MLOps and predictions (V10.2)¶
November 21, 2024
The DataRobot MLOps v10.2 release includes many new features and capabilities, described below. See additional details of Release 10.2 in:
10.2 release¶
Features grouped by capability
* Premium
Predictions and MLOps¶
GA¶
Evaluation and moderation for text generation models¶
Evaluation and moderation guardrails help your organization block prompt injection and hateful, toxic, or inappropriate prompts and responses. It can also prevent hallucinations or low-confidence responses and, more generally, keep the model on topic. In addition, these guardrails can safeguard against the sharing of personally identifiable information (PII). Many evaluation and moderation guardrails connect a deployed text generation model (LLM) to a deployed guard model. These guard models make predictions on LLM prompts and responses and then report these predictions and statistics to the central LLM deployment. To use evaluation and moderation guardrails, first, create and deploy guard models to make predictions on an LLM's prompts or responses; for example, a guard model could identify prompt injection or toxic responses. Then, when you create a custom model with the Text Generation target type, define one or more evaluation and moderation guardrails. The GA Premium release of this feature introduces general configuration settings for moderation timeout and evaluation and moderation logs.
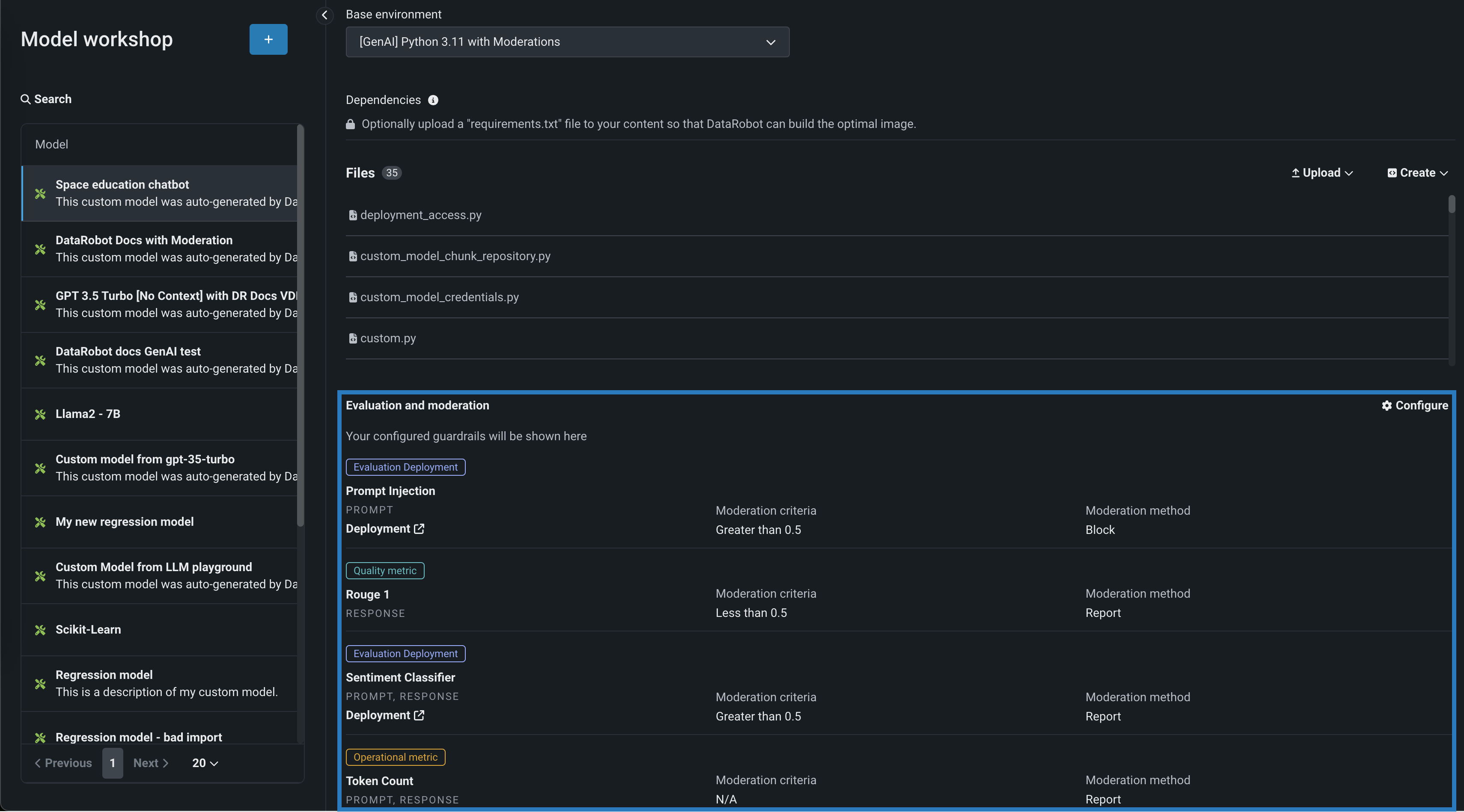
Feature flags OFF by default: Enable Moderation Guardrails (Premium feature), Enable Global Models in the Model Registry (Premium feature), Enable Additional Custom Model Output in Prediction Responses
For more information, see the documentation.
Compliance documentation now available for registered text generation models¶
DataRobot has long provided model development documentation that can be used for regulatory validation of predictive models. Now, the compliance documentation is expanded to include auto-generated documentation for text generation models in the Registry's model directory. For DataRobot natively supported LLMs, the document helps reduce the time spent generating reports, including model overview, informative resources, and most notably model performance and stability tests. For non-natively supported LLMs, the generated document can serve as a template with all necessary sections. Generating compliance documentation for text generation models requires the Enable Compliance Documentation and Enable Gen AI Experimentation feature flags.
SAP Datasphere integration for batch predictions¶
Available as a premium feature, SAP Datasphere is supported as an intake source and output destination for batch prediction jobs.
Feature flags OFF by default: Enable SAP Datasphere Connector (Premium feature), Enable SAP Datasphere Batch Predictions Integration (Premium feature)
For more information, see the prediction intake and output options documentation.
Filtering and model replacement improvements in the NextGen Console¶
This update to the NextGen Console improves deployment filtering and updates the model replacement experience to provide a more intuitive replacement workflow.
On the Console > Deployments tab, you can now filter on Created by me, Tags, and Model type.
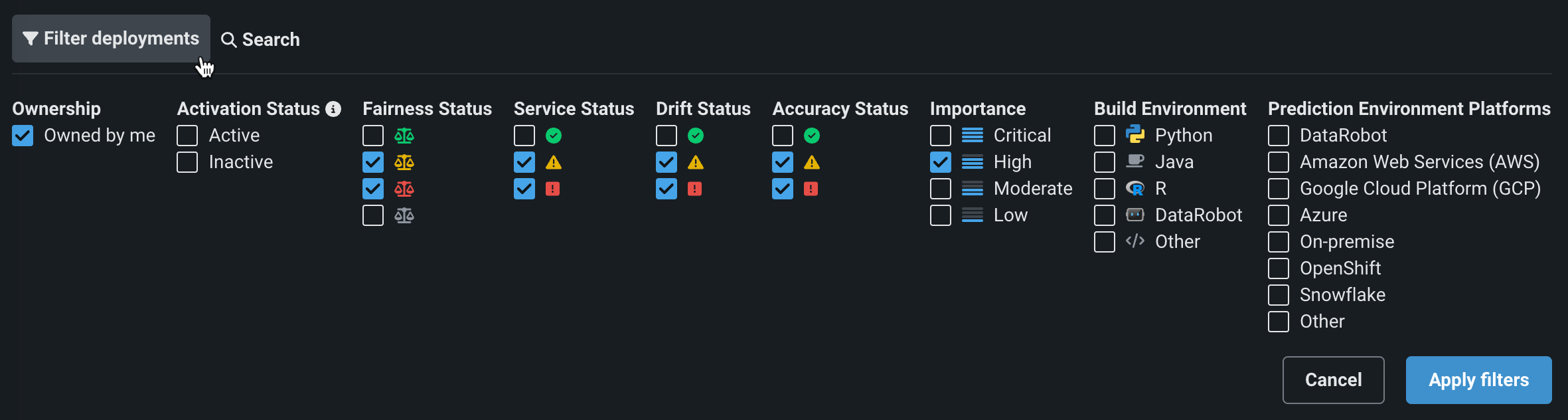
On the Console > Deployments tab, or a deployment's Overview, you can access the updated model replacement workflow from the model actions menu.

Manage custom execution environments in the NextGen Registry¶
The Environments tab is now available in the NextGen Registry, where you can create and manage custom execution environments for your custom models, jobs, applications, and notebooks:
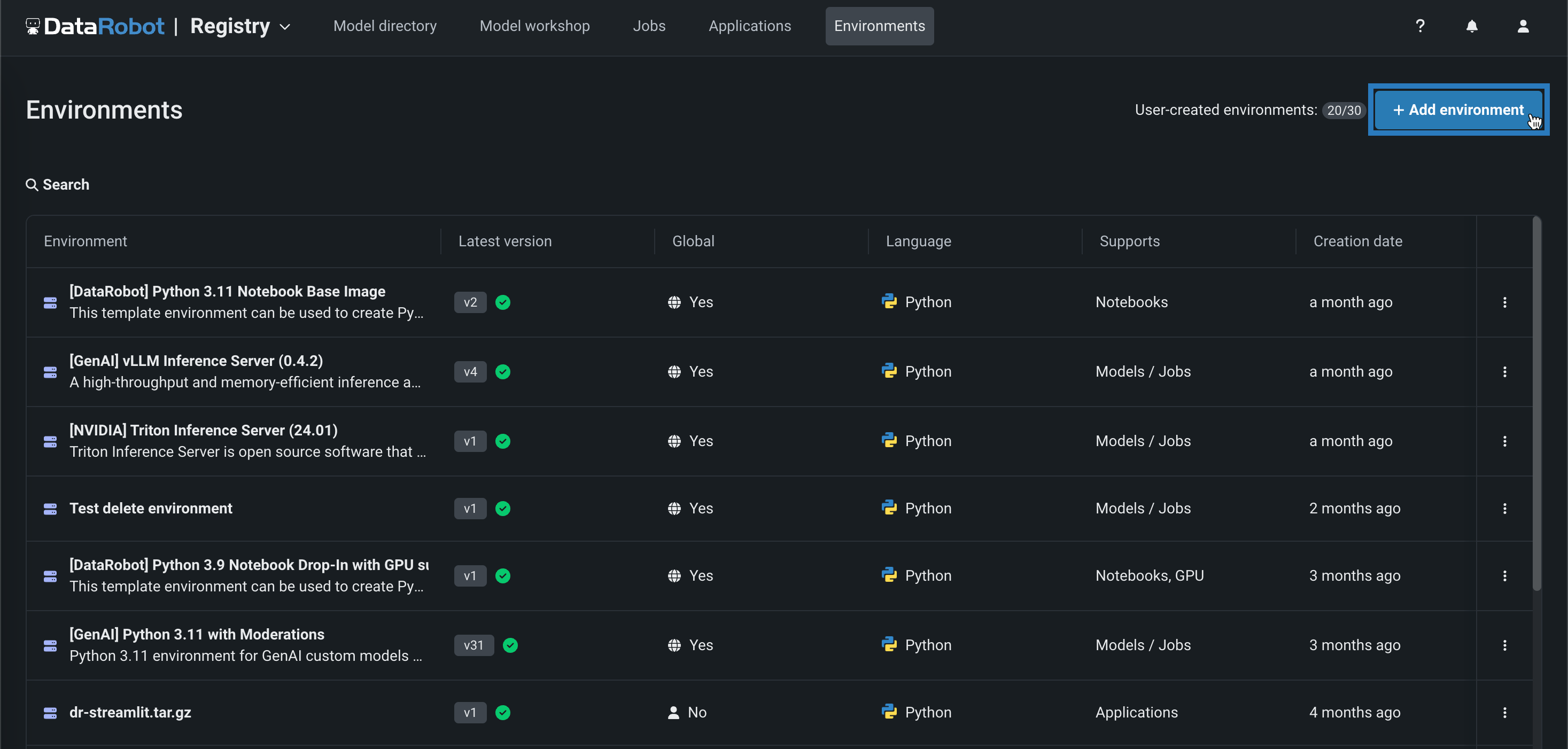
For more information, see the documentation.
Customize feature drift tracking¶
When you enable feature drift tracking for a deployment, you can now customize the features selected for tracking. During or after the deployment process, in the Feature drift section of the deployment settings, choose a feature selection strategy, either allowing DataRobot to automatically select 25 features, or selecting up to 25 features manually.


For more information, see the documentation.
Calculate insights during custom model registration¶
For custom models with training data assigned, DataRobot now computes model Insights and Prediction Explanation previews during model registration, instead of during model deployment. In addition, new model logs accessible from the model workshop can help you diagnose errors during the Insight computation process.

For more information, see the documentation.
Link Registry and Console assets to a Use Case¶
Associate registered model versions, model deployments, and custom applications to a Use Case with the new Use Case linking functionality. Link these assets to an existing Use Case, create a new Use Case, or manage the list of linked Use Cases.



For more information, see the registered model , deployment, and application linking documentation.
Code-based retraining jobs¶
Add a job, manually or from a template, implementing a code-based retraining policy. To view and add retraining jobs, navigate to the Jobs > Retraining tab, and then:
-
To add a new retraining job manually, click + Add new retraining job (or the minimized add button when the job panel is open).
-
To create a retraining job from a template, next to the add button, click , and then, under Retraining, click Create new from template.
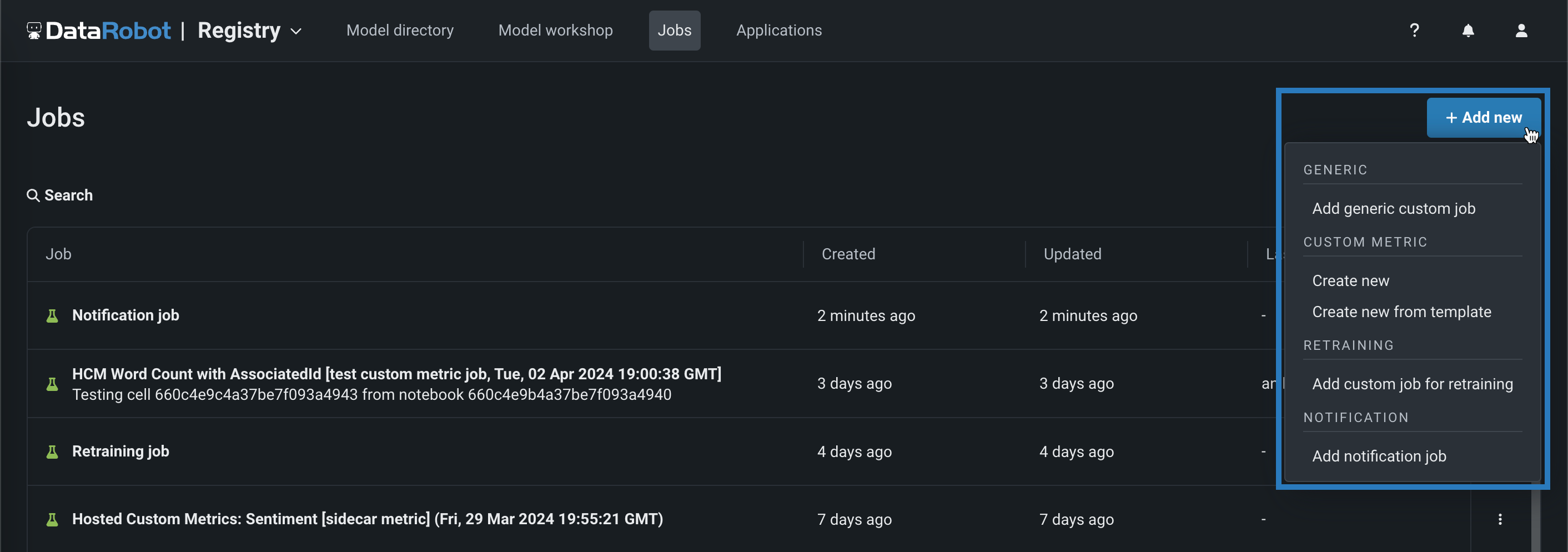
For more information, see the documentation.
Custom model workers runtime parameter¶
A new DataRobot-reserved runtime parameter, CUSTOM_MODEL_WORKERS, is available for custom model configuration. This numeric runtime parameter allows each replica to handle the set number of concurrent processes. This option is intended for process safe custom models, primarily in Generative AI use cases.
Custom model process safety
When enabling and configuring CUSTOM_MODEL_WORKERS, ensure that your model is process safe. This configuration option is only intended for process safe custom models, it is not intended for general use with custom models to make them more resource efficient. Only process safe custom models with I/O-bound tasks (like proxy models) benefit from utilizing CPU resources this way.
For more information, see the documentation.
Time series model package prediction intervals¶
To run a DataRobot time series model in a remote prediction environment and compute time series prediction intervals (from 1 to 100) for that model, download a model package (.mlpkg file) from the model's deployment or the Leaderboard with Compute prediction intervals enabled. You can then run prediction jobs with a portable prediction server (PPS) outside DataRobot.
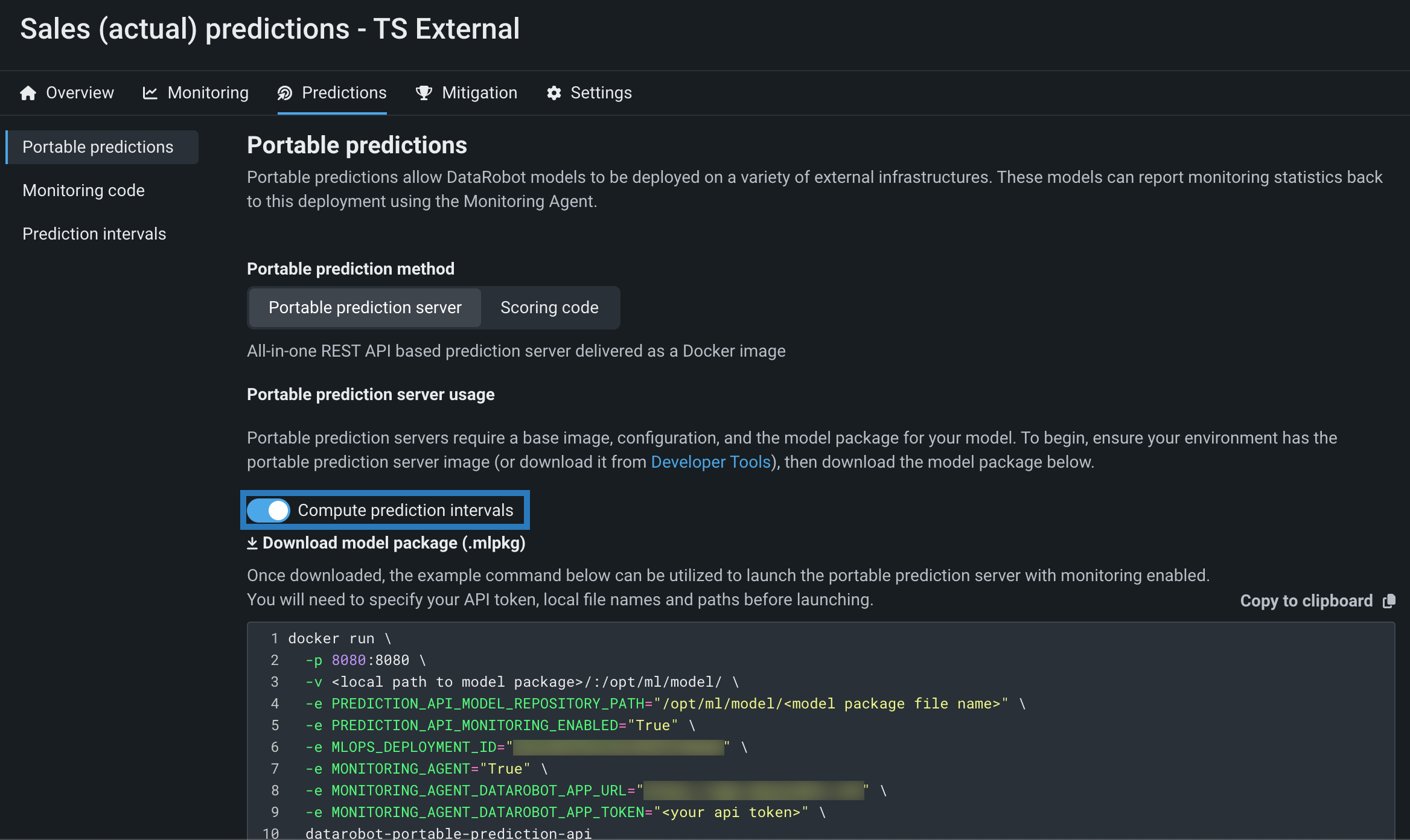
For more information, see the documentation.
Data tracing for deployments¶
Available as a premium feature, on the Data exploration tab of a Generative AI deployment, click Tracing to explore prompts, responses, user ratings, and custom metrics matched by association ID. This view can provide insight into the quality of the Generative AI model's responses, as rated by users or based on any Generative AI custom metrics you implement. Prompts, responses, and any available metrics are matched by association ID:
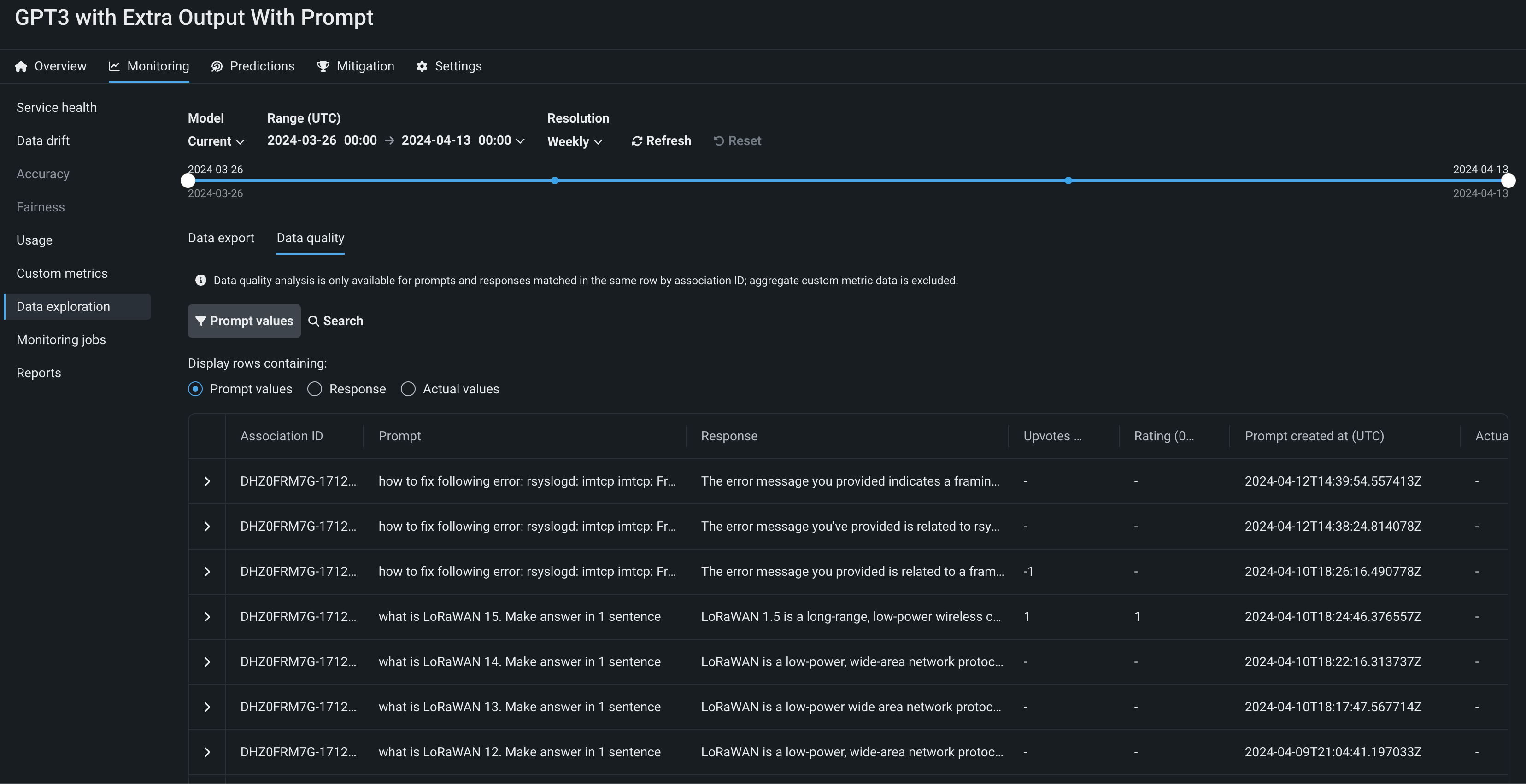
Feature flags OFF by default: Enable Data Quality Table for Text Generation Target Types (Premium feature), Enable Actuals Storage for Generative Models (Premium feature)
Wrangler recipes in batch predictions¶
Use a deployment's Predictions > Make predictions tab to efficiently score Wrangler datasets with a deployed model by making batch predictions. Batch predictions are a method of making predictions with large datasets, in which you pass input data and get predictions for each row. In the Prediction dataset box, click Choose file > Wrangler to make predictions with a Wrangler dataset:
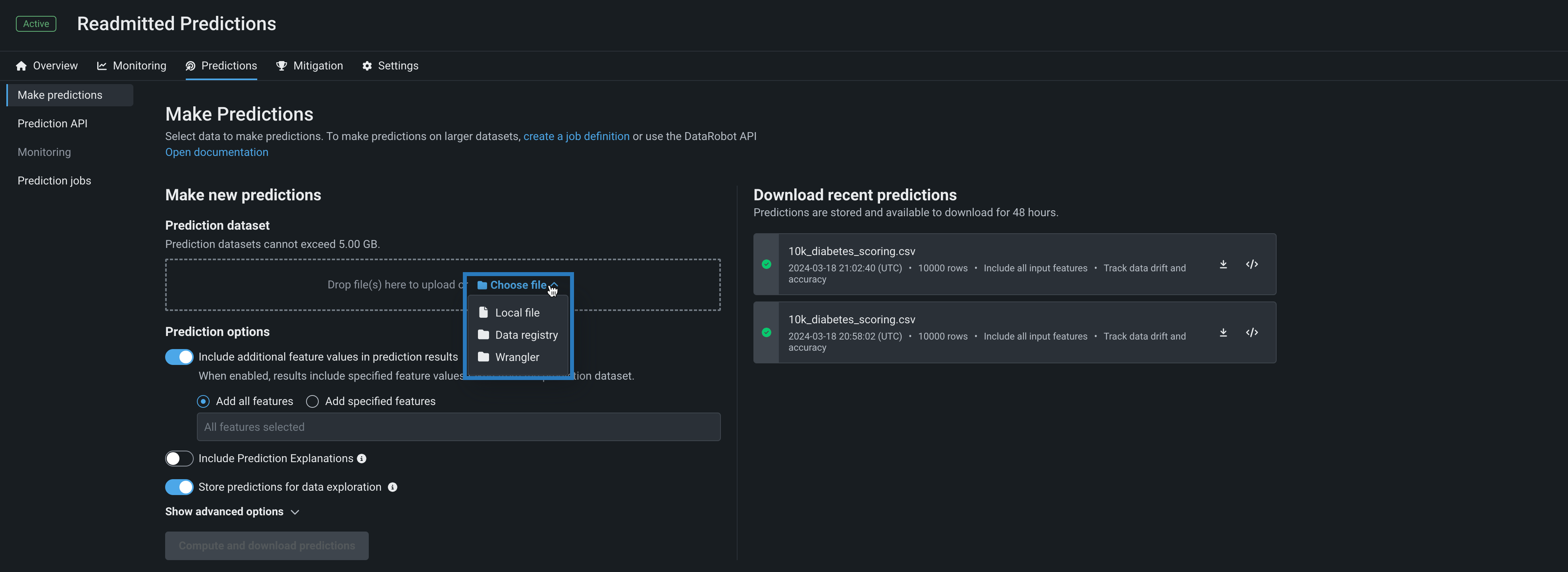
Predictions in Workbench
Wrangler is also available as a prediction dataset source in Workbench. To make predictions with a model before deployment, select the model from the Models list in an experiment and then click Model actions > Make predictions.
You can also schedule batch prediction jobs by specifying the prediction data source and destination and determining when DataRobot runs the predictions.
Multipart upload for batch prediction API¶
Multipart upload for the batch prediction API allows you to upload scoring data through multiple files to improve file intake for large datasets. The multipart upload process calls for multiple PUT requests followed by a POST request (finalizeMultipart) to finalize the upload manually. The multipart upload process can be helpful when you want to upload large datasets over a slow connection or if you experience frequent network instability.
This feature adds two endpoints to the batch prediction API and two new intake settings for the local file adapter.
Deploy LLMs from the Hugging Face Hub in DataRobot¶
Use the model workshop to create and deploy popular open source LLMs from the Hugging Face Hub, securing your AI apps with enterprise-grade GenAI observability and governance in DataRobot. The new [GenAI] vLLM Inference Server execution environment and vLLM Inference Server Text Generation Template provide out-the-box integration with the GenAI monitoring capabilities and bolt-on governance API provided by DataRobot.

This infrastructure uses the vLLM library, an open source framework for LLM inference and serving, to integrate with Hugging Face libraries to seamlessly download and load popular open source LLMs from Hugging Face Hub. To get started, customize the text generation model template. It uses Llama-3.1-8b LLM by default; however, you can change the selected model by modifying the engine_config.json file to specify the name of the OSS model you would like to use.
Feature flag OFF by default: Enable Custom Model GPU Inference (Premium feature)
Deploy models on DataRobot Serverless¶
Now generally available, you can use DataRobot Serverless prediction environments to create scalable deployments and configure the amount of compute available per deployment. Serverless prediction environments support deploying AutoML and AutoTS models, custom models, GenAI Blueprints, and vector databases. For predictions, they offer batch and real-time APIs for all deployments. To create a new DataRobot Serverless prediction environment, when you add a prediction environment, select the DataRobot Serverless platform.
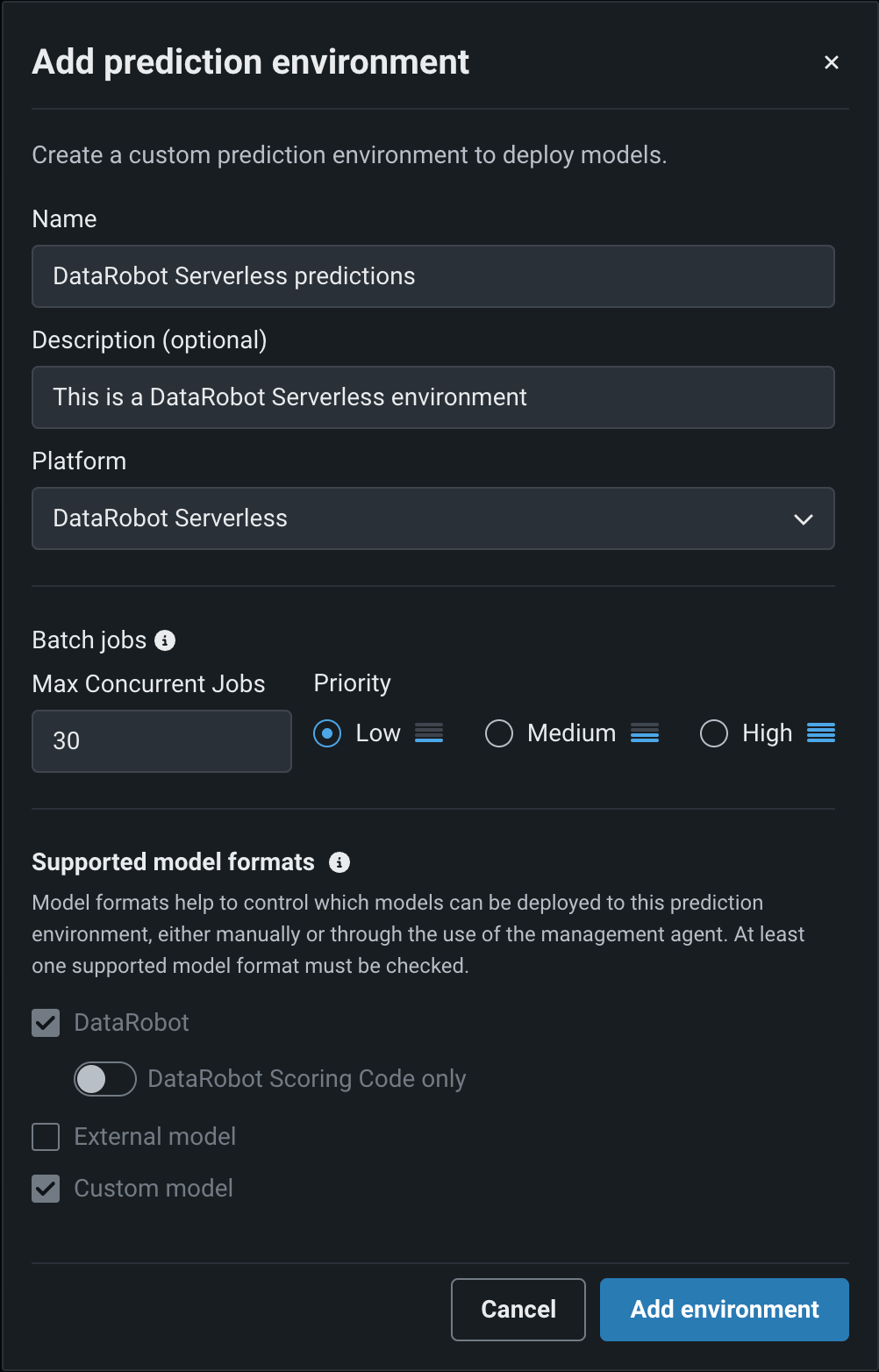
Manage DataRobot Serverless scale-to-zero policy¶
Now available as a premium feature, when creating a deployment on a DataRobot Serverless prediction environment, you can increase the minimum compute instances setting from the default of 0. If the minimum compute instances setting is set to 0 (the default), the inference server is stopped after an inactivity period of 7 days.
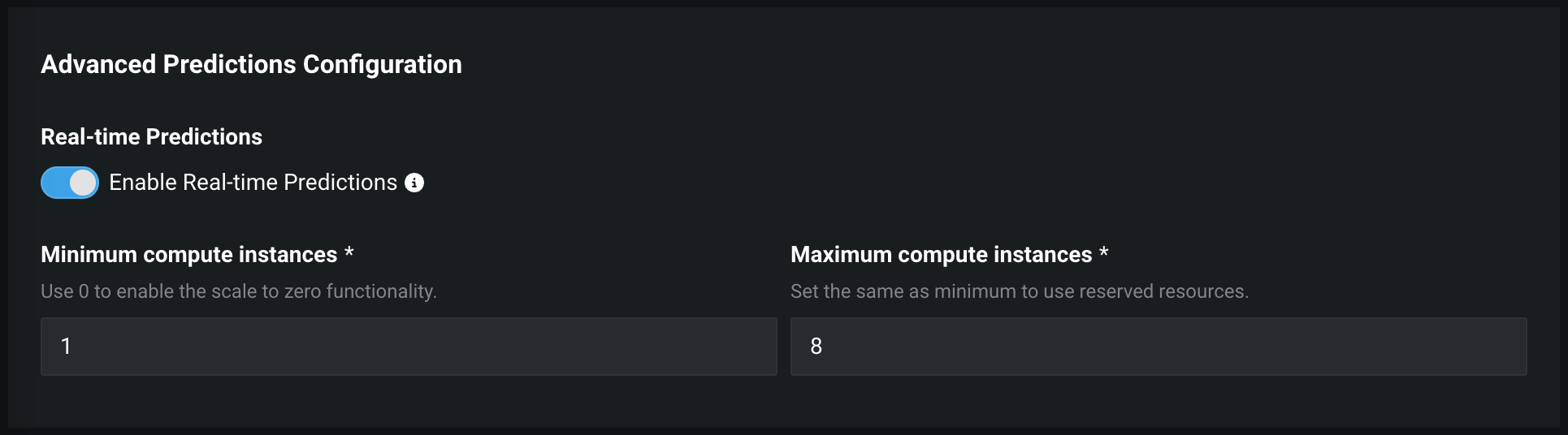
Feature flag OFF flag by default: Enable Deployment Auto-Scaling Management (Premium feature)
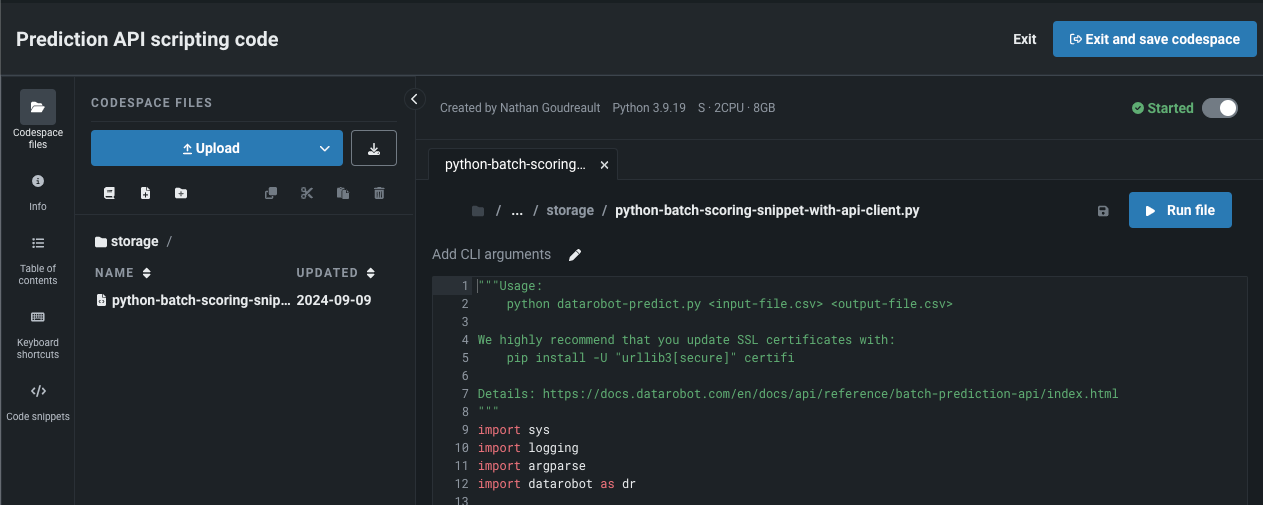
Open Prediction API snippets in a codespace¶
You can now open a Prediction API code snippet in a codespace to edit the snippet directly, share it with other users, and incorproate additional files. When selected, DataRobot generates a codespace instance and populates the snippet inside as a python file. The codespace allows for full access to file storage. You can use the Upload button to add additional datasets for scoring, and have the prediction output (output.json, output.csv, etc.) return to the codespace file directory after executing the snippet.
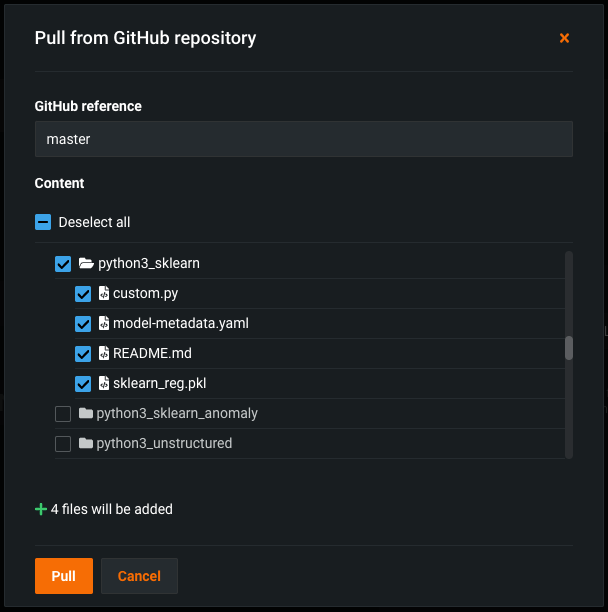
Remote repository file browser for custom models and tasks¶
With this release, while adding a model or task to the Custom Model Workshop in DataRobot Classic, you can browse and select folders and files in a remote repository, such as Bitbucket, GitHub, GitHub Enterprise, S3, GitLab, and GitLab Enterprise. When you pull from a remote repository, you can select the checkbox for any files or folders you want to pull into the custom model, or, you can select every file in the repository. This example uses GitHub; however, the process is the same for each repository type.
Batch predictions for TTS and LSTM models¶
Traditional Time Series (TTS) and Long Short-Term Memory (LSTM) models— sequence models that use autoregressive (AR) and moving average (MA) methods—are common in time series forecasting. Both AR and MA models typically require a complete history of past forecasts to make predictions. In contrast, other time series models only require a single row after feature derivation to make predictions. Previously, batch predictions couldn't accept historical data beyond the effective feature derivation window (FDW) if the history exceeded the maximum size of each batch, while sequence models required complete historical data beyond the FDW. These requirements made sequence models incompatible with batch predictions. This feature removes those limitations to allow batch predictions for TTS and LSTM models.
Preview¶
Automated deployment and replacement of Scoring Code in SAP AI Core¶
Create a DataRobot-managed SAP AI Core prediction environment to deploy DataRobot Scoring Code in SAP AI Core. With DataRobot management enabled, the model deployed externally to SAP AI Core has access to MLOps features, including automatic Scoring Code replacement. Once you've created an SAP AI Core prediction environment, you can deploy a Scoring Code-enabled model to that environment from Registry:
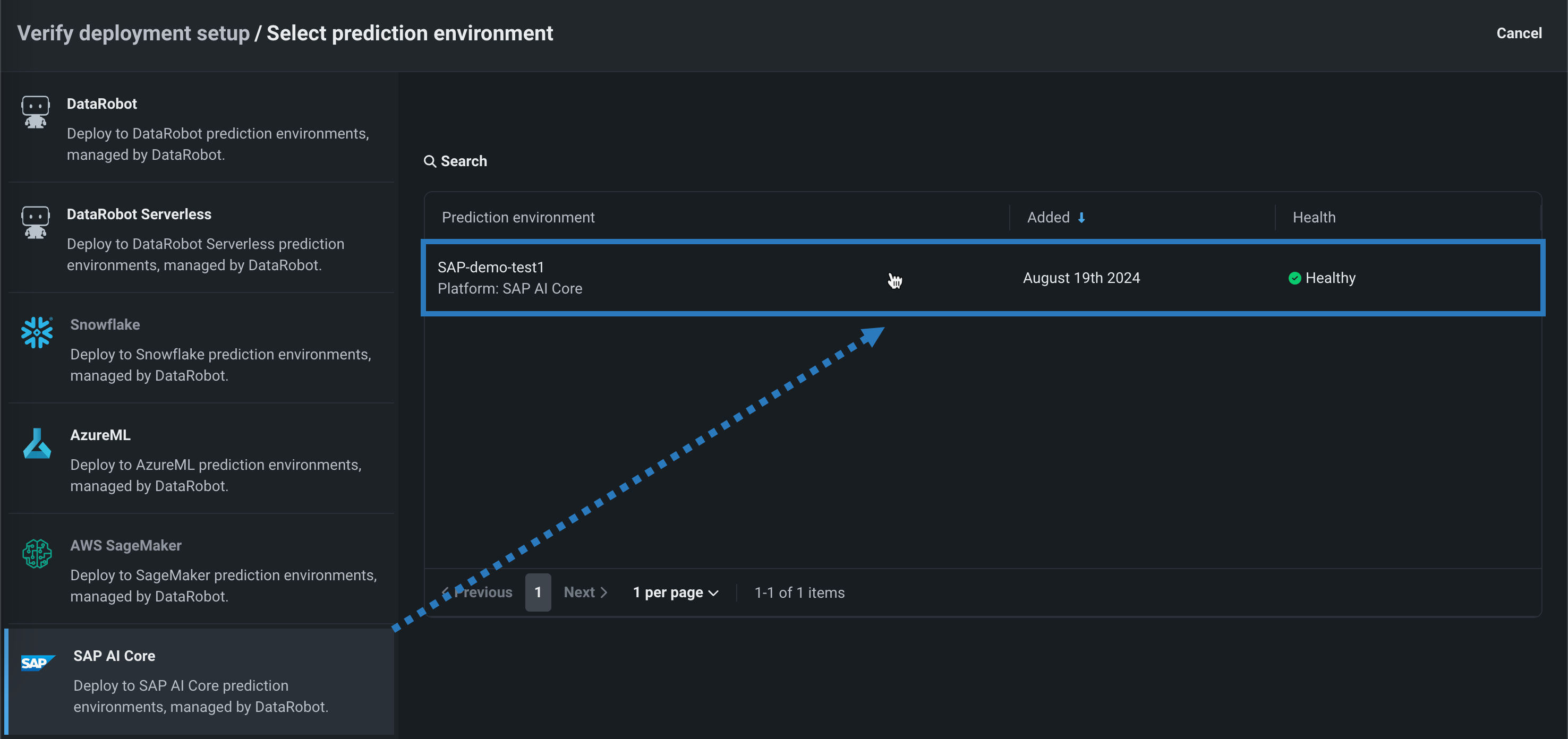
Preview documentation.
Feature flag OFF flag by default: Enable the Automated Deployment and Replacement of Scoring Code in SAP AI Core
Create categorical custom metrics¶
In the NextGen Console, on a deployment’s Custom metrics tab, you can define categorical metrics when you create an external metric. For each categorical metric, you can define up to 10 classes.
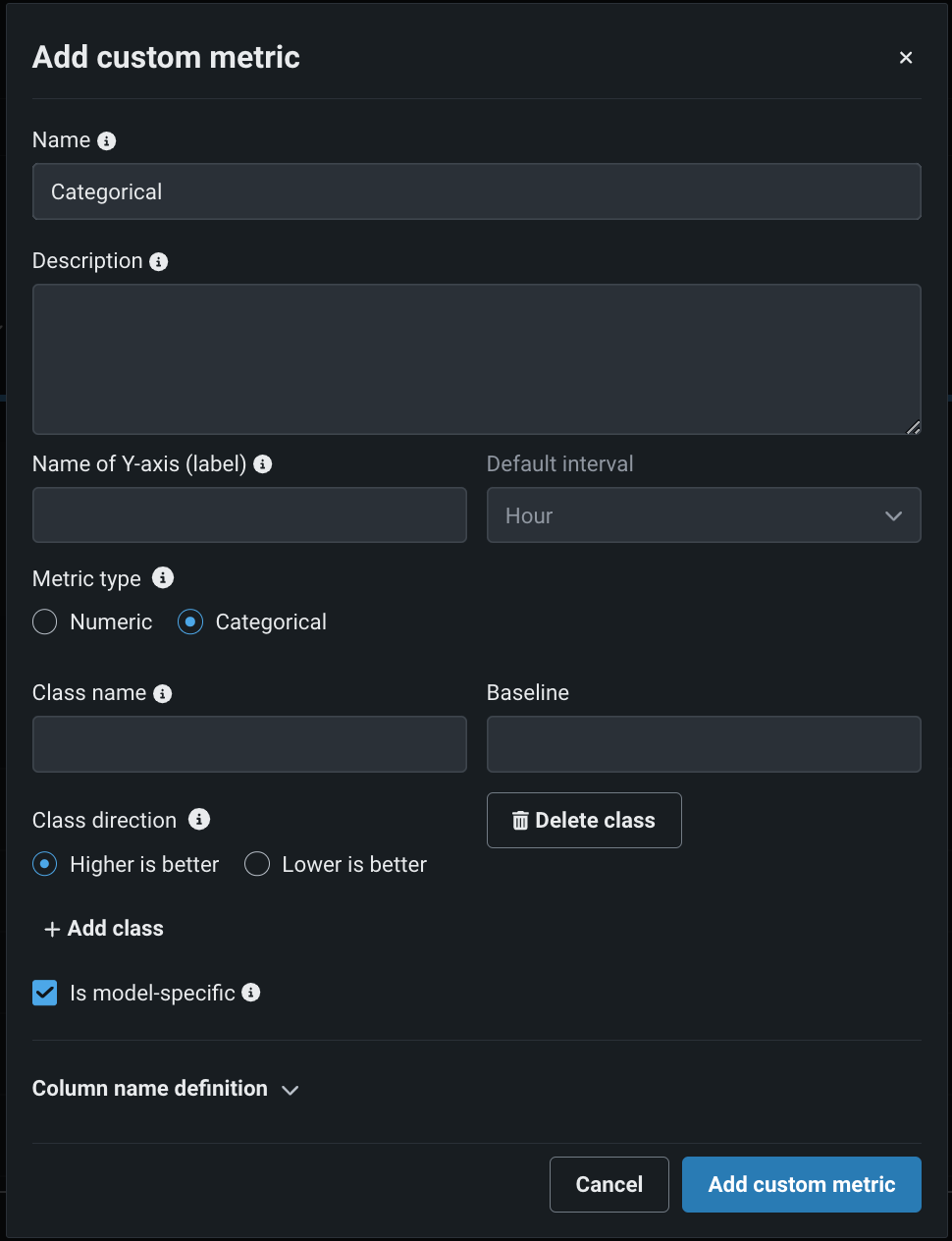
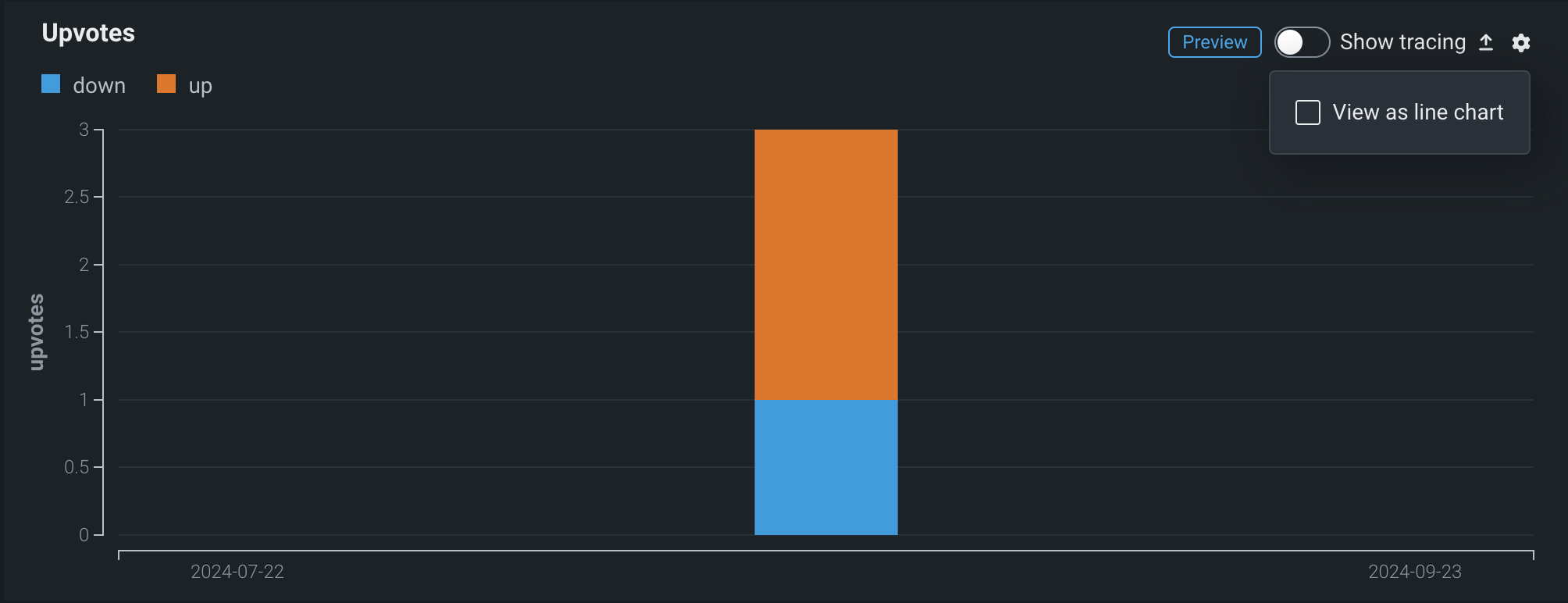
By default, these metrics are visualized in a bar chart on the Custom metrics tab; however, you can configure the chart type from the settings menu.
Preview documentation.
Feature flag ON by default: Enable Categorical Custom Metrics
Template gallery for custom jobs¶
The custom jobs template gallery is now available for the generic, notification, and retraining job types—in addition to custom metric jobs. To access the new template gallery, from the Registry > Jobs tab, create a job from a template for any job type.
Preview documentation.
Feature flags ON by default: Enable Custom Jobs Template Gallery, Enable Custom Templates
Create and deploy vector databases¶
With the vector database target type in the model workshop, you can register and deploy vector databases, as you would any other custom model.

Preview documentation.
Feature flag OFF by default: Enable Vector Database Deployment Type (Premium feature)
Geospatial monitoring for deployments¶
For a deployed binary classification, regression, or multiclass model built with location data in the training dataset, you can now leverage DataRobot Location AI to perform geospatial monitoring on the deployment's Data drift and Accuracy tabs. To enable geospatial analysis for a deployment, enable segmented analysis and define a segment for the location feature geometry, generated during location data ingest. The geometry segment contains the identifier used to segment the world into a grid of H3 cells.

Preview documentation

Preview documentation.
Feature flags ON by default: Enable Geospatial Features Monitoring, Enable Geospatial Features in Workbench
Prompt monitoring improvements for deployments¶
For deployed text generation models, the Monitoring > Data exploration tab includes additional sort and filter options on the Tracing table, providing new ways to interact with a Generative AI deployment's stored prompt and response data and gain insight into a model's performance through the configured custom metrics. In addition, this release introduces custom metric templates for Cosine Similarity and Euclidean Distance.
Preview documentation.
Feature flags OFF by default: Enable Data Quality Table for Text Generation Target Types (Premium feature), Enable Actuals Storage for Generative Models (Premium feature)
Feature flags ON by default: Enable Custom Jobs Template Gallery, Enable Custom Templates
Editable resource settings and runtime parameters for deployments¶
For deployed custom models, the custom model CPU (or GPU) resource bundle and runtime parameters defined during custom model assembly are now editable after assembly.
If the custom model is deployed on a DataRobot Serverless prediction environment and the deployment is inactive, you can modify the Resource bundle settings from the Resources tab.

Preview documentation
You can modify a custom model's runtime parameters during or after the deployment process.

Preview documentation
Feature flag ON by default: Enable Editing Custom Model Runtime-Parameters on Deployments
Feature flags OFF by default: Enable Resource Bundles, Enable Custom Model GPU Inference (Premium feature)
Data Registry wrangling for batch predictions¶
Use a deployment's Predictions > Make predictions tab to make batch predictions on a recipe wrangled from the Data Registry. Batch predictions are a method of making predictions with large datasets, in which you pass input data and get predictions for each row. In the Prediction dataset box, click Choose file > Wrangler recipe, then pick a recipe from the Data Registry:
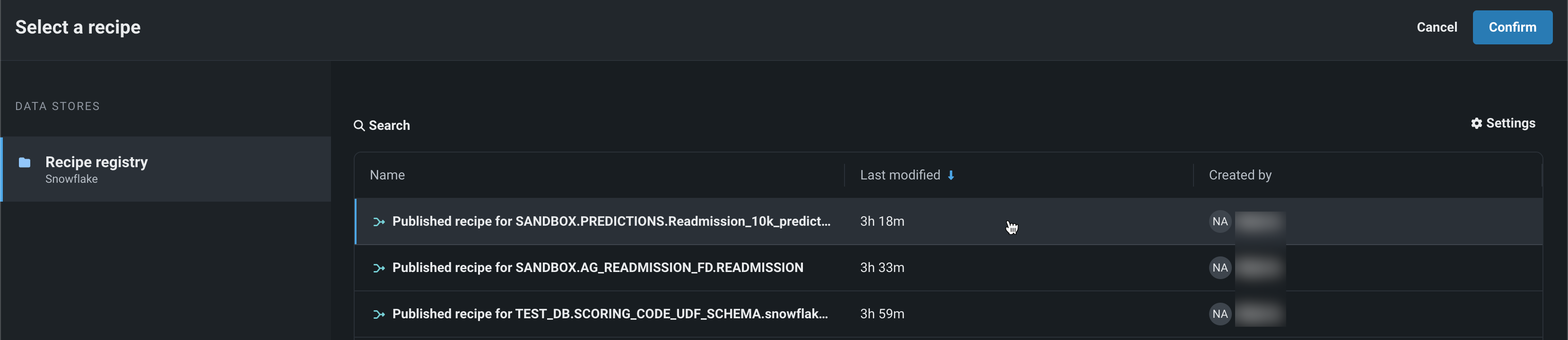
Predictions in Workbench
Batch predictions on recipes wrangled from the Data Registry are also available in Workbench. To make predictions with a model before deployment , select the model from the Models list in an experiment and then click Model actions > Make predictions.
You can also schedule batch prediction jobs by specifying the prediction data source and destination and determining when DataRobot runs the predictions.
Preview documentation.
Feature flag OFF by default: Enable Wrangling Pushdown for Data Registry Datasets
Bolt-on Governance API integration for custom models¶
The chat() hook allows custom models to implement the Bolt-on Governance API to provide access to chat history and streaming response.
For more information, see the documentation and an example notebook.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.