January 2023¶
January 25, 2023
This page provides announcements of newly released features available in the managed AI Platform, with links to additional resources. With the January deployment, DataRobot's managed AI Platform deployment delivered the following new GA and preview features. From the release center you can also access:
In the spotlight¶
DataRobot Notebooks offer an enhanced code-first experience in the application. Notebooks play a crucial role in providing a collaborative environment, using a code-first approach, to accelerate the machine learning lifecycle. Reduce hundreds of lines of code, automate data science tasks, and accommodate custom code workflows specific to your business needs. See the full description below.

January release¶
The following table lists each new feature. See the deployment history for past feature announcements and also the deprecation notices, below.
Features grouped by capability
GA¶
Quick Autopilot mode improvements speed experimentation¶
With this month’s release, Quick Autopilot mode now uses a one-stage modeling process to build models and populate the Leaderboard in AutoML projects. In the new version of Quick, all models are trained at a max sample size—typically 64%. The specific number of Quick models run varies by project and target type. DataRobot selects which models to run based on a variety of criteria, including target and performance metric, but as its name suggests, chooses only models with relatively short training runtimes to support quicker experimentation. Note that to maximize runtime efficiency, DataRobot no longer automatically generates and fits the DR Reduced Features list. (Fitting the reduced list requires retraining models.)

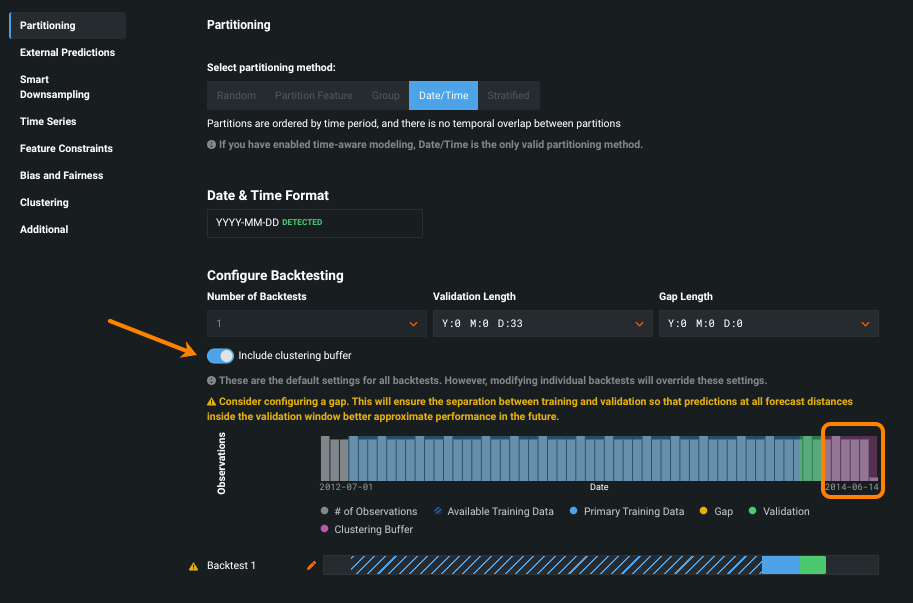
Time series clustering experience improvements¶
Initially released as generally available in September 2022, this release brings enhancements to time series clustering. Clustering enables you to easily group similar series to get a better understanding of your data or use them as input to time series segmented modeling. Clustering enhancements include:
-
A toggle to control the 10% clustering buffer if you aren’t using the result for segmented modeling.
-
Clarified project setup that removes extraneous feature lists and window setup.
-
Clustering models, and their resulting segmented models, use a uniform quantity of data for predictions (with the size based on the training size for the original clustering model).
Time series 5GB support¶
With this deployment, time series projects on the DataRobot managed AI Platform can support datasets up to 5GB. Previously the limit for time series projects on the cloud was 1GB. For more project- and platform-based information, see the dataset requirements reference.
Time series project cloning goes GA¶
Now generally available, you can duplicate ("clone") unsupervised, time series, OTV, and segmented modeling projects. Previously, this capability was only available for AutoML regression and classification projects. Use the duplication feature to copy just the dataset or a variety of project settings and assets for faster project experimentation.
Create AI Apps from models on the Leaderboard¶
You can now create No-Code AI Apps directly from trained models on the Leaderboard. To do so, select the model, click the new Build app tab, and select the template that best suits your use case.
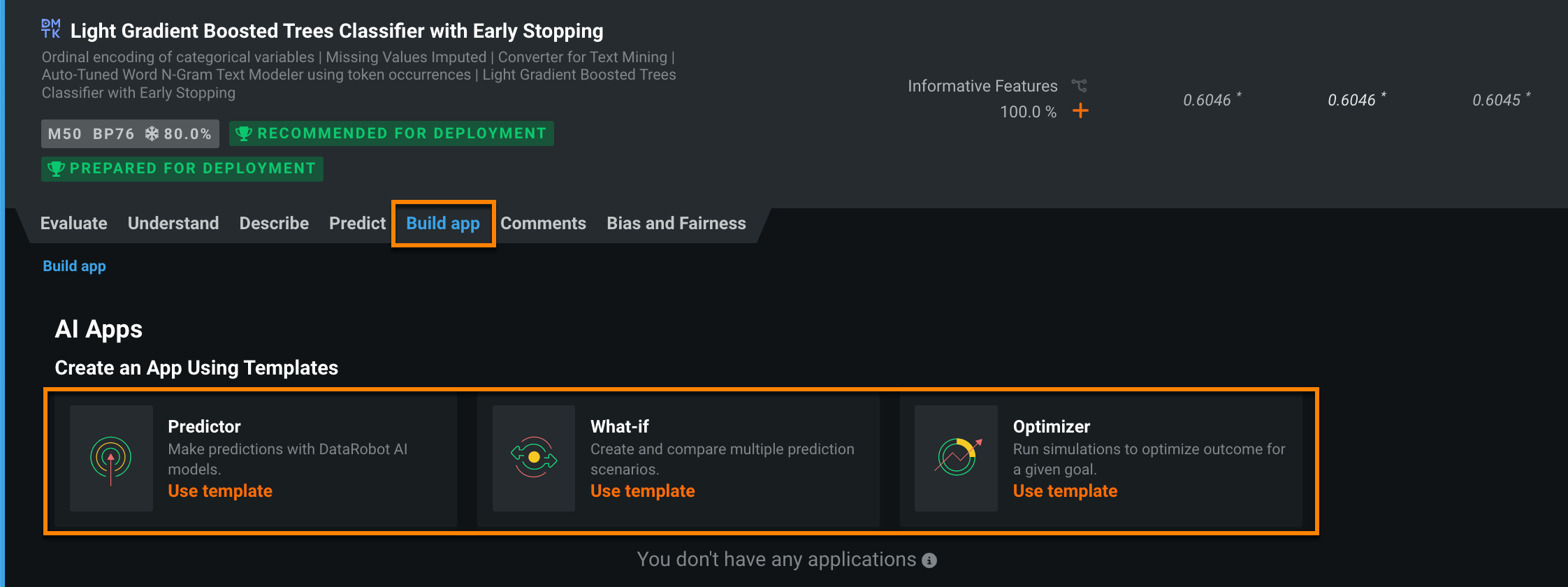
Then, name the application, select an access type, and click Create.

The new app appears in the Build app tab of the Leaderboard model as well as the Applications tab.
For more information, see the documentation for No-Code AI Apps.
Feature Discovery memory improvements¶
Feature discovery projects now use less memory, improving overall performance and reducing the risk of error.
Compliance documentation for models that don’t support null imputation¶
To generate the Sensitivity Analysis section of the default Automated Compliance Document template, your custom model must support null imputation (the imputation of NaN values), or compliance documentation generation will fail. If the custom model doesn't support null imputation, you can use a specialized template to generate compliance documentation. In the Report template dropdown list, select Automated Compliance Document (for models that do not impute null values). This template excludes the Sensitivity Analysis report and is only available for custom models. For more information, see information on generating compliance documentation.

Note
If this template option is not available for your version of DataRobot, you can download the custom template for regression models or the custom template for binary classification models.
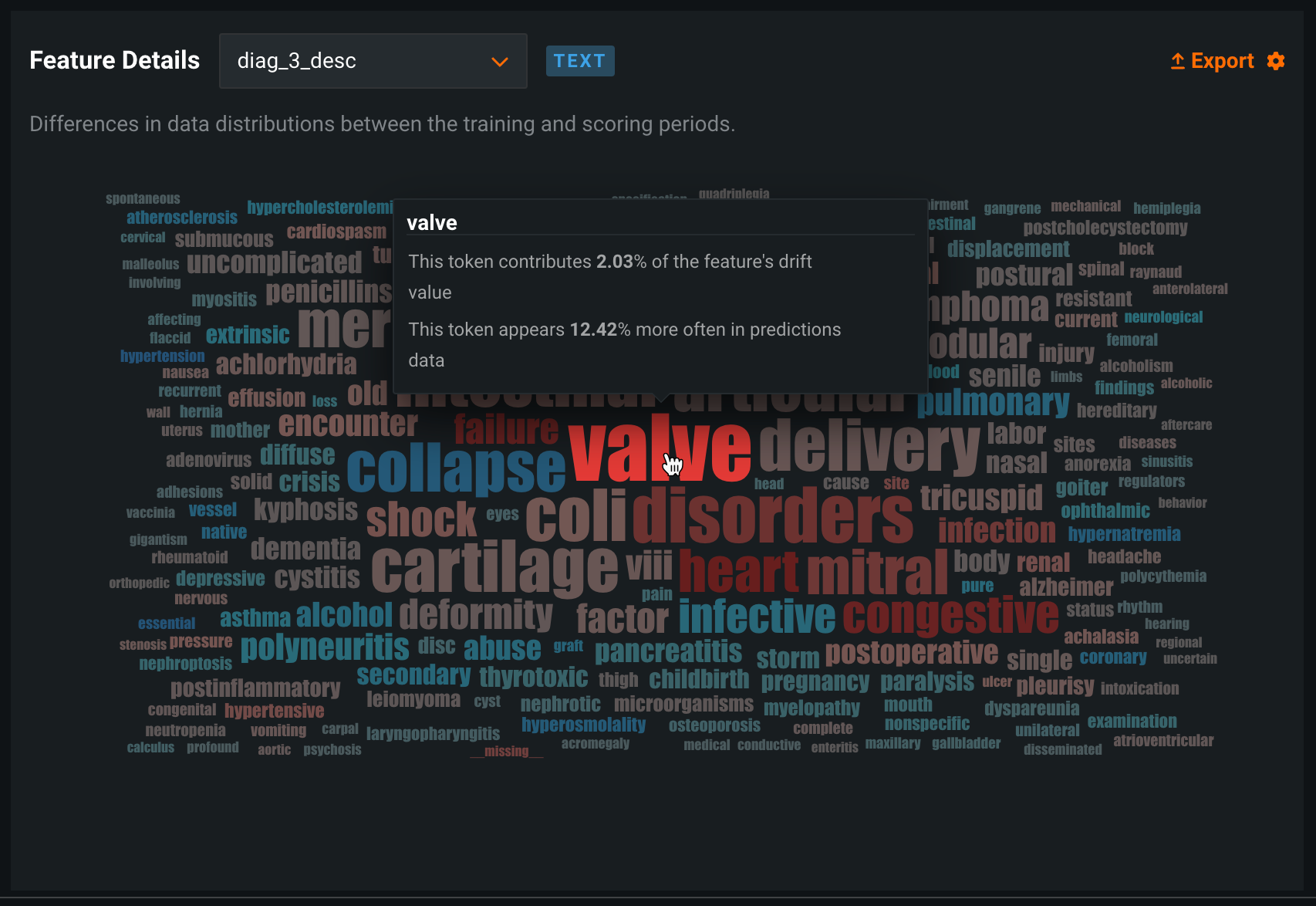
Feature drift word cloud for text features¶
The Feature Details chart plots the differences in a feature's data distribution between the training and scoring periods, providing a bar chart to compare the percentage of records a feature value represents in the training data with the percentage of records in the scoring data. For text features, the feature drift bar chart is replaced with a word cloud, visualizing data distributions for each token and revealing how much each individual token contributes to data drift in a feature.
To access the feature drift word cloud for a text feature, open the Data Drift tab of a drift-enabled deployment. On the Summary tab, in the Feature Details chart, select a text feature from dropdown list:
Note
Next to the Export button, you can click the settings icon (![]() ) and clear the Display text features as word cloud check box to disable the feature drift word cloud and view the standard chart:
) and clear the Display text features as word cloud check box to disable the feature drift word cloud and view the standard chart:

For more information, see the Feature Details chart’s Text features documentation.
MLOps deployment logs¶
On the new MLOps Logs tab, you can view important deployment events. These events can help diagnose issues with a deployment or provide a record of the actions leading to the current state of the deployment. Each event has a type and a status. You can filter the event log by event type, event status, or time of occurrence, and you can view more details for an event on the Event Details panel.
To access MLOps logs:
-
On a deployment's Service Health page, scroll to the Recent Activity section at the bottom of the page.
-
In the Recent Activity section, click MLOps Logs.
-
Under MLOps Logs, configure the log filters.
-
On the left panel, the MLOps Logs list displays deployment events with any selected filters applied. For each event, you can view a summary that includes the event name and status icon, the timestamp, and an event message preview.
-
Click the event you want to examine and review the Event Details panel on the right.
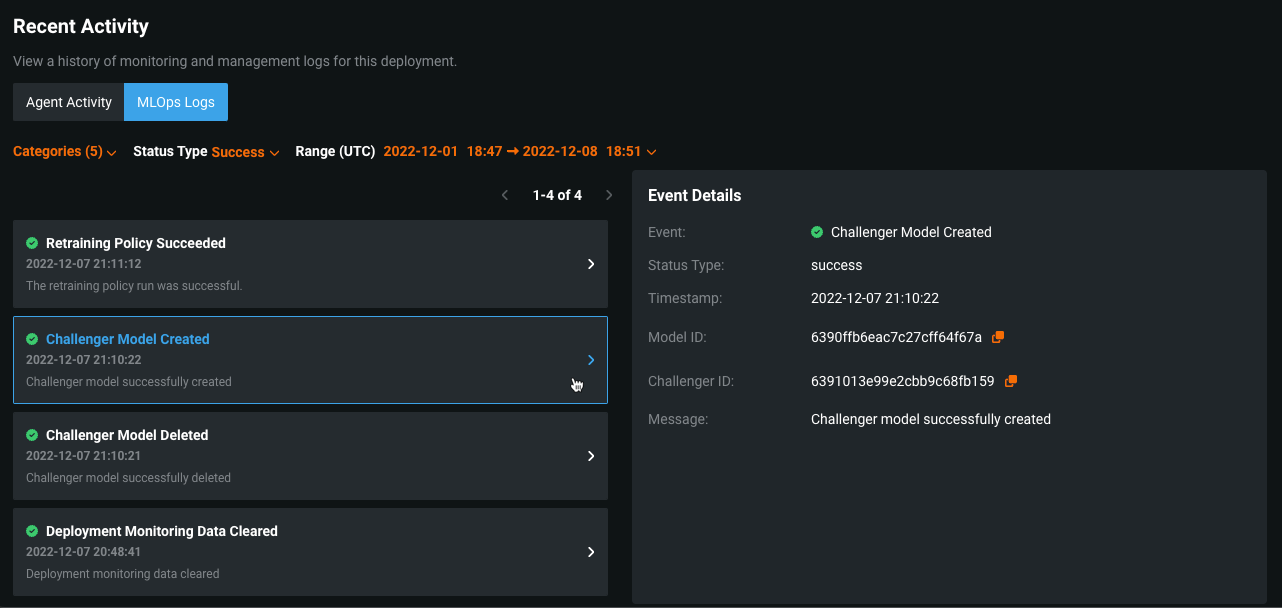
For more information, see the Service Health tab’s View MLOps Logs documentation.
Preview¶
DataRobot Notebooks¶
The DataRobot application now includes an in-browser editor to create and execute notebooks for data science analysis and modeling. Notebooks display computation results in various formats, including text, images, graphs, plots, tables, and more. You can customize output display by using open-source plugins. Cells can also contain Markdown rich text for commentary and explanation of the coding workflow. As you develop and edit a notebook, DataRobot stores a history of revisions that you can return to at any time.
DataRobot Notebooks offer a dashboard that hosts notebook creation, upload, and management. Individual notebooks have containerized, built-in environments with commonly used machine learning libraries that you can easily set up in a few clicks. Notebook environments seamlessly integrate with DataRobot's API, allowing a robust coding experience supported by keyboard shortcuts for cell functions, in-line documentation, and saved environment variables for secrets management and automatic authentication.

Preview documentation.
Batch predictions for TTS and LSTM models¶
Traditional Time Series (TTS) and Long Short-Term Memory (LSTM) models— sequence models that use autoregressive (AR) and moving average (MA) methods—are common in time series forecasting. Both AR and MA models typically require a complete history of past forecasts to make predictions. In contrast, other time series models only require a single row after feature derivation to make predictions. Previously, batch predictions couldn't accept historical data beyond the effective feature derivation window (FDW) if the history exceeded the maximum size of each batch, while sequence models required complete historical data beyond the FDW. These requirements made sequence models incompatible with batch predictions. Enabling this preview feature removes those limitations to allow batch predictions for TTS and LSTM models.
Time series Autopilot still doesn't include TTS or LSTM model blueprints; however, you can access the model blueprints in the model Repository.
To allow batch predictions with TTS and LSTM models, this feature:
-
Updates batch predictions to accept historical data up to the maximum batch size (equal to 50MB or approximately a million rows of historical data).
-
Updates TTS models to allow refitting on an incomplete history (if the complete history isn't provided).
If you don't provide sufficient forecast history at prediction time, you could encounter prediction inconsistencies. For more information on maintaining accuracy in TTS and LSTM models, see the prediction accuracy considerations.
With this feature enabled, you can access the Predictions > Make Predictions and Predictions > Job Definitions tabs of a deployed TTS or LSTM model.
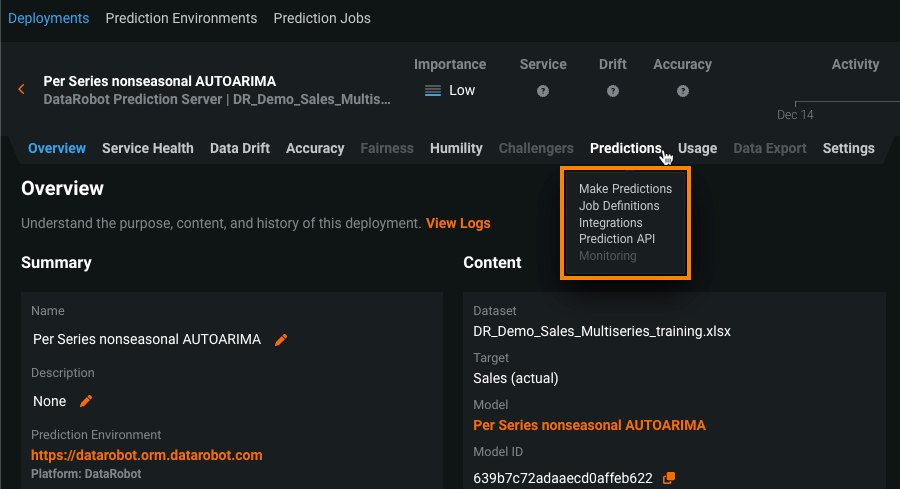
Required feature flag: Enable TTS and LSTM Time Series Model Batch Predictions
Preview documentation.
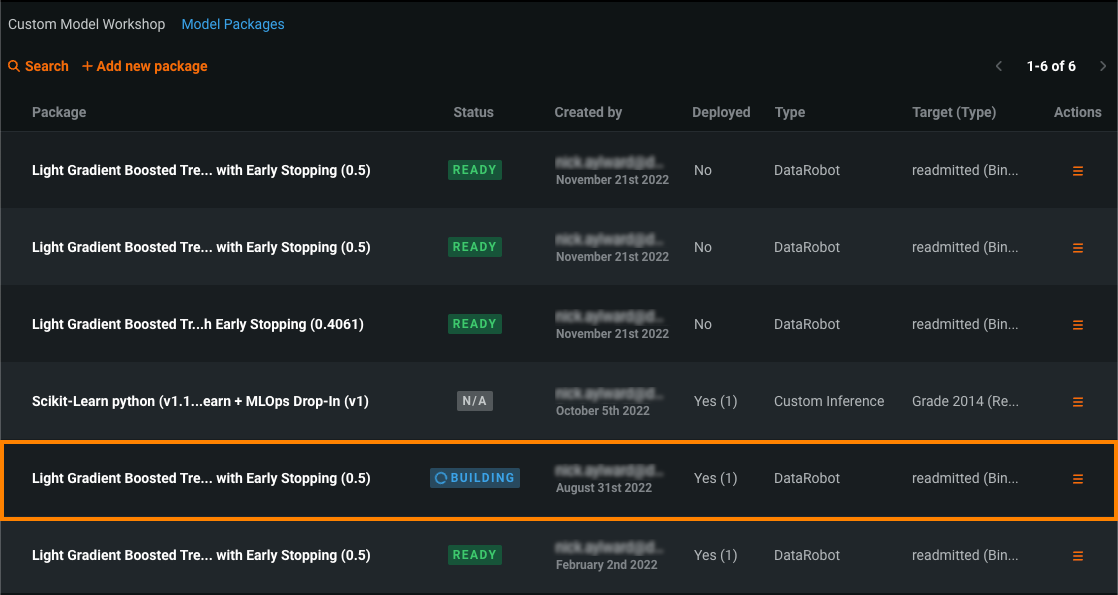
Model package artifact creation workflow¶
Now available as a preview feature, the improved model package artifact creation workflow provides a clearer and more consistent path to model deployment with visible connections between a model and its associated model packages in the Model Registry. Using this new approach, when you deploy a model, you begin by providing model package details and adding the model package to the Model Registry. After you create the model package and allow the build to complete, you can deploy it by adding the deployment information.
-
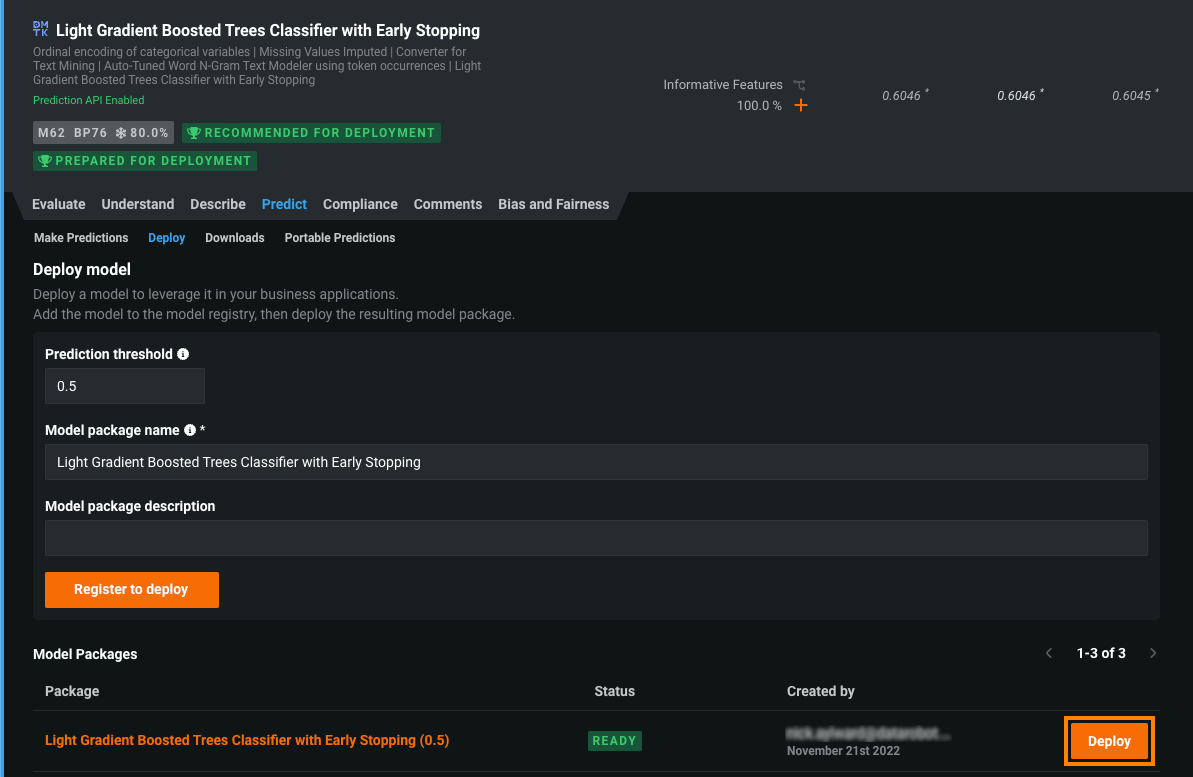
From the Leaderboard, select the model to use for generating predictions and then click Predict > Deploy. To follow best practices, DataRobot recommends that you first prepare the model for deployment. This process runs Feature Impact, retrains the model on a reduced feature list, and trains on a higher sample size, followed by the entire sample (latest data for date/time partitioned projects).
-
On the Deploy model tab, provide the required model package information, and then click Register to deploy.
-
Allow the model to build. The Building status can take a few minutes, depending on the size of the model. A model package must have a Status of Ready before you can deploy it.

-
In the Model Packages list, locate the model package you want to deploy and click Deploy.
-
Click Model Registry > Model Packages.
-
Click the Actions menu for the model package you want to deploy, and then click Deploy.
The Status column shows the build status of the model package.
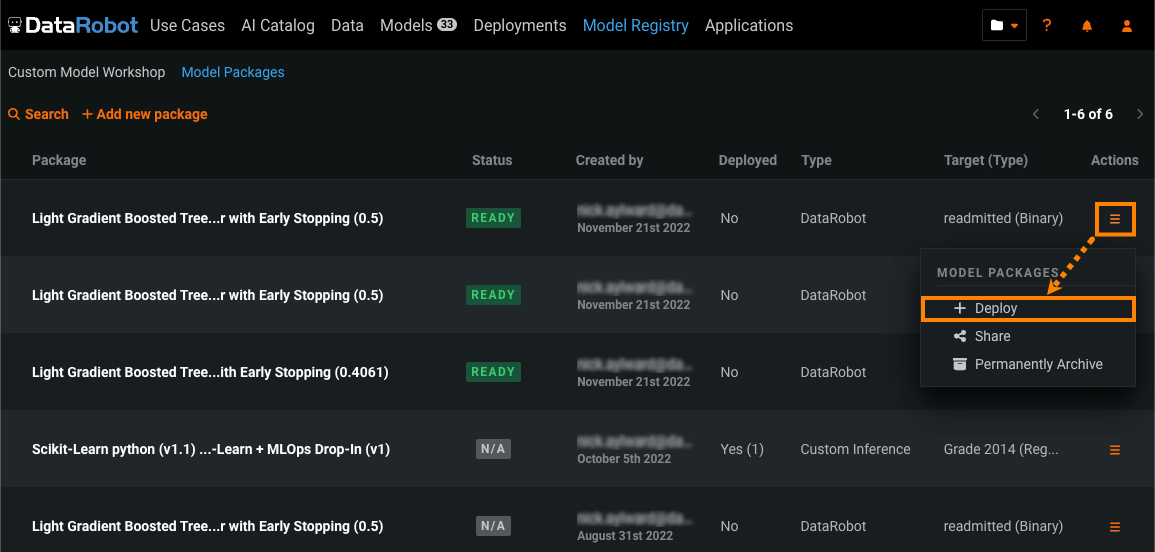
If you deploy a model package that has a Status of N/A, the build process starts:
Tip
You can also open a model package from the Model Registry and deploy it from Package Info tab.
For more information, see the Model Registry documentation.
GitHub Actions for custom models¶
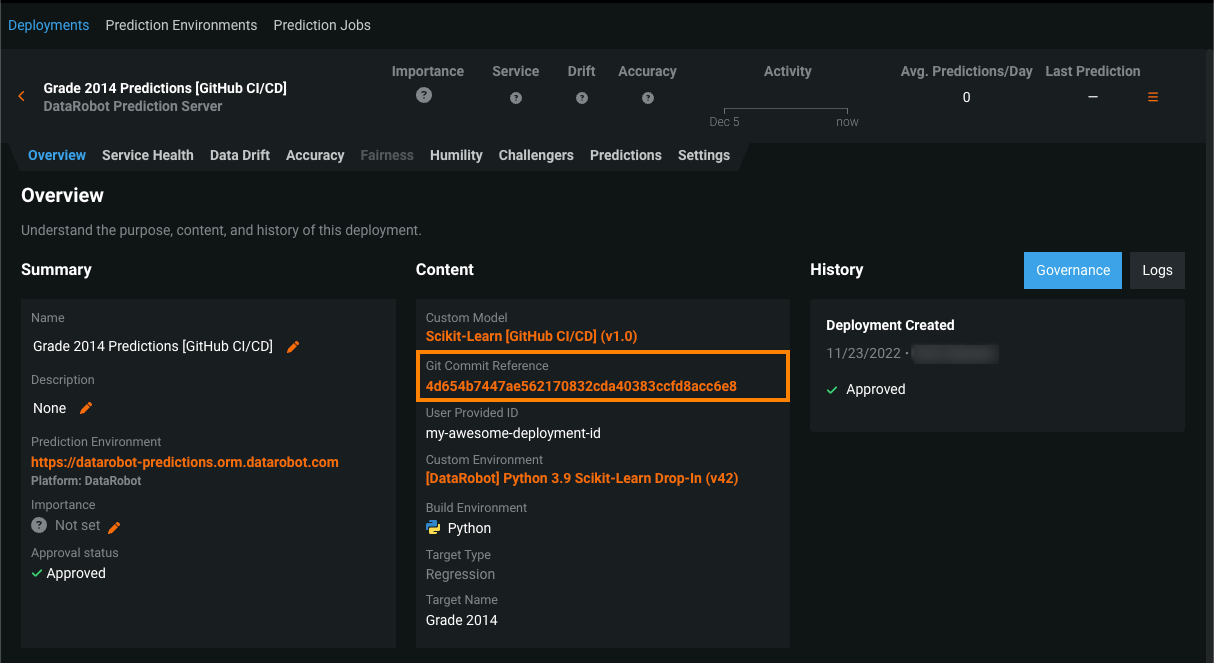
The custom models action manages custom inference models and their associated deployments in DataRobot via GitHub CI/CD workflows. These workflows allow you to create or delete models and deployments and modify settings. Metadata defined in YAML files enables the custom model action's control over models and deployments. Most YAML files for this action can reside in any folder within your custom model's repository. The YAML is searched, collected, and tested against a schema to determine if it contains the entities used in these workflows. For more information, see the custom-models-action repository. A quickstart example, provided in the documentation, uses a Python Scikit-Learn model template from the datarobot-user-model repository.
After you configure the workflow and create a model and a deployment in DataRobot, you can access the commit information from the model's version info and package info and the deployment overview:


Required feature flag: Enable Custom Model GitHub CI/CD
For more information, see the GitHub Actions for custom models documentation.
Deprecation announcements¶
Current status of Python 2 deprecation and removal¶
As of the January 2023 release, the following describes the state of the Python 2 removal:
-
Python 2 has been completely removed from the platform.
-
All Python 2 projects are disabled and compute workers are no longer able to process Python 2-related jobs.
-
All Python 2 deployments are now disabled and will, unless managed under an DataRobot-implemented individualized migration plan, return a HTTP 405 response to prediction requests.
-
The Portable Prediction Server (PPS) image no longer contains Python 2 and is not capable of serving Python 2 models using dual inference mode. The PPS image will only serve prediction requests for Python 3 models.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.