Test custom models¶
You can test custom models in the Workshop. Alternatively, you can test custom models prior to uploading them by testing locally with DRUM. Testing ensures that the custom model is functional before it is registered and deployed, using the environment to run the model with prediction test data.
Testing predictions vs. deployment predictions
There are some differences in how predictions are made during testing and for a deployed custom model:
-
Testing bypasses the prediction servers, but predictions for a deployment are made using the deployment's prediction server.
-
For both custom model testing and a custom model deployment, the model's target and partition columns are removed from prediction data before making predictions.
-
A deployment can be used to make predictions with a dataset containing an association ID. In this case, run custom model testing with a dataset that contains the association ID to make sure that the custom model is functional with the dataset.
To test a custom model in the workshop:
-
After you complete model assembly, do either of the following:
-
Open the custom model you want to test, and, from any tab, click Test model.
-
Open the custom model you want to test, click the Test tab, and then, at the top of the tab (or the middle of the tab for the first test), click Run new test.
-
-
On the Run a test page, in the General settings section, configure the following:
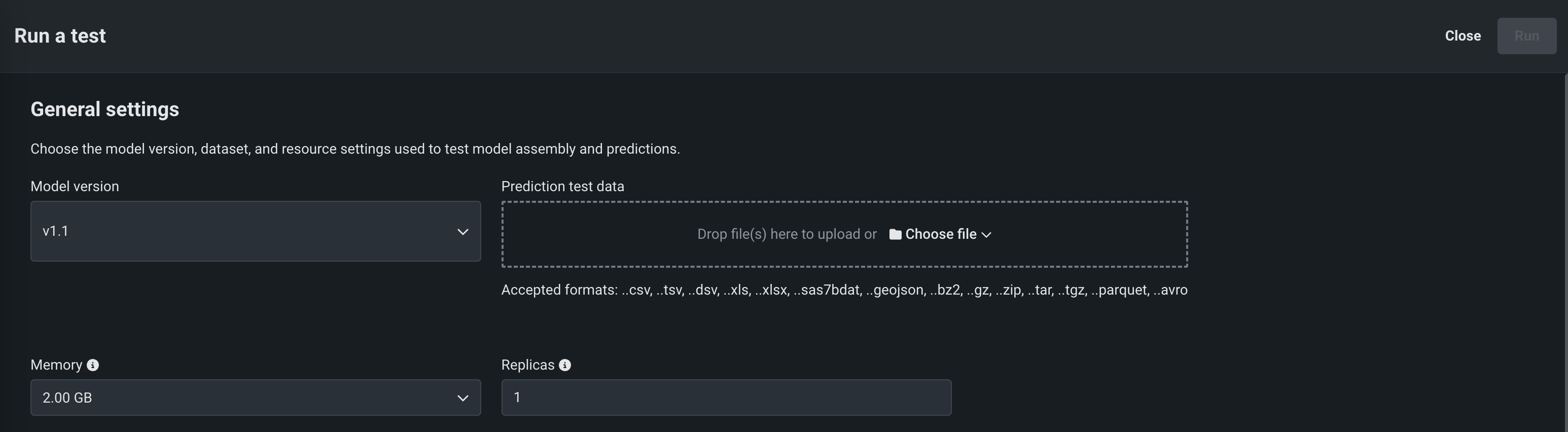
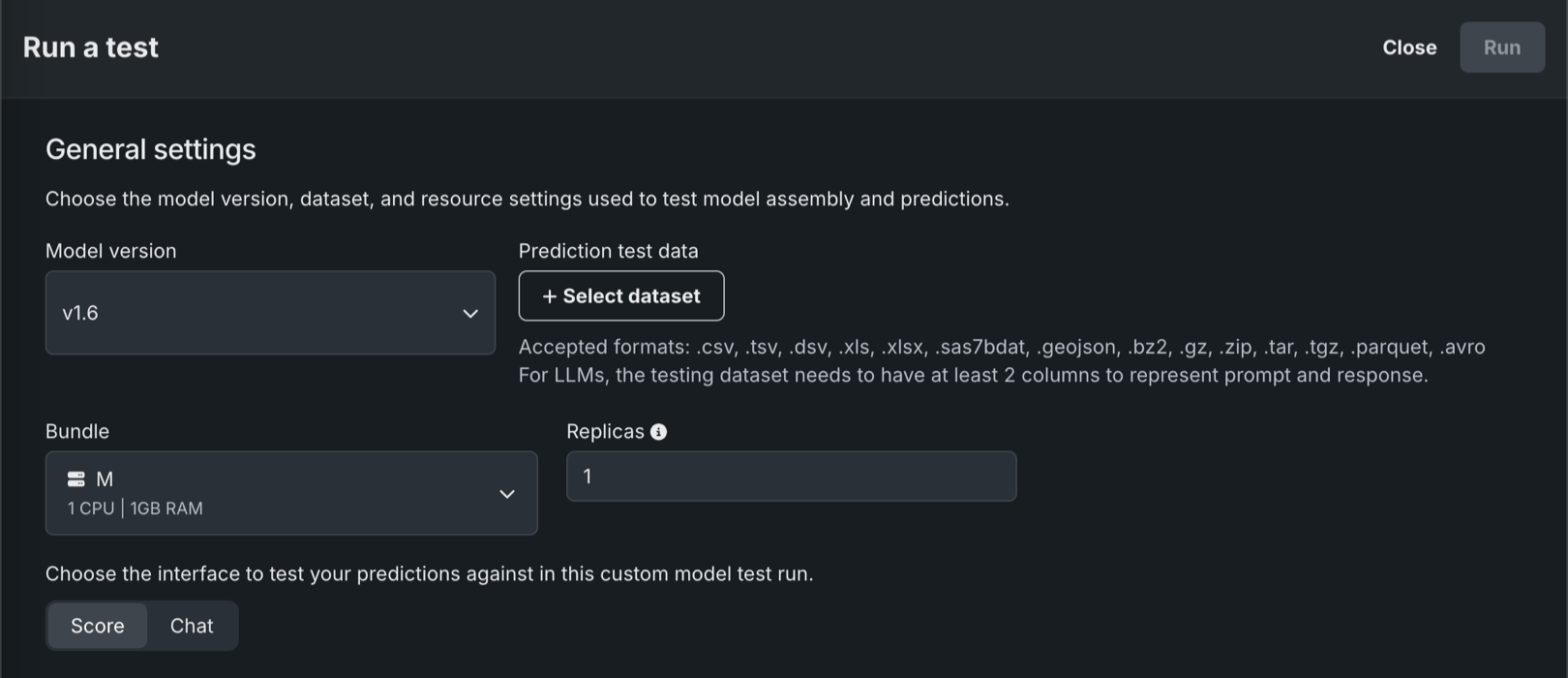
Setting Description Model version The custom model version to run tests on. Prediction test data The dataset to use for test predictions. Bundle The system memory resource setting. If the model allocates more than the selected memory value, it is evicted by the system. This setting only applies to the test, not the custom model version itself. Replicas The maximum number of replicas executed in parallel. This setting only applies to the test, not the custom model version itself. Text generation models Interface The interface to test your predictions against in this custom model test run. Click Score or Chat to run either the Prediction error test or the Chat error test. -
In the Define testing plan section, enable the tests to run. The following table describes the tests performed on custom models to ensure they are ready for deployment:
Unstructured model tests
Unstructured custom inference models only perform the Startup test, skipping all other tests.
Text generation model tests
Text generation custom inference models perform the Startup test and either the Prediction error test or the Chat error test.
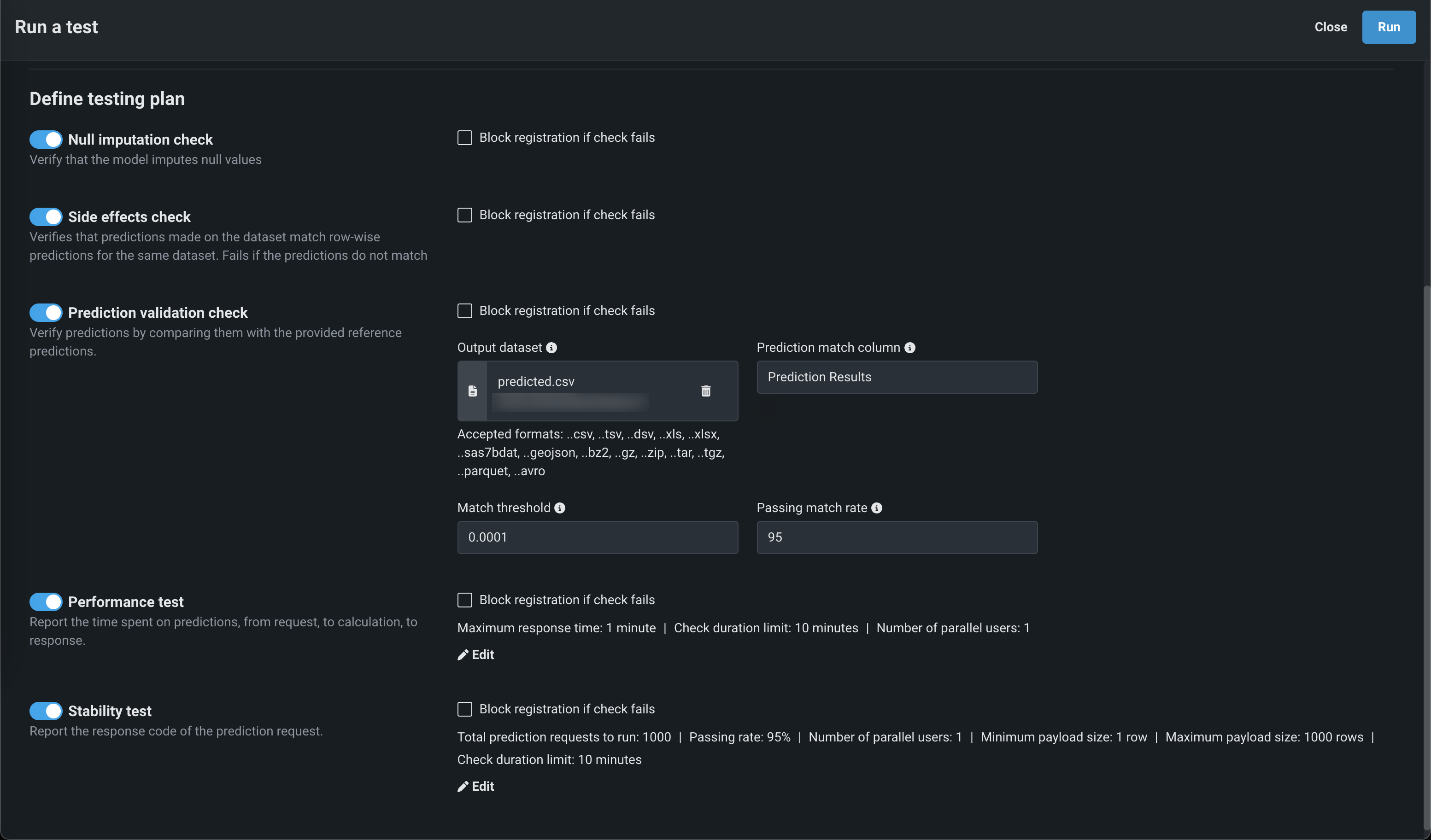
Test name Description Startup Ensures that the custom model image can build and launch. If the image cannot build or launch, the test fails and all subsequent tests are aborted. Prediction error Checks that the model can make predictions on the provided test dataset. If the test dataset is not compatible with the model or if the model cannot successfully make predictions, the test fails. Null imputation Verifies that the model can impute null values. Otherwise, the test fails. The model must pass this test in order to support Feature Impact. Side effects Checks that the batch predictions made on the entire test dataset match predictions made one row at a time for the same dataset. The test fails if the prediction results do not match. Prediction validation Verifies predictions made by the custom model by comparing them to the reference predictions. The reference predictions are taken from the specified column in the selected dataset. Performance Measures the time spent sending a prediction request, scoring, and returning the prediction results. The test creates 7 samples (from 1KB to 50MB), runs 10 prediction requests for each sample, and measures the prediction requests latency timings (minimum, mean, error rate etc.). The check is interrupted and marked as a failure if more than 10 seconds elapse. Stability Verifies model consistency. Specify the payload size (measured by row number), the number of prediction requests to perform as part of the check, and what percentage of them require 200 response code. You can extract insights with these parameters to understand where the model may have issues (for example, model failures respond with non-200 codes most of the time). Duration Measures the time elapsed to complete the testing suite. Text generation models Chat error If you selected the Chat interface in the previous step, verifies that the model can return successful chat completions from the test dataset. Additionally, you can configure the tests' parameters (where applicable):
Test name Parameter descriptions Prediction validation - Output dataset: The dataset with a prediction results column for prediction validation.
- Prediction match column: The name of the column in the dataset containing prediction results. For binary classification models, the column must contain the probabilities of the positive class.
- Match threshold: The precision of the predictions comparison.
- Passing match rate: The matching prediction percentage required for the model to pass the test, selected in increments of five.
Performance - Maximum response time: The amount of time allotted to receive a prediction response.
- Check duration limit: The total allotted time for the model to complete the performance test.
- Number of parallel users: The number of users making prediction requests in parallel.
Stability - Total prediction requests to run: The number of prediction requests to perform.
- Passing rate: The successful prediction request percentage required for the model to pass the test, selected in increments of five.
- Number of parallel users: The number of users making prediction requests in parallel.
- Minimum payload size: The minimum number of prediction requests allowed in the test.
- Maximum payload size: The maximum number of prediction requests allowed in the test.
- Check duration limit: The total allotted time for the model to complete the stability test.
When a test is enabled, and the Block registration if check fails option is selected, an unsuccessful check returns an Error, blocking the registration and deployment of the custom model and canceling all subsequent tests. If this option isn't selected, an unsuccessful check returns Warning, but still permits registration and deployment and continues the testing suite.
-
Click Run to begin testing. When testing starts, you can monitor the progress and view results for individual tests in the plan from the Results tab for the test. You can also view the applied General settings on the Overview and Resources tabs.
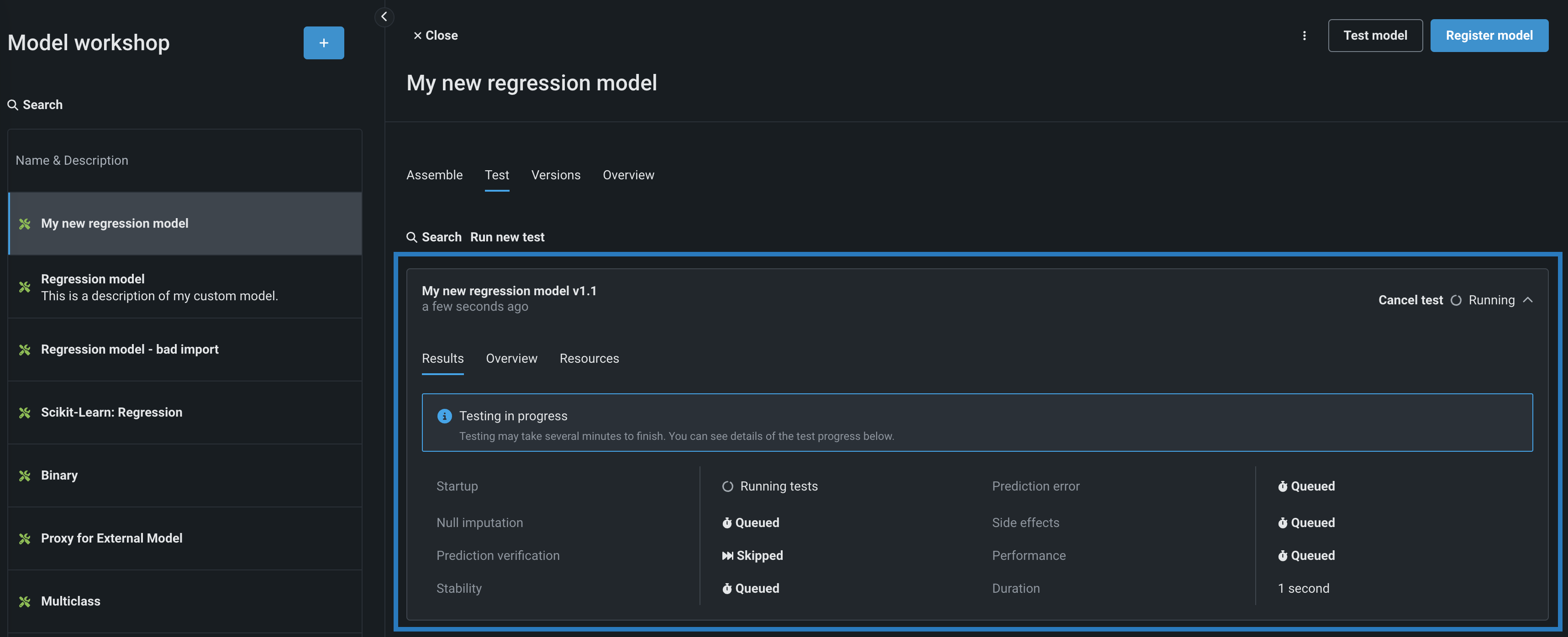
-
When testing is complete, DataRobot displays the results for each test on the Results tab. If all testing succeeds, the model is ready to register. For certain tests, you can click See details to learn more. To view any errors that occurred, on the Results tab, click View Full Log (the log is also available for download by selecting Download Log).
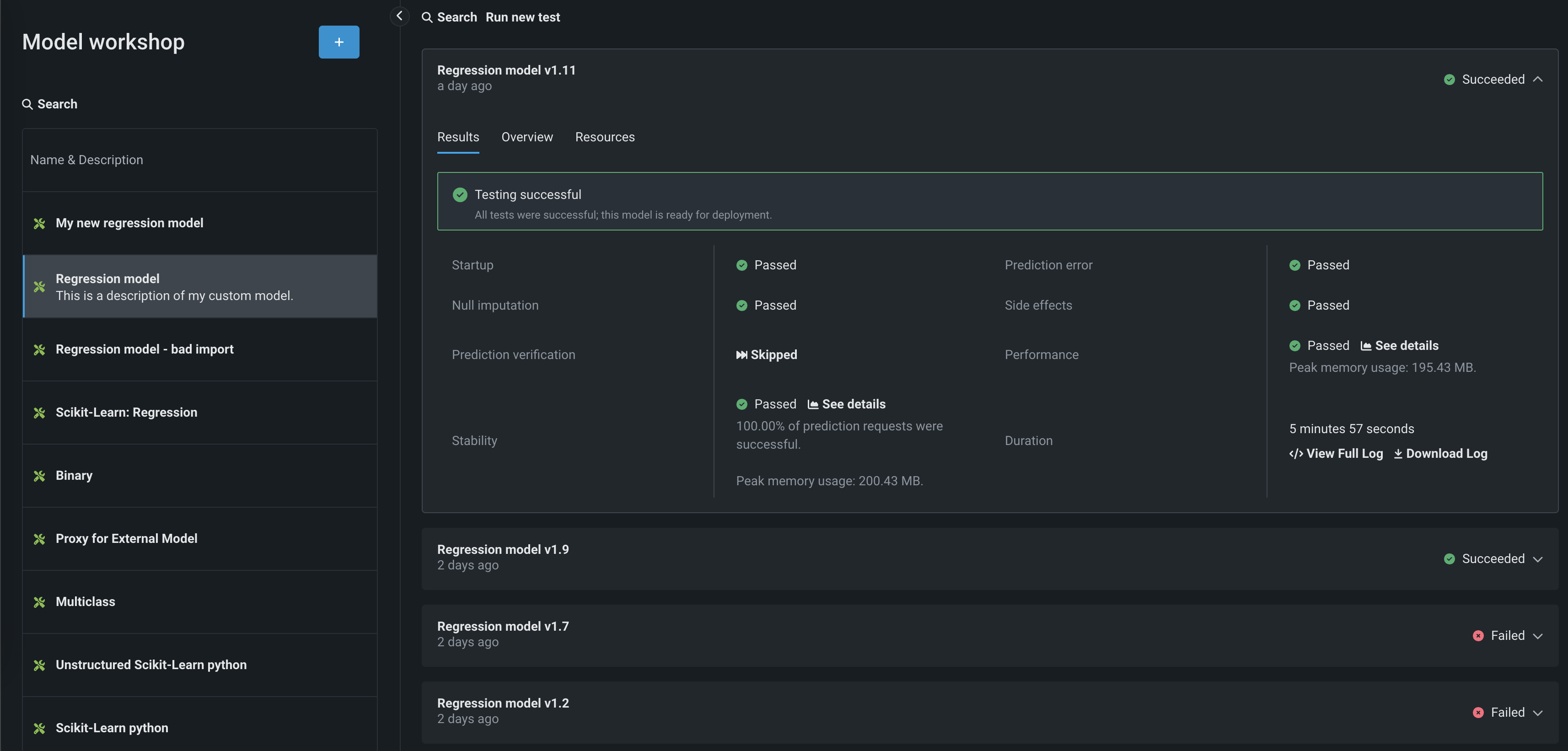
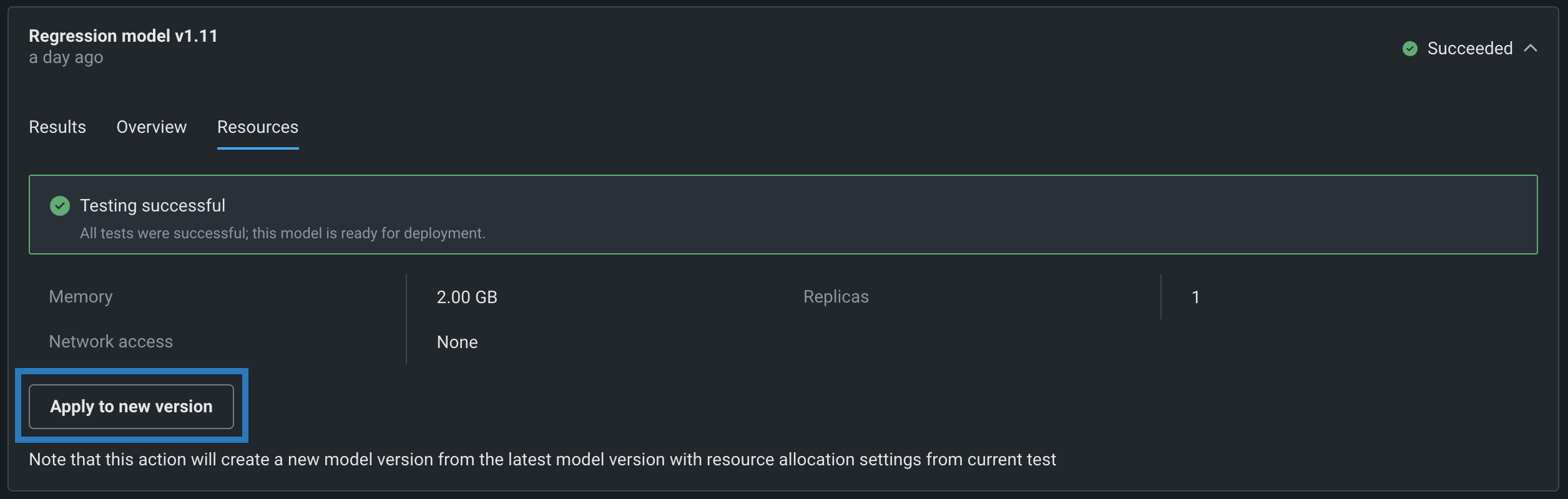
If you are satisfied with the test's configured resource settings, you can open the Resources tab and click Apply to new version to create a new custom model version with the resource allocation settings from the current test run.
Testing insights¶
Individual tests offer specific insights. Click See details on a completed test to view insights for any of the following tests:
| Test type | Details provided |
|---|---|
| Prediction verification | Displays a histogram of differences between the model predictions and the reference predictions, along with the option to exclude differences that represent matching predictions. In addition to the histogram, the prediction verification insights include a table containing rows for which model predictions do not match with reference predictions. The table values can be ordered by row number, or by the difference between a model prediction and a reference prediction. |
| Stability | Displays the Memory usage chart. This data requires the model to use a DRUM-based execution environment. The red line represents the maximum memory allocated for the model. The blue line represents how memory was consumed by the model. Memory usage is gathered from several replicas; the data displayed on the chart is coming from a different replica each time. The data displayed on the chart is likely to differ from multi-replica setups. For multi-replica setups, the memory usage chart is constructed by periodically pulling the memory usage stats from a random replica. This means that if the load is distributed evenly across all the replica, the chart shows the memory usage of each replica's model. The model's usage can slightly exceed the maximum memory allocated because model termination logic depends on an underlying executor. Additionally, a model can be terminated even if the chart shows that its memory usage has not exceeded the limit, because the model is terminated before updated memory usage data is fetched from it. |
| Performance | Displays the Prediction response timing chart, showing the response time observed at different payload sample sizes. For each sample, you can see the minimum, average, and maximum prediction request time, along with the requests per second (RPS), and error rate. The prediction requests made to the model during testing bypass the prediction server, so the latency numbers will be slightly higher in a production environment as the prediction server will add some latency. In addition, this test type provides the Memory usage chart with data points for each Payload delivery. |