Create custom models¶
Custom models are user-created, pretrained models that you can upload to DataRobot (as a collection of files) via the Workshop. You can assemble custom models in either of the following ways:
-
Create a custom model without the environment requirements and a
start_server.shfile on the Assemble tab. This type of custom model must use a drop-in environment. Drop-in environments contain the requirements andstart_server.shfile used by the model. They are provided by DataRobot in the workshop. -
Create a custom model with the environment requirements and a
start_server.shfile on the Assemble tab. This type of custom model can be paired with a custom or drop-in environment.
Be sure to review the guidelines for assembling a custom model before proceeding. If any files overlap between the custom model and the environment folders, the model's files will take priority.
Testing custom models
Once a custom model's file contents are assembled, you can test the contents locally for development purposes before uploading it to DataRobot. After you create a custom model in the workshop, you can run a testing suite from the Test tab.
Create a new custom model¶
To create a custom model in preparation for assembly:
-
Click Registry > Workshop. This tab lists the models you have created:
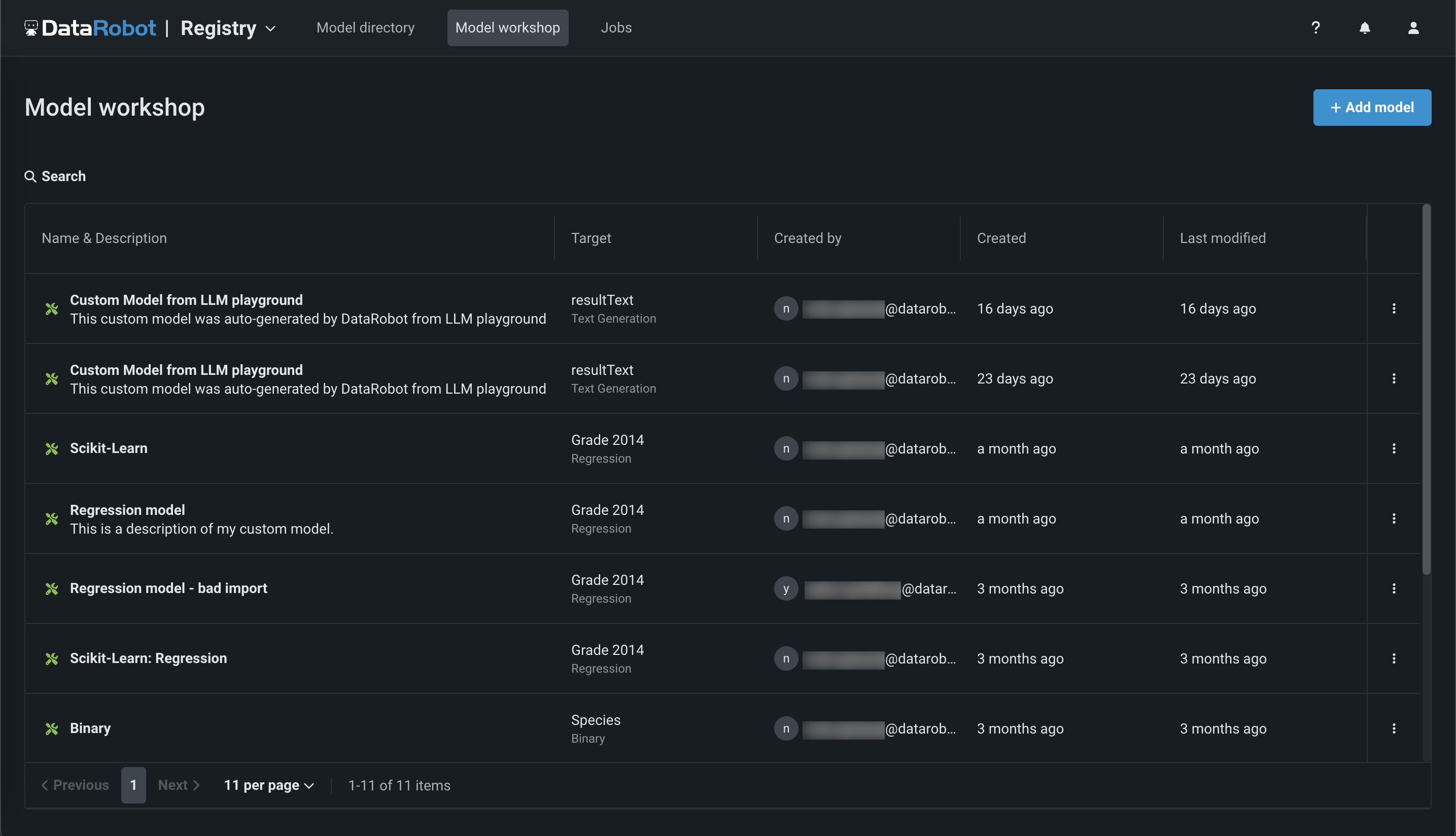
-
Click one of the following options (or the button when the custom model panel is open), depending on the currently selected tab:
-
From the All models tab, click + Add a model to open the Add a model panel without a Target type selected.
-
From the Agentic workflows tab, click + Add a workflow to open the Add a workflow panel with the Target type set to Agentic Workflow.
-
From the Tools tab, click + Add a tool to open the Add a tool panel with the Target type set to MCP Server.
-
-
On the Add a model page, enter the fields under Configure the model:
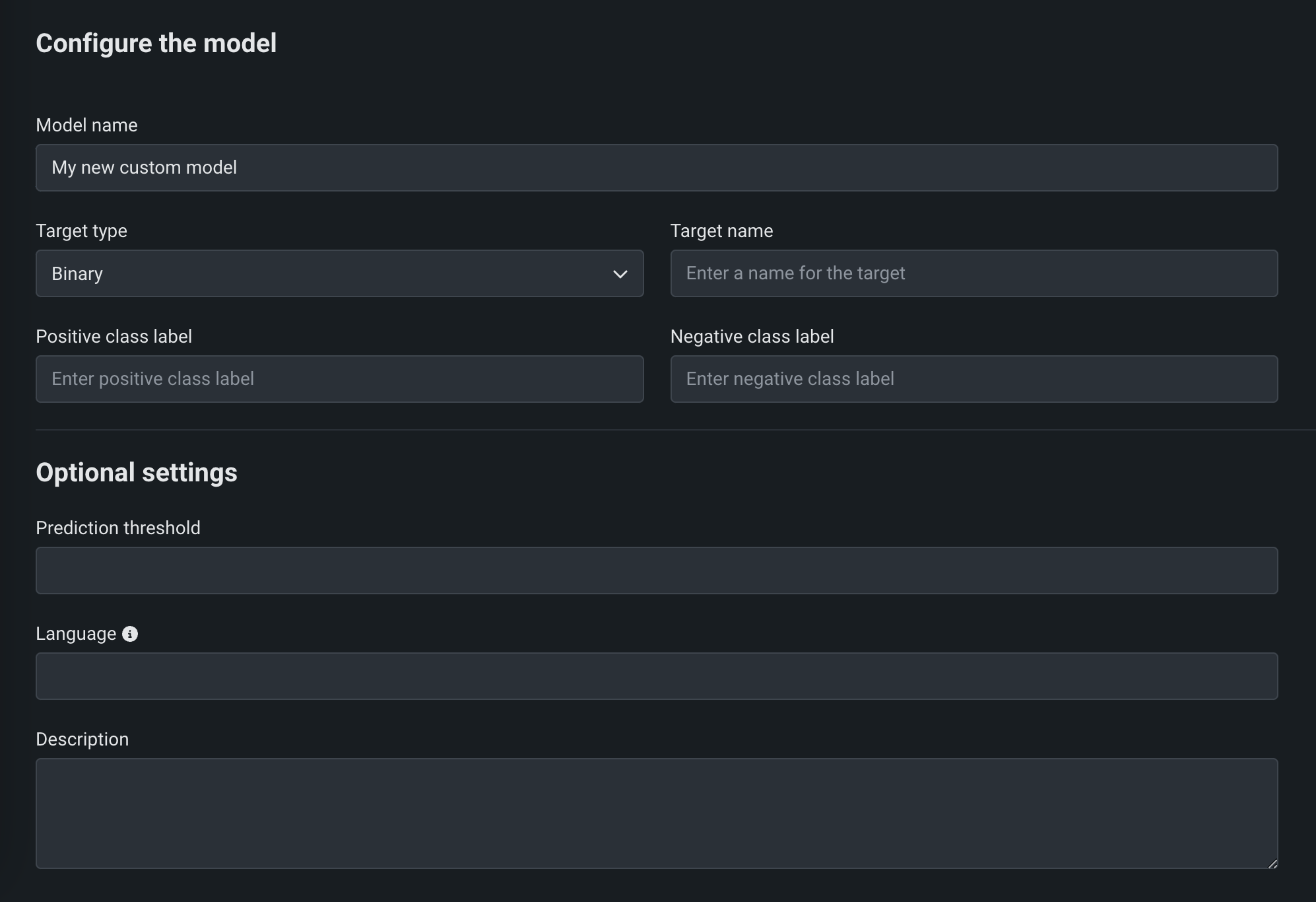
Field Description Model type The type of custom model to create, a standard Custom model or a Proxy for an external model. Model name A descriptive name for the custom model. Target type The type of prediction the model makes. Depending on the prediction type, you must configure additional settings: - Binary: For a binary classification model, enter the Positive class label and the Negative class label. Then, optionally, enter a Prediction threshold.
- Regression: No additional settings.
- Time Series (Binary): Preview feature. For a binary classification model, enter the Positive class label and the Negative class label and configure the time series settings. Then, optionally, enter a Prediction threshold.
- Time Series (Regression): Preview feature Configure the time series settings.
- Multiclass: For a multiclass classification model, enter or upload (
.csv,.txt) the Target classes for your target, one class per line. To ensure that the classes are applied correctly to your model's predictions, enter classes in the same order as your model's predicted class probabilities. - Multilabel: For a multilabel classification model, enter or upload (
.csv,.txt) the Target labels for your target, one label per line. To ensure that the labels are applied correctly to your model's predictions, enter labels in the same order as your model's predicted label probabilities. - Text Generation: Premium feature. No additional settings.
- Anomaly Detection: No additional settings.
- Unstructured: No additional settings. Unstructured models do not need to conform to a specific input/output schema and may use a different request format. Prediction drift, accuracy tracking, challengers, and humility are disabled for deployments with a "Unstructured" target type. Service health, deployment activity, and governance remain available.
- Vector Database: Preview feature No additional settings.
- Location: Premium feature. No additional settings.
- Agentic Workflow: Premium feature. No additional settings.
- MCP Server: Premium feature. No additional settings. An MCP server is a tool that allows you to expose the DataRobot API as a tool that can be used by agents.
Target name The dataset column the model predicts. Required for target types that use a target column, including multiclass and multilabel (along with Target classes or Target labels, respectively). For multiclass and multilabel models, the same column name belongs in model-metadata.yamlunderinferenceModel.targetName, and class or label names belong ininferenceModel.classLabels. This field is not used for anomaly detection models.Optional settings Prediction threshold For binary classification models, a decimal value ranging from 0 to 1. Any prediction score exceeding this value is assigned to the positive class. Language The programming language used to build the model. Description A description of the model's contents and purpose. Target type support for proxy models
If you select the Proxy model type, you can't select the Unstructured target type.
Premium
Vector database deployments are a premium feature, off by default and require GenAI experimentation. Contact your DataRobot representative or administrator for information on enabling this feature.
Premium
Agentic workflows are a premium feature. Contact your DataRobot representative or administrator for information on enabling the feature.
-
After completing the fields, click Add model.
The custom model opens to the Assemble tab.
Configure time series settings¶
Preview
Time series custom models are off by default. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Time Series Custom Models, Enable Feature Filtering for Custom Model Predictions
You can create time series custom models by configuring the following time series-specific fields, in addition to the fields required for binary classification and regression models. To create a time series custom model, select Time Series (Binary) or a Time Series (Regression) as a Target type, and configure the following settings while creating the model:
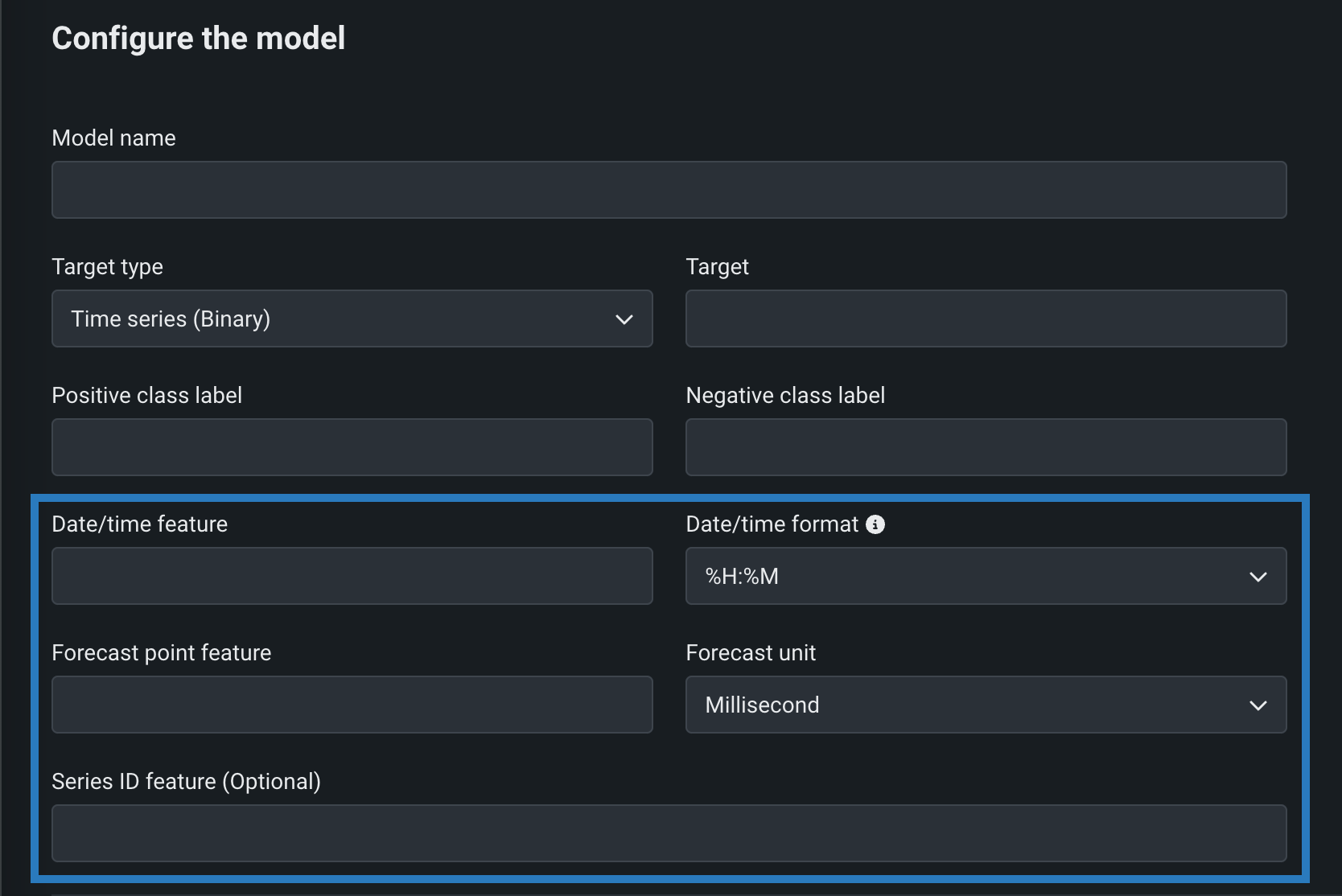
| Field | Description |
|---|---|
| Date/time feature | The column in the training dataset that contains date/time values of the given prediction row. |
| Date/time format | The format of the values in both the date/time feature column and the forecast point feature column, provided as a dropdown list of all possible values in GNU C library format. |
| Forecast point feature | The column in the training dataset that contains the point from which you are making a prediction. |
| Forecast unit | The time unit (seconds, days, months, etc.) that the time step uses, provided as a dropdown list of all possible values. |
| Series ID feature | Optional. For multiseries models, the column in the training dataset that identifies which series each row belongs to. |
When you make real-time predictions with a time series custom model, in the CSV serialization of the prediction response, any extra columns (beyond the prediction results) returned from the model have a column name suffixed with _OUTPUT.
Considerations for time series custom models
Time series custom models:
-
Cannot be selected as challengers.
-
Only support the model startup test during custom model testing.
-
Support real-time predictions, not batch predictions.
-
Do not support the portable prediction server (PPS).
Assemble the custom model¶
After you create a custom model, you can provide the required environment, dependencies, and files:
-
In the model you want to assemble, on the Assemble tab, navigate to the Environment section and select a model environment from the Base environment dropdown menu.
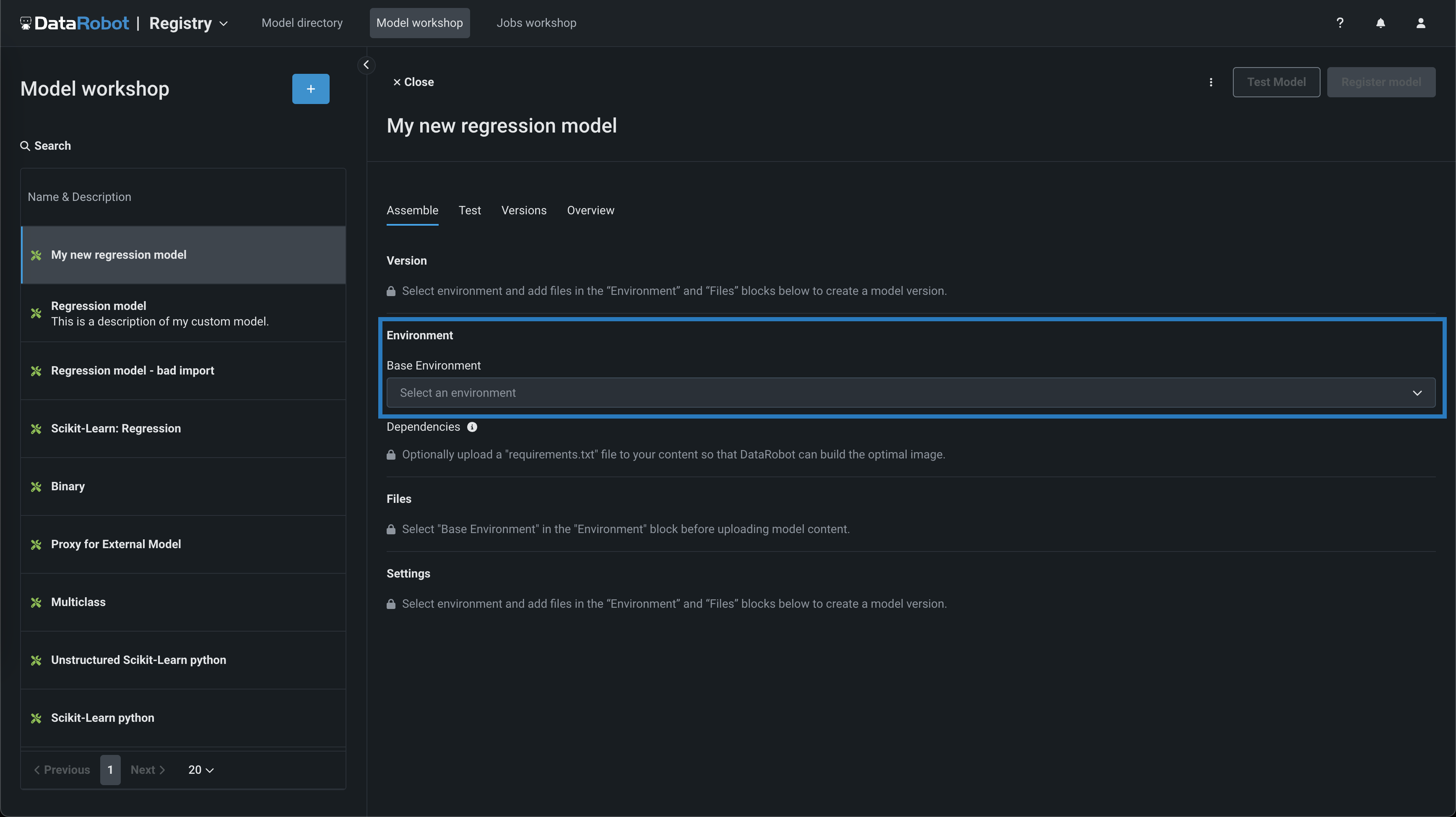
Model environments
The model environment is used for testing and deploying the custom model. The Base Environment dropdown list includes drop-in model environments and any custom environments that you can create. By default, the custom model uses the most recent version of the selected environment with a successful build.
-
To populate the Dependencies section, you can upload a
requirements.txtfile in the Files section, allowing DataRobot to build the optimal image. -
In the Files section, add the required custom model files. If you aren't pairing the model with a drop-in environment, this includes the custom model environment requirements and a
start_server.shfile. You can add files in several ways: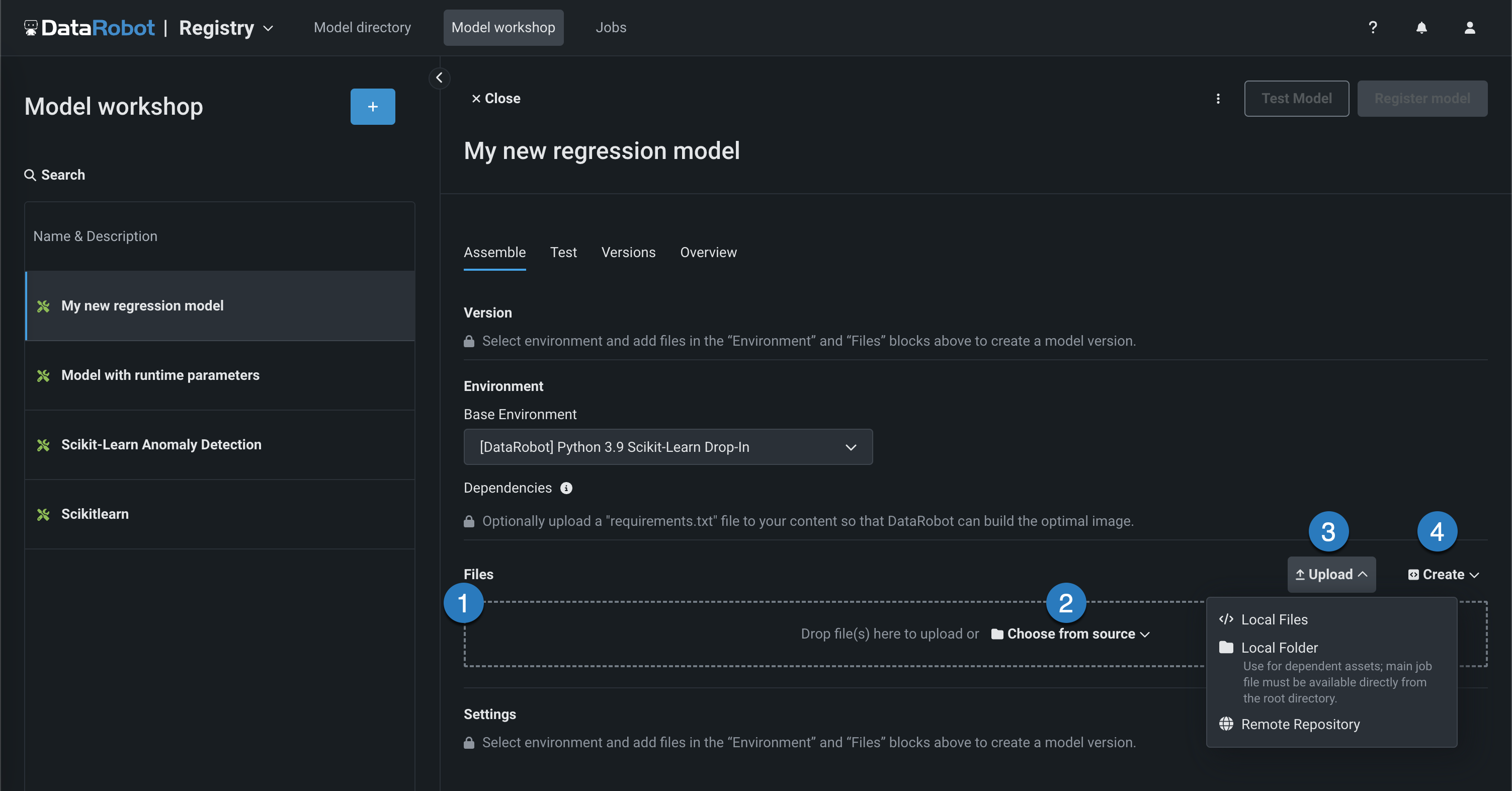
Element Description 1 Files Drag files into the group box for upload. 2 Choose from source Click to browse for Local Files or a Local Folder. To pull files from a remote repository, use the Upload menu. 3 Upload Click to browse for Local Files or a Local Folder or to pull files from a remote repository. 4 Create Create a new file, empty or as a template, and save it to the custom model: - Create model-metadata.yaml: Creates a starter
model-metadata.yamlfor this model’s target type (including requiredinferenceModelfields for binary, multiclass, and multilabel). You can addruntimeParameterDefinitionsin the same file. - Create blank file: Creates an empty file. Click the edit icon () next to Untitled to provide a file name and extension, then add your custom contents.
File replacement
If you add a new file with the same name as an existing file, when you click Save, the old file is replaced in the Files section.
Model file location
If you add files from a Local Folder, make sure the model file is already at the root of the custom model. Uploaded folders are for dependent files and additional assets required by your model, not the model itself. Even if the model file is included in the folder, it will not be accessible to DataRobot unless the file exists at the root level. The root file can then point to the dependencies in the folder.
- Create model-metadata.yaml: Creates a starter
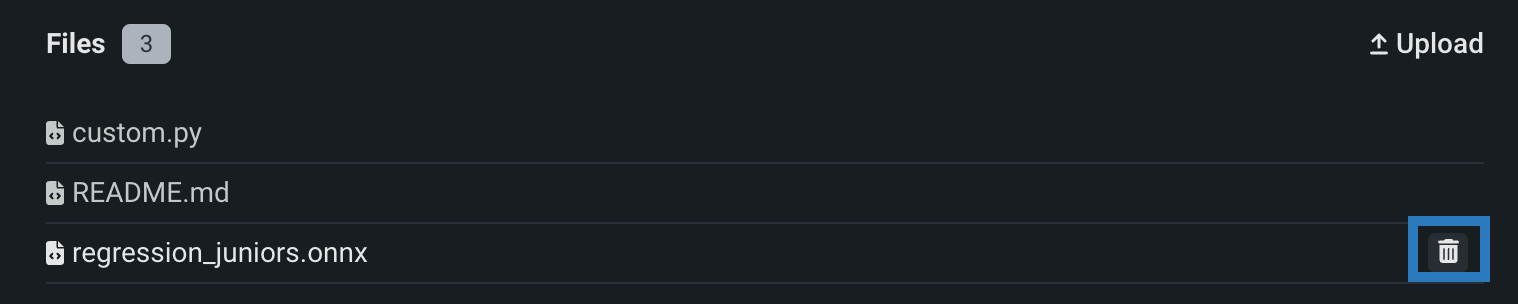
If you incorrectly add one or more files or folders to the Assemble tab, in the Files section, you can click the delete () icon next to each file or folder to remove it from the custom model.
Connect to remote repositories¶
In the Files section, if you click Upload > Remote Repository, the Add the content from remote repository panel opens. You can click Remote Repositories to register a new remote repository (A), or select an existing remote repository (B):
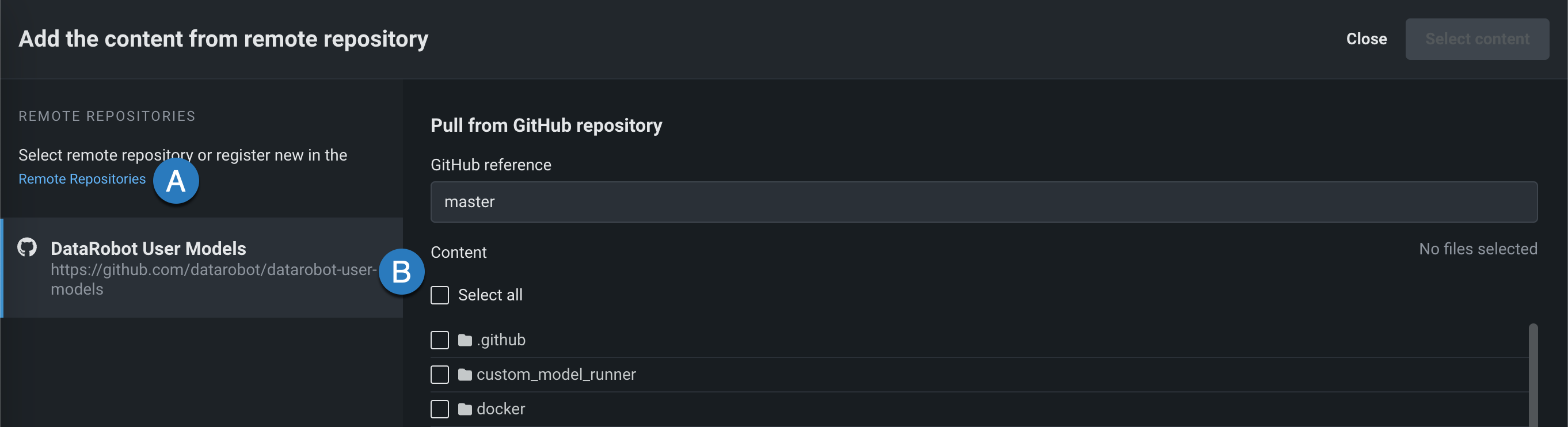
After registering and selecting a repository, you can select the checkbox for each file or folder you want to upload, and then click Select content:
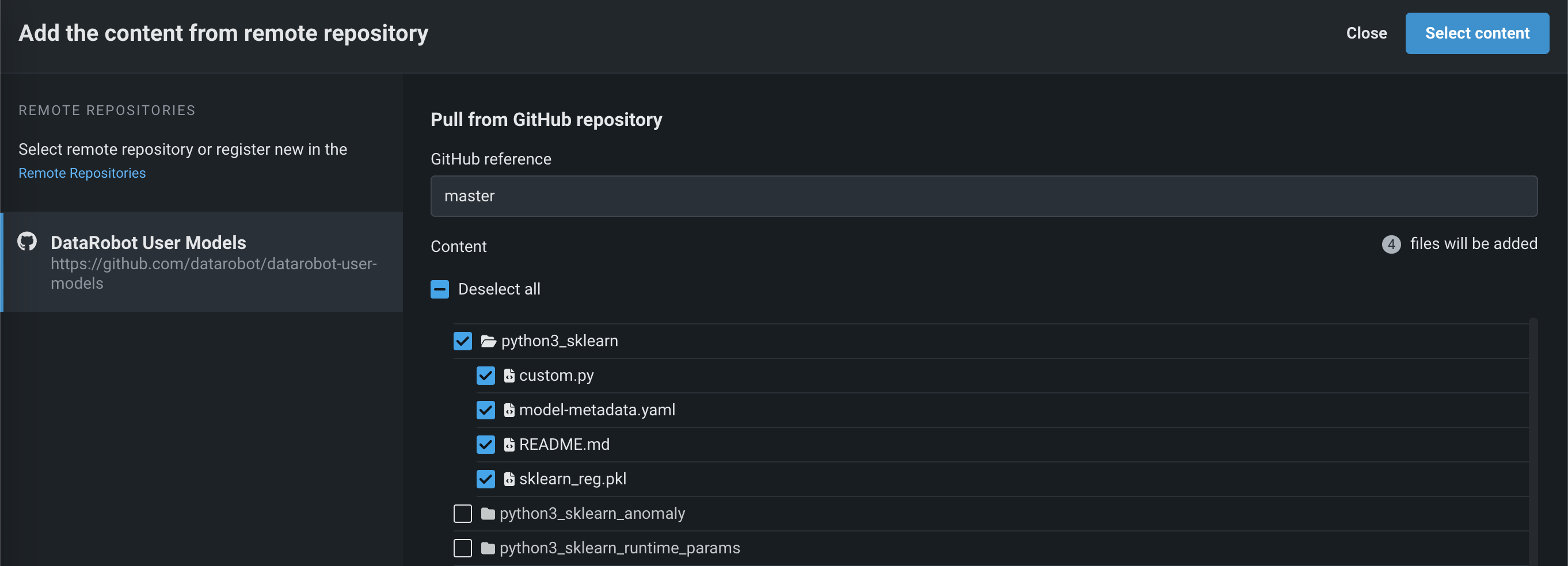
The selected files are pulled into the Files section.
Drop-in environments¶
DataRobot provides drop-in environments in the workshop, defining the required libraries and providing a start_server.sh file. Each environment is prefaced with [DataRobot] in the Environment section of the Workshop's Assemble tab.
The available drop-in environments depend on your DataRobot installation; however, the table below lists commonly available public drop-in environments with templates in the DRUM repository. Depending on your DataRobot installation, the Python version of these environments may vary, and additional non-public environments may be available for use.
Drop-in environment security
Starting with the March 2025 Managed AI Platform release, most general purpose DataRobot custom model drop-in environments are security-hardened container images. When you require a security-hardened environment for running custom jobs, only shell code following the POSIX-shell standard is supported. Security-hardened environments following the POSIX-shell standard support a limited set of shell utilities.
Drop-in environment security
Starting with the 11.0 Self-Managed AI Platform release, most general purpose DataRobot custom model drop-in environments are security-hardened container images. When you require a security-hardened environment for running custom jobs, only shell code following the POSIX-shell standard is supported. Security-hardened environments following the POSIX-shell standard support a limited set of shell utilities.
| Environment name & example | Compatibility & artifact file extension |
|---|---|
| Python 3.X | Python-based custom models and jobs. You are responsible for installing all required dependencies through the inclusion of a requirements.txt file in your model files. |
| Python 3.X GenAI Agents | Generative AI models (Text Generation or Vector Database target type) |
| Python 3.X ONNX Drop-In | ONNX models and jobs (.onnx) |
| Python 3.X PMML Drop-In | PMML models and jobs (.pmml) |
| Python 3.X PyTorch Drop-In | PyTorch models and jobs (.pth) |
| Python 3.X Scikit-Learn Drop-In | Scikit-Learn models and jobs (.pkl) |
| Python 3.X XGBoost Drop-In | Native XGBoost models and jobs (.pkl) |
| Python 3.X Keras Drop-In | Keras models and jobs backed by tensorflow (.h5) |
| Java Drop-In | DataRobot Scoring Code models (.jar) |
| R Drop-in Environment | R models trained using CARET (.rds) Due to the time required to install all libraries recommended by CARET, only model types that are also package names are installed (e.g., brnn, glmnet). Make a copy of this environment and modify the Dockerfile to install the additional, required packages. To decrease build times when you customize this environment, you can also remove unnecessary lines in the # Install caret models section, installing only what you need. Review the CARET documentation to check if your model's method matches its package name. (Log in to GitHub before clicking this link.) |
scikit-learn
All Python environments contain scikit-learn to help with preprocessing (if necessary), but only scikit-learn can make predictions on sklearn models.
When using a drop-in environment, your custom model code can reference several environment variables injected to facilitate access to the DataRobot Client and MLOps Connected Client:
| Environment Variable | Description |
|---|---|
MLOPS_DEPLOYMENT_ID |
If a custom model is running in deployment mode (i.e., the custom model is deployed), the deployment ID is available. |
DATAROBOT_ENDPOINT |
If a custom model has public network access, the DataRobot endpoint URL is available. |
DATAROBOT_API_TOKEN |
If a custom model has public network access, your DataRobot API token is available. |
Configure evaluation and moderation¶
Premium
Evaluation and moderation guardrails are a premium feature. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Moderation Guardrails (Premium), Enable Global Models in the Model Registry (Premium), Enable Additional Custom Model Output in Prediction Responses
Evaluation and moderation guardrails help your organization block prompt injection and hateful, toxic, or inappropriate prompts and responses. It can also prevent hallucinations or low-confidence responses and, more generally, keep the model on topic. In addition, these guardrails can safeguard against the sharing of personally identifiable information (PII). Many evaluation and moderation guardrails connect a deployed text generation model (LLM) to a deployed guard model. These guard models make predictions on LLM prompts and responses and report these predictions and statistics to the central LLM deployment. To use evaluation and moderation guardrails, first, create and deploy guard models to make predictions on an LLM's prompts or responses; for example, a guard model could identify prompt injection or toxic responses. Then, when you create a custom model with the Text Generation target type, define one or more evaluation and moderation guardrails.
To select and configure evaluation and moderation guardrails, on the Assemble tab for a custom model with the Text Generation target type, scroll to Evaluation and moderation and click Configure:
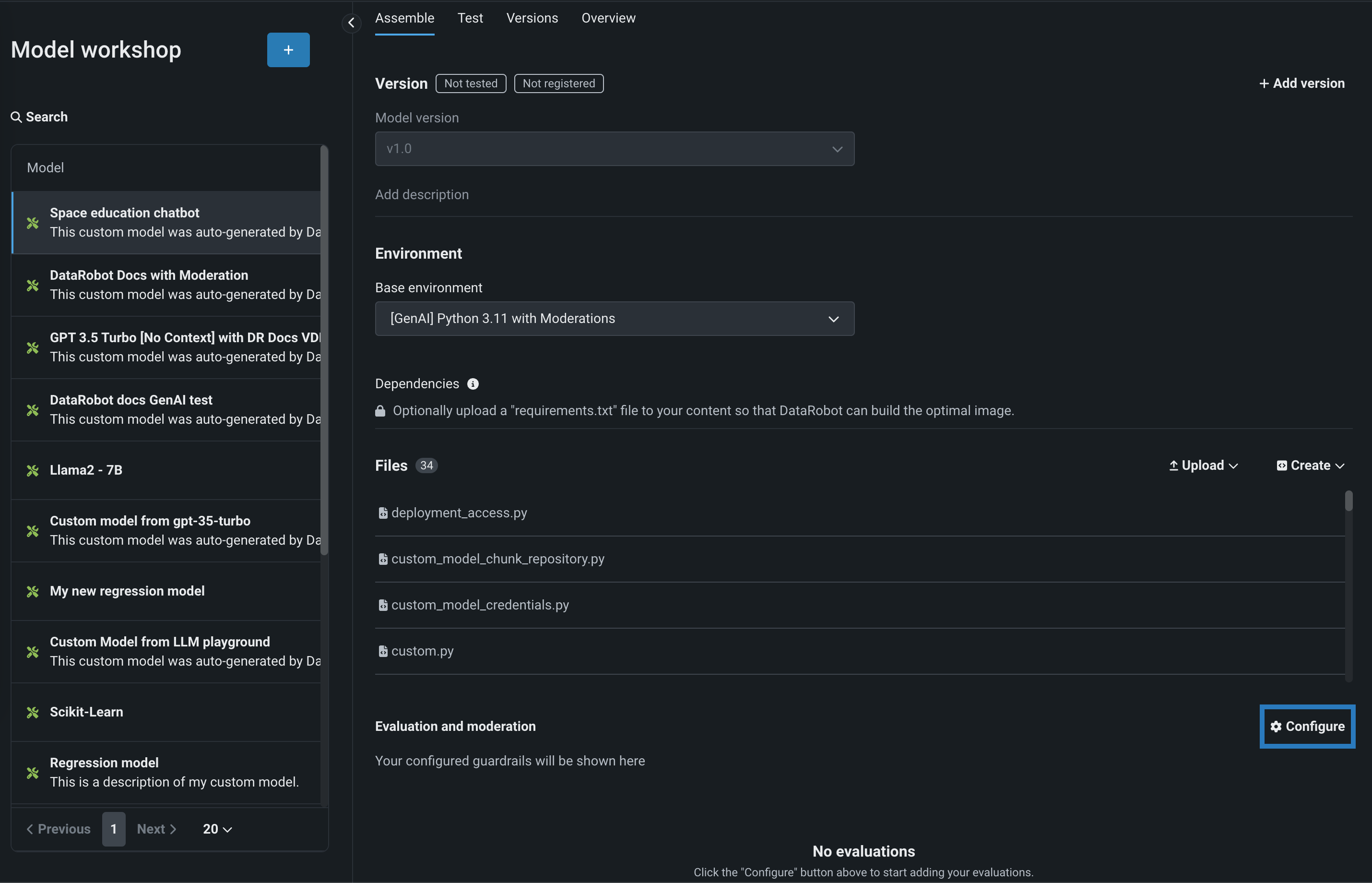
In the Configure evaluation and moderation panel, click a metric card to configure the required settings for the evaluation metric:
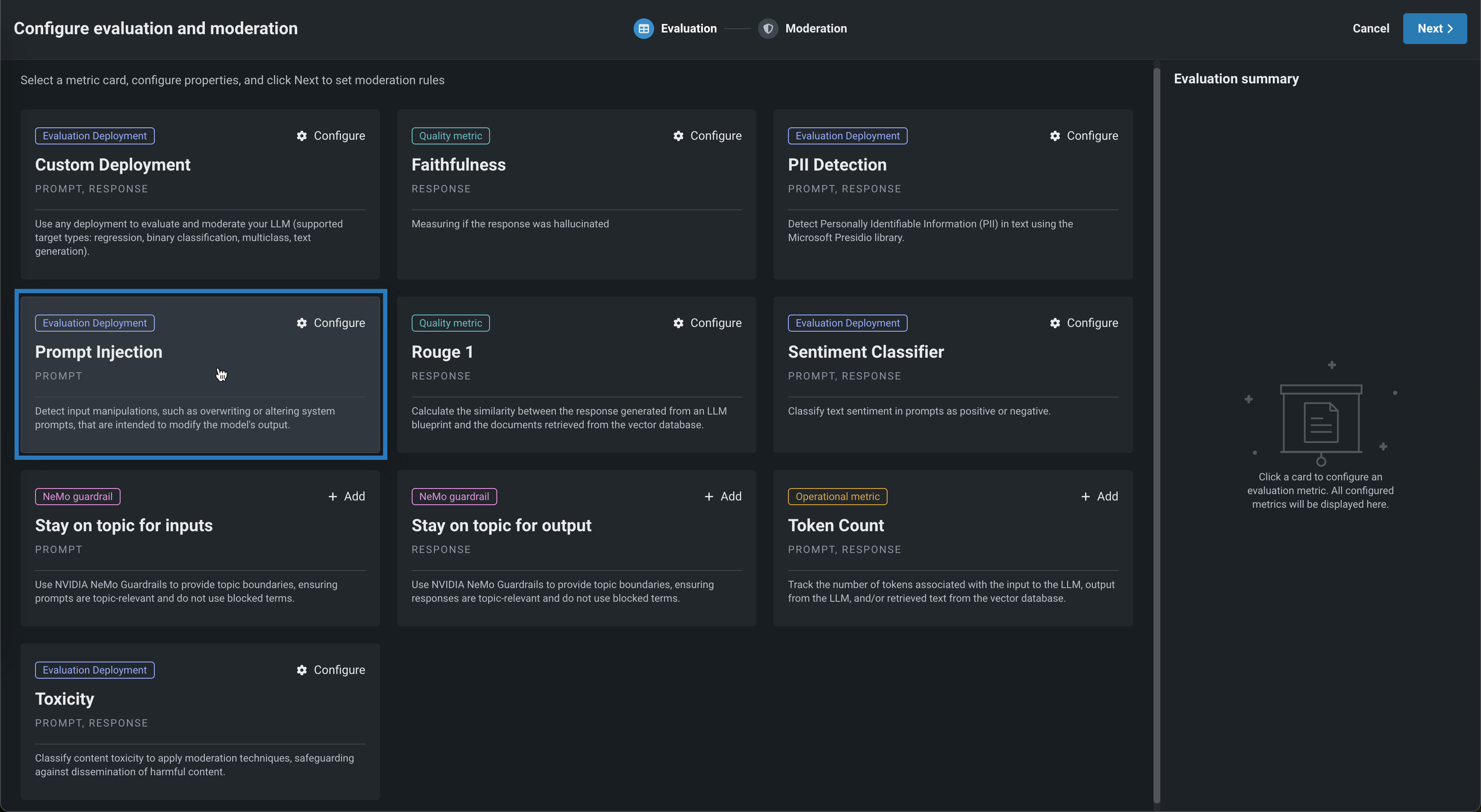
If you enabled Use metric as guard, In the Moderation section, configure the moderation settings:
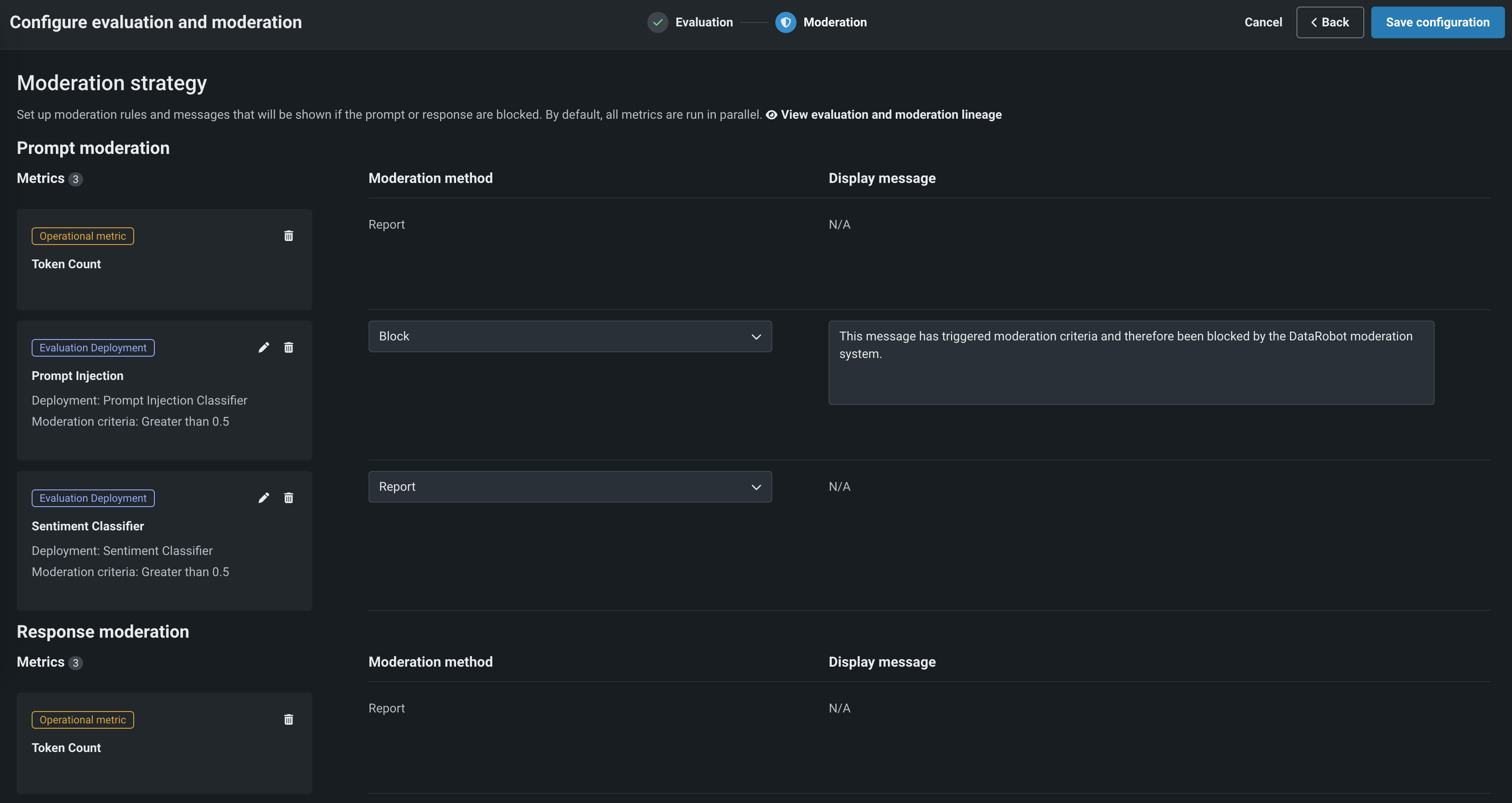
Next, click Add to return to the evaluation selection page. From there, add another metric or click Save configuration.
For a more detailed walkthrough, see Configure evaluation and moderation.
After adding guardrails to a text generation custom model, you can test, register, and deploy the model to make predictions in production. After you make predictions, you can view the evaluation metrics on the Custom metrics tab and prompts, responses, and feedback (if configured) on the Data exploration tab.
Define runtime parameters¶
In the Runtime parameters section, create runtime parameters to provide environment variables to a model at runtime. In addition, if you defined any runtime parameters through runtimeParameterDefinitions in the model-metadata.yaml file, you can manage them here. Parameters are injected into containers in two ways:
- As standard environment variables without prefixes or JSON parsing for simple types (so you can use
os.getenvto access environment variables without thedatarobot-drumlibrary). - For backward compatibility also in the legacy prefixed (
MLOPS_RUNTIME_PARAM_*) and JSONified format.
Parameters created via the UI persist and merge when you upload new code versions, ensuring a seamless development flow.
Runtime parameter considerations
The system uses a blocklist of reserved patterns (e.g., DRUM_*, MLOPS_*, KUBERNETES_*), managed in the dynamic configuration. Matching supports the * wildcard (not full regular expression syntax). Reserved names aren't blocked entirely: if a runtime parameter uses a reserved name, the UI displays a warning. How the variable is exposed depends on the context:
- Custom models: Only in prefixed (
MLOPS_RUNTIME_PARAM_*) and JSONified format—not as a raw (unprefixed) environment variable, to prevent system conflicts. - Custom apps: Prefixed, but values are not packed into a JSON payload (except for credentials).
- Custom jobs: No prefix and no JSON payload (except for credential types); the variable is available as a raw environment variable.
For credential-type runtime parameters, the system automatically unpacks JSON fields into separate environment variables rather than a single string. For example, a credential named MAIN_AWS_CREDENTIAL with the following JSON structure:
{"awsAccessKeyId": "<your-key-id>", "awsSecretAccessKey": "<your-access-key>"}
is unpacked into the following environment variables, combining the parameter name + JSON key, in uppercase:
MAIN_AWS_CREDENTIAL_AWS_ACCESS_KEY_ID="<your-key-id>"
MAIN_AWS_CREDENTIAL_AWS_SECRET_ACCESS_KEY="<your-access-key>"
For single-field credential types (for example, api_token, bearer, or gcp), the injected environment variable uses the bare runtime parameter name (MY_CRED), not the parameter name plus the credential field name (for example, not MY_CRED_API_TOKEN). Multi-field credential types (for example, basic or s3) keep the existing suffixed behavior: one variable per field, named {PARAMETER_NAME}_{FIELD_NAME} in uppercase snake case (for example, MY_CRED_USERNAME and MY_CRED_PASSWORD, or the AWS keys in the example above). JSON-encoded runtime parameter variables (for example, MLOPS_RUNTIME_PARAMETERS_OPEN_AI_API) are unchanged; only the flat variable for a single-field secret uses the bare parameter name.
Access runtime parameters in containers
For programmatic access to runtime parameters in containers, use DataRobotAppFrameworkBaseSettings as documented in the SDK API reference.
Add parameters¶
To add a new runtime parameter definition, click + Add runtime parameter.
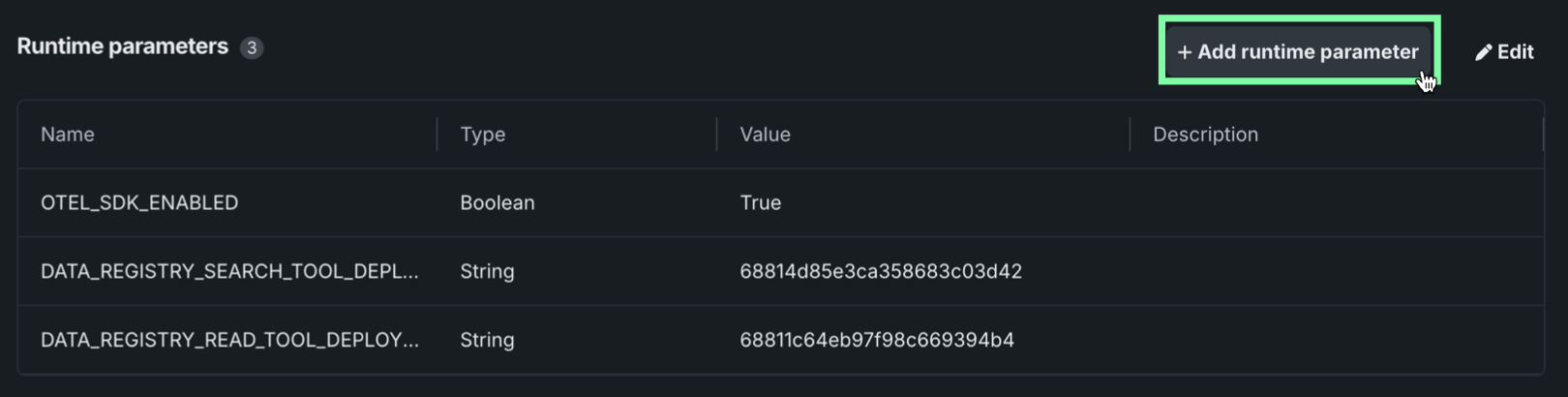
In the Add new runtime parameter dialog box, configure the runtime parameter Name, Type, Value, and, optionally, provide a Description.
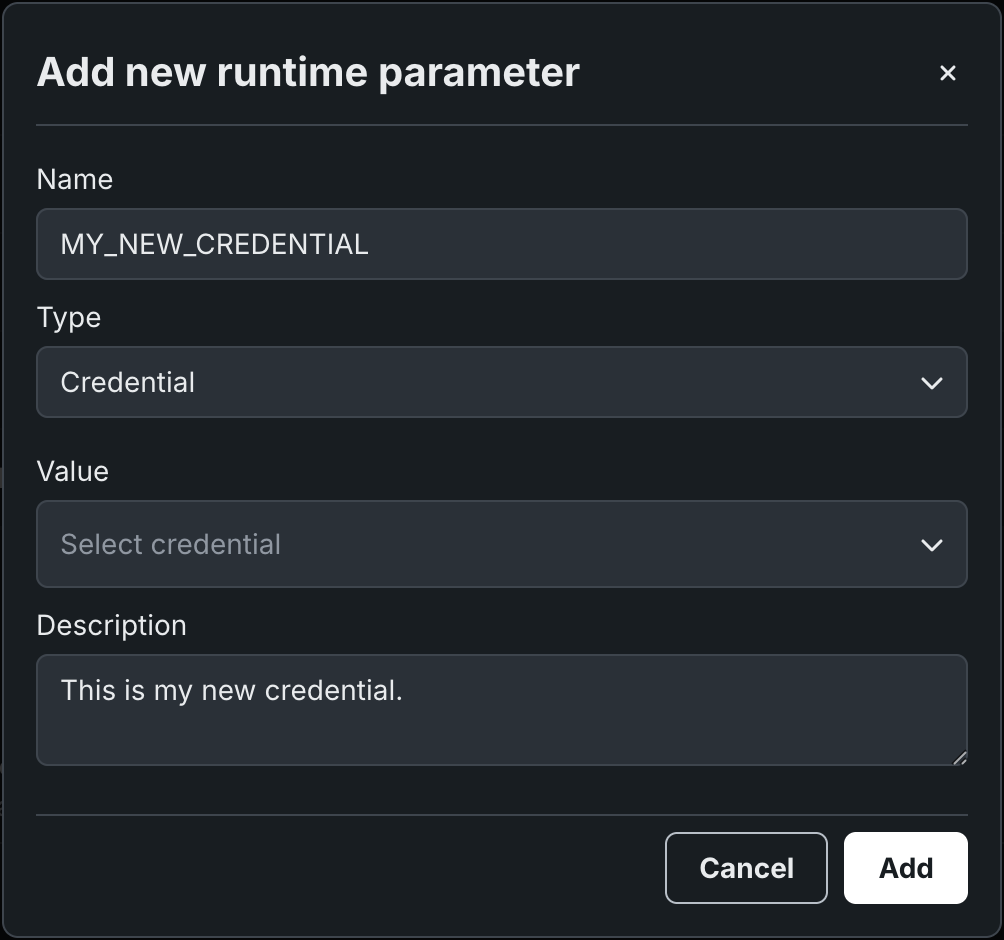
After configuring the required fields, click Add, repeat the process for any additional parameters, then click Save.
Edit parameters¶
To edit a runtime parameter definition, click Edit.
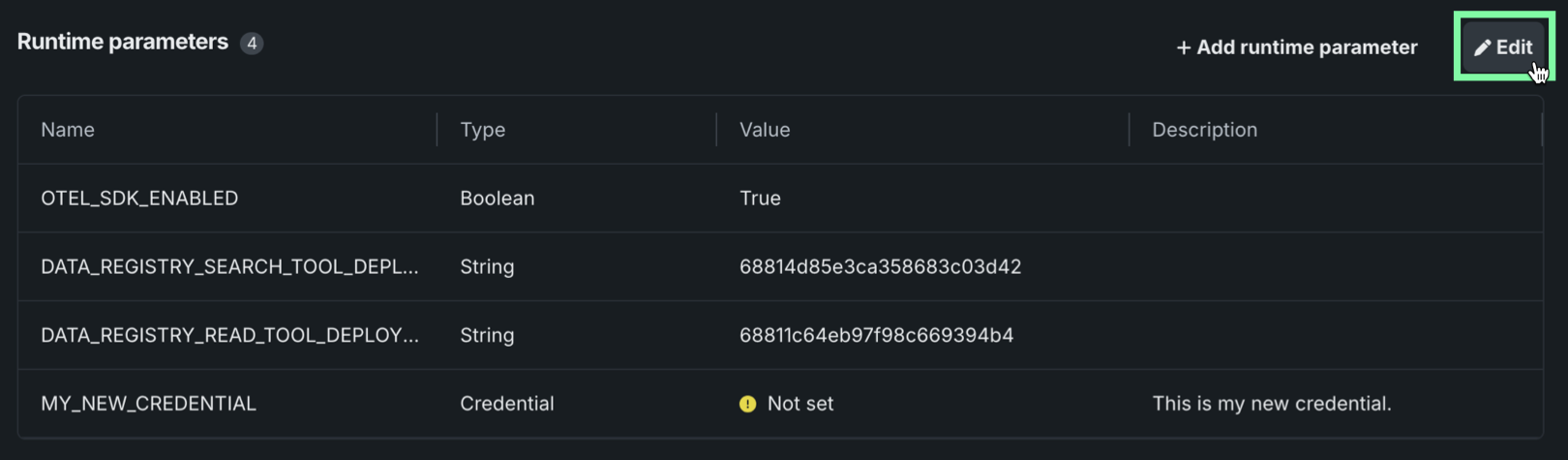
In the Runtime parameter table, define a runtime parameter Value or, in the last column, access the action icons.
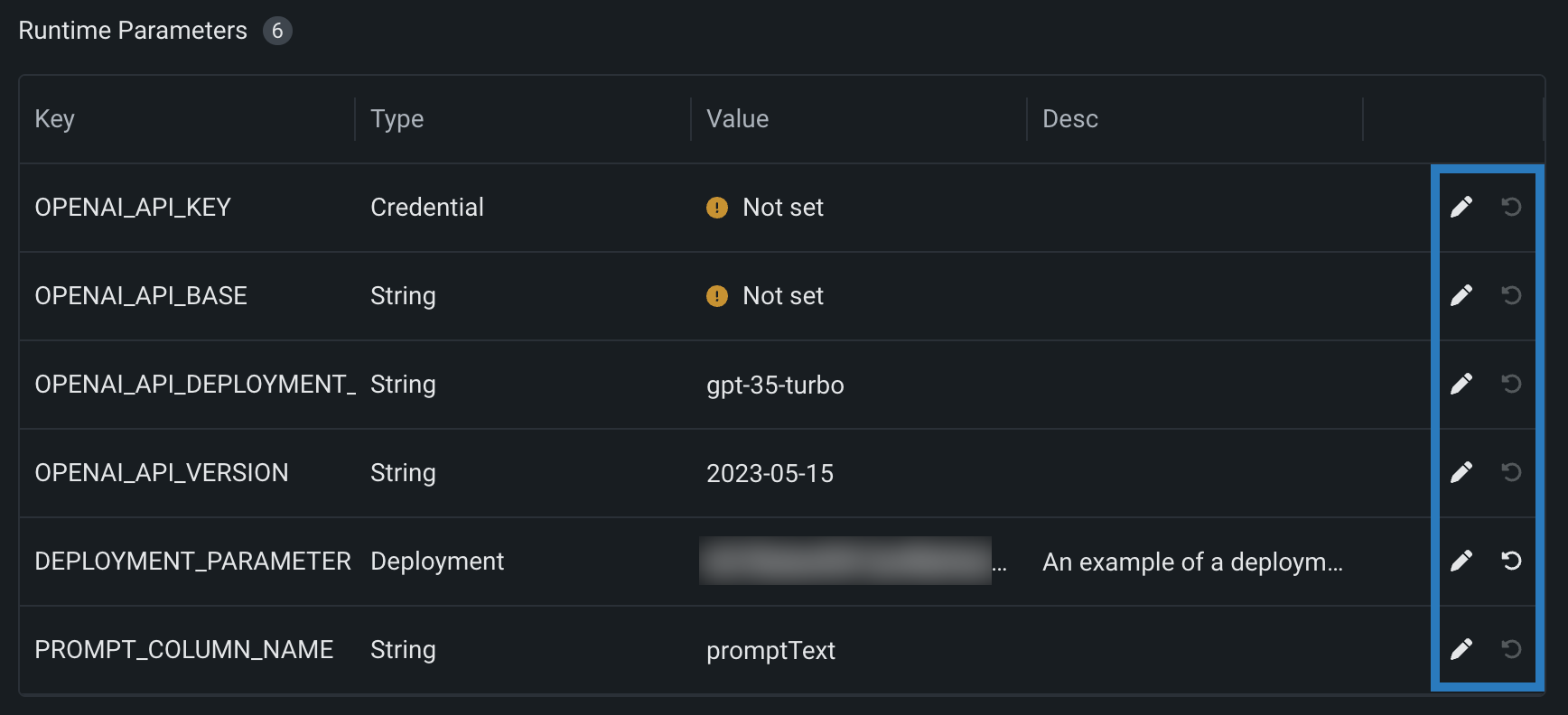
| Icon | Setting | Description |
|---|---|---|
| Revert changes | Reset the runtime parameter's Value to the defaultValue set in the model-metadata.yaml file, or to an empty state. |
|
| Delete | Delete the runtime parameter definition. |
If any runtime parameters have allowEmpty: false in the definition without a defaultValue, you must set a value before registering the custom model.
Premium: DataRobot LLM gateway access
To use the LLM gateway for a custom model with the agentic workflow target type, the ENABLE_LLM_GATEWAY_INFERENCE runtime parameter must be provided in the model-metadata.yaml file and set to true.
For more information on how to define runtime parameters and use them in your custom model code, see the Define custom model runtime parameters documentation.
Assign custom model datasets¶
To enable feature drift tracking for a model deployment, you must add training data. To do this, assign training data to a model version. The method for providing training and holdout datasets for unstructured custom inference models requires you to upload the training and holdout datasets separately. Additionally, these datasets cannot include a partition column.
File size warning
The file size limit for custom model training data uploaded to DataRobot is 1.5GB.
Considerations for training data prediction rows count
Training data uploaded to a custom model is used to compute Feature Impact, drift baselines, and Prediction Explanation previews. To perform these calculations, DataRobot automatically splits the uploaded training data into partitions for training, validation, and holdout (i.e., T/V/H) in a 60/20/20 ratio. Alternatively, you can manually provide a partition column in the training dataset to assign predictions, row-by-row, to the training (T), validation (V), or holdout (H) partitions.
Prediction Explanations require 100 rows in the validation partition, which—if you don’t define your own partitioning—requires the provided training dataset to contain a minimum of 500 rows. If the training data and partition ratio (defined automatically or manually) result in a validation partition containing fewer than 100 rows, Prediction Explanations are not calculated. While you can still register and deploy the model—and the deployment can make predictions—if you request predictions with explanations, the deployment returns an error.
To assign training data to a custom model after you define the Environment and Files:
-
On the Assemble tab, in the Settings section, under Datasets:
-
If the model version doesn't have training data assigned, click Assign.
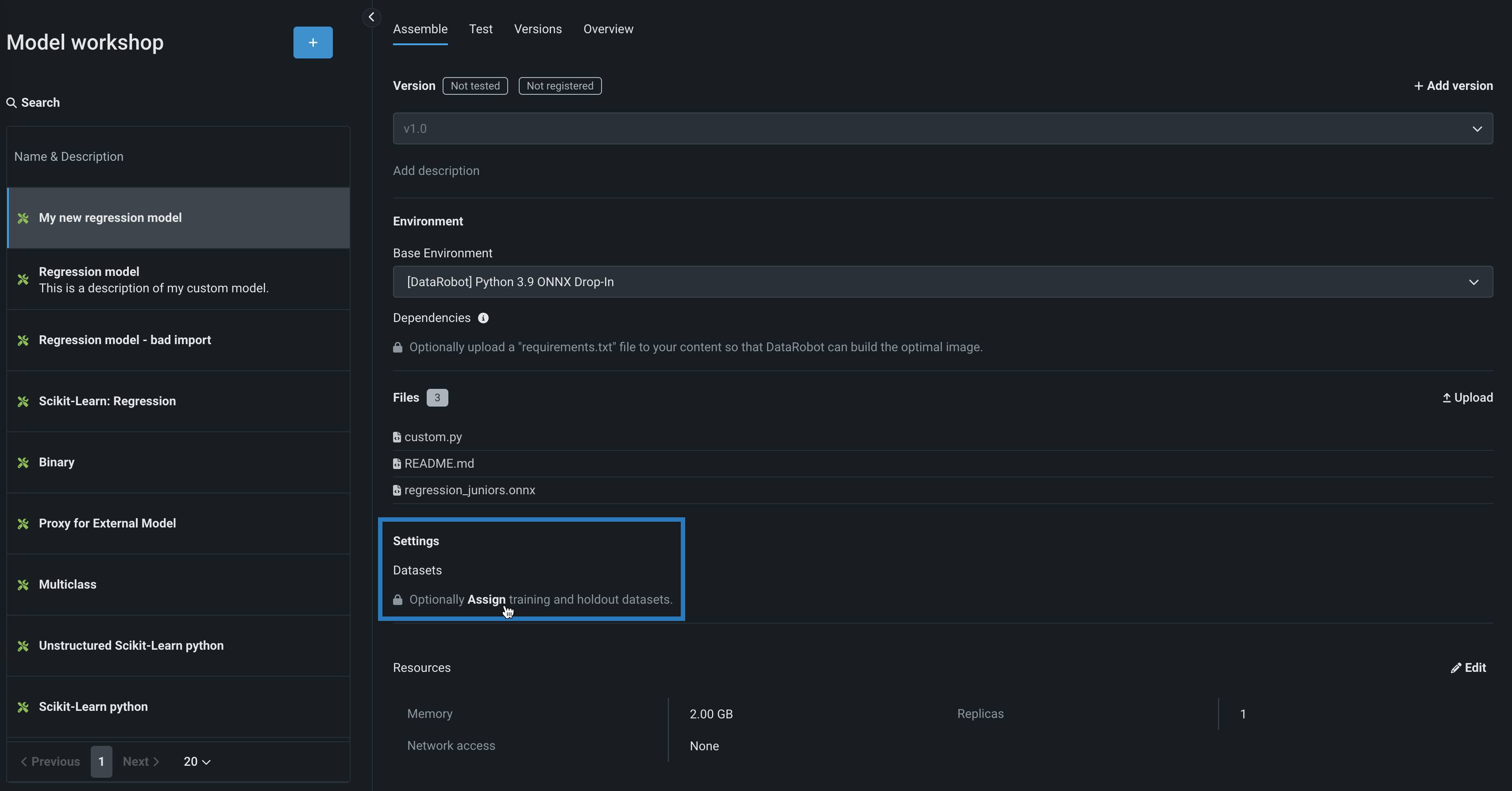
-
If the model version does have training data assigned, click () Change, and then, under Training Data, click the delete () icon to remove the existing training data.
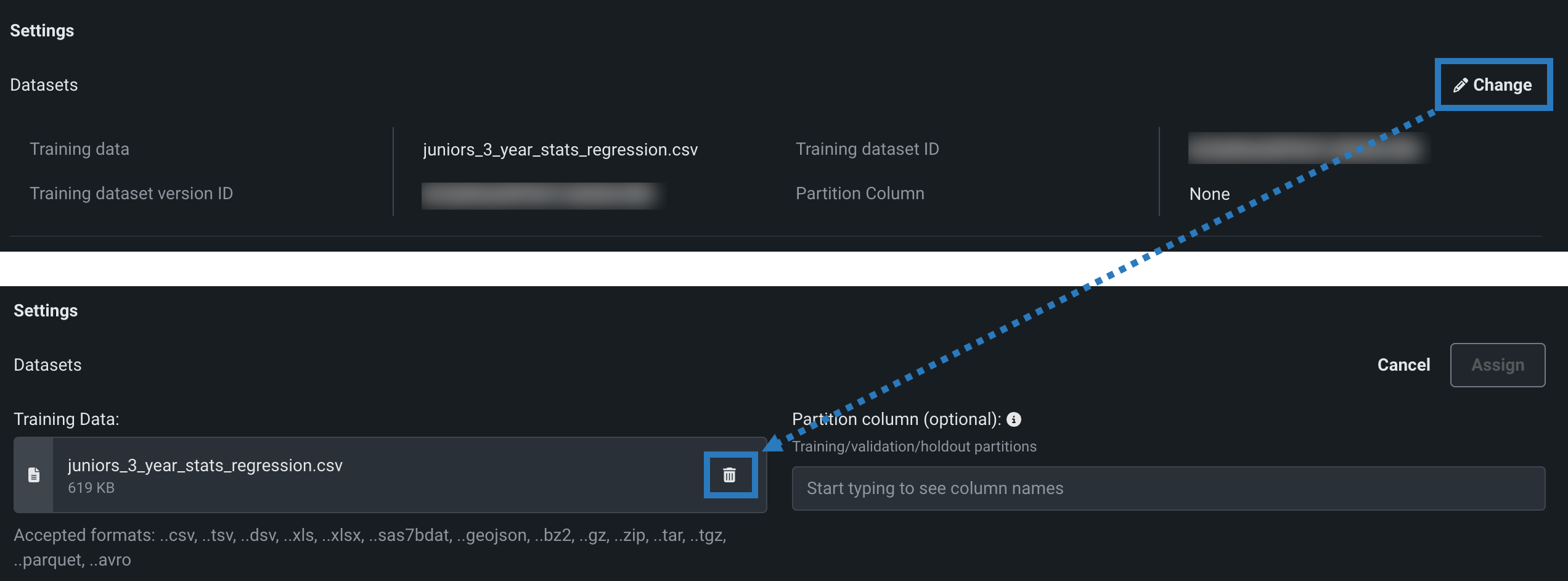
-
-
In the Training Data section, click + Select dataset and do either of the following:
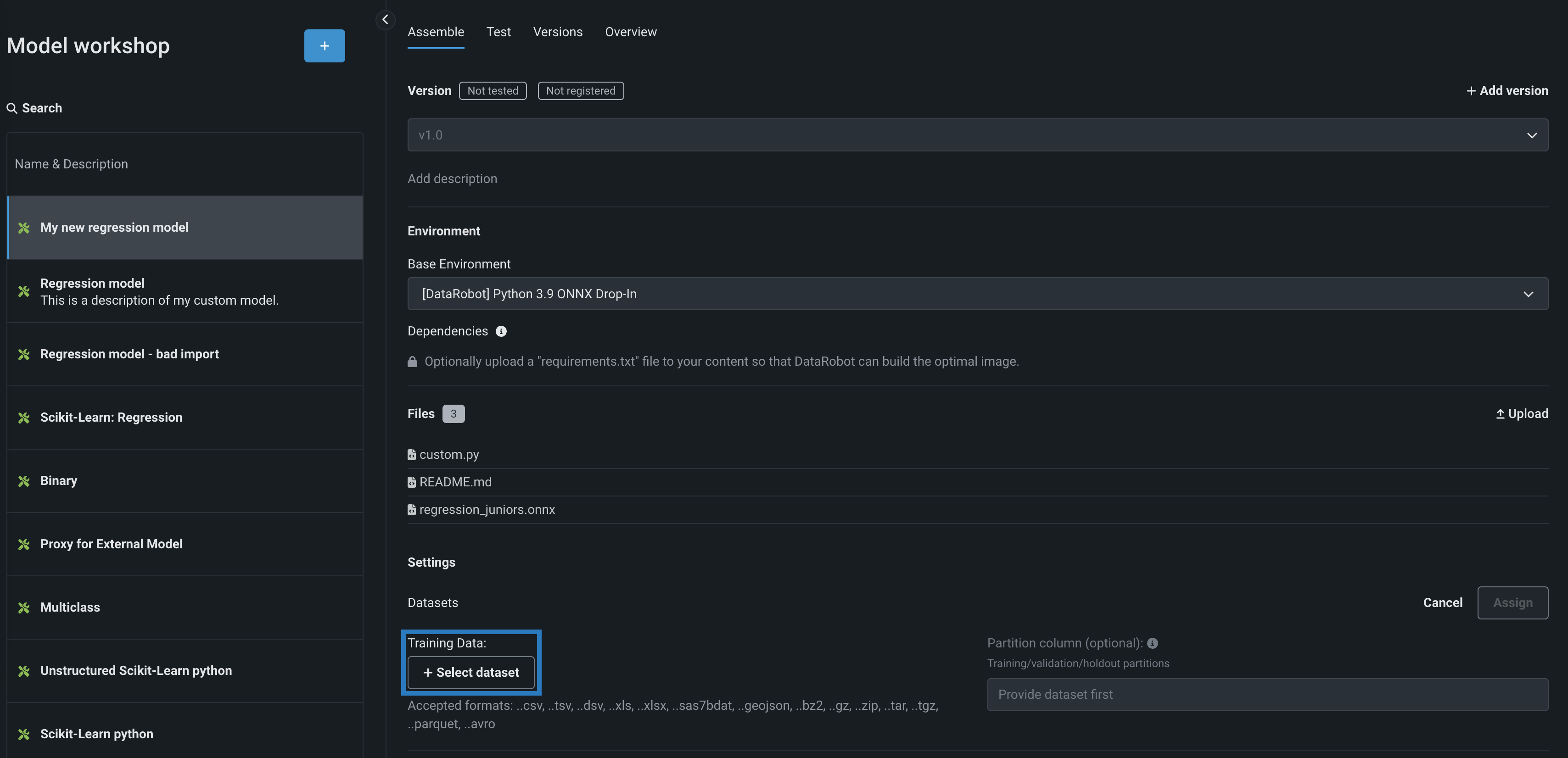
-
To add a new dataset to the Data Registry, click Upload, select a file from your local storage, and then click Open.
-
To select an existing dataset from the Data Registry, in the Data Registry list, locate and click the training dataset you previously uploaded to DataRobot, and then click Select dataset.
Include features required for scoring
The columns in a custom model's training data indicate which features are included in scoring requests to the deployed custom model. Therefore, once training data is available, any features not included in the training dataset aren't sent to the model. Available as a preview feature, you can disable this behavior using the Column filtering setting.
-
-
(Optional) In the Partition column section, specify the column name (from the provided training dataset) containing partitioning information for your data (based on training/validation/holdout partitioning). If you plan to deploy the custom model and monitor its data drift and accuracy, specify the holdout partition in the column to establish an accuracy baseline.
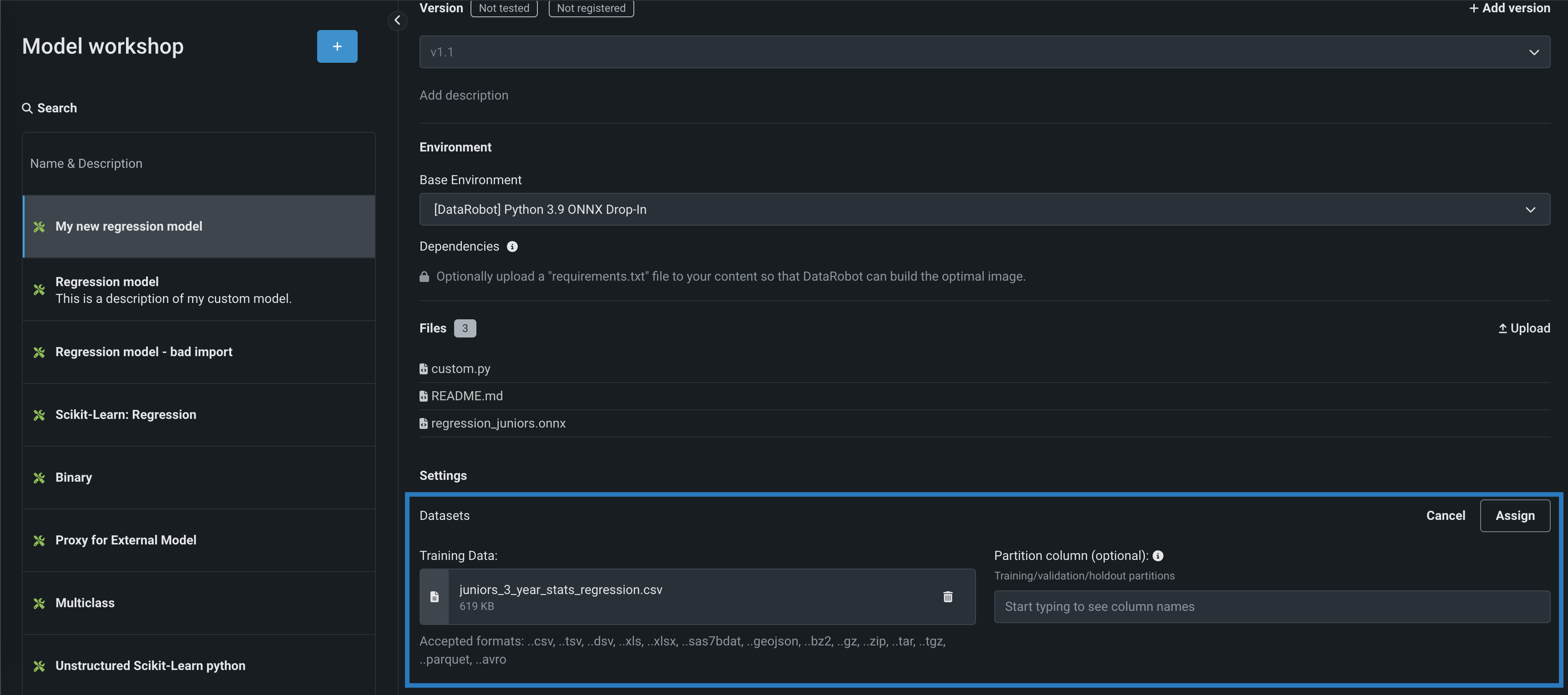
-
Click Assign.
Training data assignment error
If the training data assignment fails, an error message appears in the new custom model version under Datasets. While this error is active, you can't create a model package to deploy the affected version. To resolve the error and deploy the model package, reassign training data to create a new version, or create a new version and then assign training data.
Disable column filtering for prediction requests¶
Preview
Configurable column filtering is off by default. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Feature Filtering for Custom Model Predictions
Now available for preview, you can enable or disable column filtering for custom model predictions. The filtering setting you select is applied in the same way during custom model testing and deployment. By default, the target column is filtered out of prediction requests and, if training data is assigned, any additional columns not present in the training dataset are filtered out of any scoring requests sent to the model. Alternatively, if the prediction dataset is missing columns, an error message appears to notify you of the missing features.
You can disable this column filtering when you assemble a custom model. In the Workshop, open a custom model to the Assemble tab, and, in the Settings section, under Column filtering, clear Exclude target column from requests (or, if training data is assigned, clear Exclude target and extra columns not in training data):
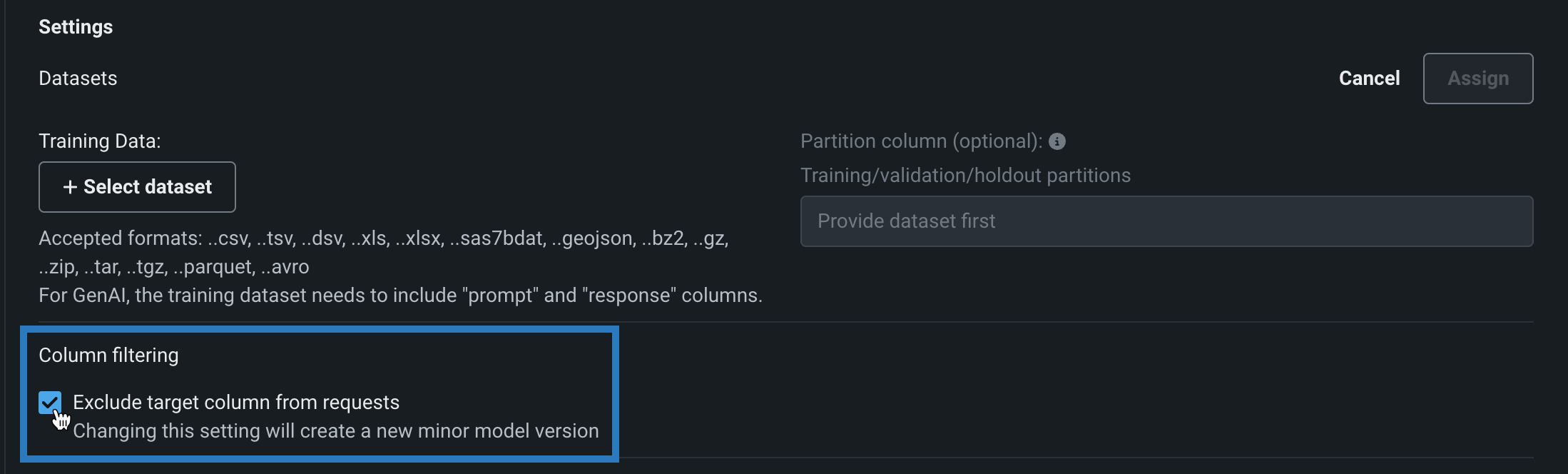
As with other changes to a model's environment, files, or settings, changing this setting creates a new minor custom model version.
The following behavior is expected when Exclude target column from requests / Exclude target and extra columns not in training data is enabled or disabled:
Training data assignment method
If a model uses the deprecated "per model" training data assignment method, this setting cannot be disabled and feature filtering is not applied during testing.
| Set to | Behavior |
|---|---|
| Enabled |
|
| Disabled |
|
DRUM predictions
Predictions made with DRUM are not filtered; all columns are included in each prediction request.
Configure custom model resource settings¶
After creating a custom inference model, you can configure the resources the model consumes to facilitate smooth deployment and minimize potential environment errors in production.
To configure the resource allocation and access settings:
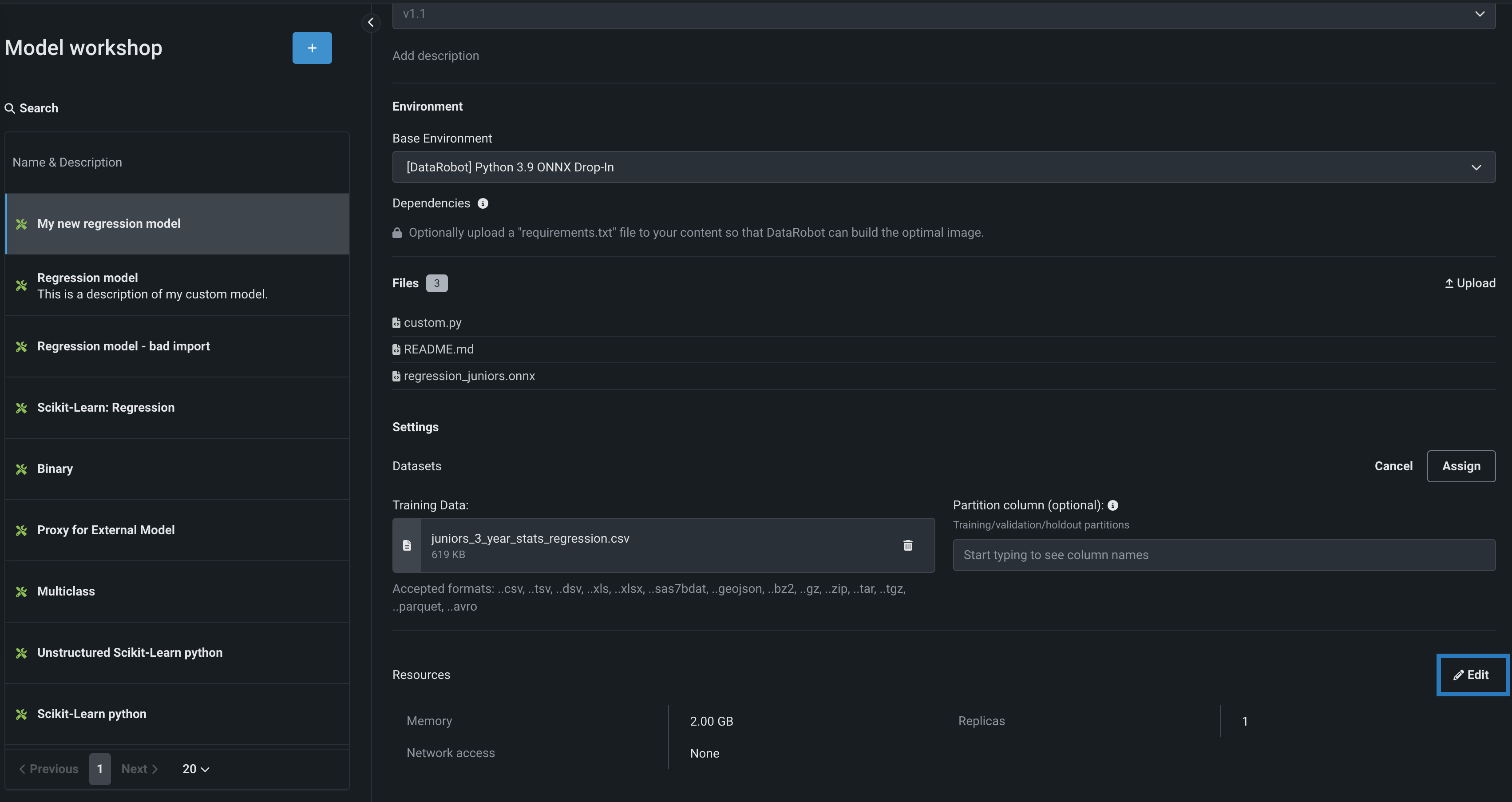
-
On the Assemble tab, in the Settings section, next to Resources, click () Edit:
-
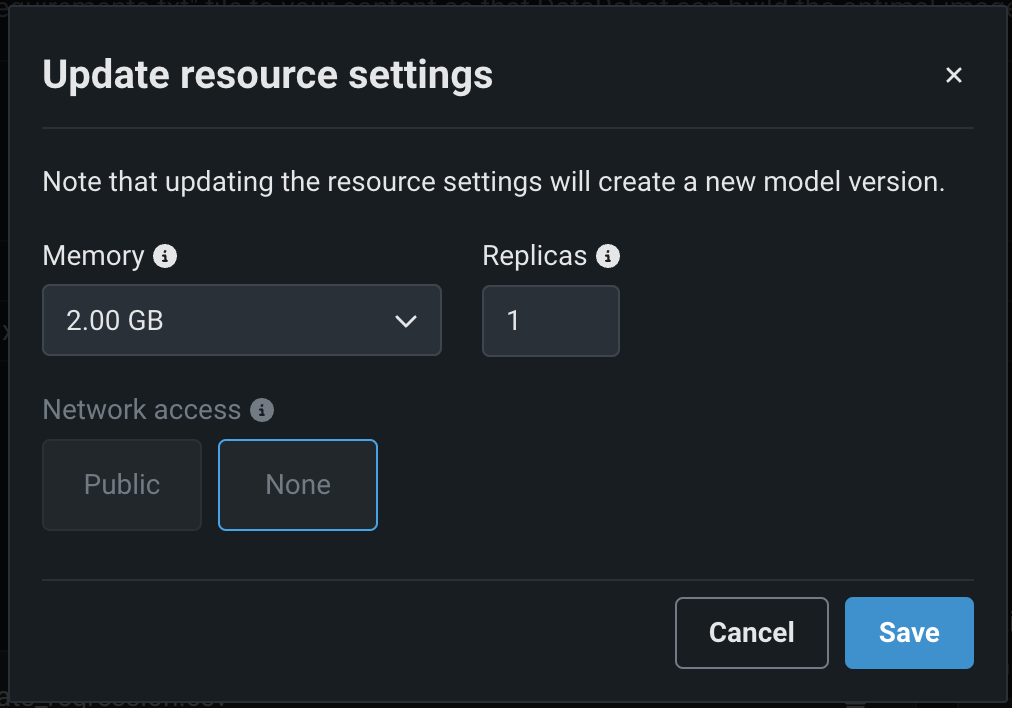
In the Update resource settings dialog box, configure the following settings:
Resource settings access
Users can determine the maximum memory allocated for a model, but only organization admins can configure additional resource settings.
Setting Description Memory Determines the maximum amount of memory that can be allocated for a custom inference model. If a model is allocated more than the configured maximum memory value, it is evicted by the system. If this occurs during testing, the test is marked as a failure. If this occurs when the model is deployed, the model is automatically launched again by Kubernetes. Replicas Sets the number of replicas executed in parallel to balance workloads when a custom model is running. Increasing the number of replicas may not result in better performance, depending on the custom model's speed. Network access Premium feature. Configures the egress traffic of the custom model: - Public: The default setting. The custom model can access any fully qualified domain name (FQDN) in a public network to leverage third-party services.
- None: The custom model is isolated from the public network and cannot access third-party services.
DATAROBOT_ENDPOINTandDATAROBOT_API_TOKENenvironment variables. These environment variables are available for any custom model using a drop-in environment or a custom environment built on DRUM.Imbalanced memory settings
DataRobot recommends configuring resource settings only when necessary. When you configure the Memory setting above, you set the Kubernetes memory "limit" (the maximum allowed memory allocation); however, you can't set the memory "request" (the minimum guaranteed memory allocation). For this reason, it is possible to set the "limit" value too far above the default "request" value. An imbalance between the memory "request" and the memory usage allowed by the increased "limit" can result in the custom model exceeding the memory consumption limit. As a result, you may experience unstable custom model execution due to frequent eviction and relaunching of the custom model. If you require an increased Memory setting, you can mitigate this issue by increasing the "request" at the organization level; for more information, contact DataRobot Support.
Premium feature: Network access
Every new custom model you create has public network access by default; however, when you create new versions of any custom model created before October 2023, those new versions remain isolated from public networks (access set to None) until you enable public access for a new version (access set to Public). From this point on, each subsequent version inherits the public access definition from the previous version.
-
Once you have configured the resource settings for the custom model, click Save.
This creates a new minor version of the custom model with edited resource settings applied.
Select a resource bundle¶
Preview
Custom model resource bundles and GPU resource bundles are off by default. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Resource Bundles, Enable Custom Model GPU Inference (Premium feature)
You can select a Resource bundle—instead of Memory—when you assemble a model and configure the resource settings. Resource bundles allow you to choose from various CPU and GPU hardware platforms for building and testing custom models. In a custom model's Settings section, open the Resources settings to select a resource bundle. In this example, the model is built to be tested and deployed on an NVIDIA A10 device.
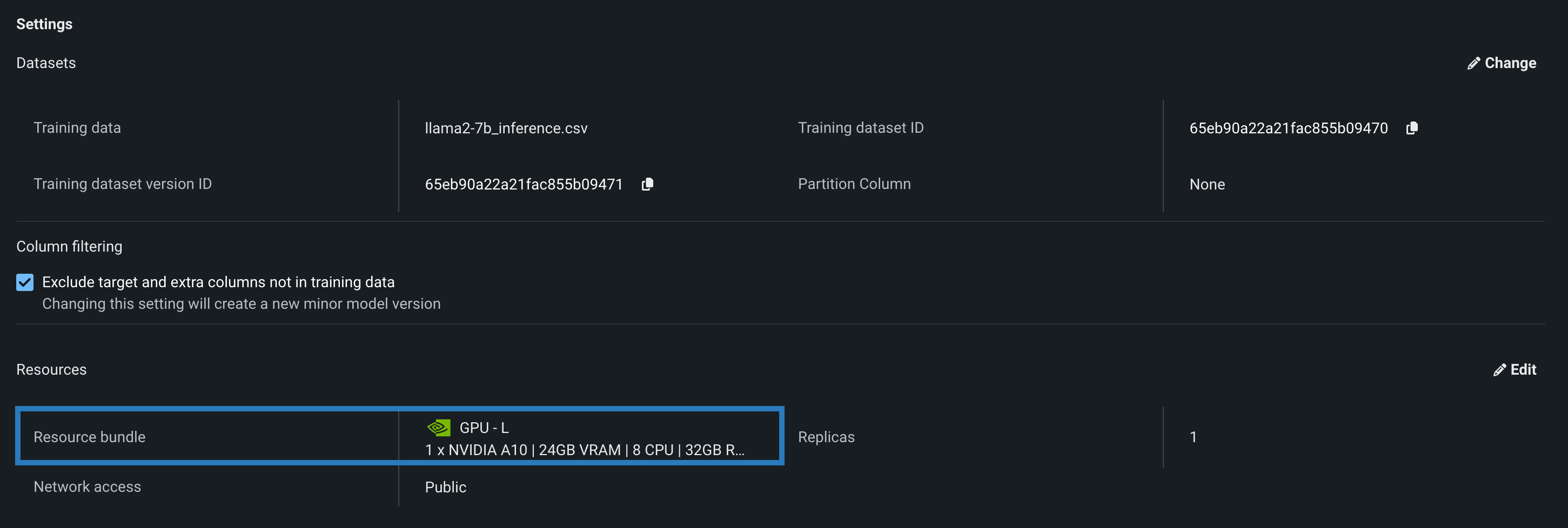
Click Edit to open the Update resource settings dialog box and, in the resource Bundle field, review the CPU and NVIDIA GPU devices available as build environments:
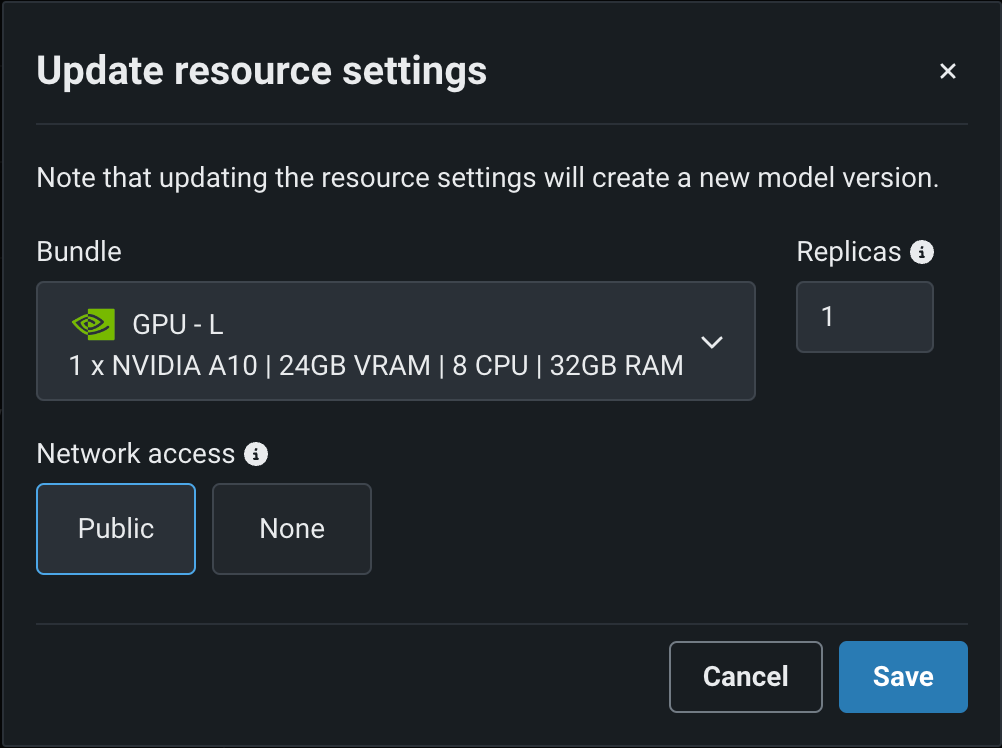
DataRobot can deploy models onto any of the following NVIDIA resource bundles:
| Bundle | GPU | VRAM | CPU | RAM |
|---|---|---|---|---|
| GPU - S | 1x NVIDIA T4 | 16GB | 4 | 16GB |
| GPU - M | 1x NVIDIA T4 | 16GB | 8 | 32GB |
| GPU - L | 1x NVIDIA A10G | 24GB | 8 | 32GB |
| GPU - XL | 1x NVIDIA L40S | 48GB | 4 | 32GB |
| GPU - XXL | 4x NVIDIA A10G | 96GB | 48 | 192GB |
| GPU - 3XL | 4x NVIDIA L40S | 192GB | 48 | 384GB |
| GPU - 4XL | 8x NVIDIA A10G | 192GB | 192 | 768GB |
| GPU - 5XL | 8x NVIDIA L40S | 384GB | 192 | 1.5TB |
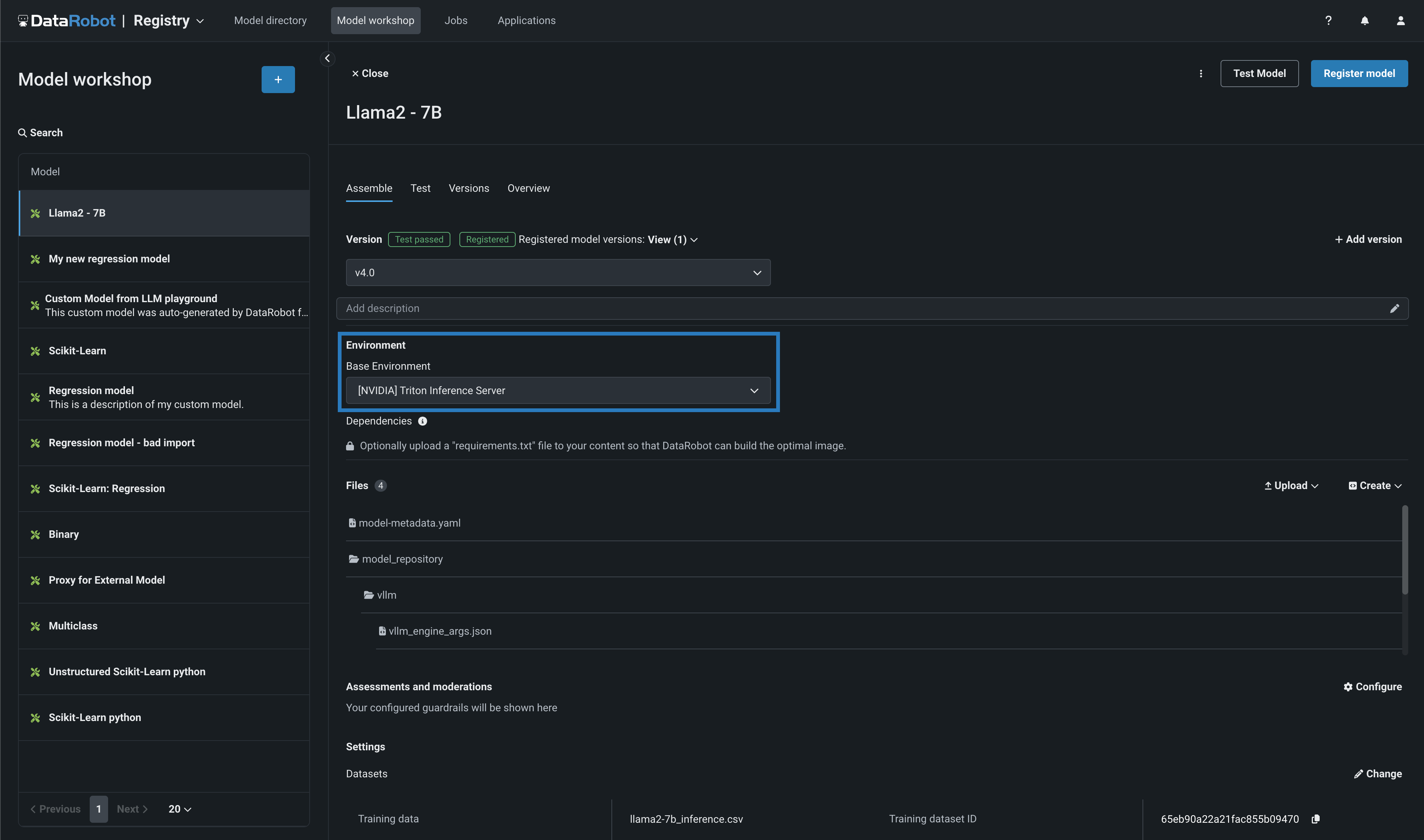
Along with the NVIDIA GPU resource bundles, this feature introduces custom model environments optimized to run on NVIDIA GPUs. When you assemble a custom model, you define a Base Environment. The model in the example below is running on an [NVIDIA] Triton Inference Server:
Assemble a multilabel model¶
You can create custom inference models that support multilabel classification problems. Multilabel custom models support inference only; you cannot create multilabel custom training tasks for the Leaderboard.
Unlike natively-trained multilabel models, custom multilabel models are created without training data. You must specify at least two target labels when creating the model in the Workshop (or in model-metadata.yaml). Multiclass custom models, by comparison, require at least three classes.
When deploying custom multilabel models, the following are available:
- Service health
- Feature drift
The following are not supported:
- Target drift
- Accuracy tracking
- Challenger models
- Retraining policies
These limitations are consistent with DataRobot multilabel models.
Assemble an anomaly detection model¶
You can create custom models that support anomaly detection problems. If you choose to build one, reference the DRUM template. (Log in to GitHub before clicking this link.) When deploying custom anomaly detection models, note that the following functionality is not supported:
- Data drift
- Accuracy and association IDs
- Challenger models
- Humility rules
- Prediction intervals
Assemble a text generation model¶
Availability information
Monitoring support for generative models is a premium feature. Contact your DataRobot representative or administrator for information on enabling this feature.
Text generation custom models custom models require the [DataRobot] Python 3.X GenAI drop-in environment, or a compatible custom environment. To assemble, test, and deploy a generative model from the workshop, a basic LLM assembled in the model workshop should, at minimum, include the following files:
| File | Contents |
|---|---|
custom.py |
The custom model code, implementing the Bolt-on Governance API (the chat() hook) calling the LLM service's API through public network access for custom models. |
model-metadata.yaml |
The custom model metadata and runtime parameters required by the generative model. |
requirements.txt |
The libraries (and versions) required by the generative model. |
After you add the required model files, add training data. To provide a training baseline for drift monitoring, upload a dataset containing at least 20 rows of prompts and responses relevant to the topic your generative model is intended to answer questions about. These prompts and responses can be taken from documentation, manually created, or generated.
Assemble a vector database¶
Premium
Vector database deployments are a premium feature, off by default, and require GenAI experimentation. Contact your DataRobot representative or administrator for information on enabling this feature.
Vector database custom models require the [DataRobot] Python 3.X GenAI drop-in environment, or a compatible custom environment. In addition, you must define the dependencies for the vector database. To populate the Dependencies section, you can upload a requirements.txt file in the Files section, allowing DataRobot to build the optimal image. In addition, vector database custom models require public network access.
After creating a vector database in the workshop, you can register and deploy the model, as you would any other custom model.
What monitoring is available for vector database deployments?
DataRobot automatically generates custom metrics relevant to vector databases for deployments with the Vector database deployment type; for example, Total Documents, Average Documents, Total Citation Tokens, Average Citation Tokens, and VDB Score Latency. Vector database deployments also support service health monitoring. Vector database deployments don't store prediction row-level data for data exploration.
Assemble an agentic workflow¶
Premium
Agentic workflows are a premium feature. Contact your DataRobot representative or administrator for information on enabling the feature.
Agentic workflows require the [DataRobot] Python 3.X GenAI drop-in environment, or a compatible custom environment. To assemble, test, and deploy an agentic workflow from the workshop, a basic agent assembled in the workshop usually includes the following files:
| File | Contents |
|---|---|
custom.py |
The custom model code, implementing the Bolt-on Governance API (the chat() hook) to call the LLM and also passing those parameters to the agent (defined in agent.py). |
agent.py |
The agent code, implementing the agentic workflow. |
model-metadata.yaml |
The custom model metadata and runtime parameters required by the agentic workflow. |
requirements.txt |
The libraries (and versions) required by the agentic workflow. |
After creating the custom agentic workflow, you can test the custom workflow's implementation of the Bolt-on Governance API (the chat() hook)
Ensure agent tools are accessible
To deploy a functional agentic workflow, ensure the deployed tools required by the custom agentic workflow are accessible.
Agentic workflow deployment functionality
Agentic workflows can only be deployed on Serverless prediction environments. After deployment, Console includes the deployment Overview tab; Monitoring for service health, usage (including quota monitoring), custom metrics, data exploration (including tracing), resource monitoring, OpenTelemetry (OTel) metrics, and deployment reports; Predictions through the Prediction API (including chat completions); and Activity log for standard output, OTel logs, and moderation events when evaluation and moderation guardrails are configured. For a tab-by-tab summary with links, see Monitor workflows.
Register an agentic tool¶
Agentic tools are registered in the Registry so that they can be easily listed and called by agents, granting them access to the DataRobot API. These tools can be viewed in the Tools tab of the Workshop.
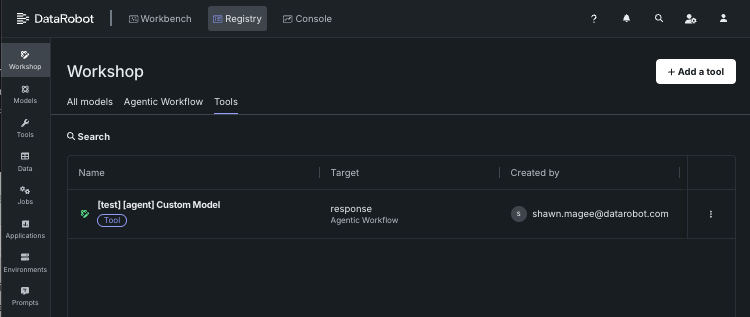
Click the tool to view its details or click Add a tool to register a new tool. This opens the Add a model page, where you can configure the model as you would for any other custom model, with the addition that the Use model as tool box under Optional settings is checked.
Click Add model to register the tool. The tool version opens on the Workshop > Tools tab with its details view.
From here, configure the tool as you would for any other custom model, as described in Assemble the custom model. For details on managing agentic tools, see the View and manage tools page.