Generative AI (V10.2)¶
November 21, 2024
The DataRobot v10.2.0 release includes many new and improved GenAI capabilities. See additional details of Release 10.2 in:
10.2 release¶
Features grouped by capability
Premium
DataRobot's Generative AI capabilities are a premium feature; contact your DataRobot representative for enablement information. Try this functionality for yourself in a limited capacity in the DataRobot trial experience.
GenAI general enhancements¶
New LLMs¶
The following new LLMs have been added since release 10.1:
- Anthropic Claude 3 Haiku
- Anthropic Claude 3 Sonnet
- Anthropic Claude 3 Opus
- Azure OpenAI GPT-4 Turbo
- Azure OpenAI GPT-4o
- Google Gemini 1.5 Flash
- Google Gemini 1.5 Pro
See the full list of LLMs, with max context window and completion token ratings, here.
New embedding models¶
The following new embedding models have been added since release 10.1:
| Model | Description |
|---|---|
| huggingface.co/infloat/multilingual-e5-small | A smaller-sized language model used for multilingual RAG performance with faster performance than the multilingual-e5-base. |
| jinaai/jina-embedding-s-en-v2 | Part of the Jina Embeddings v2 family, this embedding model is the optimal choice for long-document embeddings (large chunk sizes, up to 8192) |
| BYO embeddings | Select an embedding model deployed as an unstructured custom model. |
See the full list of embedding models here.
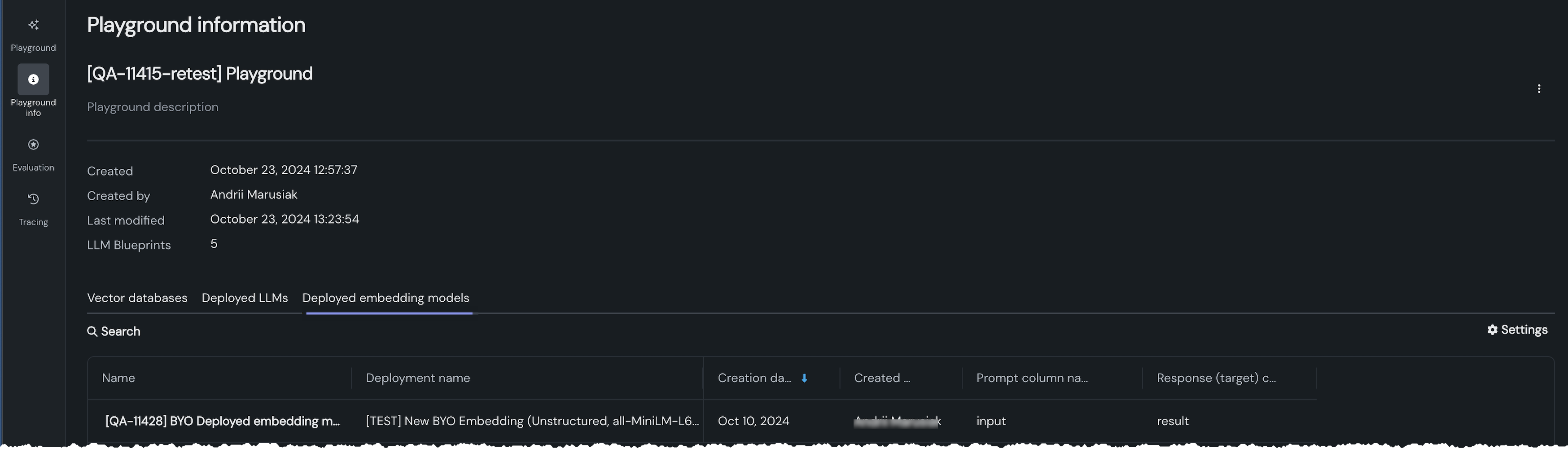
Expanded playground information now available¶
A new Playground information tab provides access to the assets associated with the playground—vector databases, deployed LLMs, and deployed embedding models. It also provides basic playground metadata. Use the tabs to view additional information.
Vector database-specific enhancements¶
The following new features enhance the vector database creation experience.
Vector database creation¶
Increased dataset size supported for BYO embeddings¶
With this deployment, DataRobot can now support datasets up to 10GB when bringing your own embedding model to a playground in SaaS. (The embedding model is the model used in the vector database creation process.) Self-managed users bringing a GPU-supported custom model can increase the supported dataset limit for BYO embeddings to 10GB using the CUSTOM_EMBEDDINGS_SUPPORTED_DATASET_SIZE environment variable. This increased size capability prevents limitations on scale or performance when using your own embedding models.
Support for CSVs in vector database creation¶
Previously, you could only create vector databases using uploaded ZIP files. With this release, support for ingested CSVs has been added. See the full description of supported dataset types and handling here.
Support for metadata in vector databases data sources¶
A vector databases data source can now contain up to 50 additional metadata columns, in addition to the required document and document_file_path columns. This additional metadata can be used as the basis for filtering when chatting with an LLM. By adding metadata to chunks in the vector database, the model can more effectively search the vector database for these chunks during retrieval.
Support for BYO embeddings¶
When creating a vector database, you can now choose to either use an existing, internal embedding model or a deployed, external embedding model. Once you identify the deployment and add prompt and response columns, you can validate the model before adding it to your vector database.

Vector database refresh¶
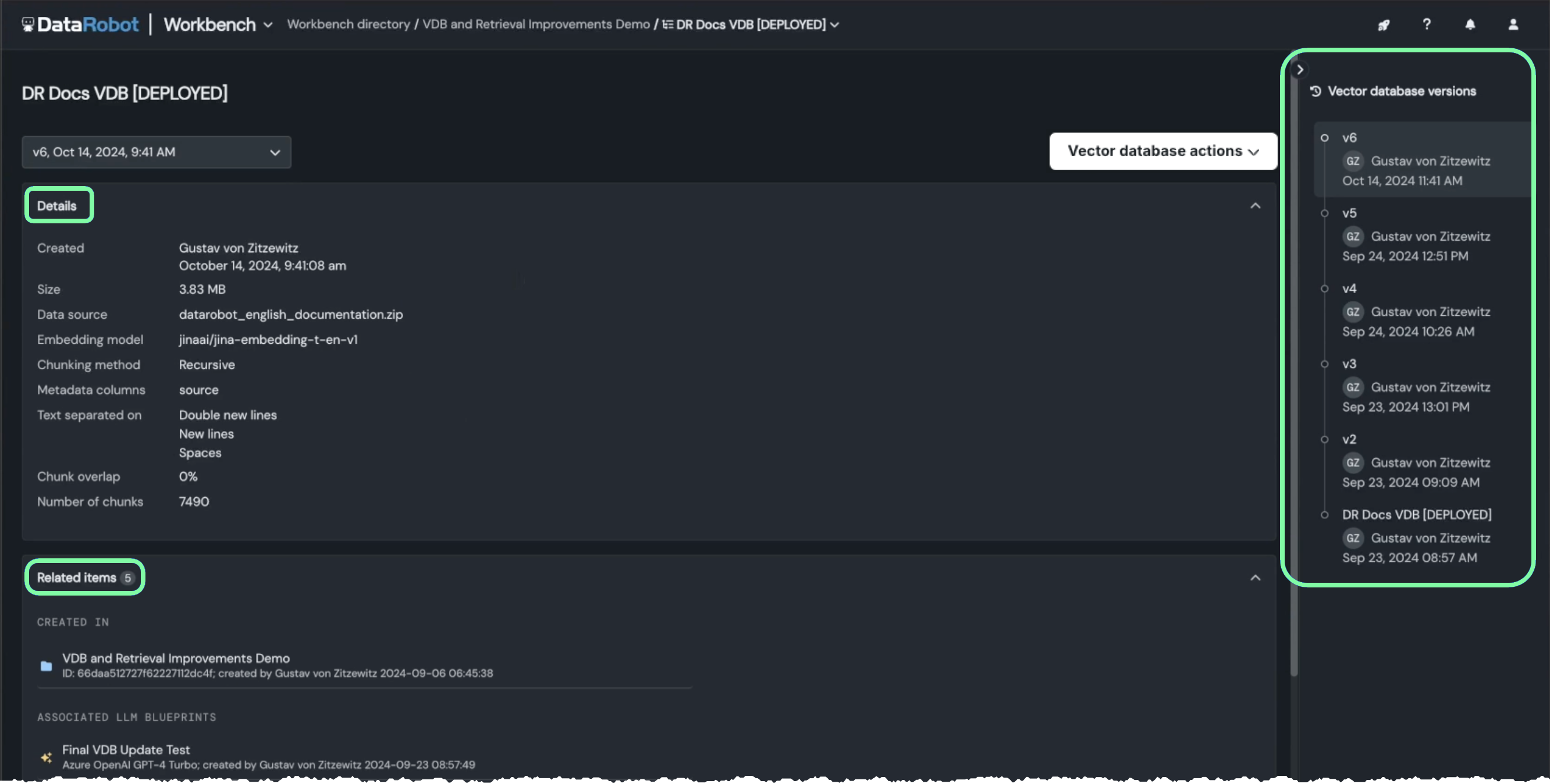
Versioning for vector databases¶
You can now update existing vector databases in both the playground and in a deployment. The ability to version vector databases—creating child, related entities based on a single parent—brings a host of benefits to GenAI solution building. Versioning uses metadata in the lineage process to help assess and compare results with previous versions. Each update creates a new vector database, as a version, allowing you to select which version to use for a current experiment or downstream assets that leverage it.
With versioning you can:
-
Update the data in your vector database, ensuring the most up-to-date data is available to ground LLM responses.
-
Create new versions, creating a full vector database lineage, but also select previous versions. This allows you to "update" older versions that are used by downstream assets and to roll back to previous versions, if needed.
-
Apply "tried and true" chunking and/or embedding parameters from existing vector databases to new data.
-
Use the dataset's metadata during retrieval, allowing you to more effectively search for chunks in the dataset.
Additionally, a new details page lists the metadata and related assets for the selected version:
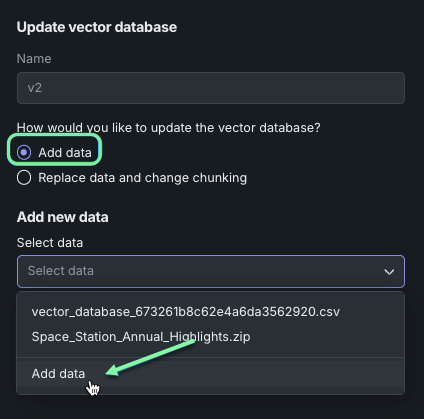
Add or replace vector database data¶
As part of versioning, you can update the data within the vector database to ensure you are using the most up-to-date data to ground LLM responses. To update data, you can choose to add to or replace the current data source, giving you control over what's in the vector database, even after it's created. When adding data, the same chunking and embedding parameters are applied. When replacing data, you have the opportunity to change the chunking and embedding if you wish.
Export vector databases¶
You can now export a vector database, or a specific version of a database, to the Data Registry for re-use in a different Use Case. The dataset is also saved to the AI Catalog where you can download, modify, and re-upload it for re-use.

Chunking¶
"No chunking" option introduced¶
This release brings the option to not perform chunking on the input data source when creating the vector database. Text chunking, the process of splitting a text document into smaller text chunks, is how embeddings are generated. When No chunking is selected, DataRobot treats each row as a chunk and directly generates an embedding on each row.

Semantic chunking method added¶
Previously, only the recursive chunking method—which splits text to meet a maximum size limit—was available in the text chunking configuration of the vector database. With the introduction of semantic chunking you can split text into smaller, meaningful units based on the semantic content instead of length, which can result in more effective chunks for prompting the LLM.
Retrieval¶

New retriever methods instruct chunk selection¶
When building a vector database, you can now select the retriever method the LLM will use to retrieve the most relevant chunks from the vector database. Choose either a Single-Lookup, Conversational, or Multi-Step retriever.
Add neighbor chunks to results¶
Use Add Neighbor Chunks to control whether to add neighboring chunks within the vector database to the chunks that the similarity search retrieves. When enabled, the retriever returns i, i-1, and i+1 (for example, if the query retrieves chunk number 42, chunks 41 and 43 are also retrieved).
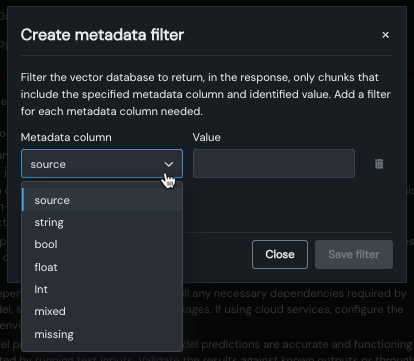
Filter metadata to limit returned citations¶
You can now use metadata that was added to the data source to limit the citations returned by the prompt query. To apply metadata filtering, simply create a column-value pair for any or all metadata columns and enter a prompt query. You can compare the results of filtering and not in the returned Citations.
LLM evaluation enhancements¶
With evaluation metrics, you can configure an array of performance, safety, and operational metrics. Configuring these metrics lets you define moderation methods to intervene when prompts and responses meet the moderation criteria you set. This functionality can help detect and block prompt injection and hateful, toxic, off-topic, and inappropriate prompts and responses. It can also help identify hallucinations or low-confidence responses and safeguard against the sharing of personally identifiable information (PII). This release provides new evaluation metrics and improvements to the LLM evaluation workflow.
In addition, the playground introduces compliance testing, combining evaluation metrics and evaluation datasets to automate the detection of compliance issues through test prompt scenarios. Configuring these tests lets you report on bias, jail-breaking, completeness, personally identifiable information, and toxicity. These tests can be sent to the NextGen Registry's model workshop, alongside the LLM, to generate compliance documentation in production.
New evaluation metrics¶
The following new LLM evaluation metrics have been added since release 10.1:
- Stay on topic for inputs
- Stay on topic for output
- Emotions Classifier (replacing Sentiment Classifier)
In addition, Token Count is now four separate metrics: All tokens, Prompt tokens, Response tokens, and Document tokens.
Manage evaluation metrics¶
When configuring evaluation metrics on the Evaluation tab, you can edit previously-configured evaluation metrics from the Configuration summary sidebar. Click the edit icon to edit the metric settings (including the metric name), or click the delete icon to remove the metric from the playground. You can also view helper text if the metric is misconfigured.

In addition, as evaluation metrics are now specific to an individual playground, from the Evaluation tab, you can copy an evaluation metrics configuration to or from an LLM playground to quickly share the configuration.

You can copy evaluation configurations from an existing playground, to an existing playground, or to a new playground.



Configure compliance testing¶
Combine an evaluation metric and an evaluation dataset to automate the detection of compliance issues through test prompt scenarios. Compliance tests are available in two locations:
-
From the Playground tile, you can run the pre-defined compliance tests without modification, create custom tests, or modify the pre-defined tests to suit your organization's testing requirements.
-
From the Evaluation tile, you can view the pre-defined compliance tests, create and manage custom tests, or modify the pre-defined tests to suit your organization's testing requirements.

The following LLM compliance tests have been added since release 10.1:
- Bias Benchmark
- Jailbreak
- Completeness
- Personally Identifiable Information (PII)
- Toxicity
- Japanese Bias Benchmark
To compare compliance test results, on the Playground tile, you can run compliance tests for up to three LLM blueprints at a time.
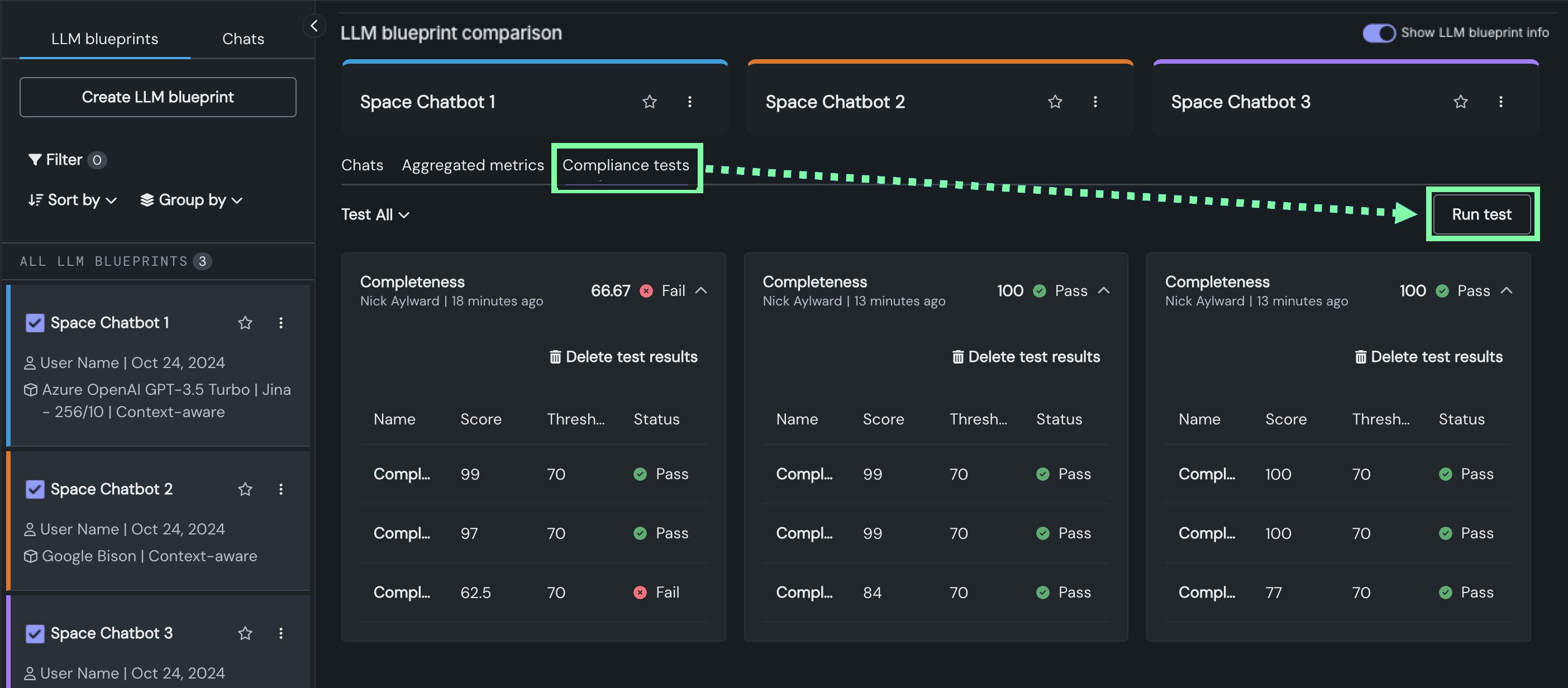
In production, you can generate compliance documentation, containing the configured compliance test results, for the deployed LLM in the NextGen Console.
Manage metrics and compliance tests sent to the model workshop¶
After creating an LLM blueprint, setting the blueprint configuration (including evaluations metrics and moderations), and testing and tuning the responses, send the LLM blueprint to the model workshop. When you send a blueprint to the workshop, you can select up to twelve evaluation metrics (and any configured moderations).

Then, select any compliance tests to send to the workshop. Compliance tests sent to the model workshop are included when you register the custom model and generate compliance documentation.

To complete the transfer of evaluation metrics, configure the custom model in the model workshop.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.