October 2022
October 2022¶
October 26, 2022
DataRobot's managed AI Platform deployment for October delivered the following new GA and preview features. See the this month's release notes as well as a deployment history for additional past feature announcements. See also:
Features grouped by capability
| Name | GA | Preview |
|---|---|---|
| Data and integrations | ||
| Added support for manual transforms of text features | ✔ | |
| Modeling | ||
| Add custom logos to No-Code AI Apps | ✔ | |
| Predictions and MLOps | ||
| Deployment Usage tab | ✔ | |
| Drill down on the Data Drift tab | ✔ | |
| Model logs for model packages | ✔ | |
GA¶
Added support for manual transforms of text features¶
With this release, DataRobot now allows manual, user-created variable type transformations from categorical-to-text even when a feature is flagged as having "too many values". These transformed variables will not be included in the Informative Features list, but can be manually added to a feature list for modeling.
Preview¶
Deployment Usage tab¶
After deploying a model and making predictions in production, monitoring model quality and performance over time is critical to ensure the model remains effective. This monitoring occurs on the Data Drift and Accuracy tabs and requires processing large amounts of prediction data. Prediction data processing can be subject to delays or rate limiting.
On the left side of the Usage tab is the Prediction Tracking chart, a bar chart of the prediction processing status over the last 24 hours or 7 days, tracking the number of processed, missing association ID, and rate-limited prediction rows. Depending on the selected view (24-hour or 7-day), the histogram's bins are hour-by-hour or day-by-day:
![]()
To view additional information on the Prediction Tracking chart, hover over a column to see the time range during which the predictions data was received and the number of rows that were Processed, Rate Limited, or Missing Association ID:
![]()
On the right side of the Usage tab are the processing delays for Predictions Processing (Champion) and Actuals Processing (the delay in actuals processing is for ALL models in the deployment):
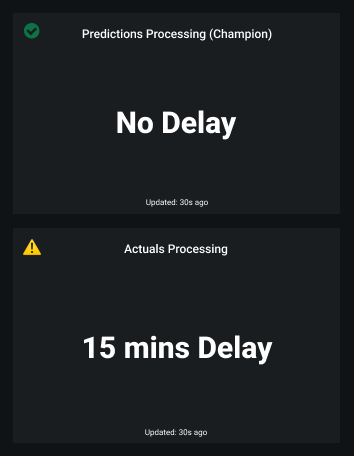
The Usage tab recalculates the processing delays without reloading the page. You can check the Updated value to determine when the delays were last updated.
Required feature flag: Enable Deployment Processing Info
Preview documentation.
Drill down on the Data Drift tab¶
The Data Drift > Drill Down chart visualizes the difference in distribution over time between the training dataset of the deployed model and the datasets used to generate predictions in production. The drift away from the baseline established with the training dataset is measured using the Population Stability Index (PSI). As a model continues to make predictions on new data, the change in the drift status over time is visualized as a heat map for each tracked feature. This heat map can help you identify data drift and compare drift across features in a deployment to identify correlated drift trends:
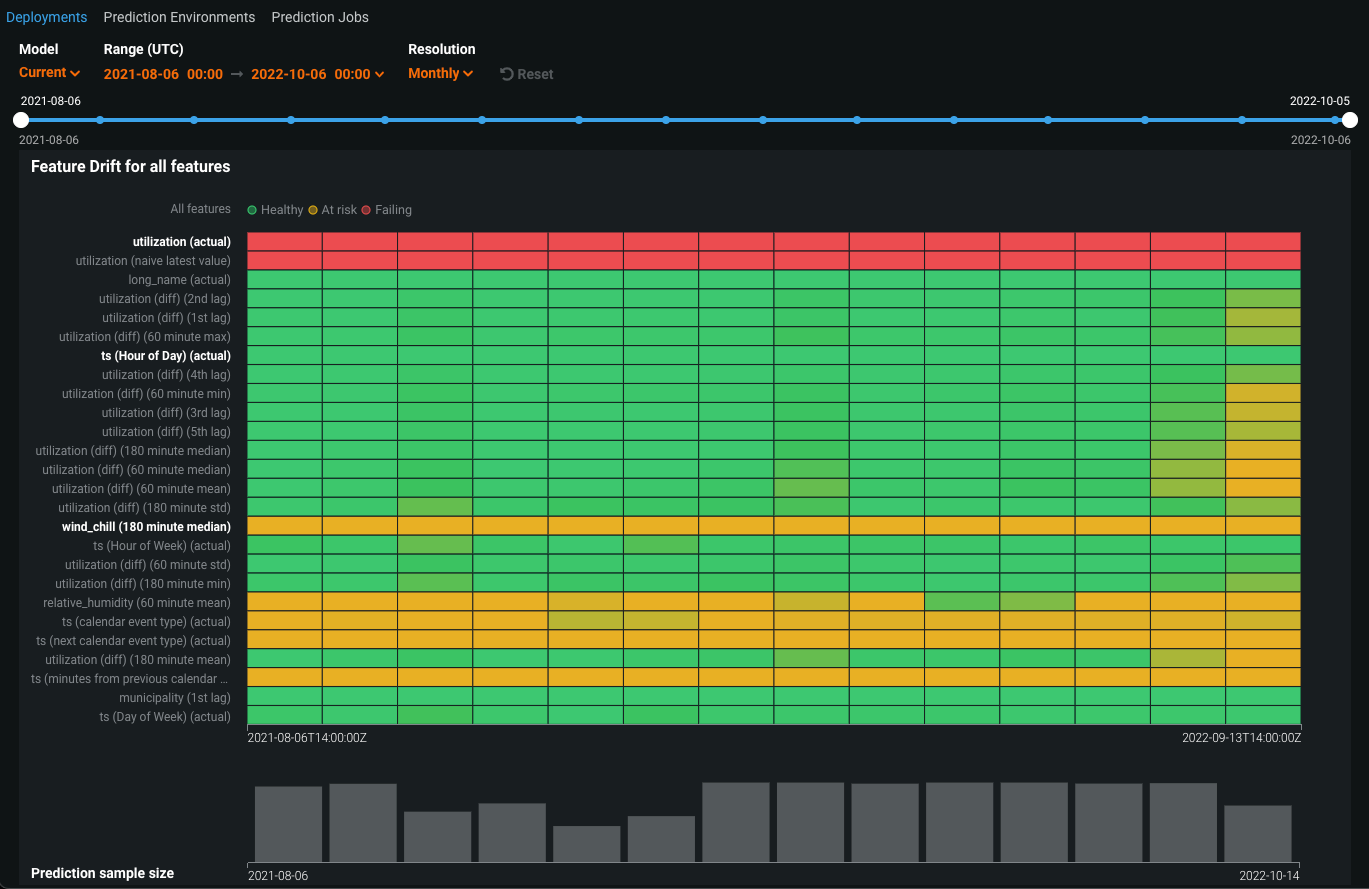
In addition, you can select one or more features from the heat map to view a Feature Drift Comparison chart, comparing the change in a feature's data distribution between a reference time period and a comparison time period to visualize drift. This information helps you identify the cause of data drift in your deployed model, including data quality issues, changes in feature composition, or changes in the context of the target variable:

Required feature flag: Enable Drift Drill Down Plot
Preview documentation.
Model logs for model packages¶
A model package's model logs display information about the operations of the underlying model. This information can help you identify and fix errors. For example, compliance documentation requires DataRobot to execute many jobs, some of which run sequentially and some in parallel. These jobs may fail, and reading the logs can help you identify the cause of the failure (e.g., the Feature Effects job fails because a model does not handle null values).
Important
In the Model Registry, a model package's Model Logs tab only reports the operations of the underlying model, not the model package operations (e.g., model package deployment time).
In the Model Registry, access a model package, and then click the Model Logs tab:
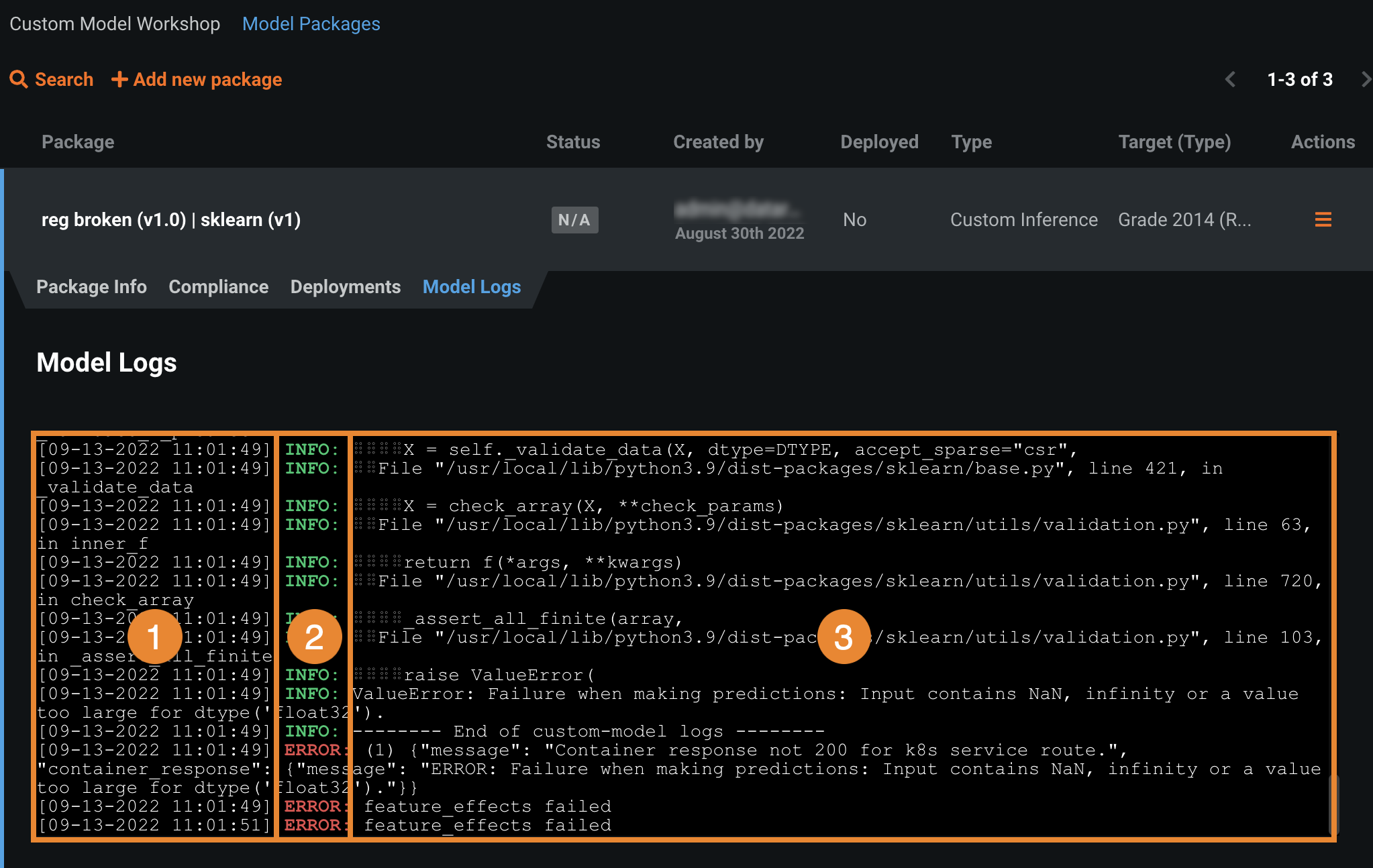
| Information | Description | |
|---|---|---|
| 1 | Date / Time | The date and time the model log event was recorded. |
| 2 | Status | The status the log entry reports:
|
| 3 | Message | The description of the successful operation (INFO), or the reason for the failed operation (ERROR). This information can help you troubleshoot the root cause of the error. |
If you can't locate the log entry for the error you need to fix, it may be an older log entry not shown in the current view. Click Load older logs to expand the Model Logs view.
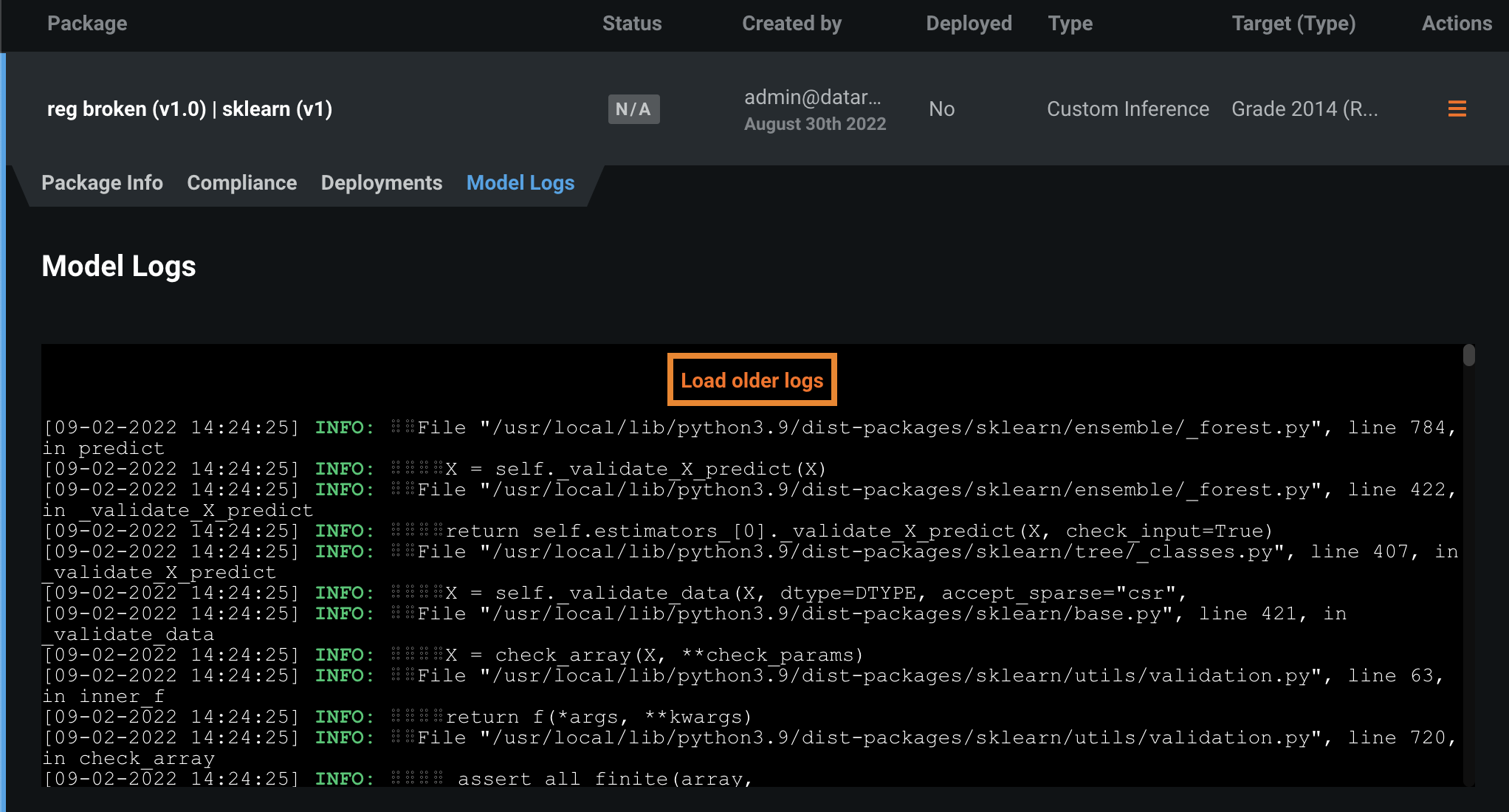
Tip
Look for the older log entries at the top of the Model Logs; they are added to the top of the existing log history.
Required feature flag: Enable Legacy Model Registry
Preview documentation.
Add custom logos to No-Code AI Apps¶
Now available for preview, you can add a custom logo to your No-Code AI Apps, allowing you to keep the branding of the AI App consistent with that of your company before sharing it either externally or internally.
![]()
To upload a new logo, open the application you want to edit and click Build. Under Settings > Configuration Settings, click Browse and select a new image, or drag-and-drop an image into the New logo field.
![]()
Required feature flag: Enable Application Builder Custom Logos
Deprecation announcements¶
DataRobot Pipelines to be removed in November¶
As of November 2022, DataRobot will be retiring Pipeline Workspaces and will no longer continue to support it. If you are currently using this offering, contact support@datarobot.com or visit support.datarobot.com.
User/Open source models disabled in November¶
As of November 2022, DataRobot disabled all models containing User/Open source (“user”) tasks. See the release notes for full information on identifying these models. Use the Composable ML functionality to create custom models.
DataRobot Prime models to be deprecated¶
DataRobot Prime, a method for creating a downloadable, derived model for use outside of the DataRobot application, will be removed in an upcoming release. It is being replaced with the new ability to export Python or Java code from Rulefit models using the Scoring Code capabilities. Rulefit models differ from Prime only in that they use raw data for their prediction target rather than predictions from a parent model. There is no change in the availability of Java Scoring Code for other blueprint types, and any existing Prime models will continue to function.
Automodel functionality to be removed¶
The October release deployment brings the removal of the "Automodel" preview functionality. There is no impact to existing projects, but the feature will no longer be accessible from the product.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.