評価とモデレーションを設定¶
プレミアム機能
評価およびモデレーションガードレールはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:モデレーションのガードレールを有効にする(プレミアム)、モデルレジストリでグローバルモデルを有効にする(プレミアム)、予測応答で追加のカスタムモデル出力を有効にする
評価とモデレーションのガードレールは、組織がプロンプトインジェクションや、悪意のある、有害な、または不適切なプロンプトや回答をブロックするのに役立ちます。 また、ハルシネーションや信頼性の低い回答を防ぎ、より一般的には、モデルをトピックに沿った状態に保つこともできます。 さらに、これらのガードレールは、個人を特定できる情報(PII)の共有を防ぐことができます。 多くの評価およびモデレーションガードレールは、デプロイ済みのテキスト生成モデル(LLM)またはエージェントワークフローをデプロイ済みのガードモデルに接続します。 これらのガードモデルはLLMのプロンプトと回答について予測し、これらの予測と統計を中心的なLLMまたはエージェントワークフローのデプロイに報告します。
評価とモデレーションのガードレールを使用するには、まず、LLMのプロンプトや回答について予測するガードモデルを作成してデプロイします。たとえば、ガードモデルは、プロンプトインジェクションや有害な回答を識別することができます。 次に、ターゲットタイプがテキスト生成またはエージェントのワークフローであるカスタムモデルを作成する場合、評価とモデレーションのガードレールを1つ以上定義します。
重要な前提条件
LLMに評価とモデレーションのガードレールを設定する前に、ガードモデルをデプロイし、LLMのデプロイを設定する際には、以下のガイドラインに従ってください。
- カスタムガードモデルを使用している場合、デプロイする前に、
moderations.input_column_nameとmoderations.output_column_nameを登録モデルバージョンのタグ型キー値{ target=blank }として定義します。 _これらのキー値を設定しない場合、ガードモデルのユーザーは、入力列名と出力列名を手動で入力する必要があります。 - 評価とモデレーションを設定する前に、中心的なLLMの監視に使用するグローバルまたはカスタムガードモデルをデプロイします。
- デプロイされたガードモデルとは異なる予測環境に、中心的なLLMをデプロイします。
- デプロイされたLLMを介して予測を開始する前に、関連付けID{ target=blank }を設定して予測ストレージを有効にします。 _関連付けIDを設定せず、LLMの予測とともに関連付けIDを指定した場合、モデレーションの指標は カスタム指標タブでは計算されません。
- 関連付けIDを定義後、関連付けIDの自動生成を有効にして、これらの指標がカスタム指標タブに表示されるようにできます。 この設定は、デプロイ 中やデプロイ 後に有効化できます。
- NeMo Evaluator指標(Agent Goal Accuracy、Context Relevance、Faithfulness (NeMo Evaluator)、LLM Judge、Response Groundedness、Response Relevancy、Topic Adherence)のいずれかを使用する場合は、まずWorkload APIを使用してNeMo Evaluatorワークロードとワークロードのデプロイを作成します。 Workload APIにはUIがありません。APIを使用してワークロードを作成してから、ワークロードのデプロイを作成する必要があります。 これらの指標のそれぞれについて、NeMo Evaluatorのデプロイが必要です。
予測方法に関する注意事項
チャット生成Q&Aアプリケーションの外部で予測を行う場合、評価とモデレーションは、 リアルタイム予測とのみ互換性があり、 バッチ予測とは互換性がありません。 また、ボルトオンのガバナンスAPIを使ってストリーミングレスポンスをリクエストする場合、評価とモデレーションはストリーミングの効果を無効にします。 ガードレールは、LLMの完全なレスポンスのみを評価するため、レスポンステキストを1つのチャンクで返します。
評価とモデレーションのガードレールを選択する¶
ターゲットタイプがテキスト生成またはエージェントのワークフローであるカスタムモデルを作成する場合、評価とモデレーションのガードレールを1つ以上定義します。
評価およびモデレーションガードレールを選択および設定するには:
-
ワークショップにおいて、ターゲットタイプがテキスト生成またはエージェントのワークフローのカスタムモデルのアセンブルタブを開き、モデルを構築します。構築方法は、DataRobot以外で作成したカスタムモデルから手動で行うか、ユースケースのLLMプレイグラウンドで構築されたモデルから自動で行うかのいずれかです。
モデレーションを使ってテキスト生成モデルを構築する場合、必要なランタイムパラメーター(資格情報など)の設定やリソース設定(パブリックネットワークへのアクセスなど)を必ず行います。 最後に、基本環境をモデレーション対応の環境(たとえば[GenAI] Python 3.12 with Moderations)に設定します。
リソース設定
DataRobotでは、より多くのメモリーおよびCPUリソースを備えた、より大きなリソースバンドルを使用してLLMカスタムモデルを作成することをお勧めします。
-
カスタムモデルに必要な設定を行ったら、評価とモデレーションセクションに移動し、 設定をクリックします。
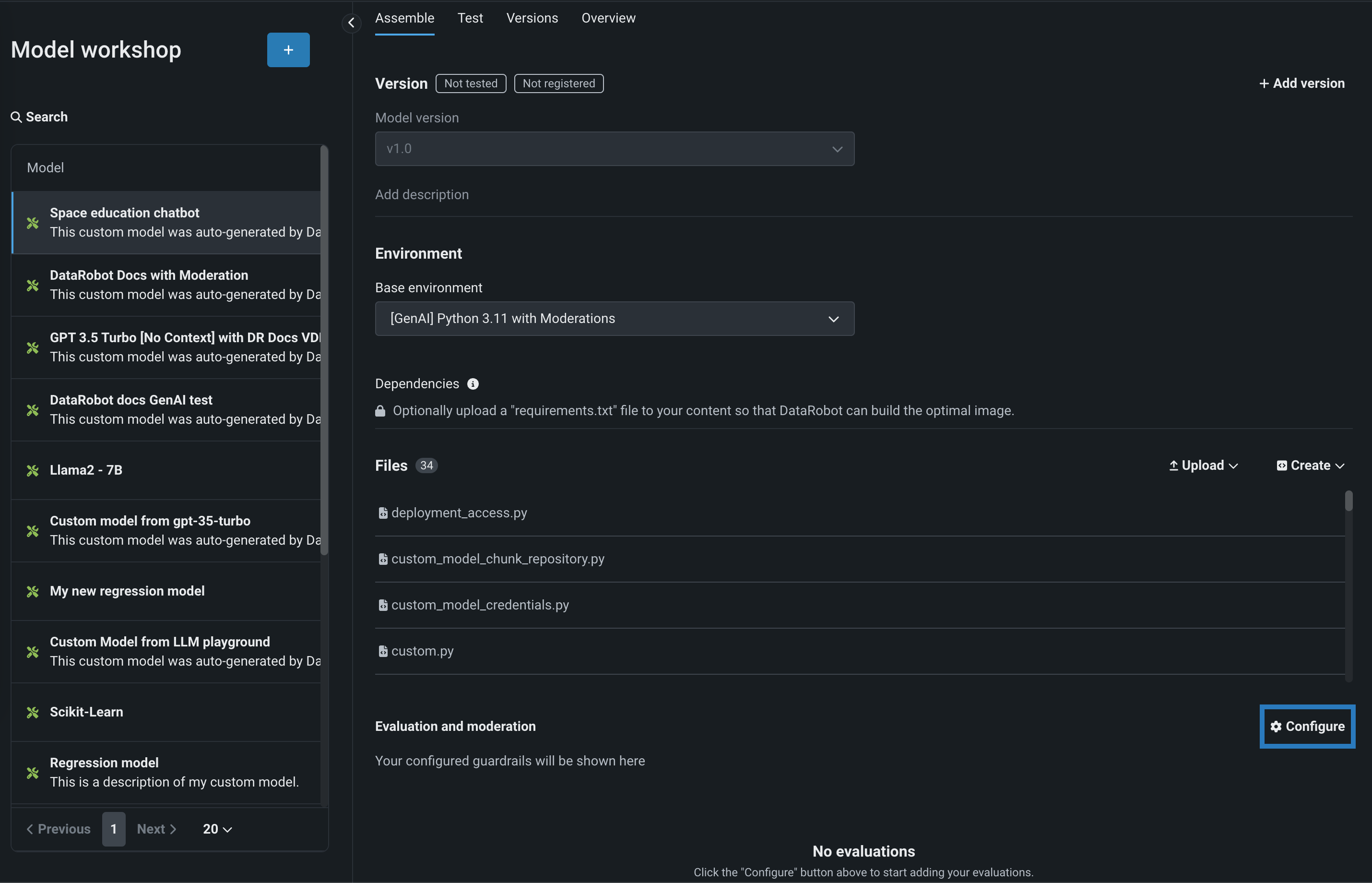
-
評価とモデレーションを設定パネルにある設定のサマリーで、以下の設定にアクセスします。

設定 説明 ワークフローを表示 DataRobotでどのように評価が実行されているかを確認します。 すべての評価とそれぞれのモデレーションは並行して実行されます。 モデレーション設定 以下を設定します。 - モデレーションのタイムアウトを設定:モデレーションシステムが自動的にタイムアウトするまでの最大待機時間を設定します。
- タイムアウトアクション:モデレーションシステムがタイムアウトした場合に何が起こるかを定義します:プロンプト/回答をスコアリングするまたはプロンプト/回答をブロックする。
NeMo Evaluatorの設定 NeMo Evaluatorの指標で使用されるNeMo Evaluatorのデプロイを設定します。 Workload APIを使用してNeMo Evaluatorのワークロードとワークロードのデプロイを作成するまで、ドロップダウンには「利用可能なオプションはありません」と表示されます。 NeMo Evaluatorの指標を設定するには、その手順を完了する必要があります。 -
評価とモデレーションを設定パネルで、以下の指標カードのいずれかをクリックし、必要なプロパティを設定します。 このパネルには、すべての指標とNeMoの指標の2つのセクションがあります。 設定のサマリーサイドバーから、ワークフローを表示、モデレーション設定、またはNeMo Evaluatorの設定を開き、すべてのNeMo Evaluator指標で使用されるEvaluatorのデプロイを設定できます。
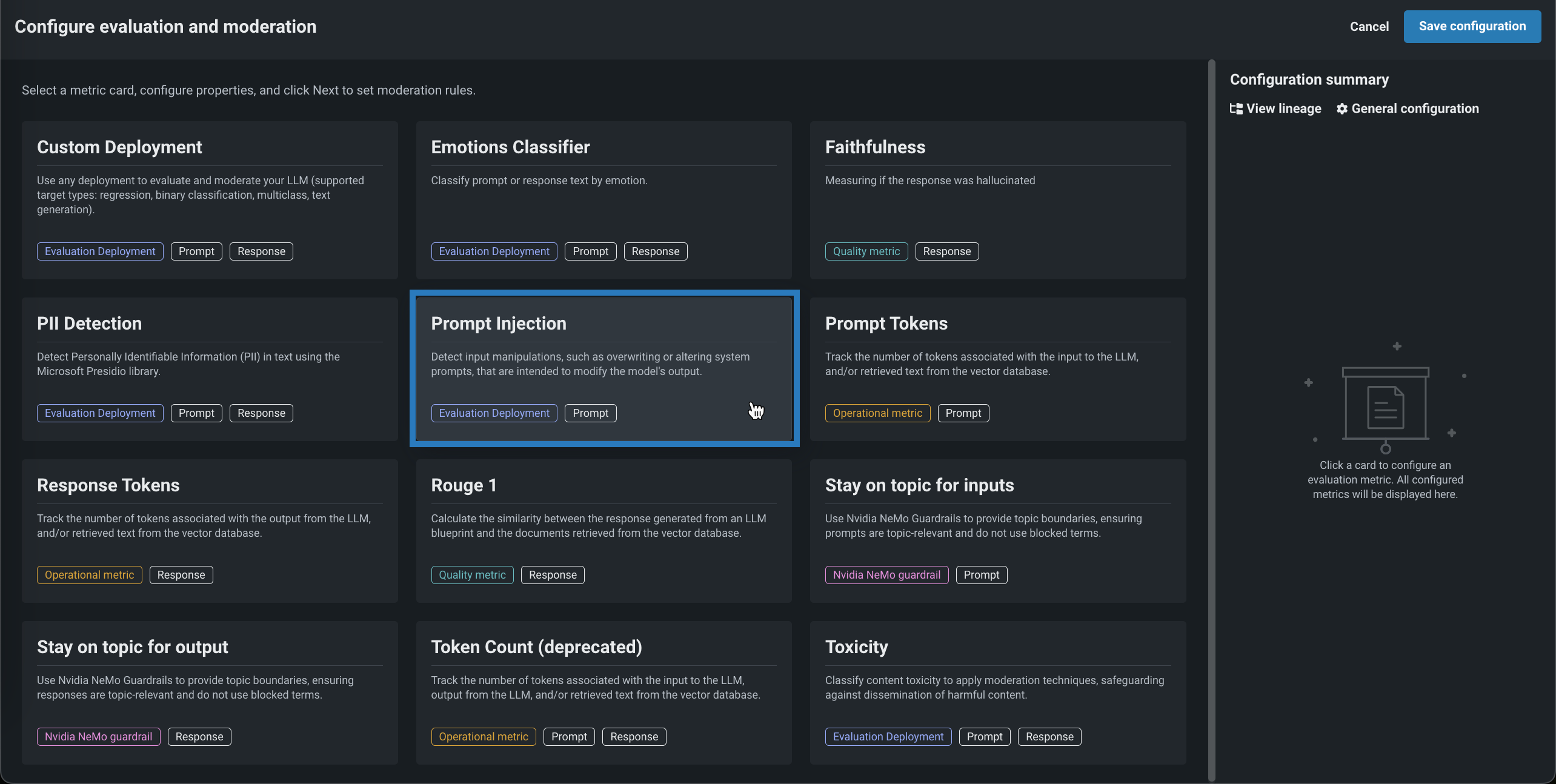
評価指標 要件 説明 コンテンツの安全性 NVIDIA GPU Cloud (NGC) Catalogからインポートされた、デプロイ済みのNIMモデルllama-3.1-nemoguard-8b-content-safety。 プロンプトと回答を安全または安全でないものとして分類し、検出された安全でないカテゴリーのリストを返します。 コスト LLMコスト設定 提供されたトークンあたりの入力コストと、トークンあたりの出力コストを使用して、LLM回答の生成コストを計算します。 コストの計算には、引用コストも含まれます。 詳細については、コスト指標の設定を参照してください。 カスタムデプロイ カスタムデプロイ 任意のデプロイを使用して、LLM(サポートされているターゲットタイプ:連続値、二値分類、多クラス、テキスト生成)の評価とモデレーションを行います。 感情分類器 感情分類器のデプロイ プロンプトまたはレスポンステキストを感情別に分類します。 忠実度 LLM、ベクターデータベース LLMの回答がソースと一致するかどうかを測定して、考えられるハルシネーションを識別します。 ジェイルブレイク NVIDIA GPU Cloud (NGC) Catalogからインポートされた、デプロイ済みのNIMモデルnemoguard-jailbreak-detect。 NemoGuard JailbreakDetectを使ってジェイルブレイクの試みを分類します。 PII検出 PresidioのPII検出 Microsoft Presidioライブラリを使用して、テキスト内の個人識別情報 (PII) を検出します。 プロンプトインジェクション プロンプトインジェクション分類器 モデルの出力変更を意図した入力操作(システムプロンプトの上書きや変更など)を検出します。 プロンプトトークン N/A LLMへの入力、およびベクターデータベースから取得されたテキスト、またはいずれか一方に関連付けられたトークンの数を追跡します。 回答トークン N/A LLMからの出力、およびベクターデータベースから取得されたテキスト、またはいずれか一方に関連付けられたトークンの数を追跡します。 ROUGE-1 ベクターデータベース LLMブループリントから生成された回答とベクターデータベースから取得されたドキュメントの間で類似度を計算します。 毒性 毒性分類器 コンテンツの有害性を分類してモデレーション技術を適用し、有害なコンテンツの拡散を防ぎます。 エージェントのワークフロー指標 Agent Goal Accuracy LLM 既知のベンチマークがないシナリオにおいて、特定の目標を達成する際のエージェントワークフローのパフォーマンスを評価します。 (このエージェントワークフロー指標は、NeMoの指標に含まれる同名のNeMo Evaluator指標とは異なります。) Task Adherence LLM エージェントワークフローの回答が適切で、完全であり、ユーザーの期待に沿っているかどうかを測定します。 Guideline Adherence LLM、ガイドライン設定 ジャッジLLMを使用して、回答が定義されたガイドラインにどの程度沿っているかを評価します。 ガイドラインに従っている場合はtrue、そうでない場合はfalseを返します。 設定時に、ガイドラインを提供し、LLMを(Gatewayまたはデプロイから)選択する必要があります。 評価指標デプロイのグローバルモデル
PII検出、プロンプトインジェクション検出、感情分類、毒性分類に必要なデプロイは、レジストリのグローバルモデルとして使用できます。
多クラスカスタムデプロイの指標の制限値
多クラスカスタムデプロイの指標には、以下の制限があります。
-
モデレーション基準の一致リストで定義できるクラスは最大で
10個までです。 -
ガードモデルで使用できるクラス名は最大で
100個までです。
NeMo Evaluator指標(Agent Goal Accuracy、Context Relevance、Faithfulness、LLM Judge、Response Groundedness、Response Relevancy、Topic Adherence)にはNeMo Evaluatorワークロードのデプロイが必要であり、これは設定のサマリーサイドバーのNeMo Evaluatorの設定で指定します。 ワークロードを選択する前に、Workload APIを使用してワークロードとワークロードのデプロイを作成します。デプロイが存在するまで、ワークロードデプロイの選択ドロップダウンには「利用可能なオプションはありません」と表示されます。 これらの各指標では、LLMジャッジ(DataRobotのデプロイまたはLLM Gateway)も使用されています。 Response Relevancyには、さらに埋め込みのデプロイが必要です。 Topic AdherenceとLLM Judgeには、追加の設定があります。 入力のトピックを維持および出力のトピックを維持では、NeMo Evaluatorのデプロイを使用しません。 これらは、
llama-3.1-nemoguard-8b-topic-controlモデルのNIMデプロイを使用します(コンテンツの安全性やジェイルブレイクがNIMモデルを使用するのと同様)。 これらを設定する際は、LLMのタイプをNIMに指定し、トピック制御用のNIMデプロイを選択します。必要に応じて、NeMo Guardrailsの設定ファイルを編集することも可能です。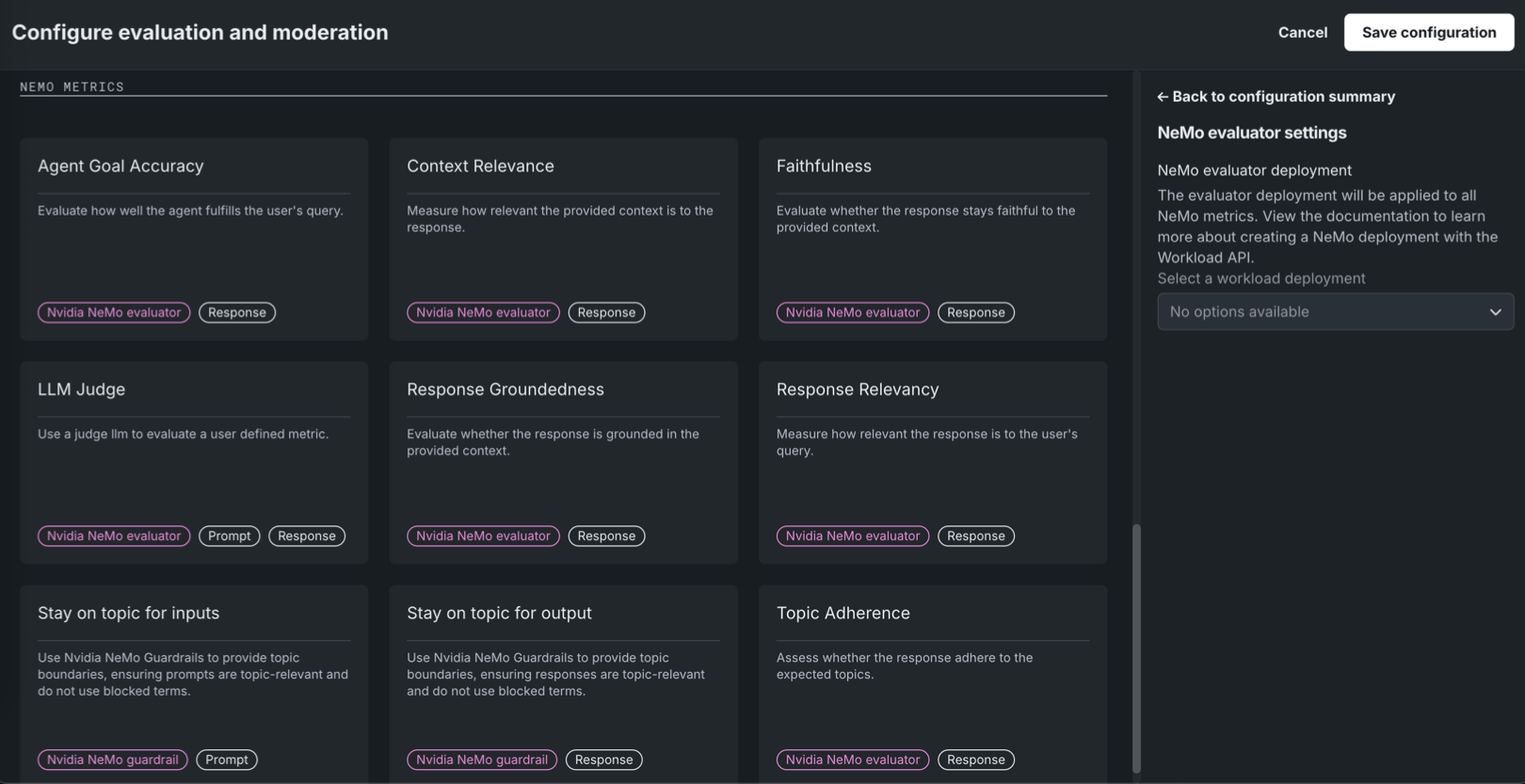
Evaluatorの指標 要件 説明 Agent Goal Accuracy Evaluatorのデプロイ、LLM エージェントがユーザーのクエリーにどの程度応えているかを評価します。 これは、すべての指標(エージェントのワークフロー)に含まれるAgent Goal Accuracyという指標とは異なります。 Context Relevance Evaluatorのデプロイ、LLM 提供されたコンテキストが回答に対してどの程度関連性があるかを測定します。 忠実度 Evaluatorのデプロイ、LLM 指定されたコンテキストに忠実な回答となっているかどうかをNeMo Evaluatorを使用して評価します。 これは、すべての指標に一覧表示されるNeMo以外のFaithfulness指標とは異なります。 LLM Judge Evaluatorのデプロイ、LLM LLMをジャッジとして使用し、ユーザー定義の指標を評価します。 Response Groundedness Evaluatorのデプロイ、LLM 回答が、提供されたコンテキストに基づいているかどうかを評価します。 Response Relevancy Evaluatorのデプロイ、LLM、埋め込みデプロイ 回答がユーザーのクエリーにどの程度関連しているかを測定します。 Topic Adherence Evaluatorのデプロイ、LLM、指標モード、参照トピック 回答が想定されたトピックに沿っているかどうかを評価します。 トピック制御指標 入力のトピックを維持 llama-3.1-nemoguard-8b-topic-controlのNIMデプロイ、NVIDIA NeMo Guardrailsの設定 NVIDIA NeMo Guardrailsを使用してトピックの境界を設定することで、プロンプトがトピックに関連し、禁止用語を使用しないようにします。 出力のトピックを維持 llama-3.1-nemoguard-8b-topic-controlのNIMデプロイ、NVIDIA NeMo Guardrailsの設定 NVIDIA NeMo Guardrailsを使用してトピックの境界を設定することで、回答がトピックに関連し、禁止用語を使用しないようにします。 NeMo Evaluatorの指標で使用されるNeMo Evaluatorのデプロイを設定するには、設定のサマリーサイドバーからNeMo Evaluatorの設定を開きます。 Evaluatorのデプロイは、NeMo Evaluatorのすべての指標に適用されます。 ワークロードデプロイの選択ドロップダウンリストから、NeMo Evaluatorのワークロードデプロイを選択します。
NeMo Evaluatorの設定パネル
Workload APIを使用してNeMo Evaluatorのワークロードとワークロードのデプロイを作成するまで、ドロップダウンには「利用可能なオプションはありません」と表示されます。 NeMo Evaluatorの指標を設定するには、その手順を完了する必要があります。
-
-
上記で選択した指標に応じて、次のフィールドを設定します。
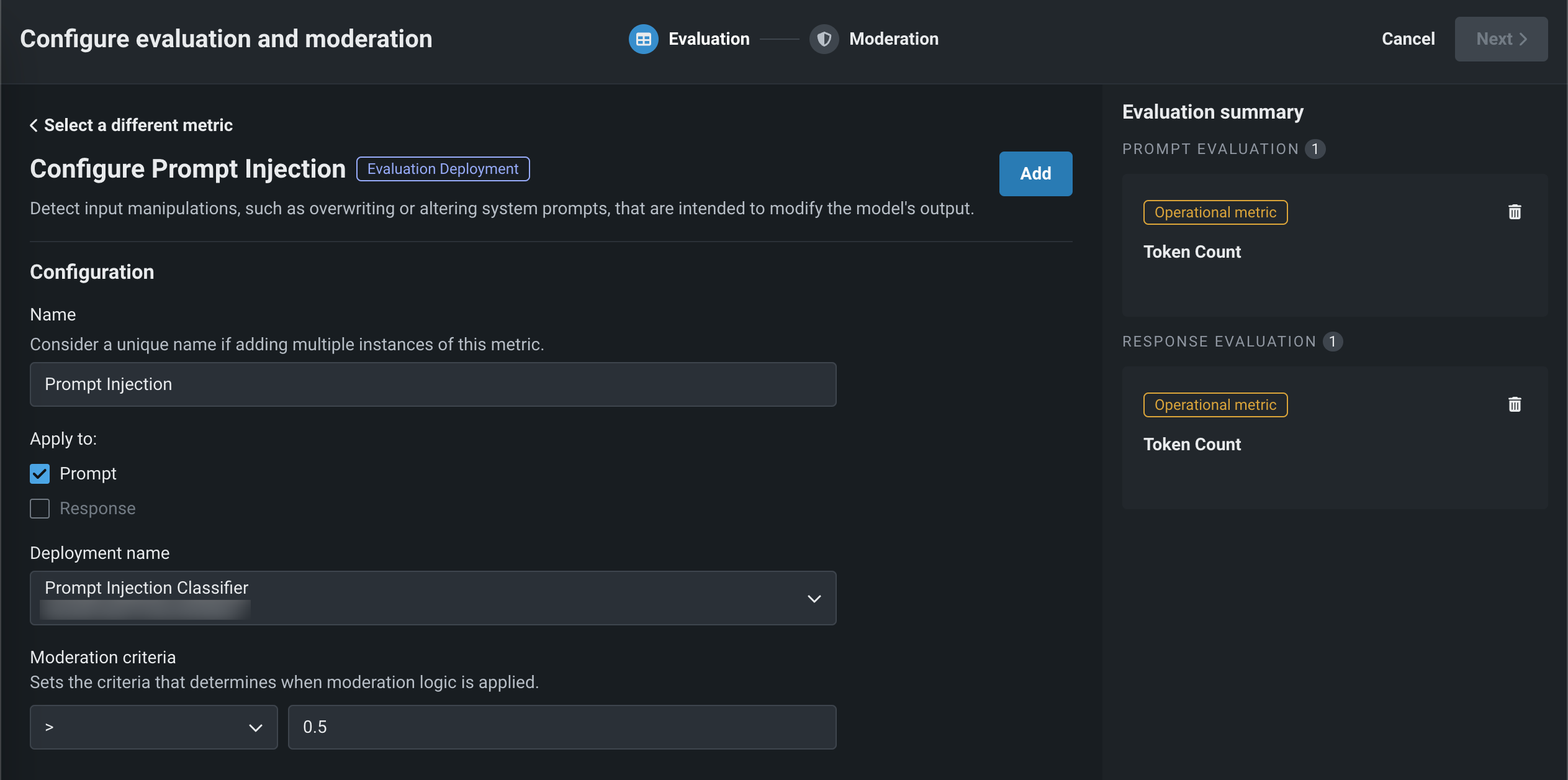
フィールド 説明 全般的な設定 名前 評価指標の複数のインスタンスを追加する場合は、一意の名前を入力します。 適用先 評価指標に応じて、プロンプトと回答のどちらか、または両方を選択します。 プロンプトを選択すると、指標の計算に使用されるのは、最後のLLMプロンプトではなく、ユーザープロンプトであることに注意してください。 このフィールドは、プロンプトと回答の両方に適用される指標に対してのみ設定可能です。 カスタムデプロイ、PII検出、プロンプトインジェクション、感情分類器、毒性設定 デプロイ名 ガードモデルによって計算された評価指標の場合、カスタムモデルデプロイを選択します。 カスタムデプロイの設定 入力列名 この名前は、カスタムモデルの作成者によって定義されます。 DataRobotによって作成されたグローバルモデルの場合、デフォルトの入力列名はtextです。 カスタムデプロイのガードモデルにmoderations.input_column_nameのキー値が定義されている場合、このフィールドには自動的に値が設定されます。 出力列名 この名前はカスタムモデル作成者によって定義され、モデルのターゲット列を参照する必要があります。 ターゲット名は、デプロイの概要タブに表示されます(多くの場合、_PREDICTIONが付加されます)。 カスタムデプロイからCSVデータをエクスポートして表示することで、列名を確認できます。 カスタムデプロイのガードモデルにmoderations.output_column_nameのキー値が定義されている場合、このフィールドには自動的に値が設定されます。 Guideline Adherenceの設定 ガイドライン エージェントの回答が従うべきルールまたは基準。 選択されたLLMは、回答がこのガイドラインに準拠しているかどうかを評価するジャッジとして機能し、true(ガイドラインに従っている)またはfalse(ガイドラインに従っていない)を返します。 この指標の設定時に、ガイドラインを提供し、LLMを(Gatewayまたはデプロイから)選択する必要があります。 Faithfulness、Task Adherence、およびGuideline Adherenceの設定 LLM 選択された指標を評価するLLMを選択します。 忠実度の場合、LLMを選択すると、DataRobotが提供する資格情報ではなく、ユーザー自身が指定した資格情報を使用するオプションがあります。 NeMo Evaluator指標の設定 LLMをジャッジとして選択 選択された指標を評価するLLMを選択します。 Evaluatorのデプロイ NeMo Evaluatorの指標のみ対象です。NeMo Evaluatorの設定サイドバーパネル(ワークロードデプロイの選択)で設定します。 NeMo Evaluatorワークロードのデプロイは、それらの指標で共有されています。 設定を行う前に、Workload APIを使用してワークロードとワークロードのデプロイを作成します。上記の前提条件を参照してください。 トピック制御の設定 LLMタイプ Azure OpenAI、OpenAI、またはNIMを選択します。 LLMのタイプがAzure OpenAIの場合、OpenAI APIのデプロイを追加で入力します。NIMの場合は、NIMのデプロイを入力します。 LLM Gatewayを使用する場合、デフォルトでは、DataRobotが提供する資格情報が指定されます。 LLMのタイプがAzure OpenAIまたはOpenAIの場合、資格情報を変更をクリックして、自身の認証情報を入力します。 ファイル トピックの維持の評価については、ファイルの横にあるをクリックして、NeMoガードレール設定ファイルを変更します。 特に、prompts.ymlを許可されたトピックとブロックされたトピックで、blocked_terms.txtをブロックされた用語で更新し、NeMo Guardrailsに適用するルールを提供します。 blocked_terms.txtファイルは、入力と出力のトピック制御指標間で共有されるため、入力指標のblocked_terms.txtを変更すると出力指標でも変更され、その逆も同様です。 カスタムモデルには、トピック制御指標が2つしか存在できません。1つは入力用、もう1つは出力用です。 モデレーション設定 モデレーションの設定と適用 この設定を有効にすると、モデレーションセクションが展開され、モデレーションロジックが適用されるタイミングを判断する基準を定義できます。 コスト指標の設定
コスト指標では、通貨額/トークン数形式での入力および出力コストを定義し、追加をクリックします。
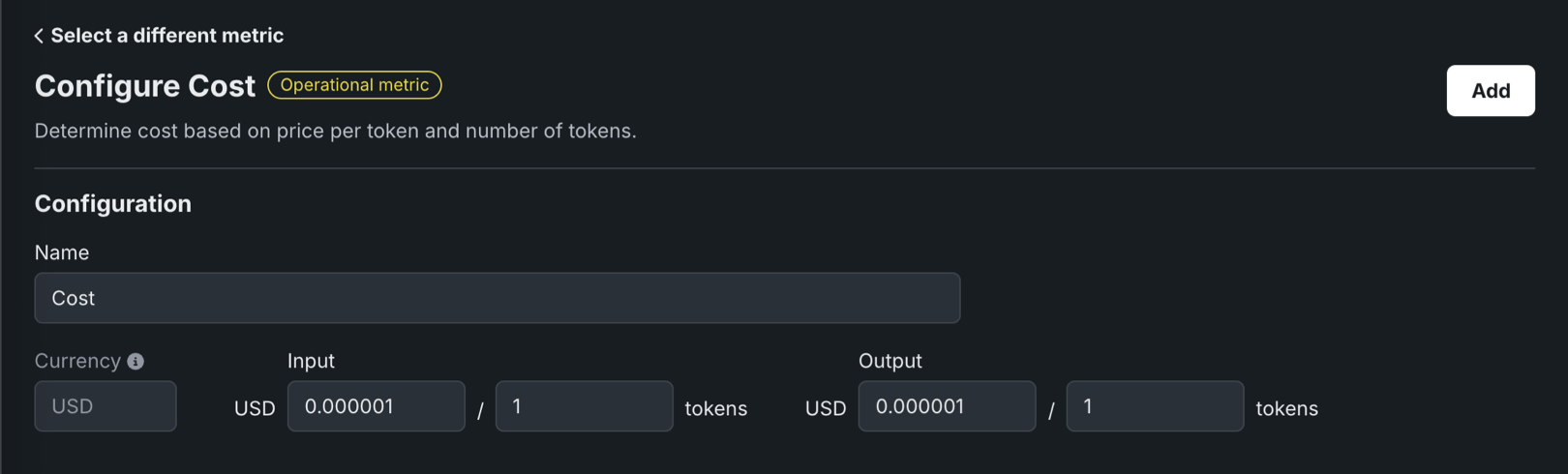
コスト指標には、モデレーションを設定して適用するためのモデレーションセクションが含まれていません。
-
モデレーションセクションで、モデレーションの設定と適用を有効にして、評価指標ごとに以下を設定します。
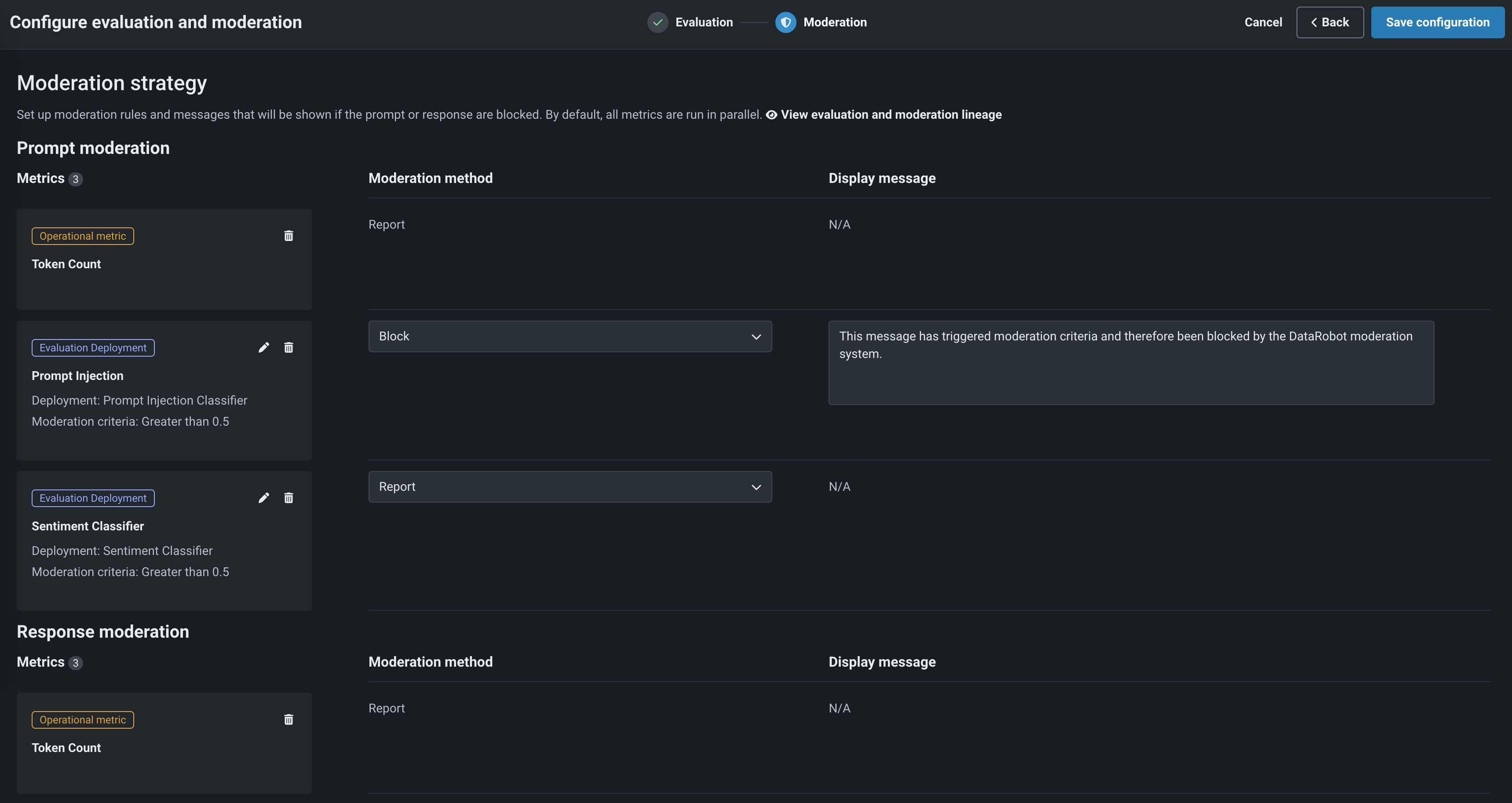
設定 説明 モデレーションの基準 該当する場合、モデレーションロジックをトリガーするために評価されるしきい値を設定します。 数値指標(整数または浮動小数)の場合、より小さい、より大きい、または等しいを任意の値と組み合わせて使用できます。 二値指標(Agent Goal Accuracyなど)の場合、0または1に等しいを使用します。感情分類器の場合、一致または一致しないを選択し、モデレーションロジックをトリガーするクラス(感情)のリストを定義します。 モデレーション方法 レポート、レポートとブロック、または置換(該当する場合)を選択します。 モデレーションのメッセージ レポートとブロックを選択すると、オプションでデフォルトのメッセージを変更できます。 -
必須フィールドを設定した後、追加をクリックして評価を保存し、評価選択ページに戻ります。 次に、別の指標を選択して設定するか、設定を保存をクリックします。
選択したガードレールは、アセンブルタブの評価とモデレーションセクションに表示されます。
テキスト生成カスタムモデルにガードレールを追加した後、モデルを テスト、 登録、および デプロイして本番環境で予測を作成できます。 予測を作成した後、 カスタム指標 タブで評価指標を表示し、 データ探索タブでプロンプト、回答、およびフィードバック(設定されている場合)を表示できます。
「トレース」タブ
LLMデプロイにモデレーションを追加すると、データ探索 > トレースタブでカスタム指標データを行ごとに表示することはできません。
資格情報を変更¶
DataRobotは、LLM Gatewayを使用して、利用可能なLLMの資格情報を提供します。 特定の指標やLLMまたはLLMのタイプによっては、認証に独自の資格情報を使用することも可能です。 続行する前に、資格情報管理ページでユーザー指定の資格情報を定義します。
トピック制御指標¶
入力のトピックを維持または出力のトピックを維持の資格情報を変更するには、LLMタイプを選択し、資格情報を変更をクリックします。
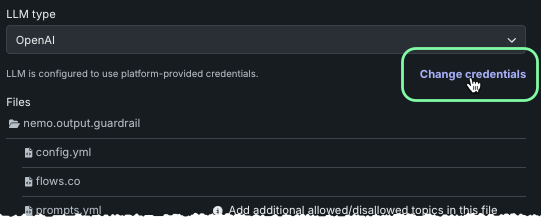
Azure OpenAI APIのデプロイとOpenAI APIのベースURLを指定します。 次に、ドロップダウンから、適用する資格情報のセットを選択します。
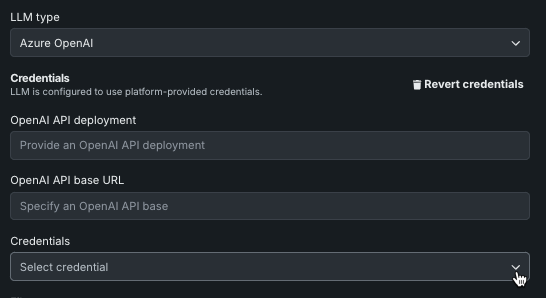
ドロップダウンから、適用する資格情報のセットを選択します。
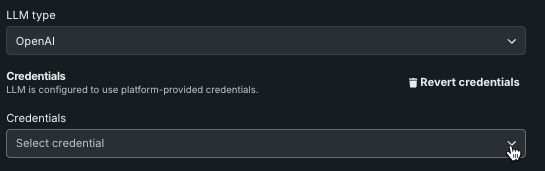
NIMのデプロイ(例:トピック制御モデル)を選択します。 通常、資格情報はデプロイ設定を通じて指定されます。
DataRobotが提供する資格情報に戻すには、資格情報を元に戻すをクリックします。
忠実度の指標¶
忠実度の資格情報を変更するには、LLMを選択し、資格情報を変更をクリックします。
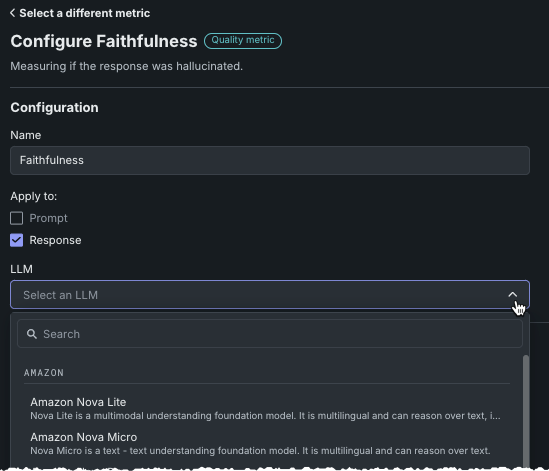
必須フィールドは、次の表のとおりです。
| プロバイダー | フィールド |
|---|---|
| Amazon |
|
| Azure OpenAI |
|
|
|
| OpenAI |
|
DataRobotが提供する資格情報に戻すには、資格情報を元に戻すをクリックします。
NeMo Evaluatorの指標に関する注意事項¶
NeMo Evaluatorの指標を使用する際は、以下の点に注意してください。
- LLMジャッジの出力:NeMo Evaluatorは、LLMジャッジが正しいJSONスキーマでデータを返すことを想定しています。 一部のモデル(たとえば、特定のLlamaのバージョンなど)では、代わりにPythonコードやその他の形式が返されることがあり、その結果、Evaluatorが失敗する可能性があります。 期待される形式を確実に返すLLMジャッジを選択します。多くの場合、新しいモデルの方がJSON出力の指示に従うことができます。
- レートとトークン数の制限:NeMo Evaluatorガードを使用する際は、レートの制限とトークン数の制限に注意してください。これらの上限に達すると、評価が失敗する可能性があります。
アクティビティログ > モデレーションタブとEvaluatorのログを使用して、リクエストがブロックされた理由やガードが失敗した理由をデバッグできます。
評価指標デプロイのグローバルモデル¶
PII検出、プロンプトインジェクション検出、感情分類、毒性分類に必要なデプロイは、レジストリのグローバルモデルとして使用できます。 次のグローバルモデルを使用できます。
| モデル | タイプ | ターゲット | 説明 |
|---|---|---|---|
| プロンプトインジェクション分類器 | 二値 | テキストをプロンプトインジェクションまたは正当なものとして分類します。 このガードモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 deberta-v3-base-injectionモデルの詳細を参照してください。 |
|
| 毒性分類器 | 二値 | テキストを有毒か無毒に分類します。 このガードモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 toxic-comment-modelの詳細を参照してください。 |
|
| センチメント分類器 | 二値 | テキストのセンチメントを肯定的か否定的に分類します。 このモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 distilbert-base-uncased-finetuned-sst-2-englishモデルの詳細を参照してください。 |
|
| 感情分類器 | 多クラス | テキストを感情で分類します。 これは多ラベルモデルです。つまり、複数の感情をテキストに適用できます。 このモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 roberta-base-go_emotions-onnxモデルの詳細を参照してください。 |
|
| 拒否スコア | 連続値 | プロンプトがモデルに設定されている回答範囲を超えているために、LLMがクエリーへの回答を拒否したケースのリストと、入力を比較して、最大類似度スコアを出力します。 | |
| PresidioのPII検出 | 二値 | テキスト内の個人を特定できる情報(PII)を検出して置き換えます。 このガードモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 必要に応じて、検出するPIIのタイプをコンマ区切りの文字列として列'entities'に指定できます。 この列が指定されていない場合は、サポートされているすべてのエンティティが検出されます。 エンティティのタイプは、PresidioがサポートするPIIエンティティのドキュメントに記載されています。 検出結果に加えて、モデルは anonymized_text列を返します。この列には、検出されたPIIがプレースホルダーに置き換えられた更新バージョンの入力が含まれています。 詳細については、Presidio: Data Protection and De-identification SDKのドキュメントを参照してください。 |
|
| ゼロショット分類器 | 二値 | ユーザー指定のラベルを持つテキストに対してゼロショット分類を実行します。 このモデルでは、textという名前の列に分類されたテキストが必要であり、labelsという名前の列にコンマ区切りの文字列としてクラスラベルが必要です。 すべての行に同じラベルセットが必要であるため、最初の行にあるラベルが使用されます。 詳しくは、 deberta-v3-large-zeroshot-v1モデルの詳細を参照してください。 |
|
| Pythonダミー二値分類 | 二値 | Positiveクラスでは、常に0.75となります。 詳しくは、 python3_dummy_binaryモデルの詳細を参照してください。 |
評価およびモデレーションガードレールの表示¶
ガードレールを含むテキスト生成モデルが登録およびデプロイされると、 登録済みモデルの概要タブと デプロイの概要タブで設定済みのガードレールを表示できます。
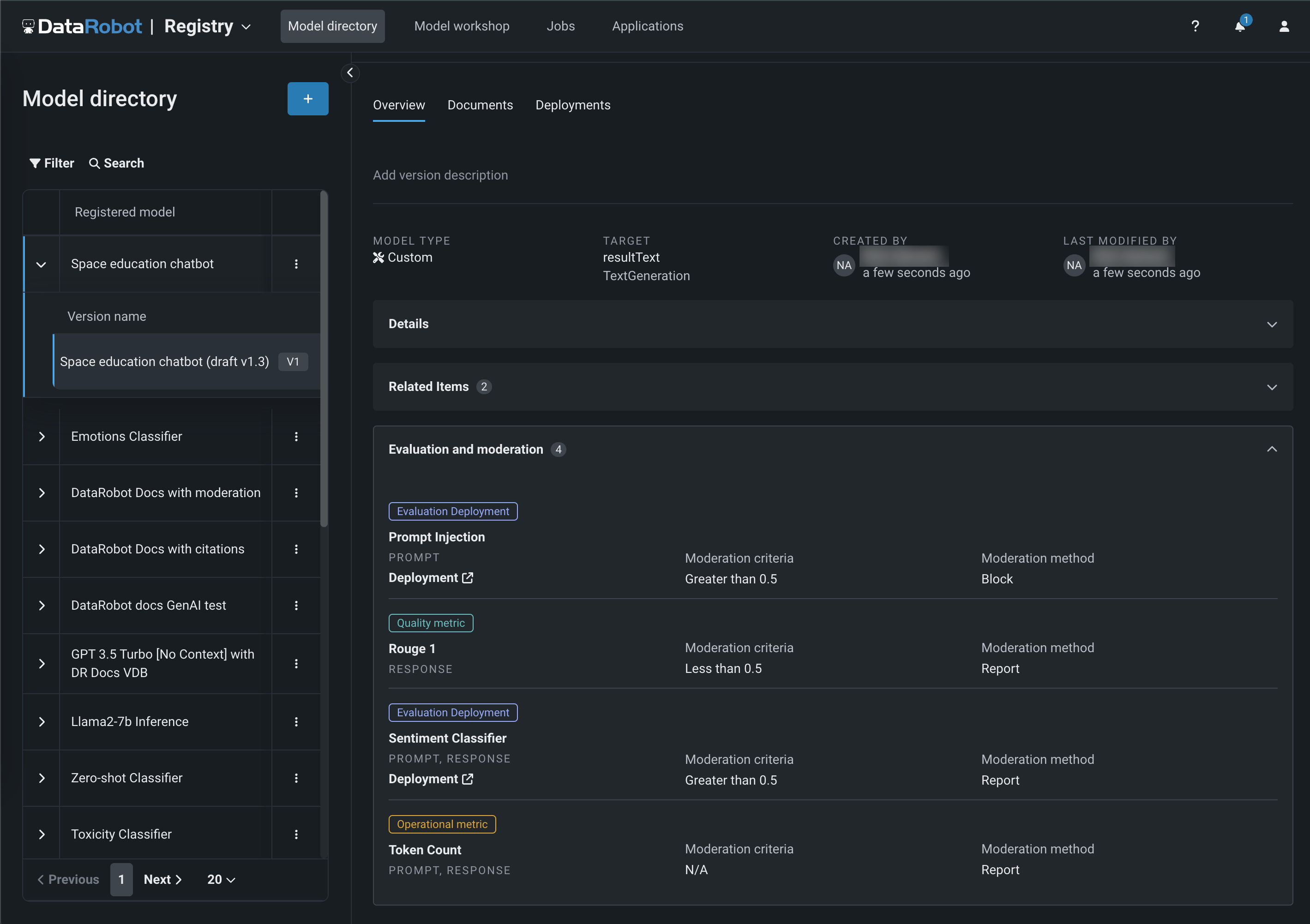
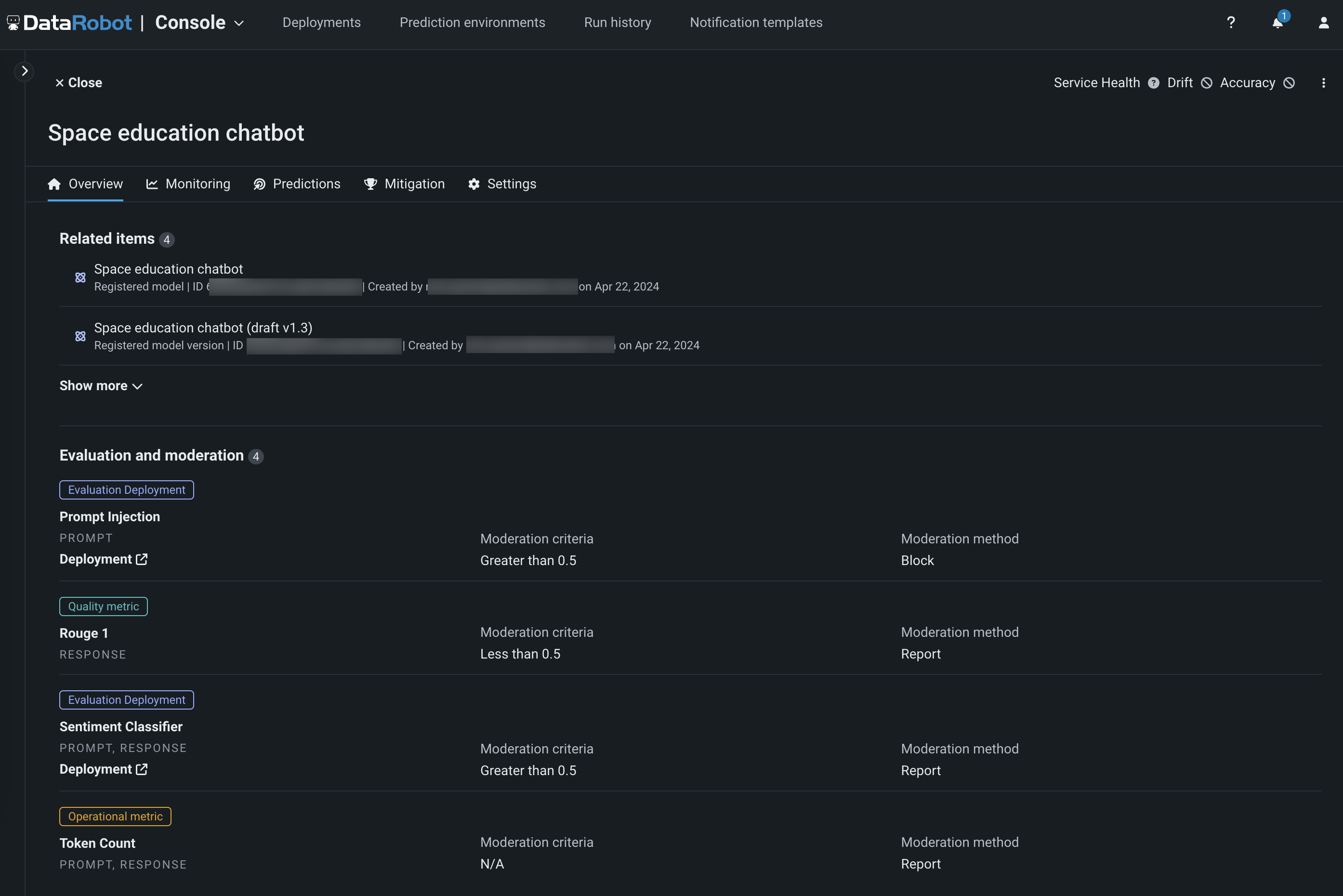
評価とモデレーションのログ
評価とモデレーションが設定されたデプロイ済みLLMのアクティビティログ > モデレーションタブで、デプロイの評価とモデレーションに関連するイベントの履歴を表示して、デプロイに設定された評価やモデレーションに関する問題を診断できます。