Managed SaaS releases¶
June SaaS feature announcements¶
June 2026
This page provides announcements of newly released features available in DataRobot's SaaS multi-tenant AI Platform, with links to additional resources. From the release center, you can also access past announcements and Self-Managed AI Platform release notes.
Agentic AI¶
Admins can use structured, policy-driven access control for LLMs¶
Organization administrators now have a dedicated page, LLM Gateway Management, to configure access to LLM models. GenAI supports several different LLMs that can be used during the creation of an LLM blueprint, and previously, access to these LLMs was controlled by feature flags—each LLM type associated with a separate feature flag. LLM Gateway Management, located in Admin settings, gives admins the ability to allow or deny access to specific providers, creators, and models at the organization, group, or individual user level.
Agent Assist skill¶
The Agent Assist skill (datarobot-agent-assist) packages the same design, code, and deploy workflows as dr assist for use in Claude Code, Cursor, OpenCode, VS Code Copilot, and other supported coding agents. Install it from the DataRobot Agentic Skills repository (npx ai-agent-skills install datarobot-oss/datarobot-agent-skills) or from agent marketplaces; run datarobot-setup once per workspace, then Run datarobot-agent-assist to start. For full instructions, see the Agent Assist skill documentation.
Agentic framework re-architecture¶
The latest and future versions of the agentic starter template have been re-engineered to transition to a unified and asynchronous interface for GenAI agents within DataRobot. New agents transition away from using DataRobot User Models (DRUM)—a predictive custom model frontserver not designed for agentic workflows—and shifts to a hybrid model integrating the open-source NeMo Agentic Toolkit (NAT) with a custom frontend server called DRAgent. Due to the new asynchronous functionality, agentic workflows using DRAgent experience dramatically increased overall agent efficiency as well as decreased response times.
All new agentic starter template instances use DRAgent by default; existing agents continue to run as before using DRUM, but can be swapped to the new experience by adding a new environment variable to the agent's .env file:
ENABLE_DRAGENT_SERVER=true
New and retired LLMs¶
Following is the list of LLM availability changes since the last monthly release notes. See the availability page for a full list of supported LLMs. As always, you can add an external integration to support specific organizational needs.
The following are newly available:
- Claude Opus 4.8: Amazon Bedrock, Anthropic, Google Gemini Enterprise Agent Platform (formerly Vertex AI).
- Google Gemini 3.5 Flash: Google Gemini Enterprise Agent Platform (formerly Vertex AI).
To enable access to these new models, org admins can set access control policies using the new LLM Gateway Management page.
For information on deprecation and retirement dates, see the LLM availability information.
Data¶
Store, share, and search for files in the File Registry¶
The Files tile in Registry is a centralized place to store, share, and search files of any type, including structured and unstructured data, documents, and binaries. It's commonly used to hold the data behind unstructured knowledge workflows, but you can use it for any files you need to manage and reuse. When unstructured data is added as part of a workflow within DataRobot, after registration is complete, you can access the file again from Registry > Files (even if the associated Use Case is deleted).
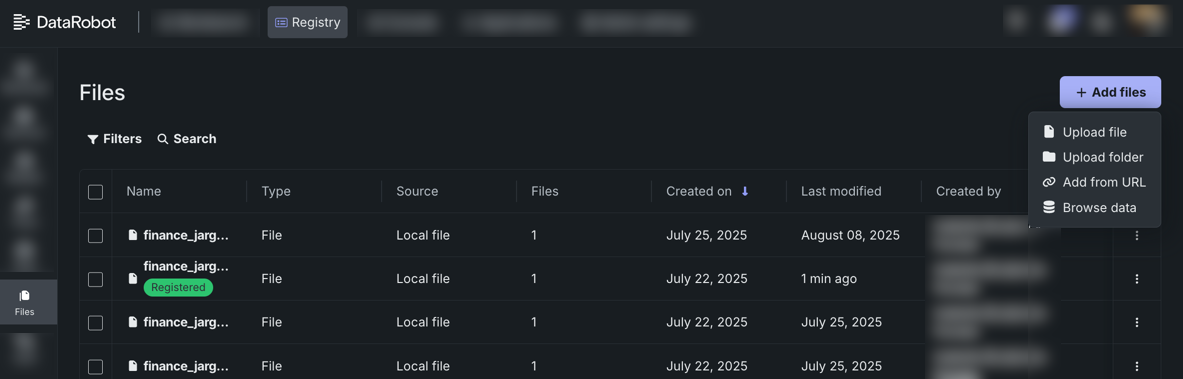
For more information, see the File Registry documentation.
Connect to ADLS Gen2 using a connection string or SAS¶
Azure connection strings and shared access signatures (SAS) have been added as supported authentication methods when connecting to ADLS Gen2 in DataRobot. For more information on configuring these connections, see the ADLS Gen2 page.
Faster previews for data connectors¶
DataRobot is migrating data connection preview capabilities to the Unified Connector Framework (UCF). This change significantly improves preview performance for tables and queries. With this migration, preview request latency is reduced from approximately 5–8 seconds to 1–1.5 seconds, enabling a faster and more responsive user experience when exploring connected data.
Predictive AI¶
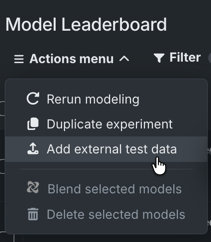
Use external data to assess model performance¶
External test datasets let you evaluate trained models against datasets that were not used during training (i.e., external holdout). Attach a dataset to an experiment and score individual models on demand. Results appear on the full Leaderboard and alongside your training-derived scores throughout the UI. Available from a variety of model insights, you can use the data selection dropdown to choose an external set for comparison.
MLOps and predictions¶
Multilabel support for custom models¶
Structured custom inference models now support multilabel classification. In Workshop, select Multilabel as the target type and provide target labels in the same order as the model's predicted label probabilities. Code-first workflows can define multilabel models with targetType: multilabel in model-metadata.yaml or dr.TARGET_TYPE.MULTILABEL in the Python client.
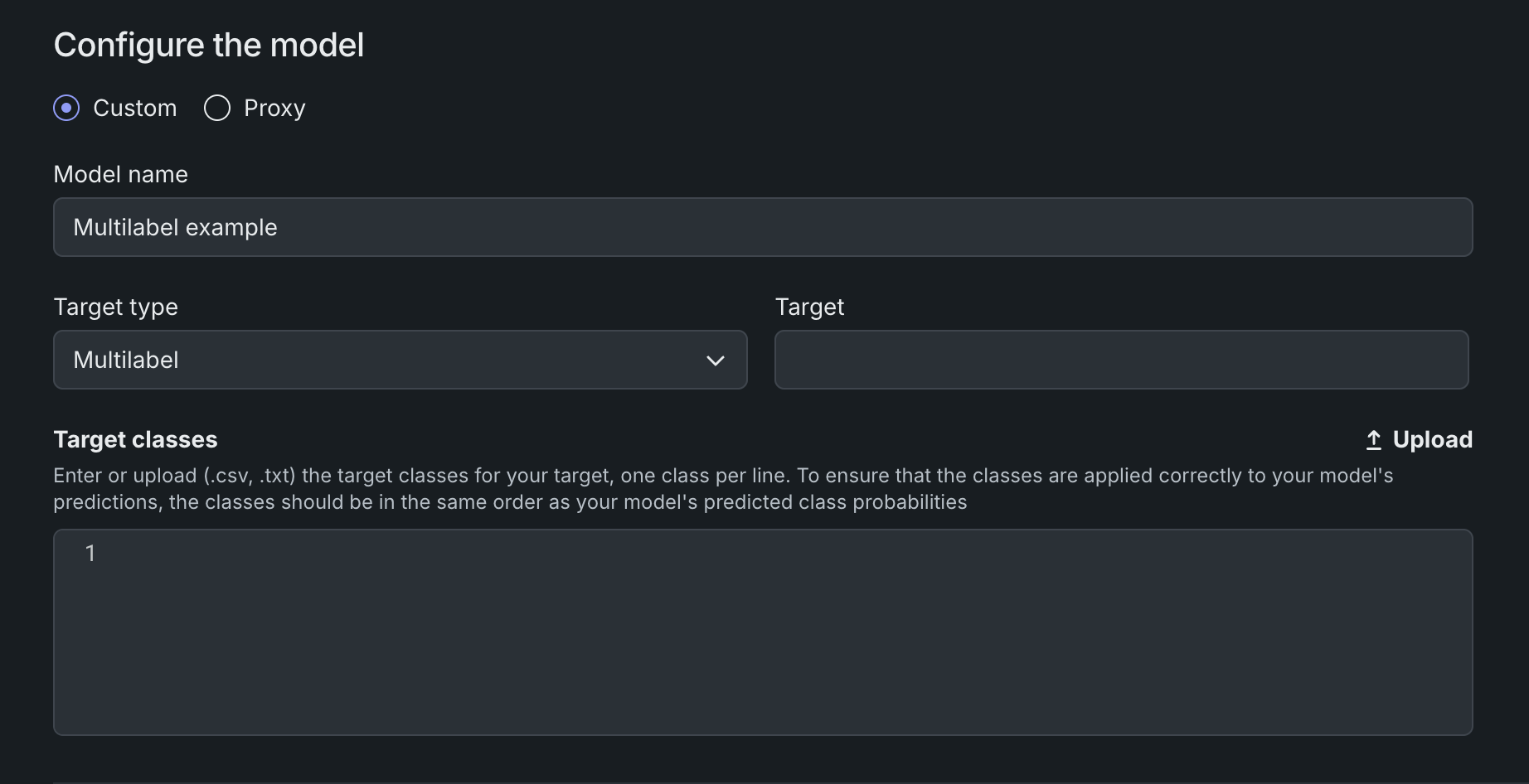
Multilabel custom models support inference only, with service health and feature drift monitoring. For more information, see Create a custom model, Define custom model metadata, and Structured custom models.
Secure configuration credential field names corrected when using runtime parameters¶
Credentials can be created manually or from a shared secure configuration. For Azure Service Principal, Snowflake key-pair, and Azure OAuth / ADLS OAuth types, secure-config-backed credentials previously used different field names than manually created credentials. Deploying a custom model, application, or agent with a secure-config-backed credential of one of these types could fail silently—the workload stayed inactive and timed out without a user-facing error. Manually configured credentials were not affected.
This release applies a single canonical field-name mapping across all credential creation paths, so secure-config-backed credentials now resolve and deploy correctly for custom models, applications, and agents when mounted as runtime parameters.
Breaking change—custom jobs only
Custom jobs receive credentials as unpacked environment variables and use a different injection path than other workloads. Unlike custom models, applications, and agents, custom jobs were not blocked when secure-config field names did not match the canonical schema. Some custom jobs may already depend on the legacy field names below when reading credential-type runtime parameters created from a shared secure configuration.
Update custom job code that reads any of the following fields:
| Credential type | Old field (before) | New field (after) |
|---|---|---|
| Azure Service Principal | tenant_id |
azure_tenant_id |
| Snowflake key-pair | user_name |
username |
| Azure OAuth / ADLS OAuth | scopes (space-delimited string) |
oauth_scopes (string representation of a JSON list) |
Fields such as client_id and client_secret are unchanged. Custom jobs that use manually configured credentials are also unchanged.
Credential-type runtime parameters are unpacked into separate environment variables named {PARAMETER_NAME}_{FIELD_NAME} in uppercase snake case. Reference this example for Azure Service Principal, where the runtime parameter is named MY_AZURE_CRED:
Example for Azure Service Principal, where the runtime parameter is named MY_AZURE_CRED:
import os
import json
# simulate injection of credential to custom job
# before upgrade
os.environ["AZURE_SP_CRED"] = '{"credential_type": "azure_service_principal", "client_id": "C123", "client_secret": "S456", "tenant_id": "T789"}'
tenant_id = json.loads(os.environ["AZURE_SP_CRED"]).get("tenant_id")
print(tenant_id) # 'T789'
# after upgrade
os.environ["AZURE_SP_CRED"] = '{"credential_type": "azure_service_principal", "client_id": "C123", "client_secret": "S456", "azure_tenant_id": "T789"}'
tenant_id = json.loads(os.environ["AZURE_SP_CRED"]).get("tenant_id") # KeyError if not using get()
print(tenant_id) # None
tenant_id = json.loads(os.environ["AZURE_SP_CRED"]).get("azure_tenant_id"). # using corrected field name
print(tenant_id) # 'T789'
For how credential-type runtime parameters are injected, see Runtime parameters for custom jobs.
Applications¶
UI component registry added to applications for improved performance¶
Applications now utilize an AI-native UI components registry built on shadcn, streamlining component reuse and distribution. Once components are built, they are saved in a centralized registry for reuse across multiple applications. The component registry provides a more consistent user interface, accelerates delivery, and offers a publicly accessible open-source library for adoption and transparency.
Additionally, for the Talk to My Docs and Agentic Starter application templates, the Settings page now includes the ability to select display theme and language.
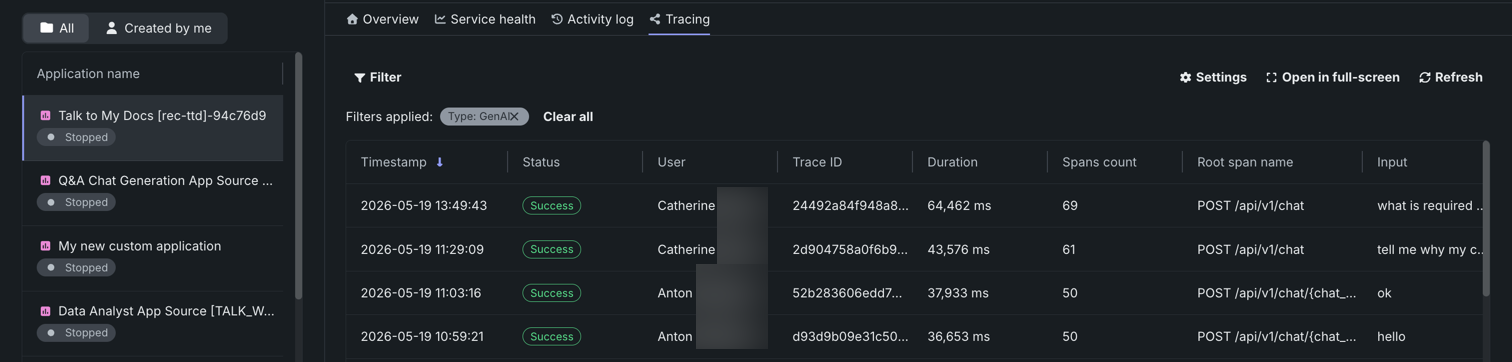
View OTEL compliant tracing for applications¶
Applications now include a Tracing tab, which displays OTEL compliant tracing. Traces represent the path taken by a request to a model or agentic workflow. Each trace follows the entire end-to-end path of a request, from origin to resolution and contains one or more spans, starting with the root span. The root span represents the entire path of the request and contains a child span for each individual step in the process.
Platform¶
Share Use Cases with user groups¶
In Workbench, you can now share Use Cases directly with user groups, in addition to individual users and your organization. You can assign roles directly to groups. The role applies to every member of the group, and members gain access to all assets in the Use Case, including datasets.
Admin settings moved to top navigation¶
Platform administrators can now open Admin settings from the top navigation bar in the NextGen UI, replacing the previous APP ADMIN menu under the profile icon. For updated navigation steps, see the administrator overview.
Code-first¶
Python client v3.17¶
Python client v3.17 is now generally available. For a complete list of changes introduced in v3.17, see the Python client changelog.
DataRobot REST API v2.46¶
DataRobot's v2.46 for the REST API is now generally available. For a complete list of changes introduced in v2.46, see the REST API changelog.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.