April 2023¶
April 22, 2023
With the latest deployment, DataRobot's AI Platform delivered the following new GA and preview features. From the release center you can also access:
In the spotlight¶
Time series clustering metrics and insights¶
To help in comparing and evaluating clustering models, two new preview optimization metrics are available via the UI and the API for time series clustering projects. Previously Silhouette scores were the only supported metric. The DTW (Dynamic Time Warping) Silhouette Score measures the average similarity of objects within a cluster and their DTW distance to other objects in the other clusters. (It’s an alternative to Euclidean distance measure for time series.) The Calinski-Harabasz Score describes, for all clusters, the ratio of the sum of between-clusters dispersion and of inter-cluster dispersion. You can set these metrics when configuring DataRobot to discover clusters.
Note that when using clustering in the API, you can enable additional insights and metrics as preview. These additional metrics are automatically computed. However, DTW metrics are not automatically computed for datasets with a large number of series (over 500) due to a risk of out-of-memory errors. Although you can request to compute these metrics manually, they are prone to failure without a significant amount of memory available.
April release¶
The following table lists each new feature. See the deployment history for past feature announcements.
Features grouped by capability
GA¶
Fast Registration in the AI Catalog¶
Now generally available, you can quickly register large datasets in the AI Catalog by specifying the first N rows to be used for registration instead of the full dataset—giving you faster access to data to use for testing and Feature Discovery.
In the AI Catalog, click Add to catalog and select your data source. Fast registration is only available when adding a dataset from a new data connection, an existing data connection, or a URL.
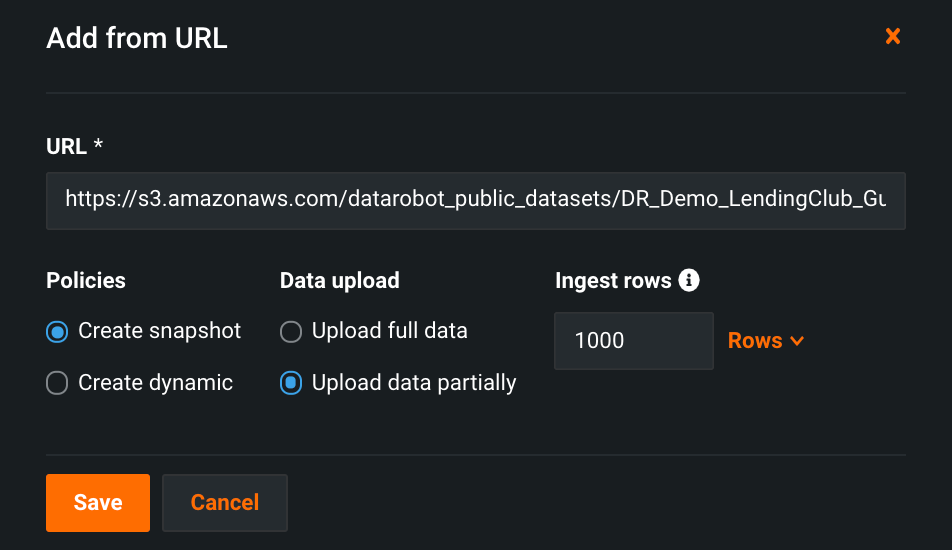
For more information, see Configure Fast Registration.
New driver version¶
With this release, the following driver version has been updated:
- Snowflake==3.13.28
See the complete list of supported driver versions in DataRobot.
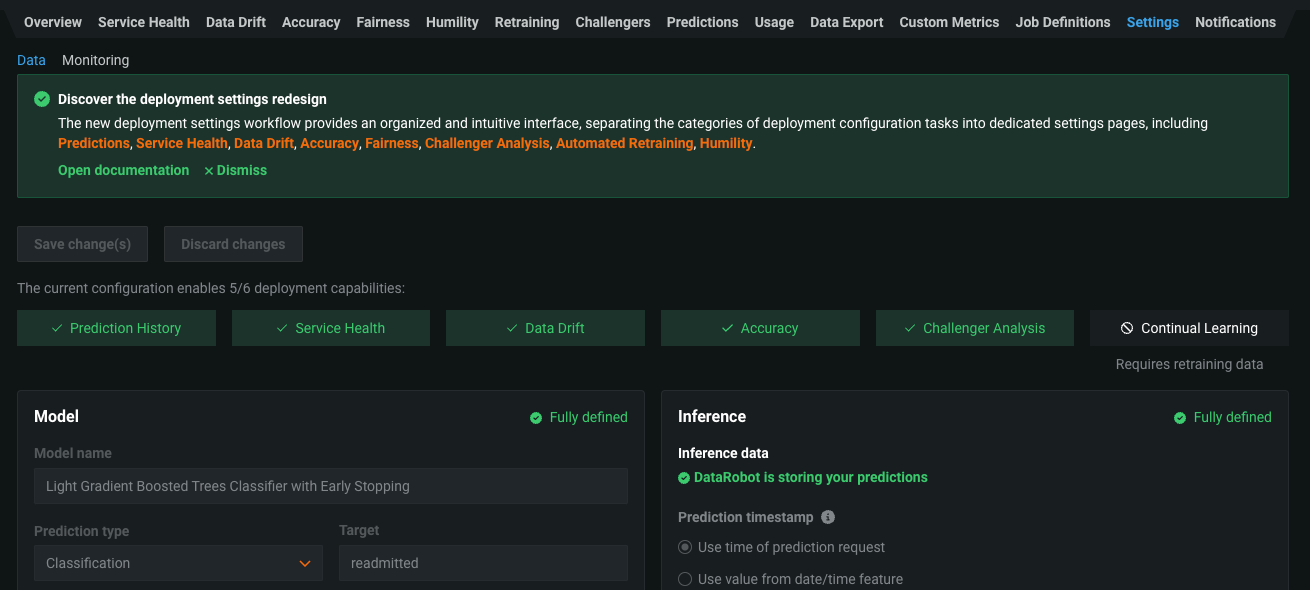
Deployment settings redesign¶
The new deployment settings workflow enhances the deployment configuration experience by providing the required options for each MLOps feature directly on the deployment tab for that feature. This new organization also provides improved tooltips and additional links to documentation to help you enable the functionality your deployment requires.
The new workflow separates the categories of deployment configuration tasks into dedicated settings on the following tabs:
The Deployment > Settings tab is now deprecated. During the deprecation period, a warning appears on the Settings tab to provide links to the new settings pages:
In addition, on each deployment tab with a Settings page, you can click the setting icon to access the required configuration options:
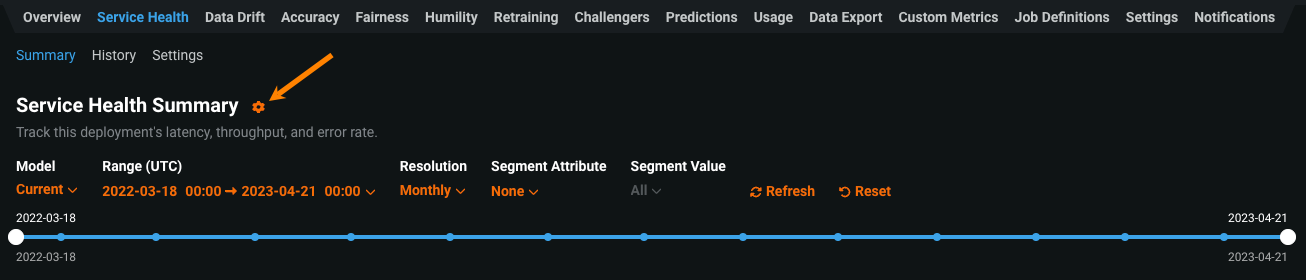
For more information, see the Deployment settings documentation.
Preview¶
Workbench expands validation/partitioning settings in experiment set up¶
Workbench now supports the ability to set and define the validation type when setting up an experiment. With the addition of training-validation-holdout (TVH), users can experiment with building models on more data without impacting run time to maximize accuracy.
Required feature flag: No flag required
Workbench adds new operations added to data wrangling capabilities¶
With this release, three new operations have been added to DataRobot’s wrangling capabilities in Workbench:
-
De-deuplicate rows: Automatically remove all duplicate rows from your dataset.
-
Rename features: Quickly change the name of one or more features in your dataset.
-
Remove features: Remove one or more features from your dataset.
To access new and existing operations, register data from Snowflake to a Workbench Use Case and then click Wrangle. When you publish the recipe, the operations are then applied to the source data in Snowflake to materialize an output dataset.
Required feature flag: No flag required
See the Workbench preview documentation.
Snowflake key pair authentication¶
Now available for preview, you can create a Snowflake data connection in DataRobot Classic and Workbench using the key pair authentication method—a Snowflake username and private key—as an alternative to basic authentication.
Required feature flag: Enable Snowflake Key-pair Authentication
Integrated notebook terminals¶
Now available for preview, DataRobot notebooks support integrated terminal windows. When you have a notebook session running, you can open one or more integrated terminals to execute terminal commands, such as running .py scripts or installing packages. Terminal integration also allows you to have full support for a system shell (bash) so you can run installed programs. When you create a terminal window in a DataRobot Notebook, the notebook page divides into two sections: one for the notebook itself, and another for the terminal.

Required feature flag: Enable Notebooks
Preview documentation.
Built-in visualization charting¶
Now available for preview, DataRobot allows you to create built-in, code-free chart cells within DataRobot Notebooks, enabling you to quickly visualize your data without coding your own plotting logic. Create a chart by selecting a DataFrame in the notebook, choosing the type of chart to create, and configuring its axes.
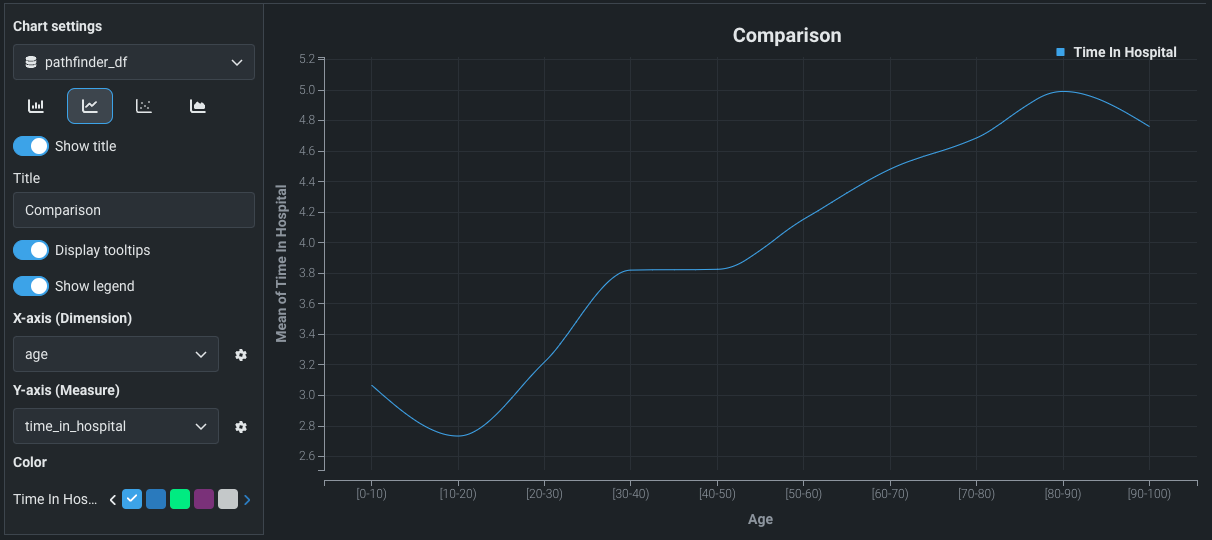
Required feature flag: Enable Notebooks
Preview documentation.
DataRobot Notebooks are now available in the EU¶
Now available for preview, EU users can access DataRobot Notebooks. DataRobot Notebooks offer an enhanced code-first experience in the application. Notebooks play a crucial role in providing a collaborative environment, using a code-first approach to accelerate the machine learning lifecycle. Reduce hundreds of lines of code, automate data science tasks, and accommodate custom code workflows specific to your business needs.

Required feature flag: Enable Notebooks
Preview documentation.
API enhancements¶
New time series clustering metrics and insights¶
To help in comparing and evaluating clustering models, two new preview optimization metrics are available via the API for time series clustering projects.
When using clustering in the API, you can enable additional insights and metrics as preview. These additional metrics are automatically computed. However, DTW metrics are not automatically computed for datasets with a large number of series (over 500) due to a risk of out-of-memory errors. Although you can request to compute these metrics manually, they are prone to failure without a significant amount of memory available.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.