Set up data drift monitoring¶
When deploying a model, there is a chance that the dataset used for training and validation differs from the prediction data. You can enable data drift monitoring on the Settings > Data drift tab. DataRobot monitors both target and feature drift information and displays results on the Monitoring > Data drift tab.
How does DataRobot track drift?
DataRobot tracks two types of drift:
-
Target drift: DataRobot stores statistics about predictions to monitor how the distribution and values of the target change over time. As a baseline for comparing target distributions, DataRobot uses the distribution of predictions on the holdout.
-
Feature drift: DataRobot stores statistics about predictions to monitor how distributions and values of features change over time. The supported feature data types are numeric, categorical, and text. As a baseline for comparing distributions of features:
-
For training datasets larger than 500MB, DataRobot uses the distribution of a random sample of the training data.
-
For training datasets smaller than 500MB, DataRobot uses the distribution of 100% of the training data.
-
On a deployment's Data Drift Settings page, configure the following settings:
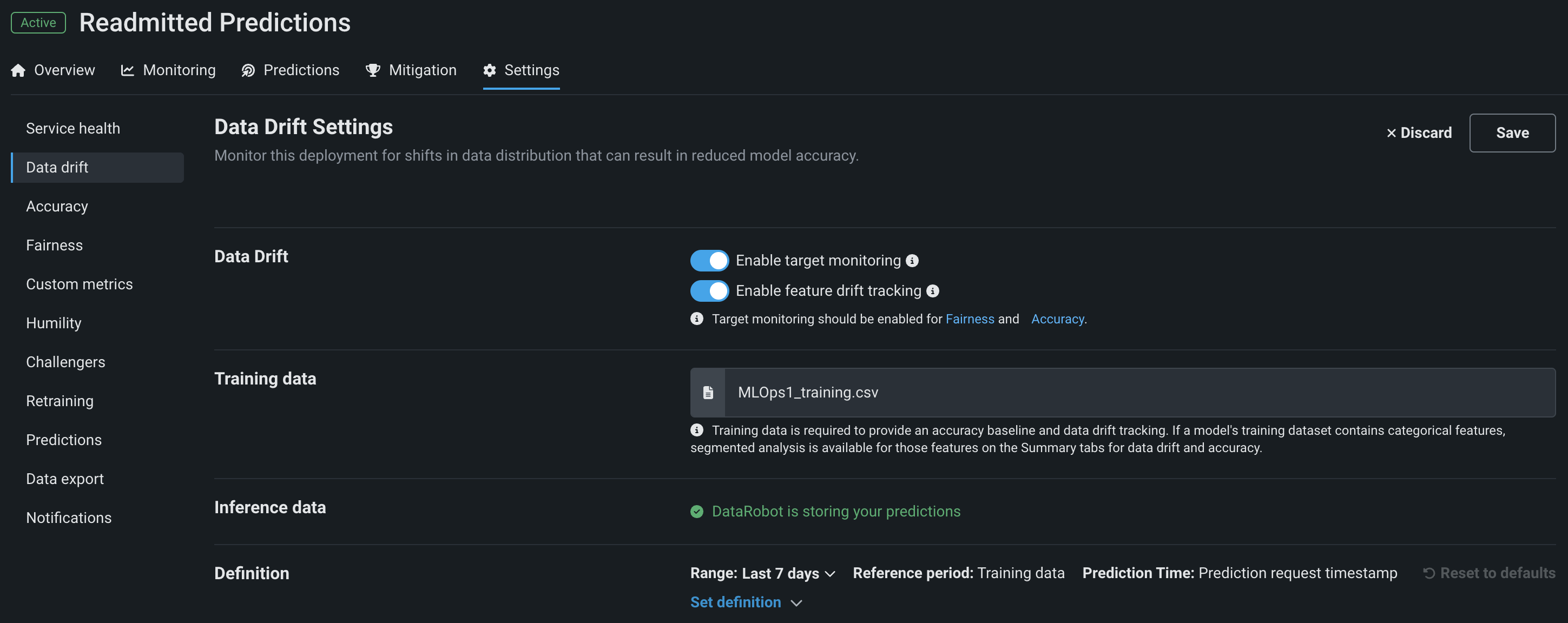
| Field | Description |
|---|---|
| Data Drift | |
| Enable feature drift tracking | Configures DataRobot to track feature drift in a deployment. Training data is required for feature drift tracking. |
| Enable target monitoring | Configures DataRobot to track target drift in a deployment. Target monitoring is required for accuracy monitoring. |
| Training data | |
| Training data | Displays the dataset used as a training baseline while building a model. |
| Feature drift | |
| Feature drift | Defines the strategy used to select the 25 features tracked for feature drift in the deployment. |
| Inference data | |
| DataRobot is storing your predictions | Confirms DataRobot is recording and storing the results of any predictions made by this deployment. DataRobot stores a deployment's inference data when a deployment is created. It cannot be uploaded separately. |
| Inference data (external model) | |
| DataRobot is recording the results of any predictions made against this deployment | Confirms DataRobot is recording and storing the results of any predictions made by the external model. |
| Drop file(s) here or choose file | Uploads a file with prediction history data to monitor data drift. |
| Definition | |
| Set definition | Configures the drift and importance metric settings and threshold definitions for data drift monitoring. |
Availability information
Data drift tracking is only available for deployments using deployment-aware prediction API routes (i.e., https://example.datarobot.com/predApi/v1.0/deployments/<deploymentId>/predictions).
Data privacy notice
DataRobot monitors both target and feature drift information by default and displays results on the Monitoring > Data drift tab. Use the Enable target monitoring and Enable feature drift tracking toggles to turn off tracking if, for example, you have sensitive data that should not be monitored in the deployment. The Enable target monitoring setting is also required to enable accuracy monitoring.
Customize feature drift tracking¶
When feature drift tracking is enabled for a deployment, the Feature drift section appears. Choose one of the following strategies to select the 25 features tracked:

Supported feature data types
The supported feature data types are numeric, categorical, and text.
-
Automatic: (Default) DataRobot selects the 25 features.
-
Manual: Click Select features and select up to 25 features from the list (sorted by importance).

Manual feature selection considerations
In the feature selection table:
-
Features are sorted by feature importance in descending order. The secondary sort is alphabetical order by name.
-
Not all features have an importance value and some features may have a negative value.
-
For deployments of external models, the feature importance value is unavailable.
-
For deployments of Leaderboard or custom models with training data, the table uses normalized ACE as the importance value, not Feature Impact.
-
For deployments of text generation models, the table uses an assigned score—the target is 1.0, text features are 0.9, and other features are 0.1.
For all deployments with manual feature selection enabled:
-
Only the selected features are tracked for drift. If a feature is not selected, it is not tracked, even if the feature exists in prediction requests or uploaded statistics.
-
Switching from manual to automatic selection may result in the removal of previously tracked features from drift tracking if they are not important enough.
-
Accumulated feature drift statistics are not removed by switching back and forth between automatic and manual or by adding or removing tracked features.
When manually selecting features for drift tracking:
-
The available features are taken from the champion model project's feature list (if applicable) or training dataset (if applicable).
-
The supported feature data types are numeric, categorical, and text.
-
For deployments with imported model packages as champion, the only supported features are those with a pre-calculated baseline (in the .mlpkg file).
-
For deployments with a Leaderboard model as champion:
-
For non-time series models, any supported feature in a project’s feature list is available, even if a feature is not part of model’s feature list.
-
For time series non-segmented models, any supported feature in a model’s feature list is available.
-
For time series segmented models, feature drift isn’t supported.
-
-
For deployments with a custom model as champion:
-
For non-timeseries models, any supported column in the training data is available.
-
For time series models, any supported column in the training data is available.
-
-
For deployments with external models, any supported column in the training data is available.
During model replacement:
-
Features currently selected are removed after replacement if they are not supported or included in the replacement model.
-
Feature drift is disabled if none of the currently selected features are eligible for tracking in the replacement model.
-
A model replacement validation warning is displayed if either of these changes will happen after replacement.
Define data drift monitoring notifications¶
Drift assesses how the distribution of data changes across all features for a specified range. The thresholds you set determine the amount of drift you will allow before a notification is triggered.
Drift monitoring configuration permissions
Only deployment Owners can modify data drift monitoring settings; however, Users can configure the conditions under which notifications are sent to them. Consumers cannot modify monitoring or notification settings.
In addition, deployment Owners can customize the rules (or definitions) used to calculate the drift status for each deployment. As a deployment Owner, you can:
-
Define or override the list of high or low-importance features to monitor features that are important to you or put less emphasis on less important features.
-
Exclude features expected to drift from drift status calculation and alerting so you do not get false alarms.
-
Customize what "At Risk" and "Failing" drift statuses mean to personalize and tailor the drift status of each deployment to your needs.
Use the Definition section of the Settings > Data drift tab to set thresholds for drift and importance:
-
Drift is a measure of how new prediction data differs from the original data used to train the model.
-
Importance allows you to separate the features you care most about from those that are less important.
For both drift and importance, you can visualize the thresholds and how they separate the features on the Data drift tab. By default, the data drift status for deployments is marked as "Failing" (![]() ) when at least one high-importance feature exceeds the set drift metric threshold; it is marked as "At Risk" (
) when at least one high-importance feature exceeds the set drift metric threshold; it is marked as "At Risk" (![]() ) when no high-importance features, but at least one low-importance feature exceeds the threshold.
) when no high-importance features, but at least one low-importance feature exceeds the threshold.
To set up drift status monitoring for a deployment, on the Data Drift Settings page, in the Definition section, configure the settings for monitoring data drift:
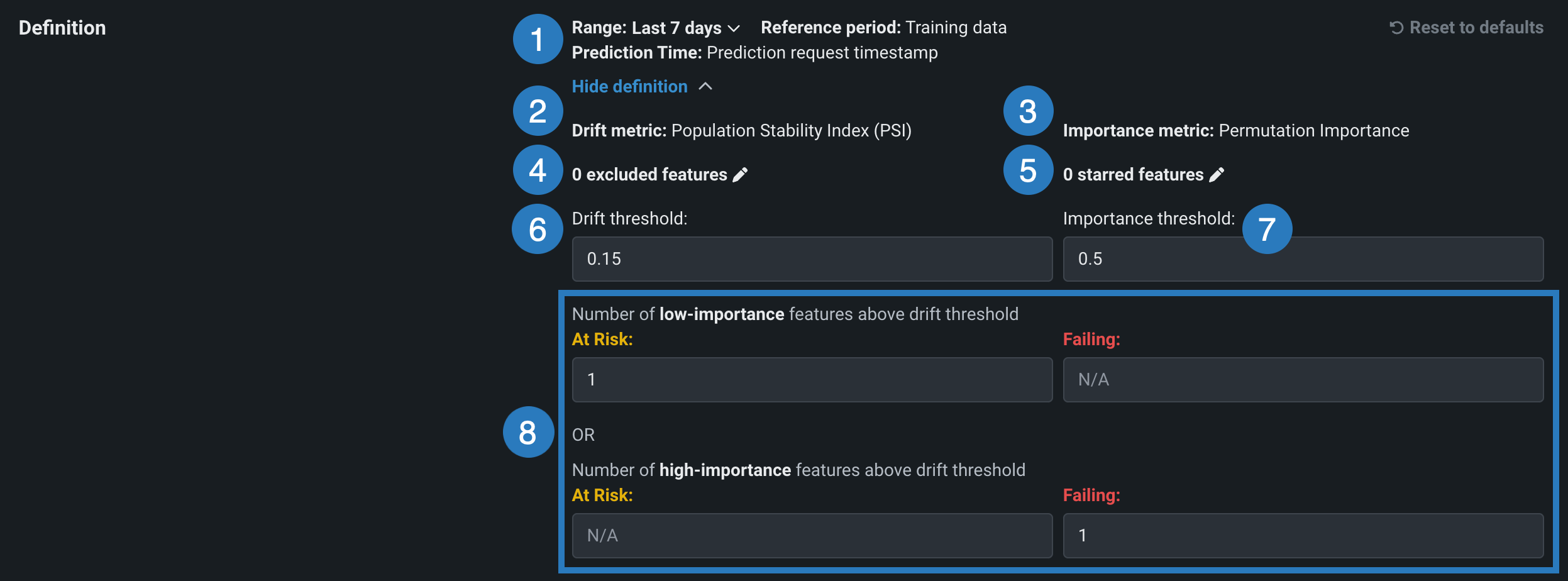
| Element | Description | |
|---|---|---|
| 1 | Range | Adjusts the time range of the Reference period, which compares training data to prediction data. Select a time range from the dropdown menu. |
| 2 | Drift metric | DataRobot only supports the Population Stability Index (PSI) metric. For more information, see the note on Drift metric support below. |
| 3 | Importance metric | DataRobot only supports the Permutation Importance metric. The importance metric measures the most impactful features in the training data. |
| 4 | X excluded features |
Excludes features (including the target) from drift status calculations. Click X excluded features to open a dialog box where you can enter the names of features to set as Drift exclusions. Excluded features do not affect drift status for the deployment but still display on the Feature Drift vs. Feature Importance chart. |
| 5 | X starred features |
Sets features to be treated as high importance even if they were initially assigned low importance. Click X starred features to open a dialog box where you can enter the names of features to set as High-importance stars. Once added, these features are assigned high importance. They ignore the importance thresholds, but still display on the Feature Drift vs. Feature Importance chart. |
| 6 | Drift threshold | Configures the thresholds of the drift metric. When drift thresholds are changed, the Feature Drift vs. Feature Importance chart updates to reflect the changes. |
| 7 | Importance threshold | Configures the thresholds of the importance metric. The importance metric measures the most impactful features in the training data. When drift thresholds are changed, the Feature Drift vs. Feature Importance chart updates to reflect the changes. |
| 8 | "At Risk" / "Failing" thresholds | Configures the values that trigger drift statuses for "At Risk" ( |
Note
Changes to thresholds affect the periods in which predictions are made across the entire history of a deployment. These updated thresholds are reflected in the performance monitoring visualizations on the Data drift tab.
Drift metric support
While the DataRobot UI only supports the Population Stability Index (PSI) metric, the DataRobot API also supports Kullback-Leibler Divergence, Hellinger Distance, Histogram Intersection (histogram-based dissimilarity), and Jensen–Shannon Divergence. In addition, using the Python API client, you can retrieve a list of supported metrics.