Configure predictions settings¶
On a deployment's Settings > Predictions tab, you can view details about your deployment's inference (also known as scoring) data—the data containing prediction requests and results from the model.
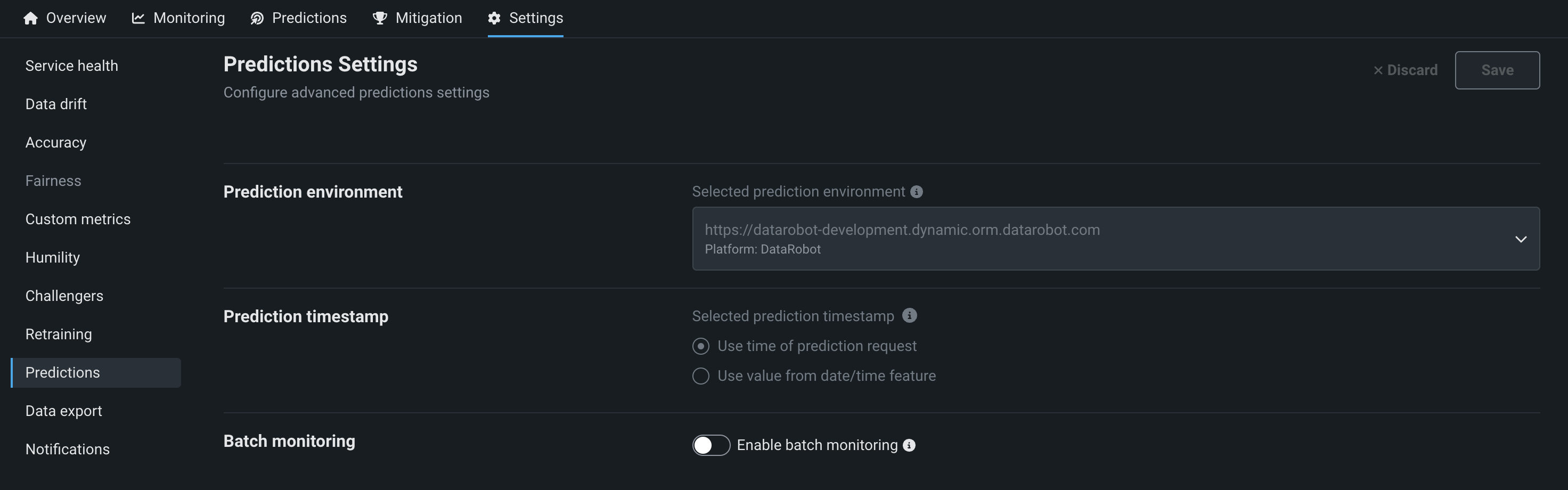
On the Predictions Settings page, you can access the following information:
| Field | Description |
|---|---|
| Prediction environment | Displays the environment where predictions are generated. Prediction environments allow you to establish access controls and approval workflows. |
| Prediction timestamp | Defines the method used for time-stamping prediction rows. To define the timestamp, select one of the following:
|
| Batch monitoring | Enables viewing monitoring statistics organized by batch, instead of by time, with batch-enabled deployments. |
Time series deployment date/time format considerations
For time series deployments using the date/time format %Y-%m-%d %H:%M:%S.%f, DataRobot automatically populates a v2 in front of the timestamp format. Date/time values submitted in prediction data should not include this v2 prefix. Other timestamp formats are not affected.
Set prediction autoscaling settings for DataRobot serverless deployments¶
Autoscaling automatically adjusts the number of replicas in your deployment based on incoming traffic. During high-traffic periods, it adds replicas to maintain performance. During low-traffic periods, it removes replicas to reduce costs. This eliminates the need for manual scaling while ensuring your deployment can handle varying loads efficiently.
To configure autoscaling, modify the following settings. Note that for DataRobot models, DataRobot performs autoscaling based on CPU usage at a 40% threshold.:

| Field | Description |
|---|---|
| Minimum compute instances | (Premium feature) Set the minimum compute instances for the model deployment. If your organization doesn't have access to "always-on" predictions, this setting is set to 0 and isn't configurable. With the minimum compute instances set to 0, the inference server will be stopped after an inactivity period of 7 days. The minimum and maximum compute instances depend on the model type. For more information, see the compute instance configurations note. |
| Maximum compute instances | Set the maximum compute instances for the model deployment to a value above the current configured minimum. To limit compute resource usage, set the maximum value equal to the minimum. The minimum and maximum compute instances depend on the model type. For more information, see the compute instance configurations note. |
To configure autoscaling, select the metric that will trigger scaling:
-
CPU utilization: Set a threshold for the average CPU usage across active replicas. When CPU usage exceeds this threshold, the system automatically adds replicas to provide more processing power.
-
HTTP request concurrency: Set a threshold for the number of simultaneous requests being processed. For example, with a threshold of 5, the system will add replicas when it detects 5 concurrent requests being handled.
When your chosen threshold is exceeded, the system calculates how many additional replicas are needed to handle the current load. It continuously monitors the selected metric and adjusts the replica count up or down to maintain optimal performance while minimizing resource usage.
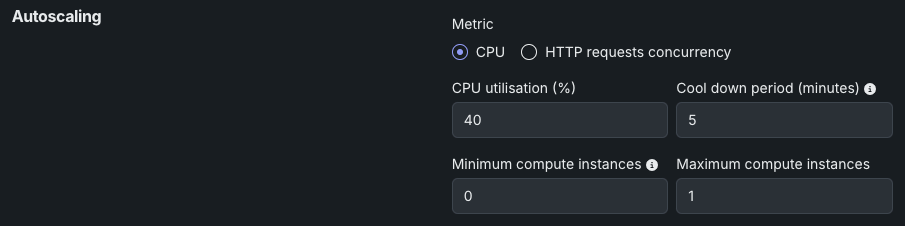
Review the settings for CPU utilization below.
| Field | Description |
|---|---|
| CPU utilization (%) | Set the target CPU usage percentage that triggers scaling. When CPU utilization reaches this threshold, the system adds more replicas. |
| Cool down period (minutes) | Set the wait time after a scale-down event before another scale-down can occur. This prevents rapid scaling fluctuations when metrics are unstable. |
| Minimum compute instances | (Premium feature) Set the minimum compute instances for the model deployment. If your organization doesn't have access to "always-on" predictions, this setting is set to 0 and isn't configurable. With the minimum compute instances set to 0, the inference server will be stopped after an inactivity period of 7 days. The minimum and maximum compute instances depend on the model type. For more information, see the compute instance configurations note. |
| Maximum compute instances | Set the maximum compute instances for the model deployment to a value above the current configured minimum. To limit compute resource usage, set the maximum value equal to the minimum. The minimum and maximum compute instances depend on the model type. For more information, see the compute instance configurations note. |
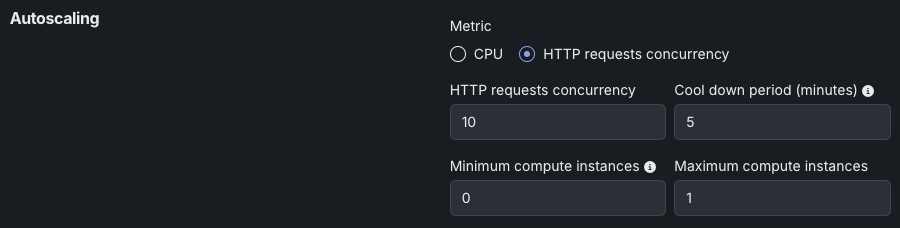
Review the settings for HTTP request concurrency below.
| Field | Description |
|---|---|
| HTTP request concurrency | Set the number of simultaneous requests required to trigger scaling. When concurrent requests reach this threshold, the system adds more replicas. |
| Cool down period (minutes) | Set the wait time after a scale-down event before another scale-down can occur. This prevents rapid scaling fluctuations when metrics are unstable. |
| Minimum compute instances | (Premium feature) Set the minimum compute instances for the model deployment. If your organization doesn't have access to "always-on" predictions, this setting is set to 0 and isn't configurable. With the minimum compute instances set to 0, the inference server will be stopped after an inactivity period of 7 days. The minimum and maximum compute instances depend on the model type. For more information, see the compute instance configurations note. |
| Maximum compute instances | Set the maximum compute instances for the model deployment to a value above the current configured minimum. To limit compute resource usage, set the maximum value equal to the minimum. The minimum and maximum compute instances depend on the model type. For more information, see the compute instance configurations note. |
Premium feature: Always-on predictions
Always-on predictions are a premium feature. Deployment autoscaling management is required to configure the minimum compute instances setting. Contact your DataRobot representative or administrator for information on enabling the feature.
Feature flag: Enable Deployment Auto-Scaling Management
Compute instance configurations
For DataRobot model deployments:
- The default minimum is 0 and default maximum is 3.
- The minimum and maximum limits are taken from the organization's
max_compute_serverless_prediction_apisetting.
For custom model deployments:
- The default minimum is 0 and default maximum is 1.
- The minimum and maximum limits are taken from the organization's
max_custom_model_replicas_per_deploymentsetting. - The minimum is always greater than 1 when running on GPUs (for LLMs).
Additionally, for high-availability scenarios:
- The minimum compute instances setting must be greater than or equal to 2.
- This requires business critical or consumption-based pricing.
Change secondary datasets for Feature Discovery¶
Feature Discovery identifies and generates new features from multiple datasets so that you no longer need to perform manual feature engineering to consolidate multiple datasets into one. This process is based on relationships between datasets and the features within those datasets. DataRobot provides an intuitive relationship editor that allows you to build and visualize these relationships. Feature Discovery engine analyzes the graphs and the included datasets to determine a feature engineering “recipe” and, from that recipe, generates secondary features for training and predictions. While configuring the deployment settings, you can change the selected secondary dataset configuration.

| Setting | Description |
|---|---|
| Secondary datasets configurations | Previews the dataset configuration or provides an option to change it. By default, DataRobot makes predictions using the secondary datasets configuration defined when starting the project. Click Change to select an alternative configuration before uploading a new primary dataset. |