カスタムモデルの作成¶
カスタムモデルは、ユーザーが作成した事前トレーニング済みのモデルであり、ワークショップを通じてDataRobotに(ファイル群として)アップロードできます。 カスタムモデルは、以下のうちいずれかの方法で構築できます。
-
アセンブルタブで、環境要件と
start_server.shファイル なし でカスタムモデルを作成します。 このタイプのカスタムモデルはドロップイン環境を使用する必要があります。 ドロップイン環境には、モデルで使用される要件とstart_server.shファイルが含まれます。 これらはワークショップ内のDataRobotによって提供されます。 -
アセンブルタブで、環境要件と
start_server.shファイル あり でカスタムモデルを作成します。 このタイプのカスタムモデルは、カスタムまたはドロップイン環境と組み合わせることができます。
作業を続ける前に、 カスタムモデルの構築に関するガイドラインを確認してください。 カスタムモデルと環境フォルダーの間でファイルが重複している場合は、モデルのファイルが優先されます。
カスタムモデルのテスト
カスタムモデルのファイルコンテンツを組み立てると、DataRobotにアップロードする前に開発目的でローカルでコンテンツをテストできます。 ワークショップでカスタムモデルを作成した後、テストタブからテストスイートを実行できます。
新しいカスタムモデルの作成¶
構築の準備としてカスタムモデルを作成するには:
-
レジストリ > ワークショップをクリックします。 このタブには、作成したモデルが一覧表示されます。
-
Click one of the following options (or the button when the custom model panel is open), depending on the currently selected tab:
-
From the All models tab, click + Add a model to open the Add a model panel without a Target type selected.
-
From the Agentic workflows tab, click + Add a workflow to open the Add a workflow panel with the Target type set to Agentic Workflow.
-
From the Tools tab, click + Add a tool to open the Add a tool panel with the Target type set to MCP Server.
-
-
モデルを追加ページで、モデルを設定のフィールドに入力します。
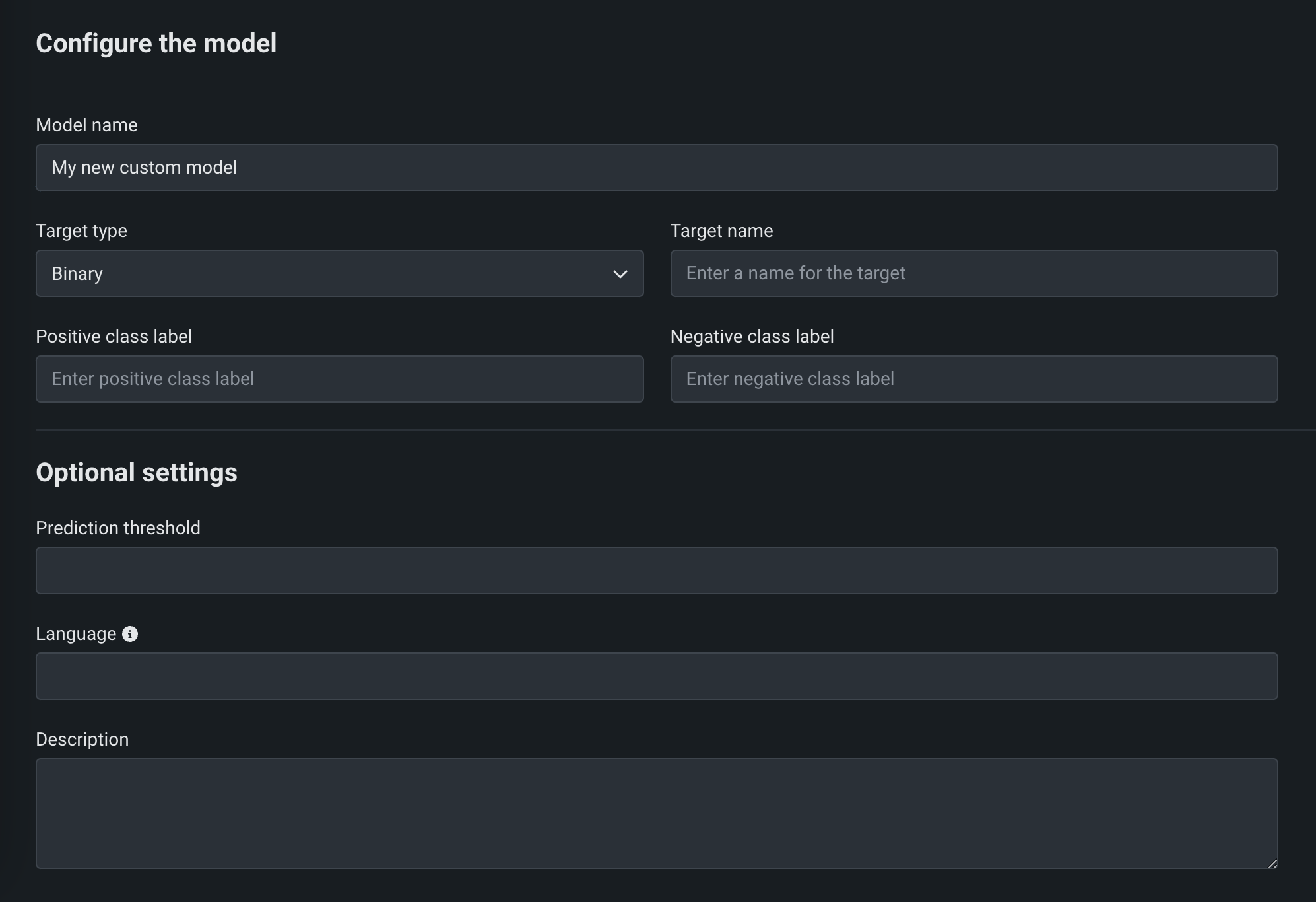
フィールド 説明 モデルタイプ 作成するカスタムモデルのタイプ、標準のカスタムモデル、または外部モデルのプロキシ。 モデル名 カスタムモデルのわかりやすい名前。 ターゲットタイプ モデルが行っている予測のタイプ。 予測タイプに応じて、追加の設定を行う必要があります。 - 二値:二値分類モデルの場合は、PositiveクラスラベルとNegativeクラスラベルを入力します。 次に、必要に応じて予測しきい値を入力します。
- 連続値:追加設定なし。
- 時系列(二値):プレビュー機能。 二値分類モデルの場合は、PositiveクラスラベルとNegativeクラスラベルを入力し、時系列設定を行います。 次に、必要に応じて予測しきい値を入力します。
- 時系列(連続値):プレビュー機能 Configure the 時系列設定を行います。
- 多クラス:多クラス分類モデルでは、ターゲットのターゲットクラスを1行に1クラスずつ入力またはアップロード(
.csv、.txt)します。 クラスがモデルの予測に正しく適用されるように、モデルが予測したクラスの確率と同じ順序でクラスを入力してください。 - 多ラベル:多ラベル分類モデルでは、ターゲットのターゲットラベルを1行に1ラベルずつ入力またはアップロード(
.csv、.txt)します。 ラベルがモデルの予測に正しく適用されるように、モデルが予測したラベルの確率と同じ順序でラベルを入力してください。 - テキスト生成:プレミアム機能。 追加設定なし。
- 異常検知:追加設定なし。
- 非構造化:追加設定なし。 非構造化モデルは、特定の入力/出力スキーマに準拠する必要はなく、異なる要求形式を使用する可能性があります。 「非構造化」ターゲットタイプのデプロイでは、予測ドリフト、精度追跡、チャレンジャー、および信頼性が無効になります。 サービスの正常性、デプロイアクティビティ、ガバナンスは引き続き利用できます。
- ベクターデータベース:プレビュー機能 追加設定はありません。
- 位置:プレミアム機能。 追加設定はありません。
- エージェントのワークフロー:プレミアム機能。 追加設定はありません。
- MCPサーバー:プレミアム機能。 追加設定なし。 MCPサーバーは、DataRobot APIをエージェントが利用できるツールとして公開するためのツールです。
ターゲット名 モデルが予測するデータセット列。 多クラスや多ラベルなど、ターゲット列を使用するターゲットタイプに(それぞれターゲットクラスまたはターゲットラベルとともに)必要です。 多クラスおよび多ラベルモデルの場合、同じ列名が inferenceModel.targetNameの下のmodel-metadata.yamlに属し、クラスまたはラベル名がinferenceModel.classLabelsに属します。 このフィールドは、異常検知モデルには使用されません。オプション設定 予測しきい値 二値分類モデルの場合、0から1までの10進数値です。この値を超える予測スコアは、すべてPositiveクラスに割り当てられます。 言語 モデルの構築に使用されるプログラミング言語。 説明 モデルのコンテンツと目的の説明。 ターゲットタイプでのプロキシモデルのサポート
プロキシモデルタイプを選択した場合、非構造化ターゲットタイプは選択できません。
Premium
ベクターデータベースのデプロイはプレミアム機能で、デフォルトではオフになっており、GenAIのエクスペリメントが必要です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
プレミアム機能
エージェントのワークフローはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
-
フィールドに入力したら、モデルを追加をクリックします。
カスタムモデルがアセンブルタブで開きます。
時系列の設定¶
プレビュー
時系列カスタムモデルは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:時系列のカスタムモデルを有効にする、カスタムモデルの予測で特徴量のフィルターを有効にする
二値分類および連続値モデルに必要なフィールドに加え、以下の時系列固有のフィールドを設定することによって時系列カスタムモデルを作成できます。 時系列カスタムモデルを作成するには、ターゲットタイプとして時系列(二値)または時系列(連続値)を選択し、モデルの作成中に次の設定を行います。
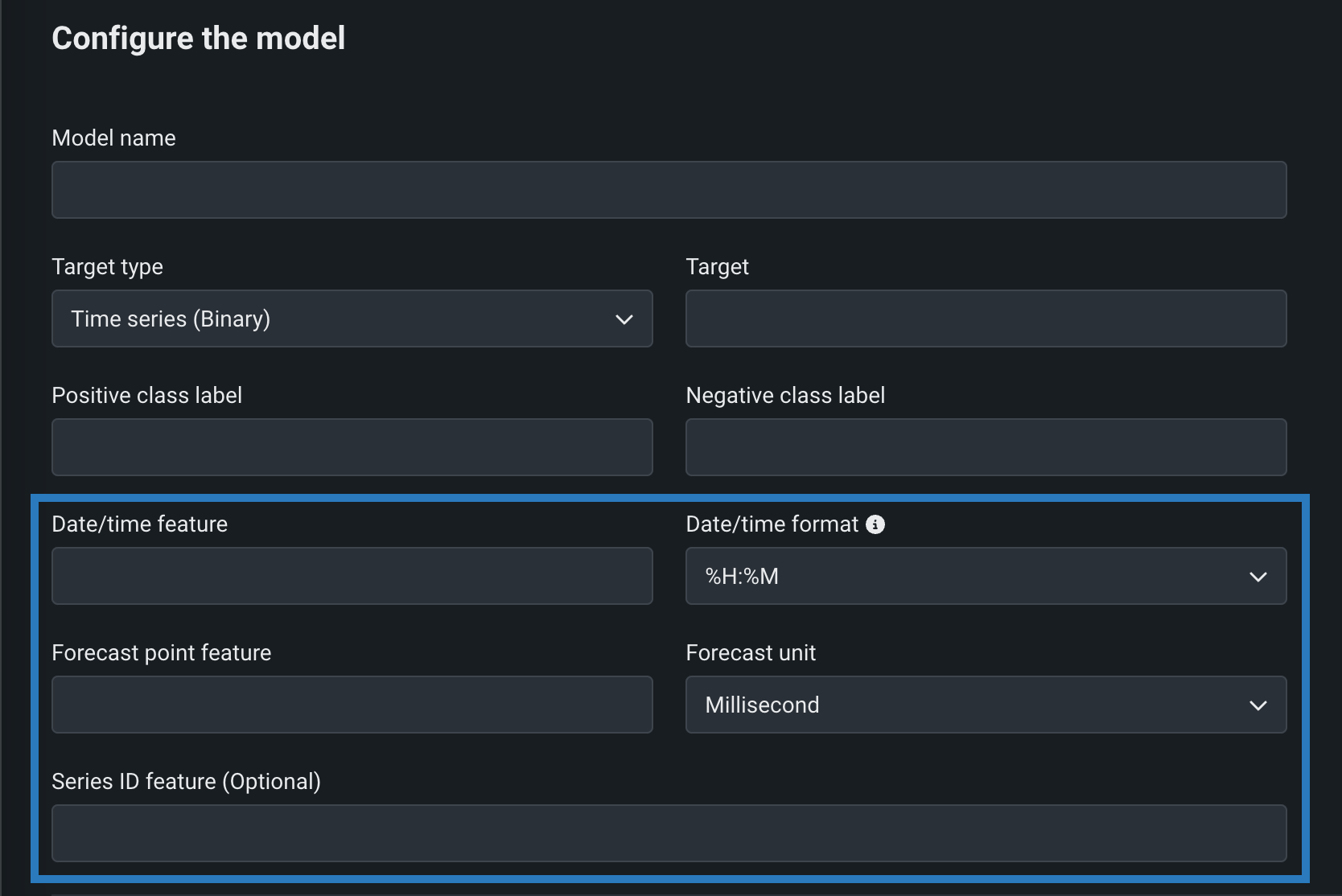
| フィールド | 説明 |
|---|---|
| 日付/時刻特徴量 | 指定された予測行の日付/時刻値を含むトレーニングデータセット内にある列。 |
| 日付/時刻形式 | 日付/時刻特徴量列と予測ポイント特徴量列の両方における値の形式。GNU Cライブラリ形式で使用可能なすべての値のドロップダウンリストとして提供されます。 |
| 予測ポイントの特徴量 | 予測の作成に使用する ポイントを含む、トレーニングデータセット内にある列。 |
| 予測単位 | 時間ステップで使用する時間単位(秒、日、月など)。使用可能なすべての値のドロップダウンリストとして提供されます。 |
| 系列ID特徴量 | オプション。 複数系列モデルの場合、各行が属する系列を識別するトレーニングデータセット内にある列を入力します。 |
時系列カスタムモデルで リアルタイム予測を行う場合、予測回答のCSVシリアル化では、モデルから返される追加の列(予測結果以外)には、サフィックス_OUTPUTを含む列名が付けられます。
時系列カスタムモデルに関する注意事項
時系列カスタムモデルの制約を以下に示します。
-
チャレンジャーとして選択することはできません。
-
カスタムモデルのテスト中は、モデルの起動テストのみがサポートされます。
-
バッチ予測ではなく、 リアルタイム予測をサポートします。
-
ポータブル予測サーバー(PPS)はサポートしていません。
カスタムモデルの構築¶
カスタムモデルを作成した後、必要な環境、依存関係、ファイルを指定できます。
-
構築するモデルで、アセンブルタブの環境セクションに移動し、基本環境ドロップダウンメニューからモデル環境を選択します。
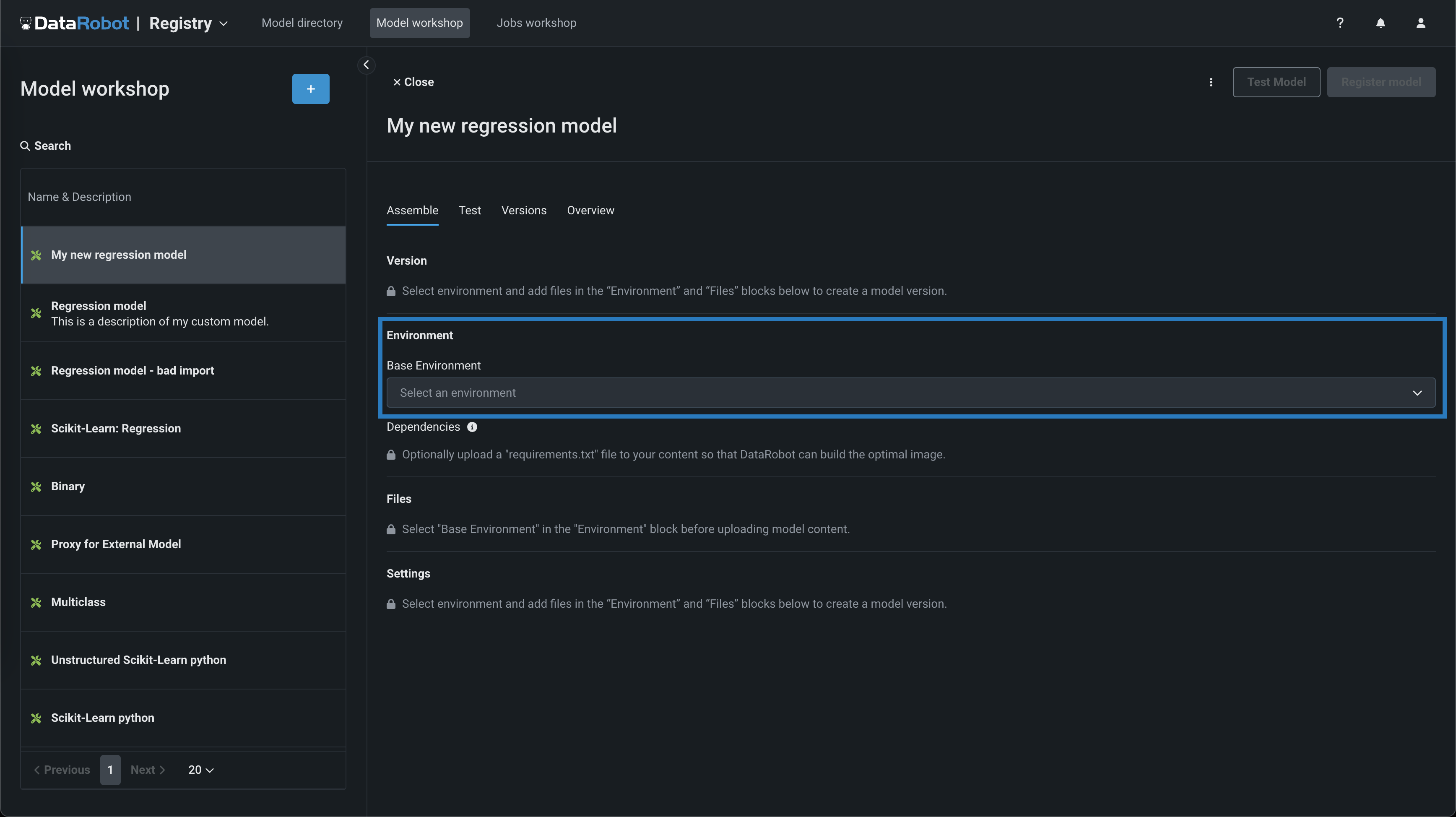
モデル環境
モデル環境は、カスタムモデルのテストとデプロイに使用されます。 基本環境ドロップダウンリストには、 ドロップインモデル環境と、作成可能な カスタム環境が含まれています。 デフォルトでは、カスタムモデルは、正常に構築され、選択された環境の最新バージョンを使用します。
-
依存関係セクションに入力するために、ファイルセクションで
requirements.txtファイルをアップロードし、DataRobotが最適なイメージを構築できるようにします。 -
ファイルセクションで、必要なカスタムモデルファイルを追加します。 モデルと ドロップイン環境をペアリングしていない場合、これにはカスタムモデル環境要件と
start_server.shファイルが含まれます。 ファイルの追加方法はいくつかあります。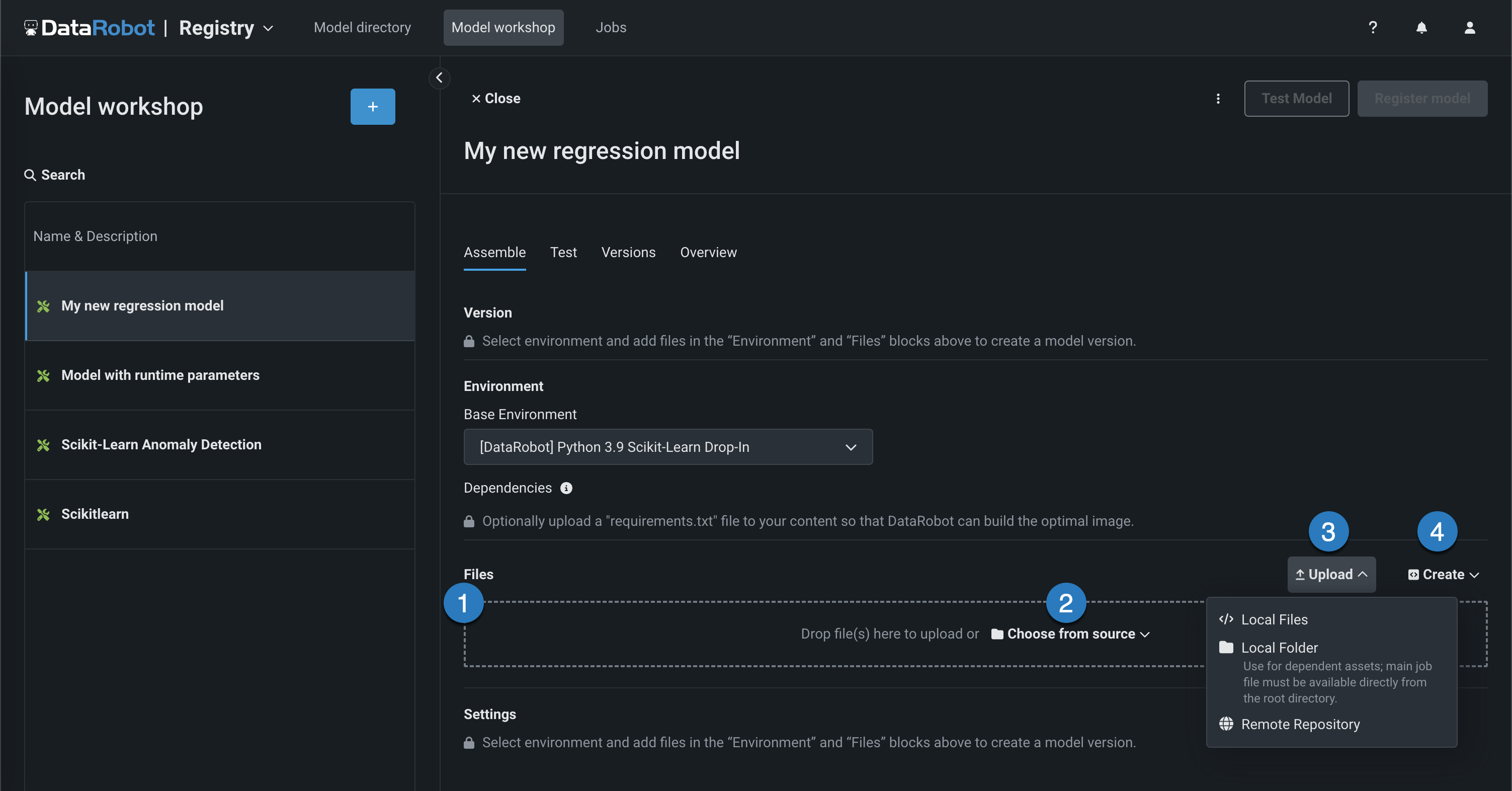
要素 説明 1 ファイル ファイルをグループボックスにドラッグしてアップロードします。 2 ソースから選択 クリックしてローカルファイルまたはローカルフォルダーを参照します。 リモートリポジトリからファイルをプルするには、 アップロードメニューを使用します。 3 アップロード クリックしてローカルファイルまたはローカルフォルダーを参照するか、 リモートリポジトリからファイルをプルします。 4 作成 新しいファイルを作成し(空のファイルでもテンプレートでもかまいません)、それをカスタムモデルに保存します。 - model-metadata.yamlを作成:このモデルのターゲットタイプにスターターファイル
model-metadata.yamlを作成します(二値、多クラス、および多ラベルに必要なinferenceModelフィールドを含みます)。 同じファイルにruntimeParameterDefinitionsを追加できます。 - 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
モデルファイルの場所
ローカルフォルダーからファイルを追加する場合は、モデルファイルがすでにカスタムモデルのルートにあることを確認してください。 アップロードされたフォルダーは、モデル自体ではなく、モデルに必要な依存ファイルおよび追加のアセット用です。 モデルファイルがフォルダーに含まれている場合でも、ファイルがルートレベルに存在しない限り、DataRobotからモデルファイルにアクセスすることはできません。 ルートにあるファイルは、フォルダー内の依存関係を指定することができます。
- model-metadata.yamlを作成:このモデルのターゲットタイプにスターターファイル
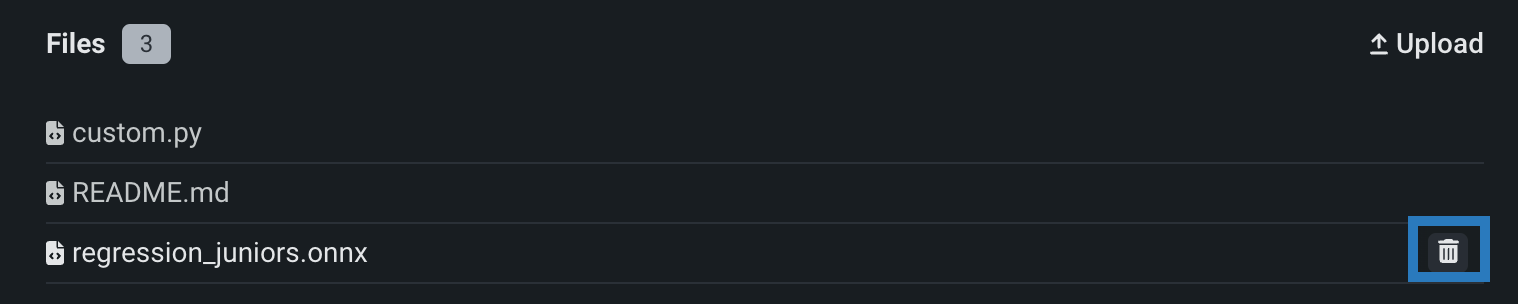
アセンブルタブのファイルセクションで1つ以上のファイルまたはフォルダーを誤って追加した場合は、各ファイルまたはフォルダーの横にある削除()アイコンをクリックして、カスタムモデルから削除できます。
リモートリポジトリに接続する¶
ファイルセクションで、 アップロード > リモートリポジトリをクリックすると、リモートリポジトリからコンテンツを追加パネルが開きます。 リモートリポジトリをクリックして、 新しいリモートリポジトリを登録(A)するか、既存のリモートリポジトリを選択(B)できます。
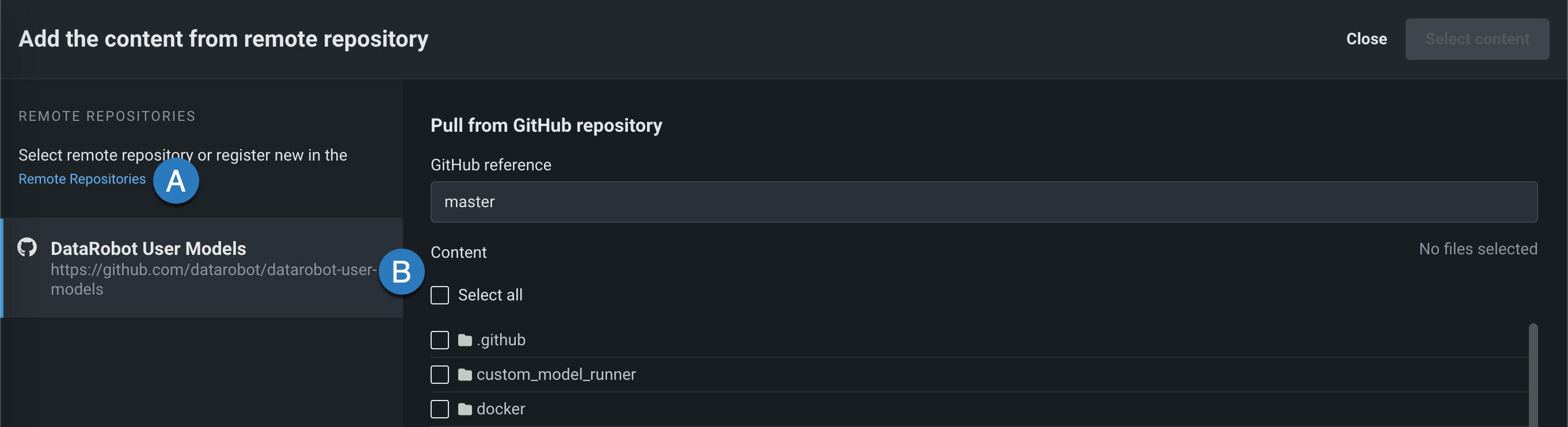
リポジトリを登録して選択した後、アップロードする各ファイルまたはフォルダーのチェックボックスを選択して、コンテンツを選択するをクリックします。
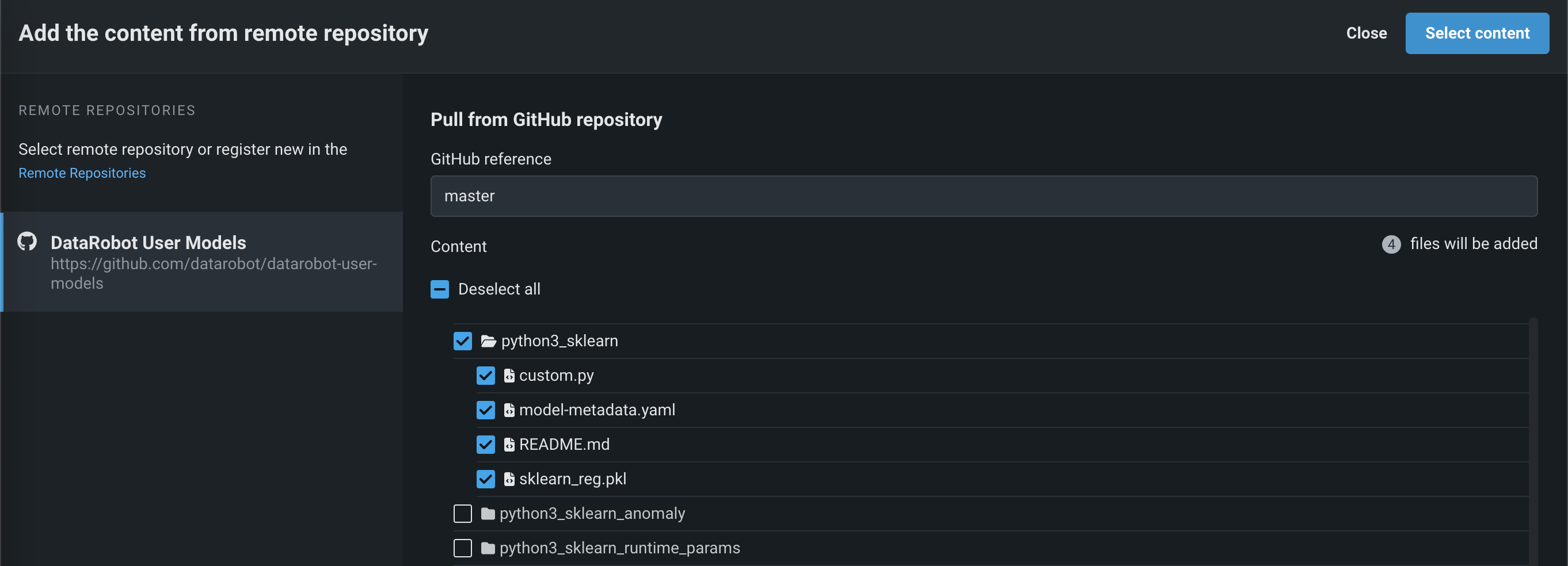
選択したファイルがファイルセクションに入れられます。
ドロップイン環境¶
DataRobotでは、必要なライブラリを定義し、start_server.shファイルを提供するためのドロップイン環境がワークショップに用意されています。 ワークショップのアセンブルタブの環境セクションでは、各環境の名前の先頭に[DataRobot]が付いています。
利用可能なドロップイン環境はDataRobotのインストール形態によって異なりますが、一般的に利用可能なパブリックドロップイン環境とDRUMリポジトリのテンプレートを以下の表に示します。 DataRobotのインストール形態によっては、これらの環境のPythonバージョンが異なる場合があり、さらに非公開の環境が利用できる場合もあります。
ドロップイン環境のセキュリティ
2025年3月にリリースされたマネージドAIプラットフォームから、ほとんどの汎用DataRobotカスタムモデルのドロップイン環境は、セキュリティが強化されたコンテナイメージになりました。 カスタムジョブの実行にセキュリティが強化された環境が必要な場合、POSIX-shell標準に準拠したシェルコードのみがサポートされます。 POSIXシェル標準に準拠したセキュリティ強化環境では、限られたシェルユーティリティのみがサポートされています。
ドロップイン環境のセキュリティ
セルフマネージドAIプラットフォームのリリース11.0から、ほとんどの汎用DataRobotカスタムモデルのドロップイン環境は、セキュリティが強化されたコンテナイメージになりました。 カスタムジョブの実行にセキュリティが強化された環境が必要な場合、POSIX-shell標準に準拠したシェルコードのみがサポートされます。 POSIXシェル標準に準拠したセキュリティ強化環境では、限られたシェルユーティリティのみがサポートされています。
| 環境名と例 | 互換性とアーティファクトファイルの拡張子 |
|---|---|
| Python 3.X | Pythonベースのカスタムモデルとジョブ。 モデルファイルにrequirements.txtファイルを含めることで、必要な依存関係をすべてインストールしてください。 |
| Python 3.X GenAIエージェント | 生成AIモデル(Text GenerationまたはVector Databaseのターゲットタイプ) |
| Python 3.X ONNXドロップイン | ONNXモデルとジョブ(.onnx) |
| Python 3.X PMMLドロップイン | PMMLモデルとジョブ(.pmml) |
| Python 3.X PyTorchドロップイン | PyTorchモデルとジョブ(.pth) |
| Python 3.X Scikit-Learnドロップイン | Scikit-Learnモデルとジョブ(.pkl) |
| Python 3.X XGBoostドロップイン | ネイティブXGBoostモデルとジョブ(.pkl) |
| Python 3.X Kerasドロップイン | TensorFlow(.h5)がサポートするKerasモデルとジョブ |
| Javaドロップイン | DataRobotスコアリングコードモデル(.jar) |
| ドロップイン環境 | CARET(.rds)を使ってトレーニングされたRモデルCARETが推奨するすべてのライブラリをインストールするのに時間がかかるため、パッケージ名でもあるモデルタイプのみがインストールされます(例: brnn、glmnet)。 この環境のコピーを作成し、Dockerfileを修正して、必要なパッケージを追加でインストールします。 この環境をカスタマイズする際のビルド回数を減らすために、# Install caret modelsセクションで不要な行を削除して、必要なものだけをインストールすることもできます。 CARETドキュメントを参照して、モデルの手法がパッケージ名と一致しているかどうかを確認してください。 このリンクをクリックする前にGitHubにログインしてください。 |
scikit-learn
すべてのPython環境には、(必要に応じて)前処理を支援するscikit-learnが含まれていますが、sklearnモデルで予測を行うことができるのはscikit-learnだけです。
ドロップイン環境を使用する場合、カスタムモデルコードは、 DataRobotクライアントと MLOps Connected Clientへのアクセスを容易にするために挿入された複数の環境変数を参照できます。
| 環境変数 | 説明 |
|---|---|
MLOPS_DEPLOYMENT_ID |
カスタムモデルがデプロイモードで実行されている場合(カスタムモデルがデプロイされている場合)、デプロイIDを使用できます。 |
DATAROBOT_ENDPOINT |
カスタムモデルに パブリックネットワークアクセスがある場合、DataRobotエンドポイントURLを使用できます。 |
DATAROBOT_API_TOKEN |
カスタムモデルに パブリックネットワークアクセスがある場合、DataRobot APIトークンを使用できます。 |
評価とモデレーションを設定¶
プレミアム機能
評価およびモデレーションガードレールはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:モデレーションのガードレールを有効にする(プレミアム)、モデルレジストリでグローバルモデルを有効にする(プレミアム)、予測応答で追加のカスタムモデル出力を有効にする
評価とモデレーションのガードレールは、組織がプロンプトインジェクションや、悪意のある、有害な、または不適切なプロンプトや回答をブロックするのに役立ちます。 また、ハルシネーションや信頼性の低い回答を防ぎ、より一般的には、モデルをトピックに沿った状態に保つこともできます。 さらに、これらのガードレールは、個人を特定できる情報(PII)の共有を防ぐことができます。 多くの評価およびモデレーションガードレールは、デプロイされたテキスト生成モデル(LLM)をデプロイされたガードモデルに接続します。 これらのガードモデルはLLMのプロンプトと回答について予測し、これらの予測と統計を中心的なLLMデプロイに報告します。 評価とモデレーションのガードレールを使用するには、まず、LLMのプロンプトや回答について予測するガードモデルを作成してデプロイします。たとえば、ガードモデルは、プロンプトインジェクションや有害な回答を識別することができます。 次に、ターゲットタイプがテキスト生成のカスタムモデルを作成する場合、評価とモデレーションのガードレールを1つ以上定義します。
評価およびモデレーションガードレールを選択および設定するには、テキスト生成ターゲットタイプのカスタムモデルのアセンブルタブで、評価とモデレーションまでスクロールして、 設定をクリックします。
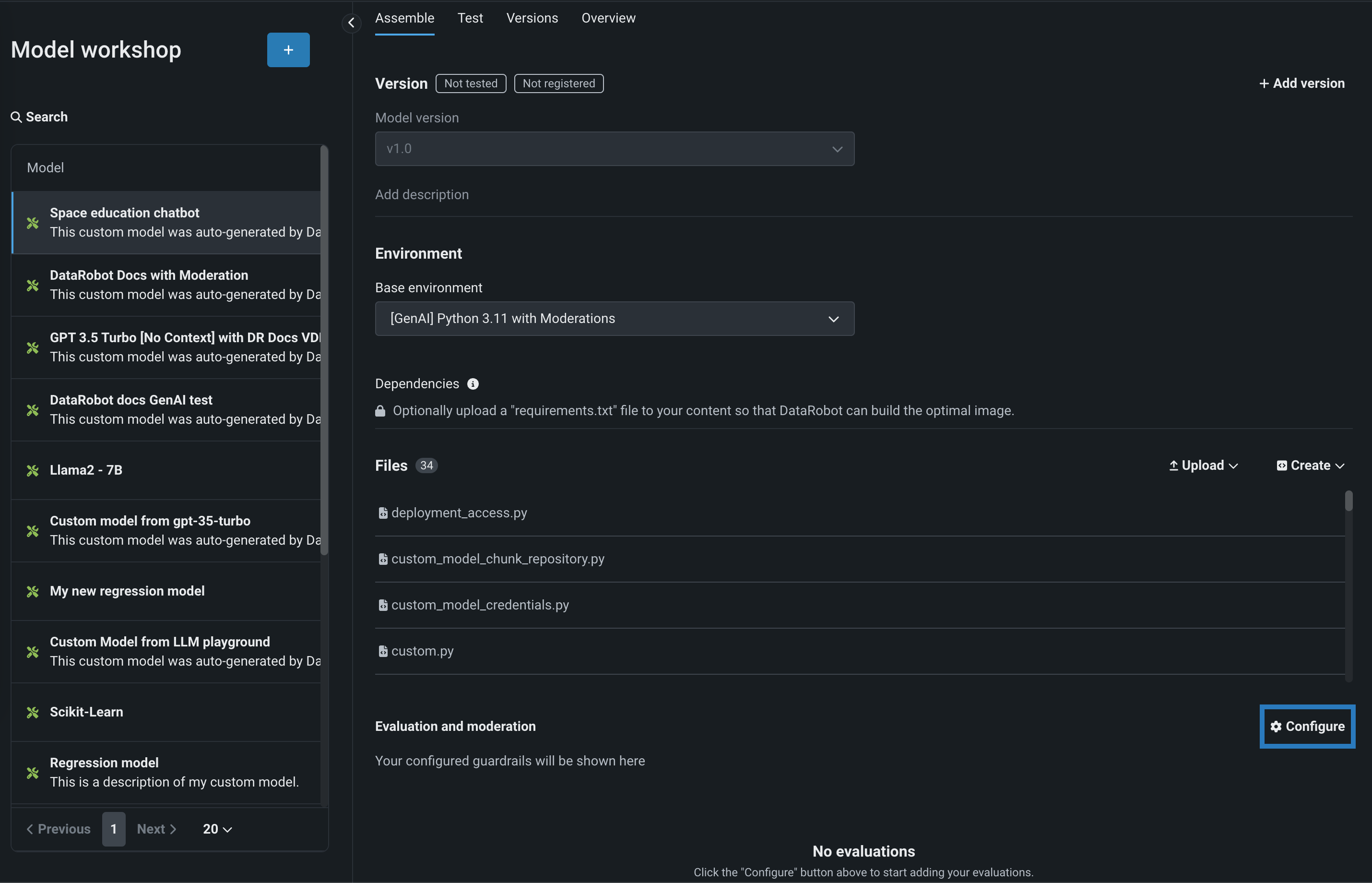
評価とモデレーションの設定パネルで、指標カードをクリックして、評価指標に必要な設定を行います。
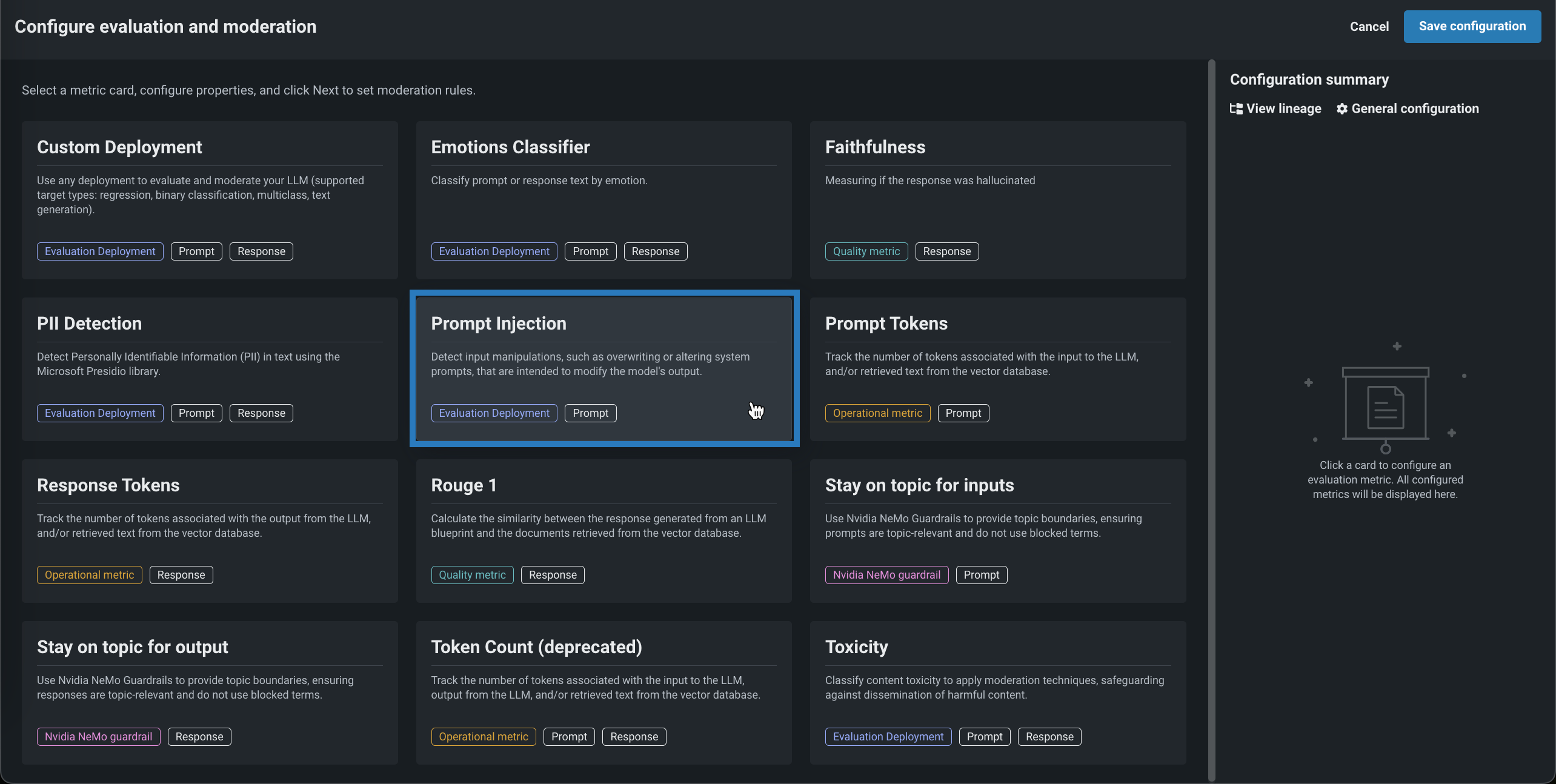
指標をガードとして使用を有効にした場合、モデレーションセクションで、モデレーション設定を行います。
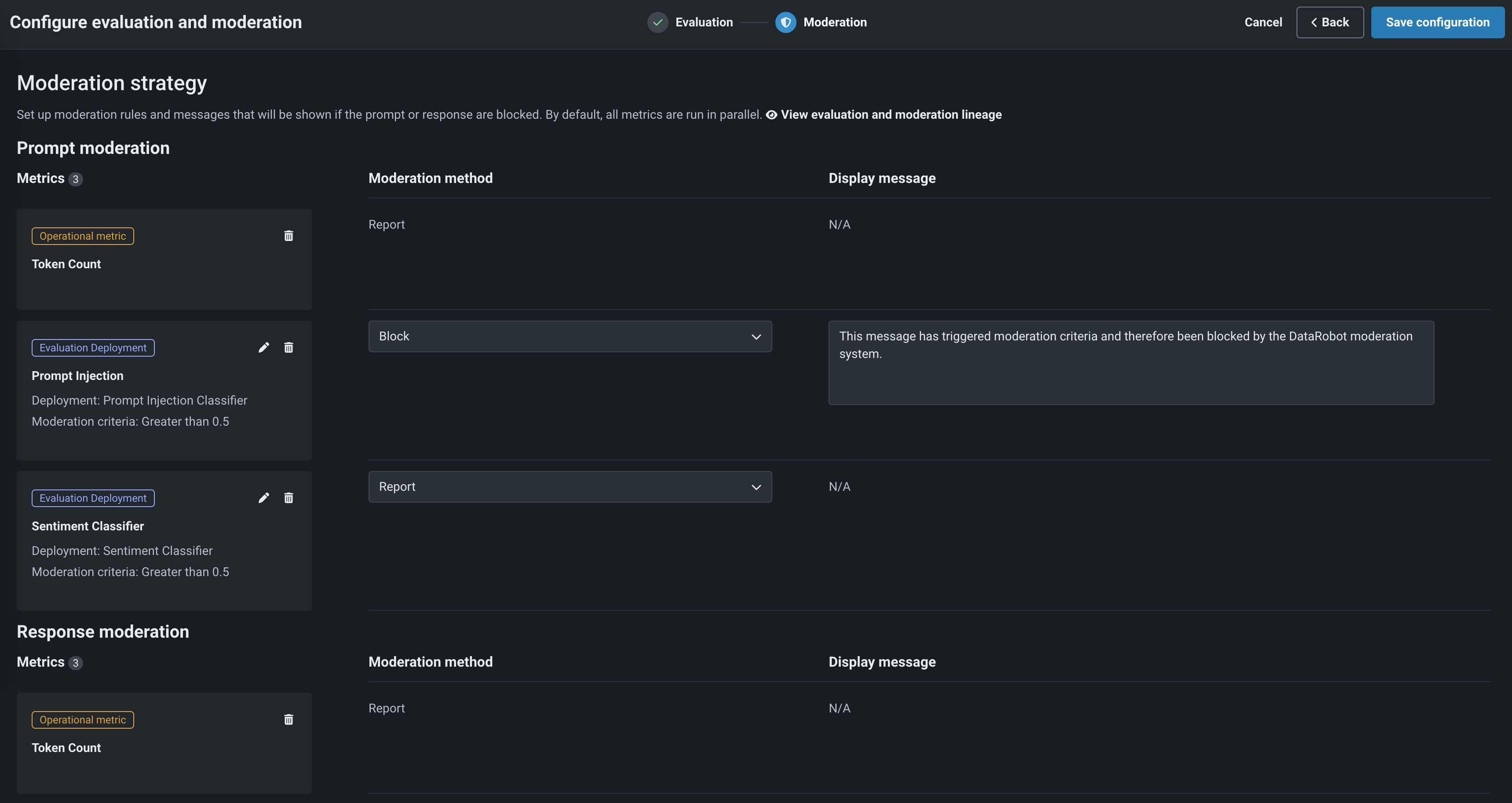
次に、追加をクリックして、評価選択ページに戻ります。 そこから、別の指標を追加するか、設定を保存をクリックします。
詳細については、 評価とモデレーションの設定を参照してください。
テキスト生成カスタムモデルにガードレールを追加した後、モデルを テスト、 登録、および デプロイして本番環境で予測を作成できます。 予測を作成した後、 カスタム指標 タブで評価指標を表示し、 データ探索タブでプロンプト、回答、およびフィードバック(設定されている場合)を表示できます。
ランタイムパラメーターの定義¶
ランタイムパラメーターセクションで、実行時にモデルに環境変数を提供するランタイムパラメーターを作成します。 さらに、model-metadata.yamlファイルのruntimeParameterDefinitionsを使用してランタイムパラメーターを定義した場合は、ここで管理できます。 パラメーターは、次の2つの方法でコンテナに挿入されます。
- 単純な型の場合、プレフィックスやJSONの解析を伴わない標準の環境変数として挿入されます(そのため、
datarobot-drumライブラリを使用せずにos.getenvで環境変数にアクセスできます)。 - 下位互換性を確保するため、従来のプレフィックス付き(
MLOPS_RUNTIME_PARAM_*)およびJSON形式でも挿入されます。
UIを通じて作成されたパラメーターは、新しいコードバージョンをアップロードする際にも保持およびマージされ、シームレスな開発フローが確保されます。
ランタイムパラメーターに関する注意事項
システムでは、動的設定で管理される予約済みパターンのブロックリスト(例:DRUM_*、MLOPS_*、KUBERNETES_*)が使用されます。 一致判定では、*ワイルドカードがサポートされています(完全な正規表現構文はサポートされていません)。 予約名は完全にはブロックされません。ランタイムパラメーターで予約名が使用されている場合、UIに警告が表示されます。 変数がどのように公開されるかは、コンテキストによって異なります。
- カスタムモデル:システムの競合を防ぐために、未加工の(プレフィックスが付かない)環境変数としてではなく、 プレフィックス付き(
MLOPS_RUNTIME_PARAM_*)およびJSON形式のみ。 - カスタムアプリ:プレフィックスは付きますが、値はJSONペイロードに格納されません(資格情報を除く)。
- カスタムジョブ:プレフィックスもJSONペイロードもありません(資格情報タイプを除く)。この変数は、未加工の環境変数として使用できます。
資格情報タイプのランタイムパラメーターの場合、システムはJSONフィールドを単一の文字列ではなく、個別の環境変数として自動的に展開します。 たとえば、次のようなJSON構造を持つMAIN_AWS_CREDENTIALという名前の資格情報があります。
{"awsAccessKeyId": "<your-key-id>", "awsSecretAccessKey": "<your-access-key>"}
パラメーター名とJSONキーを組み合わせ、大文字にして、以下の環境変数に展開されます。
MAIN_AWS_CREDENTIAL_AWS_ACCESS_KEY_ID="<your-key-id>"
MAIN_AWS_CREDENTIAL_AWS_SECRET_ACCESS_KEY="<your-access-key>"
単一フィールドの資格情報タイプ(たとえば、api_token、bearer、または gcp)の場合、挿入される環境変数には、パラメーター名に資格情報のフィールド名を組み合わせた形式(たとえば、MY_CRED_API_TOKEN)ではなく、ランタイムパラメーター名そのもの(MY_CRED)が使用されます。 複数フィールド JSONエンコードされたランタイムパラメーター変数(例:MLOPS_RUNTIME_PARAMETERS_OPEN_AI_API)は変更されません。単一フィールドのシークレットにおけるフラット変数のみが、パラメーター名そのものを使用します。
コンテナ内のランタイムパラメーターへのアクセス
コンテナ内のランタイムパラメーターにプログラムでアクセスするには、SDK APIリファレンスに記載されているように、DataRobotAppFrameworkBaseSettingsを使用します。
パラメーターを追加する¶
新しいランタイムパラメーター定義を追加するには、+ ランタイムパラメーターを追加をクリックします。
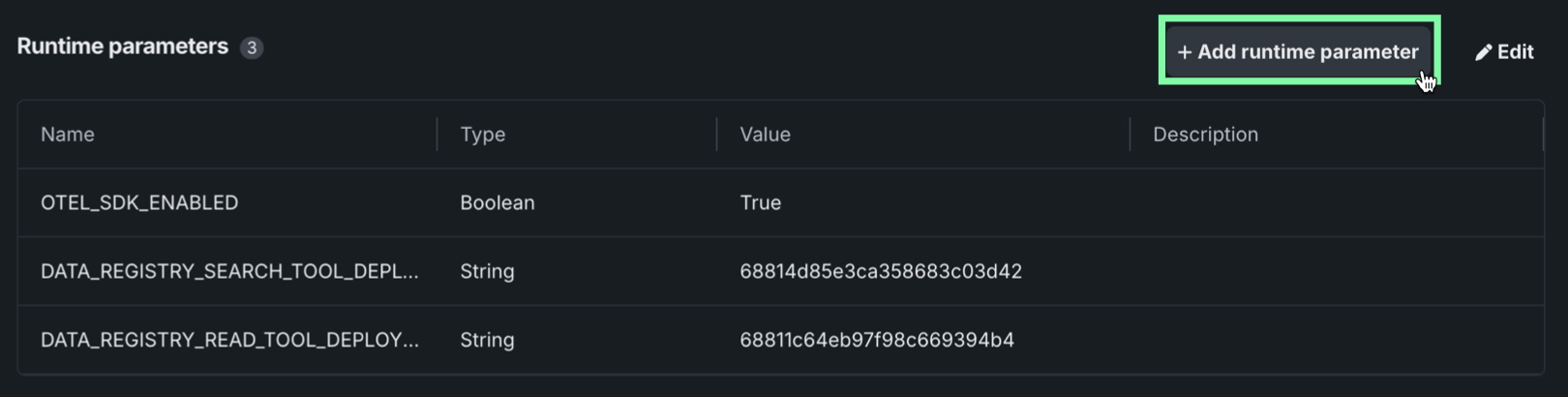
新しいランタイムパラメーターを追加ダイアログボックスで、ランタイムパラメーターの名前、タイプ、値を設定し、必要に応じて説明を入力します。
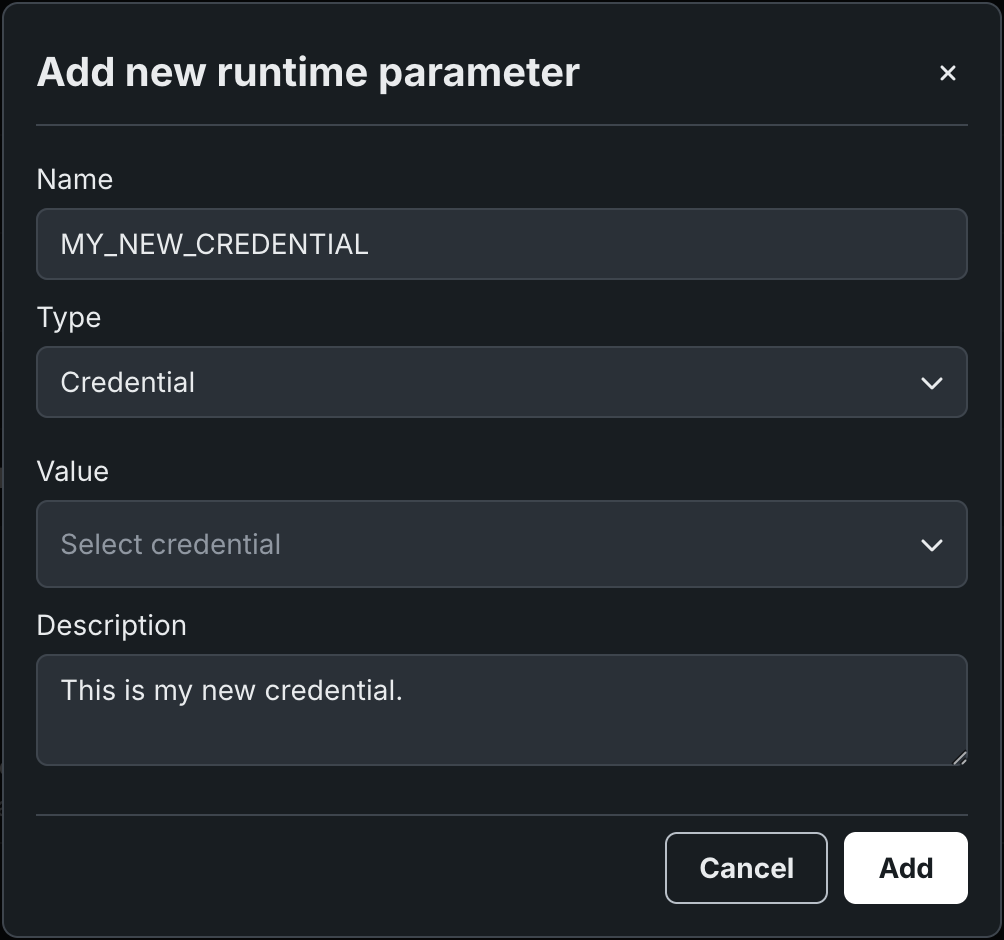
必須フィールドを設定したら、追加をクリックし、追加のパラメーターがある場合は同じ手順を繰り返してから、保存をクリックします。
パラメーターの編集¶
ランタイムパラメーターの定義を編集するには、 編集をクリックします。
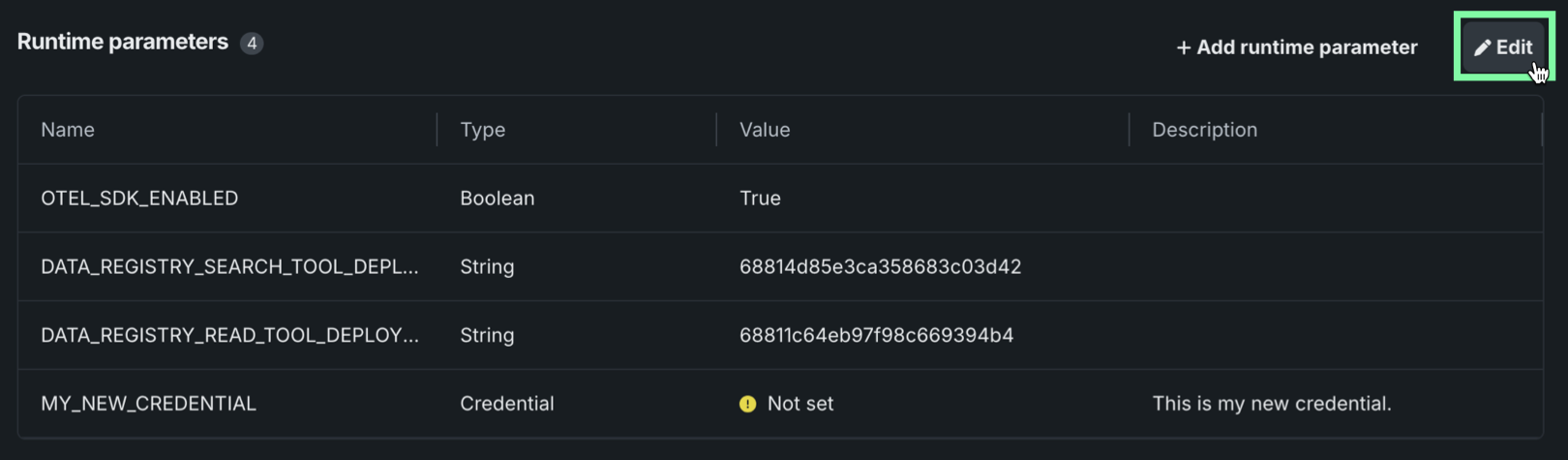
ランタイムパラメーターテーブルで、ランタイムパラメーターの値を定義するか、最後の列でアクションアイコンにアクセスします。
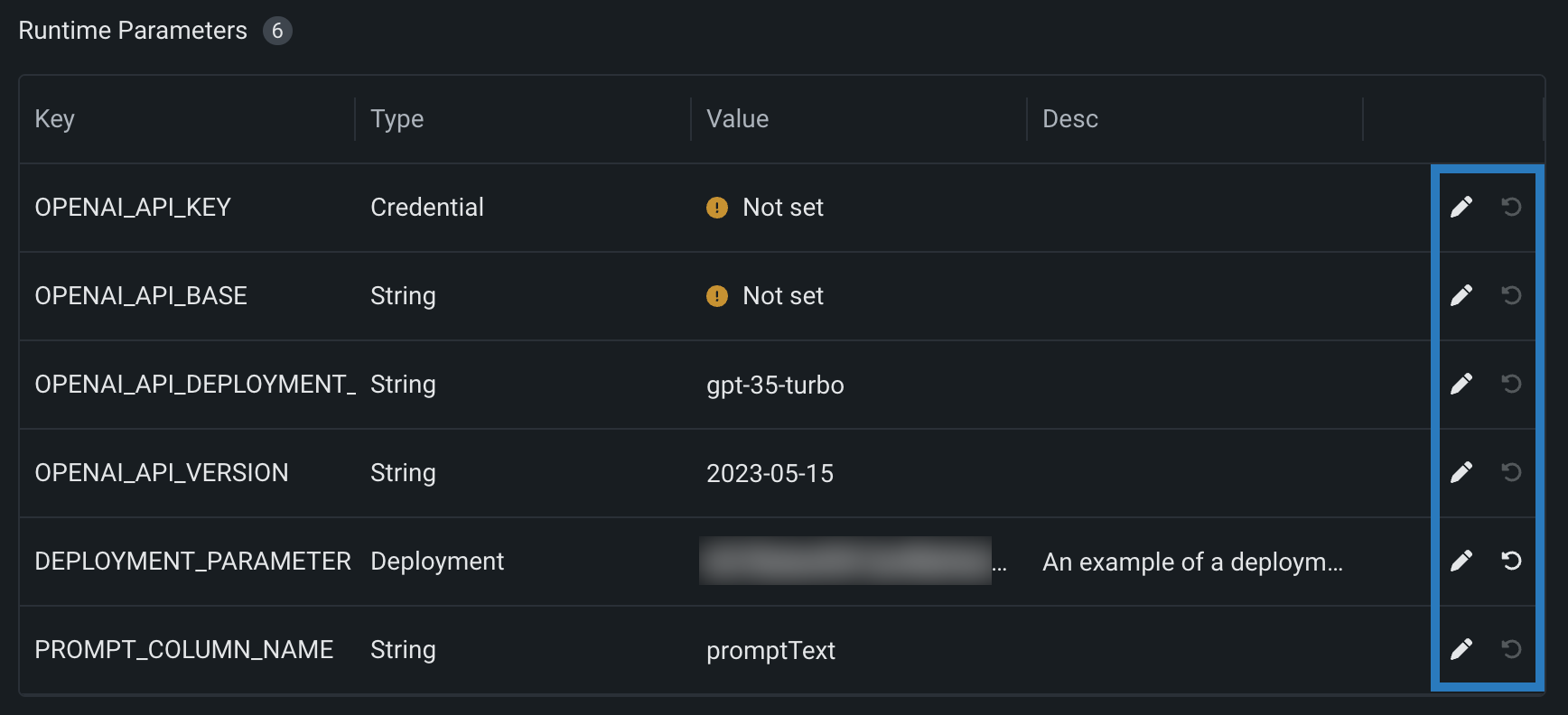
| アイコン | 設定 | 説明 |
|---|---|---|
| 変更を元に戻す | ランタイムパラメーターの値をmodel-metadata.yamlファイルで設定されたdefaultValueまたは空の状態にリセットします。 |
|
| 削除 | ランタイムパラメーターの定義を削除します。 |
defaultValueのない定義で、ランタイムパラメーターにallowEmpty: falseがある場合は、カスタムモデルを登録する前に値を設定する必要があります。
プレミアム:DataRobot LLM Gatewayへのアクセス
ターゲットタイプがエージェントのワークフローであるカスタムモデルでLLM Gatewayを使用するには、model-metadata.yamlファイルにENABLE_LLM_GATEWAY_INFERENCEランタイムパラメーターを指定し、trueに設定する必要があります。
ランタイムパラメーターを定義し、カスタムモデルコードで使用する方法の詳細については、カスタムモデルのランタイムパラメーターを定義するのドキュメントを参照してください。
カスタムモデルデータセットの割り当て¶
モデルデプロイで特徴量ドリフト追跡を有効にするには、トレーニングデータを追加する必要があります。 これを行うには、モデルのバージョンにトレーニングデータを割り当てます。 非構造化カスタム推論モデルのトレーニングデータセットとホールドアウトデータセットを指定する方法では、トレーニングデータセットとホールドアウトデータセットを個別にアップロードする必要があります。 さらに、これらのデータセットにはパーティション列を含めることはできません。
ファイルサイズに関する注意
DataRobotにアップロードされるカスタムモデルトレーニングデータのファイルサイズの上限は1.5GBです。
トレーニングデータの予測行数に関する注意事項
カスタムモデルにアップロードされたトレーニングデータは、特徴量のインパクト、ドリフトベースライン、および予測の説明プレビューを計算するために使用されます。 これらの計算を行うために、DataRobotでは、アップロードされたトレーニングデータが60/20/20の比率でトレーニング用、検定用、ホールドアウト用(すなわち、T/V/H)のパーティションに自動的に分割されます。 あるいは、トレーニングデータセットにパーティション列を手動で指定することで、予測を行ごとにトレーニング(T)、検定(V)、またはホールドアウト(H)のパーティションに割り当てることもできます。
予測の説明には、検定パーティションに100行が必要です。独自のパーティショニングを定義しない場合、提供されるトレーニングデータセットには最小でも500行を含める必要があります。 トレーニングデータとパーティションの比率(自動または手動で定義)により、検定パーティションに100行未満しか含まれない場合、予測の説明は計算されません。 モデルの登録およびデプロイは可能であり、デプロイされたモデルで予測を行うこともできますが、説明付きの予測をリクエストした場合、デプロイはエラーを返します。
環境とファイルを定義した後にカスタムモデルにトレーニングデータを割り当てるには:
-
アセンブルタブの設定セクションのデータセットの下:
-
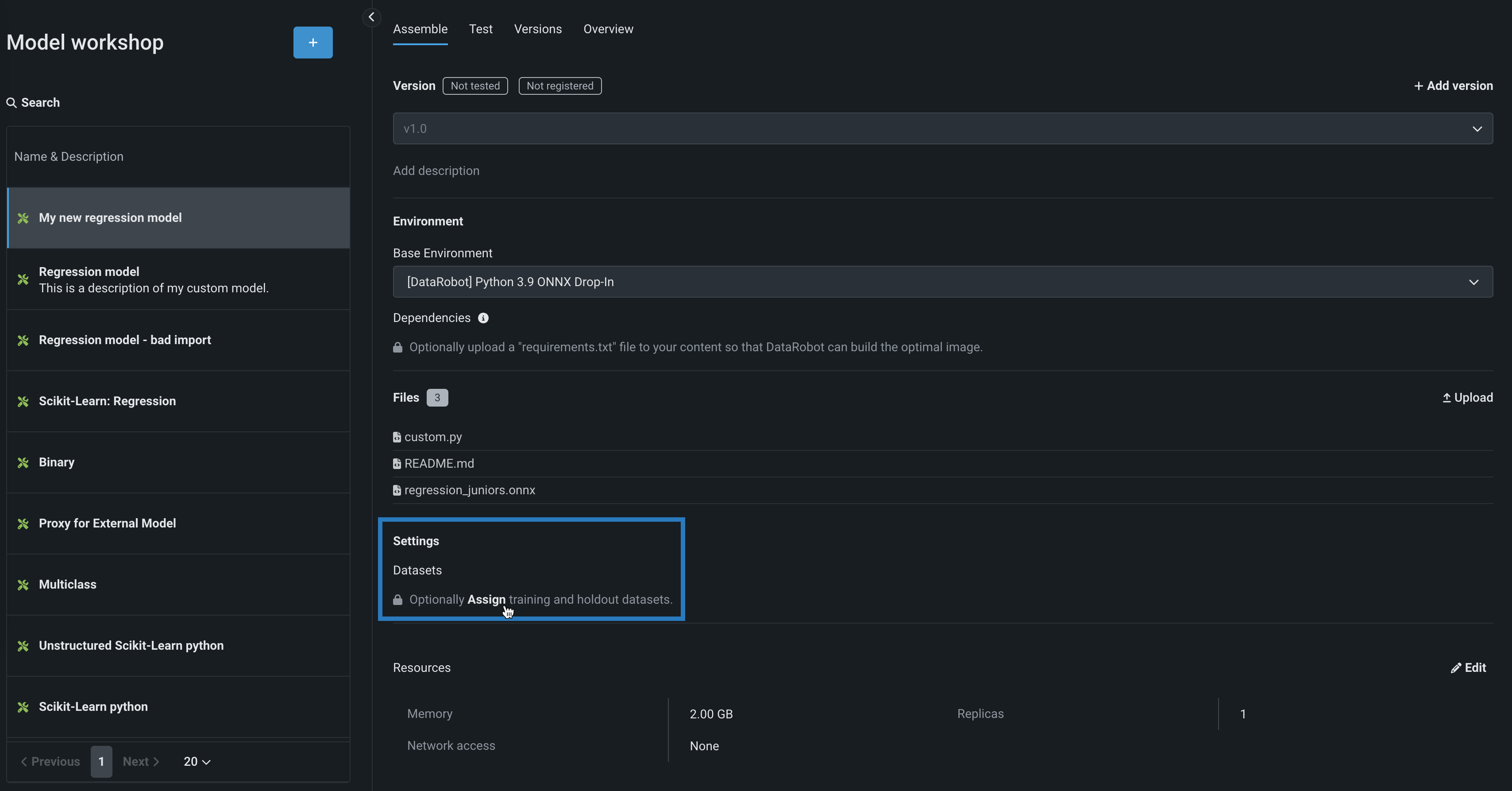
モデルのバージョンにトレーニングデータが割り当てられていない場合は、割り当てるをクリックします。
-
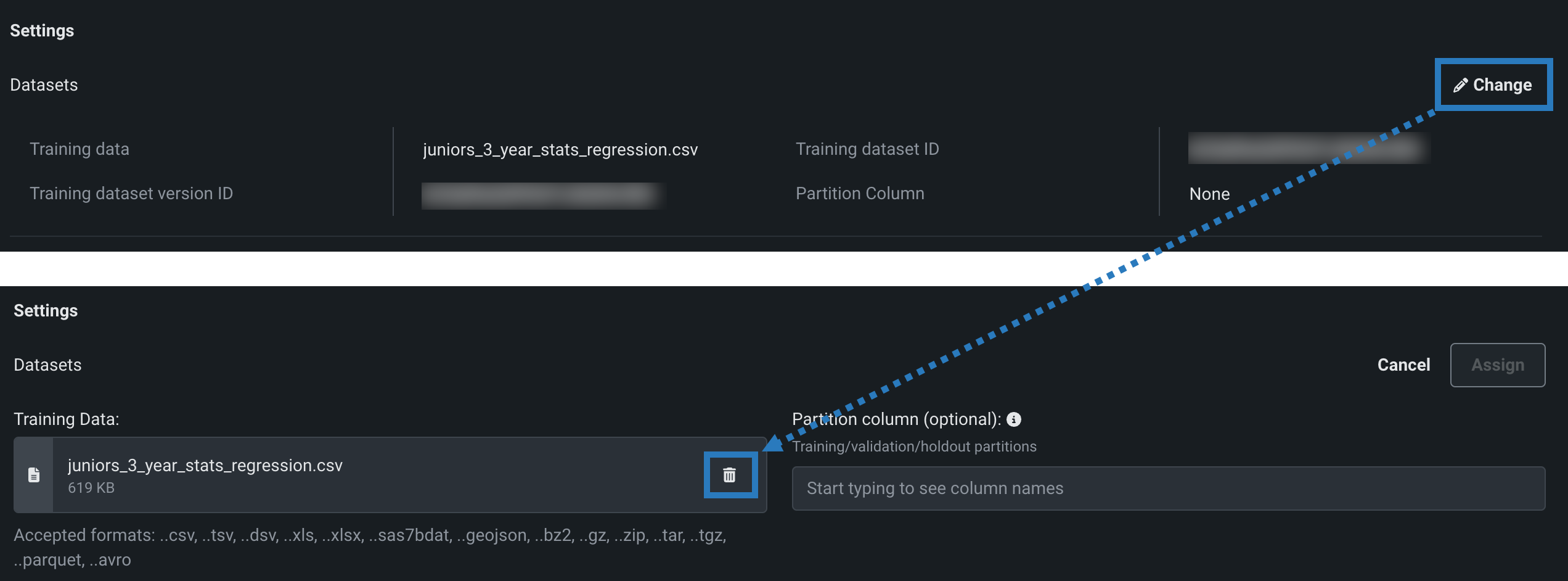
モデルバージョンにトレーニングデータが 割り当てられている 場合は、()変更をクリックし、トレーニングデータの下で削除()アイコンをクリックして、既存のトレーニングデータを削除します。
-
-
トレーニングデータセクションで、+ データセットを選択をクリックして、次のいずれかを実行します。
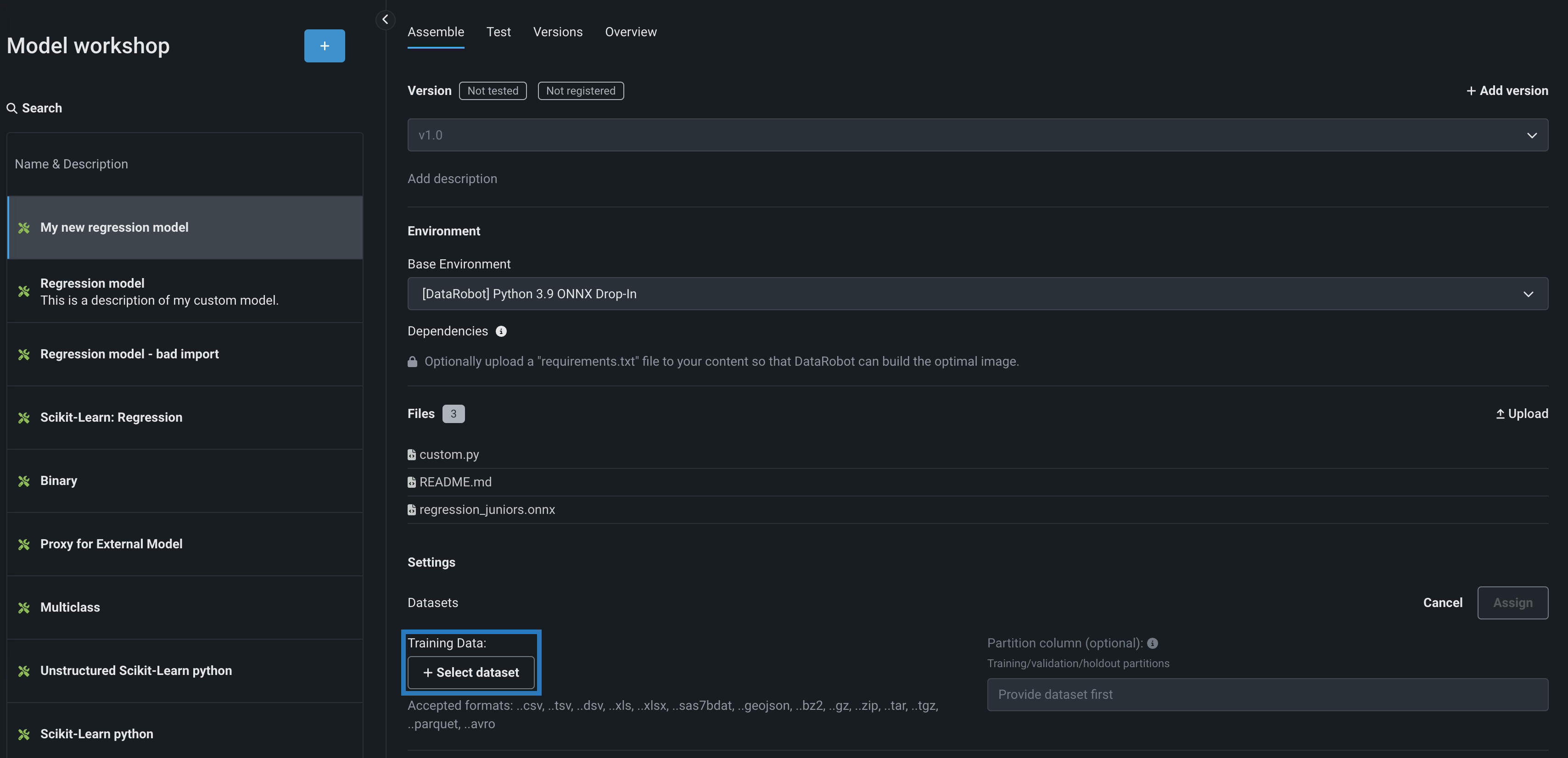
-
新しいデータセットをデータレジストリに追加するには、アップロードをクリックし、ローカルストレージからファイルを選択して、開くをクリックします。
-
データレジストリから既存のデータセットを選択するには、データレジストリリストで、DataRobotに以前アップロードしたトレーニングデータセットを見つけてクリックし、データセットを選択をクリックします。
スコアリングに必要な特徴量を含める
カスタムモデルのトレーニングデータの列は、デプロイされたカスタムモデルへのスコアリングリクエストにどの特徴量が含まれるかを示します。 したがって、トレーニングデータが利用可能になると、トレーニングデータセットに含まれない特徴量はモデルに送信されません。 プレビュー機能として利用可能で、 列フィルター設定を使用して、この動作を無効にできます。
-
-
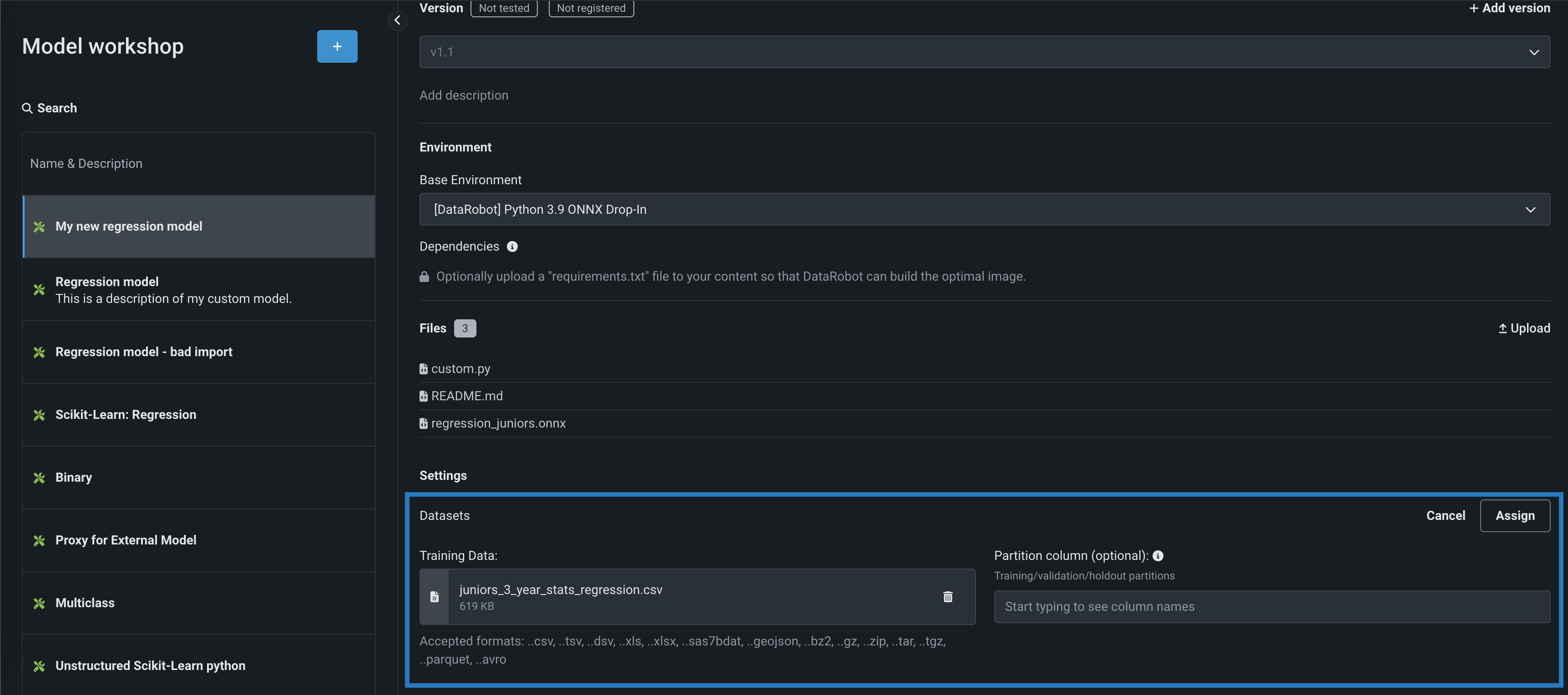
(オプション)パーティション列セクションで、(トレーニング/検定/ホールドアウトのパーティショニングに基づいて)データのパーティショニング情報を含む列名(そこにあるトレーニングデータセットから)を指定します。 カスタムモデルをデプロイし、そのデータドリフトと精度を監視する予定であれば、列にホールドアウトパーティションを指定して、精度のベースラインを確立します。
-
割り当てるをクリックします。
トレーニングデータの割り当てエラー
トレーニングデータの割り当てに失敗すると、新しいカスタムモデルバージョンのデータセットの下にエラーメッセージが表示されます。 このエラーが存在する間は、影響を受けるバージョンをデプロイするモデルパッケージを作成できません。 エラーを解決してモデルパッケージをデプロイするには、トレーニングデータを再割り当てして新しいバージョンを作成するか、新しいバージョンを作成してからトレーニングデータを割り当てます。
予測リクエストでの列フィルターの無効化¶
プレビュー
設定可能な列フィルターは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:カスタムモデルの予測で特徴量のフィルターを有効にする
プレビュー版の機能です。カスタムモデルの予測で、列フィルターを有効または無効にできます。 選択したフィルター設定は、カスタムモデルの テストやデプロイの際に同様に適用されます。 デフォルトでは、ターゲット列は予測リクエストから除外されます。また、トレーニングデータが割り当てられている場合、トレーニングデータセットに存在しない追加の列は、モデルに送信されるスコアリングリクエストから除外されます。 あるいは、予測データセットに欠損列がある場合、欠損している特徴量を通知するエラーメッセージが表示されます。
カスタムモデルを構築する場合、この列フィルターを無効にすることができます。 ワークショップでカスタムモデルを開いて、アセンブルタブをクリックし、設定セクションの列のフィルターで、リクエストからターゲット列を除外をオフにします(または、トレーニングデータが割り当てられている場合は、ターゲット列とトレーニングデータにない余分な列を除外をオフにします)。
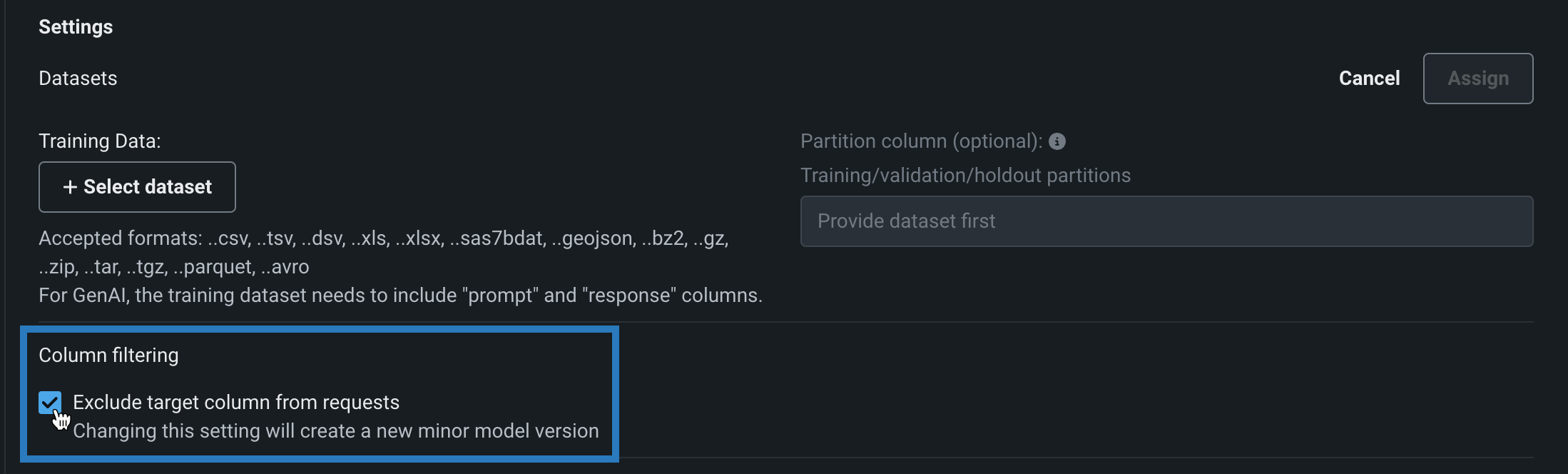
モデルの環境、ファイル、または設定に対するその他の変更と同様に、この設定を変更すると、新しい マイナーカスタムモデルバージョンが作成されます。
リクエストからターゲット列を除外またはトレーニングデータに含まれないターゲット列と追加列を除外が有効または無効の場合、次の動作が予期されます。
トレーニングデータの割り当て方法
モデルが 使用非推奨の「モデルごと」のトレーニングデータの割り当て方法を使用する場合、この設定は無効にできず、特徴量のフィルターは テスト中には 適用されません 。
| に設定 | 動作 |
|---|---|
| 有効 |
|
| 無効 |
|
DRUM予測
DRUMによる予測はフィルターされません。すべての列が各予測リクエストに含まれます。
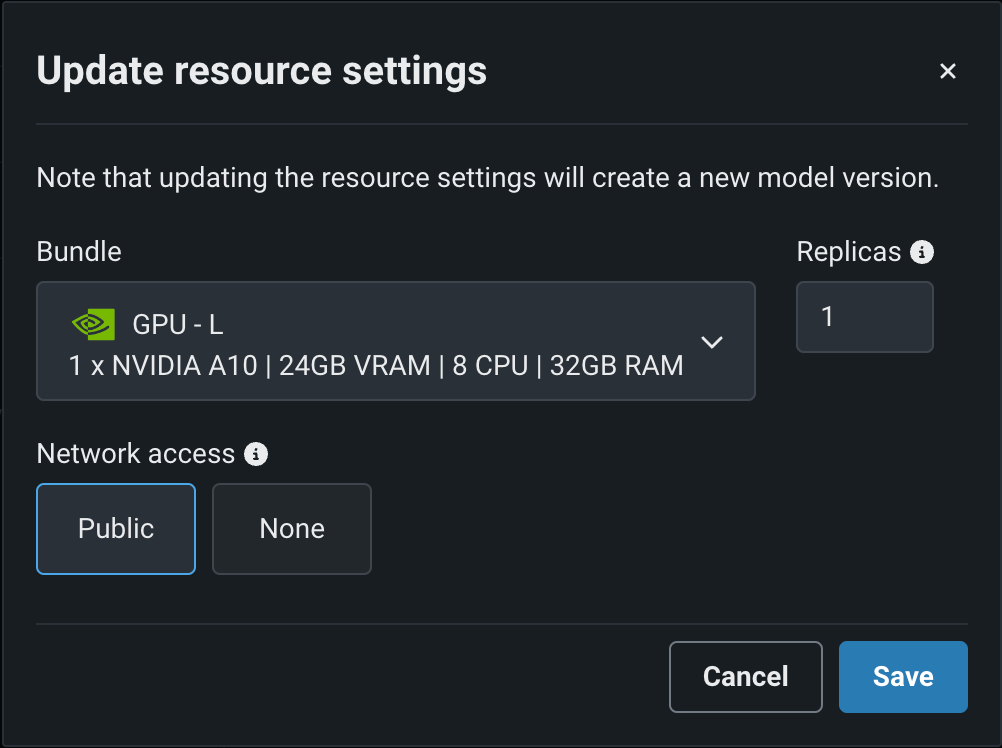
カスタムモデルのリソース設定を行う¶
カスタム推論モデルを作成した後、モデルが消費するリソースを設定して、スムーズなデプロイを促進し、本番環境で発生する可能性のある環境エラーを最小限に抑えることができます。
リソースの割り当てとアクセスを設定するには:
-
アセンブルタブの設定セクションで、リソースの横にある()編集をクリックします。
-
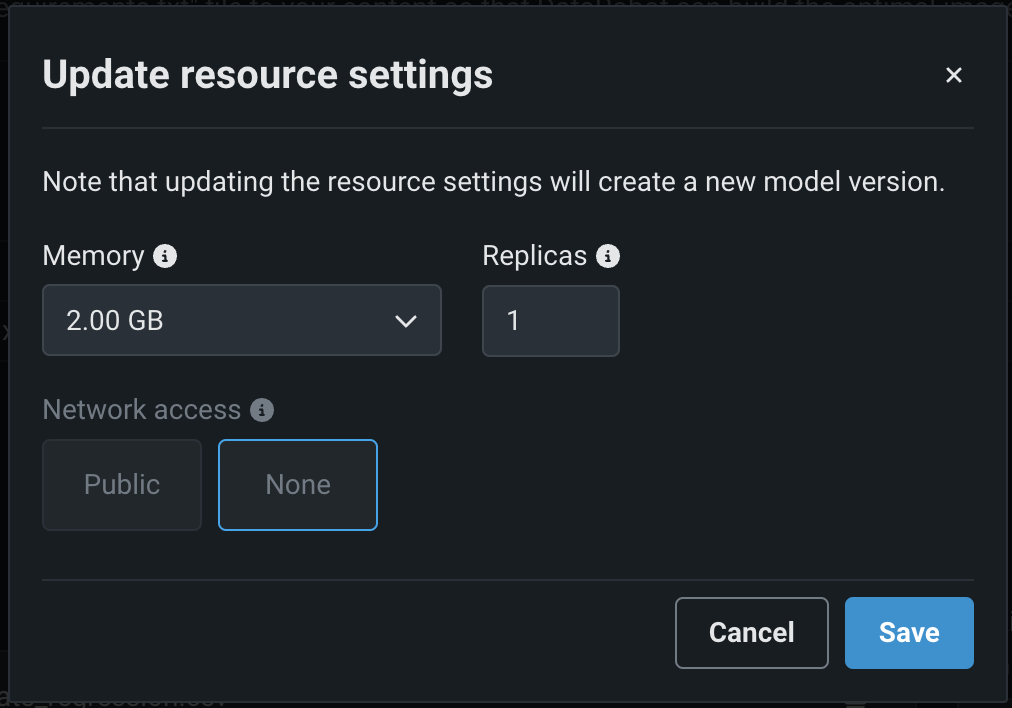
リソース設定の更新ダイアログボックスで、次の設定を行います。
リソース設定へのアクセス
ユーザーはモデルに割り当てられる最大メモリーを決定できますが、追加のリソース設定を行えるのは 組織管理者だけです。
設定 説明 メモリー カスタム推論モデルに割り当てることのできるメモリーの最大量を決定します。 設定された最大値以上のメモリーが割り当てられたモデルはシステムによって排除されます。 この問題がテスト中に発生した場合、テストは失敗としてマークされます。 モデルのデプロイ時に発生した場合は、Kubernetesによってモデルが自動的に再起動されます。 レプリカ カスタムモデルの実行時にワークロードのバランスを取るために、並行して実行するレプリカの最大数を設定します。 レプリカの数を増やしても、カスタムモデルの速度に依存するため、パフォーマンスが向上しない場合があります。 ネットワークアクセス プレミアム機能。 カスタムモデルのエグレストラフィックを設定します。 - パブリック:デフォルト設定。 カスタムモデルは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムモデルはパブリックネットワークから分離されているため、サードパーティのサービスにはアクセスできません。
DATAROBOT_ENDPOINTおよびDATAROBOT_API_TOKEN環境変数を使用できます。 これらの環境変数は、 ドロップイン環境または DRUM上に構築された カスタム環境を使用するすべてのカスタムモデルで使用できます。バランスの悪いメモリー設定
DataRobotでは、必要な場合にのみリソース設定を行うことをお勧めします。 以下のメモリー設定では、Kubernetesメモリーの「制限」(メモリーの最大許容量)が設定されます。ただし、メモリーの「リクエスト」(メモリーの最小許容量)を設定することはできません。 このため、「制限」値をデフォルトの「リクエスト」値より大きく設定することができます。 メモリーの「リクエスト」と増加した「制限」によるメモリー許容量との不均衡が生じ、カスタムモデルがメモリー使用量の上限を超える場合があります。 その結果、カスタムモデルの頻繁な削除や再起動により、カスタムモデルが実行時に不安定になる場合があります。 メモリー設定を増やす必要がある場合は、組織レベルで「リクエスト」を増やすと、この問題を軽減できます。詳細については、DataRobotサポートまでお問い合わせください。
プレミアム機能:ネットワークアクセス
_新しく_作成したカスタムモデルはすべて、デフォルトでパブリックネットワークにアクセスできます。ただし、2023年10月より前に作成されたカスタムモデルの新しいバージョンを作成した場合、その新しいバージョンは、パブリックアクセスを有効にする(アクセスをパブリックに設定する)まで、パブリックネットワークから隔離された(アクセスがなしに設定された)ままです。 パブリックアクセスを有効にすると、後続の各バージョンは、前のバージョンのパブリックアクセス定義を継承します。
-
カスタムモデルのリソース設定を行ったら、保存をクリックします。
これにより、編集したリソース設定が適用されたカスタムモデルのマイナーバージョンが新しく作成されます。
リソースバンドルを選択¶
プレビュー
カスタムモデルのリソースバンドルとGPUリソースのバンドルは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする、カスタムモデルでGPUを使用した推論を有効にする(プレミアム機能)
モデルを構築して リソース設定を行う際に、メモリーではなくリソースバンドルを選択できます。 リソースバンドルを使用すると、さまざまなCPUおよびGPUハードウェアプラットフォームから選択して、カスタムモデルを構築およびテストできます。 カスタムモデルの設定セクションで、リソース設定を開き、リソースバンドルを選択します。 この例では、モデルはNVIDIA A10デバイスでテストおよびデプロイされるように構築されています。
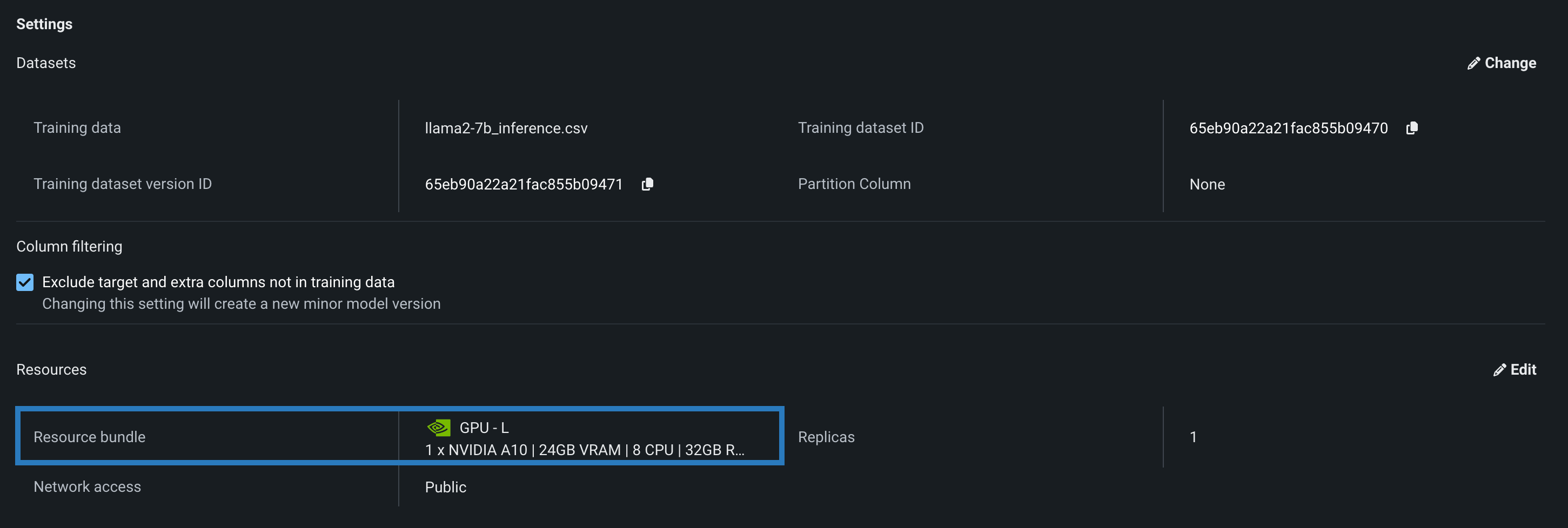
編集をクリックしてリソース設定の更新ダイアログボックスを開き、リソースのバンドルフィールドで、構築環境として使用可能な CPUおよび NVIDIA GPUデバイスを確認します。
DataRobotは、次のNVIDIAリソースバンドルのいずれかにモデルをデプロイできます。
| バンドル | GPU | VRAM | CPU | RAM |
|---|---|---|---|---|
| GPU - S | 1x NVIDIA T4 | 16GB | 4 | 16GB |
| GPU - M | 1x NVIDIA T4 | 16GB | 8 | 32GB |
| GPU - L | 1x NVIDIA A10G | 24GB | 8 | 32GB |
| GPU - XL | 1x NVIDIA L40S | 48GB | 4 | 32GB |
| GPU - XXL | 4x NVIDIA A10G | 96GB | 48 | 192GB |
| GPU - 3XL | 4x NVIDIA L40S | 192GB | 48 | 384GB |
| GPU - 4XL | 8x NVIDIA A10G | 192GB | 192 | 768GB |
| GPU - 5XL | 8x NVIDIA L40S | 384GB | 192 | 1.5TB |
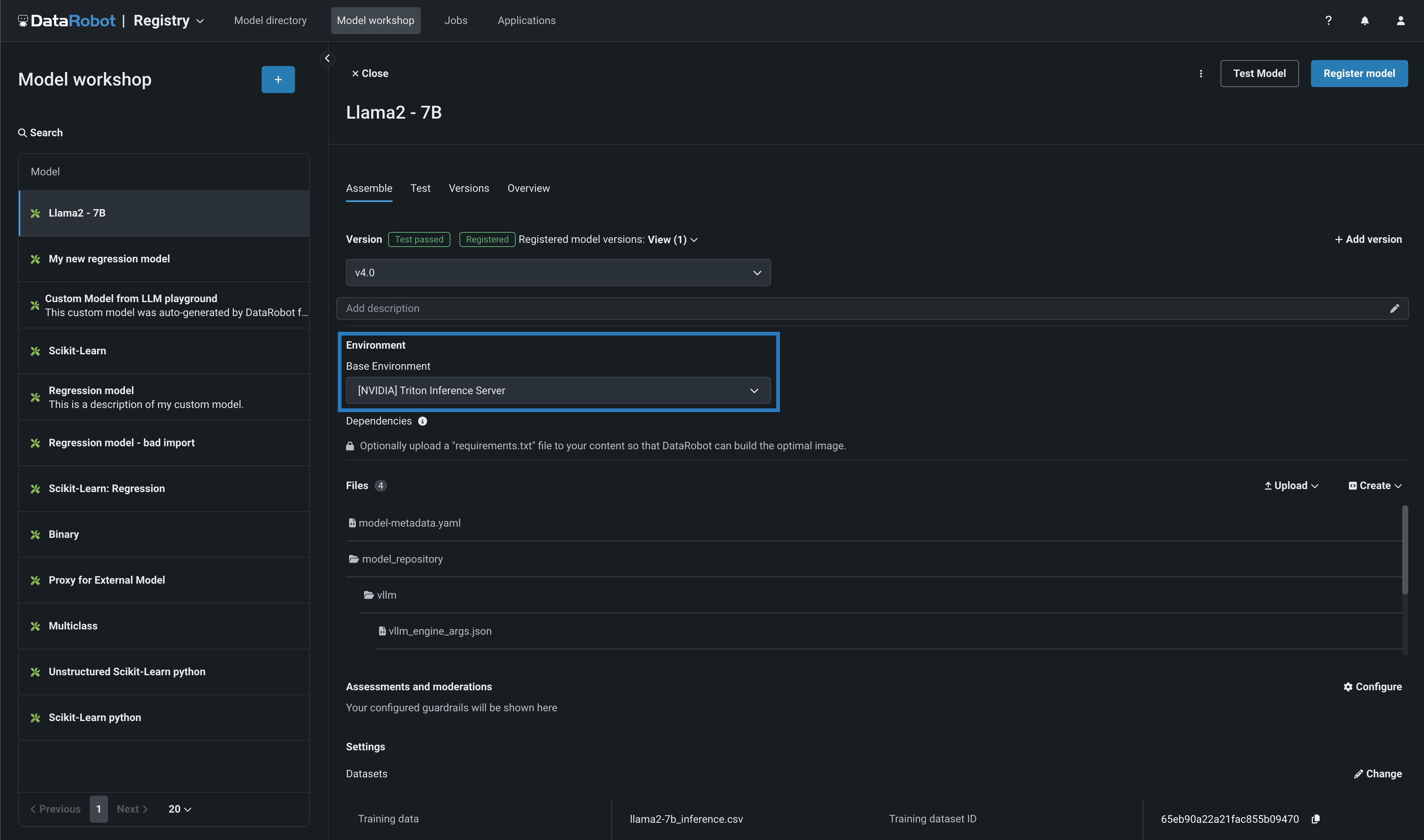
NVIDIA GPUリソースバンドルに加えて、この機能は、NVIDIA GPU上で実行するように最適化されたカスタムモデル環境を導入します。 カスタムモデルを構築する場合、基本環境を定義します。 次の例では、モデルは、 [NVIDIA] Triton推論サーバーで実行されています。
多ラベルモデルの構築¶
多ラベル分類の問題をサポートするカスタム推論モデルを作成できます。 多ラベルカスタムモデルは推論のみをサポートしています。リーダーボードに多ラベルカスタムトレーニングタスクを作成することはできません。
ネイティブにトレーニングされた多ラベルモデルとは異なり、カスタム多ラベルモデルは、トレーニングデータを使用せずに作成されます。 ワークショップ(またはmodel-metadata.yaml)でモデルを作成する際は、少なくとも2つのターゲットラベルを指定する必要があります。 これに対し、多クラスカスタムモデルでは、少なくとも3つのクラスが必要です。
カスタム多ラベルモデルをデプロイする場合は、以下を利用できます。
- サービスの正常性
- 特徴量ドリフト
以下はサポートされていません。
- ターゲットドリフト
- 精度の追跡
- チャレンジャーモデル
- 再トレーニングポリシー
これらの制限は、DataRobotの多ラベルモデルと一致しています。
異常検知モデルの構築¶
異常検知の問題をサポートするカスタムモデルを作成できます。 構築する場合は、DRUMテンプレートを参照してください。 (このリンクをクリックする前にGitHubにログインしてください。)カスタム異常検知モデルをデプロイする場合、次の機能はサポートされていないことに注意してください。
- データドリフト
- 精度と関連付けID
- チャレンジャーモデル
- 信頼性ルール
- 予測の説明
テキスト生成モデルの構築¶
本機能の提供について
生成モデルの監視サポートはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
テキスト生成カスタムモデルには、[DataRobot] Python 3.X GenAIドロップイン環境、または互換性のあるカスタム環境が必要です。 ワークショップから生成モデルを構築、テスト、およびデプロイするには、モデルワークショップで構築された基本的なLLMに、少なくとも以下のファイルが含まれている必要があります。
| ファイル | 内容 |
|---|---|
custom.py |
カスタムモデルのパブリックネットワークアクセスを介してLLMサービスのAPIを呼び出すボルトオンのガバナンスAPI(chat()フック)を実装するカスタムモデルコード。 |
model-metadata.yaml |
生成モデルに必要なカスタムモデルのメタデータと ランタイムパラメーター。 |
requirements.txt |
生成モデルに必要な ライブラリ(およびバージョン)。 |
必要なモデルファイルを追加したら、 トレーニングデータを追加します。 ドリフト監視のトレーニングベースラインを提供するには、生成モデルが質問に回答することを想定しているトピックに関連したプロンプトと回答を少なくとも20行含むデータセットをアップロードします。 これらのプロンプトとレスポンスは、ドキュメントから取得することも、手動で作成することも、生成することもできます。
ベクターデータベースの構築¶
Premium
ベクターデータベースのデプロイはプレミアム機能で、デフォルトではオフになっており、GenAIのエクスペリメントが必要です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
ベクターデータベースのカスタムモデルには、[DataRobot] Python 3.X GenAIドロップイン環境、または互換性のある カスタム環境が必要です。 さらに、ベクターデータベースの依存関係を定義する必要があります。 依存関係セクションに入力するために、ファイルセクションでrequirements.txtファイルをアップロードし、DataRobotが最適なイメージを構築できるようにします。 さらに、ベクターデータベースのカスタムモデルには、 パブリックネットワークへのアクセスが必要です。
ワークショップでベクターデータベースを作成したら、他のカスタムモデルと同じように、モデルを登録およびデプロイできます。
ベクターデータベースのデプロイでは、どのような監視が可能ですか?
デプロイタイプがベクターデータベースのデプロイでは、ベクターデータベースに関連するカスタム指標が自動的に生成されます。たとえば、Total Documents、Average Documents、Total Citation Tokens、Average Citation Tokens、VDB Score Latencyなどです。 ベクターデータベースのデプロイでは、サービス正常性の監視も可能です。 ベクターデータベースのデプロイでは、データ探索のために予測行レベルのデータが保存されることはありません。
エージェントのワークフローを構築¶
プレミアム機能
エージェントのワークフローはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
エージェントのワークフローには、[DataRobot] Python 3.X GenAIドロップイン環境、または互換性のあるカスタム環境が必要です。 ワークショップからエージェントのワークフローを構築、テスト、およびデプロイするために、ワークショップで構築された基本エージェントには、通常、以下のファイルが含まれています。
| ファイル | 内容 |
|---|---|
custom.py |
LLMを呼び出すためのボルトオンのガバナンスAPI(chat()フック)を実装し、それらのパラメーターを(agent.pyで定義されている)エージェントに渡すカスタムモデルコード。 |
agent.py |
エージェントのワークフローを実装するエージェントコード。 |
model-metadata.yaml |
エージェントのワークフローに必要なカスタムモデルのメタデータとランタイムパラメーター。 |
requirements.txt |
エージェントのワークフローに必要なライブラリ(とバージョン)。 |
カスタムエージェントワークフローを作成したら、ボルトオンのガバナンスAPI(chat()フック)のカスタムワークフローの実装をテストすることができます。
エージェントのツールがアクセス可能であることを確認
機能的なエージェントワークフローをデプロイするには、カスタムエージェントワークフローに必要なデプロイ済みツールがアクセス可能であることを確認します。
エージェントワークフローのデプロイ機能
エージェントのワークフローは、サーバーレス予測環境でのみデプロイできます。 After deployment, Console includes the deployment Overview tab; Monitoring for service health, usage (including quota monitoring), custom metrics, data exploration (including tracing), resource monitoring, OpenTelemetry (OTel) metrics, and deployment reports; Predictions through the Prediction API (including chat completions); and Activity log for standard output, OTel logs, and moderation events when evaluation and moderation guardrails are configured. For a tab-by-tab summary with links, see Monitor workflows.
エージェントツールの登録¶
エージェントツールはレジストリに登録されるため、エージェントが簡単に一覧表示や呼び出しを行うことができ、DataRobot APIへのアクセスが可能になります。 これらのツールは、ワークショップのツールタブで確認できます。
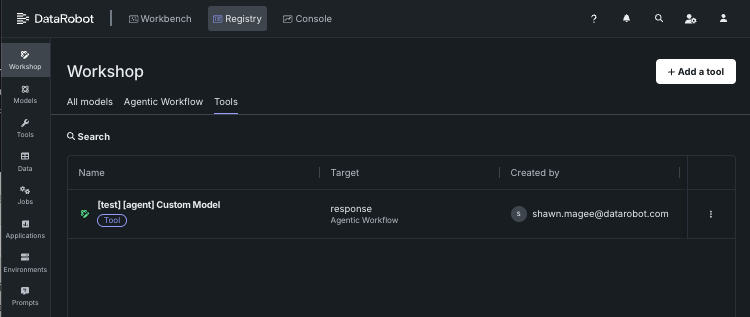
ツールをクリックすると詳細が表示されます。また、ツールを追加をクリックすると、新しいツールを登録できます。 これにより、モデルを追加ページが開きます。ここでは、他のカスタムモデルと同様にモデルを設定できますが、オプション設定の下にあるモデルをツールとして使うボックスが選択されている点が異なります。
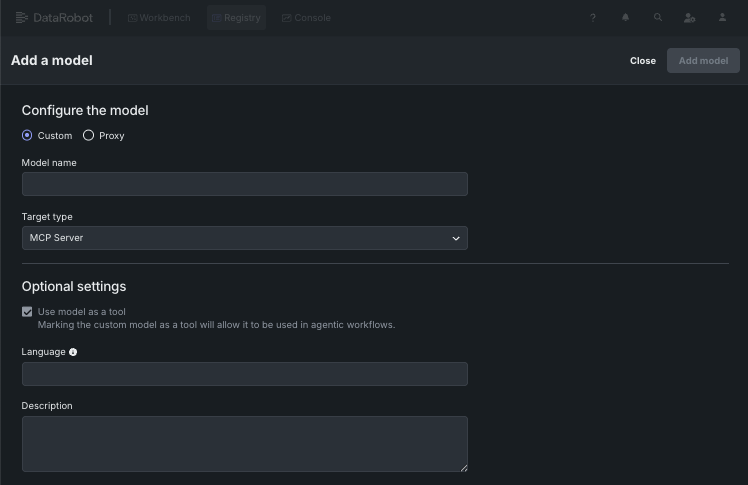
モデルを追加をクリックして、ツールを登録します。 ツールのバージョンが、ワークショップ > ツールタブの詳細ビューで開きます。
ここから、カスタムモデルの構築に記載されている手順に従い、他のカスタムモデルと同様にツールを設定します。 エージェントツール管理の詳細については、ツールの表示と管理のページを参照してください。