June 2022¶
June 28, 2022
With the latest deployment, DataRobot's managed AI Platform deployment delivered the following new GA and preview features. See the deployment history for past feature announcements. See also:
Features grouped by capability
GA¶
“Uncensored” blueprints now available to all users¶
Previously, depending on an organization’s configuration, DataRobot users had visibility to either censored or uncensored blueprints. The difference between the settings was reflected in the preprocessing details shown in a model’s Blueprint tab (the graphical representation of the data preprocessing and parameter settings). With this release, all users will be able to see the specific algorithms DataRobot uses. (Note that there is no functional change for those who already have uncensored blueprints.)
Additional capabilities with uncensored blueprints:
- More options from within Composable ML.
- Access to the Data Quality Handling Report.
- More complete model documentation (by clicking DataRobot Model docs from inside the blueprint’s tasks).
Improved join feature type compatibility in Feature Discovery¶
In Feature Discovery projects, you can now join secondary datasets using columns of different types. Previously, columns had to be the same type to execute a join.
For information on join compatibility, see the Feature Discovery documentation.
Feature Discovery explores Latest features within an FDW by default¶
As part of the Feature Discovery process, DataRobot now defaults to a new setting, Latest within window, when performing feature engineering. This new setting explores Latest values within the defined feature discovery window (FDW), as opposed to Latest, which generates Latest values by exploring all historical data up until the end point of any defined FDWs. You can change the default settings in Feature Discovery Settings > Feature Engineering.

For more information, see the Feature Discovery documentation.
New Leaderboard and Repository filtering options¶
With this release, you can now limit the Leaderboard or Repository to display models/blueprints matching the selected filters. Leaderboard filters allow you to set options categorized as: sample size—or for time series projects, training period—model family, model characteristics, feature list, and more. Repository filtering includes blueprint characteristics, families, and types. The new, enhanced filtering options are centralized in a single modal (one for the Leaderboard and one for the Repository), where previously, the more limited methods for filtering were in separate locations.
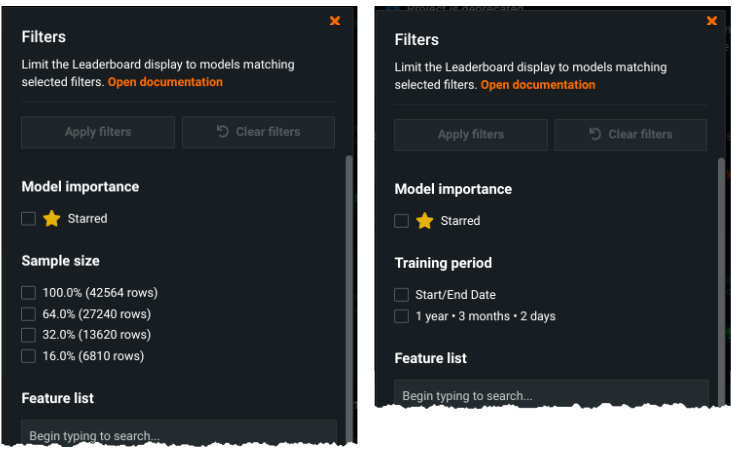
See the Leaderboard reference for more information.
Multiclass Prediction Explanations for XEMP¶
Now generally available, DataRobot calculates explanations for each class in an XEMP-based multiclass classification project, both from the Leaderboard and from deployments. With multiclass, you can set the number of classes to compute for as well as select a mode from predicted or actual (if using training data) results or specify to see only a specific set of classes.

See the section on XEMP Prediction Explanations for Multiclass for more information.
New metric support for segmented projects¶
Combined Models, the main umbrella project that acts as a collection point for all segments in a time series segmented modeling project, introduces support for RMSE-based metrics. In addition to earlier support for MAD, MAE, MAPE, MASE, and SMAPE, segmented projects now also support RMSE, RMSLE, and Theil’s U (weighted and unweighted).
Native Prophet and Series Performance blueprints¶
For time series projects, support for native Prophet, ETS, and TBATS models for single and multiseries projects is now generally available. A detailed model description can be found for each model by accessing the model blueprint.
Autoexpansion of time series input in Prediction API¶
When making predictions with time series models via the API using a forecast point, you can now skip the forecast window in your prediction data. DataRobot generates a forecast point automatically via autoexpansion. Autoexpansion applies automatically if predictions are made for a specific forecast point and not a forecast range. It also applies if a time series project has a regular time step and does not use Nowcasting.
MLOps management agent¶
Now generally available, the MLOps management agent provides a standard mechanism for automating model deployments in any type of environment or infrastructure. The management agent supports models trained on DataRobot, or models trained with open source tools on external infrastructure. The agent, accessed from the DataRobot application, ships with an assortment of example plugins that support custom configurations. Use the management agent to automate the deployment and monitoring of models to ensure your machine learning pipeline is healthy and reliable. This release introduces usability improvements to the management agent, including deployment status reporting, deployment relaunch, and the option to force the deletion of a management agent deployment.
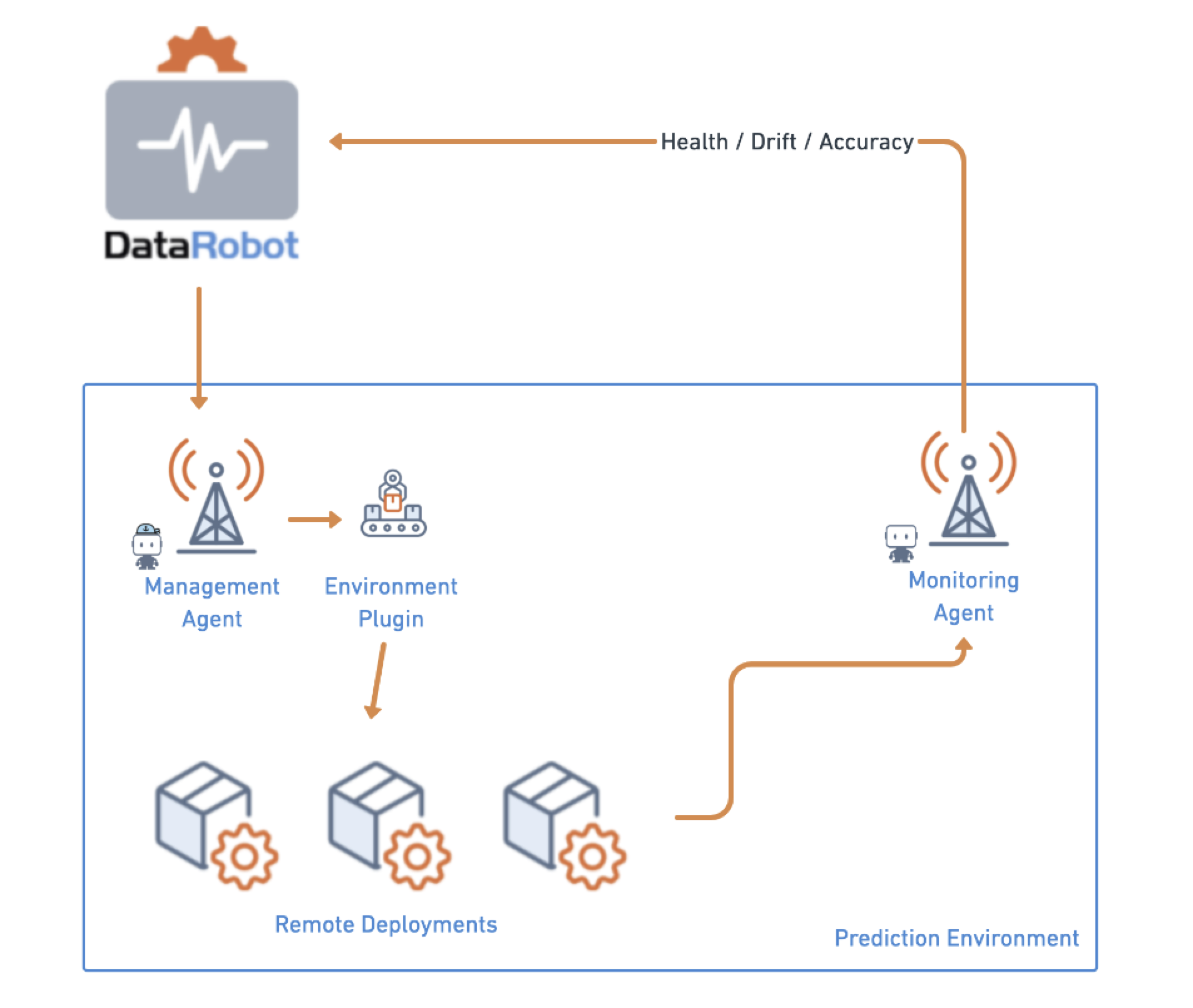
For more information on agent installation, configuration, and operation, see the MLOps management agent documentation.
Large-scale monitoring with the MLOps library¶
To support large-scale monitoring, the MLOps library provides a way to calculate statistics from raw data on the client side. Then, instead of reporting raw features and predictions to the DataRobot MLOps service, the client can report anonymized statistics without the feature and prediction data. Reporting prediction data statistics calculated on the client side is the optimal method compared to reporting raw data, especially at scale (with billions of rows of features and predictions). In addition, because client-side aggregation only sends aggregates of feature values, it is suitable for environments where you don't want to disclose the actual feature values.
The large-scale monitoring functionality is available for the Java Software Development Kit (SDK) and the MLOps Spark Utils Library:
Replace calls to reportPredictionsData() with calls to reportAggregatePredictionsData().
Replace calls to reportPredictions() with calls to predictionStatisticsParameters.report().
You can find an example of this use-case in the agent .tar file in examples/java/PredictionStatsSparkUtilsExample.
Note
To support the use of challenger models, you must send raw features. For large datasets, you can report a small sample of raw feature and prediction data to support challengers and reporting; then, you can send the remaining data in aggregate format.
This use case can be found in the Monitoring agent use case documentation.
MLOps Java library and agent public release¶
You can now download the MLOps Java library and agent from the public Maven Repository with a groupId of com.datarobot and an artifactId of datarobot-mlops (library) and mlops-agent (agent). In addition, you can access the DataRobot MLOps Library and DataRobot MLOps Agent artifacts in the Maven Repository to view all versions and download and install the JAR file.
MLOps monitoring agent event log¶
Now generally available, on a deployment's Service Health tab, under Recent Activity, you can view Management events (e.g., deployment actions) and Monitoring events (e.g., spooler channel and rate limit events). Monitoring events can help you quickly diagnose MLOps agent issues. For example, spooler channel error events can help you diagnose and fix spooler configuration issues while rate limit enforcement events can help you identify if service health stats or data drift and accuracy values aren't updating because you exceeded the API request rate limit.
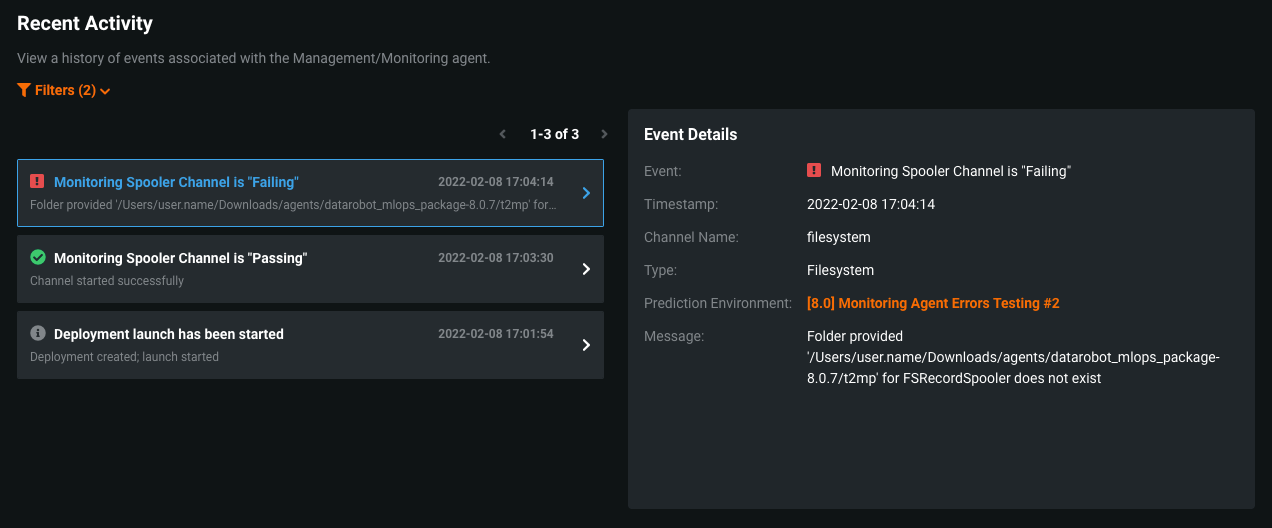
To view Monitoring events, you must provide a predictionEnvironmentID in the agent configuration file (conf\mlops.agent.conf.yaml). If you haven't already installed and configured the MLOps agent, see the Installation and configuration guide.
For more information on enabling and reading the monitoring agent event log, see the Monitoring agent event log documentation.
Prediction API cURL scripting code¶
The Prediction API Scripting Code section on a deployment's Predictions > Prediction API tab now includes a cURL scripting code snippet for Real-time predictions. cURL is a command-line tool for transferring data using various network protocols, available by default in most Linux distributions and macOS.
For more information on Prediction API cURL scripting code, see the Real-time prediction snippets documentation.
Preview¶
Multiclass support in No-Code AI Apps¶
In addition to binary classification and regression problems, No-Code AI Apps now support multiclass classification deployments across all three templates—Predictor, Optimizer, and What-if. This gives you the ability to leverage No-Code AI Apps for a broader range of business problems across several industries, thus expanding its benefits and value.
Required feature flag: Enable Application Builder Multiclass Support
Deployment for time series segmented modeling¶
Now available for preview, to fully leverage the value of segmented modeling, you can deploy Combined Models as you would deploy any other time series models. After selecting the champion model for each included project, you can deploy the Combined Model to bring predictions into production. Creating a deployment allows you to use DataRobot MLOps for accuracy monitoring, prediction intervals, and challenger models.
Note
Time series segmented modeling deployments do not support data drift monitoring, prediction explanations, or retraining.
Deploy a time series Combined Model¶
After you complete the segmented modeling workflow, you can deploy the resulting Combined Model to bring its predictions into production. Once Autopilot has finished, the Models > Leaderboard tab contains one model. This model is the completed Combined Model. To deploy, click the Combined Model, click Predict > Deploy, and then click Deploy model.
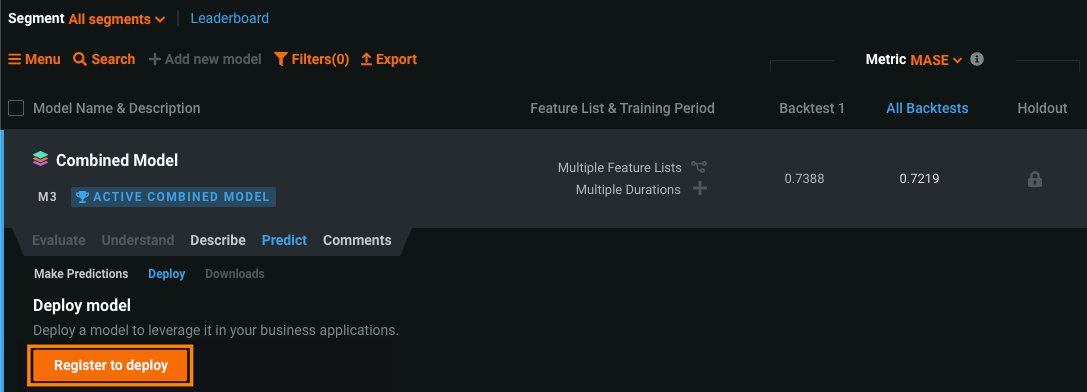
Modify and clone a deployed Combined Model¶
When a Combined Model is deployed, to change the segment champion for a segment, you must clone the deployed Combined Model and modify the cloned model. This process is automatic and occurs when you attempt to change a segment's champion within a deployed Combined Model. The cloned model you can modify becomes the Active Combined Model. This process ensures stability in the deployed model while allowing you to test changes within the same segmented project.
Note
Only one Combined Model in a project can be the Active Combined Model (marked with a badge).
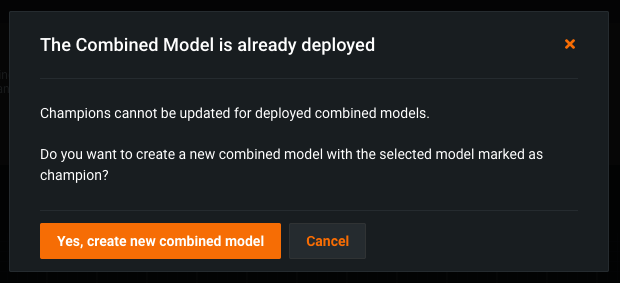
Once a Combined Model is deployed, it is labeled Prediction API Enabled. To modify this model, click the active and deployed Combined Model, and then in the Segments tab, click the segment you want to modify.

Next, reassign the segment champion, and in the dialog box that appears, click Yes, create new combined model.
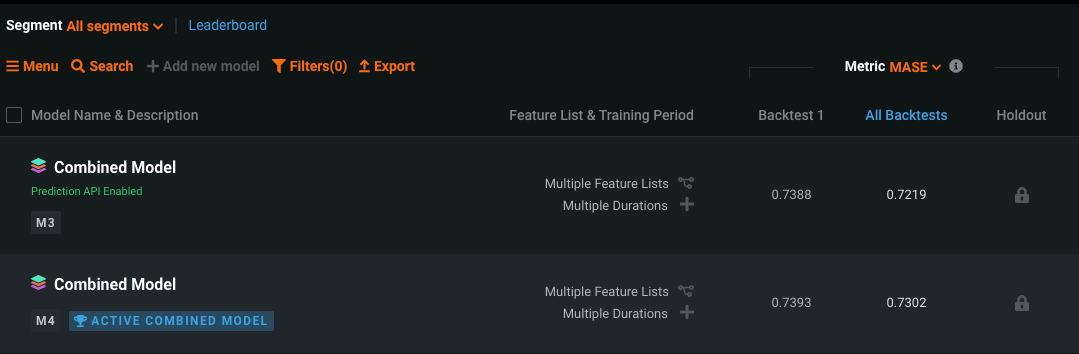
On the segment's Leaderboard, you can now access and modify the Active Combined Model.
Required feature flag: Enable Time Series Segmented Deployments Support
Segmented modeling documentation.
API enhancements¶
The following is a summary of API new features and enhancements. Go to the API Documentation home for more information on each client.
Tip
DataRobot highly recommends updating to the latest API client for Python and R.
Access DataRobot REST API documentation from docs.datarobot.com¶
DataRobot now offers REST API documentation available directly from the public documentation hub. Previously, REST API docs were only accessible through the application. Now, you can access information about REST endpoints and parameters in the API reference section of the public documentation site.
Preview: Set default credentials in the credential store¶
For a given resource in the credential store, you can make associated credentials the default set. When calling the REST API directly, you can request the default credentials using the newly implemented API routes for credential associations:
PUT /api/v2/credentials/(credentialId)/associations/(associationId)/GET /api/v2/credentials/associations/(associationId)/
Deprecation announcements¶
Auto-Tuned Word N-gram Text Modeler blueprints removed from Leaderboard¶
On July 6, 2022, Auto-Tuned Word N-gram Text Modeler blueprints will no longer be run as part of Autopilot for binary classification, regression, and multiclass/multimodal projects. The modeler blueprints will remain available in the repository. Currently, Light GBM (LGBM) models run these auto-tuned text modelers for each text column, and for each, a new blueprint is added to the Leaderboard. However, these Auto-Tuned Word N-gram Text Modelers are not correlated to the original LGBM model (i.e., modifying them does not affect the original LGBM model). Once disabled, Autopilot will create a single, larger blueprint for all Auto-Tuned Word N-gram Text Modeler tasks instead of one for each text column. Note that this change has no backward-compatibility issues; it applies to new projects only.
Feature Fit insight to be disabled in July¶
Beginning in July 2022, the Evaluate > Feature Fit insight will be disabled. Any existing projects will no longer show the option from the Leaderboard, and new projects will not create the chart. Organization admins will be able to re-enable it for their users until the tool is removed completely. The Feature Effects insight can be used in place of Feature Fit, as it provides the same output.
USER/Open Source models deprecated and soon disabled¶
With this release, all models containing USER/Open source (“user”) tasks are deprecated. The exact process of deprecating existing models will be rolling out over the next few months and implications will be announced in subsequent releases.
Identifying affected models
To determine whether your model is deprecated, you can open the blueprint where you will see the task name:
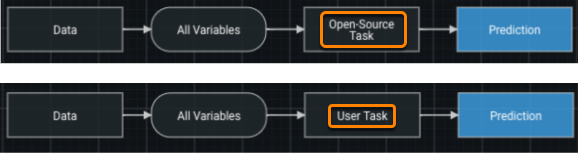
Additionally, you can see the task listed in the model description on the Leaderboard.
DataRobot is making this change now because Composable ML allows you to create custom models instead of using a USER model. Separately, there are native solutions for all currently supported Open source models. Eliminating and replacing existing USER/Open Source models addresses any potential security concerns.
At this time, any users who have generated predictions (via the Leaderboard or a deployment) with the deprecated models in the last 6 months have been contacted and provided with a migration plan. If you believe you use such models for predictions and have not been contacted, get in touch with your DataRobot representative.
Excel add-in deprecated, to be removed July 2022¶
The existing DataRobot Excel Add-In is deprecated and will be removed in July 2022. Although users who have already downloaded it can continue using the add-in, it will not be supported or further developed. If you need the add-in, you can download it until July 20, 2022.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.