Configure evaluation and moderation¶
Premium
Evaluation and moderation guardrails are a premium feature. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Moderation Guardrails (Premium), Enable Global Models in the Model Registry (Premium), Enable Additional Custom Model Output in Prediction Responses
Evaluation and moderation guardrails help your organization block prompt injection and hateful, toxic, or inappropriate prompts and responses. It can also prevent hallucinations or low-confidence responses and, more generally, keep the model on topic. In addition, these guardrails can safeguard against the sharing of personally identifiable information (PII). Many evaluation and moderation guardrails connect a deployed text generation model (LLM) or agentic workflow to a deployed guard model. These guard models make predictions on LLM prompts and responses and then report these predictions and statistics to the central LLM or agentic workflow deployment.
To use evaluation and moderation guardrails, first create and deploy guard models to make predictions on an LLM's prompts or responses; for example, a guard model could identify prompt injection or toxic responses. Then, when you create a custom model with the Text Generation or Agentic Workflow target type, define one or more evaluation and moderation guardrails.
Important prerequisites
Before configuring evaluation and moderation guardrails for an LLM, follow these guidelines while deploying guard models and configuring your LLM deployment:
- If using a custom guard model, before deployment, define
moderations.input_column_nameandmoderations.output_column_nameas tag-type key values on the registered model version. If you don't set these key values, any users of the guard model will have to enter the input and output column names manually. - Deploy the global or custom guard models you intend to use to monitor the central LLM before configuring evaluation and moderation.
- Deploy the central LLM on a different prediction environment than the deployed guard models.
- Set an association ID and enable prediction storage before you start making predictions through the deployed LLM. If you don't set an association ID and provide association IDs alongside the LLM's predictions, the metrics for the moderations won't be calculated on the Custom metrics tab.
- After you define the association ID, you can enable automatic association ID generation to ensure these metrics appear on the Custom metrics tab. You can enable this setting during or after deployment.
- If you plan to use any of the NeMo Evaluator metrics (Agent Goal Accuracy, Context Relevance, Faithfulness (NeMo Evaluator), LLM Judge, Response Groundedness, Response Relevancy, Topic Adherence), create a NeMo evaluator workload and workload deployment via the Workload API first. The Workload API has no UI; you must use the API to create the workload and then create the workload deployment. Each of these metrics requires a NeMo evaluator deployment.
Prediction method considerations
When making predictions outside a chat generation Q&A application, evaluations and moderations are only compatible with real-time predictions, not batch predictions. In addition, when requesting streaming responses using the Bolt-on Governance API, evaluation and moderation negates the effect of streaming. Guardrails evaluate only the complete response of the LLM and therefore return the response text in one chunk.
Select evaluation and moderation guardrails¶
When you create a custom model with the Text Generation or Agentic Workflow target type, define one or more evaluation and moderation guardrails.
To select and configure evaluation and moderation guardrails:
-
In the Workshop, open the Assemble tab of a custom model with the Text Generation or Agentic Workflow target type and assemble a model, either manually from a custom model you created outside of DataRobot or automatically from a model built in a Use Case's LLM playground:
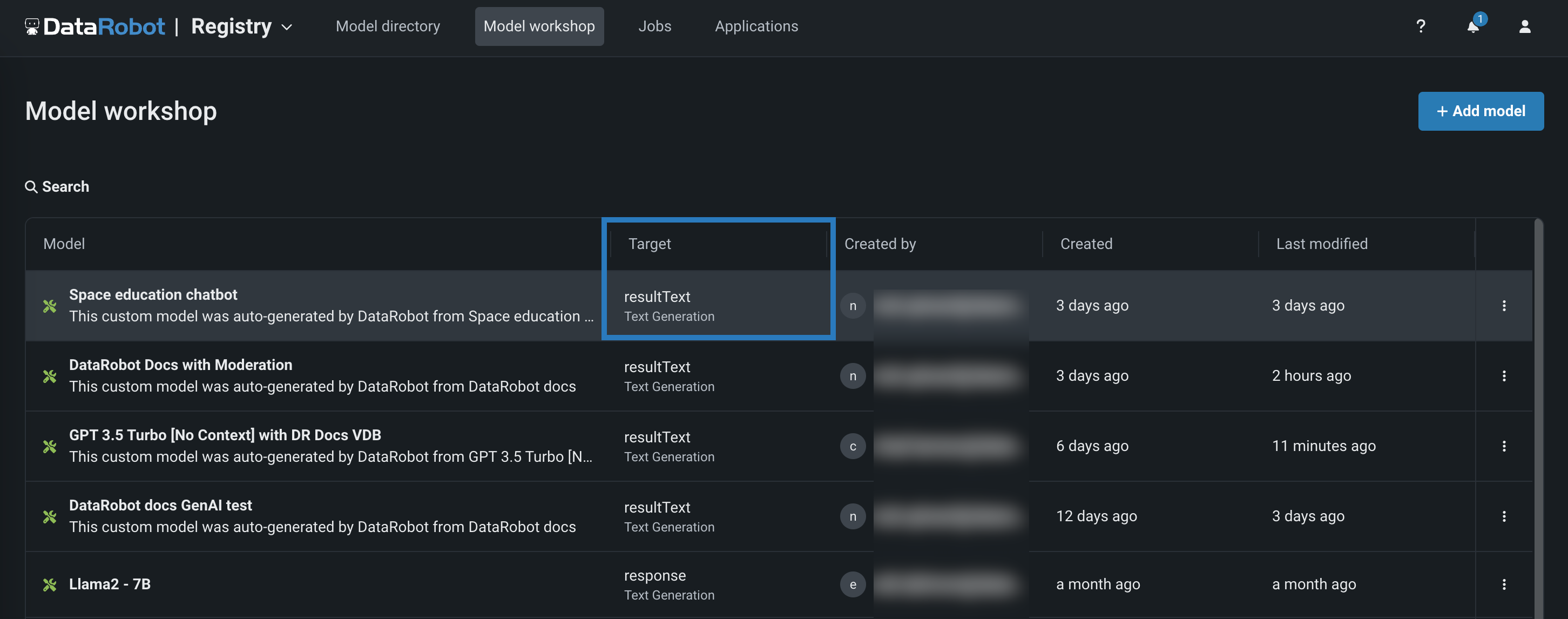
When you assemble a text generation model with moderations, ensure you configure any required runtime parameters (for example, credentials) or resource settings (for example, public network access). Finally, set the Base environment to a moderation-compatible environment; for example, [GenAI] Python 3.12 with Moderations:
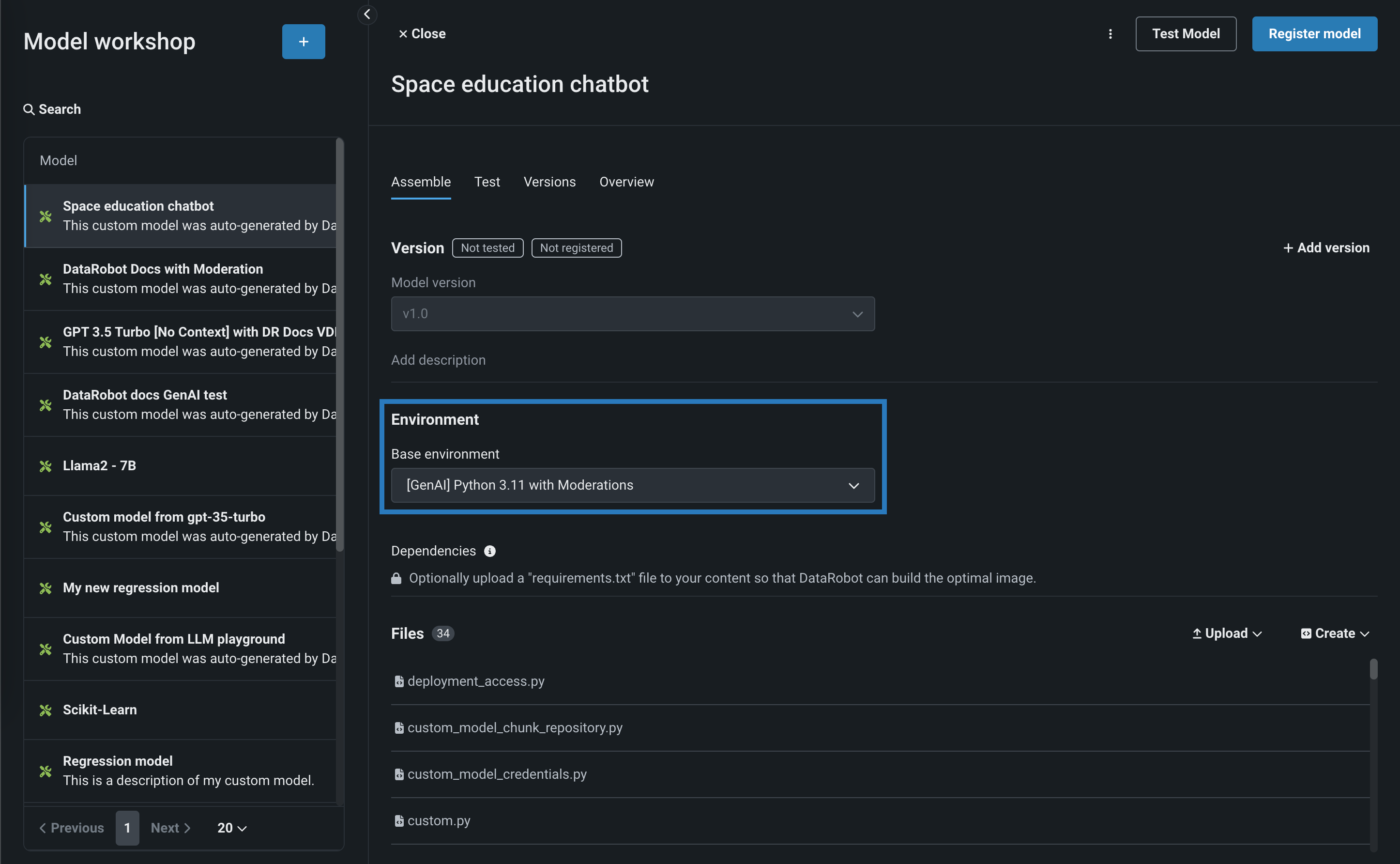
Resource settings
DataRobot recommends creating the LLM custom model using larger resource bundles with more memory and CPU resources.
-
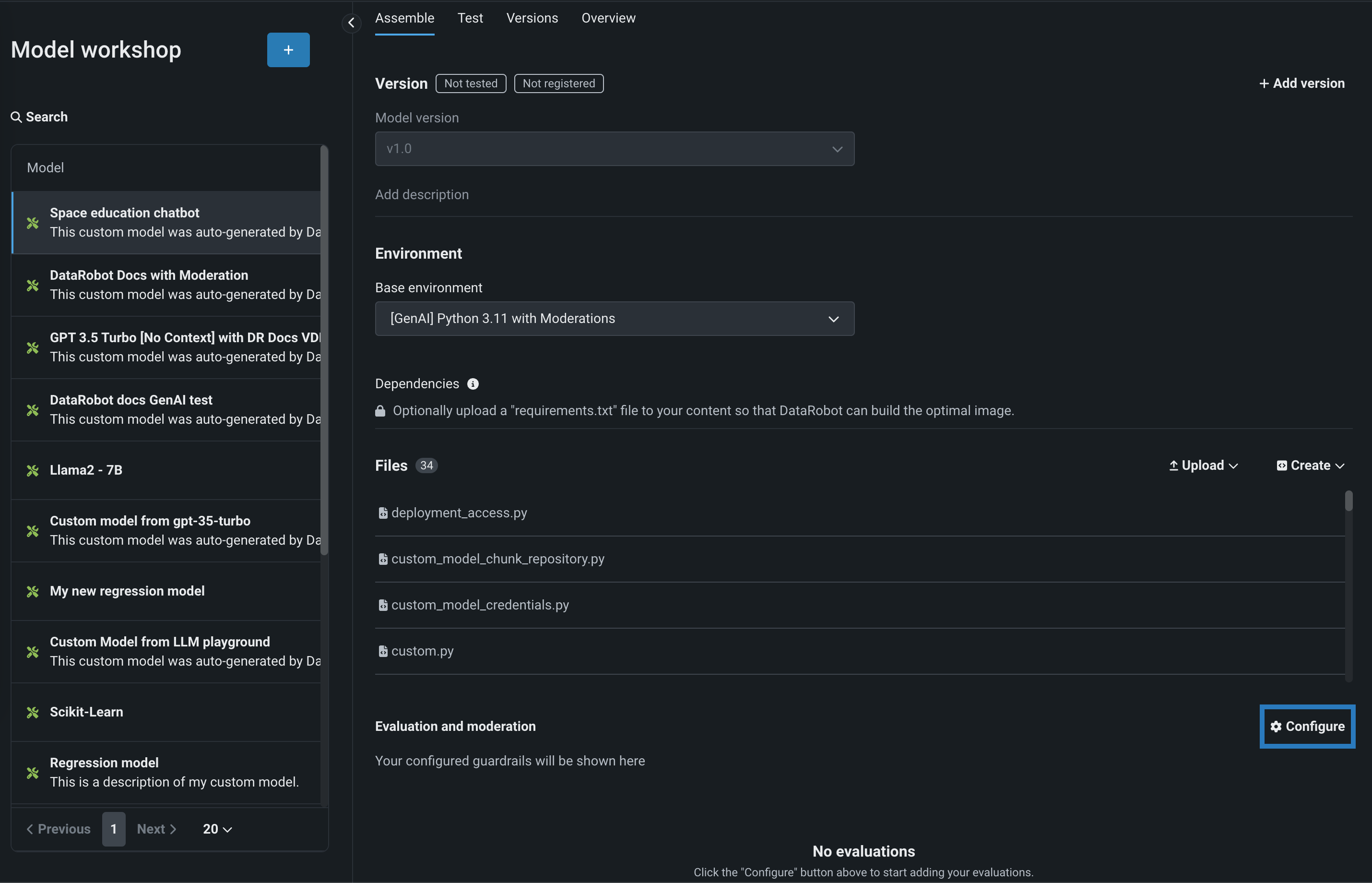
After you've configured the custom model's required settings, navigate to the Evaluation and moderation section and click Configure:
-
On the Configure evaluation and moderation panel, in the Configuration summary, access the following settings:

Setting Description Show workflow Review how evaluations are executed in DataRobot. All evaluations and their respective moderations run in parallel. Moderation settings Set the following: - Set moderation timeout: Configure the maximum wait time (in seconds) for moderations before the system automatically times out.
- Timeout action: Define what happens if the moderation system times out: Score prompt / response or Block prompt / response.
NeMo evaluator settings Set the NeMo evaluator deployment used by the NeMo Evaluator metrics. The dropdown shows "No options available" until you have created a NeMo evaluator workload and workload deployment via the Workload API. You must complete that step before you can configure the NeMo Evaluator metrics. -
In the Configure evaluation and moderation panel, click one of the following metric cards to configure the required properties. The panel has two sections: All Metrics and NeMo metrics. From the Configuration summary sidebar you can open Show workflow, Moderation settings, or NeMo evaluator settings to configure the evaluator deployment used by all NeMo evaluator metrics.
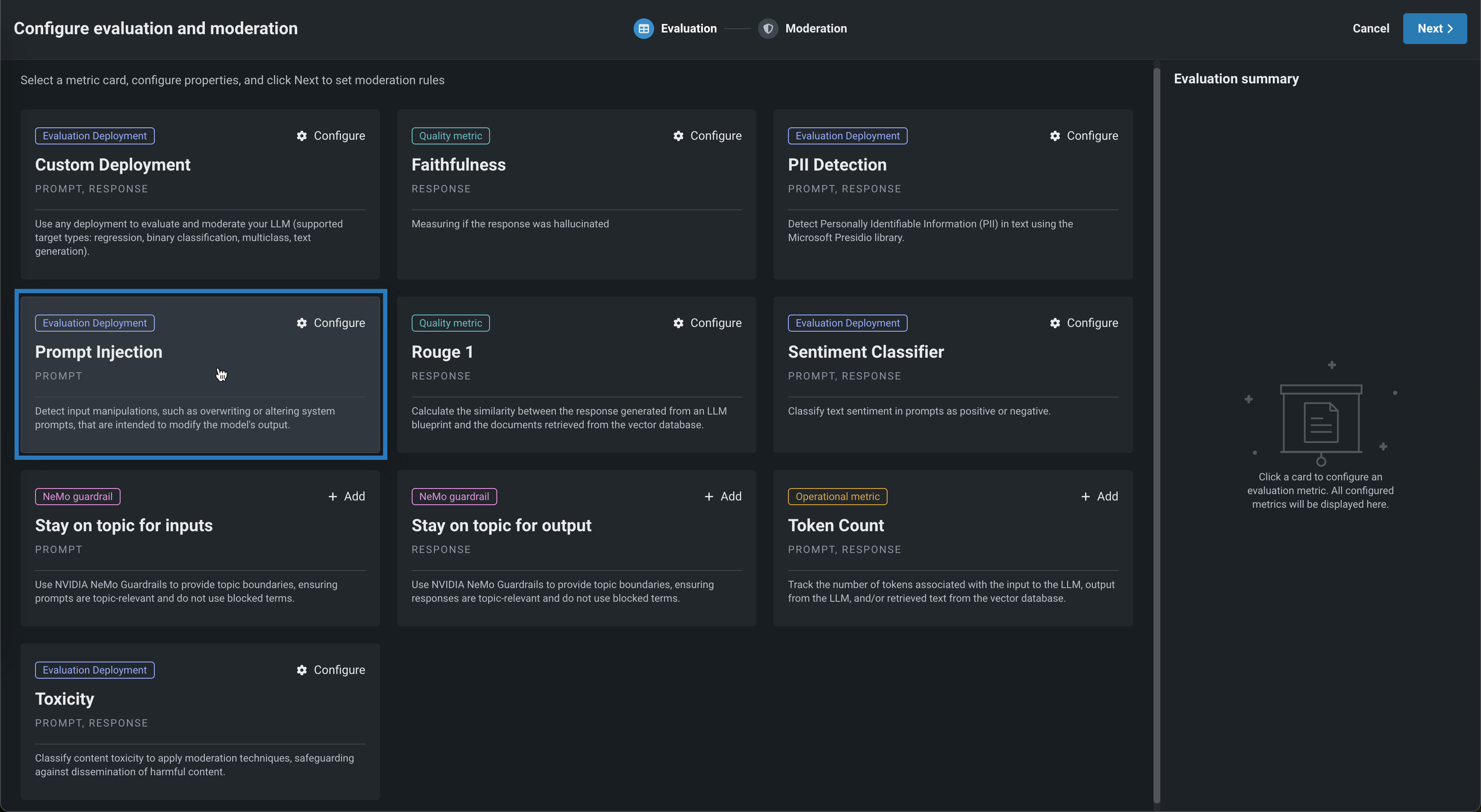
Evaluation metric Requires Description Content Safety A deployed NIM model llama-3.1-nemoguard-8b-content-safety imported from NVIDIA GPU Cloud (NGC) Catalog. Classify prompts and responses as safe or unsafe; return a list of any unsafe categories detected. Cost LLM cost settings Calculate the cost of generating the LLM response using the provided input cost-per-token, and output cost-per-token values. The cost calculation also includes the cost of citations. For more information, see Cost metric settings. Custom Deployment Custom deployment Use any deployment to evaluate and moderate your LLM (supported target types: regression, binary classification, multiclass, text generation). Emotions Classifier Emotions Classifier deployment Classify prompt or response text by emotion. Faithfulness LLM, vector database Measure if the LLM response matches the source to identify possible hallucinations. Jailbreak A deployed NIM model nemoguard-jailbreak-detect imported from NVIDIA GPU Cloud (NGC) Catalog. Classify jailbreak attempts using NemoGuard JailbreakDetect. PII Detection Presidio PII Detection Detect Personally Identifiable Information (PII) in text using the Microsoft Presidio library. Prompt Injection Prompt Injection Classifier Detect input manipulations, such as overwriting or altering system prompts, intended to modify the model's output. Prompt tokens N/A Track the number of tokens associated with the input to the LLM and/or retrieved text from the vector database. Response tokens N/A Track the number of tokens associated with the output from the LLM and/or retrieved text from the vector database. ROUGE-1 Vector database Calculate the similarity between the response generated from an LLM blueprint and the documents retrieved from the vector database. Toxicity Toxicity Classifier Classify content toxicity to apply moderation techniques, safeguarding against dissemination of harmful content. Agentic workflow metrics Agent Goal Accuracy LLM Evaluate agentic workflow performance in achieving specified objectives in scenarios without a known benchmark. (This agentic workflow metric is distinct from the NeMo Evaluator metric of the same name under NeMo metrics.) Task Adherence LLM Measure whether the agentic workflow response is relevant, complete, and aligned with user expectations. Guideline Adherence LLM, guideline setting Evaluate how well the response follows the defined guideline using a judge LLM. Returns true when the guideline is followed, false otherwise. You must supply the guideline and select an LLM (from the gateway or a deployment) when configuring. Global models for evaluation metric deployments
The deployments required for PII detection, prompt injection detection, emotion classification, and toxicity classification are available as global models in Registry
Multiclass custom deployment metric limits
Multiclass custom deployment metrics can have:
-
Up to
10classes defined in the Matches list for moderation criteria. -
Up to
100class names in the guard model.
The NeMo Evaluator metrics (Agent Goal Accuracy, Context Relevance, Faithfulness, LLM Judge, Response Groundedness, Response Relevancy, Topic Adherence) require a NeMo evaluator workload deployment, set in NeMo evaluator settings in the Configuration summary sidebar. Create the workload and workload deployment via the Workload API before you can select it; the Select a workload deployment dropdown shows "No options available" until a deployment exists. Each of these metrics also uses an LLM judge (DataRobot deployment or LLM gateway). Response Relevancy additionally requires an embedding deployment. Topic Adherence and LLM Judge have additional configuration. Stay on topic for inputs and Stay on topic for output do not use the NeMo evaluator deployment. They use a NIM deployment of the
llama-3.1-nemoguard-8b-topic-controlmodel (like Content safety and Jailbreak use NIM models). Configure them with LLM type NIM, select the topic-control NIM deployment, and optionally edit the NeMo guardrails configuration files.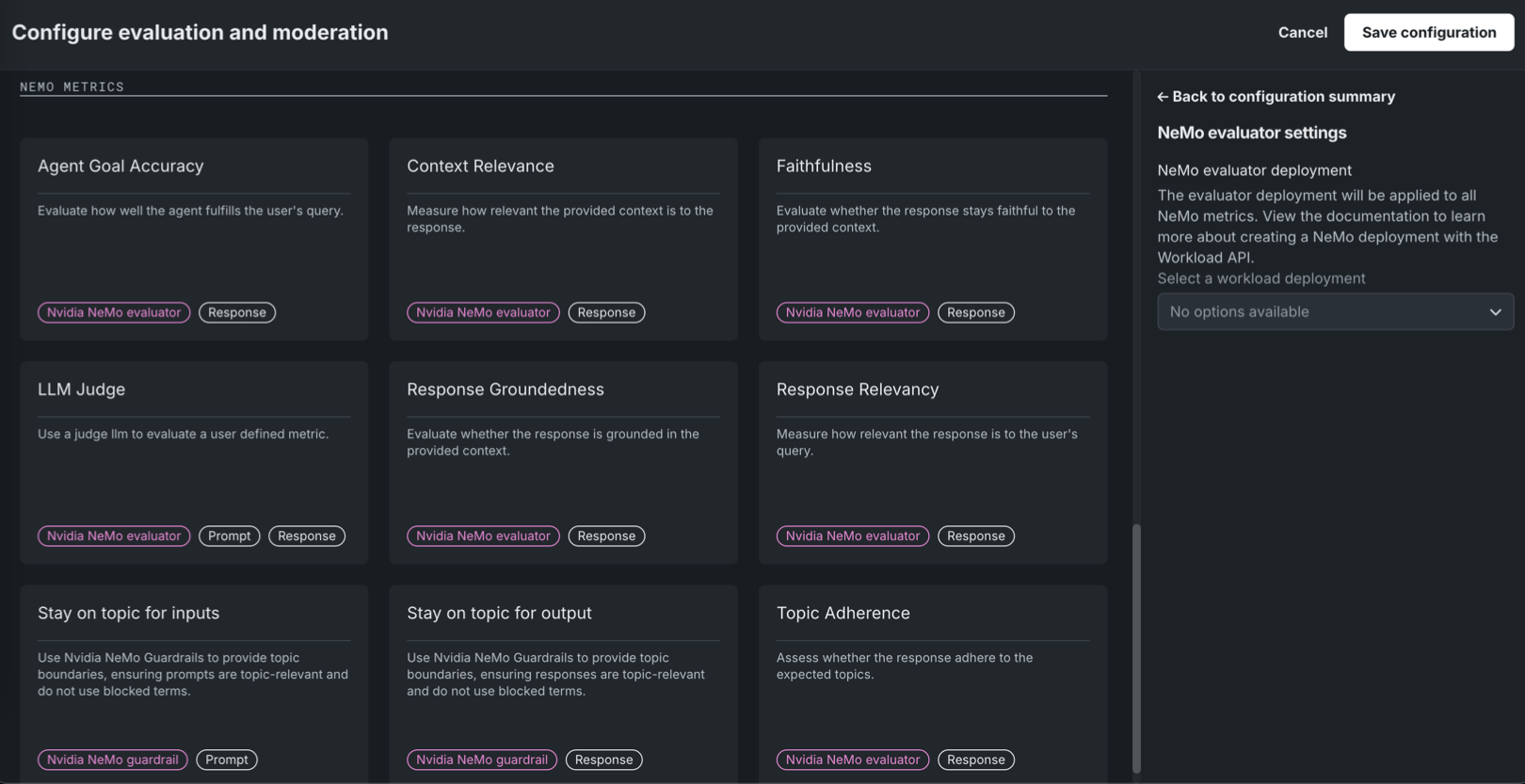
Evaluator metric Requires Description Agent Goal Accuracy Evaluator deployment, LLM Evaluate how well the agent fulfills the user's query. This is distinct from the Agent Goal Accuracy metric under All metrics (agentic workflow). Context Relevance Evaluator deployment, LLM Measure how relevant the provided context is to the response. Faithfulness Evaluator deployment, LLM Evaluate whether the response stays faithful to the provided context using the NeMo Evaluator. This is distinct from the non-NeMo Faithfulness metric listed under All metrics. LLM Judge Evaluator deployment, LLM Use a judge LLM to evaluate a user defined metric. Response Groundedness Evaluator deployment, LLM Evaluate whether the response is grounded in the provided context. Response Relevancy Evaluator deployment, LLM, Embedding deployment Measure how relevant the response is to the user's query. Topic Adherence Evaluator deployment, LLM, Metric mode, Reference topics Assess whether the response adheres to the expected topics. Topic control metrics Stay on topic for inputs NIM deployment of llama-3.1-nemoguard-8b-topic-control, NVIDIA NeMo guardrails configuration Use NVIDIA NeMo Guardrails to provide topic boundaries, ensuring prompts are topic-relevant and do not use blocked terms. Stay on topic for output NIM deployment of llama-3.1-nemoguard-8b-topic-control, NVIDIA NeMo guardrails configuration Use NVIDIA NeMo Guardrails to provide topic boundaries, ensuring responses are topic-relevant and do not use blocked terms. To set the NeMo evaluator deployment used by the NeMo Evaluator metrics, open NeMo evaluator settings from the Configuration summary sidebar. The evaluator deployment will be applied to all NeMo Evaluator metrics. From the Select a workload deployment dropdown list, choose the workload deployment for the NeMo evaluator.
NeMo evaluator settings panel
The dropdown shows "No options available" until you have created a NeMo evaluator workload and workload deployment via the Workload API. You must complete that step before you can configure the NeMo Evaluator metrics.
-
-
Depending on the metric selected above, configure the following fields:
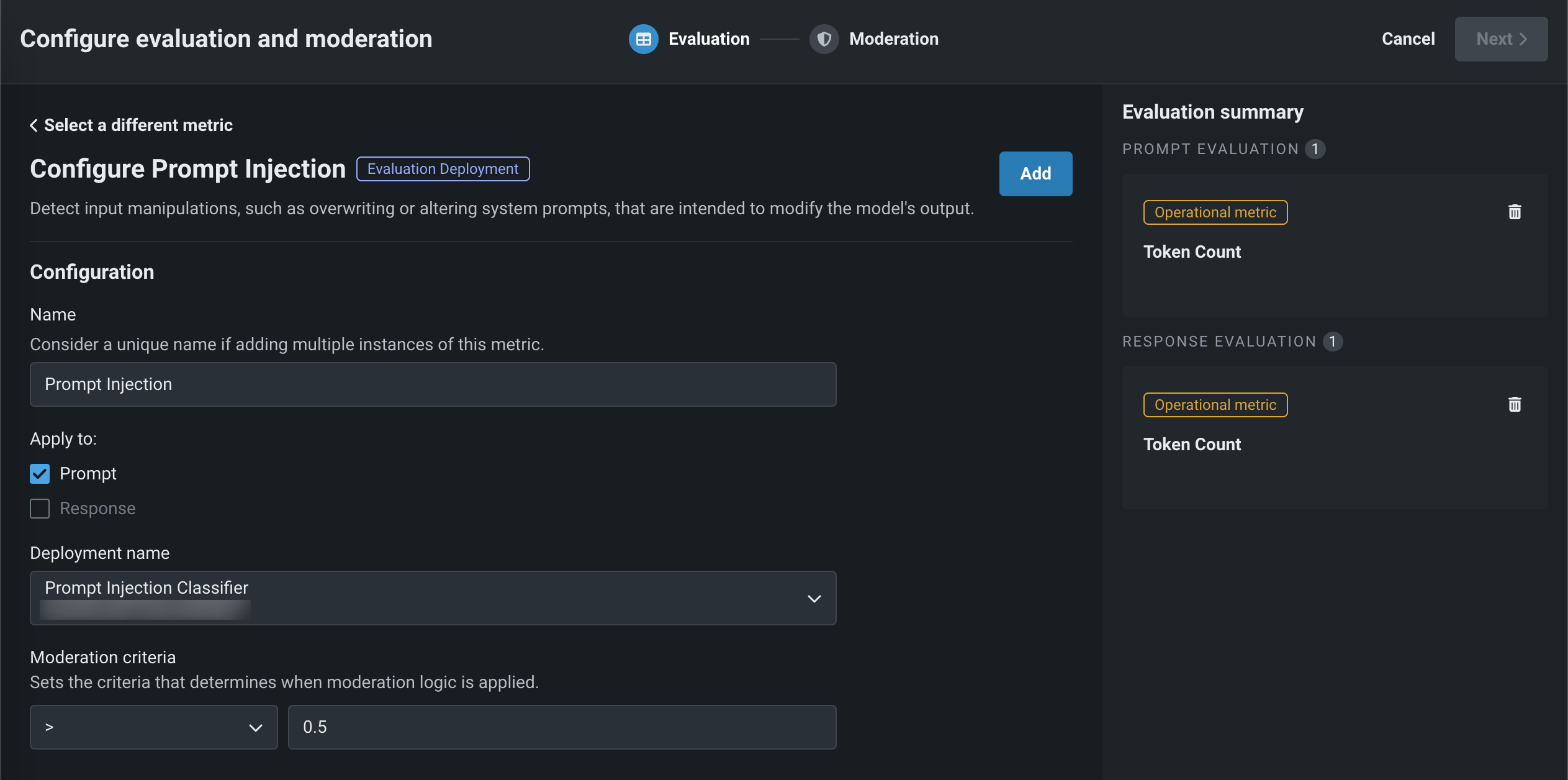
Field Description General settings Name Enter a unique name if adding multiple instances of the evaluation metric. Apply to Select one or both of Prompt and Response, depending on the evaluation metric. Note that when you select Prompt, it's the user prompt, not the final LLM prompt, that is used for metric calculation. This field is only configurable for metrics that apply to both the prompt and the response. Custom Deployment, PII Detection, Prompt Injection, Emotions Classifier, and Toxicity settings Deployment name For evaluation metrics calculated by a guard model, select the custom model deployment. Custom Deployment settings Input column name This name is defined by the custom model creator. For global models created by DataRobot, the default input column name is text. If the guard model for the custom deployment has the moderations.input_column_name key value defined, this field is populated automatically. Output column name This name is defined by the custom model creator, and needs to refer to the target column for the model. The target name is listed on the deployment's Overview tab (and often has _PREDICTION appended to it). You can confirm the column names by exporting and viewing the CSV data from the custom deployment. If the guard model for the custom deployment has the moderations.output_column_name key value defined, this field is populated automatically. Guideline Adherence setting Guideline The rule or criteria the agent's response should follow. The selected LLM acts as a judge to evaluate whether the response adheres to this guideline and returns true (guideline followed) or false (guideline not followed). You must supply the guideline and select an LLM (from the gateway or a deployment) when configuring this metric. Faithfulness, Task Adherence, and Guideline Adherence settings LLM Select an LLM to evaluate the selected metric. For Faithfulness, once you select an LLM, you have the option of using your own user-provided credentials instead of DataRobot-provided. NeMo Evaluator metric settings Select LLM as a judge Select an LLM to evaluate the selected metric. Evaluator deployment For the NeMo Evaluator metrics only: set in the NeMo evaluator settings sidebar panel (Select a workload deployment). The NeMo evaluator workload deployment is shared by those metrics. Create the workload and workload deployment via the Workload API before configuring; see the prerequisites above. Topic control settings LLM Type Select Azure OpenAI, OpenAI, or NIM. For the Azure OpenAI LLM type, additionally enter an OpenAI API deployment; for NIM enter a NIM deployment. If you use the LLM gateway, the default experience, DataRobot-supplied credentials are provided. When LLM type is Azure OpenAI or OpenAI, click Change credentials to provide your own authentication. Files For the Stay on topic evaluations, next to a file, click to modify the NeMo guardrails configuration files. In particular, update prompts.yml with allowed and blocked topics and blocked_terms.txt with the blocked terms, providing rules for NeMo guardrails to enforce. The blocked_terms.txt file is shared between the input and output topic control metrics; therefore, modifying blocked_terms.txt in the input metric modifies it for the output metric and vice versa. Only two topic control metrics can exist in a custom model, one for input and one for output. Moderation settings Configure and apply moderation Enable this setting to expand the Moderation section and define the criteria that determine when moderation logic is applied. Cost metric settings
For the Cost metric, define the Input and Output cost in currency amount / tokens amount format, then click Add:
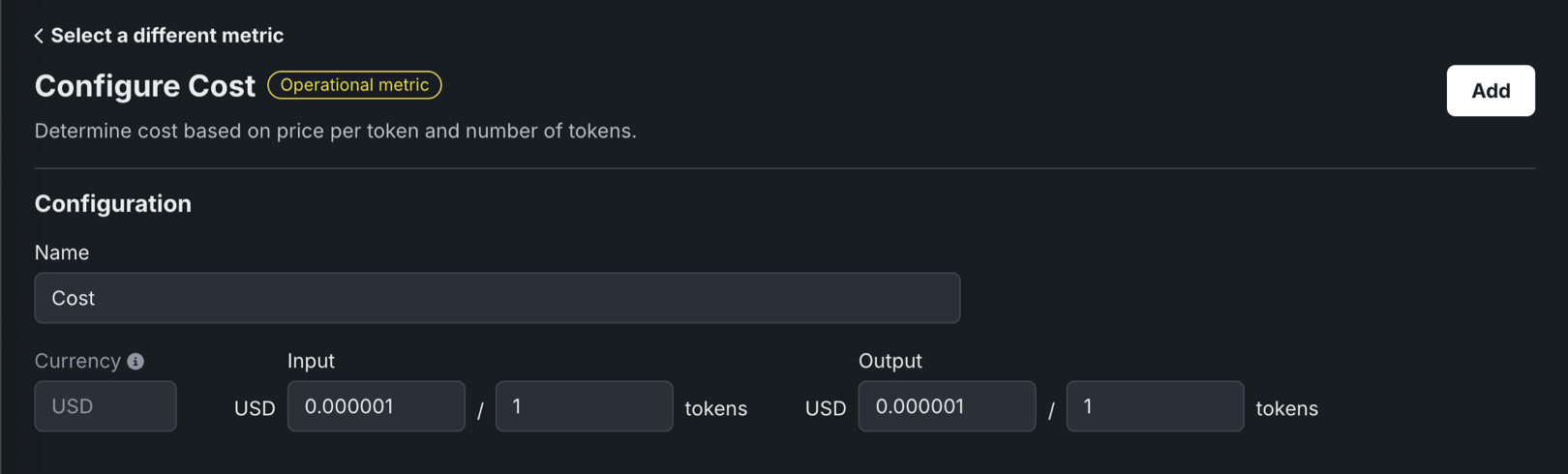
The Cost metric doesn't include the Moderation section to Configure and apply moderation.
-
In the Moderation section, with Configure and apply moderation enabled, for each evaluation metric, set the following:
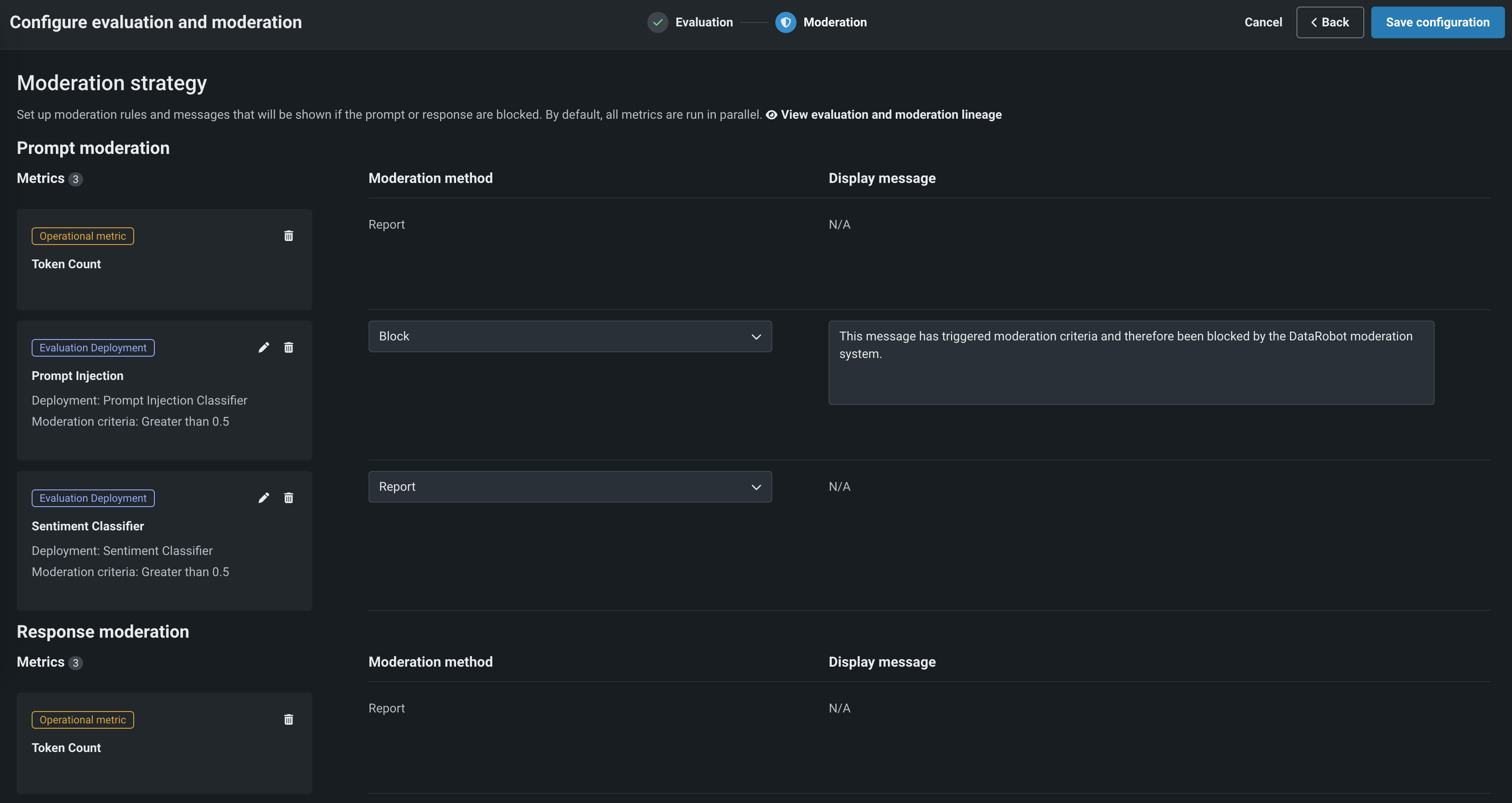
Setting Description Moderation criteria If applicable, set the threshold settings evaluated to trigger moderation logic. For numeric metrics (int or float), you can use less than, greater than, or equals to with a value of your choice. For binary metrics (for example, Agent Goal Accuracy), use equals to 0 or 1. For the Emotions Classifier, select Matches or Does not match and define a list of classes (emotions) to trigger moderation logic. Moderation method Select Report, Report and block, or Replace (if applicable). Moderation message If you select Report and block, you can optionally modify the default message. -
After configuring the required fields, click Add to save the evaluation and return to the evaluation selection page. Then, select and configure another metric, or click Save configuration.
The guardrails you selected appear in the Evaluation and moderation section of the Assemble tab.
After you add guardrails to a text generation custom model, you can test, register, and deploy the model to make predictions in production. After making predictions, you can view the evaluation metrics on the Custom metrics tab and prompts, responses, and feedback (if configured) on the Data exploration tab.
Tracing tab
When you add moderations to an LLM deployment, you can't view custom metric data by row on the Data exploration > Tracing tab.
Change credentials¶
DataRobot provides credentials for available LLMs using the LLM gateway. With certain metrics and LLMs or LLM types, you can instead use your own credentials for authentication. Before proceeding, define user-specified credentials on the credentials management page.
Topic control metrics¶
To change credentials for either Stay on topic for inputs or Stay on topic for output, choose the LLM type and click Change credentials.
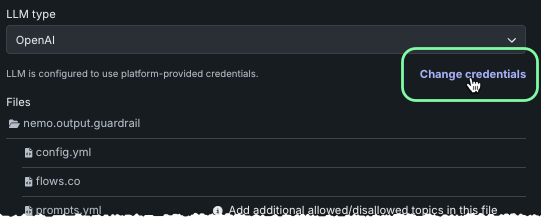
Provide the Azure OpenAI API deployment and the OpenAI API base URL. Then, from the dropdown, select the set of credentials to apply.
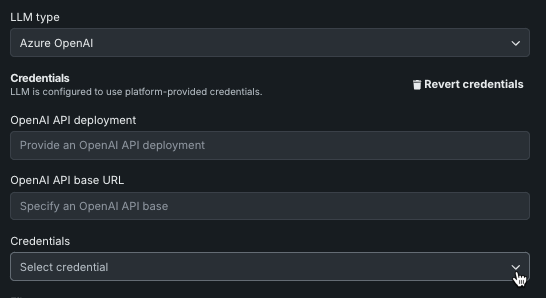
From the dropdown, select the set of credentials to apply.
Select the NIM deployment (for example, the topic-control model). Credentials are typically provided via the deployment configuration.
To revert to DataRobot-provided credentials, click Revert credentials.
Faithfulness metric¶
To change credentials for Faithfulness, select the LLM and click Change credentials.
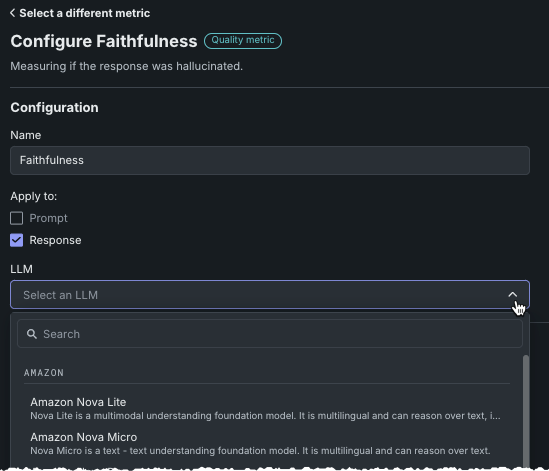
The following table lists the required fields:
| Provider | Fields |
|---|---|
| Amazon |
|
| Azure OpenAI |
|
|
|
| OpenAI |
|
To revert to DataRobot-provided credentials, click Revert credentials.
Considerations for NeMo Evaluator metrics¶
When using NeMo Evaluator metrics, consider the following:
- LLM judge output: The NeMo evaluator expects the LLM judge to return data in the correct JSON schema. Some models (for example, certain Llama versions) may return Python code or other formats instead, which can cause the evaluator to fail. Choose an LLM judge that reliably returns the expected format; newer models are often better at following JSON output instructions.
- Rate and token limits: Be aware of rate limits and token limits when using NeMo Evaluator guards; hitting these limits can cause evaluation failures.
You can use the Activity log > Moderation tab and evaluator logs to debug why a request was blocked or why a guard failed.
Global models for evaluation metric deployments¶
The deployments required for PII detection, prompt injection detection, emotion classification, and toxicity classification are available as global models in Registry. The following global models are available:
| Model | Type | Target | Description |
|---|---|---|---|
| Prompt Injection Classifier | Binary | Classifies text as prompt injection or legitimate. This guard model requires one column named text, containing the text to classify. For more information, see the deberta-v3-base-injection model details. |
|
| Toxicity Classifier | Binary | Classifies text as toxic or non-toxic. This guard model requires one column named text, containing the text to classify. For more information, see the toxic-comment-model details. |
|
| Sentiment Classifier | Binary | Classifies text sentiment as positive or negative. This model requires one column named text, containing the text to classify. For more information, see the distilbert-base-uncased-finetuned-sst-2-english model details. |
|
| Emotions Classifier | Multiclass | Classifies text by emotion. This is a multilabel model, meaning that multiple emotions can be applied to the text. This model requires one column named text, containing the text to classify. For more information, see the roberta-base-go_emotions-onnx model details. |
|
| Refusal Score | Regression | Outputs a maximum similarity score, comparing the input to a list of cases where an LLM has refused to answer a query because the prompt is outside the limits of what the model is configured to answer. | |
| Presidio PII Detection | Binary | Detects and replaces Personally Identifiable Information (PII) in text. This guard model requires one column named text, containing the text to be classified. The types of PII to detect can optionally be specified in a column, 'entities', as a comma-separated string. If this column is not specified, all supported entities will be detected. Entity types can be found in the PII entities supported by Presidio documentation. In addition to the detection result, the model returns an anonymized_text column, containing an updated version of the input with detected PII replaced with placeholders. For more information, see the Presidio: Data Protection and De-identification SDK documentation. |
|
| Zero-shot Classifier | Binary | Performs zero-shot classification on text with user-specified labels. This model requires classified text in a column named text and class labels as a comma-separated string in a column named labels. It expects the same set of labels for all rows; therefore, the labels provided in the first row are used. For more information, see the deberta-v3-large-zeroshot-v1 model details. |
|
| Python Dummy Binary Classification | Binary | Always yields 0.75 for the positive class. For more information, see the python3_dummy_binary model template. |
View evaluation and moderation guardrails¶
When a text generation model with guardrails is registered and deployed, you can view the configured guardrails on the registered model's Overview tab and the deployment's Overview tab:
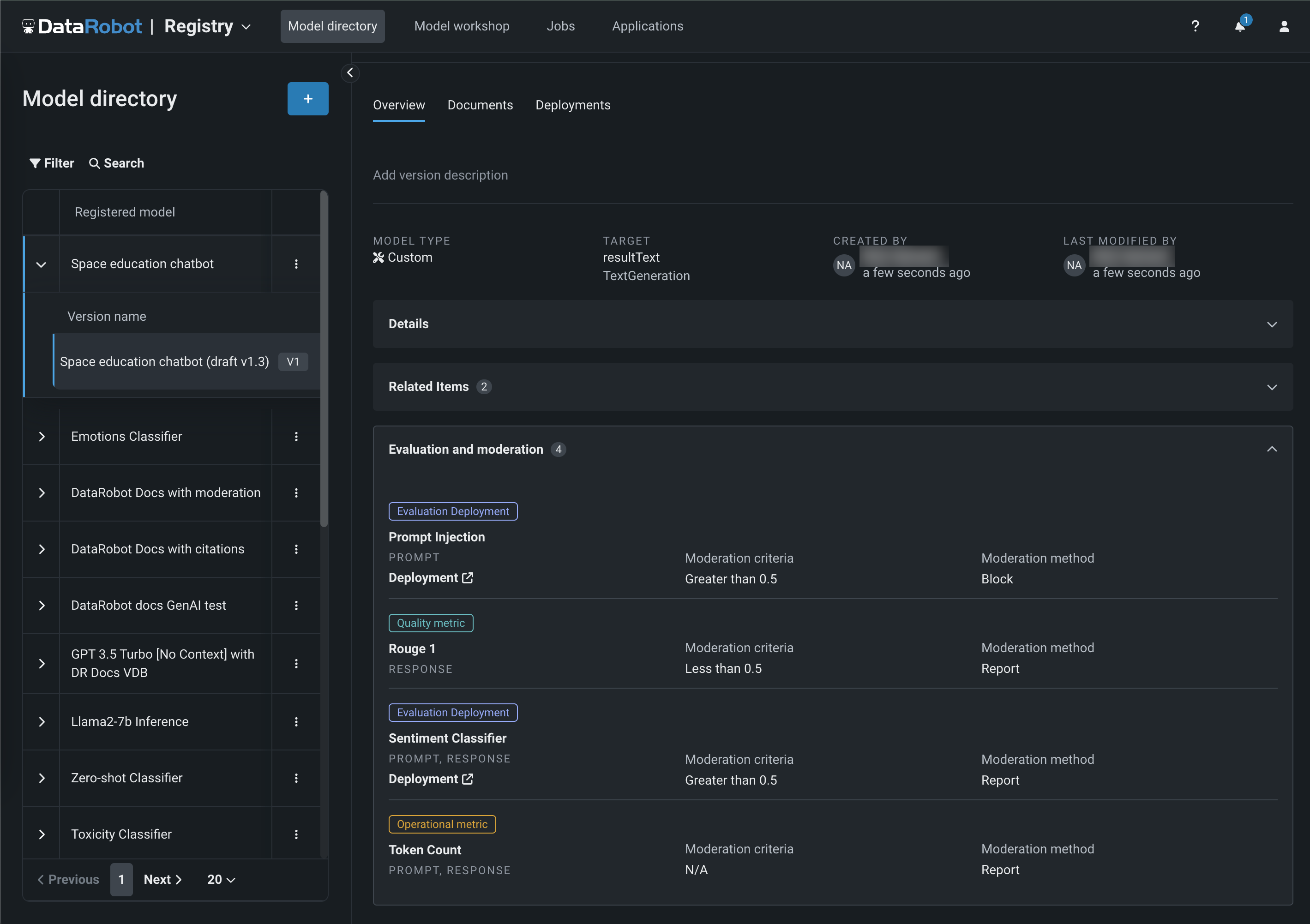
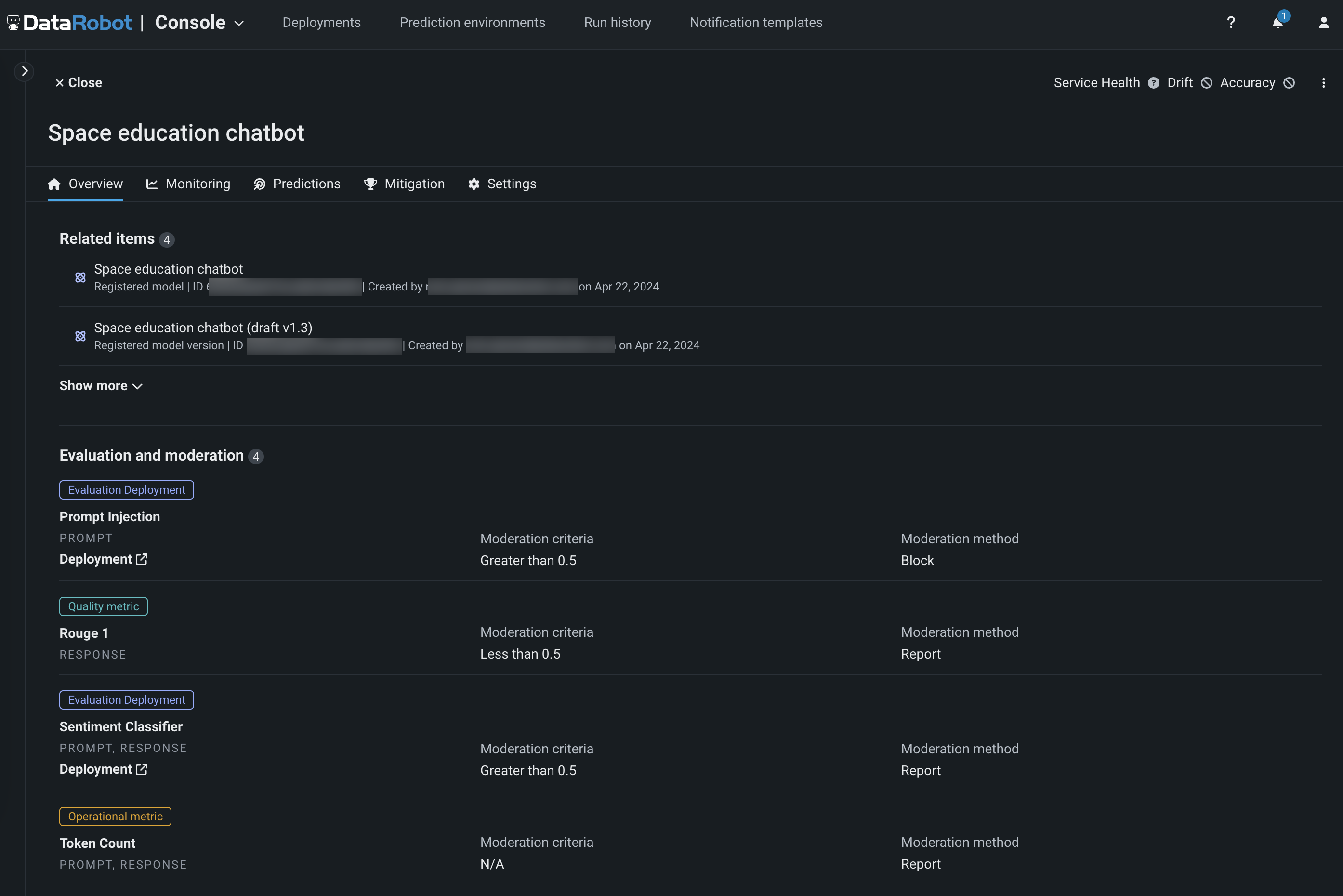
Evaluation and moderation logs
On the Activity log > Moderation tab of a deployed LLM with evaluation and moderation configured, you can view a history of evaluation and moderation-related events for the deployment to diagnose issues with a deployment's configured evaluations and moderations.