Data and modeling (V10.2)¶
November 21, 2024
The DataRobot v10.2.0 release includes many new data and modeling, as well as admin, features and enhancements, described below. See additional details of Release 10.2:
10.2 release¶
Release v10.2 provides updated UI string translations for the following languages:
- Japanese
- French
- Spanish
- Korean
- Brazilian Portuguese
Features grouped by capability
*Premium
Data¶
GA¶
ADLS Gen2 connector is GA in DataRobot¶
Support for the native ADLS Gen2 connector is now generally available in DataRobot. Additionally, you can create and share Azure service principal and Azure OAuth credentials using secure configurations.
Perform Feature Discovery in Workbench¶
Perform Feature Discovery in Workbench to discover and generate new features from multiple datasets. You can initiate Feature Discovery in two places:
- The Data tab, to the right of the dataset that will serve as the primary dataset, click the Actions menu > Feature Discovery.
- The data explore page of a specific dataset, click Data actions > Start feature discovery.
On this page, you can add secondary datasets and configure relationships between the datasets.
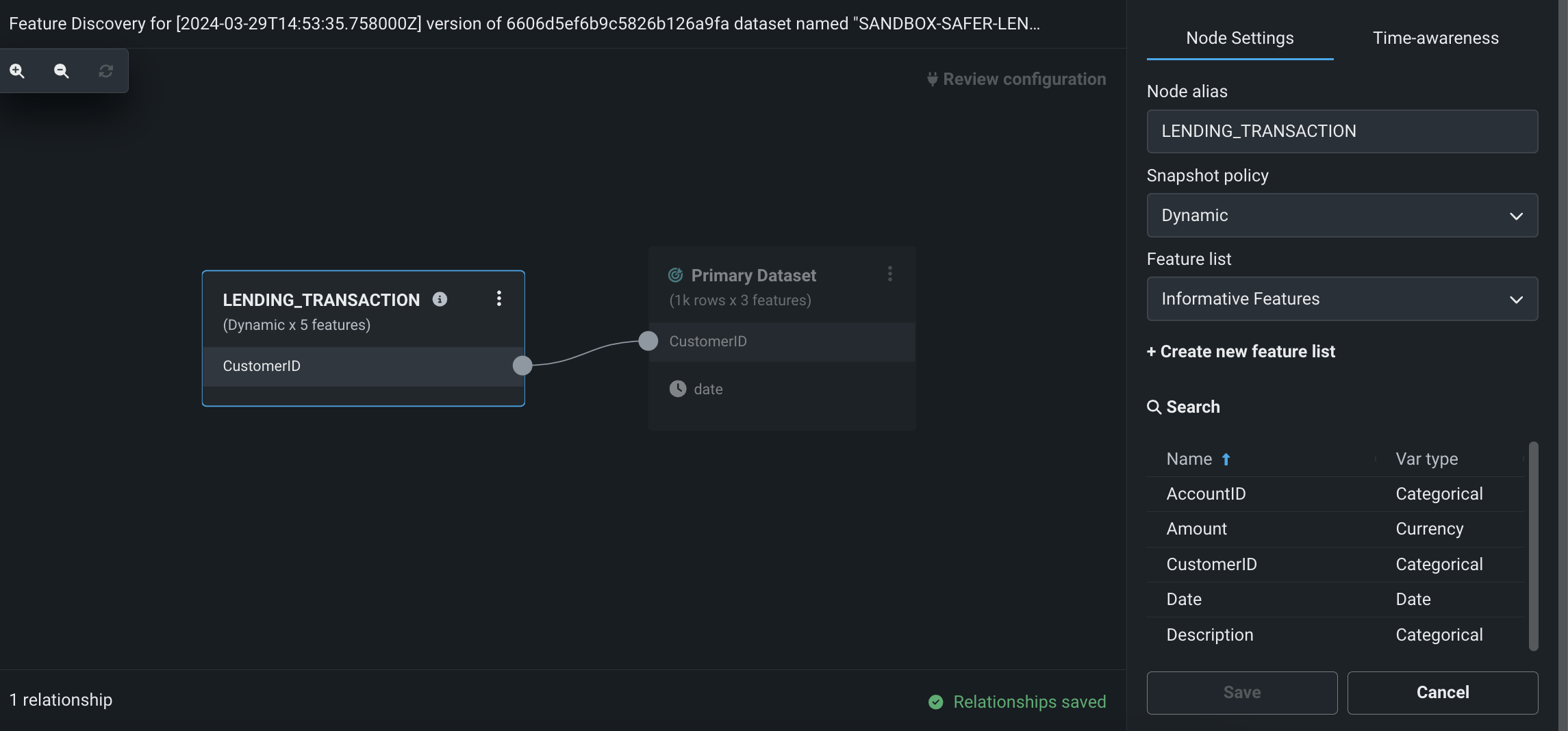
After configuring Feature Discovery and completing an automated relationship assessment, you can immediately proceed to experiment setup and modeling. As part of model building, DataRobot uses this recipe to perform joins and aggregations, generating a new output dataset that is then registered in the Data Registry and added to your current Use Case.
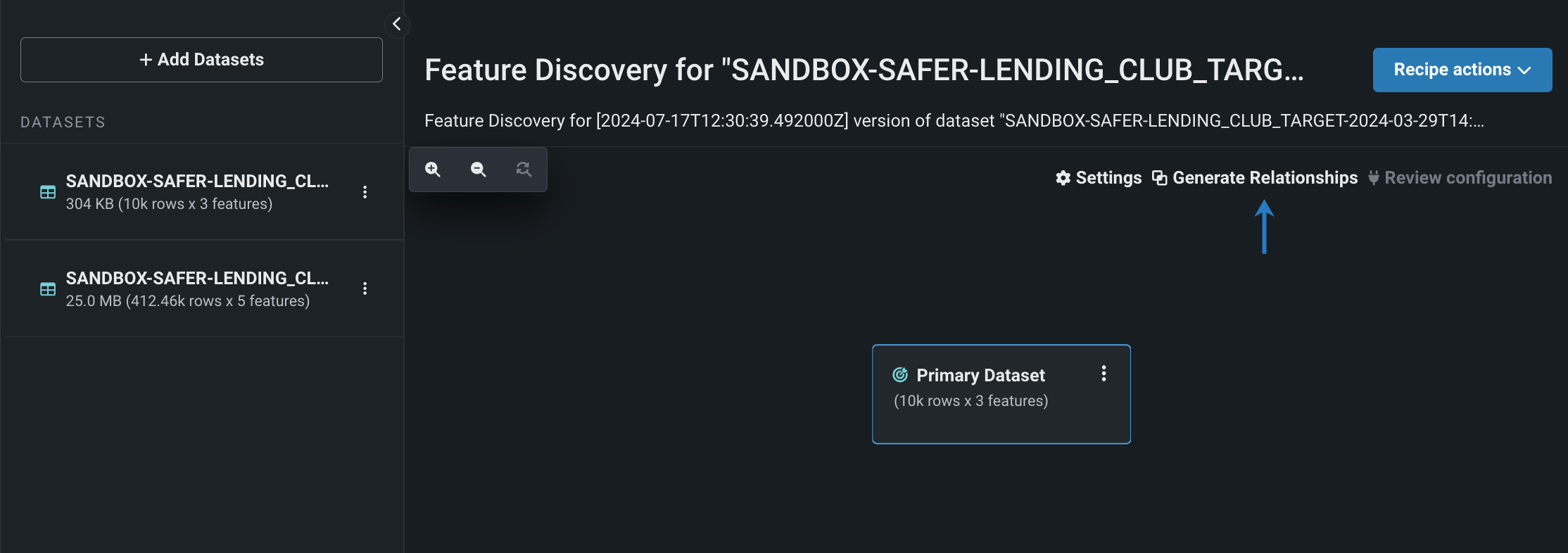
Automatically generate relationships for Feature Discovery in Workbench¶
Use automatic relationship detection (ARD) when performing Feature Discovery in Workbench. ARD analyzes the primary dataset and all secondary datasets added to the recipe to detect and generate relationships. After adding all secondary datasets to the recipe, click Generate Relationships—DataRobot then automatically adds secondary datasets to the canvas and configures relationships between the datasets.
Understand how individual catalog assets relate to other DataRobot entities¶
The AI Catalog serves as a centralized collaboration hub for working with data and related assets in DataRobot. On the Info tab for individual assets, you can now see how other entities in the application are related to—or dependent on—the current asset. This is useful for a number of reasons, allowing you to view how popular an item is based on the number of projects in which it is used, understand which other entities might be affected if you were to make changes or deletions, and learn how the entity is used.
Wrangling enhancements added to Workbench¶
This release introduces the following improvements to data wrangling in Workbench:
- The Remove features operation allows you to select all/deselect all features.
- You can import operations from an existing recipe, either at the beginning or during a wrangling session.
- Access settings for the live preview from the Preview settings button on the wrangling page.
- Additional actions are available from the Actions menu for individual operations, including, adding operation above/below, importing a recipe above/below, duplicate, and preview up to a specific operation, which allows you to quickly see how different combinations of operations affect the live sample.
Additional EDA insights added to Workbench¶
This release introduces the following EDA insights on the Features tab of the data explore page in Workbench:
-
Data quality checks appear as indicators on the Features tab of the data explore page as well as insights for individual features.

-
The Histogram chart displays data quality issues with outliers.

-
The Frequent Values chart reports inliers, disguised missing values, and excess zeros.
- The Feature lineage insight for Feature Discovery datasets shows how a feature was generated.
Support for SAP Datasphere connector in DataRobot¶
Available as a premium feature, DataRobot now supports the SAP Datasphere connector, available for preview, in both NextGen and DataRobot Classic.
Feature flag OFF by default: Enable SAP Datasphere Connector (Premium feature)
Improved scalability when working with large Feature Discovery datasets¶
DataRobot increases scalability when working with large datasets in Feature Discovery with the following improvements:
- Flexible resource allocation for Feature Discovery jobs. Admins can allocate additional compute resources by navigating to User settings > System configuration, enabling
XLARGE_MM_WORKER_SAFER_AIM_CONTAINER_MEM_MB, and specifying the number of resources in the field. - When configured, you can run Feature Discovery with secondary datasets up to 20GB, and the output dataset can also be 20GB.
- You can download the SQL recipe to understand how DataRobot performs joins and aggregations as part of Feature Discovery.
Preview¶
Additional support added to wrangling for DataRobot datasets¶
The ability to wrangle datasets stored in the Workbench Data Registry, first introduced for preview in 10.1, is now supported by all environments.
Incremental learning support for dynamic datasets is now available¶
Support for modeling on dynamic datasets larger than 10GB, for example, data in a Snowflake, BigQuery, or Databricks data source, is now available. When configuring the experiment, set an ordering feature to create a deterministic sample from the dataset and then begin incremental modeling as usual. After model building starts, View experiment info now reports the selected ordering feature.
Feature flags ON by default: Enable incremental learning, Enable dynamic datasets in Workbench, Enable data chunking service
Preview documentation.
New operations, automated derivation plan available for time series data wrangling¶
This release extends the existing data wrangling framework with tools to help prepare input for time series modeling, allowing you to perform time series feature engineering during the data preparation phase. This change works in conjunction with the fundamental wrangler improvements announced this month. Use the Derive time series features operation to execute lags and rolling statistics on the input data, either using a suggested derivation plan that automates feature generation or by manually selecting features and applying tasks, and DataRobot will build new features and apply them to the live data sample.
While these operations can be added to any recipe, setting the preview sample method to date/time enables an option to have DataRobot suggest feature transformations based on the configuration you provide. With the automated option, DataRobot expands the data according to forecast distances, adds known in advance columns (if specified) and naive baseline features, and then replaces the original sample. Once complete, you can modify the plan as needed.
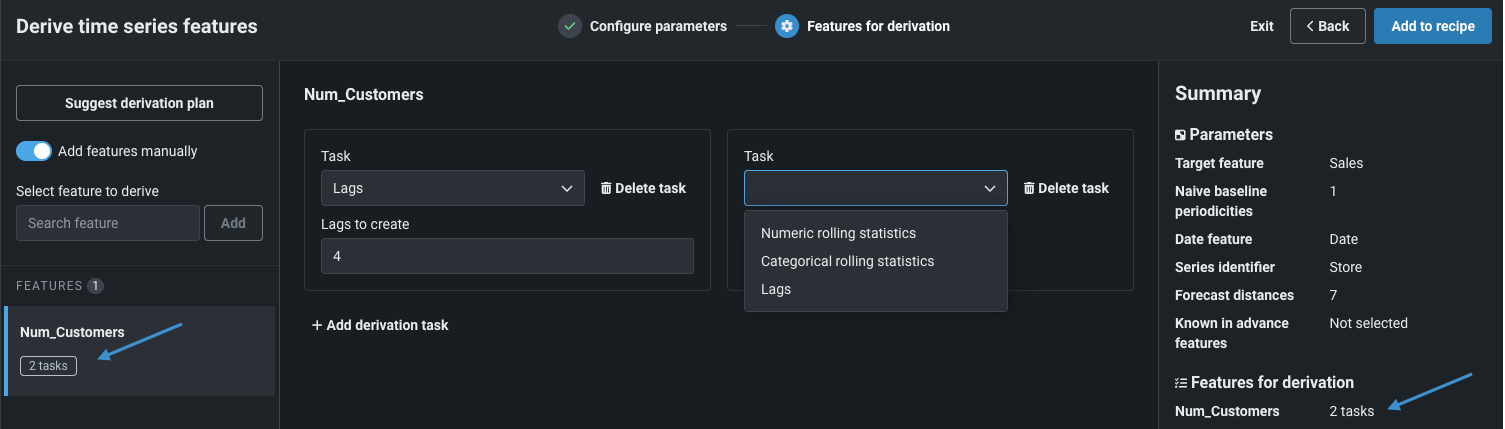
Feature flag ON by default: Enable Time Series Data Wrangling
Preview documentation.
Scalability when publishing wrangling recipes for large DataRobot datasets¶
When publishing a wrangling recipe for input datasets larger than 20GB, you can now push the data transformations and analysis down to a DataRobot compute engine for seamless, scalable, and secure data processing of CSV and Parquet files stored in S3. Note that this feature is only available for AWS SaaS and VPC installations.
Feature flag OFF by default: Enable Distributed Spark Support for Data Engine
Modeling¶
GA¶
Automatically remove date features before running Autopilot¶
When setting up a non-time aware project in DataRobot Classic, you can now automatically remove date features from the feature list you want to use to run Autopilot. To do so, open Advanced options for the project, select the Additional tab, and then select Remove date features from selected list and create new modeling feature list. Enabling this parameter duplicates the selected feature list, removes raw date features, and uses the new list to run Autopilot. Excluding raw date features from non-time aware projects can prevent issues like overfitting.
Compute Prediction Explanations for data in OTV and time series projects¶
Now generally available, you can compute Prediction Explanations for time series and OTV projects. Specifically, you can get XEMP Prediction Explanations for the holdout partition and sections of the training data. DataRobot only computes Prediction Explanations for the validation partition of backtest one in the training data.
Compliance documentation now available for text generation registered models¶
DataRobot has long provided model development documentation that can be used for regulatory validation of predictive models. Now, the compliance documentation is expanded to include auto-generated documentation for text generation models in the Registry's model directory. For DataRobot natively supported LLMs, the document helps reduce the time spent generating reports, including model overview, informative resources, and most notably model performance and stability tests. For non-natively supported LLMs, the generated document can serve as a template with all necessary sections.
Violin plot distribution insight for Individual Prediction Explanations¶
The SHAP Distributions: Per Feature, also called a violin plot, is a statistical graphic for comparing probability distributions of a dataset across different categories. Based on a sampling of 1,000 rows, this new SHAP insight displays cohorts of rows and visualizes them per feature, allowing you to inspect distributions of SHAP values and feature values.

DataRobot now provides two SHAP tools to help analyze how feature values influence predictions:
- SHAP Distributions: Per Feature shows the distribution and density of scores per feature using a violin plot for the visualization.
- Individual Prediction Explanations show the effect of each feature on prediction on a row-by-row basis.
Home page changes from user feedback¶
The DataRobot home page, introduced in November of 2023, provides access to a wealth of information for use with the DataRobot app. Responding to user feedback, the new home page has been fine-tuned to provide quick help for new users and access to recent activity for returning users. Use the tiles at the top to quickly access:
-
Application template end-to-end solutions. These code-first, reusable pipelines are available out-of-the-box, but also offer easy customization, for quick, tailored successes.
-
The Use Case directory to create or revisit your experiment-based, iterative workflows for predictive and generative AI models.
-
The Registry’s model directory where you can manage, govern, and deploy assets to production.

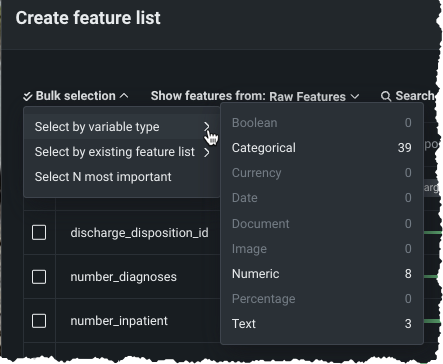
Data tab and custom feature list functionality now GA¶
The ability to add new, custom feature lists to an existing predictive or forecasting experiment through the UI was introduced in April as a preview feature. Now generally available, you can create your own lists from the Feature Lists or Data tabs (also both now GA) in the Experiment information window accessed from the Leaderboard. Use bulk selections to choose multiple features with a single click:
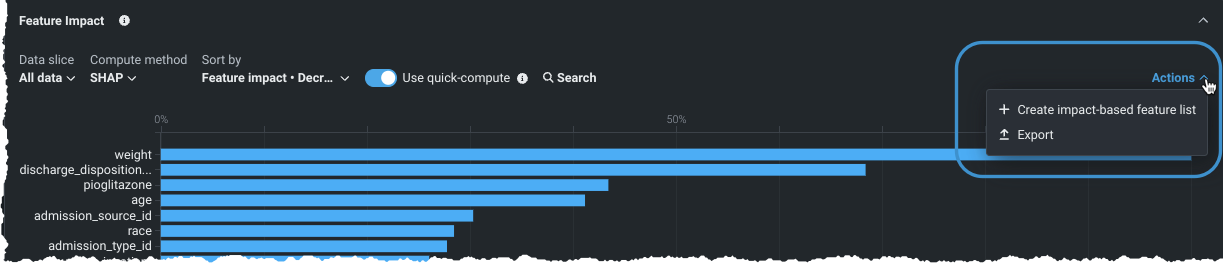
Create custom feature lists from Feature Impact¶
You can now create feature lists based on the relative impact of features from the Feature Impact insight, accessed from the Model Overview. Using the same familiar interface as the other feature list creation options in NextGen, any lists created in Feature Impact are available for use across the experiment.
Time series now generally available; support for partial and new series blueprints added¶
In this release, time series functionality in Workbench becomes generally available. As part of the update, the forecasting capabilities now include support for new and partial history data. Some blueprints return suboptimal predictions when seeing new series that have only partial history available. When this option is selected, DataRobot also trains models that are designed to make predictions on incomplete historical data. This would be series that were not seen in the training data ("cold start") and prediction datasets with series history that is only partially known (historical rows are partially available within the feature derivation window).

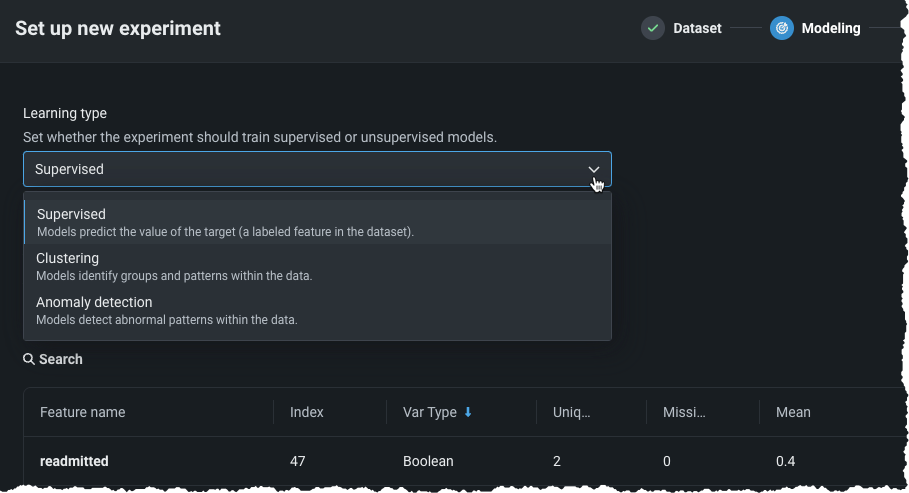
Unsupervised modeling now available in Workbench¶
Now, Workbench offers unsupervised learning, where no target is specified and data is unlabeled. Instead of generating predictions, unsupervised learning surfaces insights about patterns in your data. Available for both predictive and time-aware experiments, unsupervised learning brings clustering and anomaly detection, answering questions like "Are there anomalies in my data?" and "Are there natural clusters?" To create an unsupervised experiment, specify a learning type and complete the corresponding fields.
After model building completes, unsupervised-specific insights surface the identified patterns.
Clustering in Incremental Learning¶
This release adds support for K-Means clustering models to DataRobot’s incremental learning capabilities. Incremental learning (IL) is a model training method specifically tailored for large datasets—those between 10GB and 100GB—that chunks data and creates training iterations. With this support, you can build non-time series clustering projects with larger datasets, helping you to explore your data by grouping and identifying natural segments.
Geospatial modeling now available in Workbench¶
To help gain insights into geospatial patterns in your data, you can now natively ingest common geospatial formats and build enhanced model blueprints with spatially-explicit modeling tasks when building in Workbench. During experiment setup, from Additional settings, select a location feature in the Geospatial insights section and make sure that feature is in the modeling feature list. DataRobot will then create geospatial insights—Accuracy Over Space for supervised projects and Anomaly Over Space for unsupervised.

Increased training sizes for geospatial modeling¶
With this release, DataRobot has increased the maximum number of rows supported for geospatial modeling (Location AI) from 100,000 rows to 10,000,000 rows in DataRobot Classic. Location AI allows ingesting common geospatial formats, automatically recognizing geospatial coordinates to support geospatial analysis modeling. The increased training data size improves your ability to find geospatial patterns in your models.
Multiclass classification now GA in Workbench¶
Initially released to Workbench in March 2024, multiclass modeling and the associated confusion matrix are now generally available. To support an expansive set of multiclass modeling experiments—classification problems in which the answer has more than two outcomes—DataRobot provides support for an unlimited number of classes using aggregation.

Custom tasks now available for Self-Managed users¶
Custom tasks allow you to add custom vertices into a DataRobot blueprint, and then train, evaluate, and deploy that blueprint in the same way as you would for any DataRobot-generated blueprint. With v10.2 the functionality is available via DataRobot Classic and the API for self-managed installations as well.
XEMP Individual Prediction Explanations now in Workbench¶
Workbench now offers two methodologies for computing Individual Prediction Explanations: SHAP (based on Shapley Values) and XEMP (eXemplar-based Explanations of Model Predictions). This insight, regardless of method, helps explain what drives predictions. The XEMP-based explanations are a proprietary method that support all models—they have long been available in DataRobot Classic. In Workbench, they are only available in experiments that don't support SHAP.

Personal data detection now GA in SaaS, Self-Managed¶
Because the use of personal data as a modeling feature is forbidden in some regulated use cases, DataRobot Classic provides personal data detection capabilities. The feature is now generally available in both SaaS and self-managed environments. Access the check after uploading data to the AI Catalog.

Preview¶
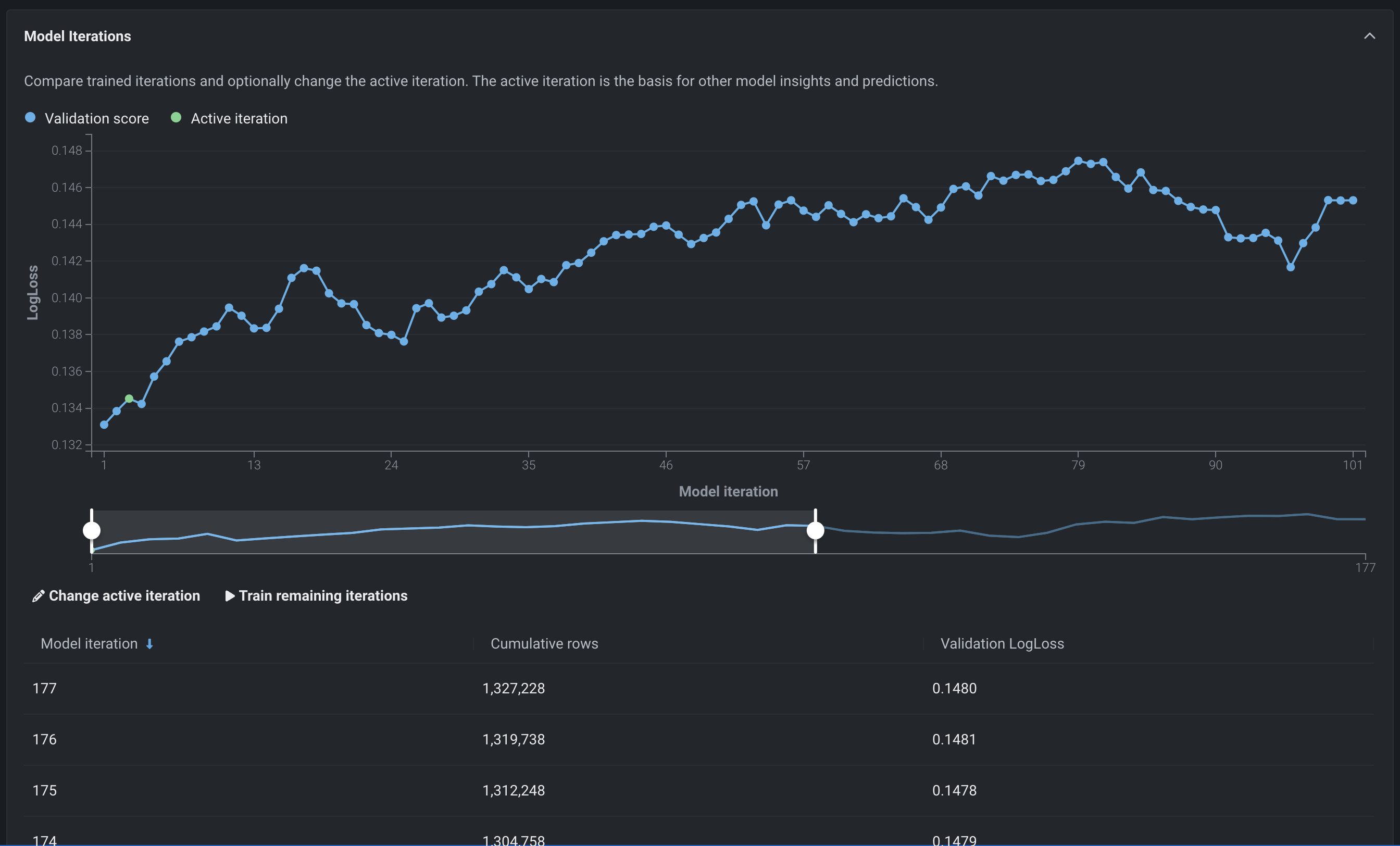
New Incremental Learning insight for comparing iterations¶
The Model Iterations insight for incremental learning allows you to compare trained iterations and, optionally, assign a different active iteration or continue training. Now, the insight adds a learning curve as an aid in data visualization. With the information gained from viewing the chart, you can, for example, continue your experimentation by changing your active iteration or training new iterations.
Feature flag ON by default: Enable Incremental Learning
Preview documentation.
Admin¶
GA¶
Configure maximum compute instances for a serverless platform¶
Admins can now increase deployments' max compute instances limit on per-organization basis. If not specified, the default is 8. To limit compute resource usage, set the maximum value equal to the minimum.
Monitor EDA resource usage across an organization¶
Now generally available, administrators can monitor the number of configured workers being used for EDA1 and related tasks on the EDA tab of the Resource Monitor. The Resource Monitor provides visibility into DataRobot's active modeling and EDA workers across the installation, providing general information about the current state of the application and specific information about the status of components.
Configure custom certificate authority bundles¶
Generally available to self-managed users, DataRobot allows you to configure a custom certificate authority (CA) bundle with root TLS certificates from private and public CA issuers. DataRobot recommends that those using self-signed certificates with the ALLOW_SELF_SIGNED_CERTS configuration to migrate. Contact DataRobot support (mailto:support@datarobot.com) for the administrator's guide that provides details on the requirements and configuration steps.
User Activity Monitor now enabled by default¶
The User Activity Monitor is now enabled for all organization admins, allowing them to access and analyze various usage data and prediction statistics within their org without manually enabling a feature flag.
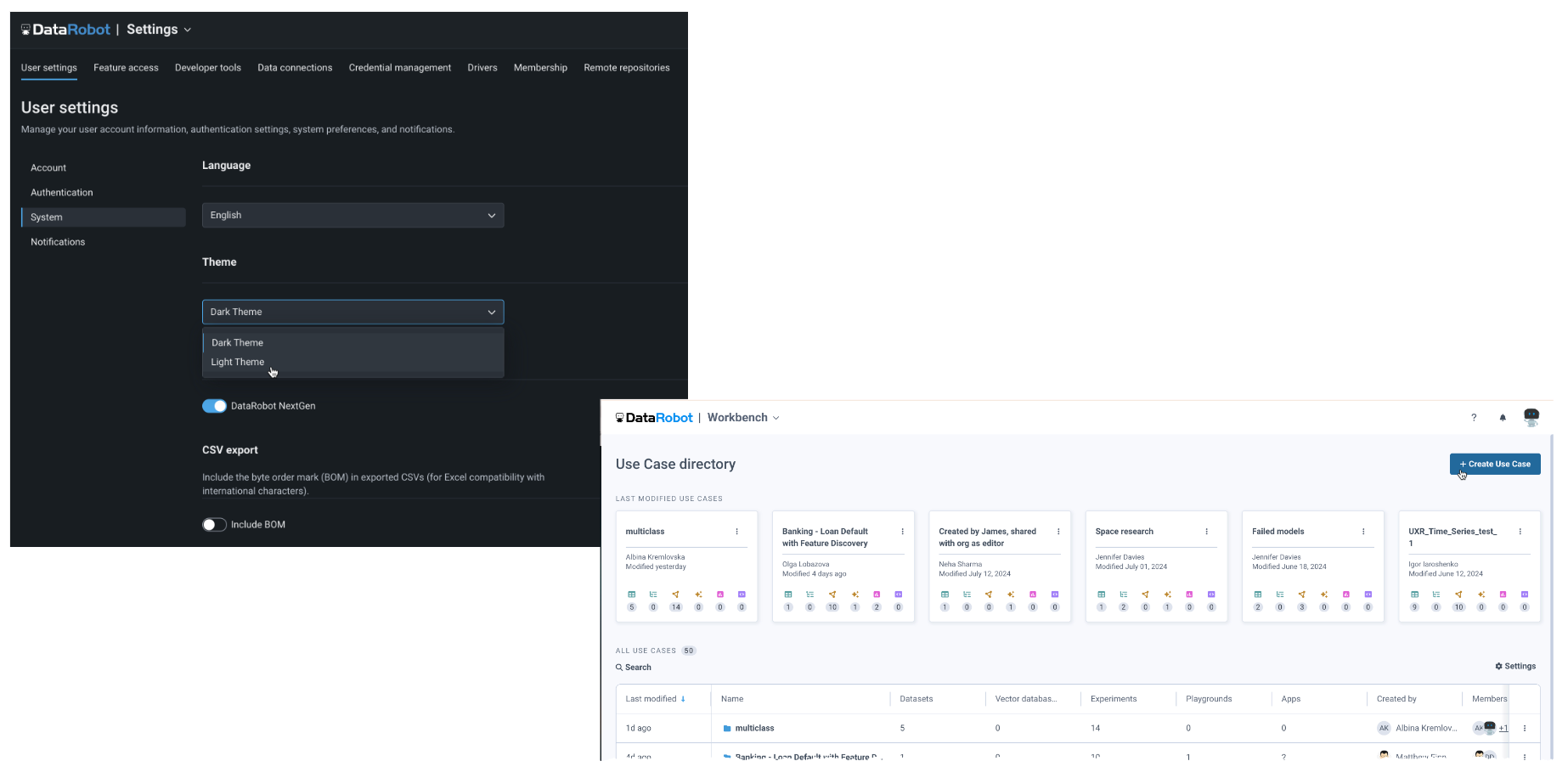
Light theme now available for application display¶
You can now change the display theme of the DataRobot application, which displays in the dark theme by default. To change the color of the display, from your profile avatar in the upper-right corner, navigate to User Settings > System and use the Themes dropdown:
Deprecations and migrations¶
ADLS Gen2 and S3 connectors versions¶
The ADLS Gen 2 (versions 2021.2.1634676262008 and 2020.3.1605726437949) and Amazon S3 (version 2020.3.1603724051432) connectors have been deprecated. It is recommended that you recreate any existing data connections using the new connector versions to benefit from additional authentication mechanisms, bug fixes, and the ability to use these connections in NextGen.
The following preview feature flags will also be disabled:
- Enable DataRobot Connector
- Enable OAuth 2.0 for ADLS Gen2
The existing connections created using older versions will continue to work. Moving forward, DataRobot won't make any enhancements or bug fixes to these older versions.
Self-signed certificates¶
Self-signed certificate configuration (ALLOW_SELF_SIGNED_CERTS) has been deprecated. It will be removed in a future release after 11.1. For improved security, DataRobot recommends that users migrate from self-signed certificates to the custom certificate authority (CA) bundle, with root TLS certificates from private and public CA issuers. Contact DataRobot support (support@datarobot.com) for the administrator's guide that provides details on the requirements and configuration steps.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.