Custom model training data assignment update¶
To enable feature drift tracking for a model deployment, you must add training data. Previously, you assigned training data directly to a custom model, meaning every version of that model used the same data; however, this assignment method was deprecated in DataRobot version 9.1 (with an additional announcement in DataRobot version 10.0) and removed in DataRobot version 10.1.
To enable feature drift tracking for a model deployment, you must add training data. Previously, you assigned training data directly to a custom model, meaning every version of that model used the same data; however, this assignment method was deprecated in March 2023 and removed in April 2024.
On this page, you can review a summary of the conversion process required during the deprecation period from March 2023 to April 2024 and the process for the removed "per model" assignment method:
During the deprecation period from March 2023 to April 2024, assigning training data to a model version required a conversion process:
Conversion no longer required
With the removal of the "per model" assignment method, the conversion step is no longer required. For more information on the current process for assigning training data to a custom model, see the documentation.
-
In Model Registry > Custom Model Workshop, in the Models list, select the model you want to add training data to.
-
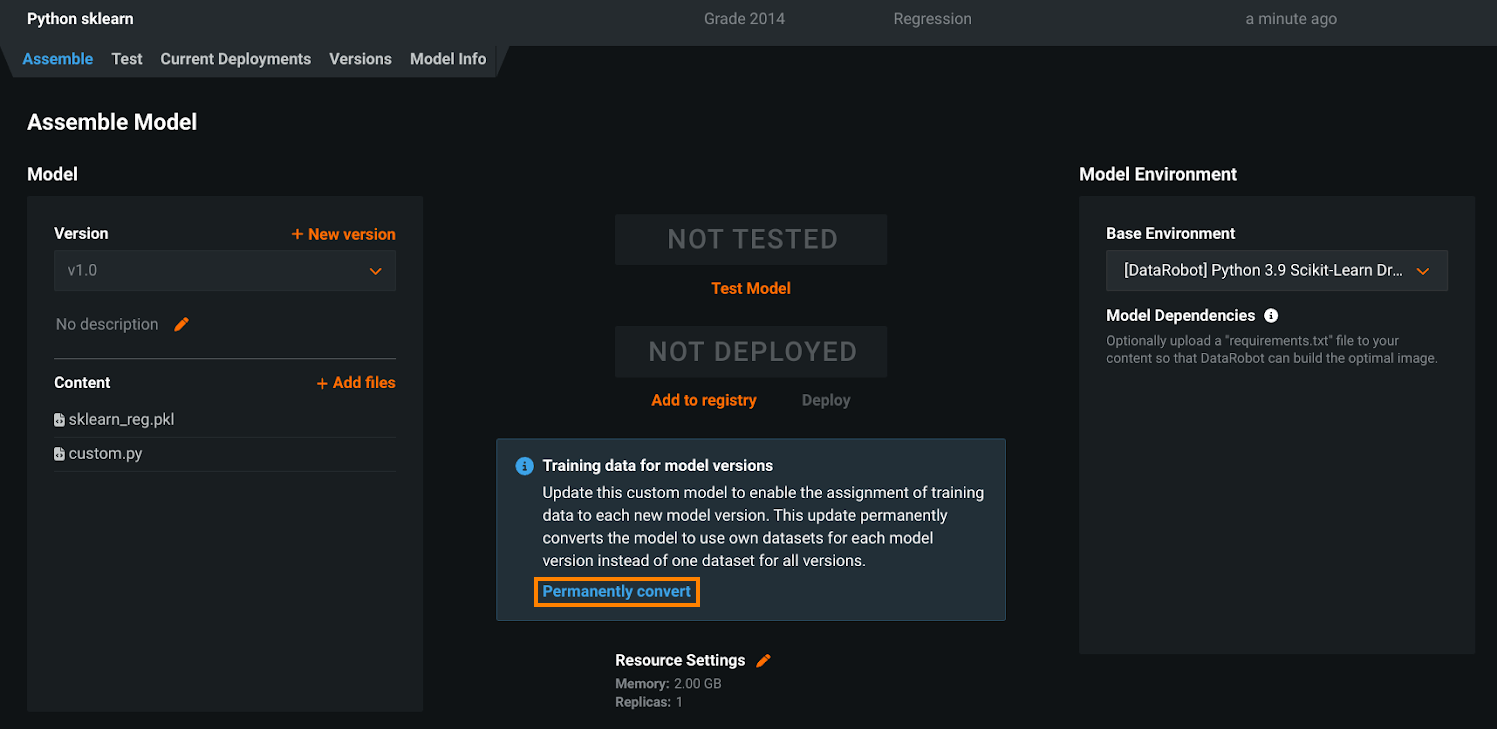
To assign training data to a custom model's versions, you must convert the model. On the Assemble tab, locate the Training data for model versions alert and click Permanently convert:
Training data assignment method conversion
Converting a model's training data assignment method is a one-way action. It cannot be reverted. After conversion, you can't assign training data at the model level. This change applies to the UI and the API. If your organization has any automation depending on "per model" training data assignment, before you convert a model, you should update any related automation to support the new workflow. As an alternative, you can create a new custom model to convert to the "per version" training data assignment method and maintain the deprecated "per model" method on the model required for the automation; however, you should update your automation before the deprecation process is complete to avoid gaps in functionality.
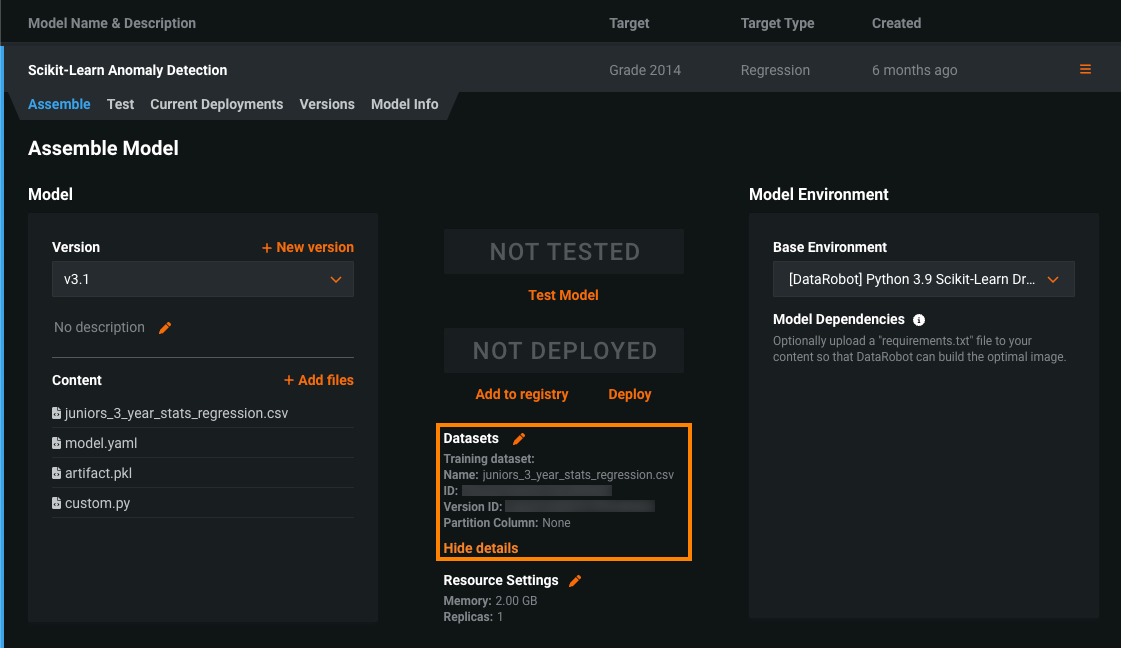
If the model was already assigned training data, after you convert the model, the Datasets section contains information about the existing training dataset.
-
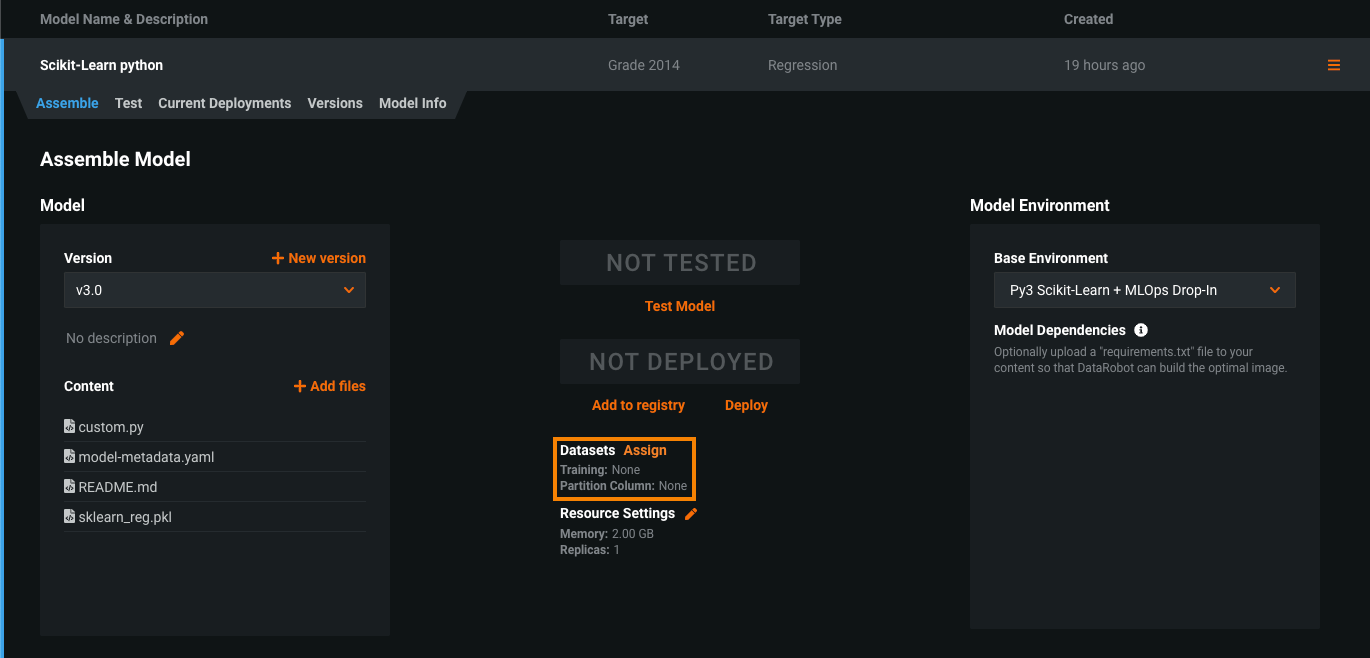
On the Assemble tab, next to Datasets:
-
If the model version doesn't have training data assigned, click Assign:
-
If the model version does have training data assigned, click the edit icon (
 ), and, in the Change Training Data dialog box, click the delete icon (
), and, in the Change Training Data dialog box, click the delete icon ( ) to remove the existing training data.
) to remove the existing training data.
-
-
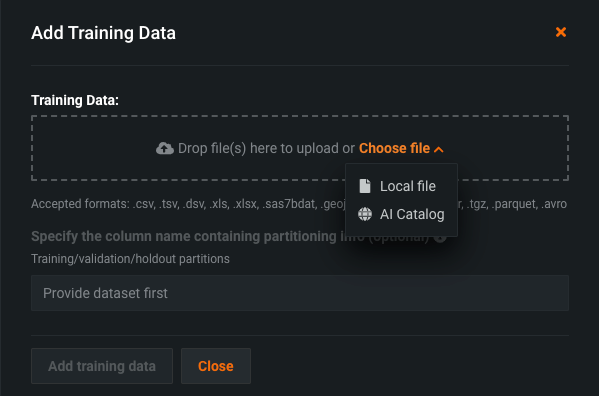
In the Add Training Data (or Change Training Data) dialog box, click and drag a training dataset file into the Training Data box, or click Choose file and do either of the following:
-
Click Local file, select a file from your local storage, and then click Open.
-
Click AI Catalog, select a training dataset you previously uploaded to DataRobot, and click Use this dataset.
Include features required for scoring
The columns in a custom model's training data indicate which features are included in scoring requests to the deployed custom model; therefore, once training data is available, any features not included in the training dataset aren't sent to the model. This requirement does not apply to predictions made while testing a custom model. Available as a preview feature, when you assemble a custom model in the NextGen experience, you can disable this behavior using the Column filtering setting.
-
-
(Optional) Specify the column name containing partitioning info for your data (based on training/validation/holdout partitioning). If you plan to deploy the custom model and monitor its data drift and accuracy, specify the holdout partition in the column to establish an accuracy baseline.
Specify partition column
You can track data drift and accuracy without specifying a partition column; however, in that scenario, DataRobot won't have baseline values. The selected partition column should only include the values
T,V, orH. -
When the upload is complete, click Add Training Data.
Training data assignment error
If the training data assignment fails, an error message appears in the new custom model version under Datasets. While this error is active, you can't create a model package to deploy the affected version. To resolve the error and deploy the model package, reassign training data to create a new version, or create a new version and then assign training data.
Deprecation notice
Previously, you assigned training data directly to a custom model, meaning every version of that model uses the same data; however, this assignment method was deprecated in March 2023 and removed in April 2024.
This workflow is removed and cannot be used:
-
In Model Registry > Custom Model Workshop, in the Models list, select the model you want to add training data to.
-
Click the Model Info tab and then click Add Training Data (due to the upcoming removal of this method, you should instead prepare to Permanently convert the custom model).
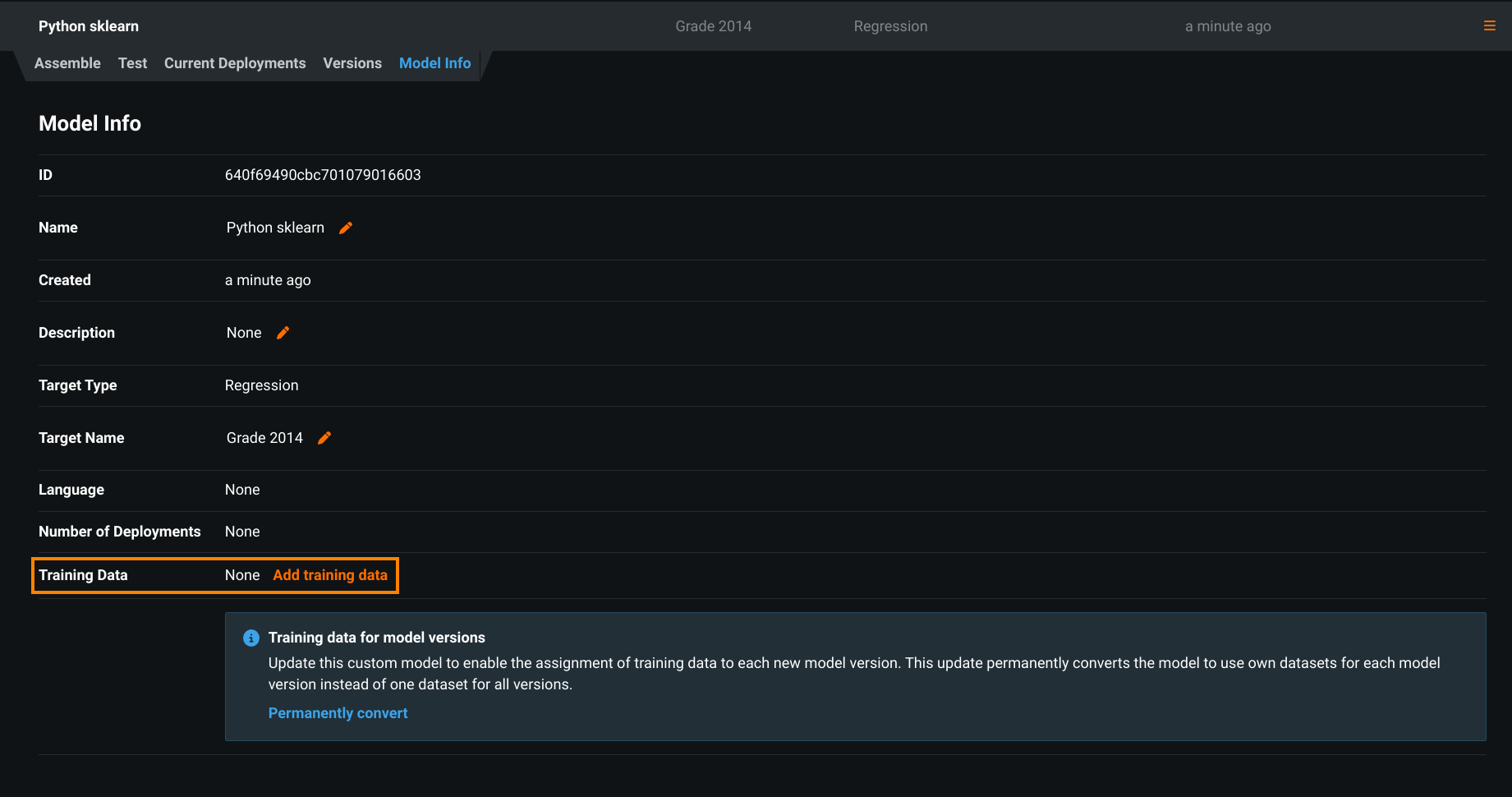
The Add Training Data dialog box appears, prompting you to upload training data.
-
Click Choose file to upload training data. (Optional) You can specify the column name containing the partitioning information for your data (based on training/validation/holdout partitioning). If you plan to deploy the custom model and monitor its accuracy, specify the holdout partition in the column to establish an accuracy baseline. You can still track accuracy without specifying a partition column; however, there will be no accuracy baseline. When the upload is complete, click Add Training Data.
Include features required for scoring
The columns in a custom model's training data indicate which features are included in scoring requests to the deployed custom model; therefore, once training data is available, any features not included in the training dataset aren't sent to the model. This requirement does not apply to predictions made while testing a custom model. Available as a preview feature, when you assemble a custom model in the NextGen experience, you can disable this behavior using the Column filtering setting.