レジストリからモデルをデプロイする¶
モデルを登録したら、デプロイしたいモデルのバージョンにアクセスすることで、レジストリからモデルをデプロイすることができます。
レジストリから登録モデルのバージョンをデプロイするには:
-
モデルタブの登録モデルのテーブルで、デプロイしたいバージョンを含む登録モデルをクリックすると、バージョンのリストが開きます。
-
バージョンのリストで、デプロイしたいバージョンをクリックし、登録されているモデルバージョンを概要タブに開きます。
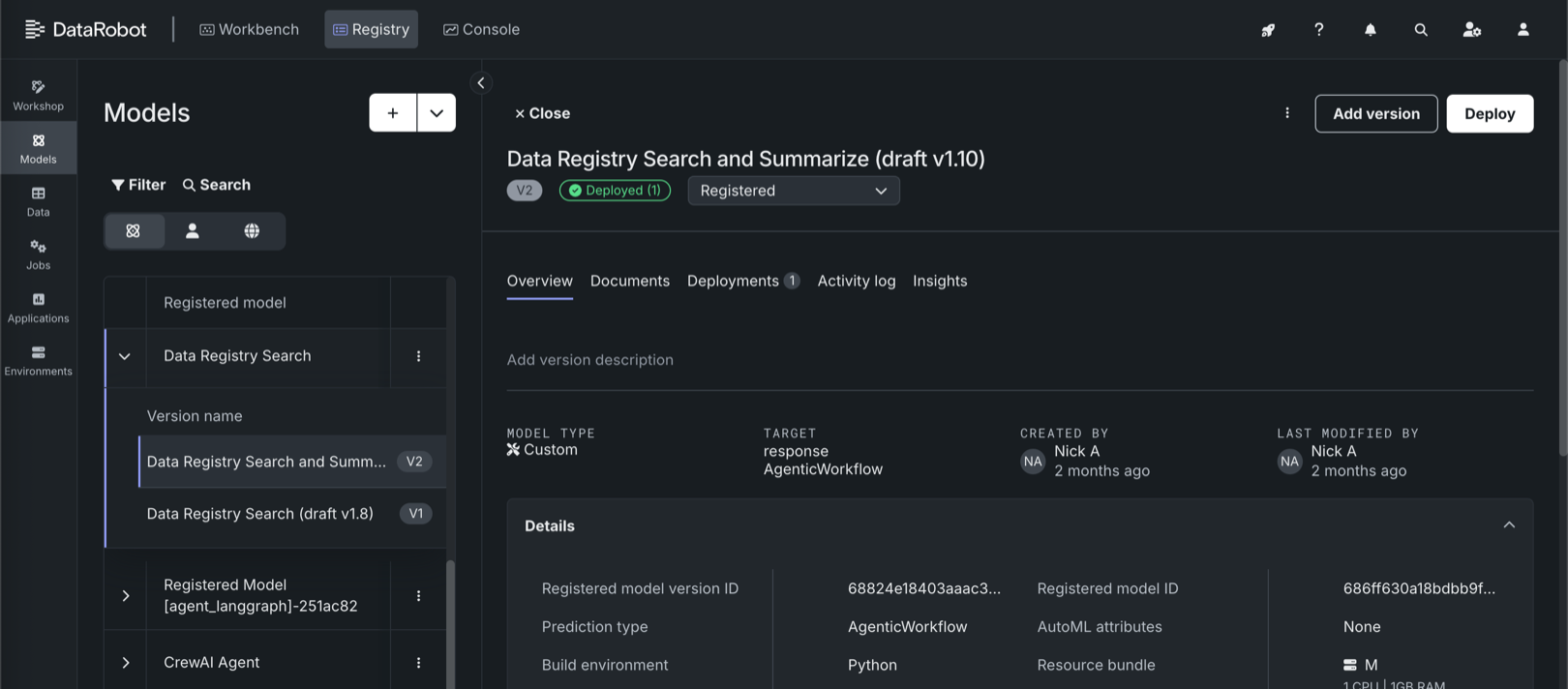
-
登録済みモデルバージョンパネルのいずれかのタブの右上隅で、デプロイをクリックし、 デプロイ設定を行います。
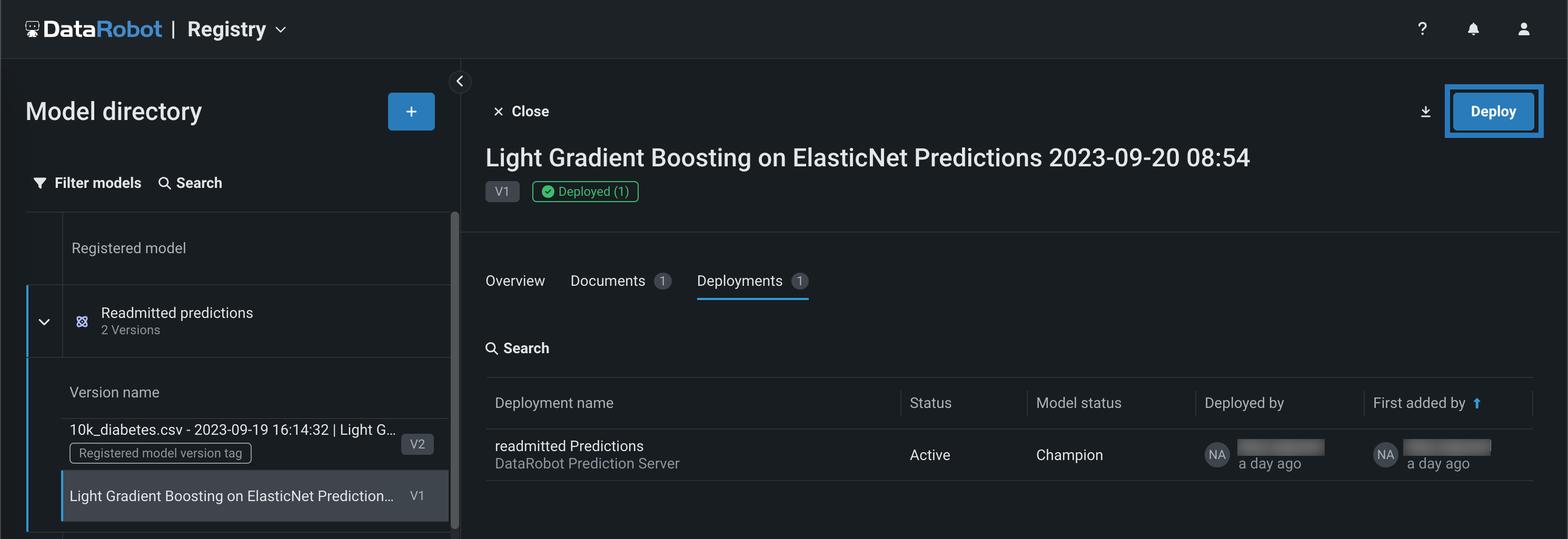
-
使用可能なデータを追加し、モデルが完全に定義されたら、画面上部にあるデプロイを作成をクリックします。
デプロイ設定を行う¶
新しいデプロイを作成する場所(ワークベンチのエクスペリメントまたはレジストリ)やアーティファクトのタイプ(DataRobotモデルまたは外部モデル)に関係なく、デプロイ情報ページが表示され、そこでデプロイを設定できます。 デプロイ情報ページには、トレーニングデータ、予測データ、実測値など、提供されたデータに基づいて現在のデプロイの機能の概要が表示されます。
標準のオプションと情報¶
モデルデプロイを開始すると、デプロイタブが開き、モデル情報および予測履歴とサービスの正常性オプションが表示されます。
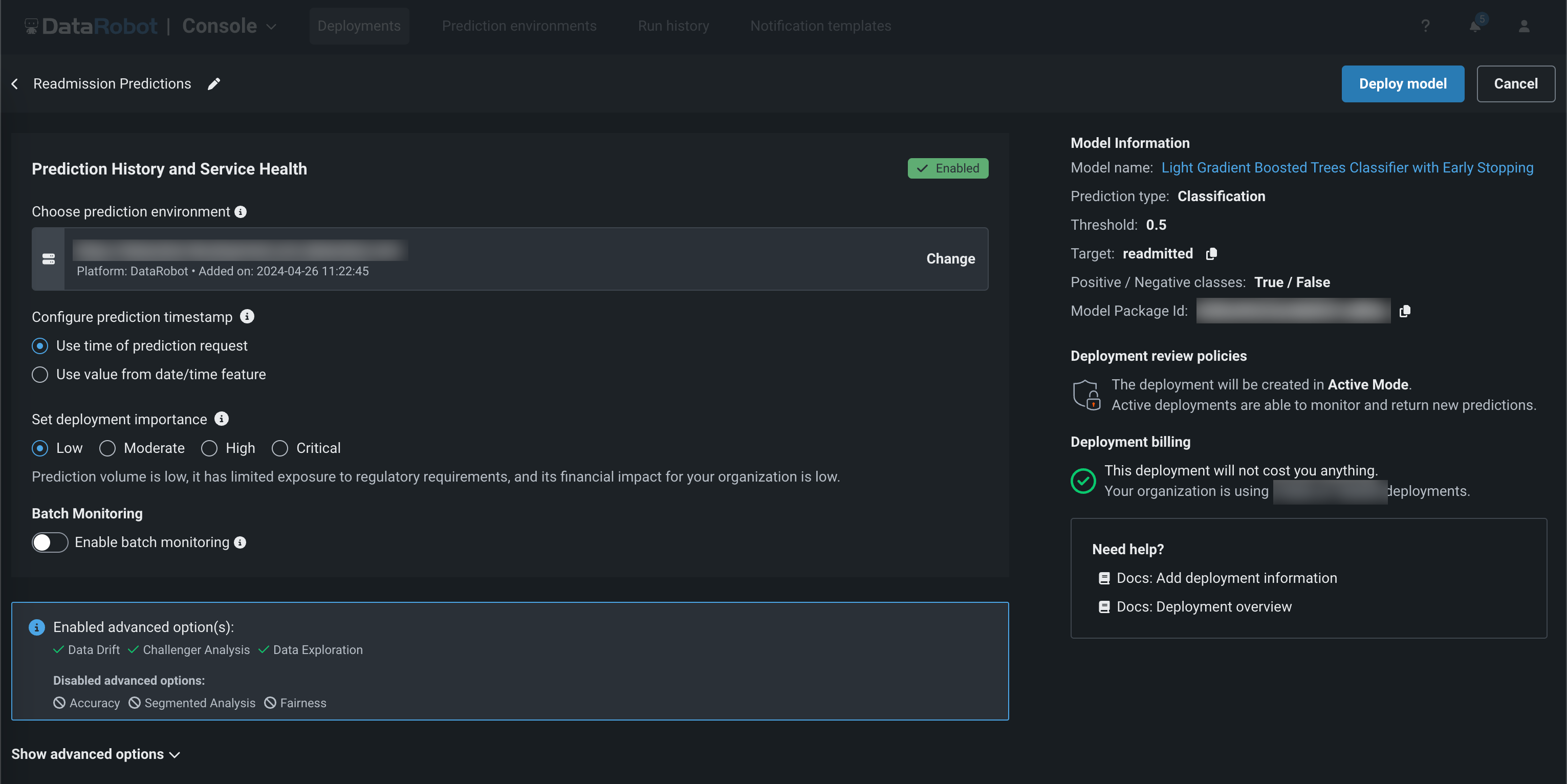
モデル情報セクションには、デプロイの予測を作成するために使用されているモデルの詳細情報が表示されます。 フィールドはデプロイのファイルおよび情報を使用して入力されるので、フィールドはグレーアウトされて編集できません。
| フィールド | 説明 |
|---|---|
| モデル名 | モデルの名前。 |
| 予測タイプ | モデルによる予測のタイプ。 例:連続値、分類、多クラス、異常検知、クラスタリングなど。 |
| しきい値 | 二値分類モデル用の予測しきい値 しきい値を超えるレコードには正のクラスラベルが、しきい値を下回るレコードには負のクラスラベルが割り当てられます。 このフィールドは、連続値モデルおよび多クラスモデルでは使用できません。 |
| ターゲット | モデルが予測するデータセットの列名。 |
| Positive/Negativeクラス | 二値分類モデルの正および負のクラス値。 このフィールドは、連続値モデルおよび多クラスモデルでは表示されません。 |
| モデルパッケージID(登録されているモデルバージョンID) | レジストリ内のモデルパッケージ(登録モデルのバージョン)のID。 |
備考
デプロイ制限のある組織に属している場合、デプロイ請求セクションでは、組織が デプロイ制限に対して使用しているデプロイの数と、組織が制限を超えた場合のデプロイコストが通知されます。
この予測履歴とサービスの正常性セクションには、デプロイの推論(スコアリング)データ—(これは予測リクエストおよびモデルからの結果を含む)に関する詳細が表示されます。
外部モデルの予測環境
外部モデルはDataRobotの外で実行され、外部の予測環境にデプロイする必要があります。 外部モデルをDataRobotのサーバーレス予測環境にデプロイしないでください。 外部環境の設定手順については、外部予測環境の追加を参照してください。
| 設定 | 説明 |
|---|---|
| 予測環境の設定 | 予測が生成される環境。 予測環境を使用すると、アクセス制御および承認ワークフローを確立できます。 |
| バッチ監視を有効にする | 予測をバッチにグループ化して監視するかどうかを決定し、予測のバッチを比較したり、バッチを削除して予測を再試行できるようにします。 詳細については、 デプロイ予測のバッチ監視のドキュメントを参照してください。 |
| 予測タイムスタンプを設定 | データドリフトと精度の監視で予測行のタイムスタンプ設定に使用する方法を決めます。
この設定は、デプロイが作成され、予測が行われた後は変更できません。 |
| デプロイの有用性を設定 | デプロイの有用性レベルを決定します。 これらのレベル(クリティカル、高、中、低)は、 承認プロセス中のデプロイの処理方法を決定します。 有用性は、組織に関連する要因(デプロイの予測量、エクスポージャーのレベル、潜在的な経済的影響など)の集計を表します。 デプロイに中以上の有用性が割り当てられたときに、レビュアー通知(モデル情報の下)が表示され、デプロイがレビューを必要とするたびに、レビュアーとして割り当てられたユーザーにDataRobotが自動的に通知することを示します。 |
予測の時間
予測の時間の値は、データドリフトタブと精度タブ、およびサービスの正常性タブで異なります。
-
[サービスの正常性]タブの「予測リクエストの日時」は、常に予測サーバーが予測リクエストを受信した日時です。 この予測リクエストの追跡方法は、診断目的で予測サービスの正常性を正確に示しています。
-
データドリフトタブと精度タブについてデフォルトで、「予測リクエストの時間」は、予測リクエストを送信した時刻になります。これは、 予測履歴とサービスの正常性設定で、予測タイムスタンプでオーバーライドできます。
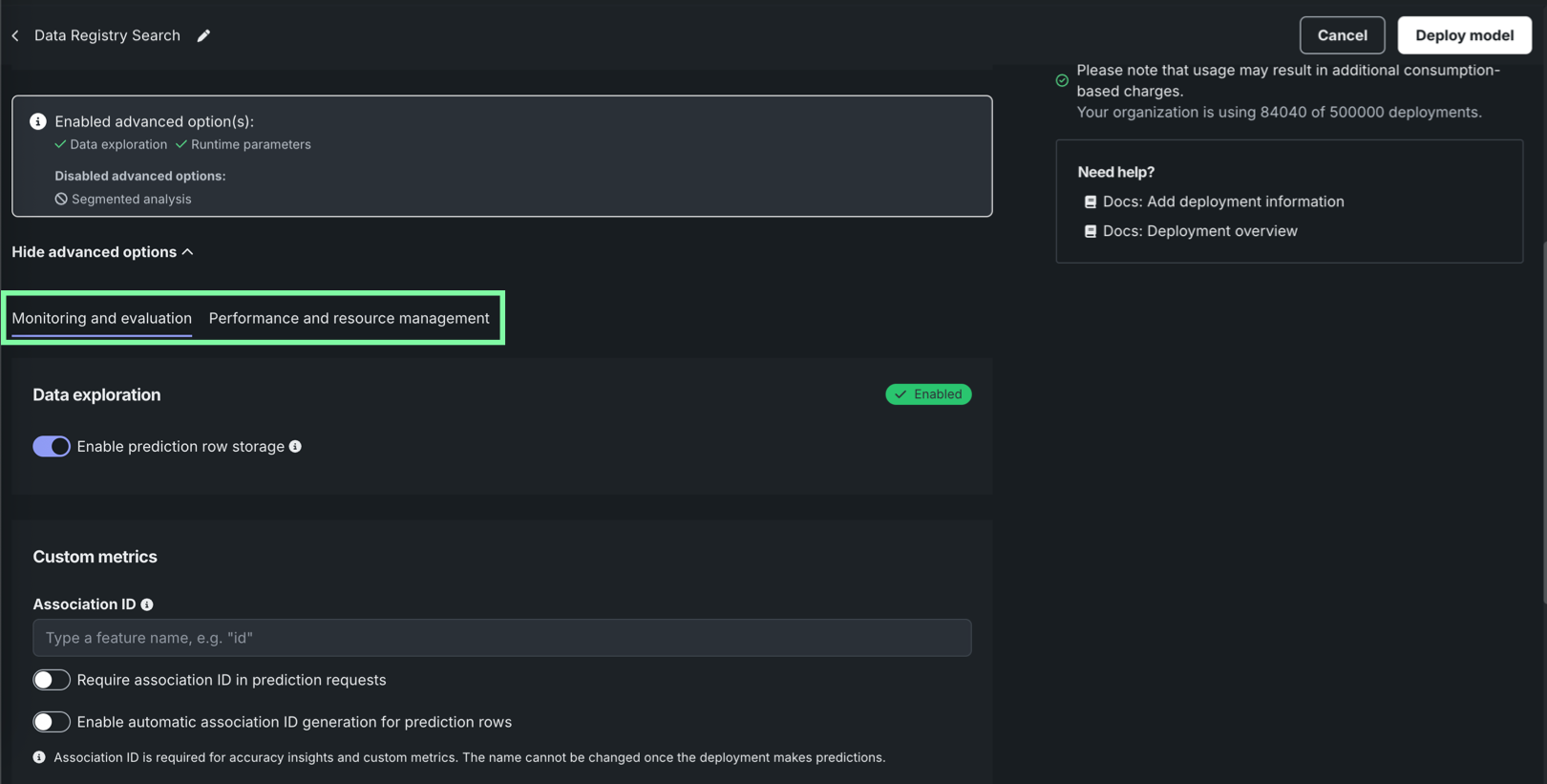
高度なオプション¶
高度なオプションを表示をクリックし、監視と評価およびパフォーマンスとリソースの管理のデプロイ設定を行います。
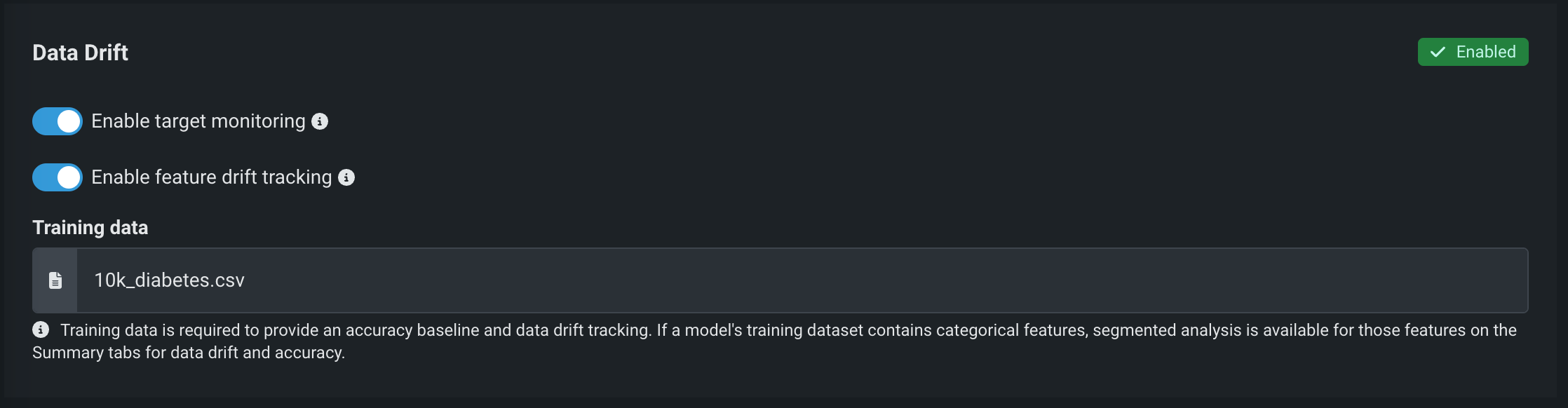
データドリフト¶
モデルをデプロイするとき、トレーニングおよび検定に使用するデータセットが予測データと異なっていることがあります。 ドリフト追跡を有効にするには、次の設定を行います。
| 設定 | 説明 |
|---|---|
| 特徴量ドリフト追跡の有効化 | デプロイ内の特徴量ドリフトを追跡するようDataRobotを設定します。 特徴量ドリフト追跡にはトレーニングデータが必要です。 |
| ターゲット監視の有効化 | デプロイ内のターゲットドリフトを追跡するようDataRobotを設定します。 実測値はターゲット監視に必要であり、ターゲット監視は精度監視に必要です。 |
| トレーニングデータ | デプロイで特徴量のドリフト追跡を有効にするために必要です。 |
| 特徴量ドリフト | デプロイで 特徴量ドリフトのために追跡される25の特徴量の選択に使用する戦略を定義します。 |
DataRobotでのドリフトの追跡方法
DataRobotは2種類のドリフトを追跡します。
-
ターゲットドリフト:DataRobotは予測に関する統計情報を蓄積しているため、時間の経過と共にターゲットの分布と値がどのように変化するかを監視することができます。 ターゲット分布の比較の基準として、DataRobotではホールドアウトの予測値の分布を使用します。
-
特徴量ドリフト:DataRobotは予測に関する統計情報を蓄積しているため、時間の経過と共に特徴量の分布と値がどのように変化するかを監視することができます。 サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。 特徴量の分布を比較するためのベースラインとして:
-
500MBより大きいトレーニングデータセットでは、DataRobotはトレーニングデータのランダムサンプルの分布を使用します。
-
500MBより小さいトレーニングデータセットでは、DataRobotはトレーニングデータの100%の分布を使用します。
-
DataRobotは、デフォルトでターゲットと特徴量ドリフト情報を監視し、データドリフトダッシュボードで結果を表示します。 たとえば、監視する必要のない機微データがデプロイに含まれている場合などは、ターゲット監視を有効化と特徴量ドリフト追跡を有効化のトグルを使用して追跡をオフにします。 デプロイのデータドリフトステータスのカスタマイズに関する詳細については、データドリフトページを参照してください。
備考
データドリフト追跡は、デプロイ対応の予測APIルートを使用するデプロイでのみ使用できます(https://example.datarobot.com/predApi/v1.0/deployments/<deploymentId>/predictionsなど)。
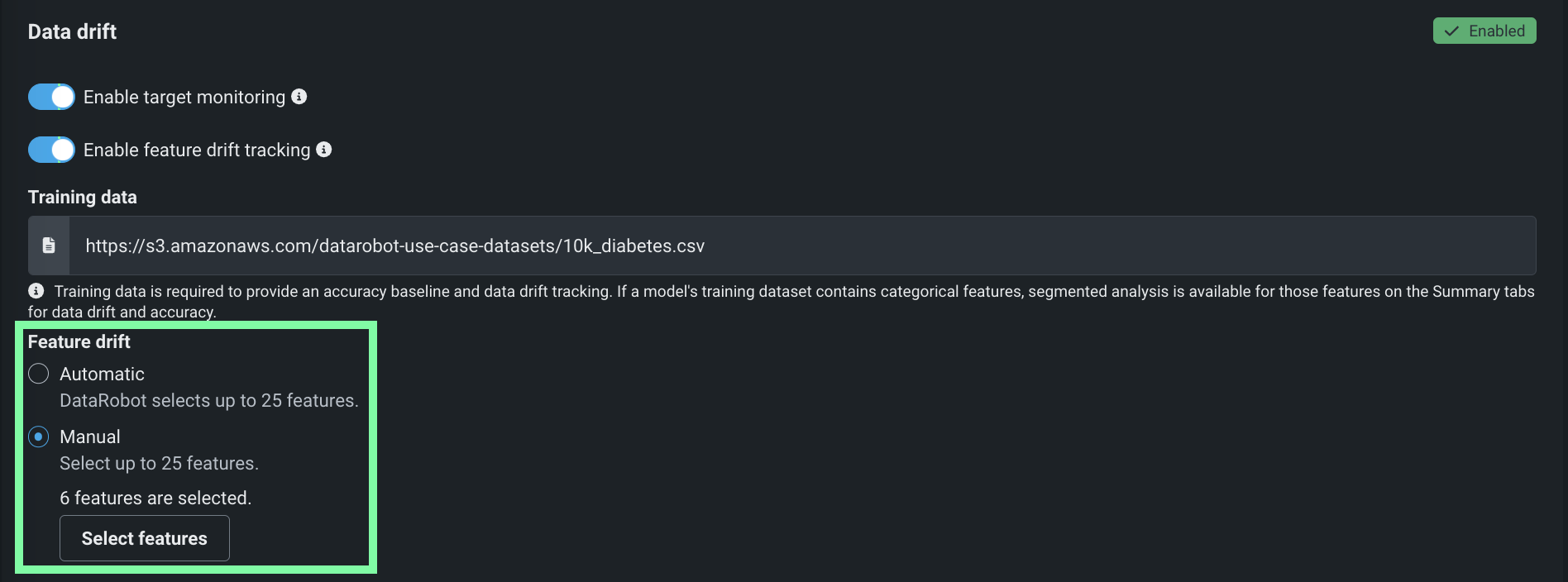
特徴量ドリフトのための特徴量の選択¶
デプロイで特徴量ドリフト追跡を有効にすると、特徴量ドリフトセクションが表示されます。 追跡する25の特徴量を選択するには、次の戦略のいずれかを選択します。
サポートされている特徴量のデータ型
サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。
-
自動:(デフォルト)DataRobotが25の特徴量を選択します。
-
手動:特徴量の選択をクリックし、リストから最大25の特徴量を選択します(有用性順に並べ替え)。

特徴量の手動選択に関する注意事項
特徴量の選択テーブルには、以下の特徴があります。
-
特徴量は、特徴量の有用性が高い順に降順でソートされています。 2番目のソートは、名前のアルファベット順です。
-
すべての特徴量に有用性の値があるわけではなく、一部の特徴量が負の値になる場合があります。
-
外部モデルのデプロイでは、特徴量の有用性値は使用できません。
-
トレーニングデータを持つリーダーボードまたはカスタムモデルのデプロイの場合、テーブルでは、特徴量のインパクトではなく、正規化されたACEが有用性の値として使用されます。
-
テキスト生成モデルのデプロイの場合、テーブルでは割り当てられたスコアが使用されます。ターゲットは1.0、テキスト特徴量は0.9、その他の特徴量は0.1です。
特徴量の手動選択が有効になっているすべてのデプロイでは:
-
選択された特徴量のみがドリフトの追跡対象となります。 特徴量が選択されていない場合、たとえその特徴量が予測リクエストやアップロードされた統計に存在していても、追跡の対象にはなりません。
-
手動選択から自動選択に切り替えた場合、以前に追跡された特徴量が十分に有用でない場合、ドリフト追跡から削除される可能性があります。
-
自動と手動の切り替えや、追跡対象の特徴量の追加や削除を行っても、累積された特徴量のドリフト統計は削除されません。
ドリフト追跡の特徴量を手動で選択する場合:
-
使用可能な特徴量は、チャンピオンモデルプロジェクトの特徴量セット(該当する場合)またはトレーニングデータセット(該当する場合)から取得されます。
-
サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。
-
チャンピオンとしてインポートされたモデルパッケージを使用したデプロイの場合、サポートされる特徴量は、(.mlpkgファイルで)事前に計算されたベースラインを持つ特徴量のみです。
-
リーダーボードモデルをチャンピオンとしてデプロイした場合:
-
非時系列モデルでは、プロジェクトの特徴量セットでサポートされている特徴量は、モデルの特徴量セットに含まれていない場合でも利用できます。
-
セグメント化されていない時系列モデルでは、モデルの特徴量セットでサポートされている特徴量はすべて利用できます。
-
セグメント化された時系列モデルでは、特徴量のドリフトはサポートされていません。
-
-
カスタムモデルをチャンピオンとしてデプロイした場合:
-
非時系列モデルでは、トレーニングデータでサポートされている列はすべて使用できます。
-
時系列モデルでは、トレーニングデータでサポートされている列はすべて使用できます。
-
-
外部モデルを使ったデプロイの場合、トレーニングデータでサポートされている列はすべて使用できます。
モデルの置換時:
-
現在選択されている特徴量は、サポートされていない場合、または置換モデルに含まれている場合、置換後に削除されます。
-
現在選択されているどの特徴量も置換モデルで追跡の対象となっていない場合、特徴量のドリフトは無効化されます。
-
これらの変更のいずれかが置換後に発生する場合、モデル置換検定の警告が表示されます。
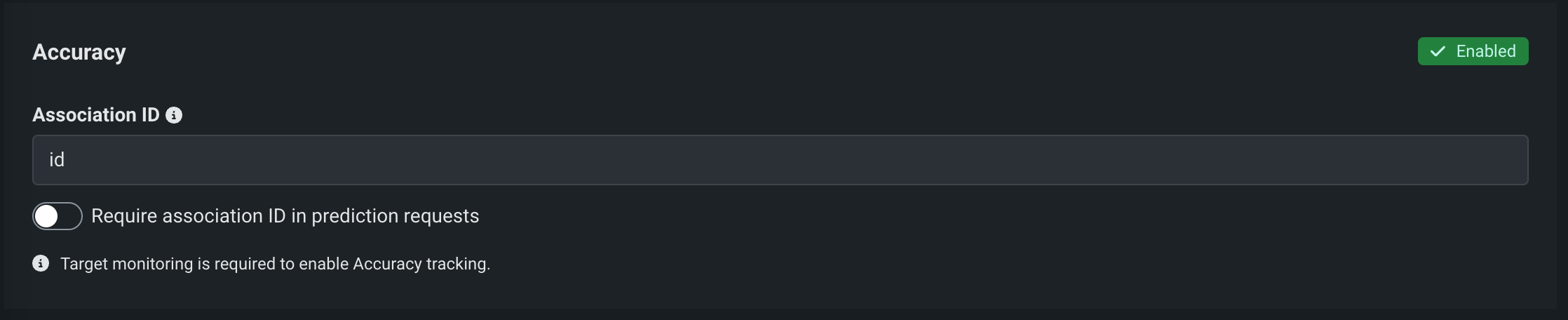
精度¶
必要となる設定を 精度タブに設定すると、標準的な統計的手法とエクスポート可能な可視化によって、時間の経過に伴うモデルデプロイのパフォーマンスを分析できます。
| 設定 | 説明 |
|---|---|
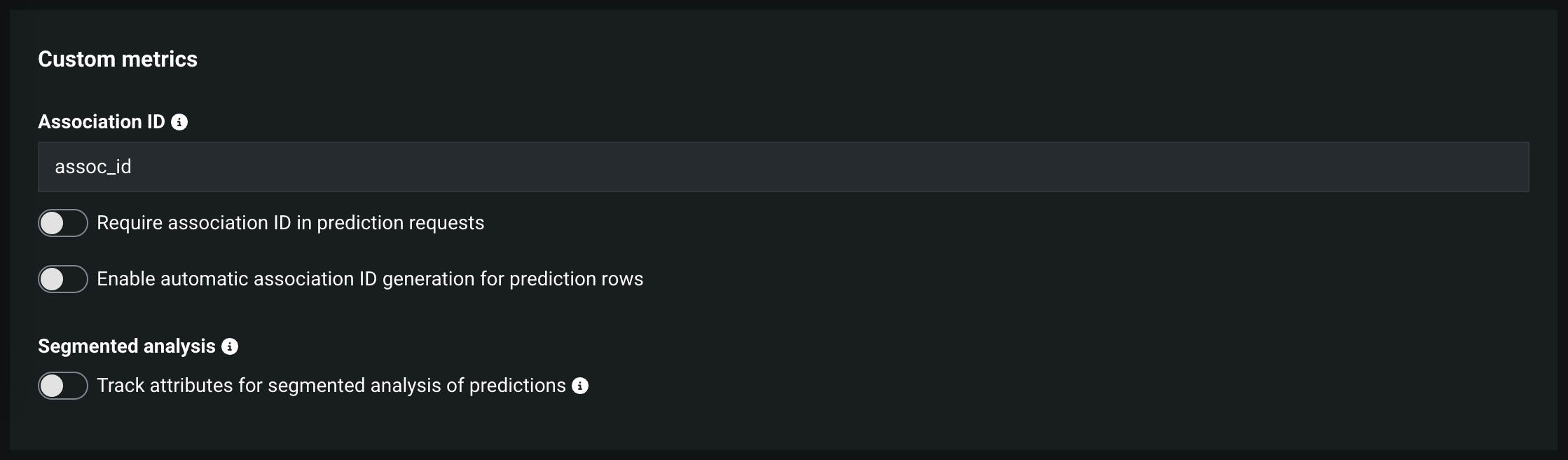
| 関連付けID | モデルの予測データセット内の関連付けIDを含む列名を指定します。 関連付けIDはデプロイの精度追跡の設定で必要となります。 関連付けIDは予測データセットの識別子として機能するので、後で出力データ(「実測値」)を予測に紐づけることができます。 |
| 予測リクエストで関連付けIDを要求 | 関連付けIDフィールドに入力した列名に一致する列名が予測データセットに存在する必要があります。 有効化したときに、列がない場合はエラーが表示されます。 デプロイを作成ボタンは関連付けIDを入力するか、このトグルを無効にするまで非アクティブとなります。 これは、予測行での関連付けIDの自動生成を有効にすると同時に有効にすることはできません。 |
| 予測行での関連付けIDの自動生成を有効にする | 関連付けID列の名前が定義されている場合、関連付けIDの値を自動的に設定できます。 これは、予測リクエストで関連付けIDを要求と同時に有効にすることはできません。 |
| 時系列モデルで自動実測値フィードバックを有効にする | 関連付けIDが示された時系列デプロイでは、この設定によって実測値の自動送信が可能になり、UIやAPIから手動で送信する必要がなくなります。 有効にした場合、予測の生成に使用されるデータから実測値を抽出できます。 各予測リクエストが送信されると、DataRobotは特定の日付の実測値を抽出できます。 これは、予測行を予測に送信すると、履歴データが含まれるためです。 この履歴データは、前の予測リクエストの実測値として機能します。 |
重要:監視エージェントと監視ジョブの関連付けID
予測を精度追跡に含めるには、予測を行う前に関連付けIDを設定する必要があります。 エージェントによって監視され、チャレンジャー(およびチャレンジャーの監視ジョブ)を含む外部モデルのデプロイの場合、モデル_と_そのチャレンジャーの精度を報告するには、関連付けIDを__DataRobot_Internal_Association_ID__にする必要があります。
データ探索¶
予測行ごとの履歴保存を有効にして、 データ探索タブをアクティブにします。 ここから、デプロイの保存されたトレーニングデータ、予測データ、および実測値をエクスポートして、 カスタム指標タブまたはDataRobotの外部で、カスタムビジネスまたはパフォーマンス指標を計算し監視します。

| 設定 | 説明 |
|---|---|
| 予測行ごとの履歴保存を有効化 | 予測データの保存を有効にします。デプロイの予測データを保存およびエクスポートしてカスタム指標で使用するために必要な設定です。 |
チャレンジャー分析¶
DataRobotは、行レベルでデプロイの予測リクエストデータを安全に保存できます(外部モデルのデプロイではサポートされていません)。 この設定は、チャレンジャータブを使用するすべてのデプロイで有効にする必要があります。 チャレンジャー分析の有効化に加え、保存された予測リクエスト行へアクセスすると、予測を詳細に監査し、そのデータを使用して運用上の問題のトラブルシューティングを行うことができます。 たとえば、データを調べることによって、異常な予測結果やデータセットが不正な形式であった理由を理解できます。
備考
DataRobotの担当者に連絡して、データのセキュリティ、プライバシー、保持方法の詳細を確認するか、予測監査の必要有無について話し合ってください。

| 設定 | 説明 |
|---|---|
| チャレンジャー分析を有効にする | チャレンジャーモデルの使用を有効化すると、デプロイ後のモデルを比較し、必要に応じてチャンピオンモデルを置換できます。 有効にすると、デプロイに対して行われた予測リクエストがDataRobotによって収集されます。 予測の説明は保存されません。 |
重要
予測リクエストが収集されるのは、予測データがCSVやJSONなどのDataRobotで解釈可能な有効なデータ形式である場合のみであることに注意してください。 有効なデータ形式を含む失敗した予測リクエストも収集されます(欠損する入力特徴量など)。
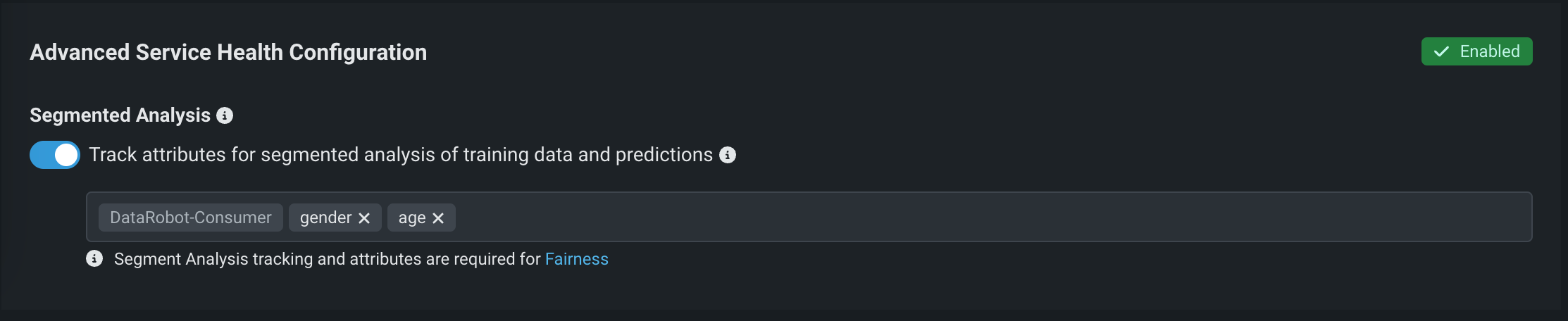
サービスの正常性に関する詳細設定¶
セグメント化された分析により、デプロイ時のトレーニングおよび予測データ要求の運用上の問題点が識別されます。 DataRobotでは、データのドリフトと精度の統計を固有のセグメント属性と値にフィルタリングすることでドリルダウン分析が可能になります。
| 設定 | 説明 |
|---|---|
| トレーニングデータと予測に対するセグメント化された分析のために属性を追跡 | DataRobotがカテゴリー特徴量などでセグメントごとにデプロイ予測を監視できるようにします。 この設定では、トレーニングデータが必要であり、公平性の監視を有効にする必要があります。 |
カスタム指標¶
生成AIのデプロイでは、データ品質とカスタム指標を監視するためにこれらの設定を行います。
| 設定 | 説明 |
|---|---|
| 関連付けID | モデルの予測データセット内の関連付けIDを含む列名を指定します。 関連付けIDはデプロイの精度追跡の設定で必要となります。 関連付けIDは予測データセットの識別子として機能するので、後で出力データ(「実測値」)を予測に紐づけることができます。 |
| 予測リクエストで関連付けIDを要求 | 関連付けIDフィールドに入力した列名に一致する列名が予測データセットに存在する必要があります。 有効化したときに、列がない場合はエラーが表示されます。 デプロイを作成ボタンは関連付けIDを入力するか、このトグルを無効にするまで非アクティブとなります。 これは、予測行での関連付けIDの自動生成を有効にすると同時に有効にすることはできません。 |
| 予測行での関連付けIDの自動生成を有効にする | 関連付けID列の名前が定義されている場合、関連付けIDの値を自動的に設定できます。 これは、予測リクエストで関連付けIDを要求と同時に有効にすることはできません。 |
| トレーニングデータと予測に対するセグメント化された分析のために属性を追跡 | DataRobotがカテゴリー特徴量などでセグメントごとにデプロイ予測を監視できるようにします。 この設定では、トレーニングデータが必要であり、公平性の監視を有効にする必要があります。 |
公平性¶
公平性を使用すると、デプロイの設定を行うことで、モデルの予測動作のバイアスを確認できます。 モデルのデプロイ以前に公平性設定を定義した場合、フィールドは自動的に入力されます。 追加情報については、公平性テストの定義に関するセクションを参照してください。
| 設定 | 説明 |
|---|---|
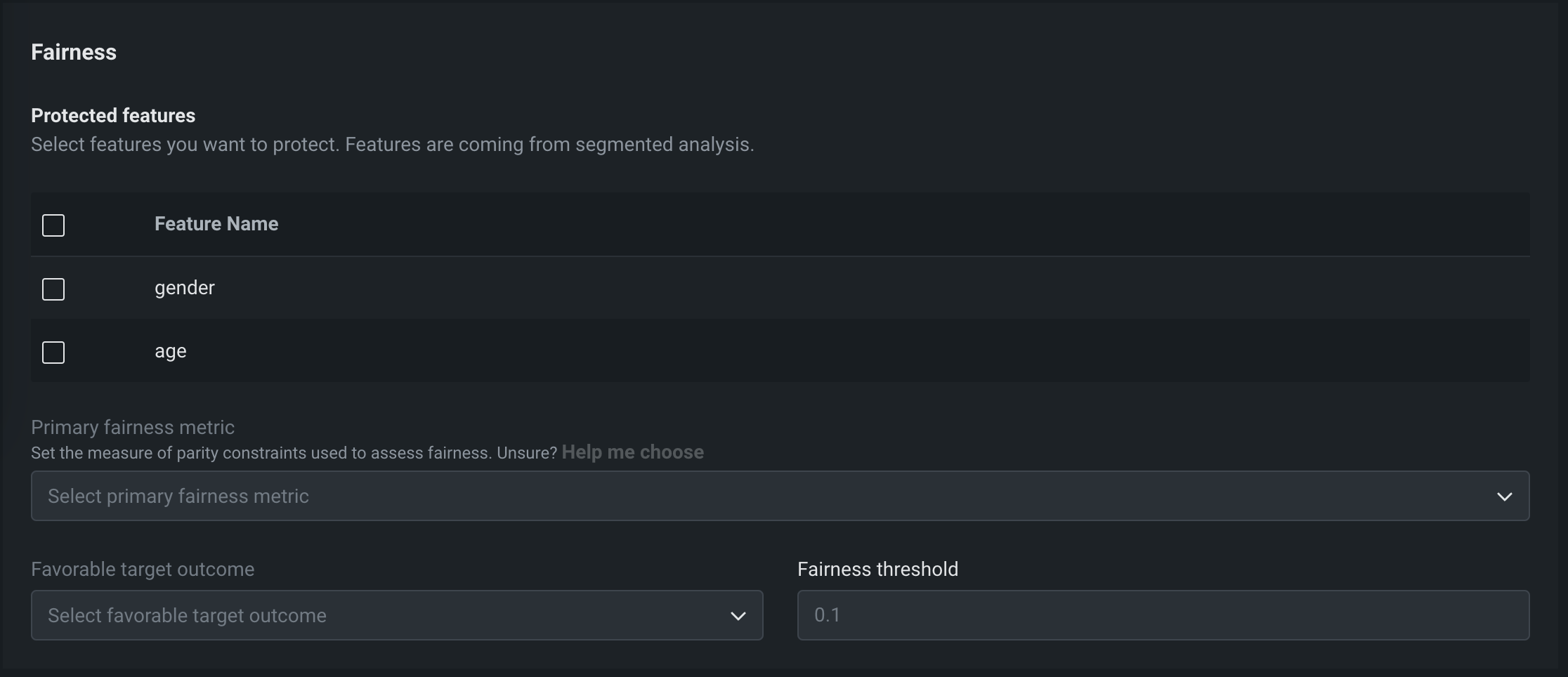
| 保護されている特徴量 | モデル予測の公平性を測定する際の基準となるデータセット列を特定します。これはカテゴリー列である必要があります。 |
| プライマリー公平性指標 | 公平性の評価に使用する平等性の制約に関する統計指標を定義。 |
| 好ましいターゲット結果 | ターゲットと比較して、保護されたクラスにとって好ましいと認識される結果の値を定義します。 |
| 公平性のしきい値 | 公平性のしきい値を定義して、保護されたクラスごとに適切な公平性の範囲内でモデルが実行されるかどうかを測定します。 |
ランタイムパラメーター¶
プレビュー
デプロイでカスタムモデルのランタイムパラメーターを編集する機能は、デフォルトでオンになっています。
機能フラグ: デプロイでカスタムモデルのランタイムパラメーターの編集を有効にする
カスタムモデルの場合、ランタイムパラメーターセクションにアクセスできます。 ランタイムパラメーターは、標準的な環境変数としてコンテナに挿入されます。単純な型の場合、プレフィックスやJSONの解析は不要です。つまり、開発者はdatarobot-drumライブラリやその関連依存関係に頼ることなく、標準的なPythonメソッド(例:os.getenv)を使用してパラメーターを取得できます。 ワークショップのUIを通じて作成されたパラメーターは、新しいコードバージョンをアップロードする際にも保持およびマージされ、シームレスな開発フローが確保されます。
このセクションから、デプロイ前にこれらのパラメーターを管理します。 これを行うには、 編集をクリックします。
ランタイムパラメーターテーブルで、値を編集します。 個別の変更を破棄するには、 変更を元に戻すをクリックします。

ランタイムパラメーターを編集した場合は、変更を保存するために保存をクリックします。
ランタイムパラメーターを定義し、カスタムモデルコードで使用する方法の詳細については、カスタムモデルのランタイムパラメーターを定義するのドキュメントを参照してください。
高度な予測設定¶
高度な予測設定セクションでは、デプロイされるモデルのプロジェクトタイプとモデルがデプロイされる予測環境に依存した設定を行うことができます。
- DataRobotのサーバーレス環境にモデルをデプロイする場合、予測自動スケーリング設定を行うことができます。
- 特徴量探索プロジェクトからモデルをデプロイする場合、セカンダリーデータセットの設定を行うことができます。
DataRobotサーバーレス予測環境における予測間隔
DataRobotサーバーレス予測環境において、時系列予測間隔を含む予測を作成するには、 モデルパッケージを登録する際に、事前に計算された予測間隔を含める必要があります。 予測間隔を事前に計算しない場合、登録されたモデルから得られるデプロイは、 予測間隔の有効化をサポートしません。
予測自動スケーリング設定¶
この環境でオンデマンド予測を設定するには、高度なオプションを表示をクリックし、自動スケーリングオプションまでスクロールダウンします。
自動スケーリングでは、着信トラフィックに基づいてデプロイ内のレプリカの数が自動的に調整されます。 トラフィックの多い時間帯には、パフォーマンスを維持するためにレプリカが追加されます。 トラフィックの少ない時間帯には、コストを削減するためにレプリカが削除されます。 これにより、手動によるスケーリングが不要になると同時に、デプロイがさまざまな負荷に効率的に対応できるようになります。
自動スケーリングを設定するには、以下の設定を変更します。 DataRobotモデルの場合、しきい値40%のCPU使用率に基づいて自動スケーリングが実行されます。

| フィールド | 説明 |
|---|---|
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
自動スケーリングを設定するには、スケーリングのトリガーとなる指標を選択します。
-
CPU使用率:アクティブなレプリカ全体の平均CPU使用率のしきい値を設定します。 CPU使用率がこのしきい値を超えると、レプリカが自動的に追加され、処理能力が向上します。
-
HTTPリクエストの同時実行:処理される同時リクエスト数のしきい値を設定します。 たとえば、しきい値が5の場合、処理中の同時リクエストが5つ検出されると、レプリカが追加されます。
選択したしきい値を超えると、現在の負荷を処理するために必要な追加のレプリカ数が計算されます。 選択された指標が継続的に監視され、リソース使用量を最小限に抑えながら最適なパフォーマンスを維持するようにレプリカ数が調整されます。
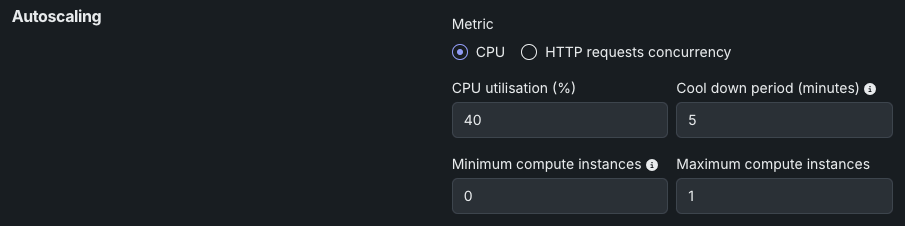
CPU使用率の設定は以下のとおりです。
| フィールド | 説明 |
|---|---|
| CPU使用率(%) | スケーリングのトリガーとなるCPU使用率の目標値を設定します。 CPU使用率がこのしきい値に達すると、さらにレプリカが追加されます。 |
| クールダウン期間(分) | スケールダウンイベント後、次のスケールダウンが発生するまでの待機時間を設定します。 これにより、指標が不安定な場合の急激なスケーリングの変動を防ぐことができます。 |
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
HTTPリクエストの同時実行に関する設定は以下のとおりです。
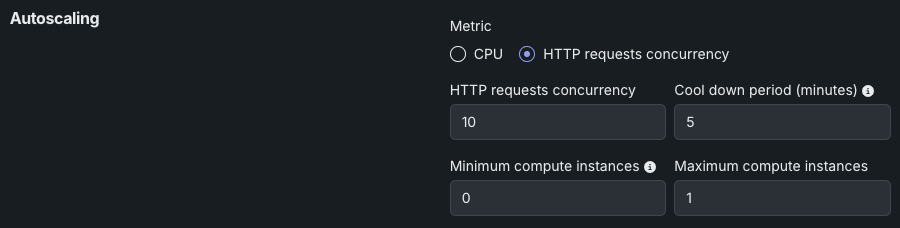
| フィールド | 説明 |
|---|---|
| HTTPリクエストの同時実行 | スケーリングのトリガーに必要な同時リクエスト数を設定します。 同時リクエストがこのしきい値に達すると、さらにレプリカが追加されます。 |
| クールダウン期間(分) | スケールダウンイベント後、次のスケールダウンが発生するまでの待機時間を設定します。 これにより、指標が不安定な場合の急激なスケーリングの変動を防ぐことができます。 |
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
プレミアム機能:常時予測
常時予測はプレミアム機能です。 最小のコンピューティングインスタンスを設定するには、デプロイの自動スケーリング管理が必要です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ: デプロイの自動スケーリング管理を有効にする
コンピューティングインスタンスの設定
DataRobotモデルデプロイの場合:
- デフォルトの最小値は0で、最大値は3です。
- 最小値と最大値は、組織の
max_compute_serverless_prediction_api設定から取得されます。
カスタムモデルデプロイの場合:
- デフォルトの最小値は0で、最大値は1です。
- 最小値と最大値は、組織の
max_custom_model_replicas_per_deployment設定から取得されます。 - GPU(LLMの場合)で実行する場合、最小値は常に1よりも大きくなります。
さらに、高可用性のシナリオの場合:
- 最小コンピューティングインスタンス数の設定は2以上である必要があります。
- これには、ビジネスクリティカルまたは消費ベースの価格設定が必要です。
コンピューティングインスタンスの設定を更新する
デプロイ後にモデルで使用できるコンピューティングインスタンスの数を更新する必要がある場合、 予測設定 タブでこれらの設定を変更できます。
特徴量探索でのセカンダリーデータセット¶
特徴量探索は、多数のデータセットから新しい特徴量を識別し生成します。このため、多数のデータセットを1つに統合するために手動で特徴量エンジニアリングを実行する必要がなくなります。 この処理は、データセットとそのデータセット内の特徴量の関係性に基づきます。 DataRobotは、このような関係性を構築および視覚化できる直感的な関係性エディターを提供します。 グラフおよび含まれるデータセットがDataRobotの特徴量探索エンジンによって分析され、特徴量エンジニアリング「レシピ」が決定されます。そのレシピから、トレーニングおよび予測に使用するセカンダリー特徴量が生成されます。 デプロイの設定中に、選択されたセカンダリーデータセットの設定を変更できます。

| 設定 | 説明 |
|---|---|
| セカンダリーデータセットの設定 | データセット設定をプレビューするか、データセット設定を変更するオプションが存在します。 デフォルトでは、プロジェクトを構築する際に使用された関係性で定義されたセカンダリーデータセット設定を使用して予測が作成されます。 他の設定を選択するには、新しいプライマリーデータセットをアップロードする前に変更をクリックします。 |
クォータ管理¶
クォータ管理設定には、DataRobotおよび外部デプロイの使用制限を管理および実施するためのコントロールが用意されています。 これにより、デプロイのオーナーは、共有されたデプロイインフラストラクチャへのアクセスを制御し、異なるチームやアプリケーション間で公平なリソース割り当てを確保し、単一のユーザーやエージェントがリソースを独占するのを防ぐことができます。
クォータポリシーの適用
クォータポリシーの変更が適用されるまでに最大5分かかる場合があります。 この遅延は、Gatewayが5分ごとにクォータキャッシュを更新するために発生します。
クォータ管理セクションで、 をクリックし、デプロイのクォータ(レート制限)設定を変更します。
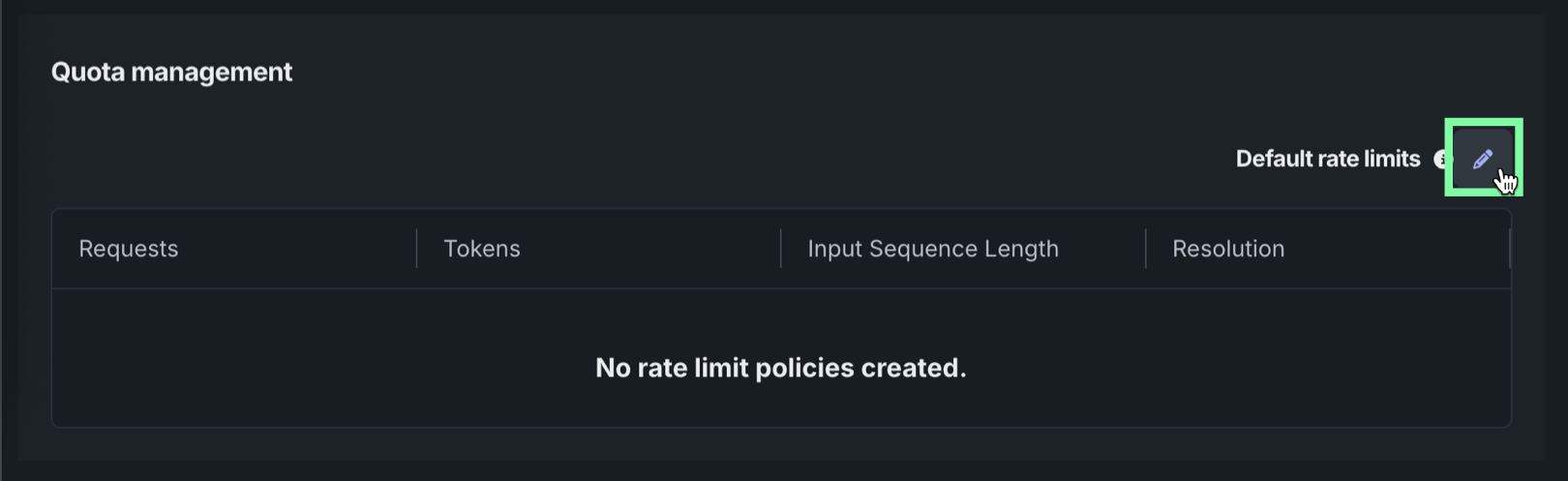
時間ベースの指標で時間の単位(分、時間、または日)を設定します。 選択した単位は、ここで定義された指標ベースの各クォータに適用されます。 次に、指標を追加をクリックして設定を開始します。
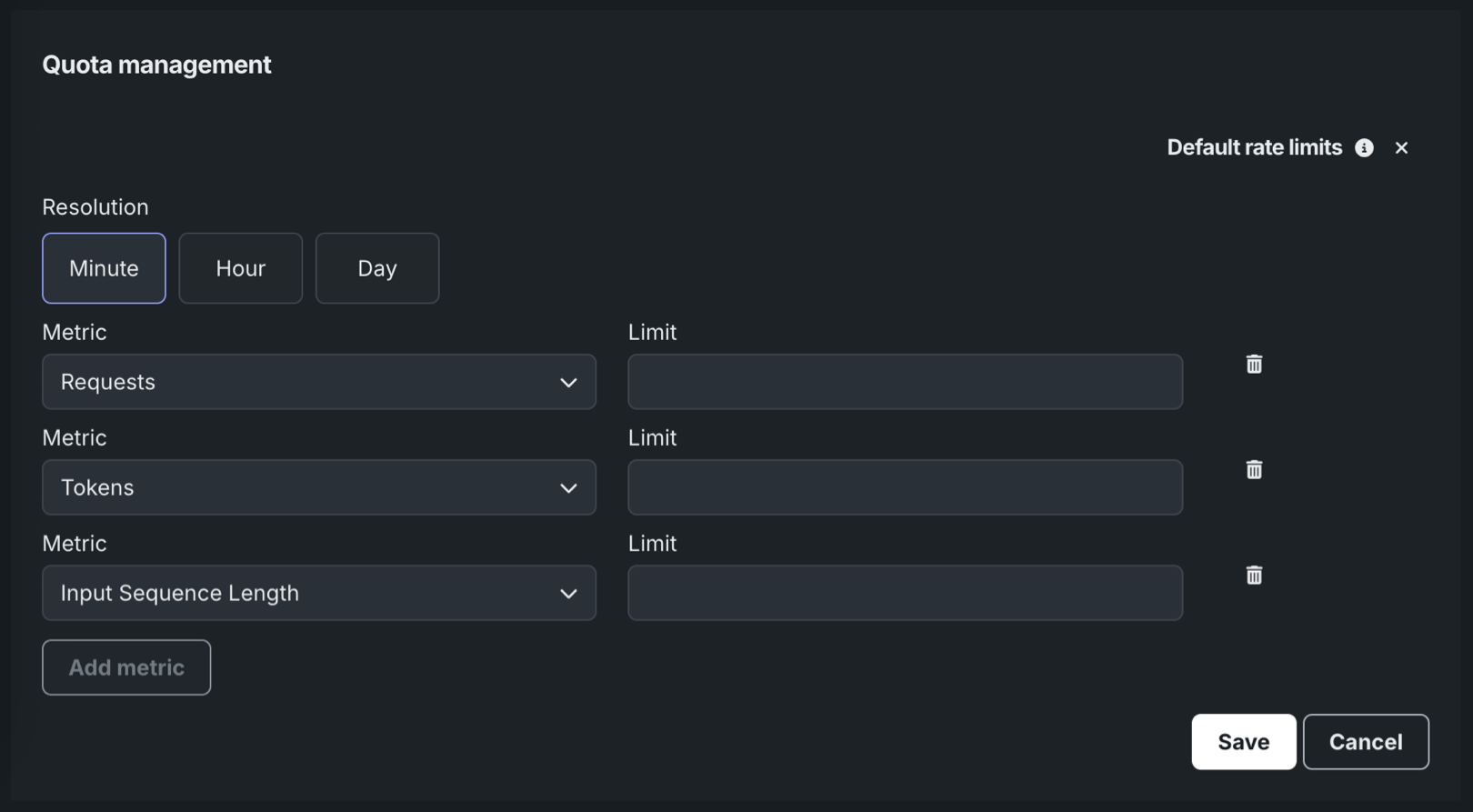
新しいクォータ行で、指標を選択し、制限を入力します。 制限は、単位設定で選択された時間枠で評価されます。 クォータ設定では、次の3つの主要な指標に対する制限を定義できます。
| 指標 | 説明 |
|---|---|
| リクエスト | 時間単位の設定によって定義される、選択された時間枠内で、デプロイ済みモデルが処理できる予測リクエストの数を制御します。 デフォルトは毎分300リクエストです。 |
| トークン | 時間単位の設定によって定義される、選択された時間枠内で、デプロイ済みモデルが処理できるトークンの数を制御します。 この制限には、すべてのタイプのトークン(入力と出力)が含まれます。 |
| 入力シーケンス長 | モデルに送信されるプロンプトまたはクエリーのトークン数を制御します。 |
組織のニーズに応じて、1つ以上の指標にこのプロセスを実行し、保存をクリックします。
指標を追加
利用可能なすべての指標の行が表示されるまで、指標を追加をクリックするたびに新しいクォータ行が表示されます。 行を削除するには、削除アイコン をクリックします。
モデルのデプロイ¶
使用可能なデータを追加し、モデルが完全に定義されたら、画面上部にあるデプロイを作成をクリックします。
備考
モデルをデプロイボタンが無効になっている場合は、関連付けIDを指定するか(精度監視の有効化に必要)、予測リクエストで関連付けIDを要求をオフに切り替えてください。
デプロイの作成中というメッセージが表示され、DataRobotがデプロイを作成中であることを示します。 デプロイが作成されると、概要タブが表示されます。
デプロイ名の左側にある矢印をクリックすると、デプロイインベントリに戻ります。