May 2022¶
May 24, 2022
With the latest deployment, DataRobot's managed AI Platform deployment delivered the following new GA and preview features. See the deployment history for past feature announcements.
Features grouped by capability
GA¶
These feature have become generally available since the last release.
Bulk action capabilities added to the AI Catalog¶
With this release, you can share, tag, download, and delete multiple AI Catalog assets at once; making working with these assets more efficient. In the AI Catalog, select the box to the left of the asset(s) you want to manage, then select the appropriate action at the top.
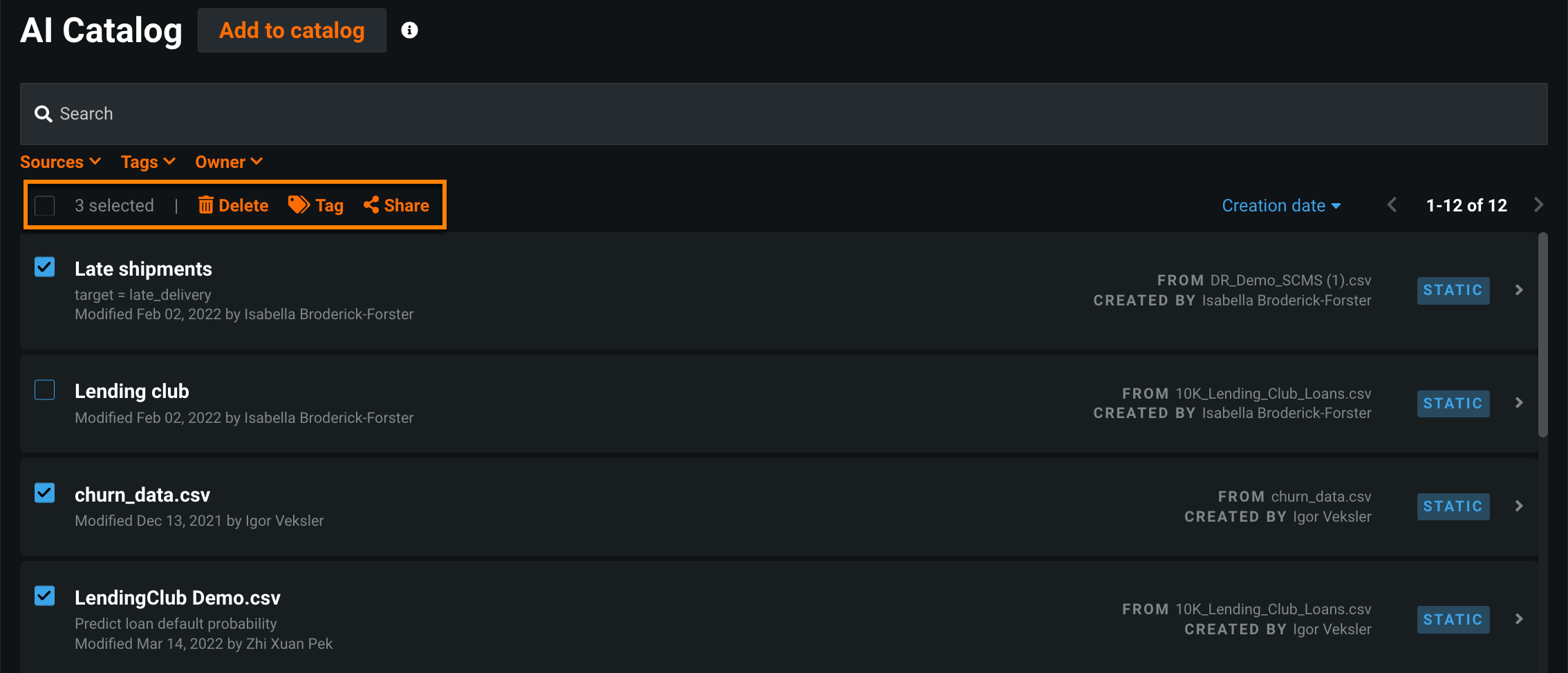
For more information, see the documentation for managing catalog assets.
Apache Kafka environment variables for Azure Even Hubs spoolers¶
The MLOPS_KAFKA_CONFIG_LOCATION environment variable was removed and replaced by new environment variables for Apache Kafka spooler configuration. These new environment variables eliminate the need for a separate configuration file and simplify support for Azure Event Hubs as a spooler type.
For more information on Apache Kafka spooler configuration, see the Apache Kafka environment variables reference.
For more information on leveraging the Apache Kafka spooler type to use a Microsoft Azure Event Hubs spooler, see the Azure Event Hubs spooler configuration reference.
Bias Mitigation functionality¶
Bias mitigation is now available as a generally available feature for binary classification projects. To clarify relationships between the parent model and any child models with mitigation applied, this release adds a table—Models with Mitigation Applied— accessible from the parent model on the Leaderboard.
Bias Mitigation works by augmenting blueprints with a pre- or post-processing task, causing the blueprint to then attempt to reduce bias across classes in a protected feature. You can apply mitigation either automatically (as part of Autopilot) or manually (after Autopilot completes). When run automatically, you set mitigation criteria as a part of the Bias and Fairness advanced option settings. Autopilot then applies mitigation to the top three Leaderboard models. Or, once Autopilot completes, you can apply mitigation to any non-blender, unmitigated model available from the Leaderboard. Finally, compare mitigated versus unmitigated models from the Bias vs Accuracy insight.

See the Bias Mitigation for more information.
Visual AI Image Embeddings visualization adds new filtering capabilities¶
The Understand > Image Embeddings tab helps to visualize what predicted results for your AI Project. Now, DataRobot calculates predicted values for the images and allows you to filter by those predictions. In addition, for select project types you can modify the prediction threshold (which may change the predicted label) and filter based on the new results. The image below shows all filtering options—new and existing—for all supported project types.
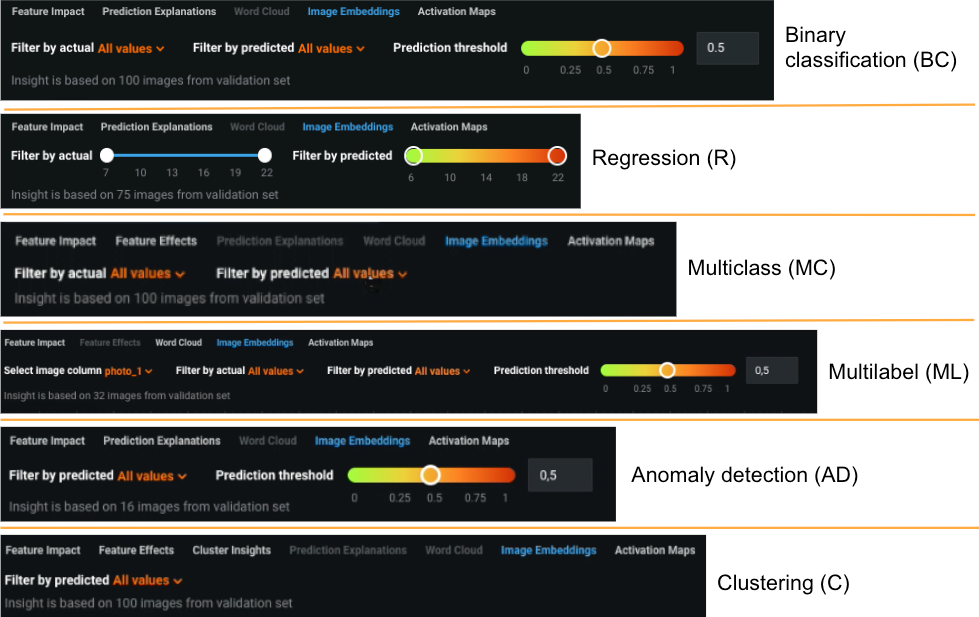
In addition, usability enhancements for clusters make exploring Visual AI results easier. With clustering, images display colored borders to indicate the predicted cluster.
Reorder scheduled modeling jobs¶
You can now change the order of scheduled modeling and prediction jobs in your project’s Worker Queue—allowing you to run more important jobs sooner.
For more information, see the Worker Queue documentation.
Creation date sort for the Deployments inventory¶
The deployment inventory on the Deployments page is now sorted by creation date (from most recent to oldest, as reported in the new Creation Date column). You can click a different column title to sort by that metric instead. A blue arrow appears next to the sort column's header, indicating if the order is ascending or descending.

Note
When you sort the deployment inventory, your most recent sort selection persists in your local settings until you clear your browser's local storage data. As a result, the deployment inventory is usually sorted by the column you selected last.
For more information, see the Deployment inventory documentation.
Model and Deployment IDs on the Overview tab¶
The Content section of the Overview tab lists a deployment's model and environment-specific information, now including the following IDs:

- Model ID: Copy the ID number of the deployment's current model.
- Deployment ID: Copy the ID number of the current deployment.
In addition, you can find a deployment's model-related events under History > Logs, including the creation and deployment dates and any model replacements events. From this log, you can copy the Model ID of any previously deployed model.
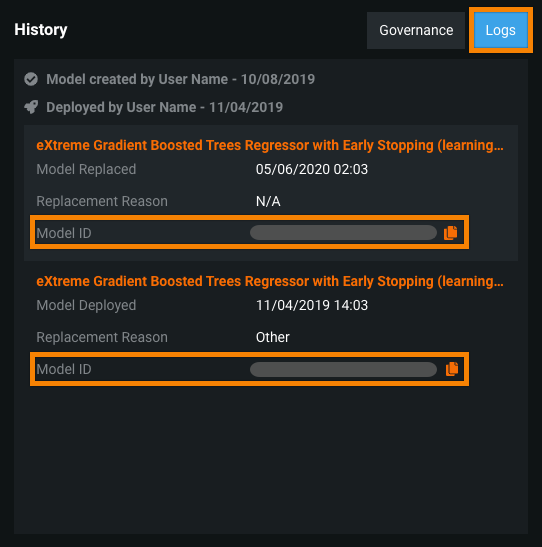
For more information, see the deployment Overview tab documentation.
Preview¶
These feature have entered the preview program since the last release. Contact your DataRobot representative or administrator for information on enabling any of them.
Improved performance when importing large datasets to the AI Catalog¶
When uploading a large dataset to the AI Catalog via the REST API, a data stage—intermediary storage that supports multipart upload of large datasets—to reduce the chance of failure, can be used. Once the dataset is whole and finalized in the data stage, it can then be pushed to the AI Catalog.
Text AI parameters now available via Composable ML¶
The ability to modify certain Text AI preprocessing tasks (Lemmatizer, PosTagging, and Stemming) is moving from the Advanced Tuning tab to blueprint tasks accessible via composable ML. The new Text AI preprocessing tasks unlock additional pathways to create unique text blueprints. For example, you can now use lemmatization in any text model that supports that preprocessing task instead of being limited to TF-IDF blueprints.
Required feature flag: Enable Text AI Composable Vertices
Prediction Explanations for multiclass projects¶
DataRobot now calculates explanations for each class in an XEMP-based multiclass classification project, both from the Leaderboard and from deployments. With multiclass, you can set the number of classes to compute for as well as select a mode from predicted or actual (if using training data) results or specify to see only a specific set of classes:

This capability helps especially with projects that require “humans-in-the-loop” to review multiple options. Previously comparisons required building several binary classification models and use scripting to evaluate. When building a multiclass project, Prediction Explanations can help improve models by highlighting, for example, where a model is too accurate (potential leakage?), where residuals are too large (some data could be missing?), or where a model can’t clearly distinguish two classes (some data could be missing?).
Updated NLP Autopilot with better language support¶
This release brings a host of natural language processing (NLP) improvements, the most impactful of which is the application of FastText for language detection at data ingest. Then, DataRobot generates the appropriate blueprints, with parameters optimized for that language. It adapts tokenization to the detected language, for better word clouds and interpretability. Additionally, specific blueprint training heuristics are triggered, so that accuracy-optimized Advanced Tuning settings are applied.
This feature works with multilingual use cases as well; Autopilot will detect multiple languages and adjust various blueprint settings for the greatest accuracy. Additionally, the following NLP enhancements are part of this release:
- New pre-trained BPE tokenizer (which can handle any language).
- Refined Keras blueprints for NLP for improved accuracy and training time.
- Various improvements across other NLP blueprints.
- New Keras blueprints (with the BPE tokenizer) in the Repository.
Clustering for segmented modeling¶
Clustering, an unsupervised learning technique, can be used to identify natural segments in your data. DataRobot now allows you to use clustering to discover the segments to be used for segmented modeling.

This workflow builds a clustering model and uses the model to help define the segments for a segmented modeling project.

A new Use for Segmentation tab lets you enable the clusters to be used in the segmented modeling project.

The clustering model is saved as a model package in the Model Registry, so that you can use it for subsequent segmented modeling projects.
Alternatively, you can save the clustering model to the Model Registry explicitly, without creating a segmented modeling project immediately. In this case, you can later create a segmented modeling project using the saved clustering model package.
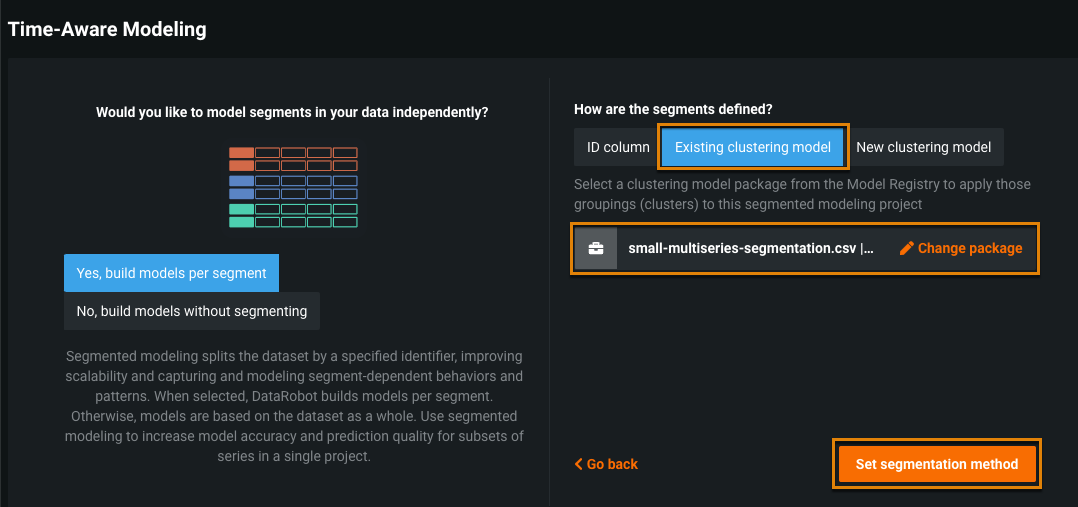
Required feature flag: Enable Time Series Clustering to Segmentation Flow
New blueprints for time series projects¶
DataRobot now supports native Prophet, ETS, and TBATS models for single series projects. For multiseries projects, these models can be used per series. To access a detailed description for a model, access the model blueprint (Models > Describe > Blueprint), click the model block in the blueprint, and click DataRobot Model Docs.
Required feature flags:
- Enable Native Prophet Blueprints for Time Series Projects
- Enable Series Performance Blueprints for Time Series Projects
Rate limit enforcement events in the MLOps agent event log¶
Now available for preview, on a deployment's Service Health tab, under Monitoring events, you can view MLOps agent events indicating that the API Rate limit was enforced. If you haven't installed and configured the MLOps agent, see the Installation and configuration guide.
Required feature flag: Enable MLOps management agent
Read the documentation.
Deprecation notices¶
The following deprecation announcements help track the state of changes to DataRobot's managed AI Platform.
Deprecated: H2O and SparkML Scaleout blueprints¶
In June 2021, DataRobot deprecated scaleout functionality by disallowing blueprint creation. Now, scaleout models have been fully disabled. All actions—including running a scaleout blueprint or getting predictions from a scaleout model—are no longer available from the product.
Deprecated: Custom task unaltered data feature lists¶
This deprecation notice refers to unaltered-data feature lists (also previously known as a super raw feature lists) which are currently available when using custom tasks. These lists will no longer be available beginning on October 25, 2022.
What’s changing?
Previously, when a blueprint contained only custom tasks, DataRobot created an unaltered-data feature list (in other words, all features from the dataset) for the project. After October 25, 2022, the unaltered-data feature lists will no longer be available.
How does this affect you?
After the disablement date, you will no longer be able to select unaltered-data feature lists and existing unaltered data feature lists will be removed. This may impact your existing projects, so carefully examine projects that are currently using unaltered-data feature lists and migrate them as appropriate.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.