データドリフトのモニタリングを設定¶
モデルをデプロイするとき、トレーニングおよび検定に使用するデータセットが予測データと異なっていることがあります。 データドリフト監視は、設定 > データドリフトタブで有効にすることができます。 DataRobotはターゲットドリフトと特徴量ドリフトの両方の情報を監視し、結果をモニタリング > データドリフトタブに表示します。
DataRobotでのドリフトの追跡方法
DataRobotは2種類のドリフトを追跡します。
-
ターゲットドリフト:DataRobotは予測に関する統計情報を蓄積しているため、時間の経過と共にターゲットの分布と値がどのように変化するかを監視することができます。 ターゲット分布の比較の基準として、DataRobotではホールドアウトの予測値の分布を使用します。
-
特徴量ドリフト:DataRobotは予測に関する統計情報を蓄積しているため、時間の経過と共に特徴量の分布と値がどのように変化するかを監視することができます。 サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。 特徴量の分布を比較するためのベースラインとして:
-
500MBより大きいトレーニングデータセットでは、DataRobotはトレーニングデータのランダムサンプルの分布を使用します。
-
500MBより小さいトレーニングデータセットでは、DataRobotはトレーニングデータの100%の分布を使用します。
-
デプロイのデータドリフト設定ページでは、次の設定を行うことができます。
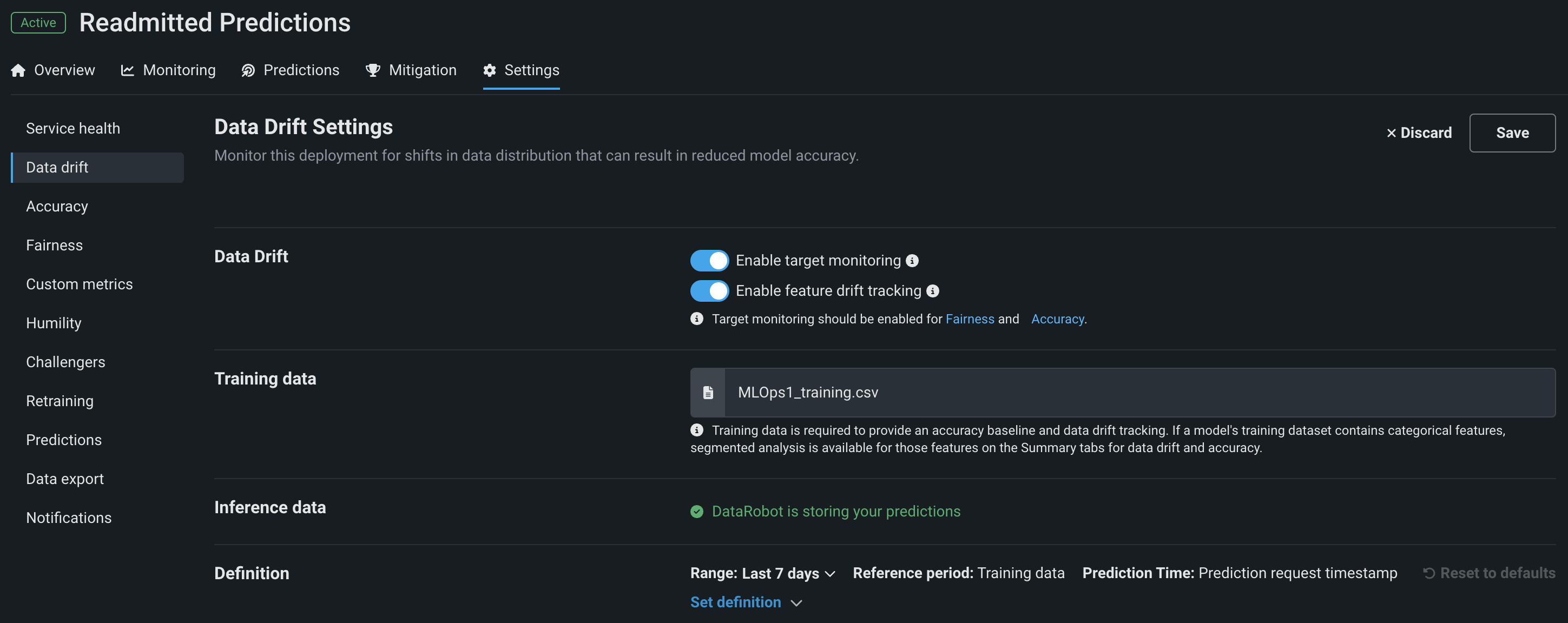
| フィールド | 説明 |
|---|---|
| データドリフト | |
| 特徴量ドリフト追跡の有効化 | デプロイ内の特徴量ドリフトを追跡するようDataRobotを設定します。 特徴量ドリフト追跡にはトレーニングデータが必要です。 |
| ターゲット監視の有効化 | デプロイ内のターゲットドリフトを追跡するようDataRobotを設定します。 精度監視にはターゲットの監視が必要です。 |
| トレーニングデータ | |
| トレーニングデータ | モデルを構築する際にトレーニングのベースラインとして使用されたデータセットを表示します。 |
| 特徴量ドリフト | |
| 特徴量ドリフト | デプロイで 特徴量ドリフトのために追跡される25の特徴量の選択に使用する戦略を定義します。 |
| 推論データ | |
| 予測を保存しています。 | DataRobotがこのデプロイによって行われた予測の結果を記録し、保存していることを確認します。 デプロイを作成すると、DataRobotにデプロイの推論データが保存されます。 これは、個別のアップロードすることはできません。 |
| 推論データ(外部モデル) | |
| DataRobotは、このデプロイに対して行われたすべての予測結果を記録しています | DataRobotが外部モデルによって行われた予測の結果を記録し、保存していることを確認します。 |
| ここにファイルをドロップするか、ファイルを選択する | 予測履歴データを含むファイルをアップロードして、データドリフトを監視します。 |
| 定義 | |
| 定義を設定 | データドリフトを監視するために、ドリフトと有用性の指標設定としきい値定義を行います。 |
本機能の提供について
データドリフト追跡は、デプロイ対応の予測APIルートを使用するデプロイでのみ使用できます(https://example.datarobot.com/predApi/v1.0/deployments/<deploymentId>/predictionsなど)。
データプライバシー通知
DataRobotはターゲットドリフトと特徴量ドリフトの両方の情報を監視し、結果をモニタリング > データドリフトタブに表示します。 たとえば、監視する必要のない機微データがデプロイに含まれている場合などは、ターゲット監視を有効化と特徴量ドリフト追跡を有効化のトグルを使用して追跡をオフにします。 ターゲット監視の有効化設定は、精度監視を有効にする際にも必要です。
特徴量ドリフト追跡のカスタマイズ¶
デプロイで特徴量ドリフト追跡を有効にすると、特徴量ドリフトセクションが表示されます。 追跡する25の特徴量を選択するには、次の戦略のいずれかを選択します。

サポートされている特徴量のデータ型
サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。
-
自動:(デフォルト)DataRobotが25の特徴量を選択します。
-
手動:特徴量の選択をクリックし、リストから最大25の特徴量を選択します(有用性順に並べ替え)。

特徴量の手動選択に関する注意事項
特徴量の選択テーブルには、以下の特徴があります。
-
特徴量は、特徴量の有用性が高い順に降順でソートされています。 2番目のソートは、名前のアルファベット順です。
-
すべての特徴量に有用性の値があるわけではなく、一部の特徴量が負の値になる場合があります。
-
外部モデルのデプロイでは、特徴量の有用性値は使用できません。
-
トレーニングデータを持つリーダーボードまたはカスタムモデルのデプロイの場合、テーブルでは、特徴量のインパクトではなく、正規化されたACEが有用性の値として使用されます。
-
テキスト生成モデルのデプロイの場合、テーブルでは割り当てられたスコアが使用されます。ターゲットは1.0、テキスト特徴量は0.9、その他の特徴量は0.1です。
特徴量の手動選択が有効になっているすべてのデプロイでは:
-
選択された特徴量のみがドリフトの追跡対象となります。 特徴量が選択されていない場合、たとえその特徴量が予測リクエストやアップロードされた統計に存在していても、追跡の対象にはなりません。
-
手動選択から自動選択に切り替えた場合、以前に追跡された特徴量が十分に有用でない場合、ドリフト追跡から削除される可能性があります。
-
自動と手動の切り替えや、追跡対象の特徴量の追加や削除を行っても、累積された特徴量のドリフト統計は削除されません。
ドリフト追跡の特徴量を手動で選択する場合:
-
使用可能な特徴量は、チャンピオンモデルプロジェクトの特徴量セット(該当する場合)またはトレーニングデータセット(該当する場合)から取得されます。
-
サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。
-
チャンピオンとしてインポートされたモデルパッケージを使用したデプロイの場合、サポートされる特徴量は、(.mlpkgファイルで)事前に計算されたベースラインを持つ特徴量のみです。
-
リーダーボードモデルをチャンピオンとしてデプロイした場合:
-
非時系列モデルでは、プロジェクトの特徴量セットでサポートされている特徴量は、モデルの特徴量セットに含まれていない場合でも利用できます。
-
セグメント化されていない時系列モデルでは、モデルの特徴量セットでサポートされている特徴量はすべて利用できます。
-
セグメント化された時系列モデルでは、特徴量のドリフトはサポートされていません。
-
-
カスタムモデルをチャンピオンとしてデプロイした場合:
-
非時系列モデルでは、トレーニングデータでサポートされている列はすべて使用できます。
-
時系列モデルでは、トレーニングデータでサポートされている列はすべて使用できます。
-
-
外部モデルを使ったデプロイの場合、トレーニングデータでサポートされている列はすべて使用できます。
モデルの置換時:
-
現在選択されている特徴量は、サポートされていない場合、または置換モデルに含まれている場合、置換後に削除されます。
-
現在選択されているどの特徴量も置換モデルで追跡の対象となっていない場合、特徴量のドリフトは無効化されます。
-
これらの変更のいずれかが置換後に発生する場合、モデル置換検定の警告が表示されます。
データドリフト監視の通知を定義する¶
ドリフトは、指定された範囲で、すべての特徴量でデータの分布がどのように変化するかを評価します。 設定したしきい値によって、通知がトリガーされる前に許容されるドリフト量が決まります。
ドリフト監視の設定権限
データドリフトの監視設定を変更できるのは、デプロイオーナーだけです。ただし、ユーザーは 通知が送信される条件を設定することができます。 コンシューマーは監視や通知の設定を変更できません。
さらに、デプロイオーナーは、各デプロイのドリフトステータスの計算に使用されるルールをカスタマイズできます。 デプロイのオーナーとして、次のことができます。
-
有用性の高いまたは低い特徴量のリストを定義または上書きして、有用な特徴量を監視、または有用性の低い特徴量をあまり重視しないようにします。
-
ドリフトステータスの計算と注意からドリフトすると予想される特徴量は除外されるため、誤ってアラームが発生することはありません。
-
「注意」および「失敗」のドリフトステータスの平均をカスタマイズして、各デプロイのドリフトステータスを必要に応じてパーソナライズおよび調整します。
ドリフトと有用性のしきい値を設定するには、設定 > データドリフトタブの定義セクションを使用します。
-
ドリフトは、新しい予測データがモデルのトレーニングに使用された元のデータとどの程度異なるかを示す指標です。
-
有用性により、有用性の高い特徴量と有用性の低い特徴量の差異を明らかにすることができます。
ドリフトと有用性の両方について、データドリフトタブで、しきい値とそれがどのように特徴量を分離するかを視覚化できます。 デフォルトで、デプロイのデータドリフトステータスは、少なくとも1つの有用性の高い特徴量が設定されたドリフトメトリックのしきい値を超えると、「失敗」(![]() )とマーク付けされます。有用性の高い特徴量はないが、少なくとも1つの有用性の低い特徴量がしきい値を超えと、「注意」(
)とマーク付けされます。有用性の高い特徴量はないが、少なくとも1つの有用性の低い特徴量がしきい値を超えと、「注意」(![]() )としてマーク付けされます。
)としてマーク付けされます。
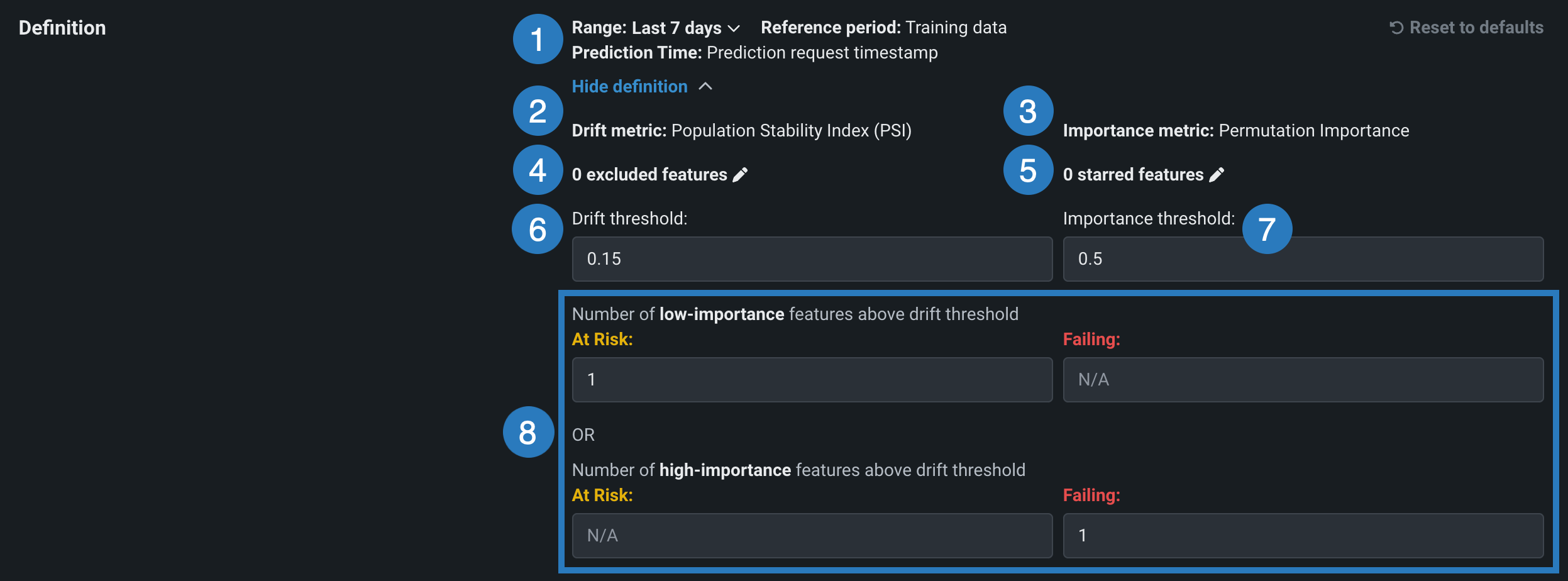
デプロイのドリフトステータス監視を設定するには、データドリフト設定ページの定義セクションで、データドリフトを監視する設定を行います。
| 要素 | 説明 | |
|---|---|---|
| 1 | 範囲 | リファレンス期間の時間範囲を調整し、トレーニングデータと予測データを比較します。 ドロップダウンメニューから時間範囲を選択します。 |
| 2 | ドリフト指標 | DataRobotはPSI(Population Stability Index)指標のみをサポートしています。 詳細については、以下のドリフト指標のサポートを参照してください。 |
| 3 | 有用性指標 | DataRobotは置換の有用性指標のみをサポートしています。 有用性指標は、トレーニングデータで最も影響の大きい特徴量を測定します。 |
| 4 | X個の除外特徴量 |
ドリフトステータス計算から特徴量(ターゲットを含む)を除外できます。 X個の除外特徴量 をクリックすると、ダイアログボックスが開き、ドリフト追跡からの除外として設定する特徴量の名前を入力できます。 除外された特徴量はデプロイのドリフトステータスには影響しませんが、特徴量ドリフト対特徴量の有用性のチャートには引き続き表示されます。 |
| 5 | X個のスター付き特徴量 |
最初は有用性が低く割り当てられていた場合でも、有用性が高く扱われるように特徴量を設定します。 X個のスター付き特徴量 をクリックすると、ダイアログボックスが開き、有用性高(スター)として設定する特徴量の名前を入力できます。 追加されると、これらの特徴量には高い有用性が割り当てられます。 有用性のしきい値は無視されますが、特徴量ドリフト対特徴量の有用性のチャートには引き続き表示されます。 |
| 6 | ドリフトしきい値 | ドリフト指標のしきい値を設定します。 ドリフトのしきい値が変更されると、特徴量ドリフト対特徴量の有用性のチャートが更新され、変更が反映されます。 |
| 7 | 有用性しきい値 | 有用性指標のしきい値を設定します。 有用性指標は、トレーニングデータで最も影響の大きい特徴量を測定します。 ドリフトのしきい値が変更されると、特徴量ドリフト対特徴量の有用性のチャートが更新され、変更が反映されます。 |
| 8 | 「注意」/「失敗」のしきい値 | 「注意」( |
備考
しきい値の変更は、デプロイの履歴全体にわたって予測が行われる期間に影響します。 これらの更新されたしきい値は、データドリフトタブでのパフォーマンス監視のビジュアライゼーションに反映されます。
ドリフト指標のサポート
DataRobotのUIではPSI(Population Stability Index)指標のみがサポートされていますが、DataRobot APIでは、カルバックライブラー情報量、ヘリンガー距離、ヒストグラム交差(ヒストグラムに基づく非類似度)、およびイェンセンシャノン情報量もサポートされています。 さらに、Python APIクライアントを使用すると、 サポート対象の指標のリストを取得できます。