traffic and route it away from any unhealthy resources, an Application Load Balancer (ALB) handles ingress traffic. The Ingress Controller in Kubernetes deploys Nginx (or equivalent reverse proxy) redundantly across nodes and automatically manages the ALB’s routing rules to direct traffic to healthy pods. The Ingress Controller routes traffic to the API Gateway as a central front-door to handle access control across the platform. The API Gateway is deployed with a high-availability configuration, and routes traffic to Kubernetes services for the DataRobot platform which themselves are load balanced with multiple pod replicas.
- Employ redundancy: The DataRobot platform uses N+1 load balancing across multiple nodes. This provides higher throughput by distributing load across nodes to more effectively utilize the capacity and reduce latency by using pre-warmed nodes. This provides graceful degradation in the event of failures, and continues to service requests albeit with potentially less capacity. The system remains highly available with no downtime for maintenance since nodes can be taken offline without affecting overall service availability. In general, DataRobot designs services as stateless components that can be horizontally scaled using Horizontal Pod Autoscaler and KEDA for scale-to-zero. For latency-sensitive workloads, DataRobot utilizes a Daemonset across nodes to pre-pull container images for faster container starts when scaling up. For distributed workloads requiring consistency when performing tasks on shared resources, coordination among multiple replicas is achieved using built-in Kubernetes leader-election capabilities. Should the leader instance fail, the system will automatically elect a new leader and transition seamlessly to avoid disruption to service availability. DataRobot utilizes this capability for Kubernetes Operators which extend the Kubernetes control plane with AI-specific primitives and require consistency when deploying workloads to the Data Plane.
Design for automation and self-healing¶
- Automatic scaling: Within cloud environments, the platform uses cloud-managed services (EKS, GKE, AKS) which provision Kubernetes nodes using cloud instances elastically. In order to scale additional cluster capacity based on demand or scale-in nodes that are unutilized, DataRobot utilizes various cluster autoscaling amenities (Cluster Autoscaler, Karpenter, Descheduler). These autoscalers are tuned to provide extra idle capacity to handle rapid spikes in load while minimizing resource waste for efficiency. DataRobot workloads are designed using Kubernetes-native principles to handle pre-emption and pod eviction, allowing the Kubernetes scheduler to make optimal decisions about pod placement and node consolidation automatically. This is achieved using pod disruption budgets (PDBs) to ensure a minimal number of replicas are always available, topology spread constraints which place pods on different nodes and AZs, and pod anti-affinities to inform the scheduler to place pods on different nodes to reduce the likelihood of multiple replicas being disrupted at once. Stateful workloads, such as long-running batch jobs, use special labels to inform the scheduler and auto-scaler not to disrupt them or the nodes they are running on. Some long-running, stateful workloads are designed with point-in-time snapshot capabilities that checkpoint, persist and offload their state to a persistent volume claim rather than in ephemeral instance storage so that they can be recovered and resumed from the last checkpointed state should the node become unhealthy and the workload need to be retried on a healthy node.
- Self-healing infrastructure: DataRobot aims to design the architecture for automatically detecting and recovering from failures without human intervention. This is achieved using resource schedulers (at the node or pod level) which monitor health using probes. Pods are required to implement liveness and readiness probes, where readiness probes determine that a pod is ready to process requests and liveness probes to detect whether a pod is stuck or in an unhealthy state that needs replacement. Kubernetes will only route traffic to healthy pods for a Service, and automatically updates the endpoints mapping for the Ingress Controller to make routing decisions.
Implement disaster recovery strategies based on objectives¶
- Recovery Time Objective (RTO): The maximum acceptable delay between a disaster event and the restoration of services. DataRobot is committed to quickly restoring availability of services within managed SaaS environments. This is achieved using high availability with redundancy across availability zones, in conjunction with Infrastructure as Code (IaC) and continuous delivery for deploying the platform in any infrastructure automatically. The SRE team in DataRobot has documented runbooks for performing failover operations, as needed.
- Recovery Point Objective (RPO): The maximum amount of data loss the business can tolerate. This depends on how frequently data is backed up or replicated. DataRobot commits to achieving minimal data loss within managed SaaS environments. This is achieved using automated data backup and recovery testing performed on a schedule, with alerting for failures and data drift. The SRE team in DataRobot has documented runbooks for performing data recovery operations, as needed.
- Multi-region recovery: The DataRobot platform can be deployed using multi-region strategies such as Pilot Light and Warm Standby. Pilot Light runs a minimal, scaled-down version of the application in a secondary region that would be scaled up during a failover when the primary region is experiencing an outage. Warm Standby would allow a faster failover by running a fully redundant cluster, but with a significantly higher cost for redundant resource consumption and data replication.
Reference architecture for multi-tenant SaaS¶
For reference on how DataRobot achieves HA, DR, and scale within managed SaaS environments, the image below depicts the high-level topology of multi-tenant SaaS deployments.
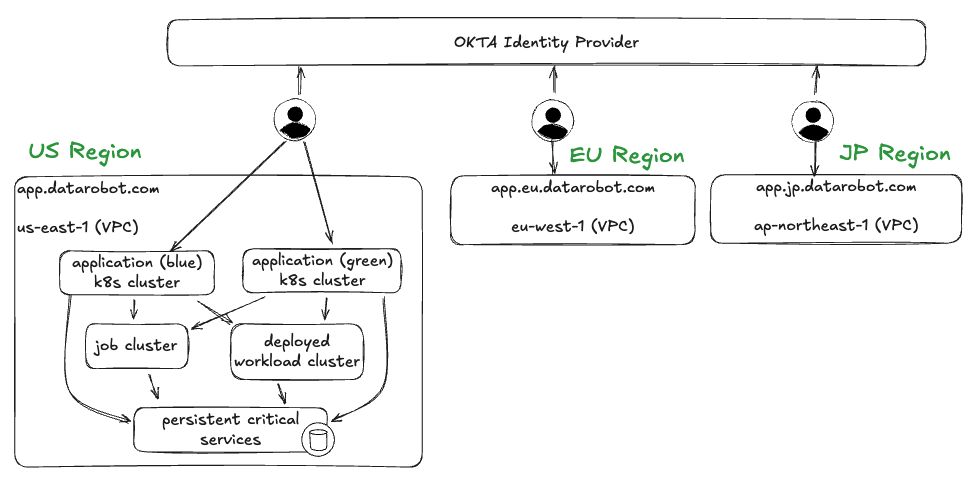
Each region is physically disjointed and self-contained. This allows DataRobot to meet the security and compliance requirements (e.g. GDPR) for certain regions as it relates to data sovereignty, and provide a geo-localized service deployment for lower latency and better performance for customers within that area. In addition, this regional approach allows DataRobot to scale these deployments independently based on demand and capacity needs, and to exploit data locality for compute workloads.
Within each region, the platform is deployed across multiple Kubernetes clusters:
- Application cluster: Runs the DataRobot application plane (UI, API servers) and control plane (middleware services to deploying workloads).
- Jobs cluster: Runs ephemeral worker jobs.
- Deployed Workload cluster: Runs custom workload deployments (agentic workflows, custom models, applications).
- Persistent critical services (PCS): Runs the critical services needed to power the DataRobot platform - object storage, databases, distributed caching, message brokers.
This multi-cluster design enables independent scaling for these subsystems as well as network isolation.
In addition, the application cluster utilizes a blue/green strategy for zero-downtime deployment where user traffic is routed to the “active” instance while test workloads are routed to the “inactive” instance. If tests pass on the inactive instance where newer code is deployed, then an automated switchover event is triggered to route all traffic to this instance as “active”. This deployment strategy could be utilized as the basis of an active-passive, pilot light or warm standby design for failover.
Within each region, workloads are replicated across compute nodes running in different availability zones (AZ) for redundancy across data centers. Each Kubernetes cluster is configured with node groups (or node pools if using Karpenter) that span these AZs so that the Kubernetes scheduler can schedule pod replicas across them.
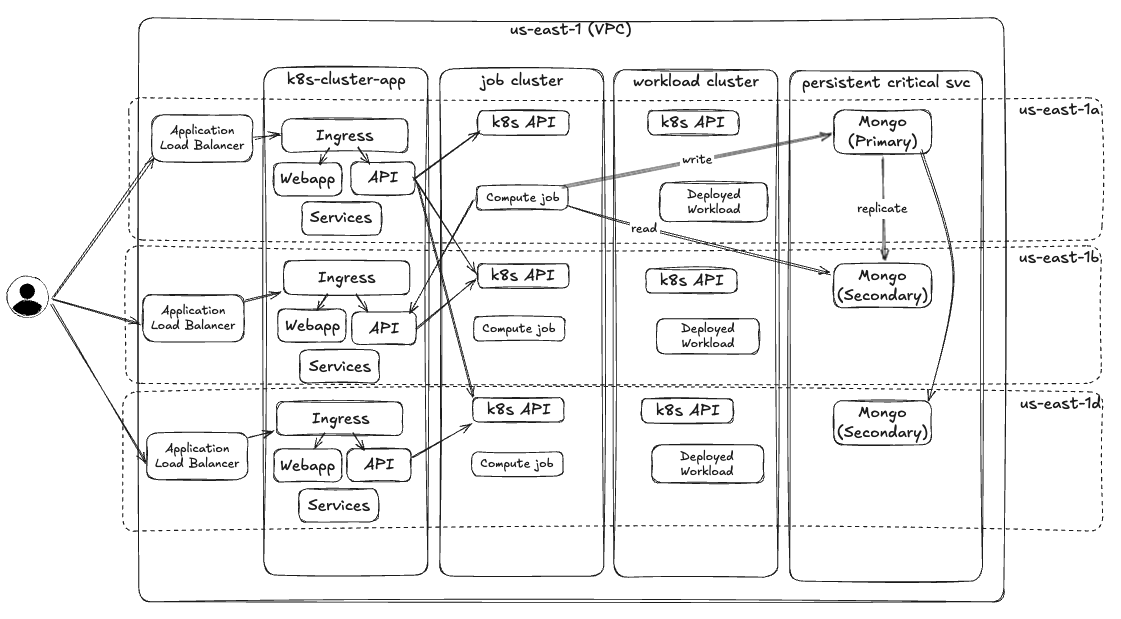
For one of the MTSaaS production regions, the following are scale numbers to use as a reference over the trailing six month period:
- Availability: 99.95%
- Kubernetes node count: Mean: 280, Max: 460
- Kubernetes pod count: Mean: 10k, Max: 16k
- New projects created: 225K+
- New models created: 3M+
- Active deployments: 3M+
- Prediction rows scored: 18B+
Kubernetes¶
Performance/scale¶
According to Considerations for Large Clusters, Kubernetes is designed to handle:
- No more than 5,000 nodes.
- No more than 110 pods per node.
- No more than 150,000 total pods.
- No more than 300,000 total containers.
These limits are determined based on the performance SLOs:
- 99% of API calls return in less than 1 second.
- 99% of Pods start within 5 seconds.
Although possible to scale beyond these limits, the performance SLOs may no longer be achievable without significant optimization.
Scaling the control plane¶
- All control plane components (e.g. k8s API server) are designed to scale horizontally with multiple replicas.
- Run one or two control plane instances per failure zone, scaling those instances vertically first (more CPU and RAM) and then scaling horizontally (more replicas across compute nodes) after reaching the point of diminishing returns with vertical scaling.
-
API server load scales based on the number of nodes and pods.
-
Node kubelets send heartbeats, events, node status and pod status updates to the API server.
- Pods may interact directly with the API server, such as operators and controllers.
-
Watch operations may send a lot of event data to pods
-
Etcd performance must be able to scale to handle the volume of cluster state changes which must be persisted. This requires
etcdto be configured for high availability as well as with fast I/O for write operations.
Cluster networking¶
-
IP address constraints: Since every pod gets its own unique cluster-scoped IP address, the available IP address space is a major constraint on the number of nodes and pods within a cluster.
-
Each node is given a CIDR block range from which to assign pod IPs. An individual node may exhaust its allocated CIDR range and not be able to launch new pods, even though the overall cluster IP space still has available addresses.
- One technique used is IP masquerading with a private IP range to not interfere with the corporate network range and provide a larger assignable IP address space.
High availability¶
HA for the control plane¶
- Run at least one instance per failure zone (availability zone in public cloud or self-managed data center) to provide fault-tolerance.
- Run control plane replicas across 3 or more compute nodes.
- Use an odd number of control plane nodes to help with leader selection for failover.
- Use a TCP-forwarding load balancer in front of the Kubernetes API server to distribute traffic to all healthy control plane nodes.
- Refer to the Kubernetes High Availability documentation.
When running in multiple zones:
- Node labels are applied to identify the zone for zone-aware pod scheduling.
- Topology spread constraints can be used to define how multiple pod replicas should be distributed across the node topology and ensure redundancy across failure zones.
- Pod anti-affinity rules can be used to ensure pod replicas are not scheduled on the same compute node, reducing the likelihood of availability problems due to node failures.
- Persistent volumes can have zone labels so that the scheduler can place pods in the same zone as the persistent volume being claimed. This minimizes network latency and improves I/O performance.
Cluster networking¶
- Configure zone-aware or topology-aware load balancing for routing traffic from kubelet running on the node to the k8s API server in the control plane within the same zone. This is achieved by configuring the control plane endpoint on every node kubelet to direct traffic to the load balancer. Make sure the load balancer fails over to routing traffic to the control plane within another zone in case the API server within the zone is not available. Zone-aware routing reduces cross-zone routing latency and network traffic costs.
- Zone-aware networking is not enabled by default in Kubernetes and requires configuring the network plugin for cluster networking.
Disaster recovery¶
To back up a Kubernetes cluster, you must capture the cluster state by backing up the etcd database, and you should also back up your application-specific data and configurations, such as workloads, persistent volumes, and custom resources. A comprehensive backup strategy includes both these components to enable a full restore of the cluster and its applications in case of failure.
Cluster state¶
etcd: This is the primary storage for all Kubernetes objects (configuration, secrets, API objects). Backing upetcdcaptures the entire state of your cluster.etcdcan be backed up using the built-in snapshot tool or by taking a volume snapshot. See backing up anetcdcluster guide.-
Secrets and ConfigMaps: These are critical for the application configuration. These will be backed up as part of
etcdsnapshot and should be stored securely in an encrypted format. -
Consider storing these resources in an external secret store such as Hashicorp Vault and using the open source external-secrets-operator to sync these secrets and configmaps to the Kubernetes cluster.
-
Declarative configurations: Use Gitops and CI/CD tooling for version control of the Helm charts and resources deployed into the Kubernetes cluster.
Application data¶
- Persistent volumes: These are used for pod-level storage within the cluster for databases, logs and application data. Volume snapshots can be created and stored on an external storage system.
Persistent critical services¶
The database layer, a critical component, encompasses the following technologies each designed with robust HA and DR capabilities:
- MongoDB for application data and metadata.
- PostgreSQL for model monitoring data.
- Redis for distributed caching.
- RabbitMQ for message queue.
- Elasticsearch for full-text indexing of GenAI data and app/agent-level telemetry.
- Container registry for storing container images built as execution environments for custom workloads in DataRobot.
- Object storage for raw object storage.
When deploying persistent critical services on Kubernetes using the Bitnami distribution of Helm charts and container images, the following k8s design principles are used for HA and DR:
- Using StatefulSets for data consistency (attach the correct PersistentVolume to the correct instance).
- Use PodDisruptionBudgets to avoid pod eviction for node consolidation to disrupt the replica set and cause replication storms or trigger primary failover. Use multiple replicas with pod anti-affinity to avoid scheduling on the same node and topology spread constraints to place replicas in different failure zones.
- Liveness/readiness probes to monitor health of replicas so that k8s can reschedule pods as needed and route traffic (via the Service) to healthy endpoints.
MongoDB¶
DataRobot leverages a MongoDB cluster replica set for high availability, consisting of a single primary replica and two secondary replicas. For Onprem, DataRobot recommends Mongo Enterprise Advanced (over the open source product) which comes with Ops Manager for monitoring and managing backup/restore. See the Mongo Atlas Well-Architected Framework’s Reliability section for documentation covering HA and DR.
High availability¶
Data is replicated in near real-time between the replicas. In the event of a replica failure, a leader election protocol is initiated, automatically promoting one of the secondary replicas to primary. All subsequent traffic is then seamlessly redirected to the newly elected primary. This setup provides a near real-time recovery Point Objective (RPO) and recovery Time Objective (RTO) for the loss of a single replica.
Disaster recovery¶
In the rare event of a multi-replica failure, disaster recovery is achieved through established backup and restore procedures utilizing mongodump and mongorestore utilities. Clients can customize backup schedules to align with their specific RPO and RTO requirements. Backups should be persisted within a distributed object storage system. Additionally, when deployed on k8s, it's possible to snapshot the underlying persistent volumes as a backup mechanism.
PostgreSQL¶
High Availability and Fault Tolerance for PostgreSQL are achieved through a multi-node cluster configuration comprising a single primary and multiple secondary nodes. For Onprem deployments, DataRobot bundles postgresql-ha Bitnami distribution for Helm charts and container images. This distribution provides both pgPool for connection pooling and load balancing (for reads only, writes are disabled to ensure data consistency) and repmgr for replication and managing the primary/secondary failover. Repmgr uses a Raft-like consensus algorithm for failover.
High availability¶
DataRobot employs Replication Manager (RepManager), an open-source tool, to manage replication, leader election, and automatic failovers within the PostgreSQL cluster. This ensures continuous operation and data consistency.
Disaster recovery¶
Backup and restore operations are performed using pg_dump and pg_restore. This provides clients with the flexibility to define their backup frequency based on their disaster recovery objectives.
Redis¶
High availability¶
In self-managed deployments, Redis Sentinel is utilized to manage the high-availability configuration. Redis Sentinel maintains a primary instance and two read-only secondary instances. This configuration ensures service continuity in the event of a primary instance failure by automatically promoting a secondary to primary.
Disaster recovery¶
Although it is possible to enable Redis with persistence (RDB snapshotting or append-only file), the application is designed to not require Redis state persistence. Redis is primarily used as a distributed cache (using a cache-aside strategy with MongoDB as the persistence storage backend) and for distributed coordination using Redis Lock.
RabbitMQ¶
RabbitMQ manages the asynchronous messaging between DataRobot services (like job queuing for AutoML). Its high availability focuses on preventing message loss and maintaining queue access.
High availability¶
DataRobot typically utilizes three RabbitMQ instances (replicaCount: 3) within the cluster.
The RabbitMQ cluster provides HA by allowing the application to distribute requests across the instances, preventing single points of failure.
When deployed within a node autoscaling group, the nodes are dynamically adjusted with additional resources to maintain performance and availability, while load balancing distributes incoming requests across the RabbitMQ instances, preventing single points of failure.
Disaster recovery¶
Queues are declared as “durable” or “transient”. For durable queues, messages are stored on disk (within a mounted persistent volume) and are recovered when the RabbitMQ broker restarts. RabbitMQ is deployed on Kubernetes as a StatefulSet with Parallel policy to aid in cluster recovery, ensuring instances are consistently bound to the correct persistent volume for data integrity. Persistent volumes can be backed up to prevent message loss in RabbitMQ.
Elasticsearch¶
High availability¶
Deploy Elasticsearch with three or more cluster nodes with multiple master-eligible nodes and data nodes distributed across failure zones. Elasticsearch is designed to scale horizontally by adding more data nodes and configuring the indices with an appropriate number of shards to distribute the query/indexing load. Indices are configured with multiple replicas (primary shard and replica shards) distributed across the available nodes and failure zones.
Disaster recovery¶
Asynchronous replication of replica shards ensures near zero RPO within the cluster, although this is influenced by replication lag if deployed across multiple data centers. Automated snapshots can be configured using snapshot lifecycle management (SLM) to snapshot indices and store them within a remote s3-compatible object store that is accessible across zones.
Container registry¶
The DataRobot platform requires a container registry for pulling and pushing container images. This is a “bring your own” (BYO) component and is not bundled with DataRobot. The container registry is needed to pull the images for the various DataRobot services, as well as building custom execution environments within the platform so that users can build and deploy their own custom workloads.
Many customers utilize Harbor, Red Hat Quay, Gitlab container registry, or JFrog container registry within self-managed environments. DataRobot recommends following the vendor or open source project’s official documentation for achieving HA and DR.
Object storage¶
The DataRobot platform requires object storage to provide persistent volumes to the Kubernetes cluster, as well as for s3-compatible object storage used by the DataRobot platform. This is a “bring your own” (BYO) component and is not bundled with DataRobot. Object storage is used for storing raw customer data (e.g. uploaded training data) as well as derived assets (e.g. trained models, generated insights data, prediction results, etc.).
Many customers utilize Minio or Ceph within self-managed environments. DataRobot recommends following the vendor or open source project’s official documentation for achieving HA and DR.