Create a retraining job¶
Add a job, manually or from a template, implementing a code-based retraining policy. To view and add retraining jobs, navigate to the Jobs > Retraining tab, and then:
-
To add a new retraining job manually, click + Add new retraining job (or the minimized add button when the job panel is open).
-
To create a retraining job from a template, next to the add button, click , and then, under Retraining, click Create new from template.
The new job opens to the Assemble tab. Depending on the creation option you selected, proceed to the configuration steps linked in the table below.
| Retraining job type | Description |
|---|---|
| Add new retraining job | Manually add a job implementing a code-based retraining policy. |
| Create new from template | Add a job, from a template provided by DataRobot, implementing a code-based retraining policy. |
Retraining jobs require metadata
All retraining jobs require a metadata.yaml file to associate the retraining policy with a deployment and a retraining policy.
Add a new retraining job¶
To manually add a job for code-based retraining:
-
On the Assemble tab for the new job, click the job name (or the edit icon ) to enter a new job name, and then click confirm :
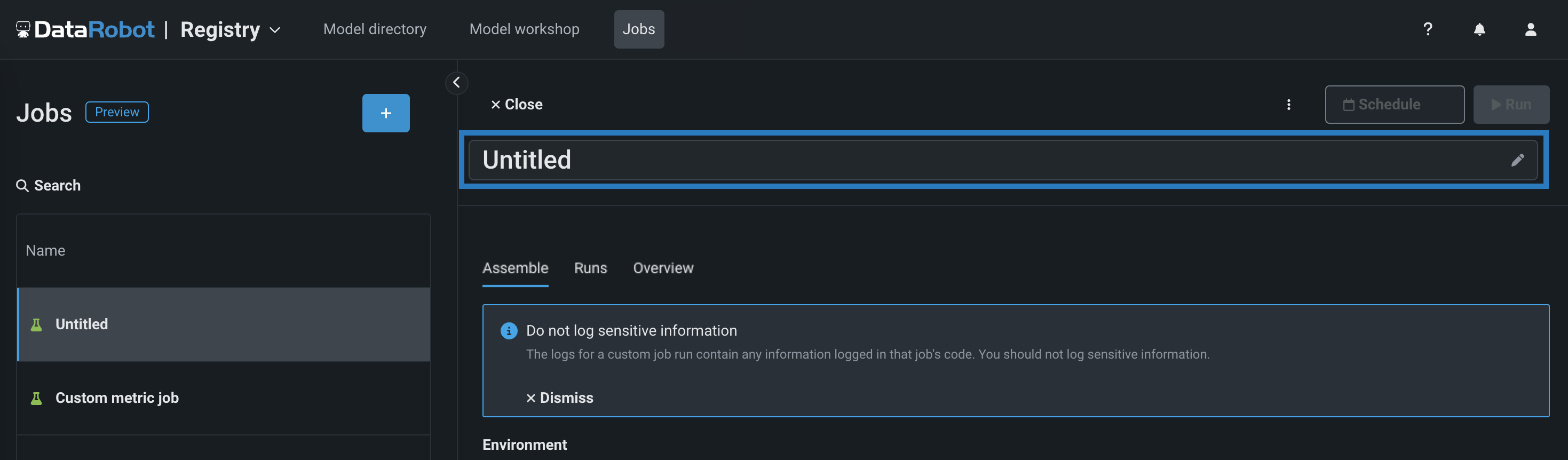
-
In the Environment section, select a Base environment for the job.
The available drop-in environments depend on your DataRobot installation; however, the table below lists commonly available public drop-in environments with templates in the DRUM repository. Depending on your DataRobot installation, the Python version of these environments may vary, and additional non-public environments may be available for use.
Drop-in environment security
Starting with the March 2025 Managed AI Platform release, most general purpose DataRobot custom model drop-in environments are security-hardened container images. When you require a security-hardened environment for running custom jobs, only shell code following the POSIX-shell standard is supported. Security-hardened environments following the POSIX-shell standard support a limited set of shell utilities.
Drop-in environment security
Starting with the 11.0 Self-Managed AI Platform release, most general purpose DataRobot custom model drop-in environments are security-hardened container images. When you require a security-hardened environment for running custom jobs, only shell code following the POSIX-shell standard is supported. Security-hardened environments following the POSIX-shell standard support a limited set of shell utilities.
Environment name & example Compatibility & artifact file extension Python 3.X Python-based custom models and jobs. You are responsible for installing all required dependencies through the inclusion of a requirements.txtfile in your model files.Python 3.X GenAI Agents Generative AI models ( Text GenerationorVector Databasetarget type)Python 3.X ONNX Drop-In ONNX models and jobs ( .onnx)Python 3.X PMML Drop-In PMML models and jobs ( .pmml)Python 3.X PyTorch Drop-In PyTorch models and jobs ( .pth)Python 3.X Scikit-Learn Drop-In Scikit-Learn models and jobs ( .pkl)Python 3.X XGBoost Drop-In Native XGBoost models and jobs ( .pkl)Python 3.X Keras Drop-In Keras models and jobs backed by tensorflow ( .h5)Java Drop-In DataRobot Scoring Code models ( .jar)R Drop-in Environment R models trained using CARET ( .rds)
Due to the time required to install all libraries recommended by CARET, only model types that are also package names are installed (e.g.,brnn,glmnet). Make a copy of this environment and modify the Dockerfile to install the additional, required packages. To decrease build times when you customize this environment, you can also remove unnecessary lines in the# Install caret modelssection, installing only what you need. Review the CARET documentation to check if your model's method matches its package name. (Log in to GitHub before clicking this link.)scikit-learn
All Python environments contain scikit-learn to help with preprocessing (if necessary), but only scikit-learn can make predictions on
sklearnmodels. -
In the Files section, assemble the custom job. Drag files into the box, or use the options in this section to create or upload the files required to assemble a custom job:
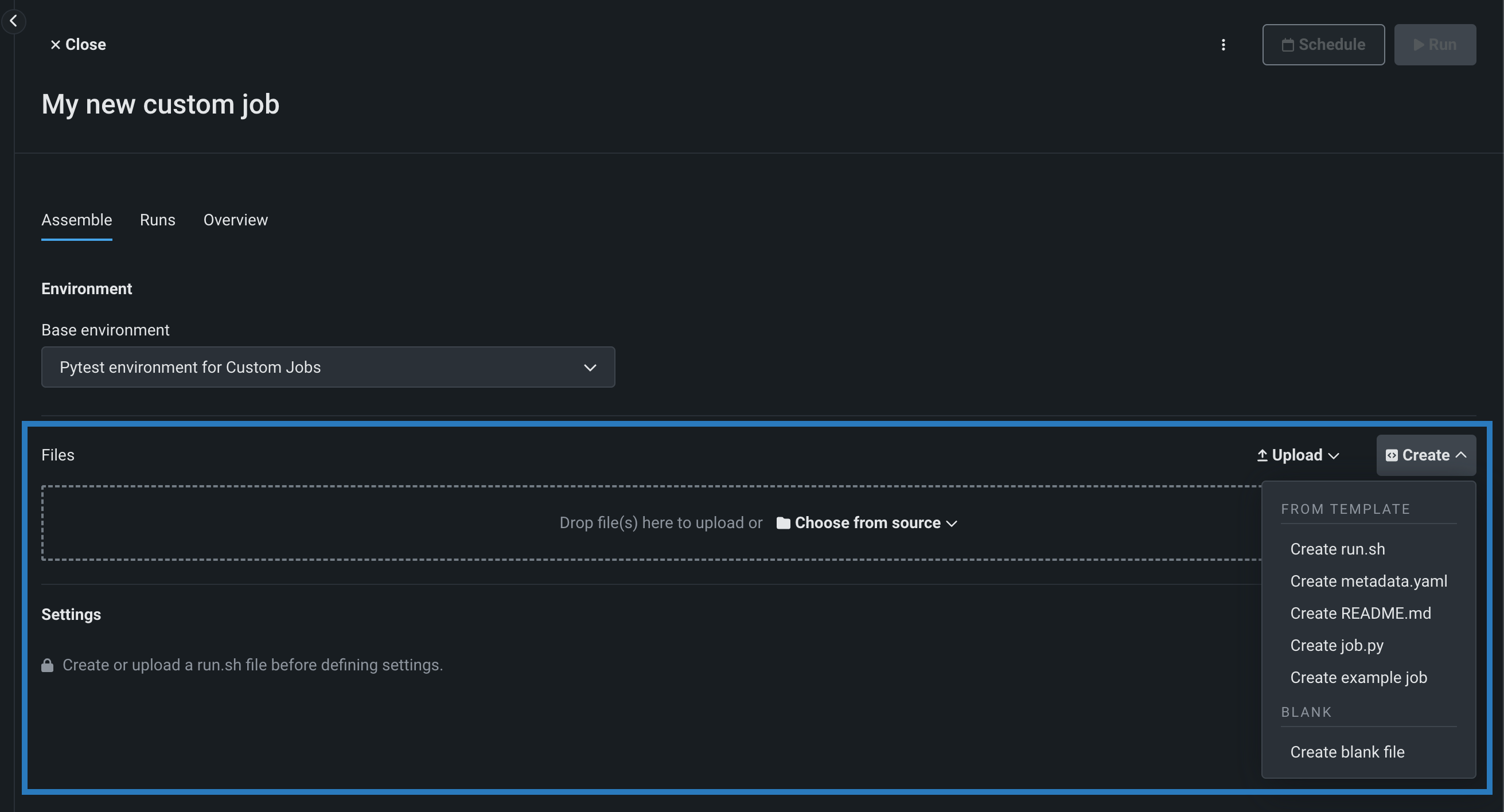
Option Description Choose from source / Upload Upload existing custom job files ( run.sh,metadata.yaml, etc.) as Local Files or a Local Folder.Create Create a new file, empty or containing a template, and save it to the custom job: - Create run.sh: Creates a basic, editable example of an entry point file.
- Create metadata.yaml: Creates a basic, editable example of a runtime parameters file.
- Create README.md: Creates a basic, editable README file.
- Create job.py: Creates a basic, editable Python job file to print runtime parameters and deployments.
- Create example job: Combines all template files to create a basic, editable custom job. You can quickly configure the runtime parameters and run this example job.
- Create blank file: Creates an empty file. Click the edit icon next to Untitled to provide a file name and extension, then add your custom contents. In the next step, it is possible to identify files created this way, with a custom name and content, as the entry point. After you configure the new file, click Save.
File replacement
If you add a new file with the same name as an existing file, when you click Save, the old file is replaced in the Files section.
-
In the Settings section, configure the Entry point shell (
.sh) file for the job. If you've added arun.shfile, that file is the entry point; otherwise, you must select the entry point shell file from the dropdown list. The entry point file allows you to orchestrate multiple job files: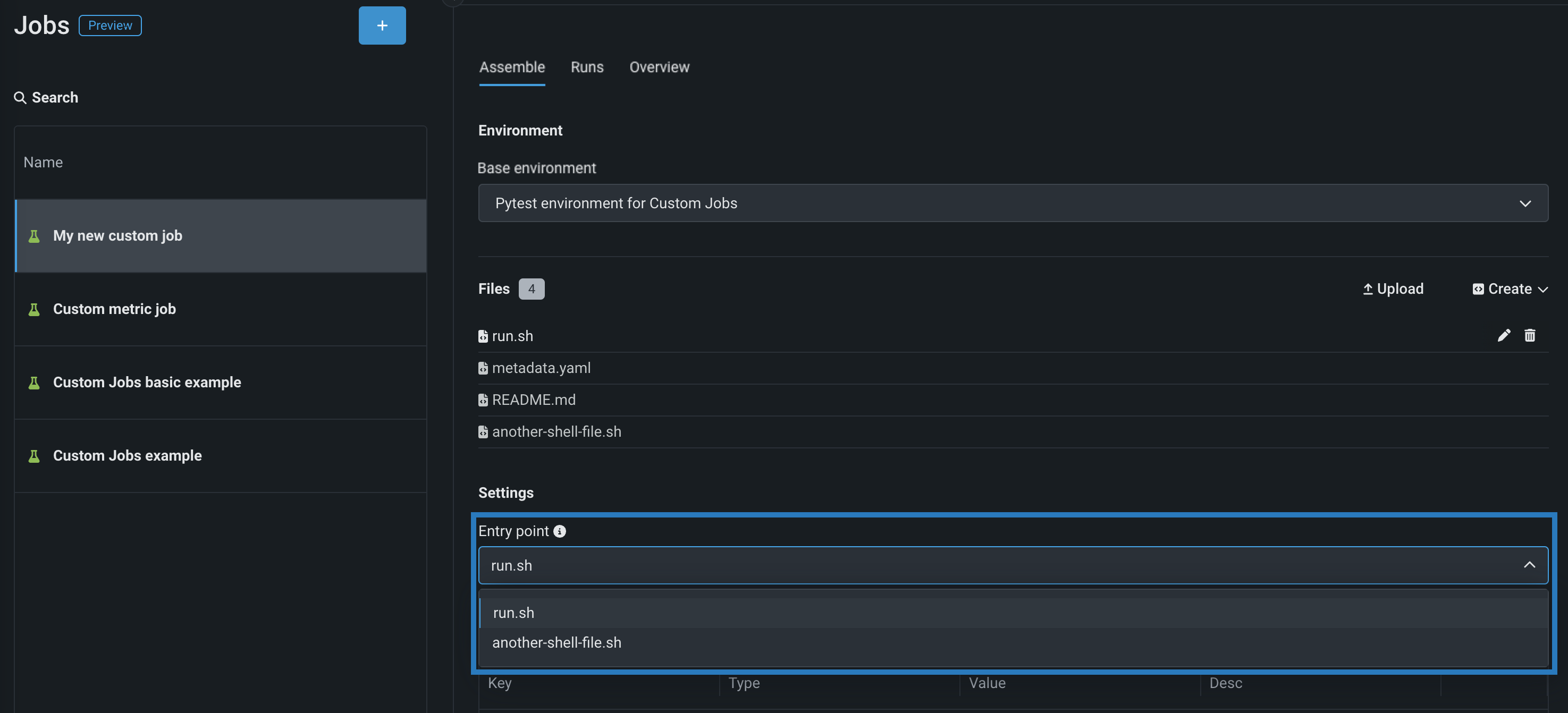
-
In the Resources section, next to the section header, click Edit and configure the following:
Preview
Custom job resource bundles are off by default. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Resource Bundles
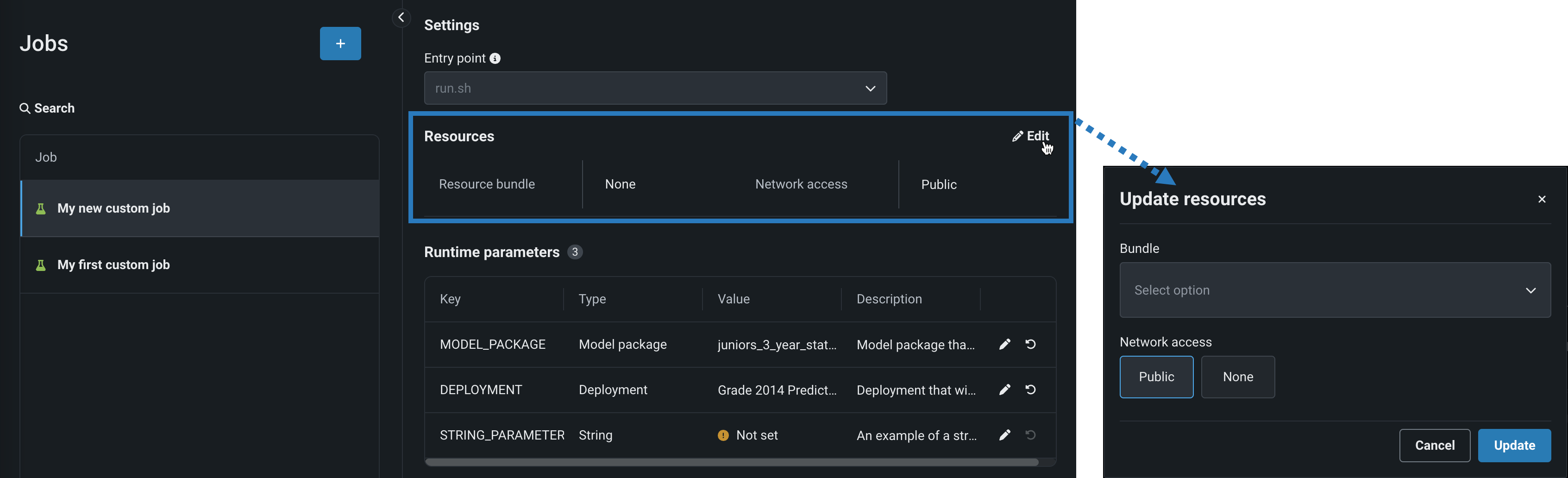
Setting Description Resource bundle Preview feature. Configure the resources the custom job uses to run. Network access Configure the egress traffic of the custom job. Under Network access, select one of the following: - Public: The default setting. The custom job can access any fully qualified domain name (FQDN) in a public network to leverage third-party services.
- None: The custom job is isolated from the public network and cannot access third party services.
Default network access
For the Managed AI Platform, the Network access setting is set to Public by default and the setting is configurable. For the Self-Managed AI Platform, the Network access setting is set to None by default and the setting is restricted; however, an administrator can change this behavior during DataRobot platform configuration. Contact your DataRobot representative or administrator for more information.
-
(Optional) Define Runtime parameters. Click + Add runtime parameter to define a new runtime parameter by providing a Name, Type, Value, and, optionally, a Description.
Alternatively define runtime parameters in a
metadata.yamlfile. A template for this file is available from the Files > Create dropdown.For existing runtime parameters, click Edit to edit parameter values, remove parameters, or reset parameter values.
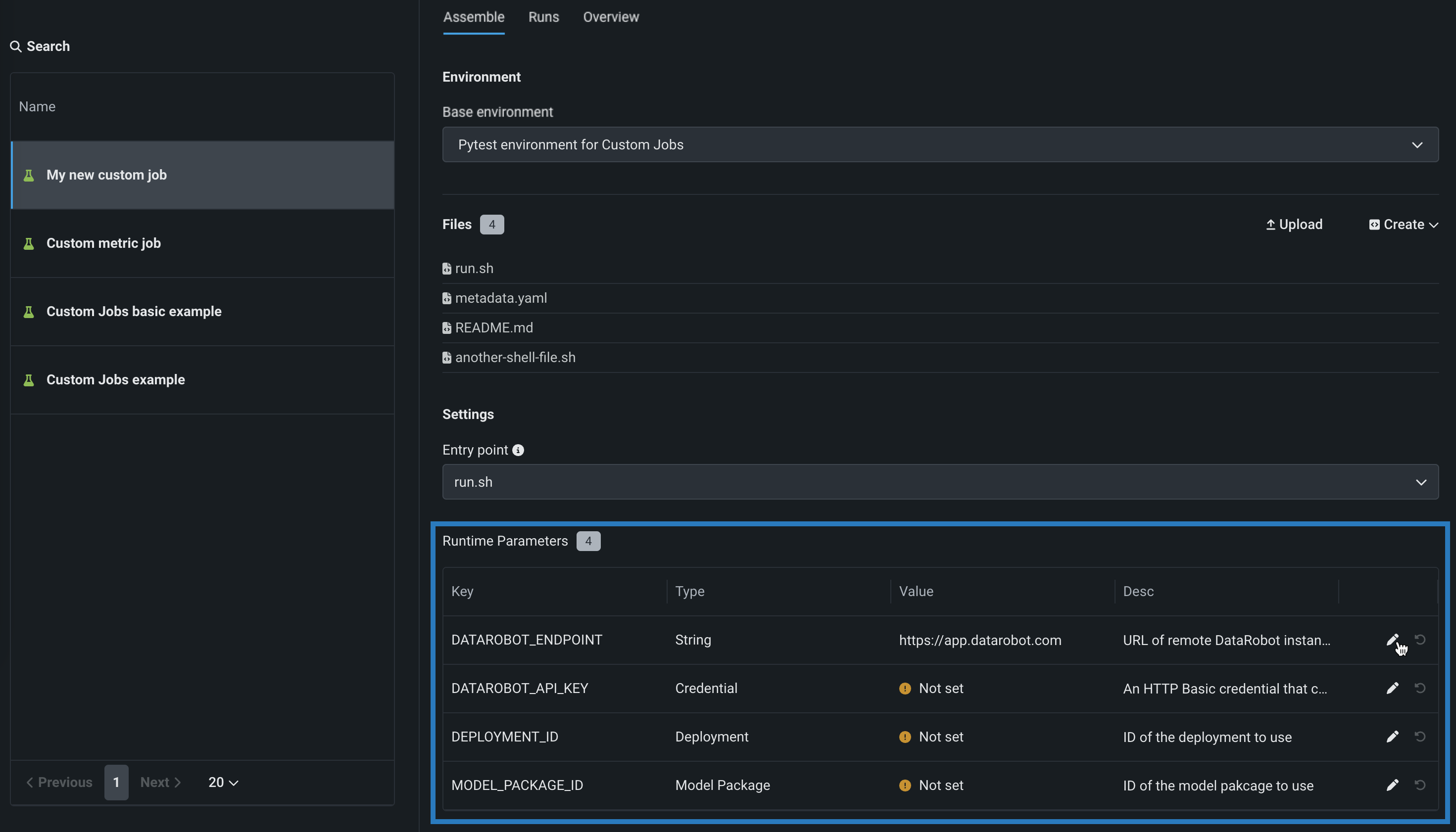
-
(Optional) Configure additional Key values for Tags, Metrics, Training parameters, and Artifacts.
Create a retraining job from a template¶
To add a pre-made retraining job from a template:
Preview
The jobs template gallery is on by default.
Feature flag: Enable Custom Jobs Template Gallery
-
In the Add custom job from gallery panel, click the job template you want to create a job from.

-
Review the job description, Execution environment, Metadata, and Files, then, click Create custom job:

The job opens to the Assemble tab.
-
On the Assemble tab for the new job, click the job name (or the edit icon ()) to enter a new job name, and then click confirm :
-
In the Environment section, review the Base environment for the job, set by the template.
-
In the Files section, review the files added to the job by the template:
-
Click the edit icon to modify the files added by the template.
-
Click the delete icon to remove files added by the template.
-
-
If you need to add new files, use the options in this section to create or upload the files required to assemble a custom job:

Option Description Upload Upload existing custom job files ( run.sh,metadata.yaml, etc.) as Local Files or a Local Folder.Create Create a new file, empty or containing a template, and save it to the custom job: - Create run.sh: Creates a basic, editable example of an entry point file.
- Create metadata.yaml: Creates a basic, editable example of a runtime parameters file.
- Create README.md: Creates a basic, editable README file.
- Create job.py: Creates a basic, editable Python job file to print runtime parameters and deployments.
- Create example job: Combines all template files to create a basic, editable custom job. You can quickly configure the runtime parameters and run this example job.
- Create blank file: Creates an empty file. Click the edit icon () next to Untitled to provide a file name and extension, then add your custom contents. In the next step, it is possible to identify files created this way, with a custom name and content, as the entry point. After you configure the new file, click Save.
File replacement
If you add a new file with the same name as an existing file, when you click Save, the old file is replaced in the Files section.
-
In the Settings section, review the Entry point shell (
.sh) file for the job, added by the template (usuallyrun.sh). The entry point file allows you to orchestrate multiple job files: -
In the Resources section, review the default resource settings for the job. To modify the settings, next to the section header, click Edit and configure the following:
Availability information
Custom job resource bundles are off by default. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Resource Bundles
Setting Description Resource bundle Preview feature. Configure the resources the custom job uses to run. Network access Configure the egress traffic of the custom job. Under Network access, select one of the following: - Public: The default setting. The custom job can access any fully qualified domain name (FQDN) in a public network to leverage third-party services.
- None: The custom job is isolated from the public network and cannot access third party services.
Default network access
For the Managed AI Platform, the Network access setting is set to Public by default and the setting is configurable. For the Self-Managed AI Platform, the Network access setting is set to None by default and the setting is restricted; however, an administrator can change this behavior during DataRobot platform configuration. Contact your DataRobot representative or administrator for more information.
-
(Optional) Define Runtime parameters. Click + Add runtime parameter to define a new runtime parameter by providing a Name, Type, Value, and, optionally, a Description.
Alternatively define runtime parameters in a
metadata.yamlfile. A template for this file is available from the Files > Create dropdown.For existing runtime parameters, click Edit to edit parameter values, remove parameters, or reset parameter values.
-
Configure additional Key values for Tags, Metrics, Training parameters, and Artifacts.
After you create a retraining job, you can add it to a deployment as a retraining policy.