July 2022¶
July 27, 2022
With the latest deployment, DataRobot's managed AI Platform deployment delivered the following new GA and preview features. See the deployment history for past feature announcements. See also:
Features grouped by capability
Features grouped by capability
GA¶
Native Prophet and Series Performance blueprints in Autopilot¶
Support for native Prophet, ETS, and TBATS models for single and multiseries time series projects was announced as generally available in the June release. (A detailed model description can be found for each model by accessing the model blueprint.) With this release, a slight modification has been made so that these models no longer run as part of Quick Autopilot. DataRobot will run them, as appropriate in full Autopilot and they are also available from the model repository.
Text AI parameters now generally available via Composable ML¶
The ability to modify certain Text AI preprocessing tasks (Lemmatizer, PosTagging, and Stemming) has moved from the Advanced Tuning tab to blueprint tasks accessible via composable ML. The new Text AI preprocessing tasks unlock additional pathways to create unique text blueprints. For example, you can now use lemmatization in any text model that supports that preprocessing task instead of being limited to TF-IDF blueprints. Previously available as a preview feature, these tasks are now available without a feature flag.
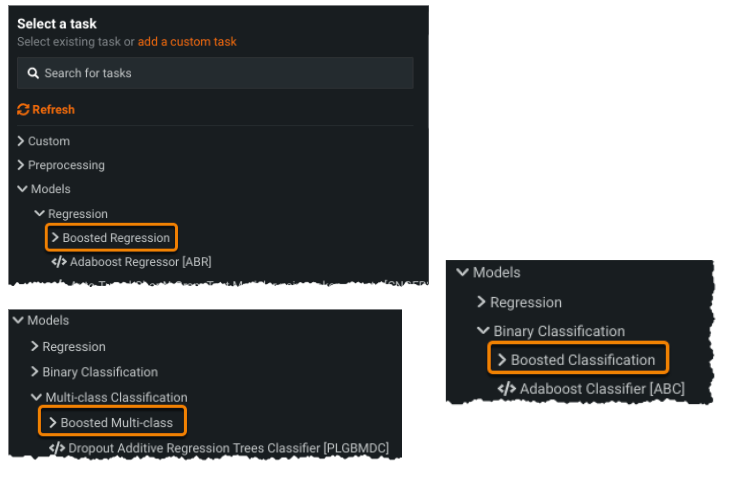
Composable ML task categories refined¶
In response to the feedback and widespread adoption of Composable ML and blueprint editing, this release brings some refinements to task categorization. For example, boosting tasks are now available under the specific project/model type:
NLP Autopilot with better language support now GA¶
A host of natural language processing (NLP) improvements are now generally available. The most impactful is the application of FastText for language detection at data ingest, which:
-
Allows DataRobot to generate the appropriate blueprints with parameters optimized for that language.
-
Adapt tokenization to the detected language for better word clouds and interpretability.
-
Trigger specific blueprint training heuristics so that accuracy-optimized Advanced Tuning settings are applied.
This feature works with multilingual use cases as well; Autopilot will detect multiple languages and adjust various blueprint settings for the greatest accuracy.
The following NLP enhancements are also now generally available:
-
New pre-trained BPE tokenizer (which can handle any language).
-
Refined Keras blueprints for NLP for improved accuracy and training time.
-
Various improvements across other NLP blueprints.
-
New Keras blueprints (with the BPE tokenizer) in the Repository.
No-Code AI App header enhancements¶
This release introduces improvements to the layout and header of No-Code AI Apps. Toggle between the tabs below to view the improvements made to the UI when using and editing an application:
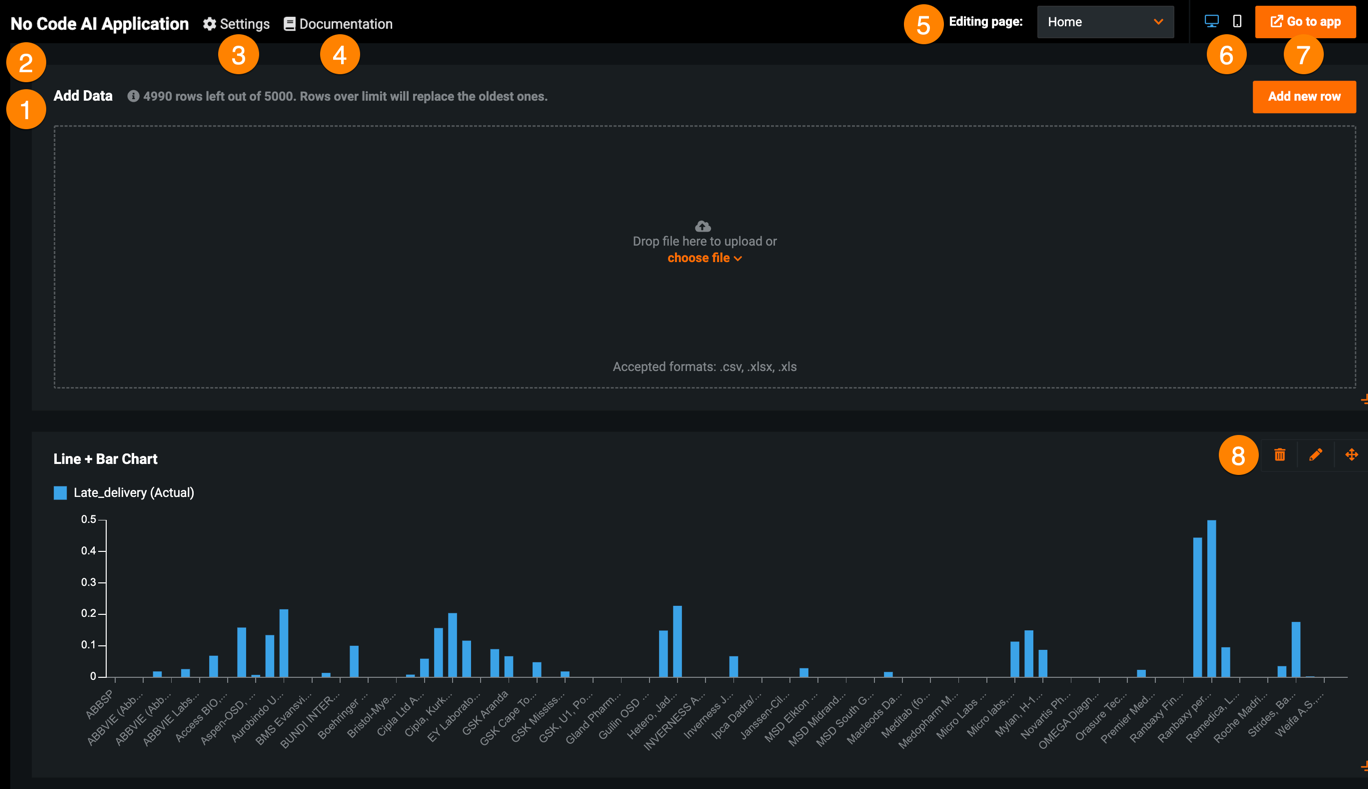
| Element | Description | |
|---|---|---|
| 1 | Pages panel | Allows you to rename, reorder, add, hide, and delete application pages. |
| 2 | Widget panel | Allows you to add widgets to your application. |
| 3 | Settings | Modifies general configurations and permissions as well as displays app usage. |
| 4 | Documentation | Opens the DataRobot documentation for No-Code AI Apps. |
| 5 | Editing page dropdown | Controls the application page you are currently editing. To view a different page, click the dropdown and select the page you want to edit. Click Manage pages to open the Pages panel. |
| 6 | Preview | Previews the application on different devices. |
| 7 | Go to app / Publish | Opens the end-user application, where you can make new predictions, as well as view prediction results and widget visualizations. After editing an application, this button displays Publish, which you must click to apply your changes. |
| 8 | Widget actions | Moves, hides, edits, and deletes widgets. |
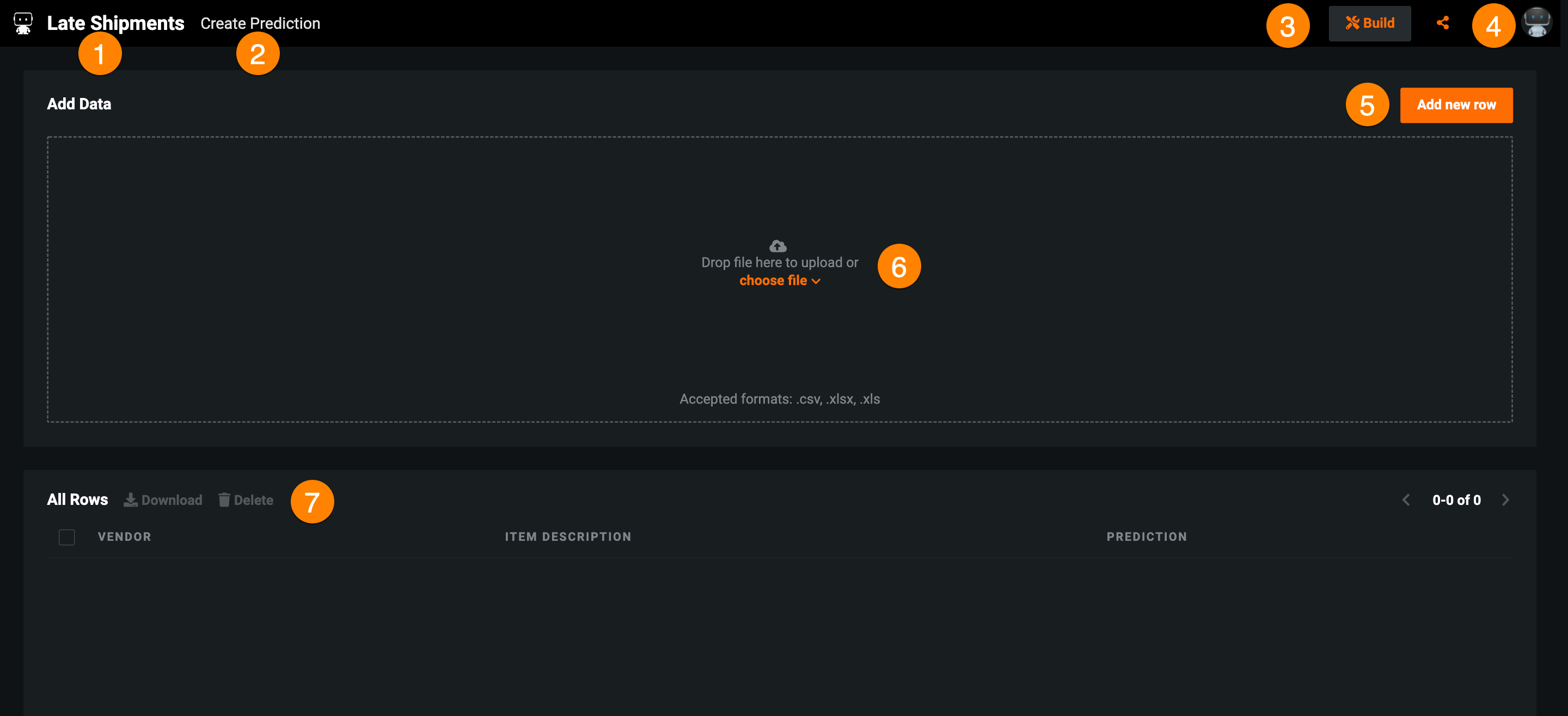
| Widget | Description | |
|---|---|---|
| 1 | Application name | Displays the application name. Click to return to the app's Home page. |
| 2 | Pages | Navigates between application pages. |
| 3 | Build | Allows you to edit the application. |
| 4 | Share | Share the application with users, groups, or organizations within DataRobot. |
| 5 | Add new row | Opens the Create Prediction page, where you can make single record predictions. |
| 6 | Add Data | Upload batch predictions—from the AI Catalog or a local file. |
| 7 | All rows | Displays a history of predictions. Select a row to view prediction results for that entry. |
Support for Manual mode introduced to segmented modeling¶
With this release, you can now use manual mode with segmented modeling. Previously you could on choose Quick or full Autopilot. When using Manual mode with segmented modeling, DataRobot creates individual projects per segment and completes preparation as far as the modeling stage. However, DataRobot does not create per-project models. It does create the Combined Model (as a placeholder), but does not select a champion. Using Manual mode is a technique you can use to have full manual control over which models are trained in each segment and selected as champions, without taking the time to build models.
Scoring code for time series projects¶
Now generally available, you can export time series models in a Java-based Scoring Code package. Scoring Code is a portable, low-latency method of utilizing DataRobot models outside the DataRobot application.
You can download a model's time series Scoring Code from the following locations:
-
Download from the Leaderboard (Leaderboard > Predict > Portable Predictions)
-
Download from the deployment (Deployments > Predictions > Portable Predictions)
With segmented modeling, you can build individual models for segments of a multiseries project. DataRobot then merges these models into a Combined Model. You can generate Scoring Code for the resulting Combined Model.
To generate and download Scoring Code, each segment champion of the Combined Model must have Scoring Code:
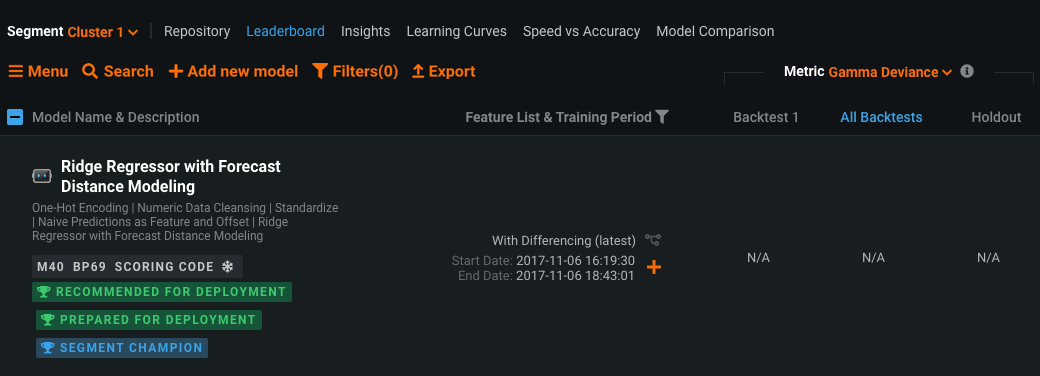
After you ensure each segment champion of the Combined Model has Scoring Code, you can download the Scoring Code from the Leaderboard or you can deploy the Combined Model and download the Scoring Code from the deployment.
You can now include prediction intervals in the downloaded Scoring Code JAR for a time series model. You can download Scoring Code with prediction intervals from the Leaderboard or from a deployment.

You can score data at the command line using the downloaded time series Scoring Code. This release introduces efficient batch processing for time series Scoring Code to support scoring larger datasets. For more information, see the Time series parameters for CLI scoring documentation.
For more details on time series Scoring Code, see Scoring Code for time series projects.
Preview¶
Project duplication, with settings, for time series projects¶
Now available for preview, you can duplicate ("clone") any DataRobot project type, including unsupervised and time-aware projects like time series, OTV, and segmented modeling. Previously, this capability was only available for AutoML projects (non time-aware regression and classification).
Duplicating a project provides an option to select the dataset only—which is faster than re-uploading it—or a dataset and project settings. For time-aware projects, this means cloning the target, the feature derivation and forecast window values, any selected calendars, KA, features, series IDs—all time series settings. If you used the data prep tool to address irregular time step issues, cloning uses the modified dataset (which is the one that was used for model building in the parent project.) You can access the Duplicate option from either the projects dropdown (upper right corner) or the Manage Project page.
Required feature flag: Enable Cloning Time-Aware and Unsupervised Projects with Project Settings
Multiclass support in No-Code AI Apps¶
In addition to binary classification and regression problems, No-Code AI Apps now support multiclass classification deployments across all three templates—Predictor, Optimizer, and What-if. This gives you the ability to leverage No-Code AI Apps for a broader range of business problems across several industries, thus expanding its benefits and value.
Required feature flag: Enable Application Builder Multiclass Support
Details page added to time series Predictor applications¶
In time series Predictor No-Code AI Apps, you can now view prediction information for specific predictions or dates, allowing you to not only see the prediction values, but also compare them to other predictions that were made for the same date. Previously, you could only view values for the prediction, residuals, and actuals, as well as the top three Prediction Explanations.
To drill down into the prediction details, click on a prediction in either the Predictions vs Actuals or Prediction Explanations chart. This opens the Forecast details page, which displays the following information:


| Description | |
|---|---|
| 1 | The average prediction value in the forecast window. |
| 2 | Up to 10 Prediction Explanations for each prediction. |
| 3 | Segmented analysis for each forecast distance within the forecast window. |
| 4 | Prediction Explanations for each forecast distance included in the segmented analysis. |
Required feature flag: Enable Application Builder Time Series Predictor Details Page
Preview documentation.
Text Prediction Explanations illustrate impact on an n-gram level¶
With Text Prediction Explanations, you can understand how the individual words (n-grams) in a text feature influence predictions, helping to validate and understand the model and the importance it is placing on words. Previously, DataRobot evaluated the impact of text in a dataset as the impact of a text feature as a whole, potentially requiring reading the full text for best understanding. With Text Prediction Explanations, which uses the standard color bar spectrum of blue (negative) to red (positive) impact, you can easily visualize and understand your text. An option to display unknown n-grams helps to identify, via gray highlight, those n-grams not recognized by the model (most likely because they were not seen during training).
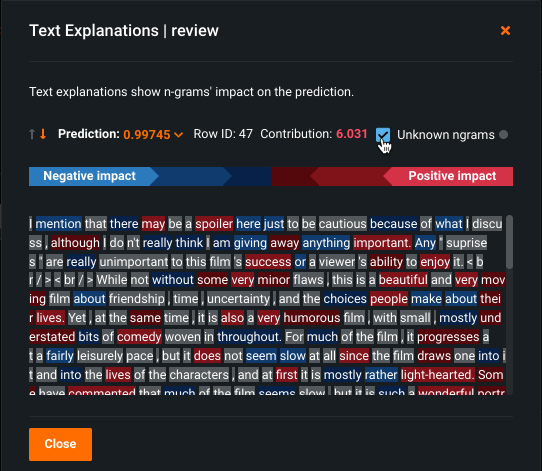
Required feature flag: Enable Text Prediction Explanations
For more information, see the Text Prediction Explanations documentation.
Blueprint toggle allows summary and detailed views from Leaderboard¶
Blueprints that are viewed from the Leaderboard’s Blueprint tab are, by default, a read-only, summarized view, showing only those tasks used in the final model.
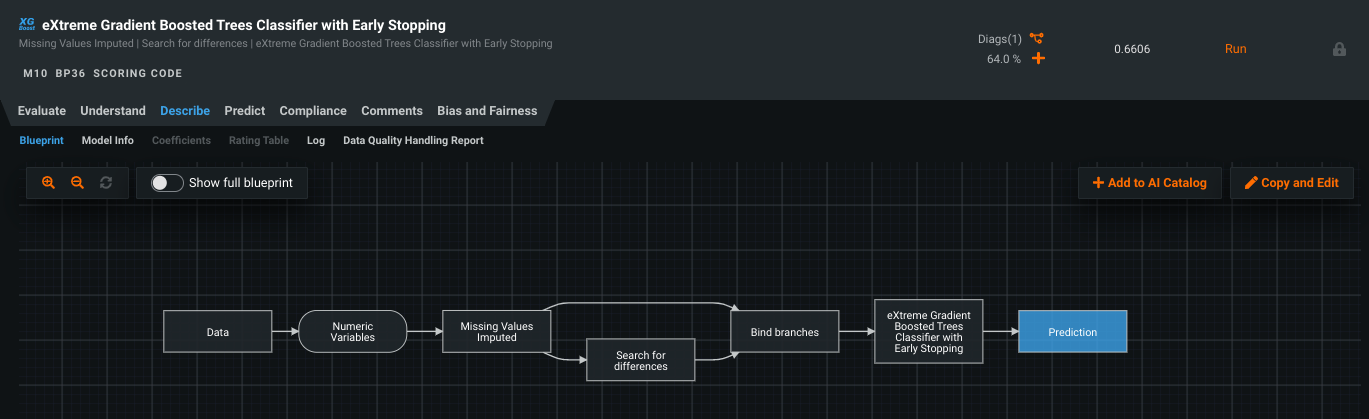
However, the original modeling algorithm often contains many more “branches,” which DataRobot prunes when they are not applicable to the project data and feature list. Now, you can toggle to see a detailed view while in read-only mode. Prior to the introduction of this feature, viewing the full blueprint required entering edit mode of the blueprint editor.

Required feature flag: Enable Blueprint Detailed View Toggle
API enhancements¶
The following is a summary of API new features and enhancements. Go to the API Documentation home for more information on each client.
Tip
DataRobot highly recommends updating to the latest API client for Python and R.
Calculate Feature Impact for each backtest¶
Feature Impact provides a transparent overview of a model, especially in a model's compliance documentation. Time-dependent models trained on different backtests and holdout partitions can have different Feature Impact calculations for each backtest. Now generally available, you can calculate Feature Impact for each backtest using DataRobot's REST API, allowing you to inspect model stability over time by comparing Feature Impact scores from different backtests.
Deprecation announcements¶
Excel add-in removed¶
With deprecation announced in June, the existing DataRobot Excel Add-In is now removed from the product. Users who have already downloaded the add-in can continue using it, but it will not be supported or further developed.
USER/Open Source models deprecated and soon disabled¶
With this release, all models containing USER/Open source (“user”) tasks are deprecated. The exact process of deprecating existing models will be rolling out over the next few months and implications will be announced in subsequent releases. See the full announcement in the June Cloud Announcements.
Feature Fit insight disabled¶
The Feature Fit visualization has been disabled. Any existing projects will no longer show the option from the Leaderboard, and new projects will not create the chart. Organization admins can re-enable it for their users until the tool is removed completely. Use the Feature Effects insight in place of Feature Fit, as it provides the same output.
Auto-Tuned Word N-gram Text Modeler blueprints removed from the Leaderboard¶
With this release, Auto-Tuned Word N-gram Text Modeler blueprints are no longer run as part of Autopilot for binary classification, regression, and multiclass/multimodal projects. The modeler blueprints remain available in the repository. Currently, Light GBM (LGBM) models run these auto-tuned text modelers for each text column, and for each, a new blueprint is added to the Leaderboard. However, these Auto-Tuned Word N-gram Text Modelers are not correlated to the original LGBM model (i.e., modifying them does not affect the original LGBM model). Now, Autopilot creates a single, larger blueprint for all Auto-Tuned Word N-gram Text Modeler tasks instead of one for each text column. Note that this change has no backward-compatibility issues; it applies to new projects only.
Hadoop deployment and scoring removed¶
With this release, Hadoop deployment and scoring, including the Standalone Scoring Engine (SSE), is fully removed and unavailable.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.