Explore registry data¶
Once data registration is complete, you can select the dataset to view various insights and interact with the dataset. From here you can:

| Element | Description | |
|---|---|---|
| 1 | Navigation tabs | Explore different aspects of your dataset:
|
| 2 | Snapshot policy | Displays the asset's snapshot policy. |
| 3 | Actions menu | Allows you to:
|
| 4 | Share | Shares the asset with other users, groups, and/or organizations. |
| 5 | Link to Use Cases | Allows you to add the asset to Use Cases and manage Use Cases the asset is currently linked to. |
There are two types of data stored in the Data Registry:
- Materialized data: These datasets are marked with the
Static,Snapshot, orSparkbadge. As part of the registration process upon import, DataRobot runs EDA1 on the dataset, making additional insights available. - Unmaterialized data: These datasets are marked with
Dynamicbadge. This is data that was added using a data connection and is still stored in the data source. If you did not choose to run EDA1 on a sample upon import, fewer insights are available.
Metadata info¶
On the Info tab, you can view a high-level summary of the dataset, add identifying information, and view impact analysis.
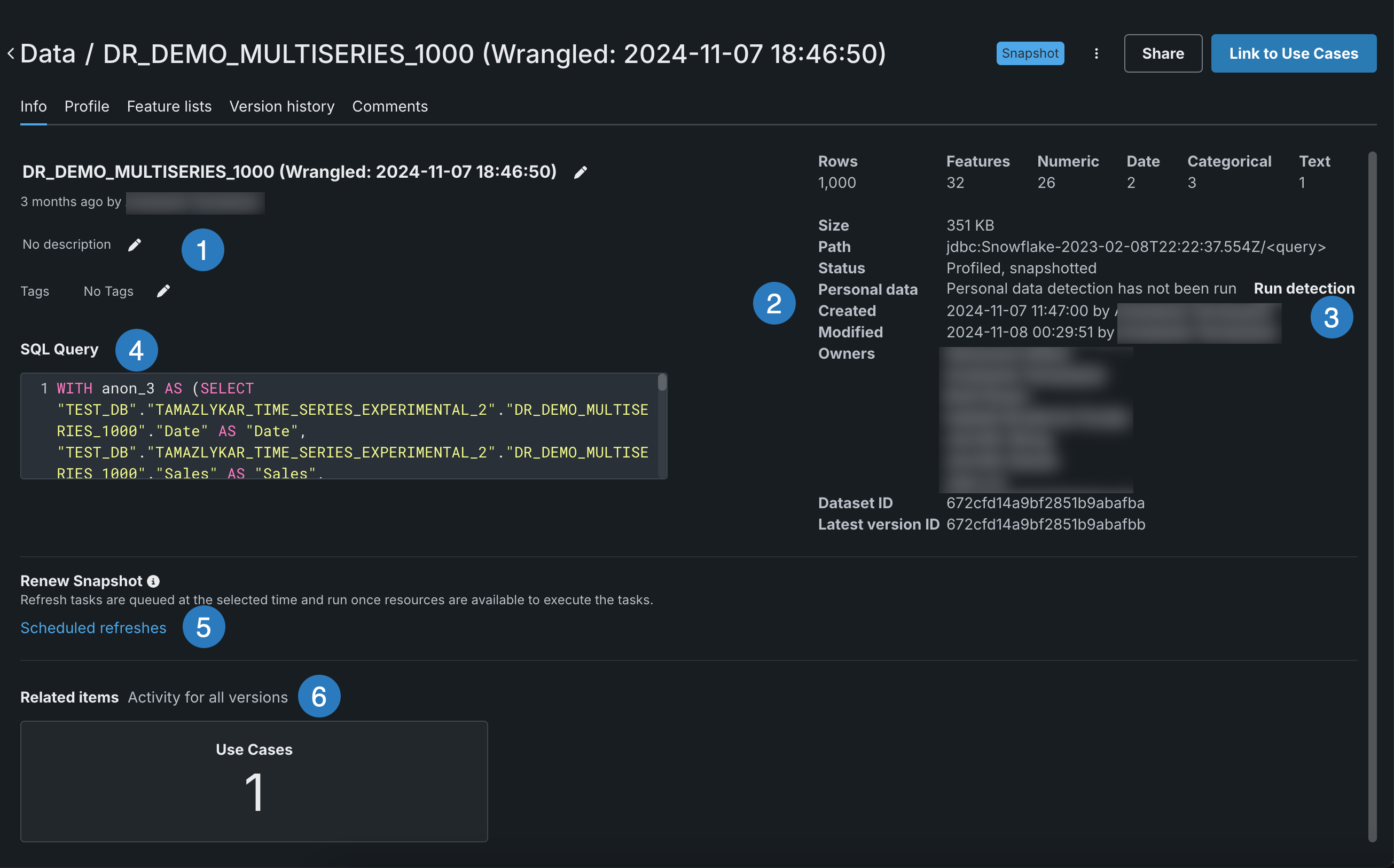
| Element | Description | |
|---|---|---|
| 1 | Descriptive information | Update the name and description, or add tags to use for search. |
| 2 | Dataset information | Displays the number of rows and features display on the right, along with other details. |
| 3 | Run detection | Run personal data detection to identify, and if detected, remove, personal data from the dataset. |
| 4 | SQL Query | SQL query used to create dataset. |
| 5 | Renew snapshot | Add a scheduled snapshot. |
| 6 | Impact analysis | View how other DataRobot entities are related to—or dependent on—the current asset. |
Personal data detection¶
In some regulated and specific use cases, the use of personal data as a feature in a model is forbidden. DataRobot automates the detection of specific types of personal data to provide a layer of protection against the inadvertent inclusion of this information in a dataset and prevent its usage at modeling and prediction time.
After a dataset is ingested through the Data Registry, you have the option to check each feature for the presence of personal data. The result is a process that checks every cell in a dataset against patterns that DataRobot has developed for identifying this type of information. If found, a warning message is displayed, informing you of the type of personal data detected for each feature and providing sample values to help you make an informed decision on how to move forward. Additionally, DataRobot creates a new feature list—the equivalent of Informative Features but with all features containing any personal data removed. The new list is named Informative Features - Personal Data Removed.
Warning
There is no guarantee that this tool has identified all instances of personal data. It is intended to supplement your own personal data detection controls.
DataRobot currently supports detection of the following fields:
- Email address
- IPv4 address
- US telephone number
- Social security number
To run personal data detection on a dataset in the Data Registry, go to the Info page click Run Detection.
-
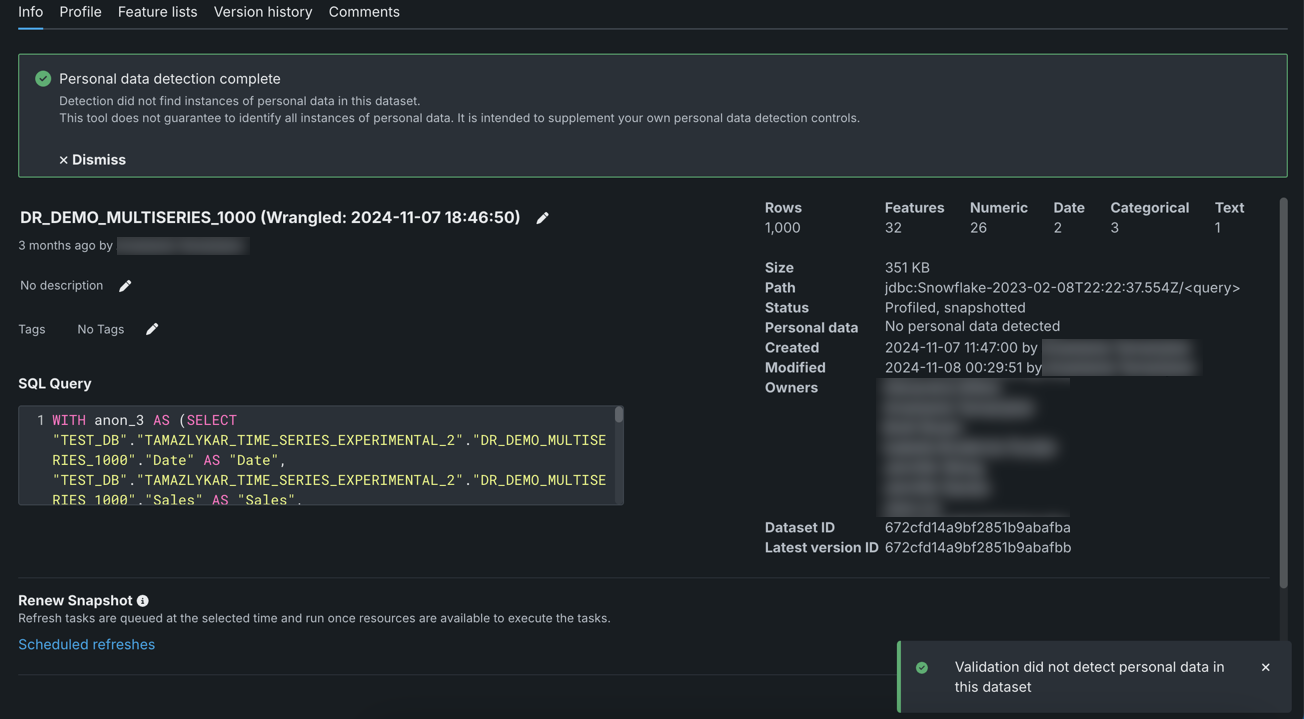
If no personal data is detected in the dataset, a success message displays.
-
If DataRobot detects personal data in the dataset, a warning message displays. Click Details to view more information about the personal data detected; click Dismiss to remove the warning and prevent it from being shown again. Warnings are also highlighted by column on the Profile tab.
Impact analysis¶
Impact analysis shows how other entities in the application are related to—or dependent on—the current asset. This is useful for a number of reasons, allowing you to:
- View how popular an item is based on the number of projects in which it is used.
- Understand which other entities might be affected if you were to makes changes or deletions.
- Gain understanding on how the entity is used.
To view Impact analysis, scroll down to the bottom of the Info tab. Click on a tile for summary details and then click on the associated button, Open Use Case in the below example, for specific details.
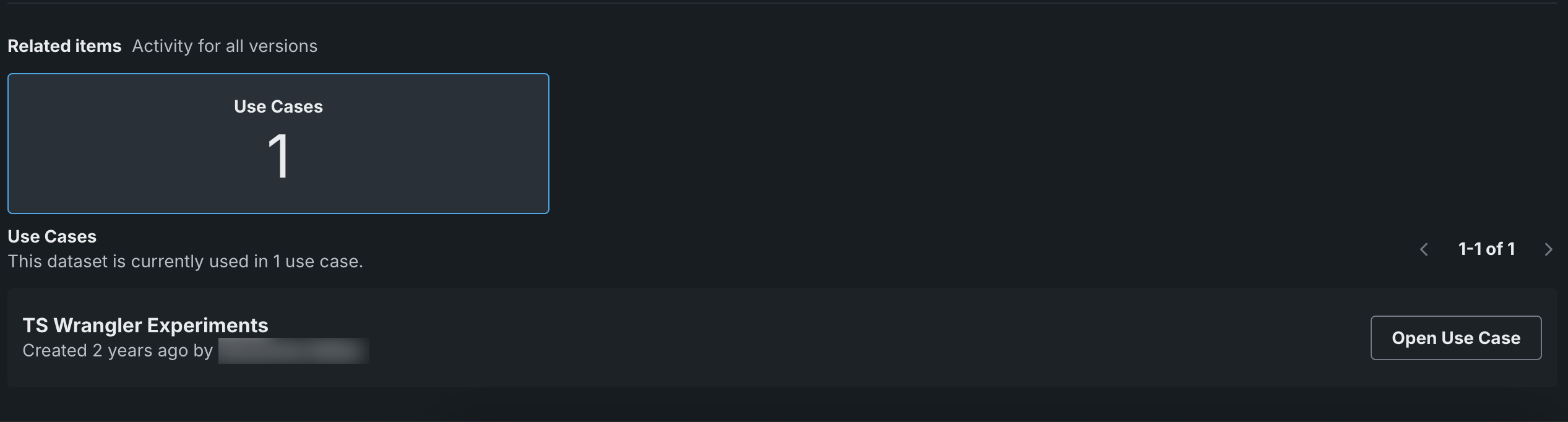
If you do not have permission to access an asset, you can view an entry that represents the asset but the entry does not disclose any additional information.
All of the following associations are reported (with frequency values) as applicable:
- Projects
- Prediction datasets
- Feature Discovery configurations
- Time series calendars
- Spark SQL queries
- External model packages
- Deployment retraining
This functionality is also available from the Version History tab for individual dataset versions.
Profile¶
The Profile tab allows you to preview dataset column names and row data. It can be useful for finding or verifying column names.
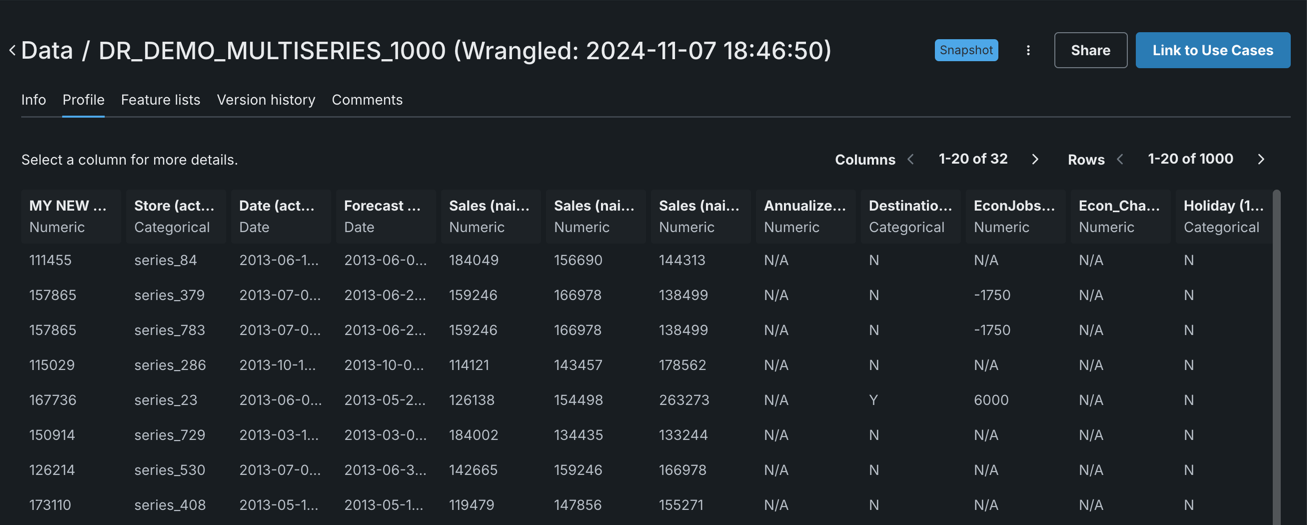
Info tab vs. Profile tab
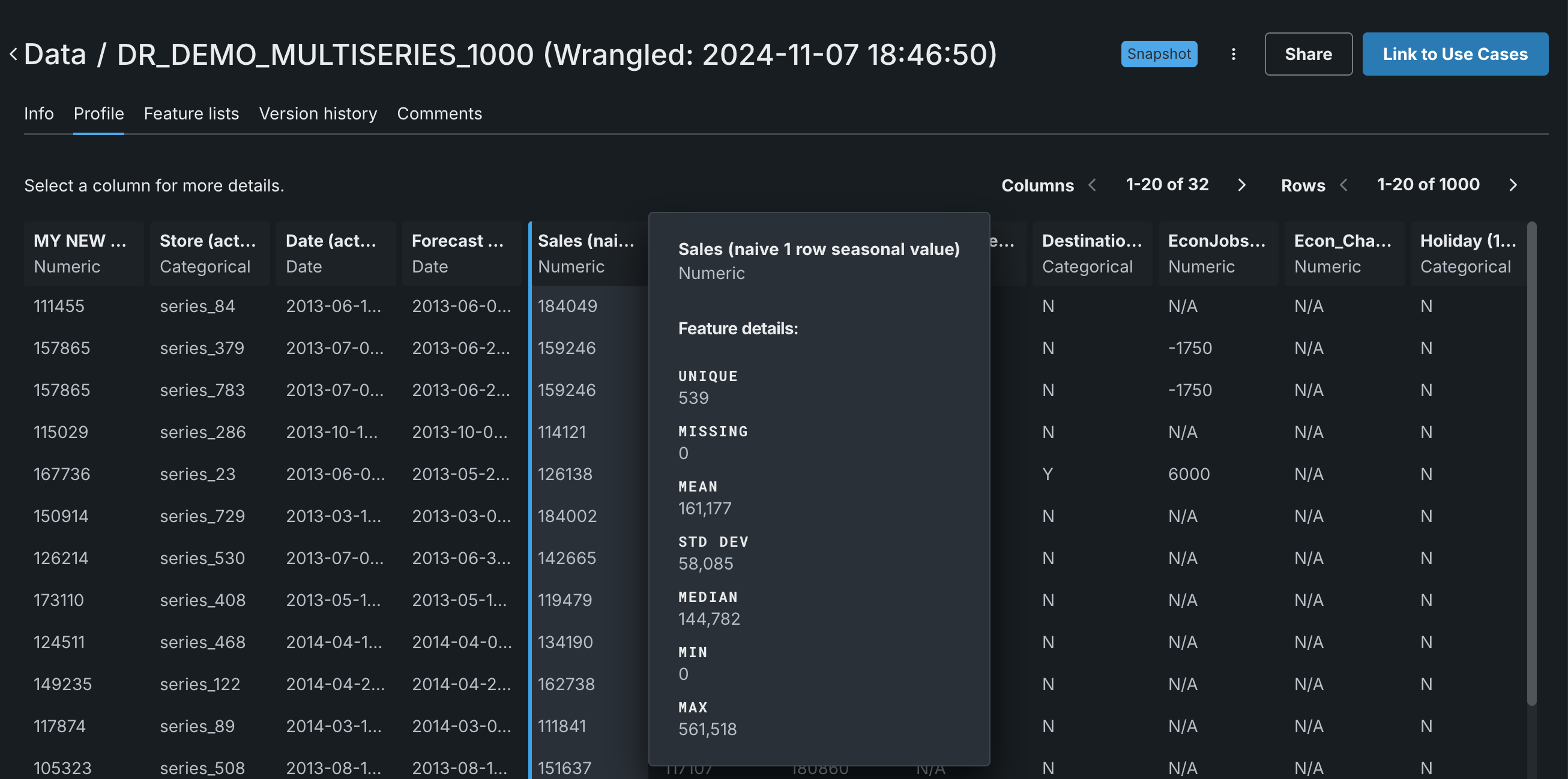
The Info tab displays the data's total row count, feature count, and size. The Profile tab only displays a preview of the data based on a 1MB raw sample, and the feature types and details are based on a 500MB sample. Meaning the row count observed on the Profile tab may not match that displayed in the Info tab.
Note that the preview is a random sample of up to 1MB of the data and may be ordered differently from the original data. To see the complete, original data, use the Download Dataset option.
To view details for a particular feature, scroll to it in the display and click.
Feature lists¶
You can create new lists and feature transformations for features of any dataset in the Data Registry. To do so, select the dataset in the Data Registry and then Feature Lists in the left navigation panel.
For information on feature lists and creating custom feature lists, see the Feature lists reference page.
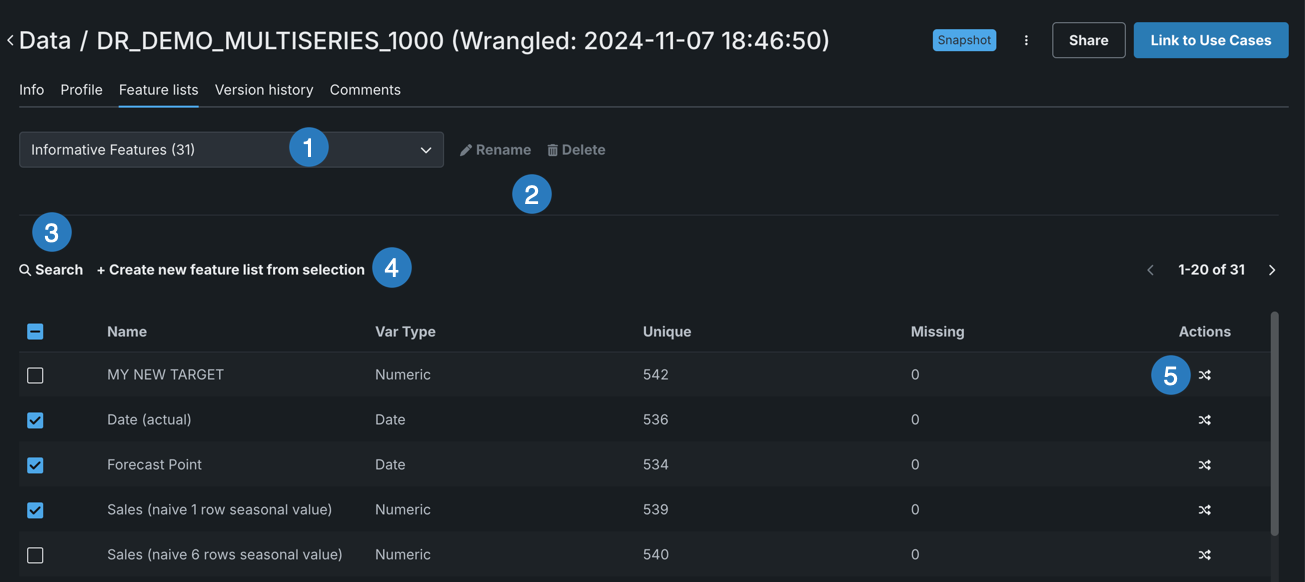
| Element | Description | |
|---|---|---|
| 1 | Feature list dropdown | View a list of DataRobot-generated or custom feature lists. |
| 2 | Rename / Delete | Rename or Delete the custom feature list selected in the feature list dropdown. You cannot make any changes to DataRobot default feature lists. |
| 3 | Search | Search for a specific feature. |
| 4 | + Create new feature list from selection | Create a new feature list from the features that are currently selected. |
| 5 | Create feature transformation | Change the variable type of a feature. |
Transform single features¶
The Feature Lists tab also provides access to a tool for creating single feature variable type transformations. For more information, including concepts and workflows, see Transform features.
Version history¶
The Version history tab lists all versions of a selected asset.
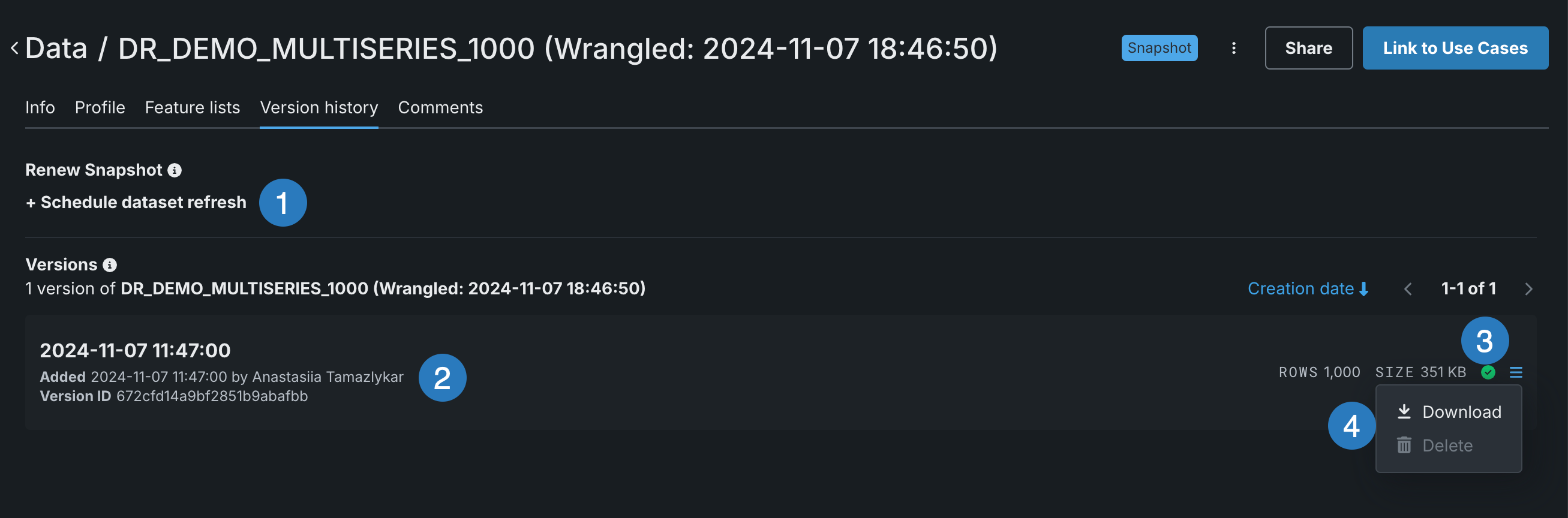
| Element | Description | |
|---|---|---|
| 1 | + Schedule dataset refresh | Add a scheduled snapshot. |
| 2 | Dataset version information | Displays the number of rows and features display on the right, along with other details for the individual dataset version. |
| 3 | Snapshot status | The snapshot status of the dataset version—green if successful, red if failed, gray if the original version did not have a snapshot. |
| 4 | Actions menu | Allows you to download or delete the dataset version. |
Renew snapshot¶
Availability information
For Self-Managed AI Platform installations, the Model Management Service must also be installed.
To ensure that a dataset is always in sync with the data source, if desired, DataRobot provides an automated, scheduled refresh mechanism. Through the Data Registry, users with dataset access above the consumer level can schedule snapshots at daily, weekly, monthly, and annual intervals. You can refresh any data asset type (JDBC, Spark, and URL) except for files.
Schedule refresh tasks¶
You can schedule multiple refresh tasks; limits are applied to datasets and to users independently.
To schedule snapshots for a dataset:
-
From the Data Registry, select the asset for which you want to schedule one or more refresh tasks.
-
Click the Schedule refresh link to expand the scheduler.
-
If the asset source is JDBC a login dialog results. Select the account credentials associated with the asset. DataRobot uses these credentials each time it runs the scheduled task. Once credentials are accepted (or if they were not required), the scheduler opens:
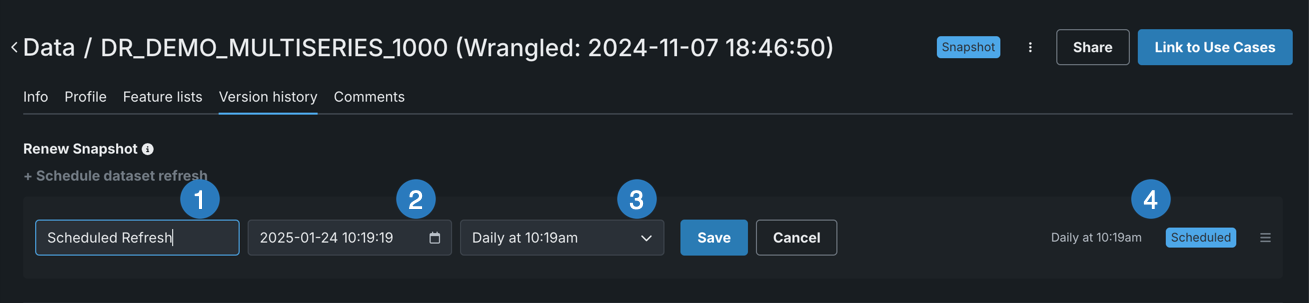
-
Complete the fields to set your task:
Element Description 1 Name Enter a name for the refresh job (or leave the default). 2 Calendar picker Sets the basis for the interval setting. 3 Interval Based on the calendar setting, the interval dropdown sets the frequency to daily, weekly, monthly, or annually. The time on the selected day is always set to the timestamp when the job was scheduled. 4 Summary Provides a summary of the selected scheduled task, including the interval and whether it is active or paused, supplied by DataRobot and updated with any changes to the job. -
Click Save to schedule a refresh for the asset. DataRobot reports the last execution status under the scheduled job name.
Use the calendar picker¶
Use the calendar picker to select a date that will serve as the basis of the day-of-week, monthly date, or day of year for the refresh.
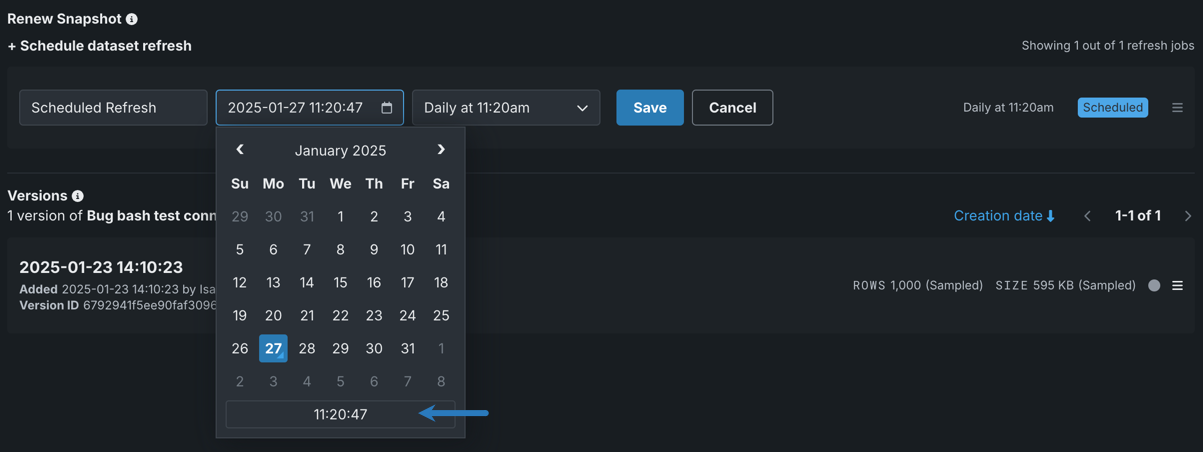
Refreshes will start on or after (depending on the time set) the specific date. For example, if January 27 is the date selected, refreshes will begin:
- Daily at timestamp, either that day or the next day (January 27).
- Weekly on the set day (every Monday at timestamp).
- Monthly on that date of month (the 27th of each month at timestamp).
- Annually on that date (every January 27 at timestamp).
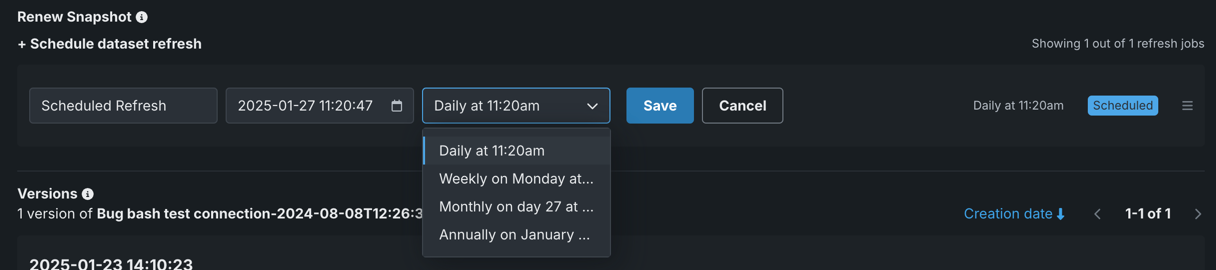
Click in the time picker. Use the arrows to change the time, setting the timestamp to the local time at which you want the snapshot to refresh. Click on the date to return to the full calendar view:
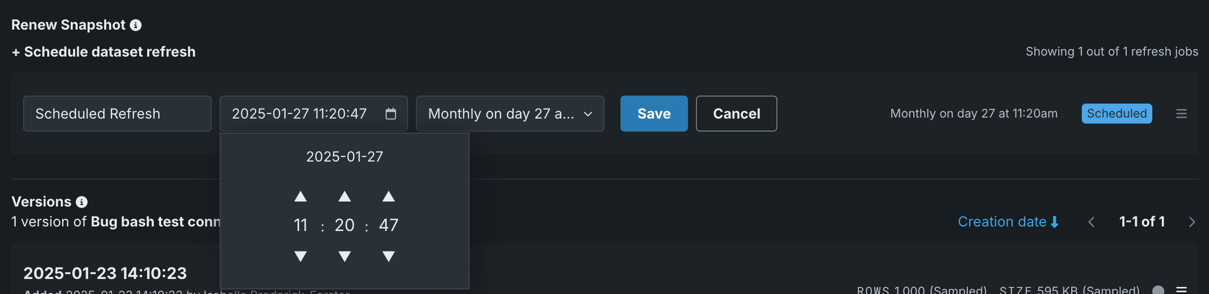
Work with scheduled tasks¶
Once scheduled, you can modify the task in a variety of ways. Use the Actions menu associated with the task to access the options.
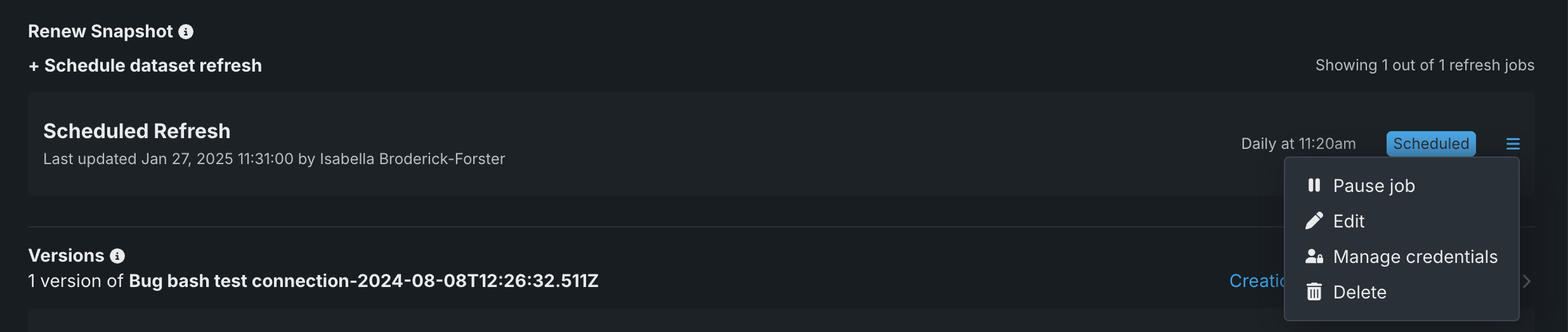
| Option | Description |
|---|---|
| Pause job | Pauses the scheduled task indefinitely. When paused, the "Scheduled" label changes to "Paused" and the menu item changes to "Resume job". Use this action to re-enable the scheduled task. Paused jobs do not count against the task limits. |
| Edit | Retrieves the scheduler interface, allowing you to change any aspect of the task configuration. |
| Manage credentials | Opens the credentials selection modal, allowing you to change the credentials associated with the dataset. |
| Delete | Deletes the scheduled task. |
Refresh limit settings¶
The following table lists the defaults and maximums for refresh-related activities.
Availability information
The default listed in the table is for the managed AI Platform. For Self-Managed AI Platform installations, consider the maximum setting as the default.
| Parameter | Description | Default | Maximum |
|---|---|---|---|
| Enabled dataset refresh jobs for a user | The total number of refresh jobs a user can have across all Data Registry datasets. | 100 | 100 |
| Enabled dataset refresh jobs for a dataset | The total number of refresh jobs that can exist for a specific dataset for all users. | 5 | 100 |
| Stored snapshots until a dataset refresh job is automatically disabled | The total number of stored snapshots that can exist for a specific dataset until the dataset refresh job is automatically disabled. | 100 | 1000 |
Comments¶
The Comments tab allows you to add comments to—even host a discussion around—any asset in the Data Registry that you have access to. With comments, you can:
- Tag other users in a comment; DataRobot will then send them an email notification.
- Edit or delete any comment you have added (you cannot edit or delete other users' comments).