Monitoring jobs¶
To integrate more closely with external data sources, monitoring job definitions allow DataRobot to monitor deployments running and storing feature data, predictions, actuals, and custom metrics outside of DataRobot. For example, you can create a monitoring job to connect to Snowflake, fetch raw data from the relevant Snowflake tables, and send the data to DataRobot for monitoring purposes. You can then view and manage monitoring job definitions as you would any other job definition.
Service health information for external models and monitoring jobs
Service health information is unavailable for external agent-monitored deployments and deployments with predictions uploaded through a prediction monitoring job.
Time series model consideration
Monitoring jobs don't support monitoring predictions made by time series models.
To create monitoring jobs, in the deployment you want to create a job for, click Monitoring > Monitoring jobs, then, on the Job Definitions page, click Add Job Definition. On the New Monitoring Job Definition page, configure the following options:
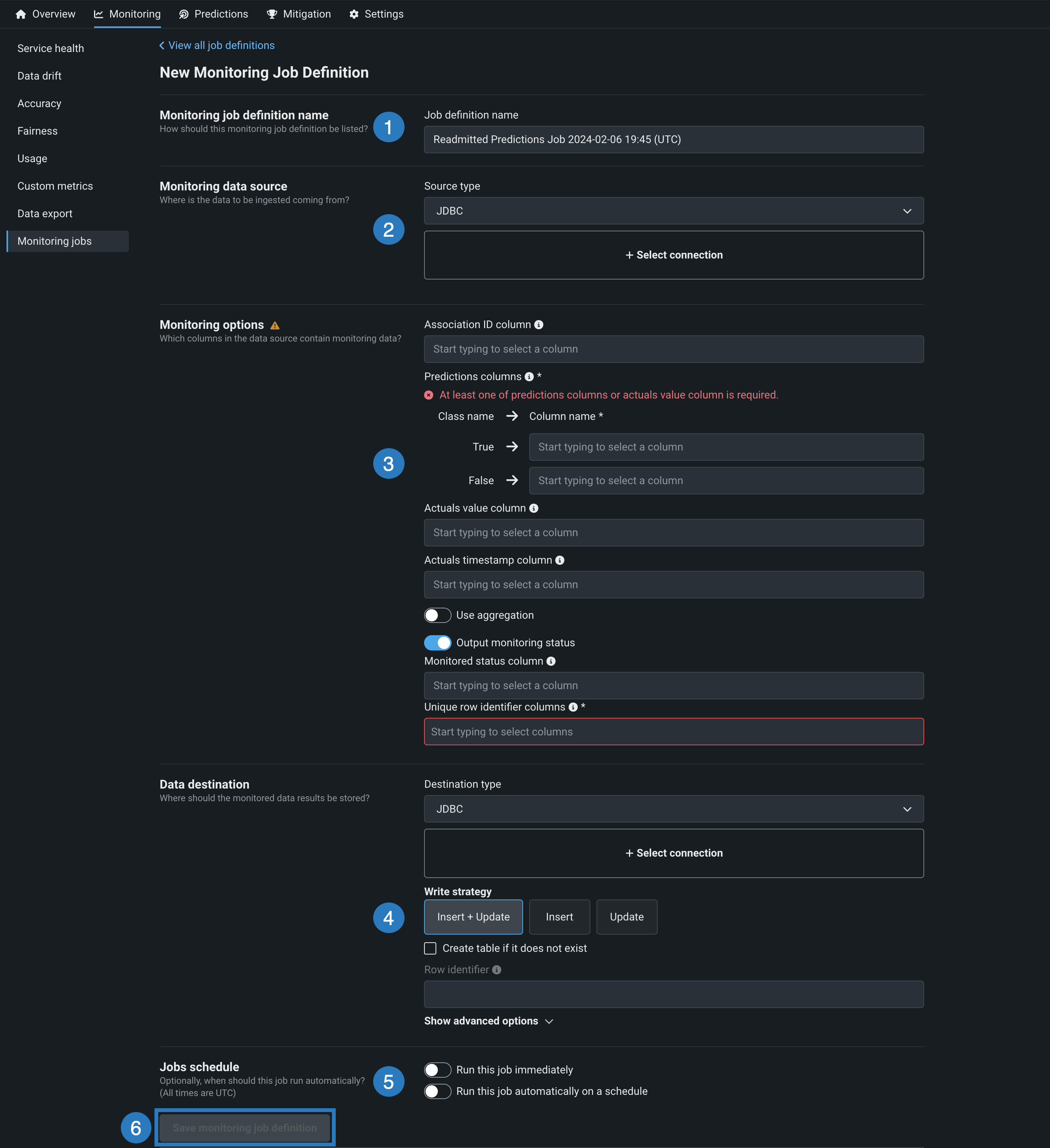
| Field name | Description | |
|---|---|---|
| 1 | Monitoring job definition name | Enter the name of the monitoring job that you are creating for the deployment. |
| 2 | Monitoring data source | Set the source type and define the connection for the data to be scored. |
| 3 | Monitoring options | Configure predictions and actuals or custom metrics (preview feature) monitoring options. |
| 4 | Data destination | (Optional) Configure the data destination options if you enable output monitoring. |
| 5 | Jobs schedule | Configure whether to run the job immediately and whether to schedule the job. |
Set monitoring data source¶
Select a monitoring source, called an intake adapter, and complete the appropriate authentication workflow for the source type. Select a connection type below to view field descriptions:
Note
When browsing for connections, invalid adapters are not shown.
Database connections
Cloud storage connections
Data warehouse connections
Other
After you set your monitoring source, DataRobot validates that the data is applicable to the deployed model.
Note
DataRobot validates that a data source is compatible with the model when possible, but not in all cases. DataRobot validates for Data Registry, most JDBC connections, Snowflake, and Synapse.
Set monitoring options¶
In the Monitoring options section, you can configure a Predictions and actuals monitoring job or a Custom metrics monitoring job.
Configure predictions and actuals options¶
Monitoring job definitions allow DataRobot to monitor deployments that are running and storing feature data, predictions, and actuals outside of DataRobot.
In the Monitoring Options section, on the Predictions and actuals tab, the options available depend on the model type: regression or classification.
Important: Association ID for monitoring agent and monitoring jobs
You must set an association ID before making predictions to include those predictions in accuracy tracking. For agent-monitored external model deployments with challengers (and monitoring jobs for challengers), the association ID should be __DataRobot_Internal_Association_ID__ to report accuracy for the model and its challengers.
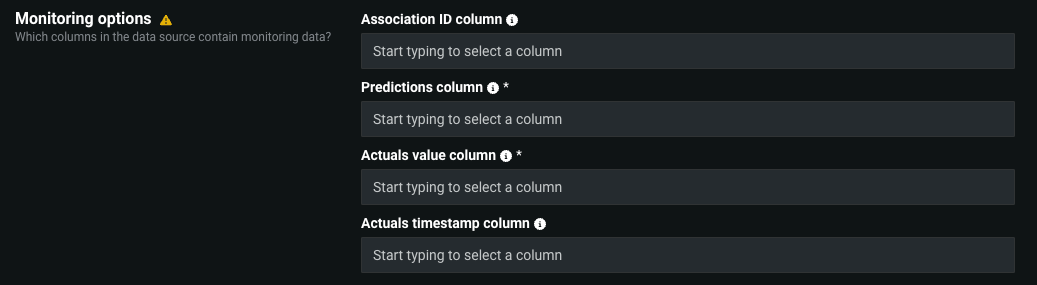
| Option | Description |
|---|---|
| Association ID column | Identifies the column in the data source containing the association ID for predictions. |
| Predictions column | Identifies the column in the data source containing prediction values. You must provide this field and/or Actuals value column. |
| Actuals value column | Identifies the column in the data source containing actual values. You must provide this field and/or Predictions column. |
| Actuals timestamp column | Identifies the column in the data source containing the timestamps for actual values. |
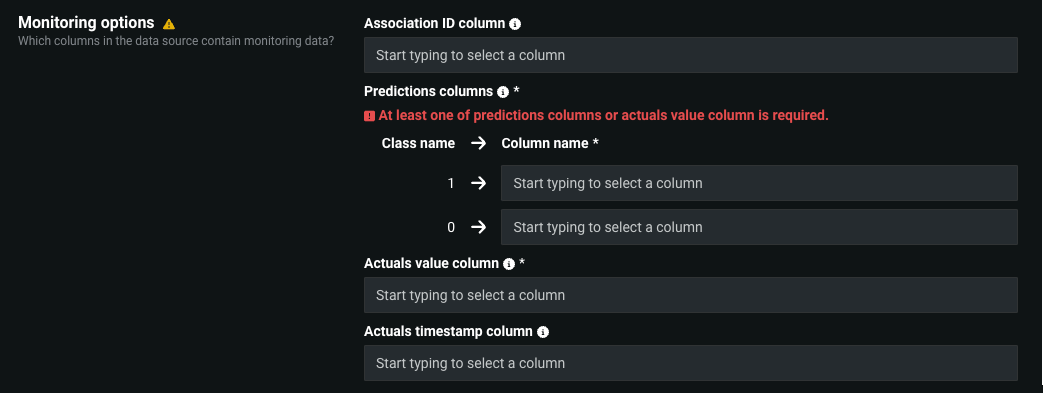
| Option | Description |
|---|---|
| Association ID column | Identifies the column in the data source containing the association ID for predictions. |
| Predictions column | Identifies the columns in the data source containing each prediction class. You must provide this field and/or Actuals value column. |
| Actuals value column | Identifies the column in the data source containing actual values. You must provide this field and/or Predictions column. |
| Actuals timestamp column | Identifies the column in the data source containing the timestamps for actual values. |
Set aggregation options¶
To support challengers for external models with large-scale monitoring enabled (meaning that raw data isn't stored in the DataRobot platform), you can report a small sample of raw feature and prediction data; then, you can send the remaining data in aggregate format. Enable Use aggregation and configure the retention settings to indicate that raw data is aggregated by the MLOps library and define how much raw data should be retained for challengers.
Autosampling for large-scale monitoring
To automatically report a small sample of raw data for challenger analysis and accuracy monitoring, you can define the MLOPS_STATS_AGGREGATION_AUTO_SAMPLING_PERCENTAGE when enabling large-scale monitoring for an external model.

| Property | Description |
|---|---|
| Retention policy | The policy definition determines if the Retention value represents a number of Samples or a Percentage of the dataset. |
| Retention value | The amount of data to retain, either a percentage of data or the number of samples. |
If you define these properties, raw data is aggregated by the MLOps library. This means that the data isn't stored in the DataRobot platform. Stats aggregation only supports feature and prediction data, not actuals data for accuracy monitoring. If you've defined one or more of the Association ID column, Actuals value column, or Actuals timestamp column, DataRobot cannot aggregate data. If you enable the Use aggregation option, the association ID and actuals-related fields are disabled.
Preview feature: Accuracy monitoring with aggregation
Now available for preview, monitoring jobs for external models with aggregation enabled can support accuracy tracking. With this feature enabled, when you enable Use aggregation and configure the retention settings, you can also define the Actuals value column for accuracy monitoring; however, you must also define the Predictions column and Association ID column.
Feature flag OFF by default: Enable Accuracy Aggregation
Set output monitoring and data destination options¶
After setting the prediction and actuals monitoring options, you can choose to enable Output monitoring status and configure the following options:
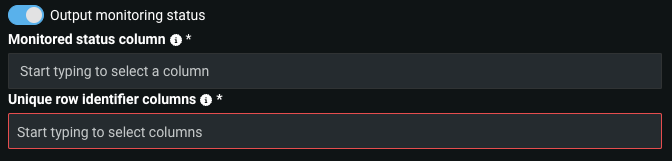
| Option | Description |
|---|---|
| Monitored status column | Identifies the column in the data destination containing the monitoring status for each row. |
| Unique row identifier columns | Identifies the columns from the data source to serve as unique identifiers for each row. These columns are copied to the data destination to associate each monitored status with its corresponding source row. |
With Output monitoring status enabled, you must also configure the Data destination options to specify where the monitored data results should be stored. Select a monitoring data destination, called an output adapter, and complete the appropriate authentication workflow for the destination type. Select a connection type below to view field descriptions:
Note
When browsing for connections, invalid adapters are not shown.
Database connections
Cloud storage connections
Data warehouse connections
Configure custom metric options¶
Preview
Monitoring jobs for custom metrics are off by default. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Custom Metrics Job Definitions
Monitoring job definitions allow DataRobot to pull calculated custom metric values from outside of DataRobot into the custom metric defined on the Custom metrics tab, supporting custom metrics with external data sources.
In the Monitoring options section, click Custom metrics and configure the following options:
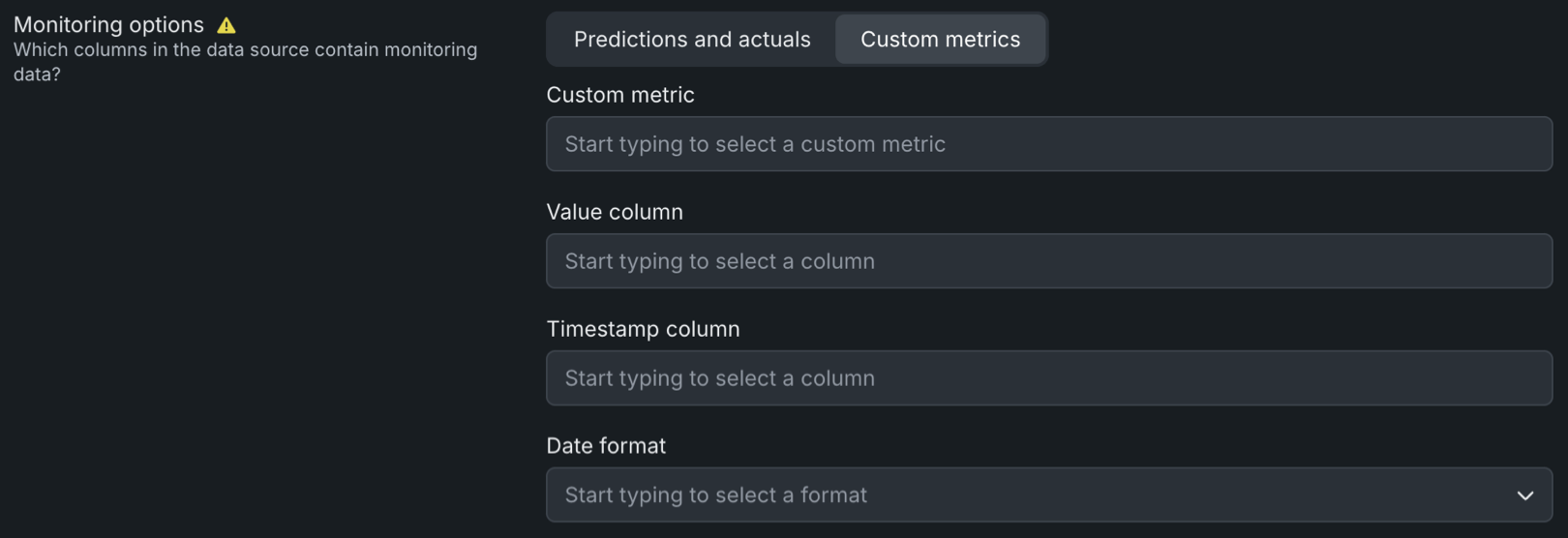
| Field | Description |
|---|---|
| Custom metric | Select the custom metric you want to monitor from the current deployment. |
| Value column | Select the column in the dataset containing the calculated values of the custom metric. |
| Timestamp column | Select the column in the dataset containing a timestamp. |
| Date format | Select the date format used by the timestamp column. |
Schedule monitoring jobs¶
You can schedule monitoring jobs to run automatically on a schedule. When outlining a monitoring job definition, enable Run this job automatically on a schedule, then specify the frequency (daily, hourly, monthly, etc.) and time of day to define the schedule on which the job runs.
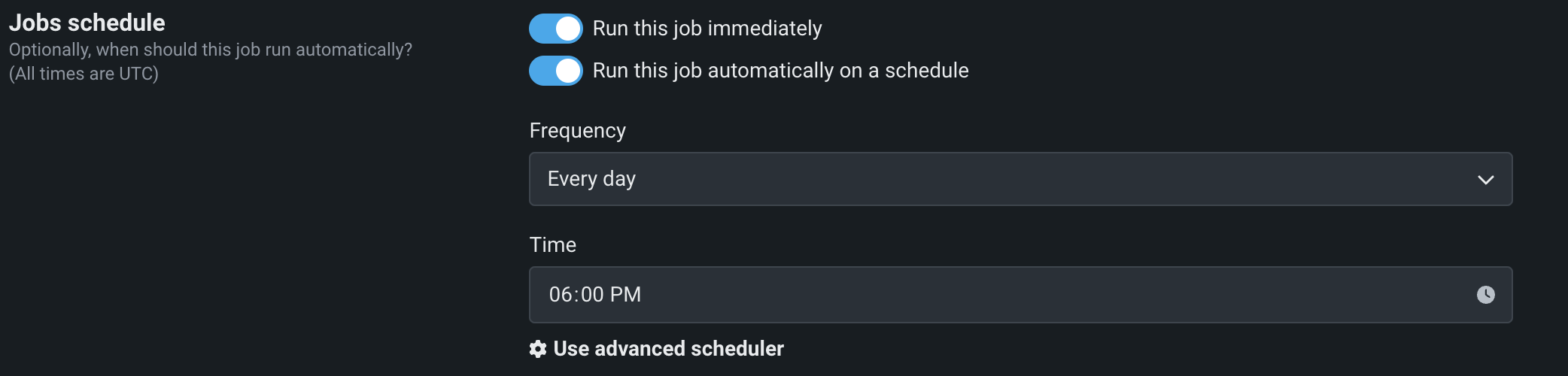
For further granularity, select Use advanced scheduler. You can set the exact time (to the minute) you want to run the monitoring job.
Save monitoring job definition¶
After setting all applicable options, click Save monitoring job definition. The button text changes to Save and run monitoring job definition if Run this job immediately is enabled.
Validation errors
This button is disabled if there are any validation errors.