March 2023¶
March 22, 2023
This page provides announcements of newly released features available in DataRobot's SaaS single- and multi-tenant AI Platform, with links to additional resources. With the March deployment, DataRobot's AI Platform delivered the following new GA and preview features. From the release center you can also access:
March release¶
The following table lists each new feature. See the deployment history for past feature announcements.
Features grouped by capability
| Name | GA | Preview |
|---|---|---|
| Data | ||
| New driver versions | ✔ | |
| Modeling | ||
| Reduced feature lists restored in Quick Autopilot mode | ✔ | |
| Details page added to time series applications | ✔ | |
| Increased prediction limit for No-Code AI Apps | ✔ | |
| Predictions and MLOps | ||
| Assign training data to a custom model version | ✔ | |
| API enhancements | ||
| Python client v3.1 | ✔ | |
GA¶
Reduced feature lists restored in Quick Autopilot mode¶
With this release, Quick mode now reintroduces creating a reduced feature list when preparing a model for deployment. In January, DataRobot made Quick mode enhancements for AutoML; in February, the improvement was made available for time series projects. At that time, DataRobot stopped automatically generating and fitting the DR Reduced Features list, as fitting required retraining models. Now, based on user requests, when recommending and preparing a model for deployment, DataRobot once again creates the reduced feature list. The process, however, does not include model fitting. To apply the list to the recommended model—or any Leaderboard model—you can manually retrain it.
Details page added to time series applications¶
In the Time Series Forecasting widget, you can now view prediction information for specific predictions or dates, allowing you to not only see the prediction values, but also compare them to other predictions that were made for the same date.
To drill down into the prediction details, click on a prediction in either the Predictions vs Actuals or Prediction Explanations chart. This opens the Forecast details page, which displays the following information:


| Description | |
|---|---|
| 1 | The average prediction value in the forecast window. |
| 2 | Up to 10 Prediction Explanations for each prediction. |
| 3 | Segmented analysis for each forecast distance within the forecast window. |
| 4 | Prediction Explanations for each forecast distance included in the segmented analysis. |
New driver versions¶
With this release, the following driver versions have been updated:
- AWS Athena==2.0.35
- SAP Hana==2.15.10
See the complete list of supported driver versions in DataRobot.
Assign training data to a custom model version¶
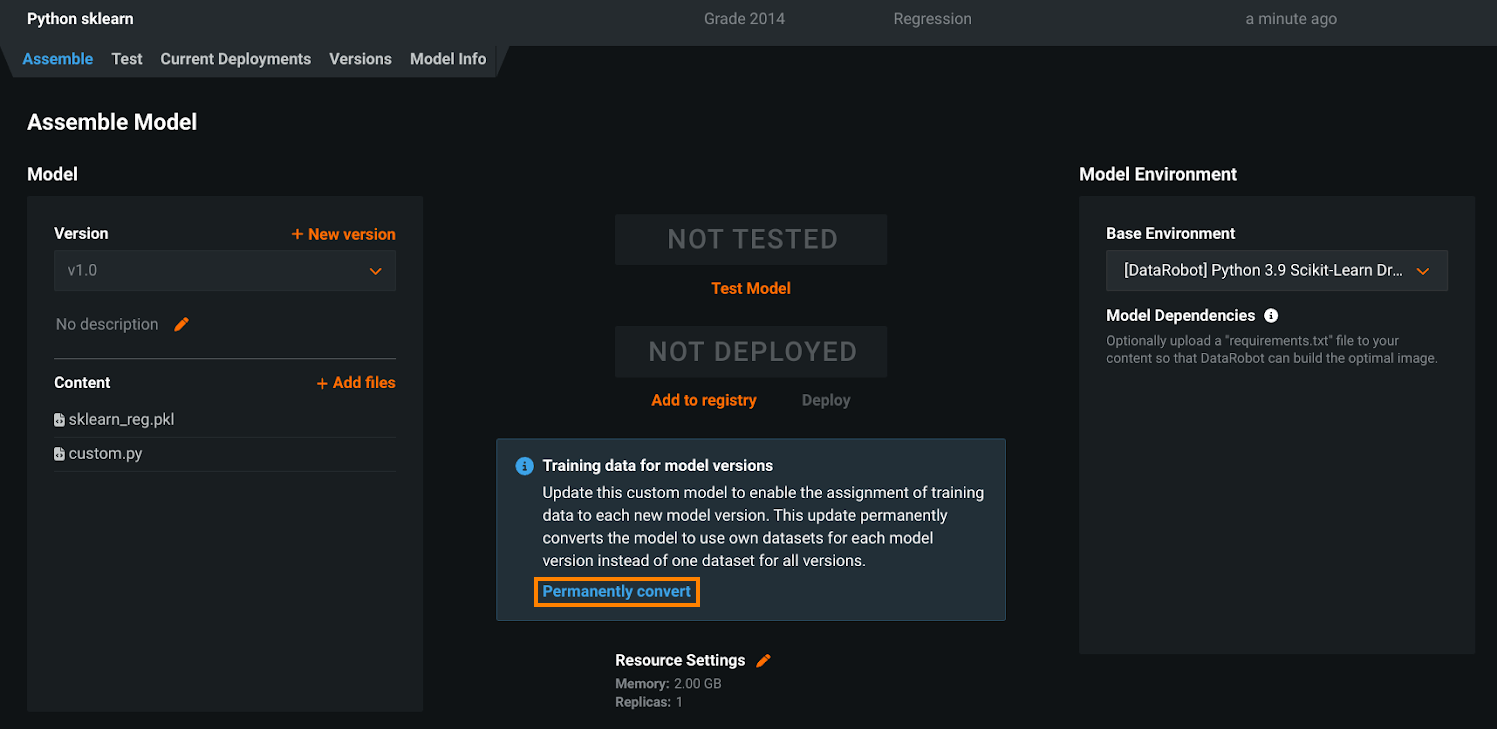
To enable feature drift tracking for a custom model deployment, you must add training data. Currently, when you add training data, you assign it directly to the custom model. As a result, every version of that model uses the same data. In this release, the assignment of training data directly to a custom model is deprecated and scheduled for removal, replaced by the assignment of training data to each custom model version. To support backward compatibility, the deprecated method of training data assignment remains the default during the deprecation period, even for newly created models.
To assign training data to a custom model's versions, you must convert the model. On the Assemble tab, locate the Training data for model versions alert and click Permanently convert:
Warning
Converting a model's training data assignment method is a one-way action. It cannot be reverted. After conversion, you can't assign training data at the model level. This change applies to the UI and the API. If your organization has any automation depending on "per model" training data assignment, before you convert a model, you should update any related automation to support the new workflow. As an alternative, you can create a new custom model to convert to the "per version" training data assignment method and maintain the deprecated "per model" method on the model required for the automation; however, you should update your automation before the deprecation process is complete to avoid gaps in functionality.
After you convert the model, you can assign training data to a custom model version:
-
If the model was already assigned training data, the Datasets section contains information about the existing training dataset. To replace existing training data, click the edit icon (
 ). In the Change Training Data dialog box, click the delete icon (
). In the Change Training Data dialog box, click the delete icon ( ) to remove the existing training data, then upload new training data.
) to remove the existing training data, then upload new training data. -
If the model version doesn't have training data assigned, click Assign, then, in the Add Training Data dialog box, upload training data.
When you create a new custom model version, you can Keep training data from previous version. This setting is enabled by default to bring the training data from the current version to the new custom model version:
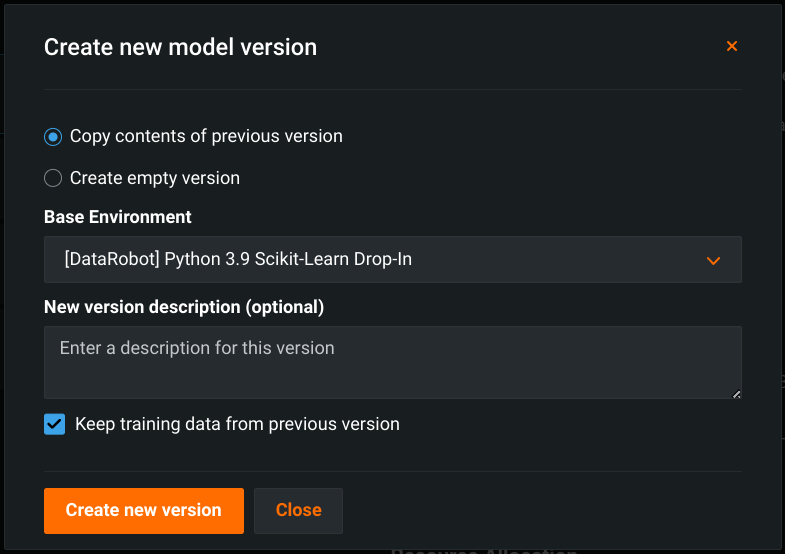
For more information, see Add training data to a custom model and Add custom model versions.
Preview¶
Increased prediction limit for No-Code AI Apps¶
Now available for preview, you can make up to 50K predictions in an application. Previously, and without the flag enabled, applications supported only 5K predictions. With or without the flag, a message will indicate how many predictions remain. Note that the limit applies to individual apps, not to individual users. This means that if you share the app, any predictions that a user makes are deducted from the remainder.
Required feature flag: Enable Increased Prediction Row Limit
API enhancements¶
Python client v3.1¶
The following API enhancements are introduced with version 3.1 of DataRobot's Python client:
-
Added new methods
BatchPredictionJob.apply_time_series_data_prep_and_scoreandBatchPredictionJob.apply_time_series_data_prep_and_score_to_filethat apply time series data prep to a file or dataset and make batch predictions with a deployment. -
Added new methods
DataEngineQueryGenerator.prepare_prediction_datasetandDataEngineQueryGenerator.prepare_prediction_dataset_from_catalogthat apply time series data prep to a file or catalog dataset and upload the prediction dataset to a project. -
Added new
max_waitparameter to the methodProject.create_from_dataset. Values larger than the default can be specified to avoid timeouts when creating a project from a dataset. -
Added the
Project.create_segmented_project_from_clustering_modelmethod for creating a segmented modeling project from an existing clustering project and model. Switch to this function if you were previously using ModelPackage for segmented modeling purposes. -
Added the
is_unsupervised_clustering_or_multiclassmethod for checking whether clustering or multiclass parameters are used. It is quick and efficient without extra API calls. -
Added value
PREPARED_FOR_DEPLOYMENTto theRECOMMENDED_MODEL_TYPEenum. -
Added two new methods to the
ImageAugmentationListclass:ImageAugmentationList.listandImageAugmentationList.update. -
Added
formatkey to Batch Prediction intake and output settings for S3, GCP and Azure. -
The method
PredictionExplanations.is_multiclassnow adds an additional API call to check for multiclass target validity, which adds a small delay. -
The
AdvancedOptionsparameterblend_best_modelsnow defaults to false. -
The
AdvancedOptions <datarobot.helpers.AdvancedOptions>parameterconsider_blenders_in_recommendationnow defaults to false. -
DatetimePartitioningnow has the parameterunsupervised_mode.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.