November 2023¶
November, 2023
With the latest deployment, DataRobot's AI Platform delivered the new GA and preview features listed below. From the release center, you can also access:
In the spotlight¶
DataRobot introduces extensible, fully-customizable, cloud-agnostic GenAI capabilities¶
With DataRobot GenAI capabilities, you can generate text content using a variety of pre-trained large language models (LLMs). Additionally, you can tailor the content to your data by building vector databases and leveraging them in the LLM blueprints. The DataRobot GenAI offering builds off of DataRobot's predictive AI experience to provide confidence scores and enable you to bring your favorite libraries, choose your LLMs, and integrate third-party tools. Via a hosted notebook or DataRobot’s UI, embed or deploy AI wherever it will drive value for your business and leverage built-in governance for each asset in the pipeline. Through the DataRobot UI you can:
- Create playgrounds
- Build vector databases
- Build and compare LLM blueprints
- Deploy LLM blueprints to production
With code you can bring your own external LLMs or vector databases.
New navigation reflects expansion of DataRobot NextGen¶
The introduction of Registry and Console to the new DataRobot user interface, NextGen, changes the top-level navigation. Now, instead of choosing between “DataRobot Classic” and “Workbench,” the interface switcher takes you to either the classic version or DataRobot NextGen. NextGen comprises the full pipeline of tools, which include building (Workbench), governing (Registry), and operations (Console). All options are available from the breadcrumbs dropdown.
November release¶
The following table lists each new feature:
Features grouped by capability
* Premium feature
GA¶
Disable Elasticsearch in the AI Catalog¶
If you are experiencing performance issues or unexpected behavior when searching for assets in the AI Catalog, try disabling Elasticsearch.
Feature flag OFF by default: Disable ElasticSearch For AI Catalog Search
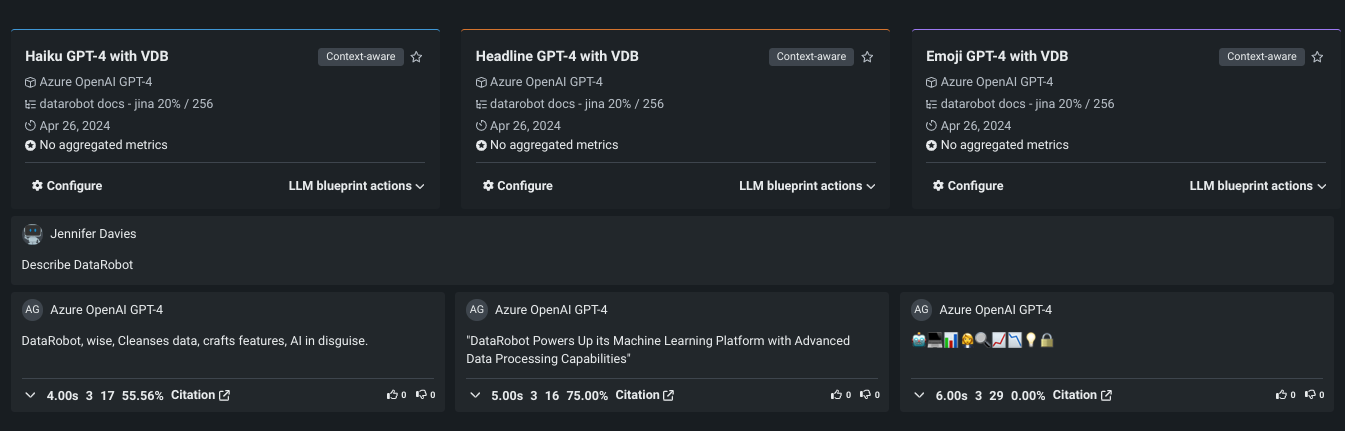
Change default user experience¶
You can now set your default user interface experience, toggling between DataRobot Classic and NextGen. From the user settings dropdown, select Profile. Enable the toggle to use the new, NextGen UI; disable the toggle to use the Classic DataRobot experience.
Workbench adds two partitioning methods for predictive projects¶
Now GA, Workbench now supports user-defined grouping (“column-based” or “partition feature” in Classic) and automated grouping (“group partitioning” in classic). While less common, user-defined and automated group partitioning provide a method for partitioning by partition feature—a feature from the dataset that is the basis of grouping. To use grouping, select which method based on the cardinality of the partition feature. Once selected, choose a validation type; see the documentation for assistance in selecting the appropriate validation type and more details about using grouping for partitioning.

Sliced insights for time-aware experiments now GA in DataRobot Classic¶
With this deployment, sliced insights for OTV and time series projects are now generally available for Lift Chart, ROC Curve, Feature Effects, and Feature Impact in DataRobot Classic. Sliced insights provide the option to view a subpopulation of a model's derived data based on feature values. Use the segment-based accuracy information gleaned from sliced insights, or compare the segments to the "global" slice (all data), to improve training data, create individual models per segment, or augment predictions post-deployment.
Date/time partitioning for time-aware experiments now GA¶
The ability to create time-aware experiments—either predictive or forecasting with time series—is now generally available. With a simplified workflow that shares much of the setup for row-by-row predictions and forecasting, clearer backtest modification tools, and the ability to reset changes before building, you can now quickly and easily work with time-relevant data.
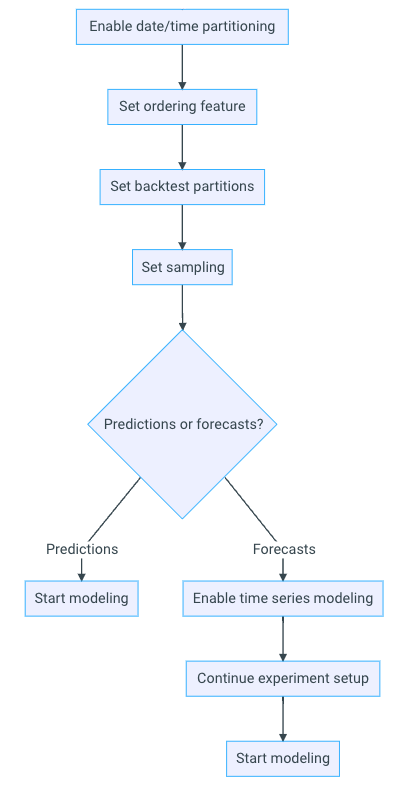
Versioning support in the new Model Registry¶
Now generally available for app.eu.datarobot.com and app.datarobot.com users, the new Model Registry is an organizational hub for the variety of models used in DataRobot. Models are registered as deployment-ready model packages. These model packages are grouped into registered models containing registered model versions, allowing you to categorize them based on the business problem they solve. Registered models can contain DataRobot, custom, external, challenger, and automatically retrained models as versions.
During this update, packages from the Model Registry > Model Packages tab are converted to registered models and migrated to the new Registered Models tab. Each migrated registered model contains a registered model version, and the original packages can be identified in the new tab by the model package ID (registered model version ID) appended to the registered model name.
Once the migration is complete, in the updated Model Registry, you can track the evolution of your predictive and generative models with new versioning functionality and centralized management. In addition, you can access both the original model and any associated deployments and share your registered models (and the versions they contain) with other users.
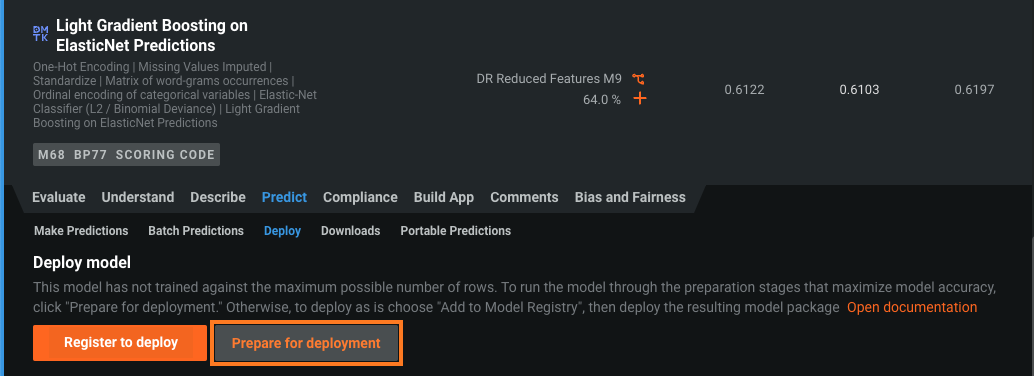
This update builds on the previous model package workflow changes, requiring the registration of any model you intend to deploy. To register and deploy a model from the Leaderboard, you must first provide model registration details:
-
On the Leaderboard, select the model to use for generating predictions. DataRobot recommends a model with the Recommended for Deployment and Prepared for Deployment badges. The model preparation process runs feature impact, retrains the model on a reduced feature list, and trains on a higher sample size, followed by the entire sample (latest data for date/time partitioned projects).

-
Click Predict > Deploy. If the Leaderboard model doesn't have the Prepare for Deployment badge, DataRobot recommends you click Prepare for Deployment to run the model preparation process for that model.
Tip
If you've already added the model to the Model Registry, the registered model version appears in the Model Versions list. You can click Deploy next to the model and skip the rest of this process.
-
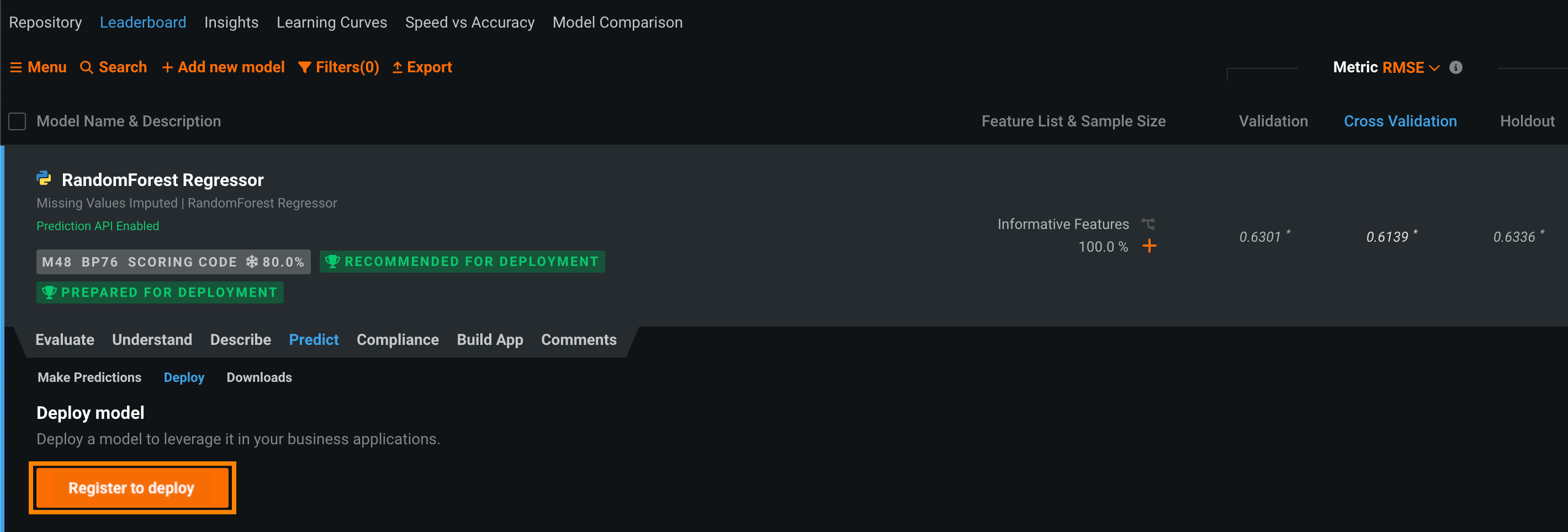
Under Deploy model, click Register to deploy.
-
In the Register new model dialog box, provide the required model package model information:

-
Click Add to registry. The model opens on the Model Registry > Registered Models tab.
-
While the registered model builds, click Deploy and then configure the deployment settings.
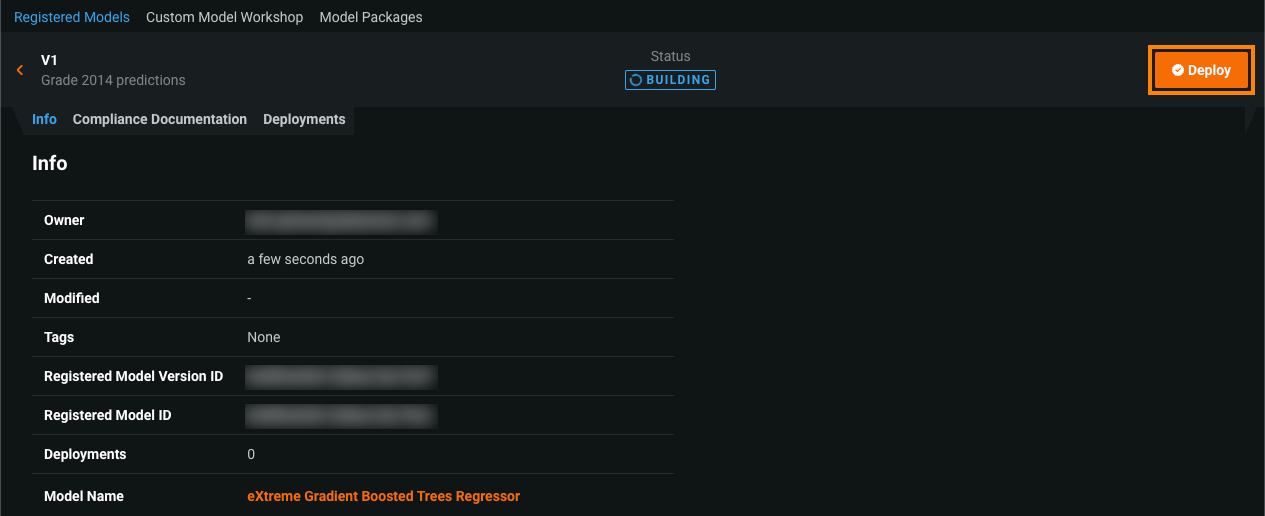
For more information, see the documentation.
Automated deployment and replacement of Scoring Code in AzureML¶
Now available as a premium feature, you can create a DataRobot-managed AzureML prediction environment to deploy DataRobot Scoring Code in AzureML. With the Managed by DataRobot option enabled, the model deployed externally to AzureML has access to MLOps management, including automatic Scoring Code replacement. Once you've created an AzureML prediction environment, you can deploy a Scoring Code-enabled model to that environment from the Model Registry:
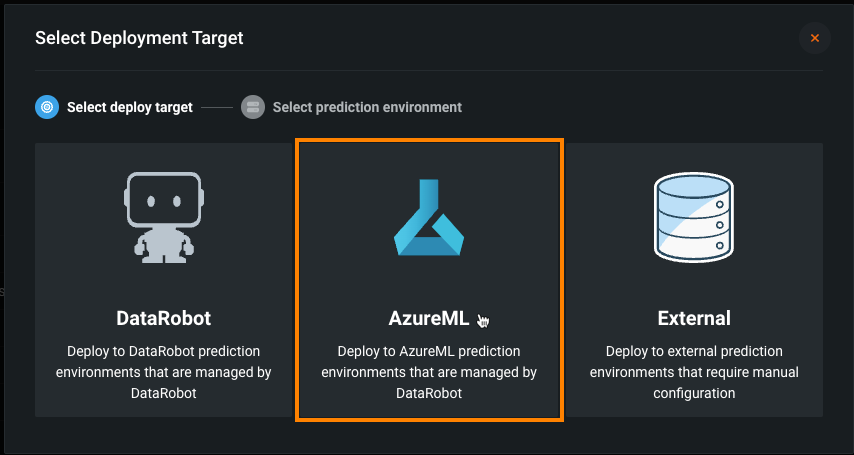
For more information, see the documentation.
Preview¶
Share Use Cases with your organization¶
Now available for preview, you can share a Use Case with your entire organization as well as specific users. In a Use Case, click Manage members and select Organizations.
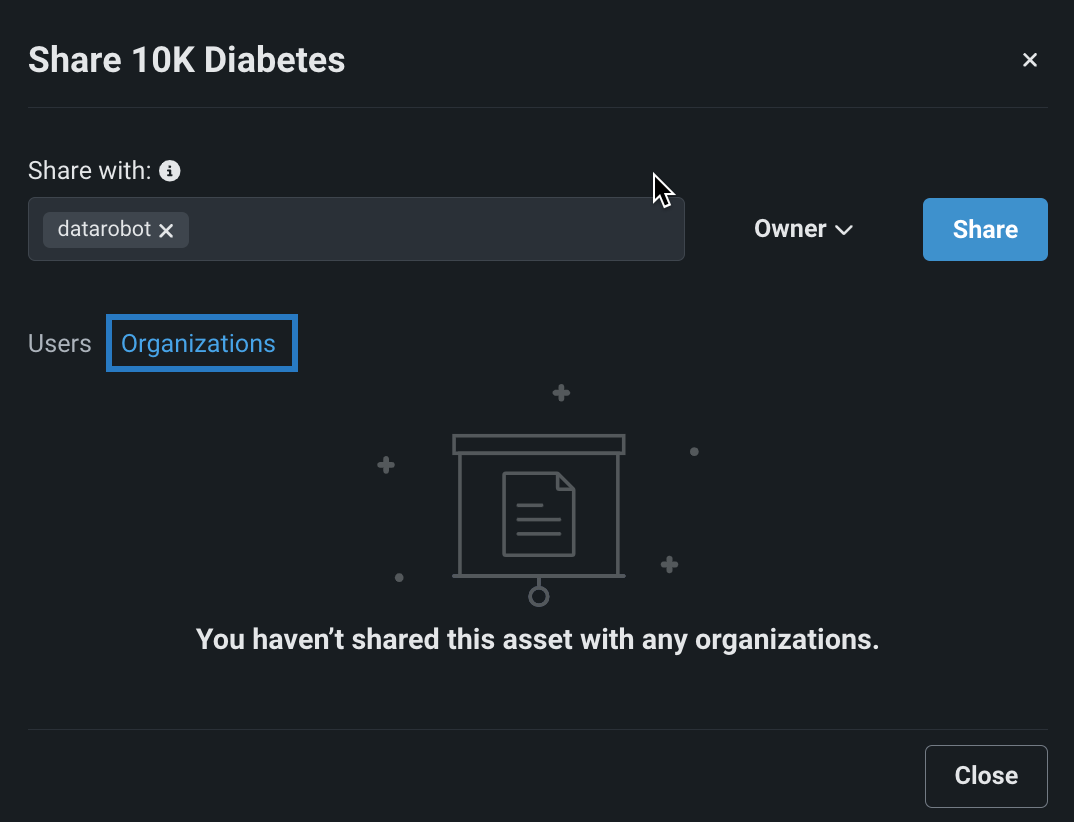
Feature flag ON by default: Disable Organization-wide Use Case Sharing
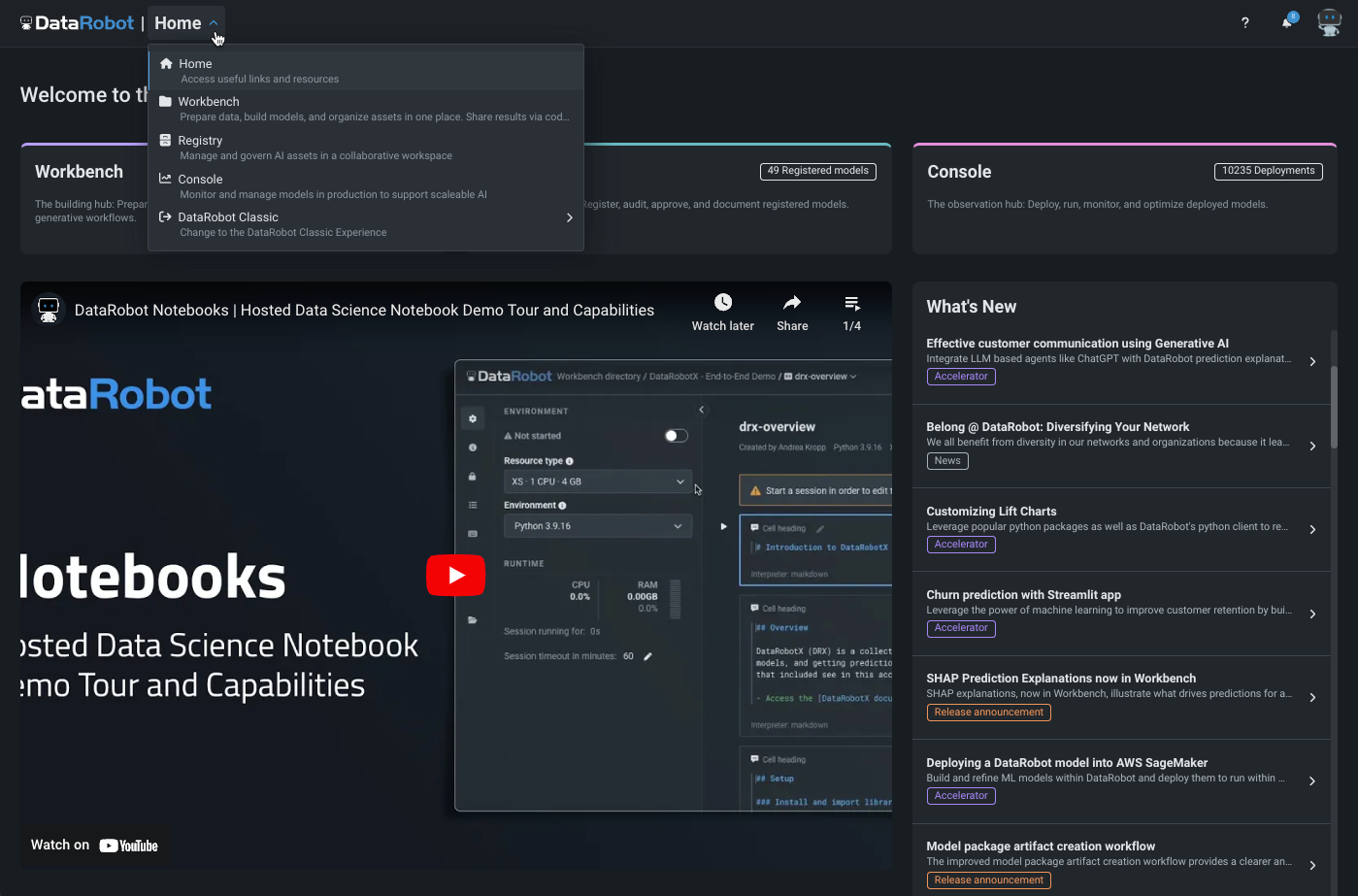
New home page highlights new features, accelerators, news¶
The new DataRobot home page provides access to all the information you need to be successful with DataRobot. The right-hand pane lists quick summaries of newly launched features and accelerators, as well as news items. Click each for more information. This month’s featured YouTube highlight as well as access to a getting started playlist fill the center. Tabs at the top of the page report activity for—and launch—Workbench, Registry, and Console. Tabs at the bottom provide quick links to DataRobot sites outside the application (Documentation, Support, Community, and DataRobot University).
S3 support added to Workbench¶
Support for AWS S3 has been added to Workbench, allowing you to:
- Create and configure data connections.
- Add S3 datasets to a Use Case.
Feature flag ON by default: Enable Native S3 Driver
Preview documentation.
Distributed mode for improved performance in Feature Discovery projects¶
Distributed mode is now available for preview in Feature Discovery projects. Enabling this feature improves scalability, especially when working with large secondary datasets. When you click Start, DataRobot begins generating new features based on the primary and secondary datasets and automatically detects if the datasets are large enough to run distributed processing—improving performance and speed. Additionally, this allows you to work with secondary datasets up to 100GB.
Feature flag OFF by default: Enable Feature Discovery in Distributed Mode
Preview documentation.
Automatically generate relationships for Feature Discovery¶
Now available for preview, DataRobot can automatically detect and generate relationships between datasets in Feature Discovery projects, allowing you to quickly explore potential relationships when you’re unsure of how they connect. To automatically generate relationships, make sure all secondary datasets are added to your project, and then click Generate Relationships at the top of the Define Relationships page.
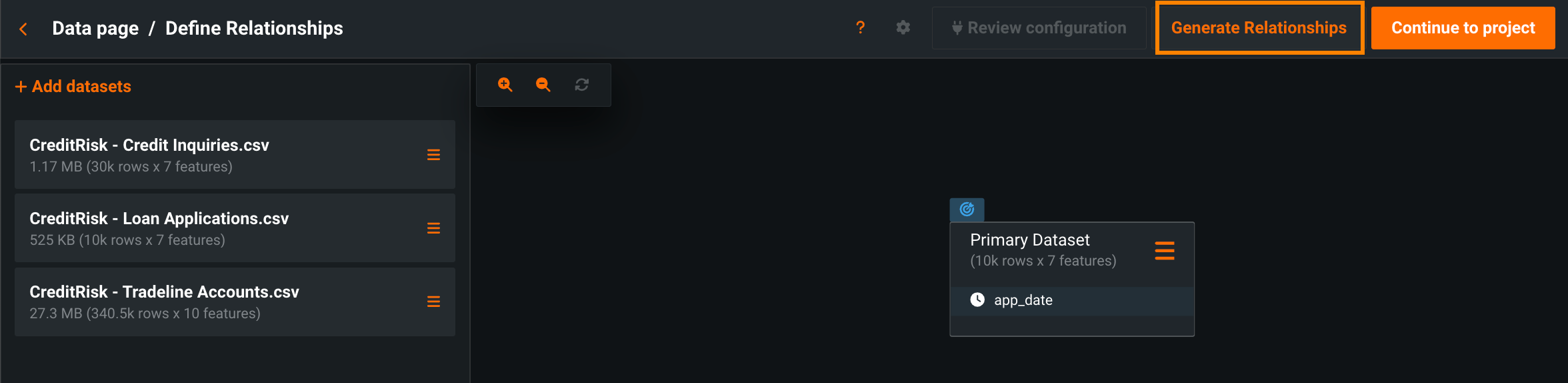
Feature flag OFF by default: Enable Feature Discovery Relationship Detection
Preview documentation.
New configuration options added to Workbench¶
This deployment adds several preview settings during experiment setup, covering many common cases for users. New settings include the ability to:
-
Change the modeling mode. Previously Workbench ran quick Autopilot only, now you can set the mode to manual mode (for building via the blueprint repository) or Comprehensive mode (not available for time-aware).
-
Change the optimization metric—the metric that defines how DataRobot scores your models—from the metric selected by DataRobot to any supported metric appropriate for your experiment.
-
Configure additional settings, such as offset/weight/exposure, monotonic feature constraints, and positive class selection.
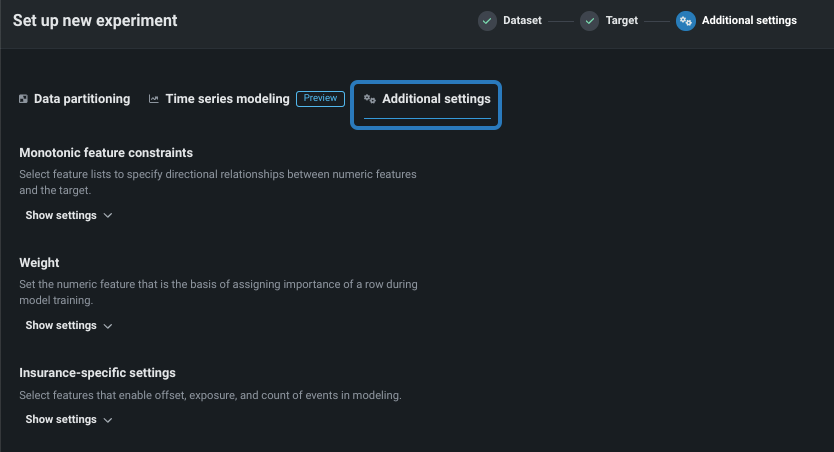
Feature flag ON by default: UXR Advanced Modeling Options
Preview documentation
Compute Prediction Explanations for data in OTV and time series projects¶
Now available for preview, you can compute Prediction Explanations for time series and OTV projects. Specifically, you can get XEMP Prediction Explanations for the holdout partition and sections of the training data. DataRobot only computes Prediction Explanations for the validation partition of backtest one in the training data.
Feature flag OFF by default: Enable Prediction Explanations on training data for time-aware Projects
Preview documentation.
NextGen Registry¶
Now available in the NextGen Experience, Registry is an organizational hub for the variety of models used in DataRobot. The Registry > Models tab lists registered models, each containing deployment-ready model packages as versions. These registered models can contain DataRobot, custom, and external models as versions, allowing you to track the evolution of your predictive and generative models and providing centralized management:
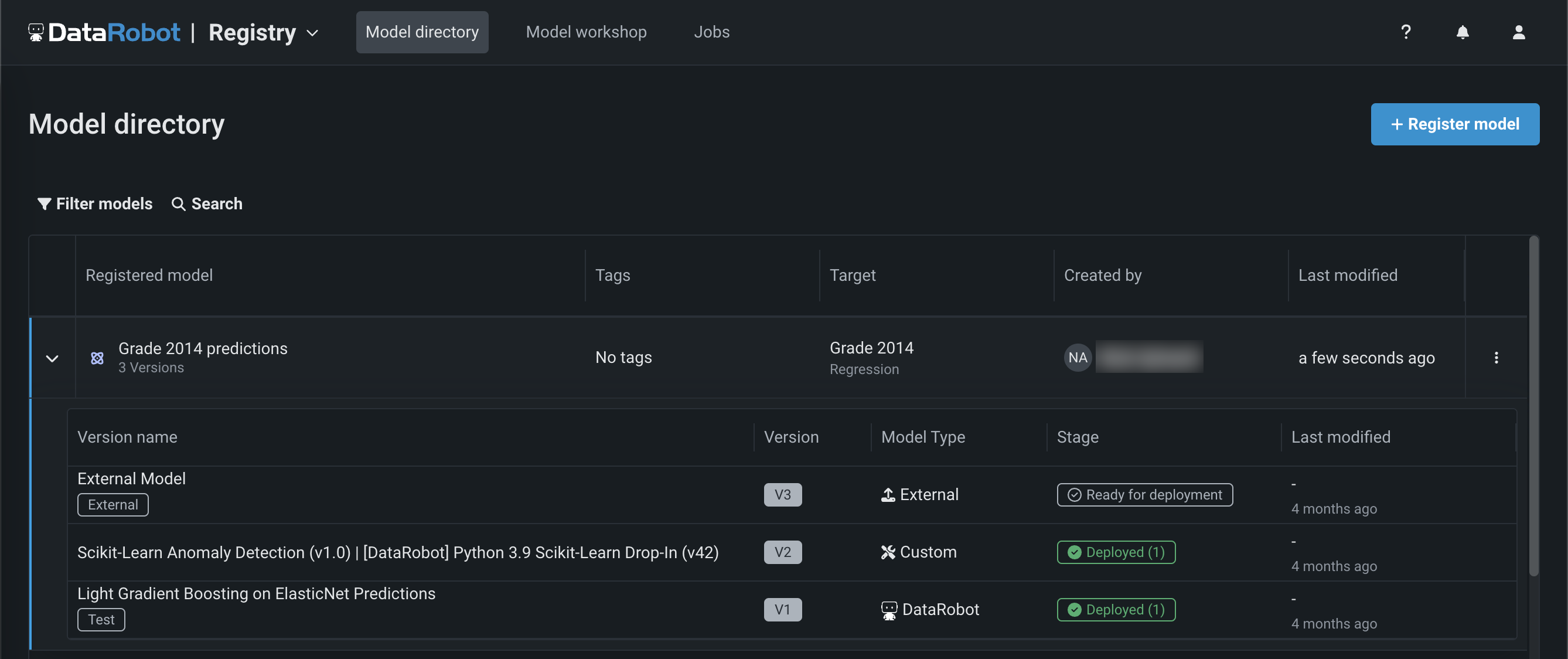
From Registry, you can generate compliance documentation to provide evidence that the components of the model work as intended, manage key values for registered model versions, and deploy the model to production.
For more information, see the documentation.
Feature flag ON by default: Enable NextGen Registry
NextGen model workshop¶
Now available in the NextGen Experience, the model workshop allows you to upload model artifacts to create, test, register, and deploy custom models to a centralized model management and deployment hub. Custom models are pre-trained, user-defined models that support most of DataRobot's MLOps features. DataRobot supports custom models built in a variety of languages, including Python, R, and Java. If you've created a model outside of DataRobot and want to upload your model to DataRobot, define the model content and the model environment in the model workshop:
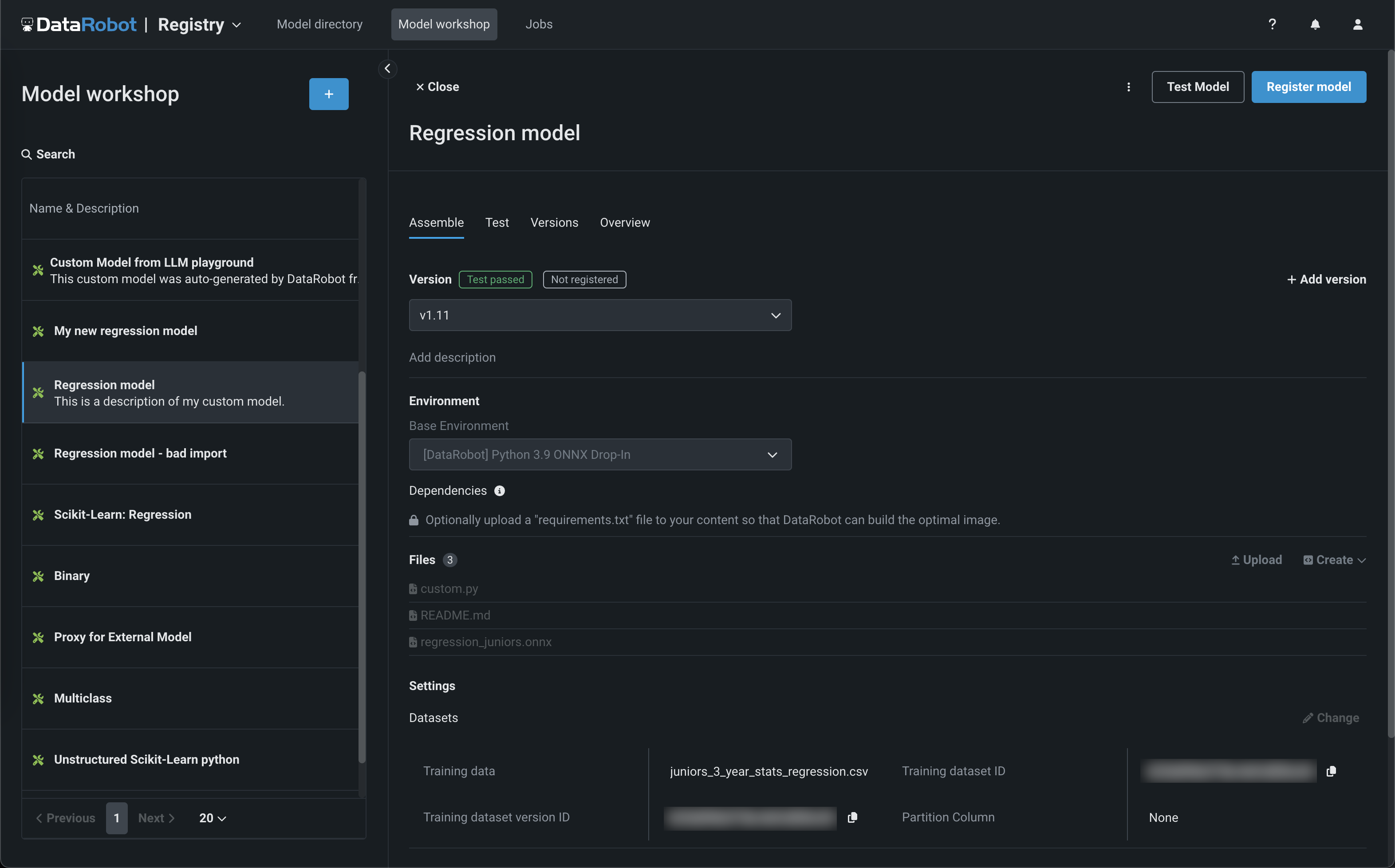
What are custom models?
Custom models are not custom DataRobot models. They are user-defined models created outside of DataRobot and assembled in the model workshop for access to deployment, monitoring, and governance. To support the local development of the models you want to bring into DataRobot through the model workshop, the DataRobot Model Runner provides you with tools to locally assemble, debug, test, and run the model before assembly in DataRobot. Before adding a custom model to the workshop, DataRobot recommends you reference the custom model assembly guidelines for building a custom model to upload to the workshop.
For more information, see the documentation.
Feature flag ON by default: Enable NextGen Registry
NextGen jobs¶
Now available in the NextGen Experience, you can use jobs to implement automation (for example, custom tests) for models and deployments. Each job serves as an automated workload, and the exit code determines if it passed or failed. You can run the custom jobs you create for one or more models or deployments. The automated workloads defined through custom jobs can make prediction requests, fetch inputs, and store outputs using DataRobot's Public API:
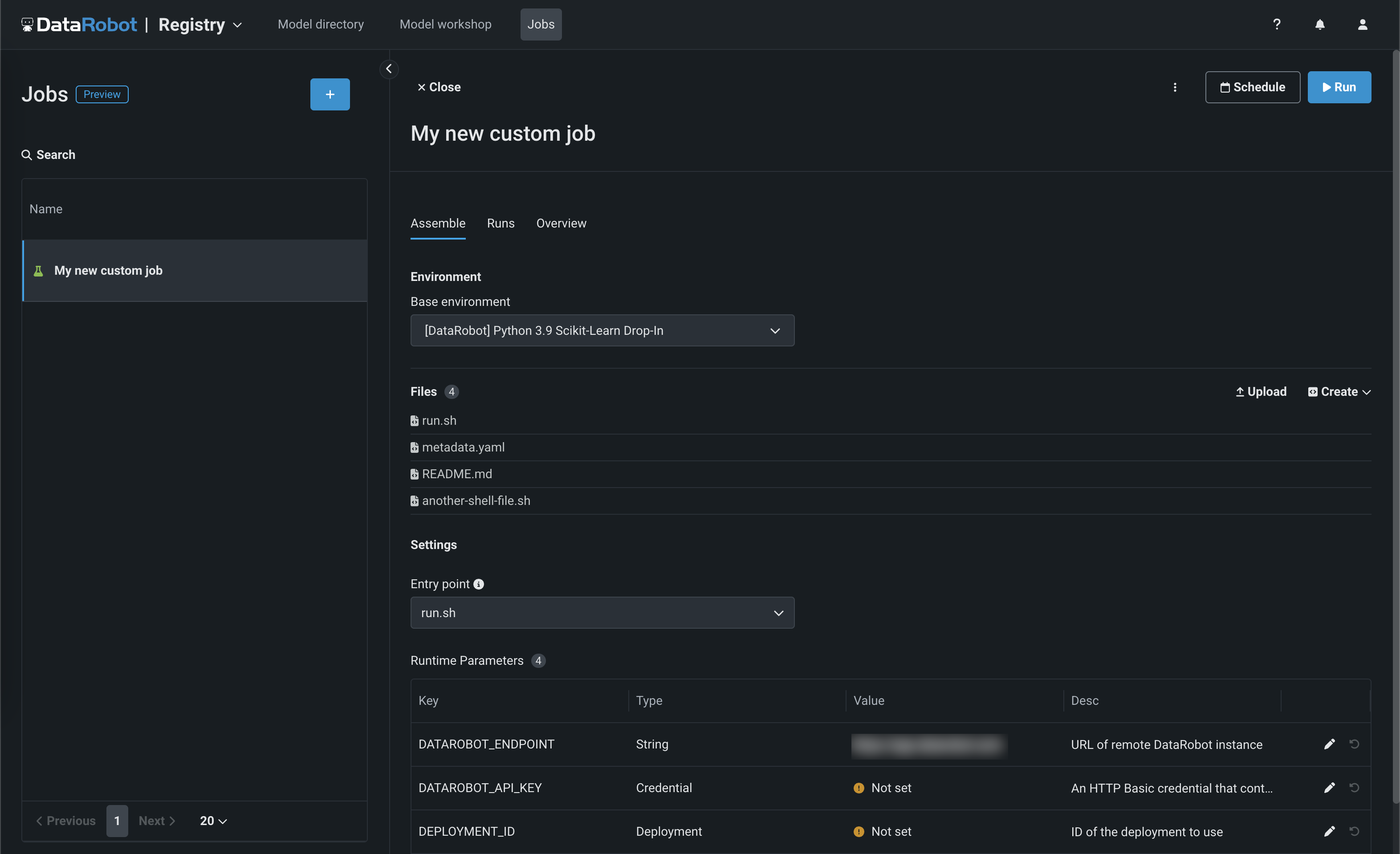
For more information, see the documentation.
NextGen Console¶
The NextGen DataRobot Console provides important management, monitoring, and governance features in a refreshed, modern user interface, familiar to users of MLOps features in DataRobot Classic:
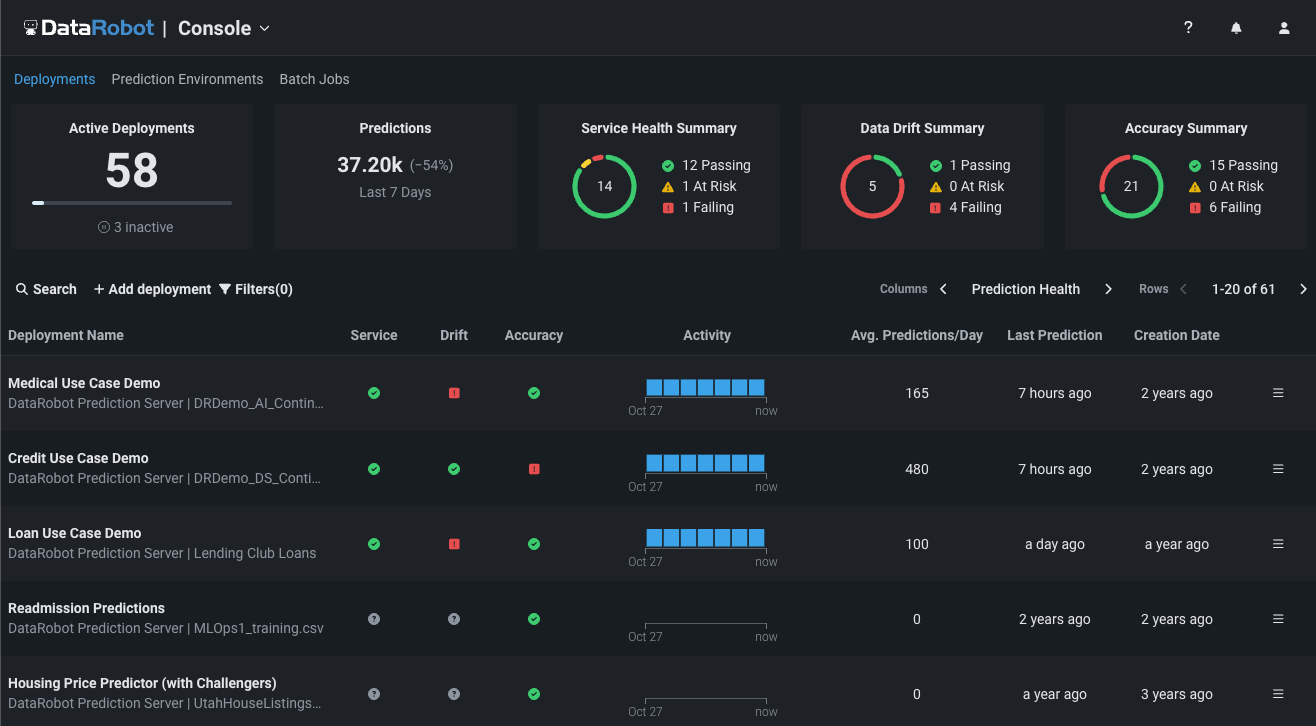
This updated user interface provides a seamless transition from model experimentation and registration—in the NextGen Workbench and Registry—to model monitoring and management through deployments in Console, all while maintaining the user experience you are accustomed to.
For more information, see the documentation.
Feature flag ON by default: Enable Console
Monitoring agent in DataRobot¶
The monitoring agent typically runs outside of DataRobot, reporting metrics from a configured spooler populated by calls to the DataRobot MLOps library in the external model's code. Now available for preview, you can run the monitoring agent inside DataRobot by creating an external prediction environment with an external spooler's credentials and configuration details.
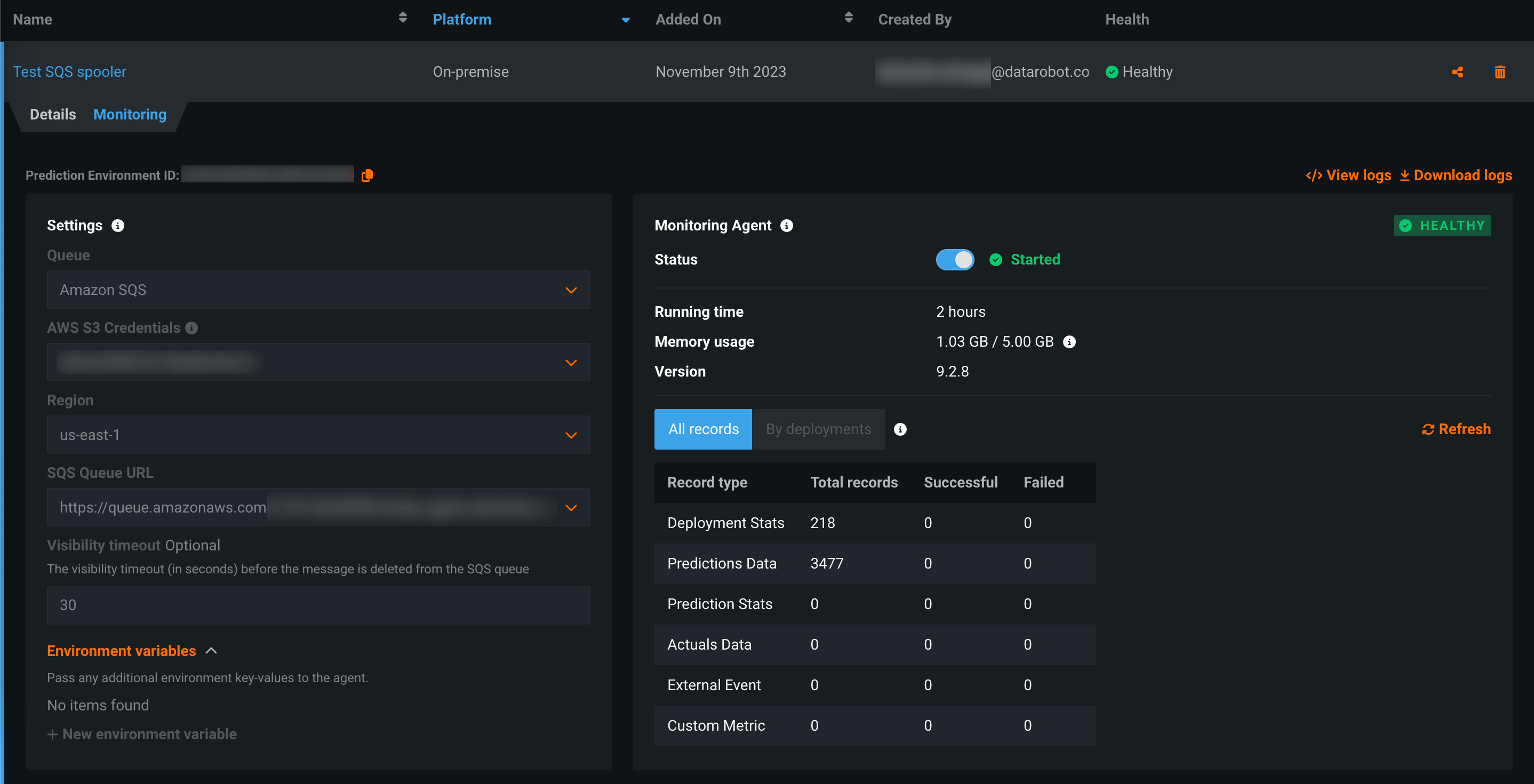
Preview documentation.
Feature flag ON by default: Monitoring Agent in DataRobot
Custom apps hosting with DRApps¶
DRApps is a simple command line interface (CLI) providing the tools required to host a custom application, such as a Streamlit app, in DataRobot using a DataRobot execution environment. This allows you to run apps without building your own docker image. Custom applications don't provide any storage; however, you can access the full DataRobot API and other services.
To install the DRApps CLI tool, clone the ./drapps directory in the datarobot-user-models (DRUM) repository and then install the Python requirements by running the following command:
pip install -r requirements.txt
Preview documentation.
Feature flag ON by default: Enable Custom Applications
API enhancements¶
DataRobot REST API v2.32¶
DataRobot's v2.32 for the REST API is now generally available. For a complete list of changes introduced in v2.31, view the REST API changelog.
New features¶
- New routes to retrieve document thumbnail insights:
GET /api/v2/projects/(projectId)/documentThumbnails/GET /api/v2/projects/(projectId)/documentPages/(documentPageId)/file/GET /api/v2/projects/(projectId)/documentThumbnailSamples/GET /api/v2/projects/(projectId)/documentThumbnailBins/
- New routes to compute and retrieve document text extraction sample insights:
POST /api/v2/models/(modelId)/documentTextExtractionSamples/GET /api/v2/projects/(projectId)/documentTextExtractionSamples/GET /api/v2/models/(modelId)/documentTextExtractionSampleDocuments/GET /api/v2/models/(modelId)/documentTextExtractionSamplePages/
- New routes to retrieve document data quality information:
GET /api/v2/projects/(projectId)/documentsDataQualityLog/GET /api/v2/datasets/(datasetId)/documentsDataQualityLog/GET /api/v2/datasets/(datasetId)/versions/(datasetVersionId)/documentsDataQualityLog/
- New routes to retrieve document data quality information as log files:
GET /api/v2/projects/(projectId)/documentsDataQualityLog/file/GET /api/v2/datasets/(datasetId)/documentsDataQualityLog/file/,GET /api/v2/datasets/(datasetId)/versions/(datasetVersionId)/documentsDataQualityLog/file/
- New route to retrieve deployment predictions vs actuals over time:
GET /api/v2/deployments/(deploymentId)/predictionsVsActualsOverTime/
- New routes to managed registered models and registered model versions(previously known as Model Packages):
GET /api/v2/registeredModels/GET /api/v2/registeredModels/(registeredModelId)/PATCH /api/v2/registeredModels/(registeredModelId)/DELETE /api/v2/registeredModels/(registeredModelId)/GET /api/v2/registeredModels/(registeredModelId)/versions/GET /api/v2/registeredModels/(registeredModelId)/versions/(versionId)/PATCH /api/v2/registeredModels/(registeredModelId)/sharedRoles/GET /api/v2/registeredModels/(registeredModelId)/sharedRoles/GET /api/v2/registeredModels/(registeredModelId)/deployments/GET /api/v2/registeredModels/(registeredModelId)/versions/(versionId)/deployments/
- Added new routes for Use Cases, listed below:
GET /api/v2/useCases/POST /api/v2/useCases/GET /api/v2/useCases/(useCaseId)/PATCH /api/v2/useCases/(useCaseId)/DELETE /api/v2/useCases/(useCaseId)/GET /api/v2/useCases/(useCaseId)/projects/GET /api/v2/useCases/(useCaseId)/applications/GET /api/v2/useCases/(useCaseId)/datasets/GET /api/v2/useCases/(useCaseId)/notebooks/GET /api/v2/useCases/(useCaseId)/playgrounds/GET /api/v2/useCases/(useCaseId)/vectorDatabases/GET /api/v2/useCases/(useCaseId)/modelsForComparison/GET /api/v2/useCases/(useCaseId)/filterMetadata/GET /api/v2/useCases/(useCaseId)/resources/GET /api/v2/useCases/(useCaseId)/sharedRoles/PATCH /api/v2/useCases/(useCaseId)/sharedRoles/POST /api/v2/useCases/(useCaseId)/(referenceCollectionType)/(entityId)/DELETE /api/v2/useCases/(useCaseId)/(referenceCollectionType)/(entityId)/
Python client v3.2¶
v3.2 for DataRobot's Python client is now generally available. For a complete list of changes introduced in v2.31, view the Python client changelog.
New Features¶
- Added support for Python 3.11.
- Added new a library, "strenum", to add
StrEnumsupport while maintaining backwards compatibility with Python 3.7-3.10. DataRobot does not use the nativeStrEnumclass in Python 3.11. - Added a new class
PredictionEnvironmentfor interacting with DataRobot prediction environments. - Extended the advanced options available when setting a target to include new parameters:
modelGroupId,modelRegimeId, andmodelBaselines(part of theAdvancedOptionsobject). These parameters allow you to specify the user columns required to run time series models without feature derivation in OTV projects. -
Added a new method
PredictionExplanations.create_on_training_data, for computing prediction explanation on training data. -
Added a new class
RegisteredModelfor interacting with DataRobot registered models to support the following methods: RegisteredModel.getto retrieve a RegisteredModel object by ID.RegisteredModel.listto list all registered models.RegisteredModel.archiveto permanently archive registered model.RegisteredModel.updateto update registered model.RegisteredModel.get_shared_rolesto retrieve access control information for a registered model.RegisteredModel.shareto share a registered model.RegisteredModel.get_versionto retrieve a RegisteredModelVersion object by ID.RegisteredModel.list_versionsto list registered model versions.-
RegisteredModel.list_associated_deploymentsto list deployments associated with a registered model. -
Added a new class
RegisteredModelVersionfor interacting with DataRobot registered model versions (also known as model packages) to support the following methods: RegisteredModelVersion.create_for_externalto create a new registered model version from an external model.RegisteredModelVersion.list_associated_deploymentsto list deployments associated with a registered model version.RegisteredModelVersion.create_for_leaderboard_itemto create a new registered model version from a Leaderboard model.-
RegisteredModelVersion.create_for_custom_model_versionto create a new registered model version from a custom model version. -
Added a new method
Deployment.create_from_registered_model_versionto support creating deployments from a registered model version. -
Added a new method
Deployment.download_model_package_fileto support downloading model package files (.mlpkg) of the currently deployed model. -
Added support for retrieving document thumbnails:
DocumentThumbnail <datarobot.models.documentai.document.DocumentThumbnail>-
DocumentPageFile <datarobot.models.documentai.document.DocumentPageFile> -
Added support to retrieve document text extraction samples using:
DocumentTextExtractionSampleDocumentTextExtractionSamplePage-
DocumentTextExtractionSampleDocument -
Added new fields to
CustomTaskVersionfor controlling network policies. The new fields were also added to the response. This can be set withdatarobot.enums.CustomTaskOutgoingNetworkPolicy. -
Added a new method
BatchPredictionJob.score_with_leaderboard_modelto run batch predictions using a Leaderboard model instead of a deployment. -
Set
IntakeSettingsandOutputSettingsto useIntakeAdaptersandOutputAdaptersenum values respectively for the propertytype. -
Added the method
Deployment.get_predictions_vs_actuals_over_timeto retrieve a deployment's predictions vs actuals over time data.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.