Import and deploy with NVIDIA NIM¶
Premium
The use of NVIDIA Inference Microservices (NIM) in DataRobot requires access to premium features for GenAI experimentation and GPU inference. Contact your DataRobot representative or administrator for information on enabling the required features.
The DataRobot integration with the NVIDIA AI Enterprise Suite enables users to perform one-click deployment of NVIDIA Inference Microservices (NIM) on GPUs in DataRobot Serverless Compute. This process starts in Registry, where you can import NIM containers from the NVIDIA AI Enterprise model catalog. The registered model is optimized for deployment to Console and is compatible with the DataRobot monitoring and governance framework.
NVIDIA NIM provides optimized foundational models you can add to a playground in Workbench for evaluation and inclusion in agentic blueprints, embedding models used to create vector databases, and NVIDIA NeMo Guardrails used in the DataRobot moderation framework to secure your agentic application.
Import from NVIDIA GPU Cloud (NGC)¶
On the Models tab in Registry, create a registered model from the gallery of available NIM models, selecting the model name and performance profile and reviewing the information provided on the model card.
To import from NVIDIA NGC:
-
On the Registry > Models tab, next to + Register a model, click and then Import from NVIDIA NGC.
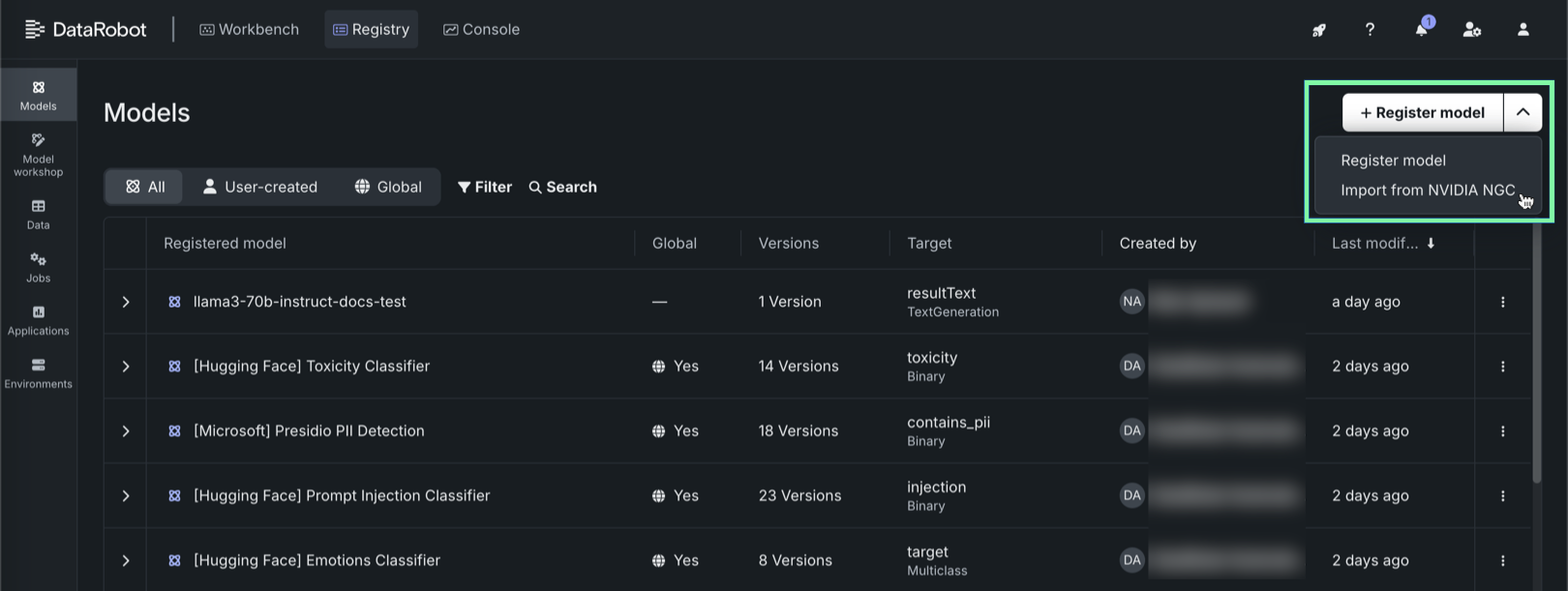
-
In the Import from NVIDIA NGC panel, on the Select NIM tab, click a NIM in the gallery.
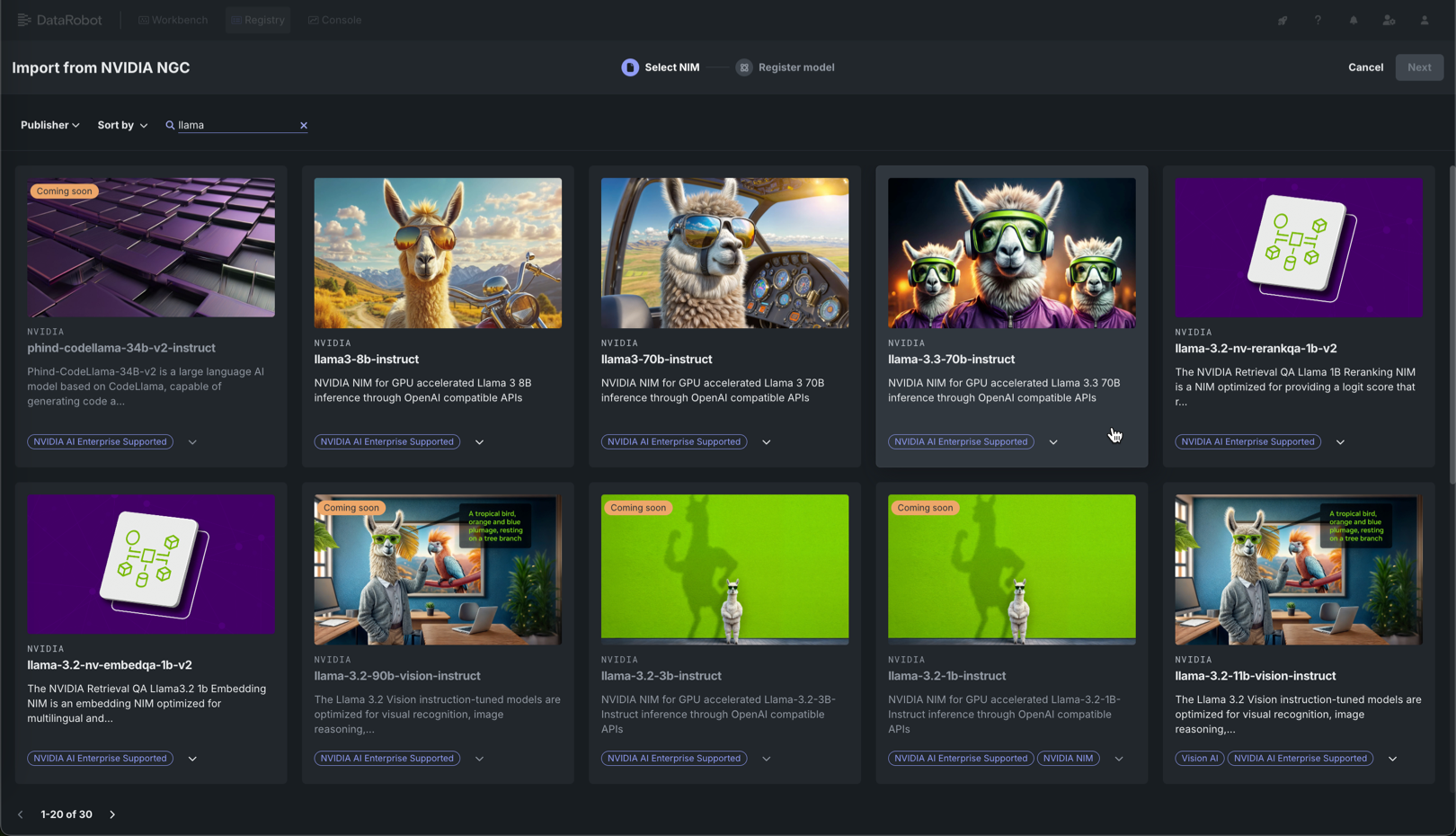
Search the gallery
To direct your search, you can Search, filter by Publisher, or click Sort by to order the gallery by date added or alphabetically (ascending or descending).
-
Review the model information from the NVIDIA NGC source, then click Next.
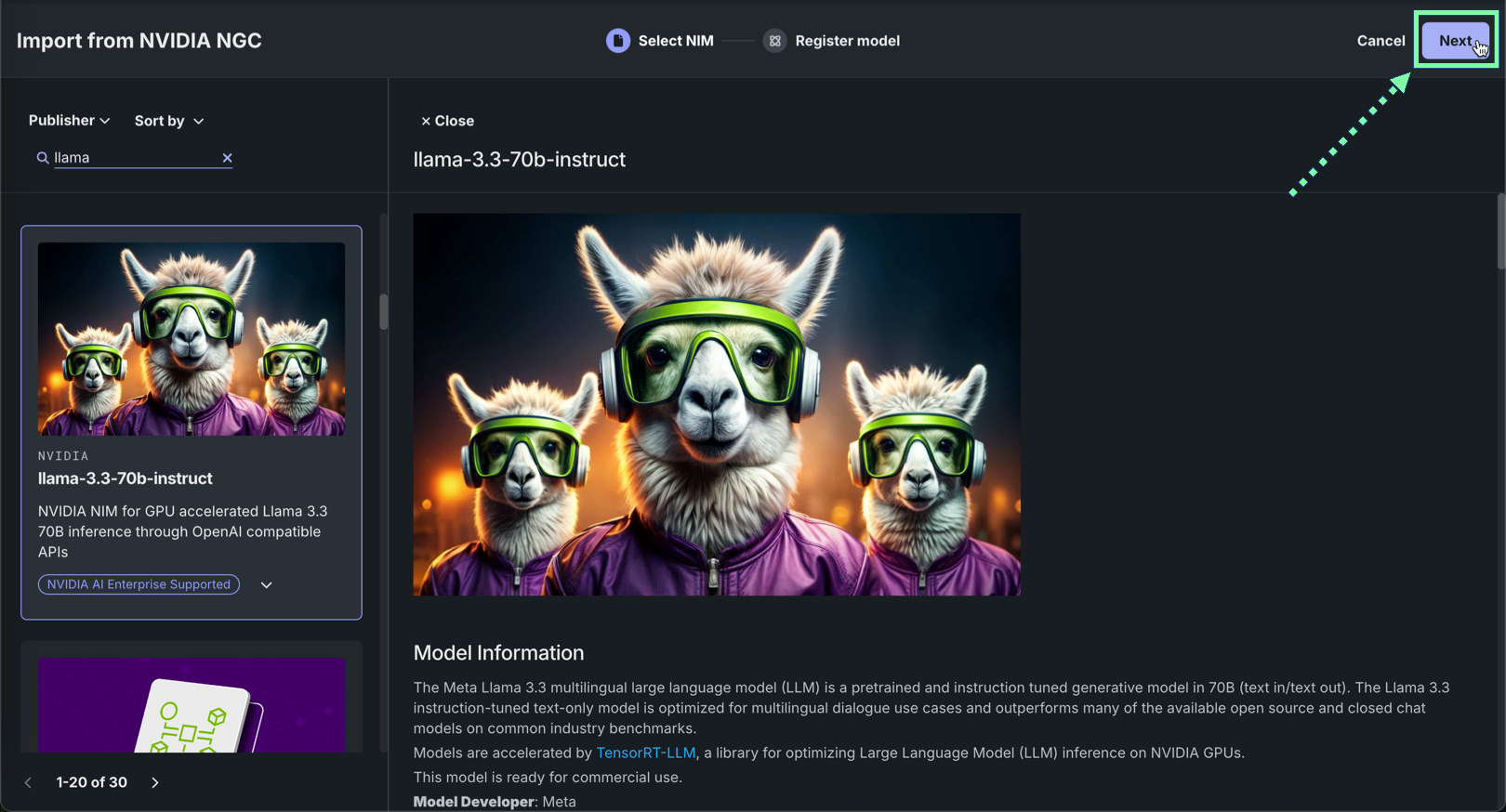
-
On the Register model tab, configure the following fields and click Register:
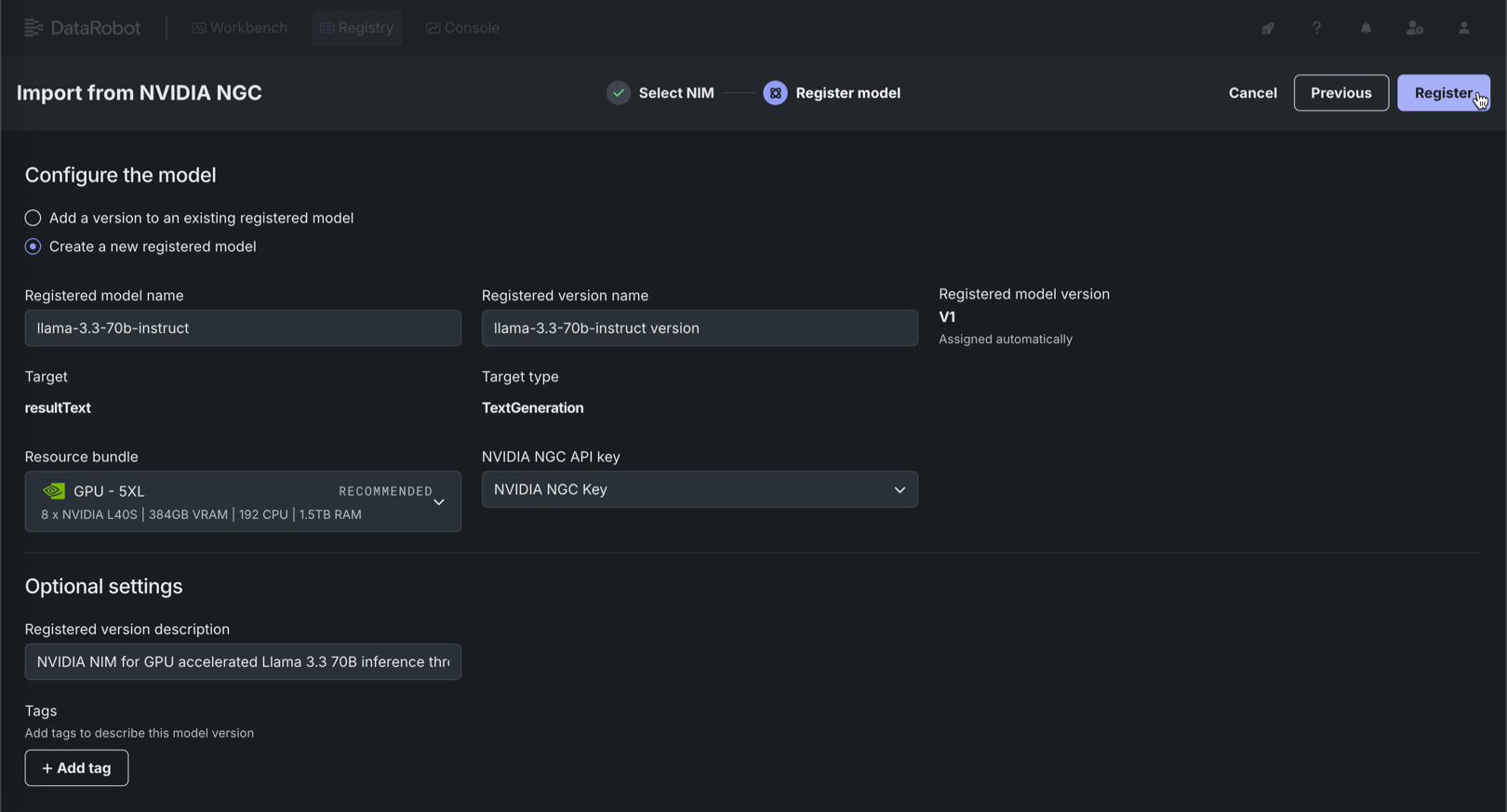
Field Description Registered model name / Registered model Configure one of the following: - Registered model name: When registering a new model, enter a unique and descriptive name for the new registered model. If you choose a name that exists anywhere within your organization, a warning appears.
- Registered model: When saving as a version of an existing model, select the existing registered model you want to add a new version to.
Registered version name Automatically populated with the model name and the word version. Change the version name or modify the default version name as necessary.Registered model version Assigned automatically. This displays the expected version number of the version (e.g., V1, V2, V3) you create. This is always V1 when you select Register as a new model. Resource bundle Recommended automatically. If possible, DataRobot translates the GPU requirements for the selected model into a resource bundle. In some cases, DataRobot can't detect a compatible resource bundle. To identify a resource bundle with sufficient VRAM, review the documentation for that NIM.
For Managed AI Platform installations, note that the GPU - 5XL resource bundle can be difficult to procure on-demand. If possible, consider a smaller resource bundle.NVIDIA NGC API key Select the credential associated with your NVIDIA NGC API key. Ensure that the selected NVIDIA NGC API key exists in your DataRobot organization, as cross-organization sharing of NVIDIA NGC API keys is unsupported. In addition, due to this restriction, cross-organization sharing of global models created with NVIDIA NIM is unsupported. Optional settings Registered version description Enter a description of the business problem this model package solves, or, more generally, describe the model represented by this version. Tags Click + Add tag and enter a Key and a Value for each key-value pair you want to tag the model version with. Tags added when registering a new model are applied to V1.
Deploy the registered NVIDIA NIM¶
After the NVIDIA NIM is registered, deploy it to a DataRobot Serverless prediction environment.
To deploy a registered model to a DataRobot Serverless environment:
-
On the Registry > Models tab, locate and click the registered NIM, and then click the version to deploy.
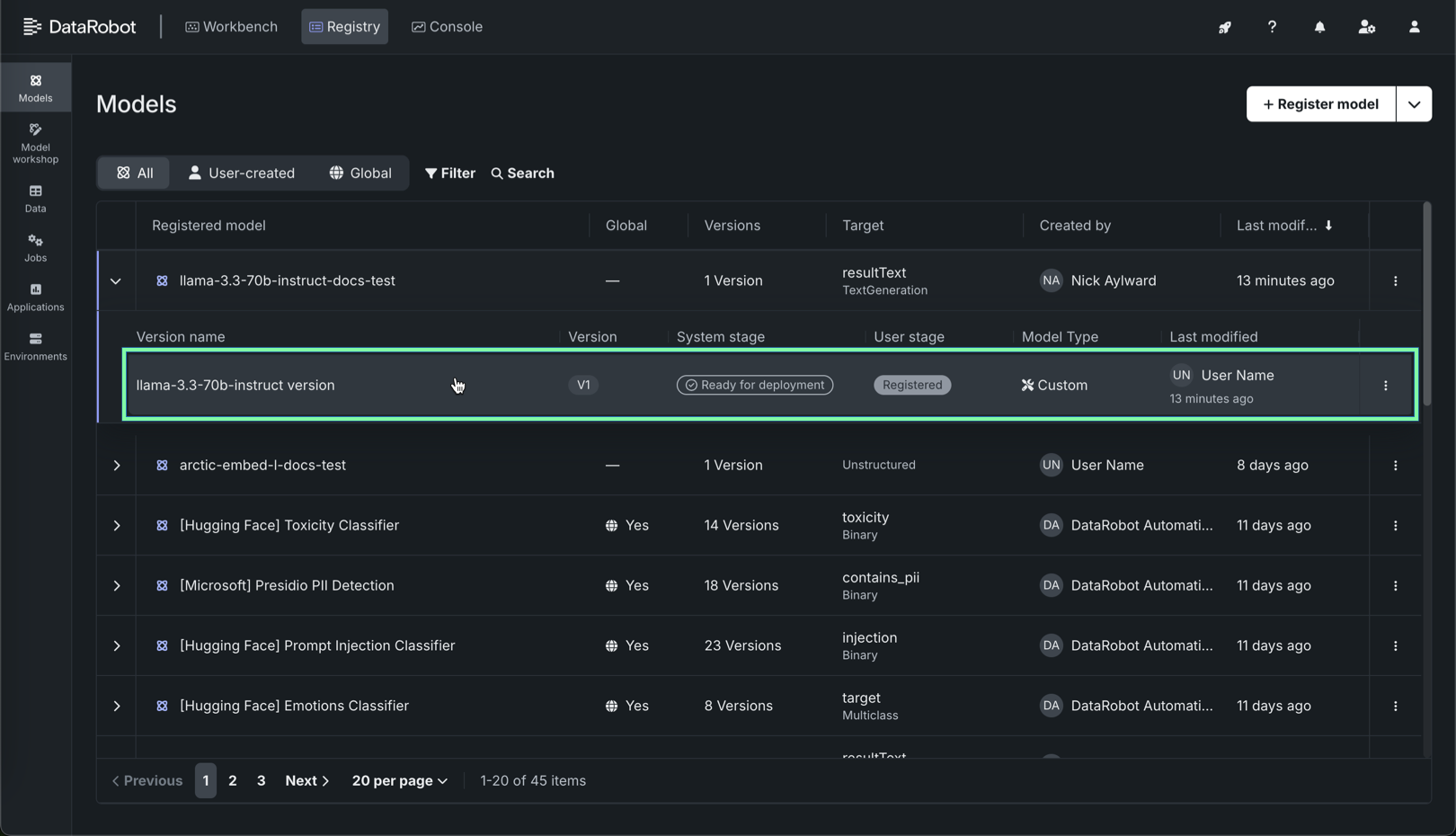
-
In the registered model version, you can review the version information, then click Deploy.
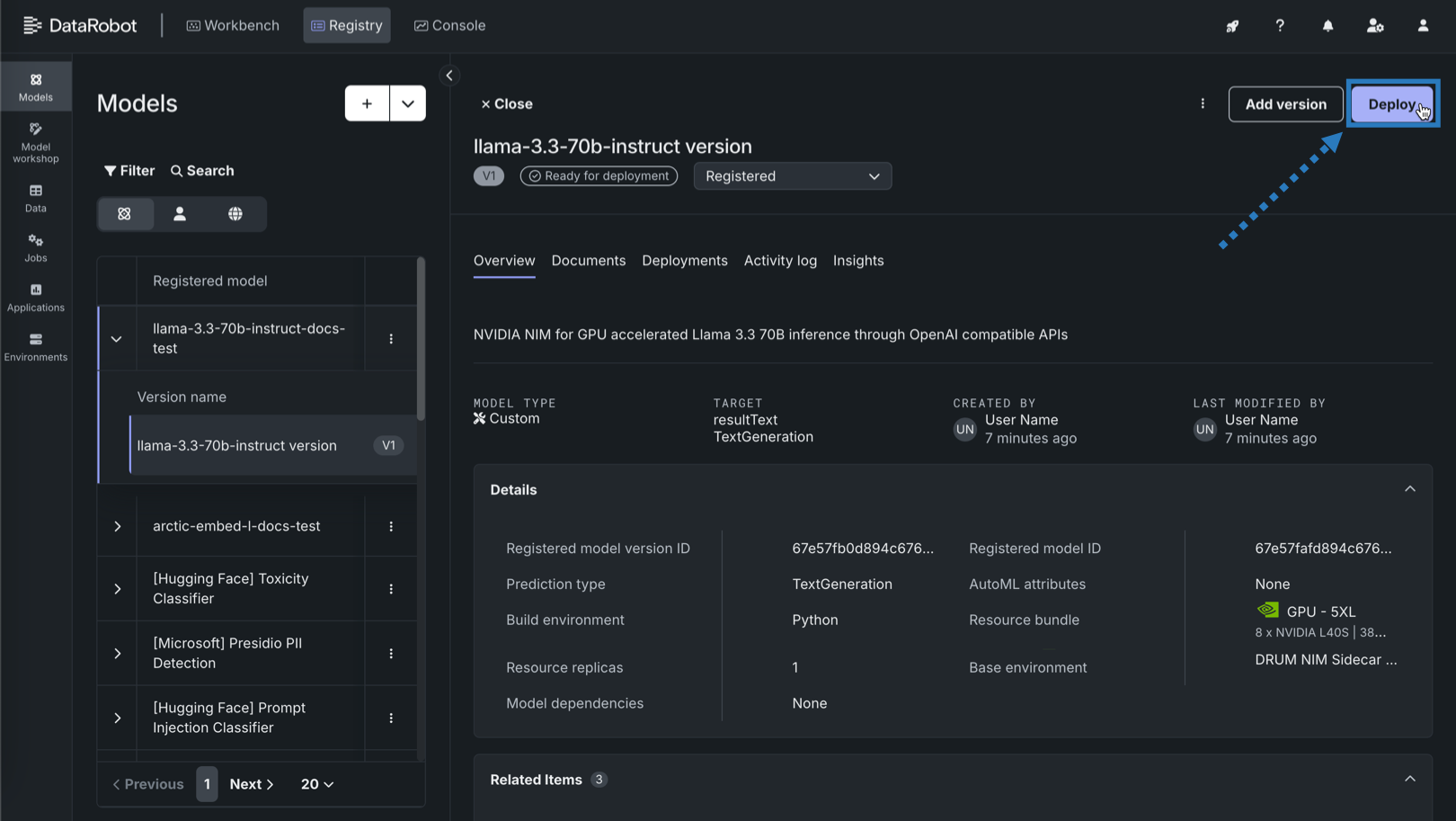
-
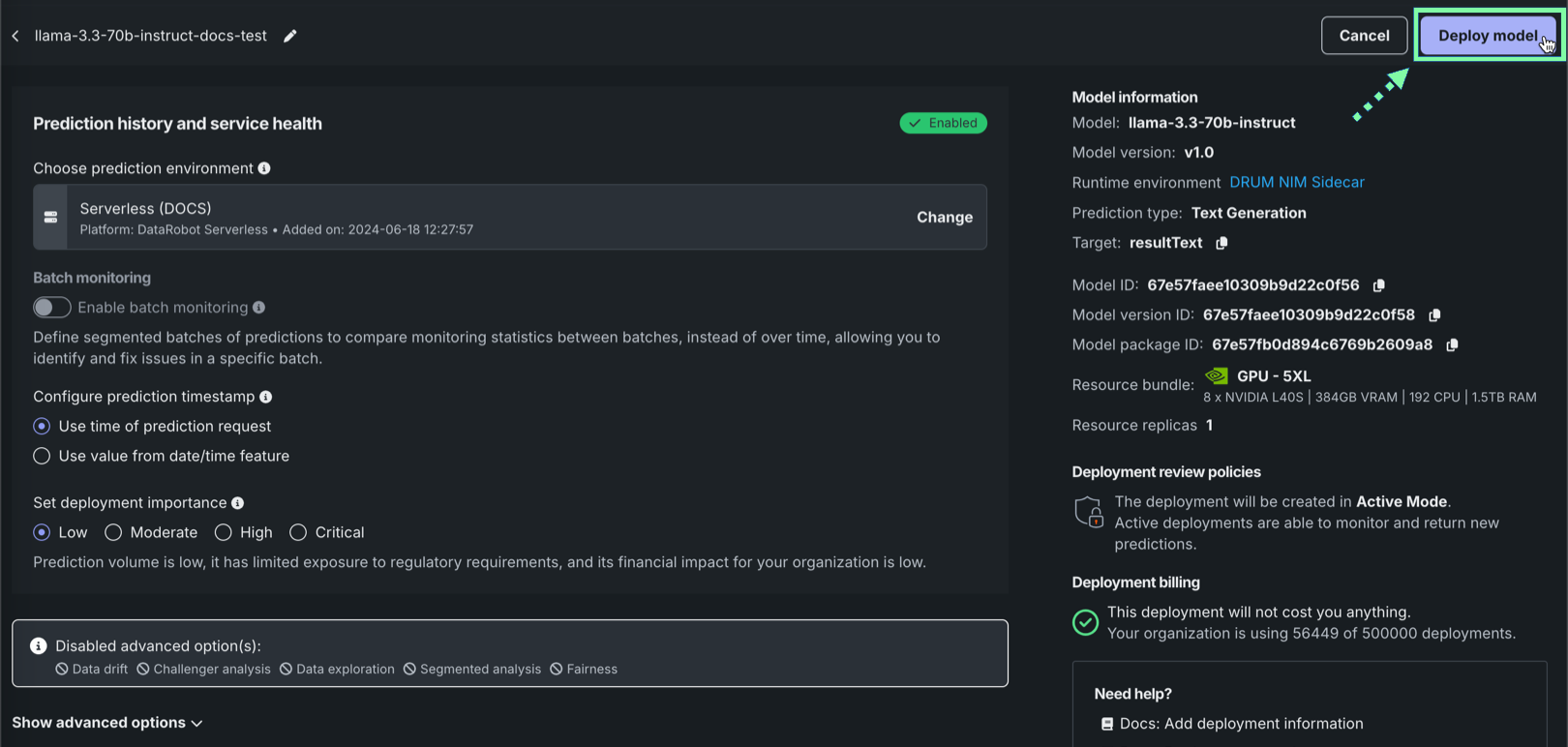
In the Prediction history and service health section, under Choose prediction environment, verify that the correct prediction environment with Platform: DataRobot Serverless is selected.
Change DataRobot Serverless environments
If the correct DataRobot Serverless environment isn't selected, click Change. On the Select prediction environment panel's DataRobot Serverless tab, select a different serverless prediction environment from the list.
-
Optionally, configure additional deployment settings. Then, when the deployment is configured, click Deploy model.
Enable the tracing table
To enable the tracing table for the NIM deployment, ensure that you enable prediction row storage in the data exploration (or challenger) settings and configure the deployment settings required to define an association ID.
Make predictions with the deployed NVIDIA NIM¶
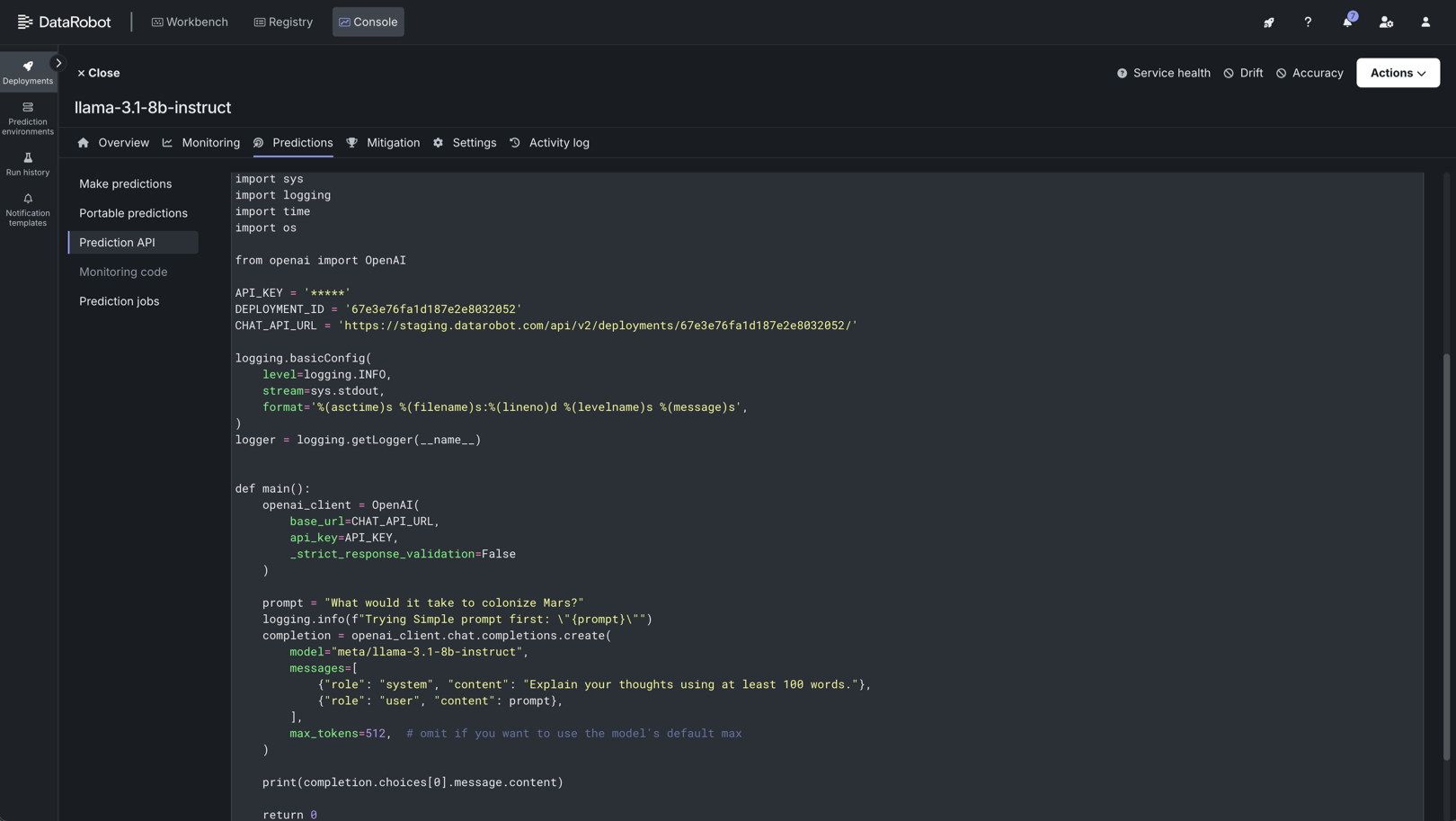
After the model is deployed to a DataRobot Serverless prediction environment, you can access real-time prediction snippets from the deployment's Predictions tab. The requirements for running the prediction snippet depend on the model type: text generation or unstructured.
When you add a NIM to Registry in DataRobot, LLMs are imported as text generation models, allowing you to use the Bolt-on Governance API to communicate with the deployed NIM. Other types of models are imported as unstructured models and endpoints provided by the NIM containers are exposed to communicate with the deployed NIM. This provides the flexibility required to deploy any NIM on GPU infrastructure using DataRobot Serverless Compute.
| Target type | Supported endpoint type | Description |
|---|---|---|
| Text generation | /chat/completions |
Deployed text generation NIM models provide access to the /chat/completions endpoint. Use the code snippet provided on the Predictions tab to make predictions. |
| Unstructured | /directAccess/nim/ |
Deployed unstructured NIM models provide access to the /directAccess/nim/ endpoint. Modify the code snippet provided on the Predictions tab to provide a NIM URL suffix and a properly formed payload. |
| Unstructured (embedding model) | Both | Deployed unstructured NIM embedding models can provide access to both the /directAccess/nim/ and /chat/completions endpoints. Modify the code snippet provided on the Predictions tab to suit your intended usage. |
CSV predictions endpoint use
With an imported text generation NIM, it is also possible to make requests to the /predictions endpoint (accepting CSV input). For CSV input submitted to the /predictions endpoint, ensure that you use promptText as the column name for user prompts to the text generation model. If the CSV input isn't provided in this format, those predictions do not appear in the deployment's tracing table.
Text generation model endpoints¶
Access the Prediction API scripting code on the deployment's Predictions > Prediction API tab. For a text generation model, the endpoint link required is the base URL of the DataRobot deployment. For more information, see the Bolt-on Governance API documentation.
Prediction snippets for Private CA environments
For Self-managed AI Platform installations in a Private Certificate Authority (Private CA) environment, the snippets provided on the Predictions tab may need to be updated, depending on how your organization's IT team configured the Private CA environment.
If your organization's Private CA environment requires modifications to the provided prediction snippet, locate the following code:
| Standard Prediction API scripting code | |
|---|---|
1 2 3 4 5 | |
Update the code above, making the following changes to allow the prediction snippet to access the Private CA bundle file:
| Private CA Prediction API scripting code | |
|---|---|
1 2 3 4 5 6 7 8 | |
Unstructured model endpoints¶
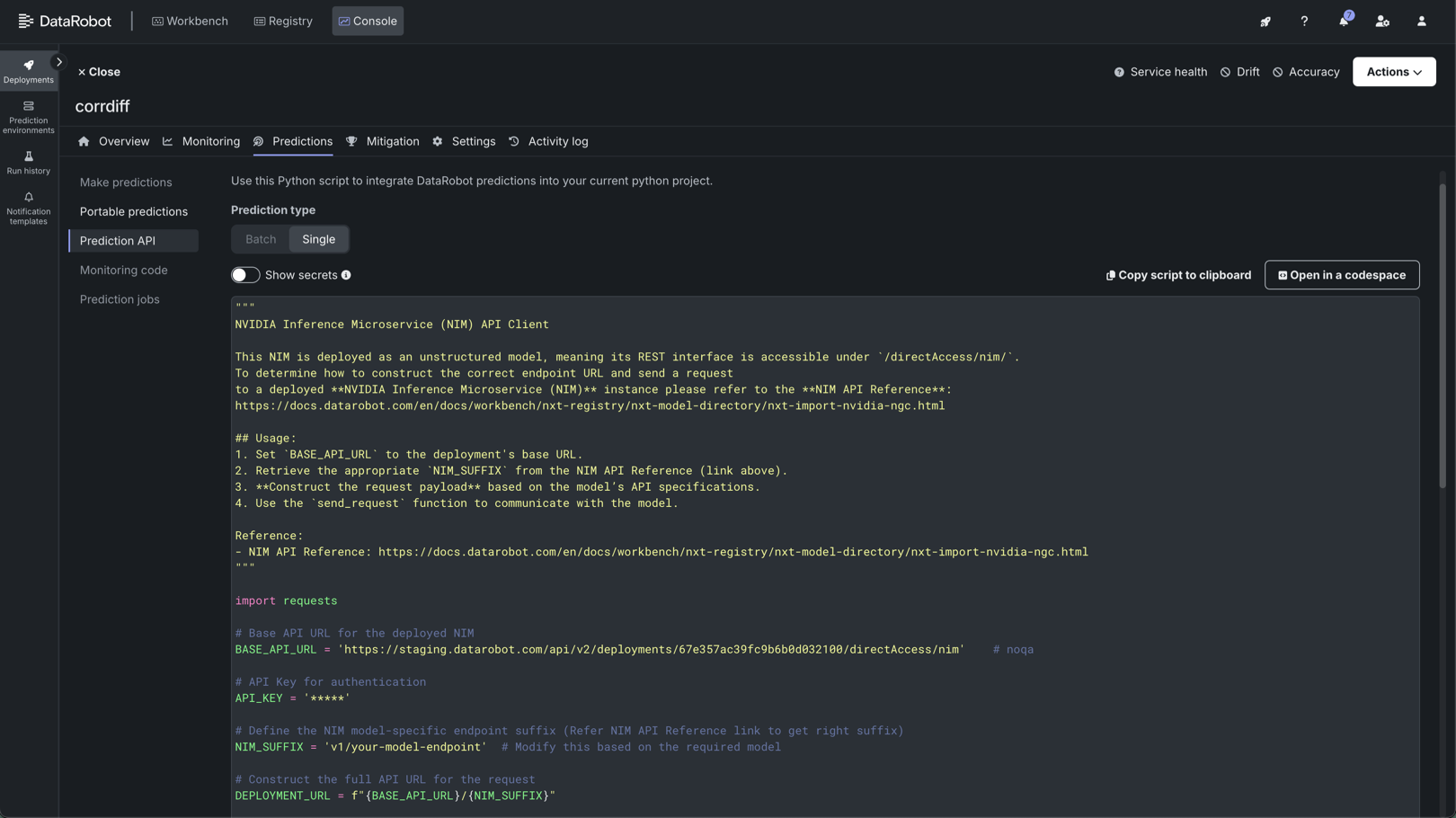
Access the Prediction API scripting code from the deployment's Predictions > Prediction API tab. For unstructured models, endpoints provided by the NIM containers are exposed to enable communication with the deployed NIM. To determine how to construct the correct endpoint URL and send a request to a deployed NVIDIA NIM instance, refer to the documentation for the registered and deployed NIM, listed below.
Observability for direct access endpoints
Most unstructured models from NVIDIA NIM only provide access to the /directAccess/nim/ endpoint. This endpoint is compatible with a limited set of observability features. For example, accuracy and drift tracking is not supported for the /directAccess/nim/ endpoint.
To use the Prediction API scripting code, perform the following steps and use the send_request function to communicate with the model:
- Review the
BASE_API_URL(line 4). This is the prefix of the endpoint. It automatically populates with the deployment's base URL. - Retrieve the appropriate
NIM_SUFFIX(line 10). This is the suffix of the NIM endpoint. Locate this suffix in the NVIDIA NIM documentation for the deployed model. - Construct the request payload (
sample_payload, line 45). This request payload must be structured based on the model’s API specifications from the NVIDIA NIM documentation for the deployed model.
| Prediction API scripting code | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | |
Unstructured model NVIDIA NIM documentation list
For unstructured models, the required NIM endpoint can be found in the NIM documentation. The list below provides the documentation link required to assemble the NIM_SUFFIX and sample_payload.
- arctic-embed-l
- boltz-2
- cuopt
- diffdock
- genmol
- llama-3.2-nv-embedqa-1b-v2
- llama-3.2-nv-rerankqa-1b-v2
- molmim
- nemoguard-jailbreak-detect
- nemoretriever-graphic-elements-v1
- nemoretriever-page-elements-v2
- nemoretriever-parse
- nemoretriever-table-structure-v1
- nv-embedqa-e5-v5
- nv-embedqa-e5-v5-pb24h2
- nv-embedqa-mistral-7b-v2
- nv-rerankqa-mistral-4b-v3
- nvclip
- openfold3
- paddleocr
- proteinmpnn
- rfdiffusion
Unstructured models with text generation support¶
Embedding models are imported and deployed as unstructured models while maintaining the ability to request chat completions. The following embedding models support both a direct access endpoint and a chat completions endpoint:
arctic-embed-lllama-3.2-nv-embedqa-1b-v2nv-embedqa-e5-v5nv-embedqa-e5-v5-pb24h2nv-embedqa-mistral-7b-v2nvclip
Each embedding NIM is deployed as an unstructured model, providing a REST interface at /directAccess/nim/. In addition, these models are capable of returning chat completions, so the code snippet provides a BASE_API_URL with the /chat/completions endpoint used by (structured) text generation models. To use the Prediction API scripting code, review the table below to determine how to modify the prediction snippet to access each endpoint type:
| Endpoint type | Requirements |
|---|---|
| Direct access | Update the BASE_API_URL (on line 4), replacing /chat/completions with /directAccess/nim/. To structure the request payload, review the model’s API specifications from the NVIDIA NIM documentation for the deployed model. |
| Chat completion | Update the DEPLOYMENT_URL (on line 13), removing /{NIM_SUFFIX} to create DEPLOYMENT_URL = BASE_API_URL. To structure the request payload, review the model’s API specifications from the NVIDIA NIM documentation for the deployed model. |
| Prediction API scripting code | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |