指標の評価¶
プレイグラウンドのエージェント評価ツールには、評価指標とデータセット、集計された指標、コンプライアンステスト、トレースが含まれます。 エージェントの評価指標ツールには、以下のようなものがあります。
| エージェントワークフロー評価ツール | 説明 |
|---|---|
| 評価指標 | プレイグラウンドでのプロンプトと回答のパフォーマンス、安全性、運用に関する一連の指標を報告し、設定された指標にモデレーションの基準とアクションを定義します。 |
| 評価データセット | 評価データセットの指標と集計された指標によってエージェントのワークフローを評価する際に使用する評価データセットをアップロードまたは生成します。 |
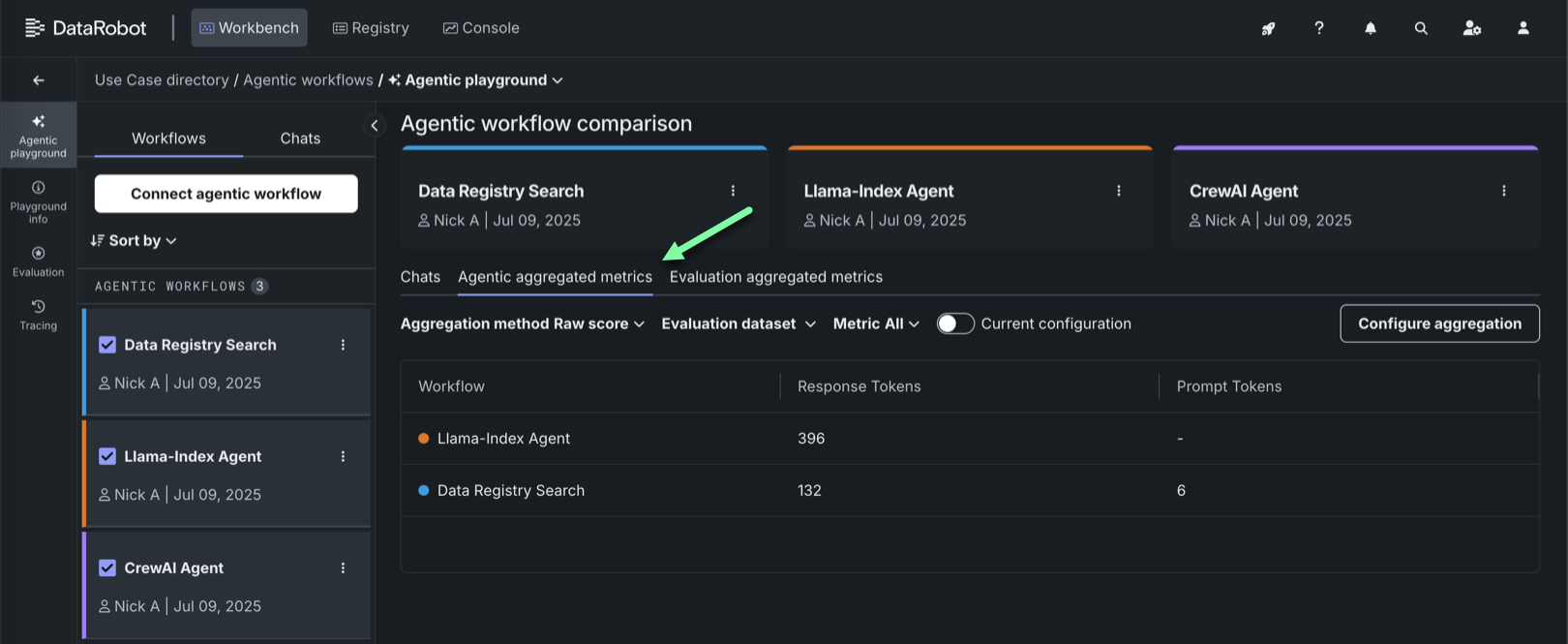
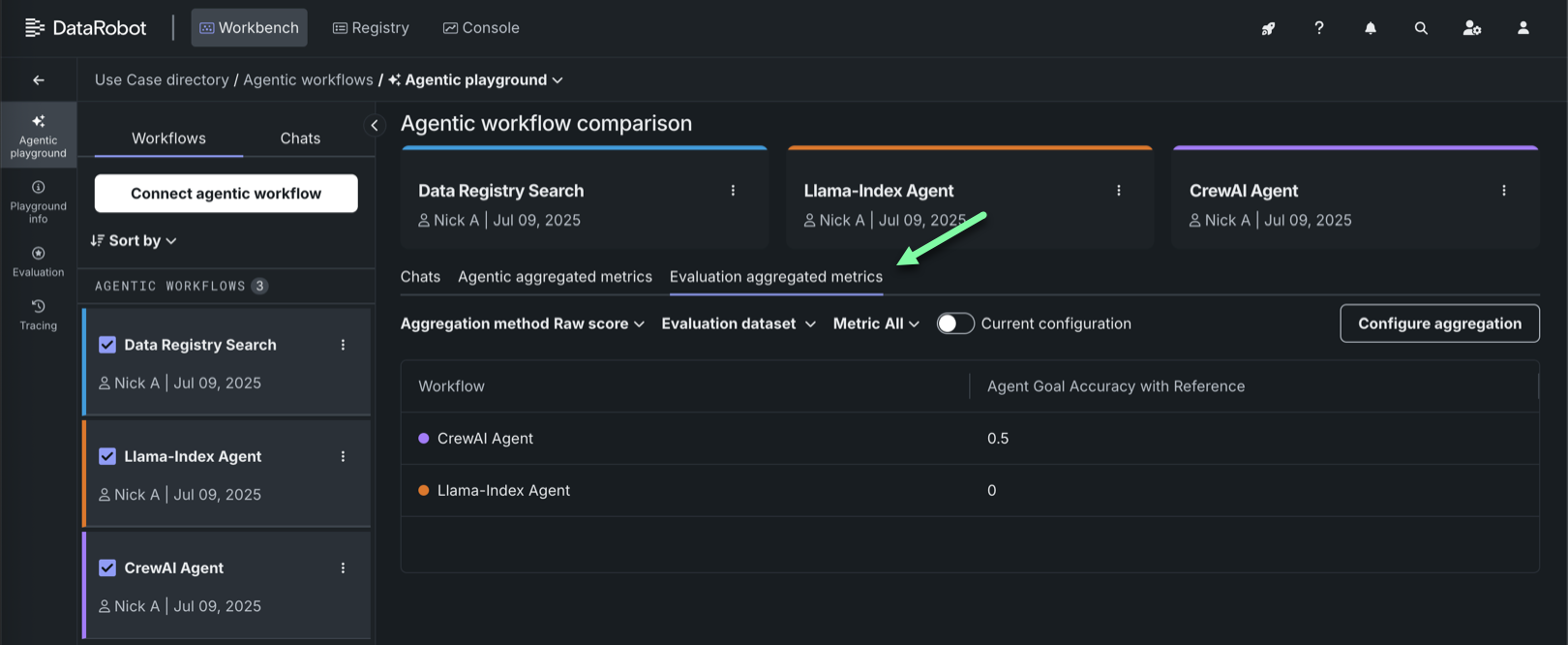
| 集計された指標 | 1つのプロンプトや回答の評価から学べることは限られているため、多くのプロンプトや回答の評価指標を組み合わせて、エージェントのワークフローを大枠で評価します。 |
| トレーステーブル | プレイグラウンドで回答を生成する際に使用されたすべてのコンポーネントとプロンプティングアクティビティのログを通して、エージェントワークフローの実行をトレースします。 |
評価指標の設定¶
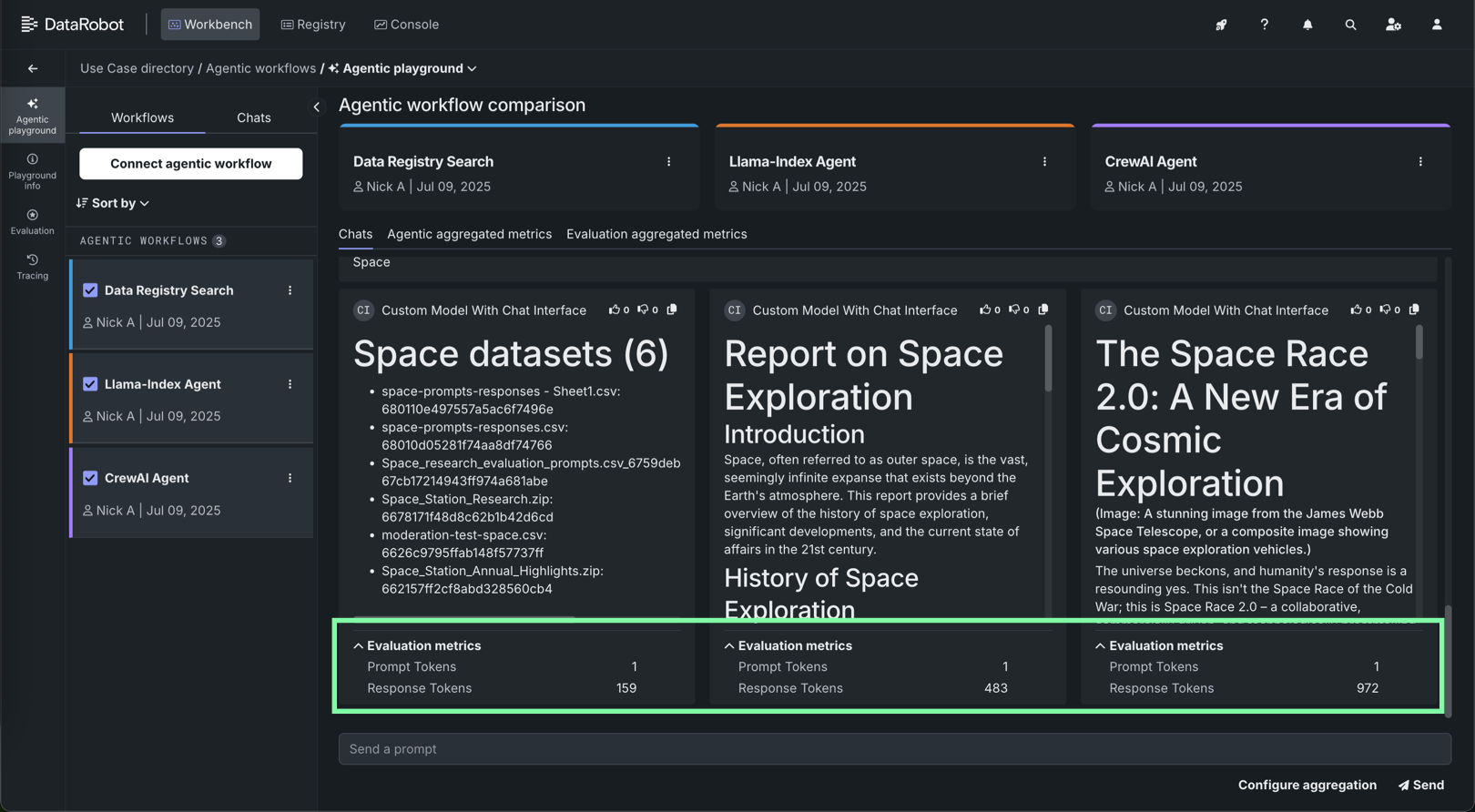
評価指標を使用すると、エージェントのパフォーマンスおよび運用指標を設定できます。 これらの指標は、比較チャットおよび個々のエージェントとのチャットで確認できます。
プレイグラウンドの指標は、評価データセットを通じて提供される参照情報を必要とし、エージェントのワークフローが期待どおりに動作しているかどうかを評価するのに役立ちます。 評価データセットが必要なため、プレイグラウンドでのみ使用できます。 エージェントワークフローの指標は参照データを必要としないため、本番環境で使用でき、ワークショップで設定されます。
| プレイグラウンドの指標 | エージェントのワークフロー指標 |
|---|---|
| プレイグラウンドで設定される。 | ワークショップで設定される。 |
| 評価データセットとして提供される参照データが必要。 | 参照データを必要としない。 |
| 本番環境では計算できない。 | 本番環境で計算できる。 |
| トップレベルのエージェントワークフローにのみ適用できる。 | ワークフローのトップレベルエージェントおよびサブエージェントとサブツール(それらが個別のカスタムモデルである場合)に適用できる。 |
エージェントのモデレーション
エージェントのワークフロー固有の指標は、モデレーション基準の設定をサポートしていません。
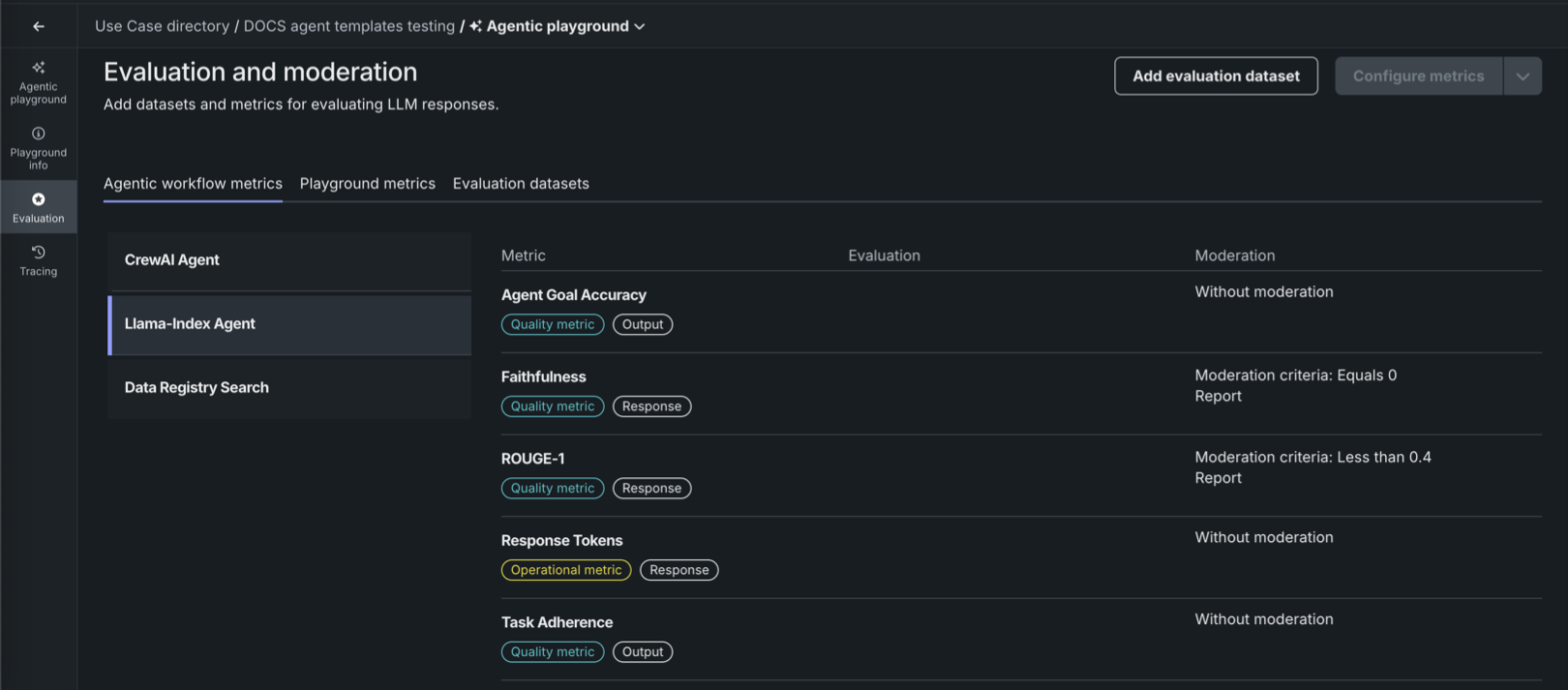
エージェントワークフローの指標を表示¶
ワークフローでエージェントワークフローの指標を有効にするには、ワークショップで評価とモデレーションを設定します。 評価タイルをクリックして、エージェントのワークフローで有効になっている構成済みの指標をエージェントのワークフロー指標で確認します。
プレイグラウンドの指標を設定¶
ワークフローでプレイグラウンドの指標を有効にするには、エージェントのプレイグラウンドに1つ以上の評価指標を追加します。 さらに、評価データセットを使用して参照データを提供する必要があります。
-
エージェントのプレイグラウンドでプレイグラウンドの評価指標を選択して設定するには、次のいずれかを実行します。
プレイグラウンドにエージェントを接続していない場合は、指標で評価タイルで、指標の設定をクリックして、エージェントを追加する前に指標を設定します。
プレイグラウンドに1つ以上のエージェントを追加した場合は、サイドナビゲーションバーで 評価タイルをクリックします。
-
評価とモデレーションページで、プレイグラウンドの指標タブをクリックし、指標の設定をクリックします。
-
評価とモデレーションを設定ページで運用指標をクリックします。
プレイグラウンドの指標 説明 Agent latency 特定のリクエストに対してエージェントワークフローを実行する際のレイテンシーの合計。 完了処理、ツール呼び出し、およびモデレーションライブラリによって計算される指標のための時間が含まれます。 エージェントがOTel用に設定されている場合は、常に使用可能です。 Agent total tokens LLM Gatewayを使用するエージェントの場合、合計トークン数はOTelで報告されます。現在のテンプレートでは、すでにこれが行われています。 デプロイ済みLLMを使用するエージェントの場合、そのLLMはモデレーション設定でトークン数指標が有効になっている必要があります。 Agent cost デプロイされたLLMへの呼び出しにのみ使用できます。 デプロイされたLLMには、モデレーション設定においてコスト指標が設定されている必要があります。 運用指標とエージェントワークフローの比較
Agent Cost、Agent Latency、およびAgent Total Tokensは、エージェントテンプレートでデフォルト設定されているOTelコレクターのデータを使用します。 これらの指標は報告されたOTelデータを集計し、正しいスパンをそのデータに関連付けるためにトレースを有効にする必要があります。 エージェントワークフローの比較画面ではトレースを利用できないため、これらの運用評価指標は、エージェントごとの回答を評価する場合のみ使用でき、エージェントワークフローを比較する場合には使用できません。
その後、必要に応じて指標の名前を変更し、追加をクリックします。 これらの指標には、適用先が事前に設定されています。
-
評価とモデレーションを設定ページで品質指標をクリックします。
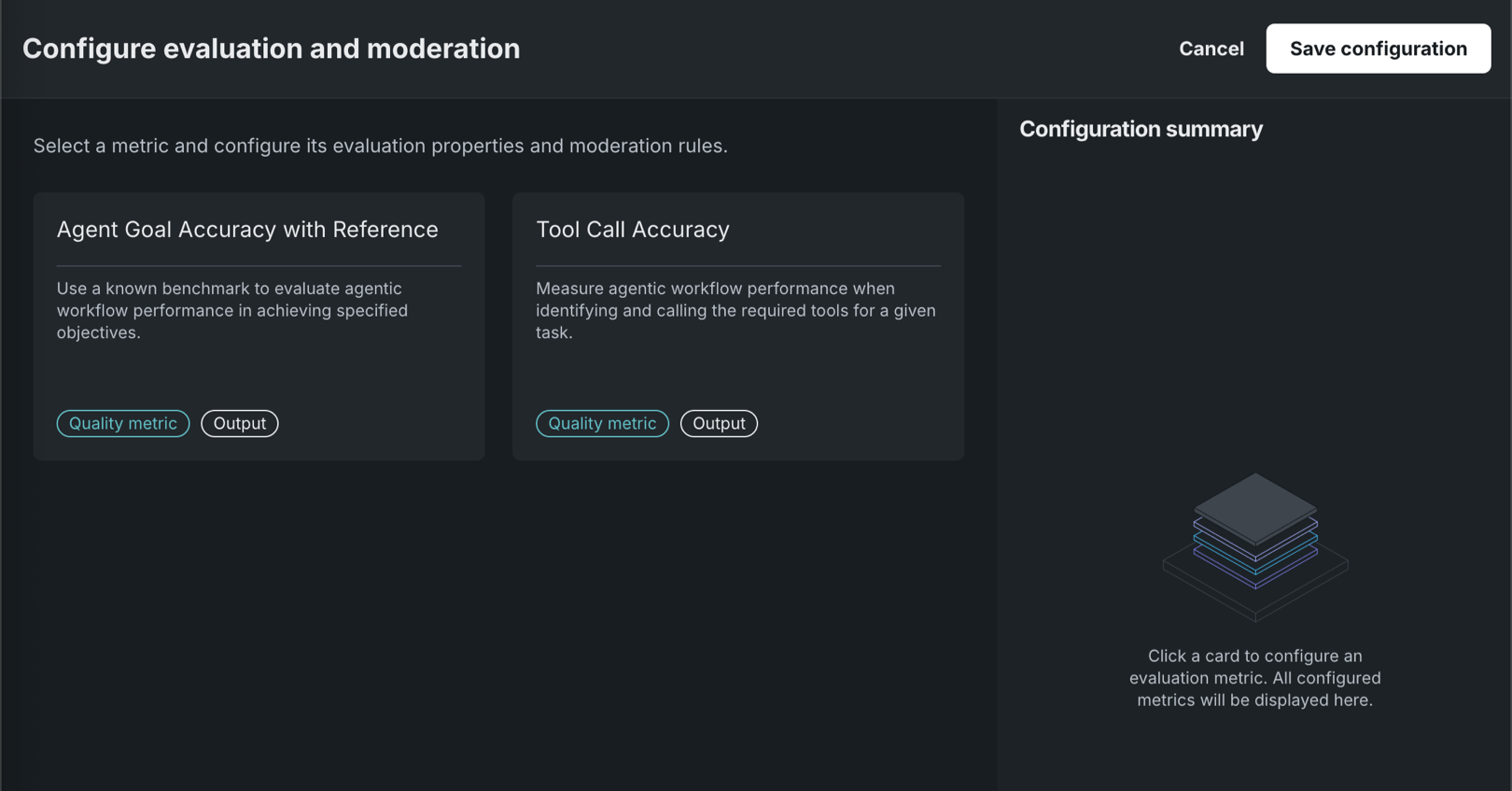
プレイグラウンドの指標 説明 Agent Goal Accuracy with Reference 既知のベンチマークを使用して、特定の目標を達成する際のエージェントワークフローのパフォーマンスを評価します。 エージェントゴール列を含む評価データセットが必要です。 Tool Call Accuracy 指定のタスクに必要なツールを特定して呼び出す際の、エージェントワークフローのパフォーマンスを評価します。 予想されるツール呼び出し列を含む評価データセットが必要です。 評価データセットの例
以下の評価データセットの例には、Tool Call Accuracy指標に必要な予想されるツール呼び出し列(
toolCalls)と、Agent Goal Accuracy with Reference指標に必要なエージェントゴール列(agentGoal)が含まれています。example_evaluation_dataset.csvid,promptText,expectedResponse,toolCalls,agentGoal 1,What is the weather like in New York today?,It is 24 C and sunny in New York today.,"[{""name"":""weather_check"",""args"":{""location"":""New York""}},{""name"":""temperature_conversion"",""args"":{""temperature_fahrenheit"":75}}]",A concise answer to a question about weather. 2,How many planets are in the solar system?,Our solar system has 8 planets.,[],A concise answer to a question about the solar system.さらに、DataRobot Pythonクライアントには、予想されるツール呼び出し列を構築するためのユーティリティクラスが用意されています。
次に、選択した指標に応じて以下の設定を行います。
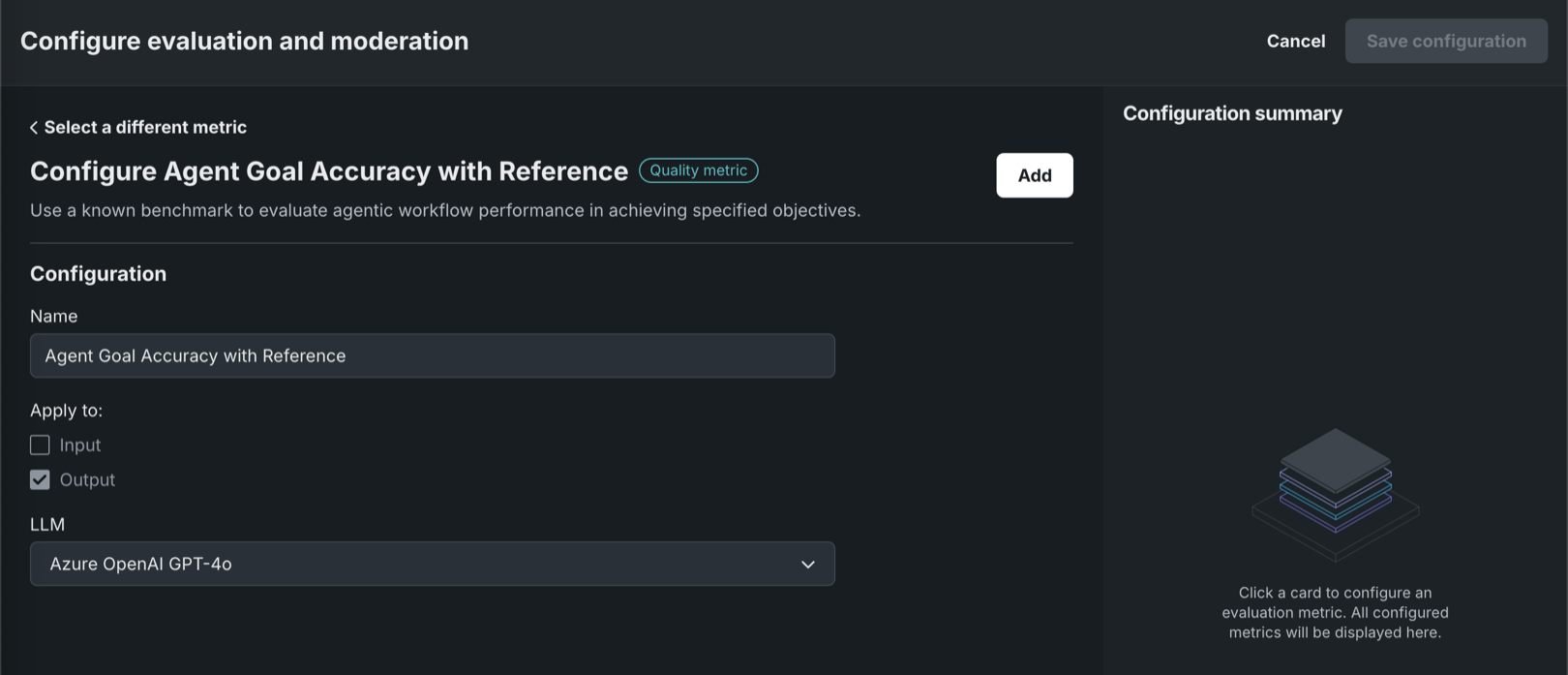
プレイグラウンドの指標 説明 Agent Goal Accuracy with Reference - (オプション)指標名を入力します。
- 目標精度を評価するプレイグラウンドまたはデプロイ済みLLMを選択します。
Tool Call Accuracy (オプション)指標名を入力します。 設定後、追加をクリックします。 これらの指標には、適用先が事前に設定されています。
-
別の指標を選択して設定するか、設定を保存をクリックします。
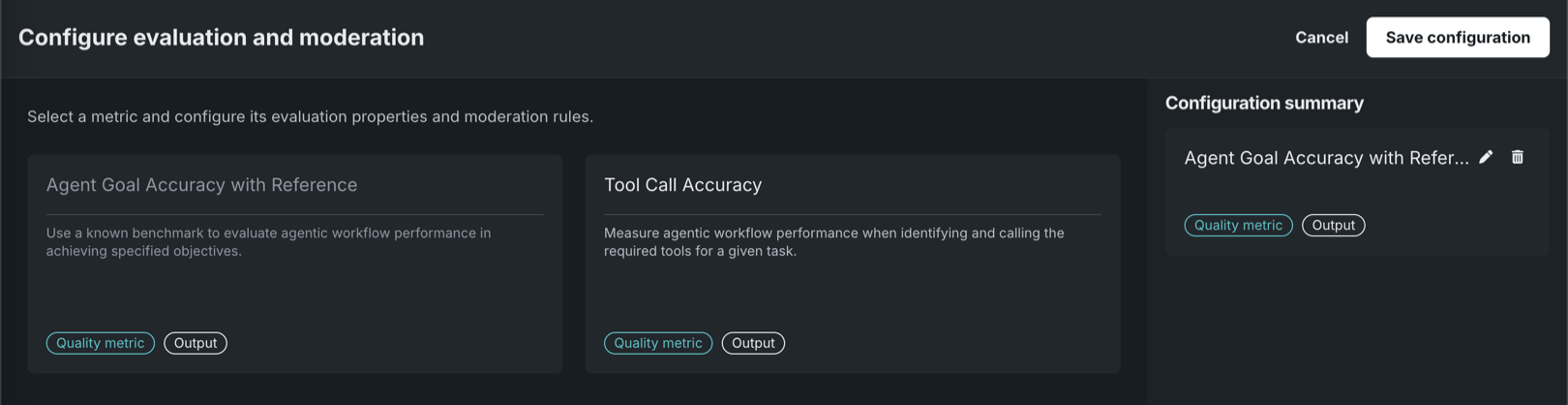
設定サマリーの編集
プレイグラウンド設定に1つ以上の指標を追加したら、それらの指標の編集や削除ができます。
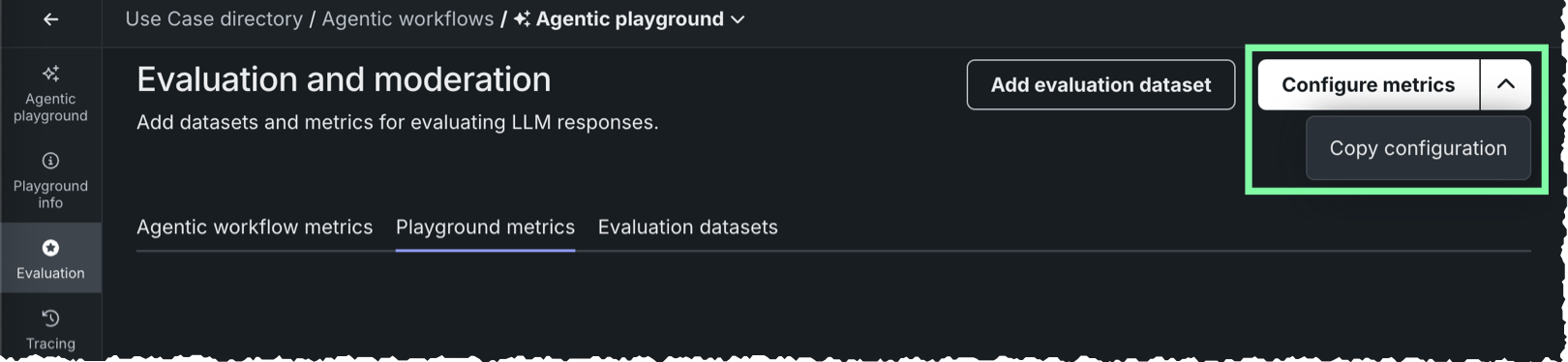
指標設定のコピー¶
評価指標の設定をエージェントのプレイグラウンドにコピーしたり、エージェントのプレイグラウンドからコピーしたりするには:
-
評価とモデレーションページの右上隅で、指標の設定の隣にある をクリックしてから、設定をコピーをクリックします。
-
評価とモデレーション設定のコピーモーダルで、次のいずれかのオプションを選択します。
既存のプレイグラウンドからを選択した場合は、既存の設定に追加または既存の設定を置換を選択してから、コピー元のプレイグラウンドを選択します。

既存のプレイグラウンドへを選択した場合は、既存の設定に追加または既存の設定を置換を選択してから、コピー先のプレイグラウンドを選択します。

新しいプレイグラウンドへを選択した場合は、新しいプレイグラウンド名を入力します。

-
評価データセットを含めるかどうかを選択し、設定をコピーをクリックします。
評価指標の重複
既存の設定に追加を選択すると、指標が重複することがあります。
評価データセットの追加¶
プレイグラウンドの評価指標と集計指標を有効にするには、参照データとして使用する評価データセットをプレイグラウンドに 1 つ以上追加する必要があります。 データセットは、データレジストリ内のCSVファイルであり、少なくとも1つのテキスト型またはカテゴリー型の列が含まれている必要があります。
-
エージェントのプレイグラウンドに評価データセットを追加するには、次のいずれかを実行します。
-
プレイグラウンドにエージェントを接続していない場合は、指標で評価タイルで、指標の設定をクリックして、エージェントを追加する前に指標を設定します。
-
プレイグラウンドに1つ以上のエージェントを追加した場合は、サイドナビゲーションバーで 評価をクリックします。
-
-
評価とモデレーションページで、評価データセットタブをクリックして既存のデータセットを表示するか、任意のタブから評価データセットを追加をクリックして、次のいずれかの方法を選択します。
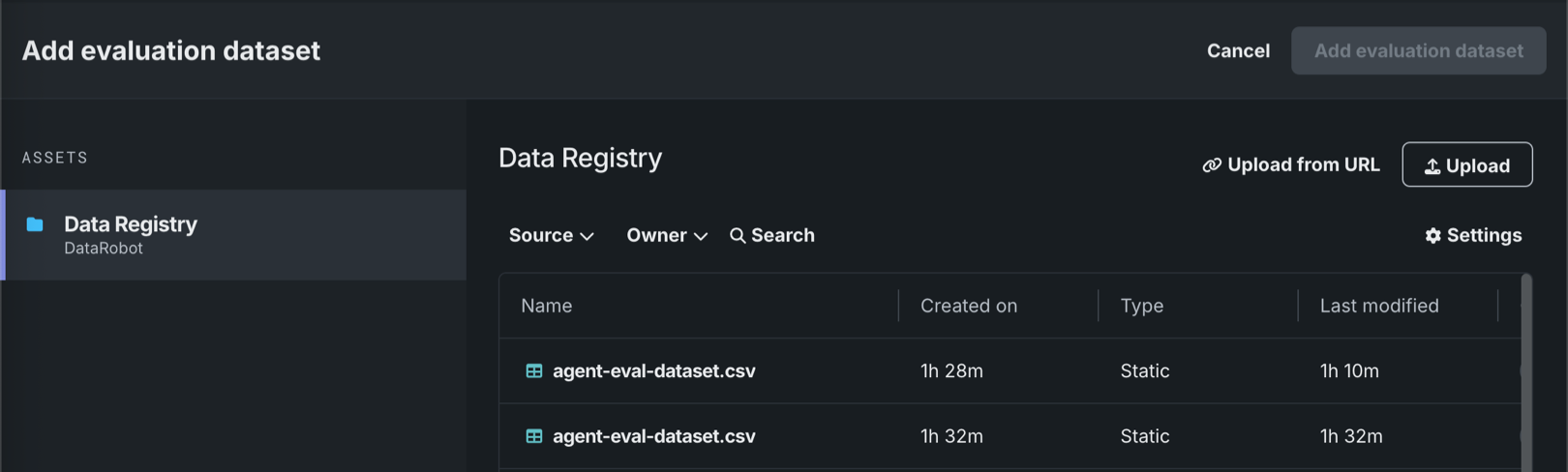
方法 説明 既存のデータセットを選択する データレジストリテーブルのデータセットをクリックします。 新規データセットをアップロード - アップロードをクリックして登録し、ローカルファイルシステムから新しいデータセットを選択します。
- URLからアップロードをクリックしてから、ホストされたデータセットのURLを入力し、追加をクリックします。
データセットを選択したら、右側のサイドバーの評価データセットの設定で、以下の列を定義します。
列 説明 プロンプト列の名前 ユーザープロンプトを含む参照データセット列の名前。 回答(ターゲット)列の名前 予想されるエージェントの回答を含む参照データセット列の名前。 リファレンスゴール列名 エージェントに期待される(目標)出力の説明を含む参照データセット列の名前。 このデータは、Configure Agent Goal Accuracy with Reference指標に使用されます。 リファレンスツール列名 予想されるエージェントツールの呼び出しを含む参照データセット列の名前。 このデータは、Configure Tool Call Accuracy指標に使用されます。 次に、評価データセットを追加をクリックします。
評価データセットの例
以下の評価データセットの例には、Tool Call Accuracy指標に必要な予想されるツール呼び出し列(
toolCalls)と、Agent Goal Accuracy with Reference指標に必要なエージェントゴール列(agentGoal)が含まれています。example_evaluation_dataset.csvid,promptText,expectedResponse,toolCalls,agentGoal 1,What is the weather like in New York today?,It is 24 C and sunny in New York today.,"[{""name"":""weather_check"",""args"":{""location"":""New York""}},{""name"":""temperature_conversion"",""args"":{""temperature_fahrenheit"":75}}]",A concise answer to a question about weather. 2,How many planets are in the solar system?,Our solar system has 8 planets.,[],A concise answer to a question about the solar system.さらに、DataRobot Pythonクライアントには、予想されるツール呼び出し列を構築するためのユーティリティクラスが用意されています。
-
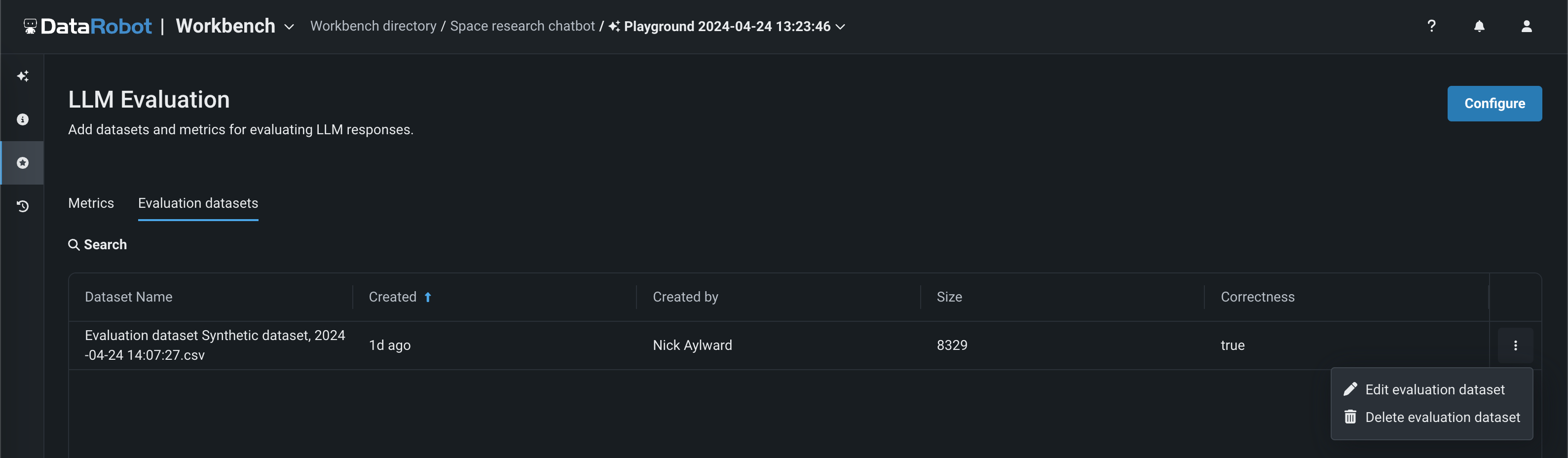
評価データセットを追加すると、評価とモデレーションページの評価データセットタブに表示されます。ここでは、次のことができます。
- データセットを開く をクリックして、データを表示する。
- アクションメニュー をクリックして、 評価データセットを編集するか、 評価データセットを削除する。
集計された指標の追加¶
プレイグラウンドに複数の指標が含まれている場合は、集計された指標の作成を開始できます。 集計とは、多くのプロンプトや回答にまたがる指標を組み合わせることで、エージェントを大枠で評価するのに役立ちます(1つのプロンプトや回答の評価から学べることは限られています)。 集計では、評価に対するより包括的なアプローチが可能になります。
集計では、元のスコアの平均化、ブール値のカウント、または多クラスモデル内のカテゴリー数の表示が行われます。 DataRobotでは、個々のプロンプト/回答の指標を生成し、指標に基づいてリストされているメソッドの1つを使用して集計することによってこれの処理を行います。
エージェントのプレイグラウンドに集計された指標を設定するには:
-
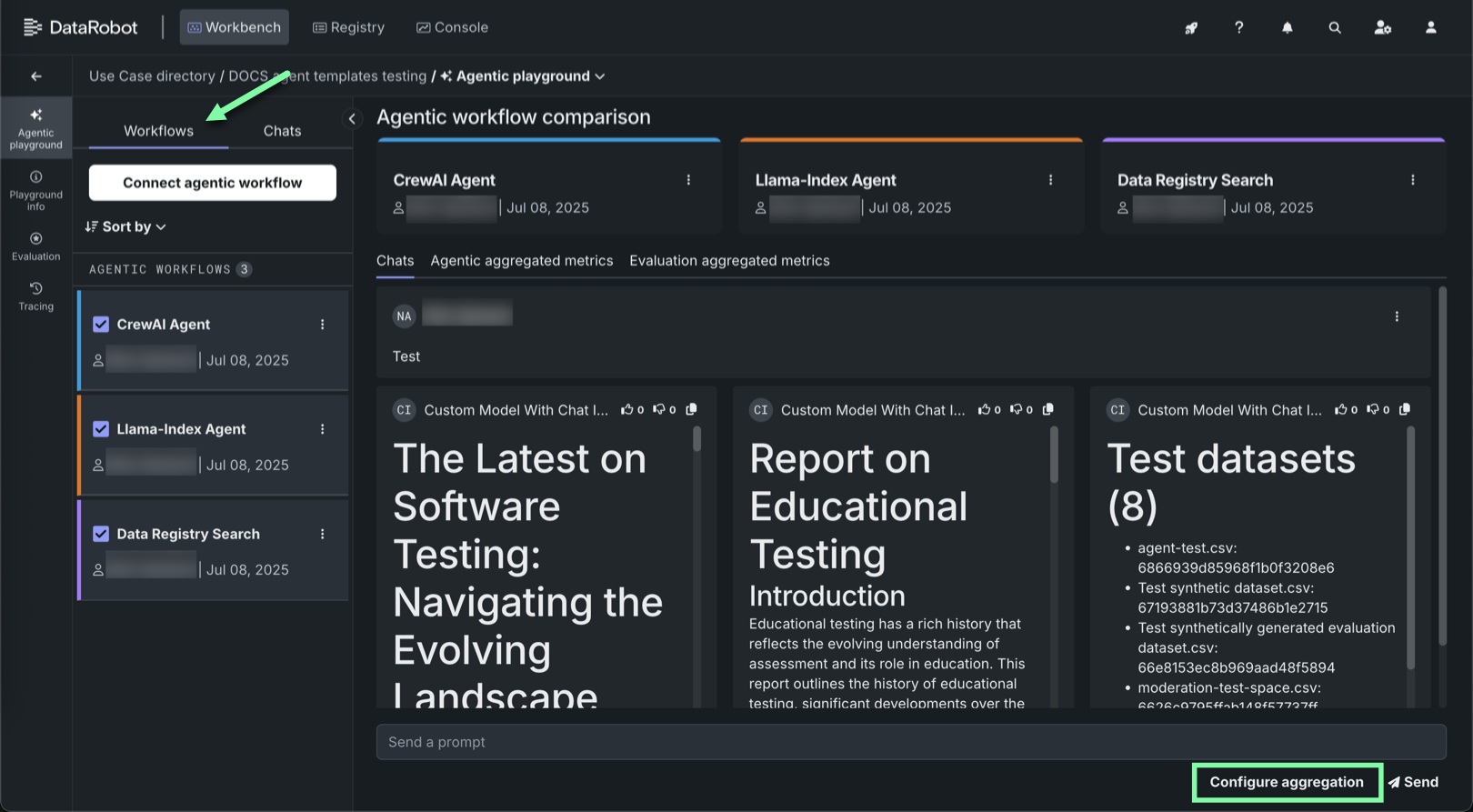
エージェントプレイグラウンドで、(ワークフロータブまたは個々のエージェントのチャットタブの)プロンプト入力の下にある集計の設定をクリックします。
ワークフロータブでは、選択した各エージェントワークフローが集計ジョブに含まれます。
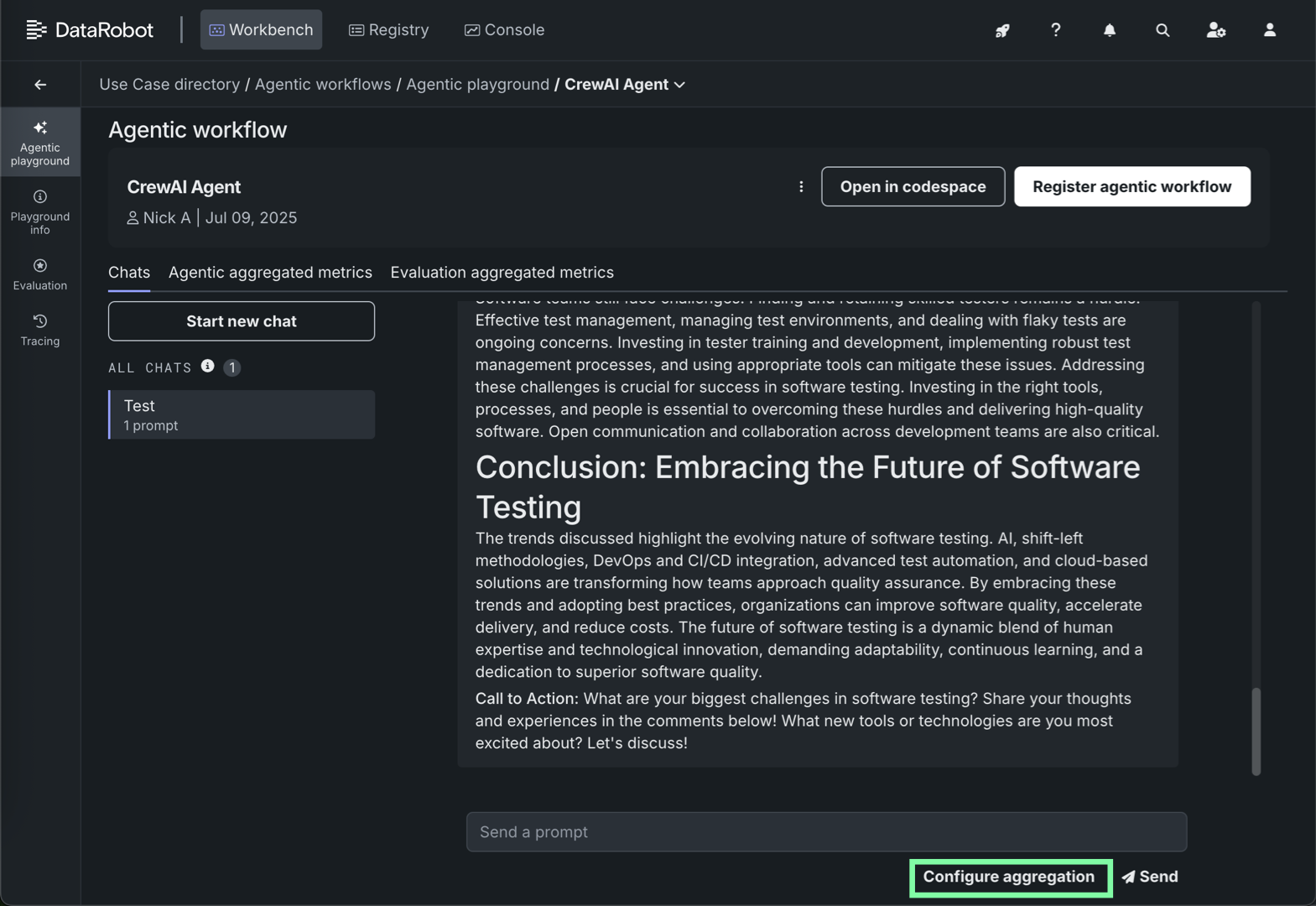
シングルエージェントのチャットタブでは、現在のエージェントワークフローのみが集計ジョブに含まれます。
集計ジョブの実行制限
一度に実行できる集計指標ジョブは1つだけです。 集計ジョブが現在実行されている場合、 集計の設定ボタンが無効になり、「集計ジョブが進行中です。処理が完了したら、もう一度試してください」というツールチップが表示されます。
-
集計された指標を生成パネルで、集計に含める指標を選択し、集計方法を設定します。 右側のパネルで、新しいチャット名を入力して、評価データセットを選択し(新しいチャットでプロンプトを生成するため)、指標を生成するワークフローを選択します。 これらのフィールドは、現在のプレイグラウンドに基づいて事前に入力されています。
プレイグラウンドとエージェントのワークフロー指標
以下の例では、Agent Goal Accuracy with ReferenceとTool Call Accuracyはプレイグラウンドの指標であり、ROUGE-1とResponse Tokenは(ワークショップからの)エージェントワークフローの指標です。
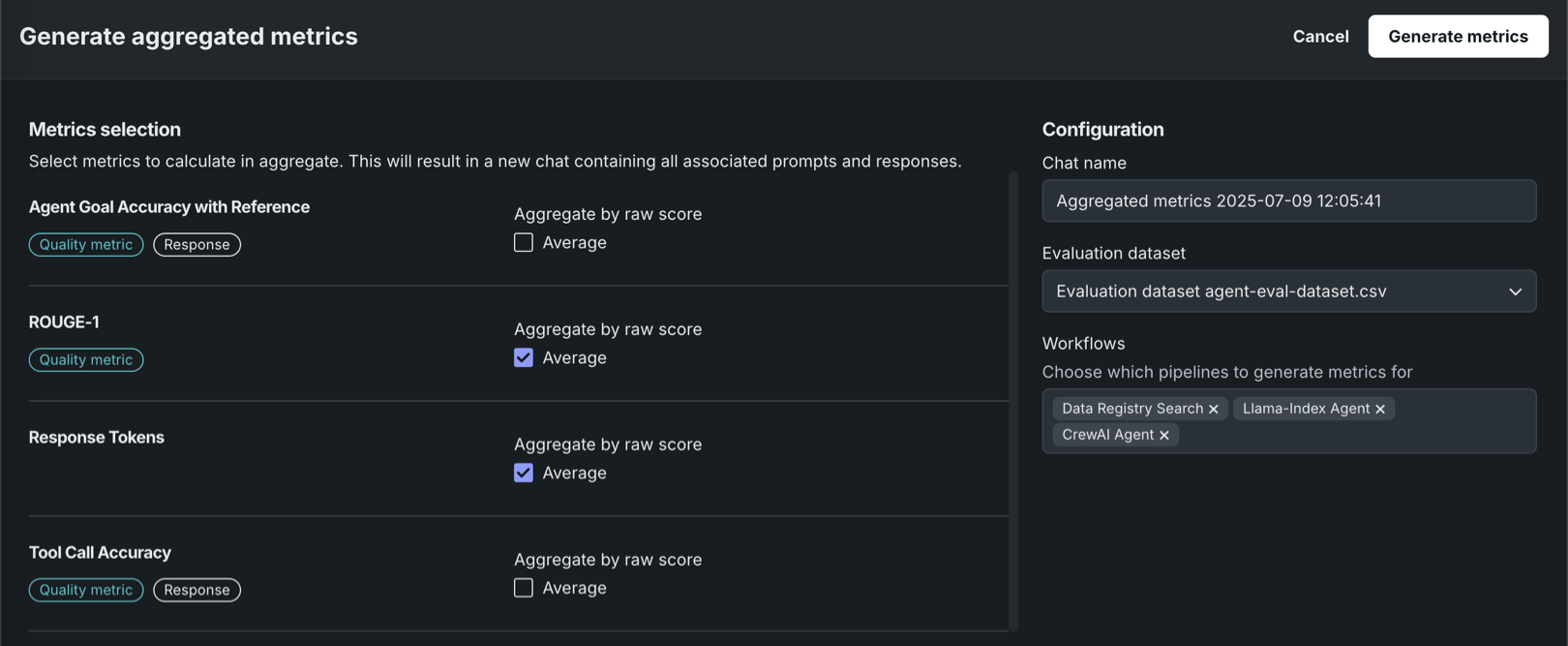
指標の選択および設定セクションを完了した後、指標の生成をクリックします。 これにより、指標チャットとして識別されるチャットが生成され、関連するすべてのプロンプトと回答が含まれます。
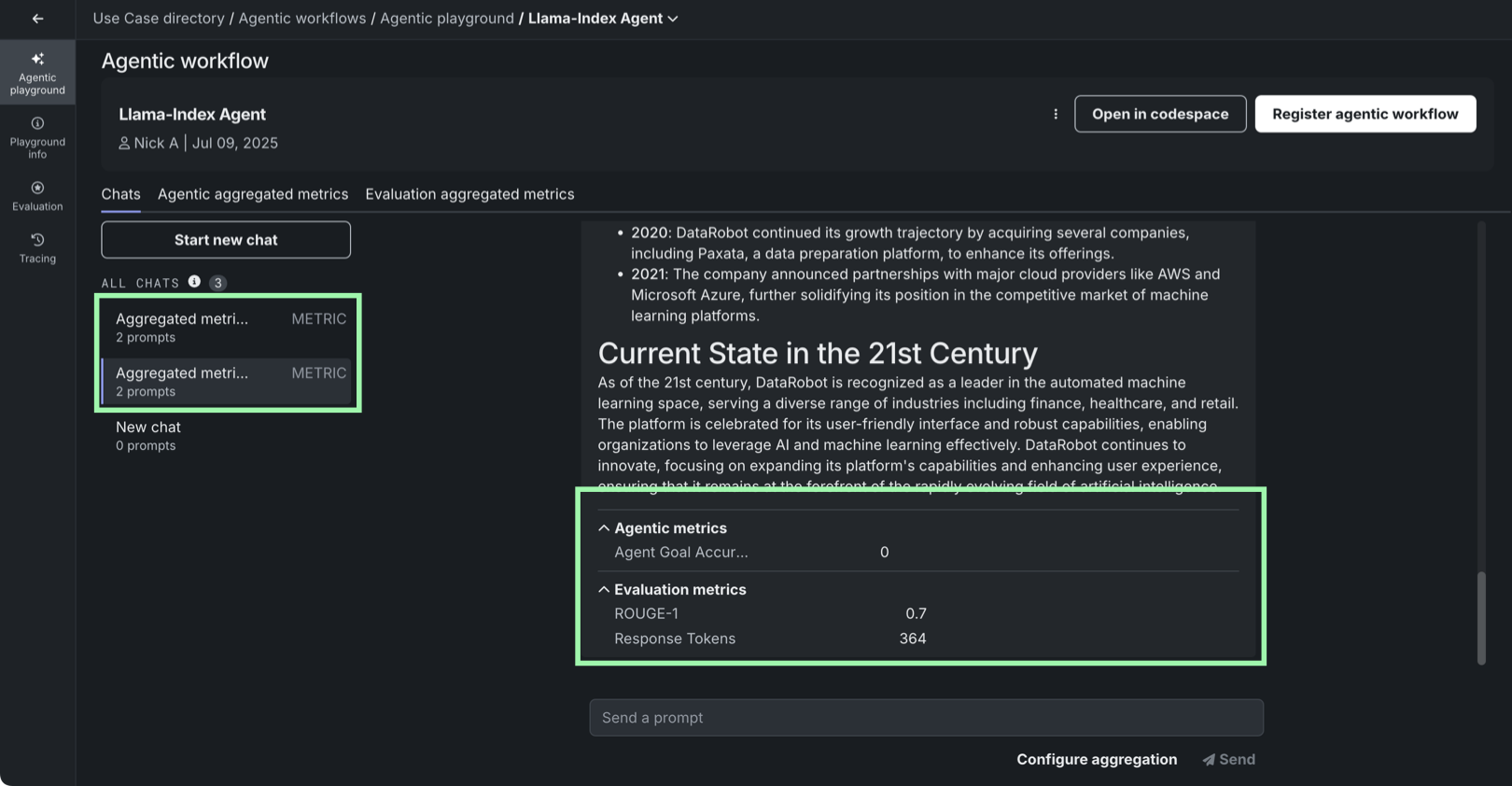
集計された指標は、標準のチャットの個々のプロンプトではなく、評価データセットに対して実行されます。 そのため、生成され、(エージェントの個々のチャットタブにある)エージェントのすべてのチャットリストに追加された集計指標チャットでのみ、集計された指標を見ることができます。
複数のエージェントでの集計指標の計算
指標集計リクエストに多くのエージェントが含まれている場合、集計された指標はエージェントごとに順番に計算されます。
-
集計されたチャットが生成されたら、エージェントの集計された指標タブおよび 評価の集計された指標タブで、その結果として得られた集計指標、スコア、関連アセットを確認できます。 これらのタブは、エージェントのチャットを比較するとき、およびシングルエージェントのチャットを表示するときに利用できます。 集計方法、評価データセット、指標でフィルターすることができます。