再トレーニングジョブをの作成¶
手動またはテンプレートから、コードベースの再トレーニングポリシーを実行するジョブを追加します。 再トレーニングジョブを表示および追加するには、ジョブ > 再トレーニングタブに移動し、以下の操作を行います。
-
新しい再トレーニングジョブを手動で追加するには、+ 新しい再トレーニングジョブを追加(またはジョブパネルが開いている場合は最小化された追加ボタン )をクリックします。
-
テンプレートから再トレーニングジョブを作成するには、追加ボタンの横にある をクリックし、再トレーニングの下にあるテンプレートから新規作成をクリックします。
新しいジョブがアセンブルタブに開きます。 選択した作成オプションに応じて、以下の表でリンクされている設定手順に進みます。
| 再トレーニングジョブタイプ | 説明 |
|---|---|
| 新しい再トレーニングジョブを追加 | コードベースの再トレーニングポリシーを実装するジョブを手動で追加します。 |
| テンプレートから新規作成 | DataRobotが提供するテンプレートからジョブを追加して、コードベースの再トレーニングポリシーを実装します。 |
再トレーニングジョブにはメタデータが必要
すべての再トレーニングジョブには、再トレーニングポリシーをデプロイおよび再トレーニングポリシーに関連付けるためのmetadata.yamlファイルが必要です。
新しい再トレーニングジョブを追加¶
コードベースの再トレーニングのジョブを手動で追加するには:
-
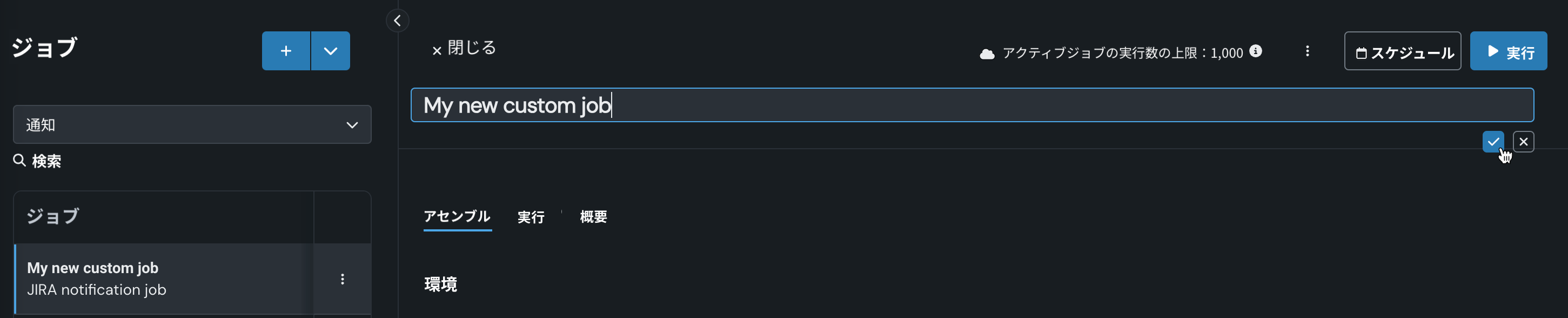
新しいジョブのアセンブルタブで、ジョブ名(または編集アイコン )をクリックして新しいジョブ名を入力し、確認 をクリックします。
-
環境セクションで、ジョブの基本環境を選択します。
利用可能なドロップイン環境はDataRobotのインストール形態によって異なりますが、一般的に利用可能なパブリックドロップイン環境とDRUMリポジトリのテンプレートを以下の表に示します。 DataRobotのインストール形態によっては、これらの環境のPythonバージョンが異なる場合があり、さらに非公開の環境が利用できる場合もあります。
ドロップイン環境のセキュリティ
2025年3月にリリースされたマネージドAIプラットフォームから、ほとんどの汎用DataRobotカスタムモデルのドロップイン環境は、セキュリティが強化されたコンテナイメージになりました。 カスタムジョブの実行にセキュリティが強化された環境が必要な場合、POSIX-shell標準に準拠したシェルコードのみがサポートされます。 POSIXシェル標準に準拠したセキュリティ強化環境では、限られたシェルユーティリティのみがサポートされています。
ドロップイン環境のセキュリティ
セルフマネージドAIプラットフォームのリリース11.0から、ほとんどの汎用DataRobotカスタムモデルのドロップイン環境は、セキュリティが強化されたコンテナイメージになりました。 カスタムジョブの実行にセキュリティが強化された環境が必要な場合、POSIX-shell標準に準拠したシェルコードのみがサポートされます。 POSIXシェル標準に準拠したセキュリティ強化環境では、限られたシェルユーティリティのみがサポートされています。
環境名と例 互換性とアーティファクトファイルの拡張子 Python 3.X Pythonベースのカスタムモデルとジョブ。 モデルファイルに requirements.txtファイルを含めることで、必要な依存関係をすべてインストールしてください。Python 3.X GenAIエージェント 生成AIモデル( Text GenerationまたはVector Databaseのターゲットタイプ)Python 3.X ONNXドロップイン ONNXモデルとジョブ( .onnx)Python 3.X PMMLドロップイン PMMLモデルとジョブ( .pmml)Python 3.X PyTorchドロップイン PyTorchモデルとジョブ( .pth)Python 3.X Scikit-Learnドロップイン Scikit-Learnモデルとジョブ( .pkl)Python 3.X XGBoostドロップイン ネイティブXGBoostモデルとジョブ( .pkl)Python 3.X Kerasドロップイン TensorFlow(.h5)がサポートするKerasモデルとジョブ Javaドロップイン DataRobotスコアリングコードモデル( .jar)ドロップイン環境 CARET( .rds)を使ってトレーニングされたRモデル
CARETが推奨するすべてのライブラリをインストールするのに時間がかかるため、パッケージ名でもあるモデルタイプのみがインストールされます(例:brnn、glmnet)。 この環境のコピーを作成し、Dockerfileを修正して、必要なパッケージを追加でインストールします。 この環境をカスタマイズする際のビルド回数を減らすために、# Install caret modelsセクションで不要な行を削除して、必要なものだけをインストールすることもできます。 CARETドキュメントを参照して、モデルの手法がパッケージ名と一致しているかどうかを確認してください。 このリンクをクリックする前にGitHubにログインしてください。scikit-learn
すべてのPython環境には、(必要に応じて)前処理を支援するscikit-learnが含まれていますが、
sklearnモデルで予測を行うことができるのはscikit-learnだけです。 -
ファイルセクションで、カスタムジョブを構築します。 ボックスにファイルをドラッグするか、このセクションのオプションを使用して、カスタムジョブの構築に必要なファイルを作成またはアップロードします。
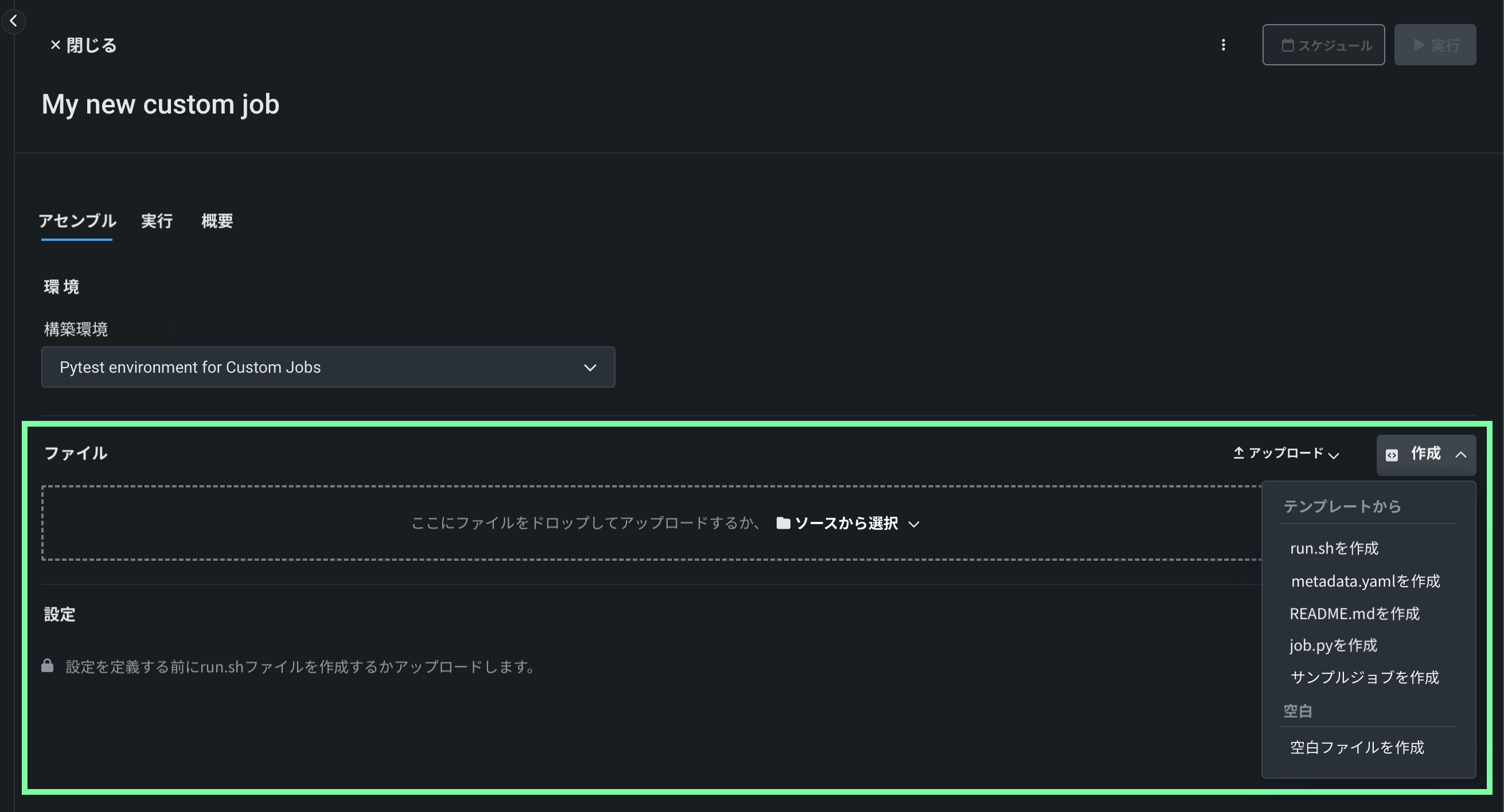
オプション 説明 ソース/アップロードから選択 既存のカスタムジョブファイル( run.sh、metadata.yaml、など)をローカルファイルまたはローカルフォルダーとしてアップロードします。作成 空のファイルまたはテンプレートを含んだファイルとして新しいファイルを作成し、カスタムジョブに保存します。 - run.shを作成:エントリーポイントファイルの基本的で編集可能な例を作成します。
- metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- README.mdを作成:基本的で編集可能なREADMEファイルを作成します。
- job.pyを作成:実行時のパラメーターとデプロイをプリントするための基本的で編集可能なPythonジョブファイルを作成します。
- サンプルジョブを作成:すべてのテンプレートファイルを結合して、基本的で編集可能なカスタムジョブを作成します。 簡単にランタイムパラメーターを設定し、このサンプルジョブを実行できます。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。 次のステップでは、カスタム名とコンテンツを使用して、このように作成されたファイルをエントリーポイントとして識別できます。 新しいファイルを設定したら、保存をクリックします。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
-
設定セクションで、ジョブのエントリーポイントシェル(
.sh)ファイルを設定します。run.shファイルを追加した場合、そのファイルがエントリーポイントになります。それ以外の場合は、ドロップダウンリストからエントリーポイントのシェルファイルを選択する必要があります。 エントリーポイントファイルでは、複数のジョブファイルを調整できます。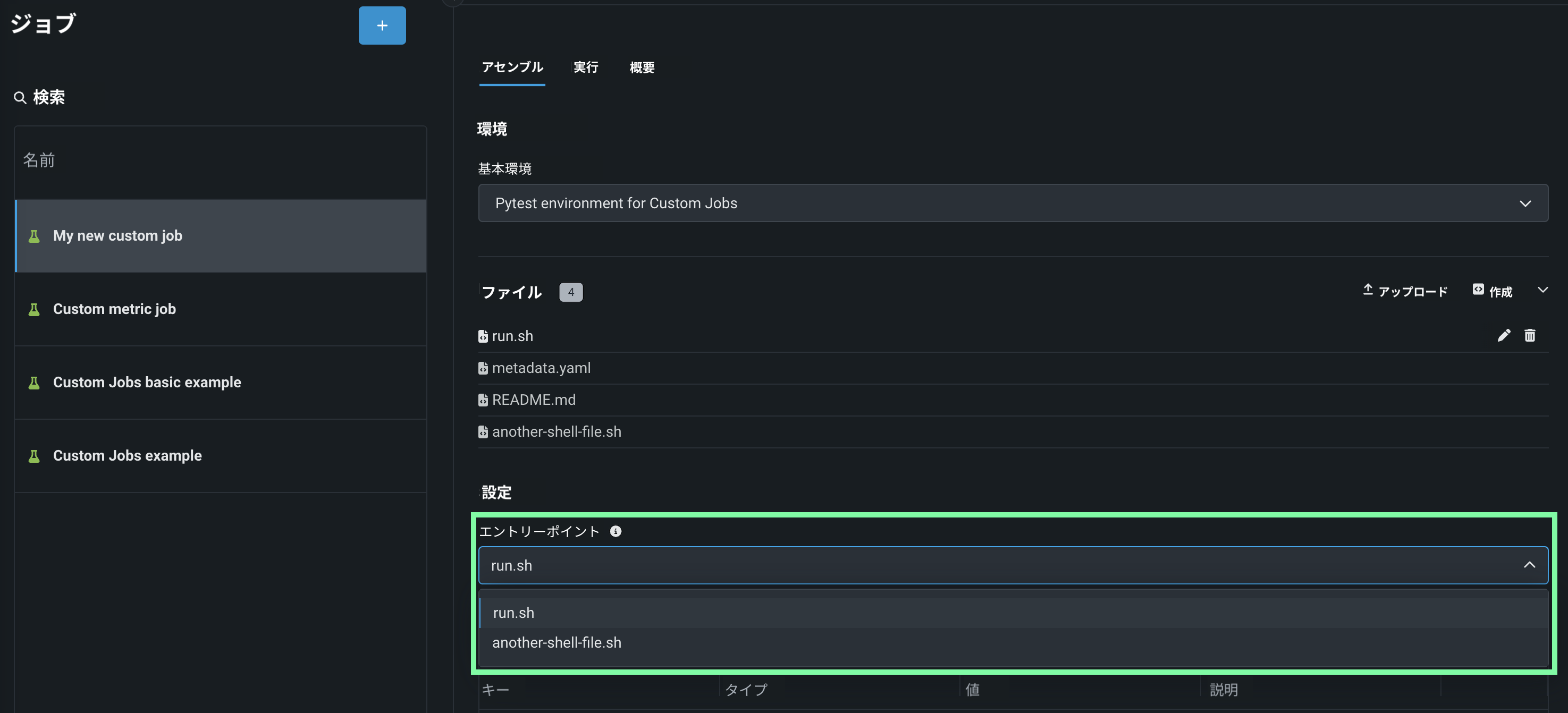
-
リソースセクションのセクションヘッダーの横にある 編集をクリックして、以下を設定します。
プレビュー
カスタムジョブのリソースバンドルは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする
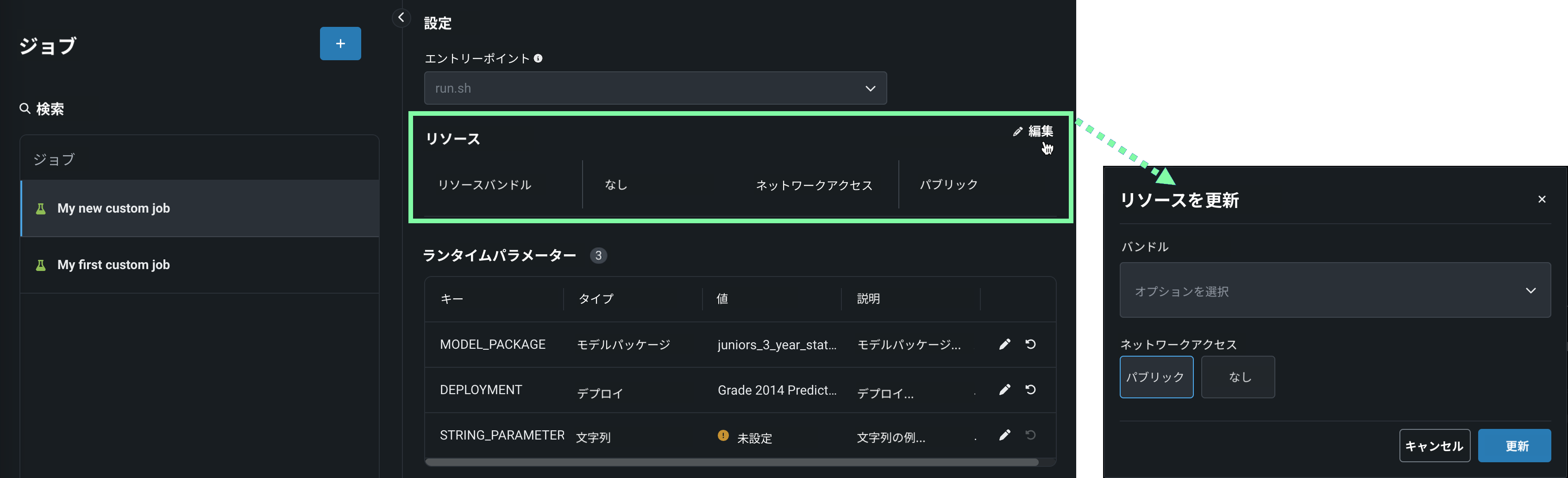
設定 説明 リソースバンドル プレビュー機能 カスタムジョブが実行に使用するリソースを設定します。 ネットワークアクセス カスタムジョブのエグレストラフィックを設定します。 ネットワークアクセスで、以下のいずれかを選択します。 - パブリック:デフォルト設定。 カスタムジョブは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムジョブはパブリックネットワークから隔離され、サードパーティのサービスにアクセスできません。
デフォルトのネットワークアクセス
_マネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでパブリックに設定されていますが、変更可能です。 _セルフマネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでなしに設定されており、制限があります。ただし、管理者は、DataRobotプラットフォームの設定時にこれを変更できます。 詳細については、DataRobotの担当者または管理者にお問い合わせください。
-
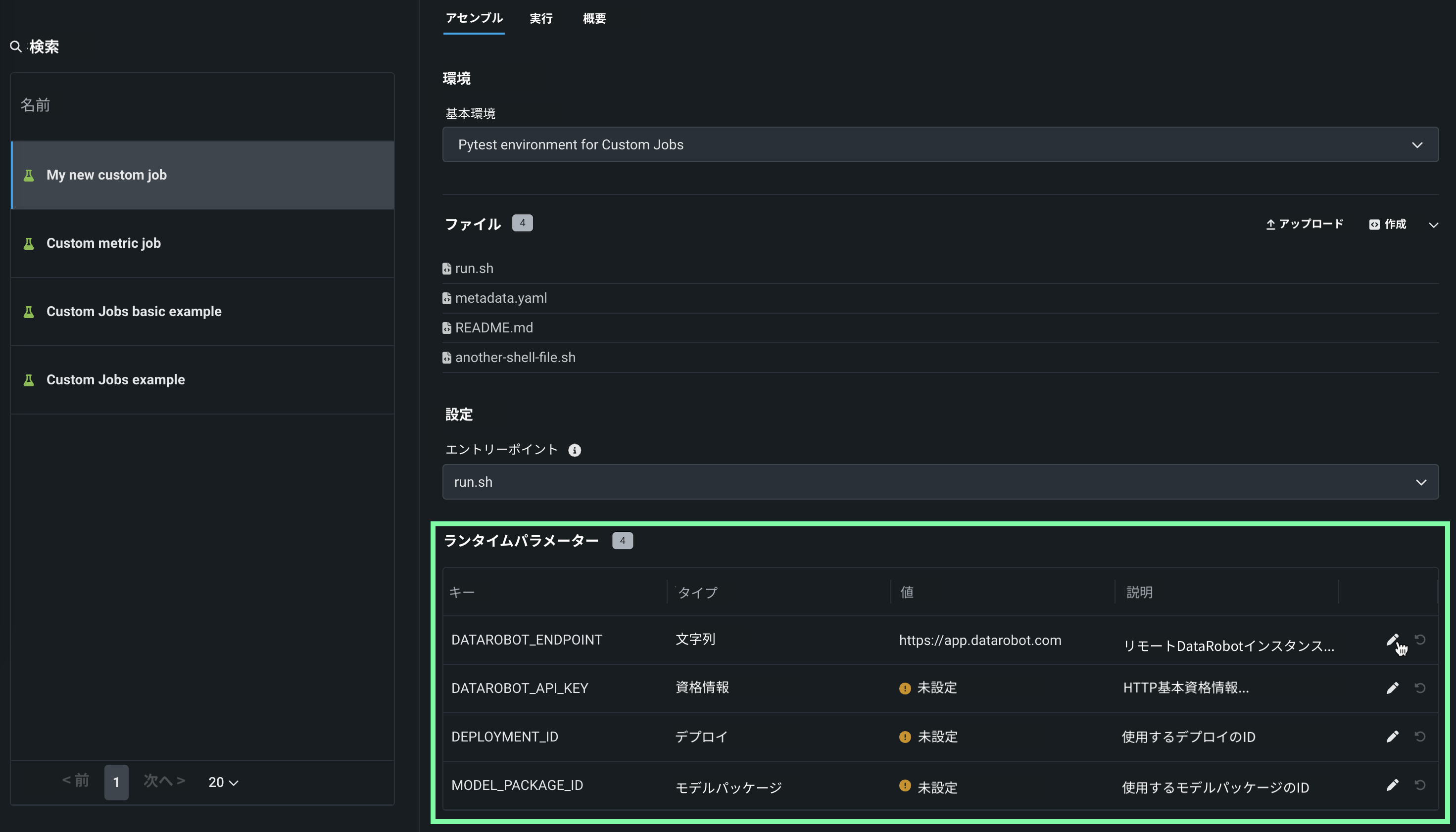
(オプション)ランタイムパラメーターを定義します。 + ランタイムパラメーターを追加をクリックし、名前、タイプ、値、および必要に応じて説明を入力して、新しいランタイムパラメーターを定義します。
または、
metadata.yamlファイルでランタイムパラメーターを定義します。 このファイルのテンプレートは、ファイル > 作成ドロップダウンから入手できます。既存のランタイムパラメーターの場合、 編集をクリックして、パラメーター値の編集、パラメーターの削除、またはパラメーター値のリセットを行います。
-
(オプション)タグ、指標、トレーニングパラメーター、アーティファクトに、追加の キー値を設定します。
テンプレートからの再トレーニングジョブの作成¶
テンプレートから事前に作成された再トレーニングジョブを追加するには:
プレビュー
ジョブテンプレートギャラリーは、デフォルトでオンになっています。
機能フラグ:カスタムジョブのテンプレートギャラリーを有効にする
-
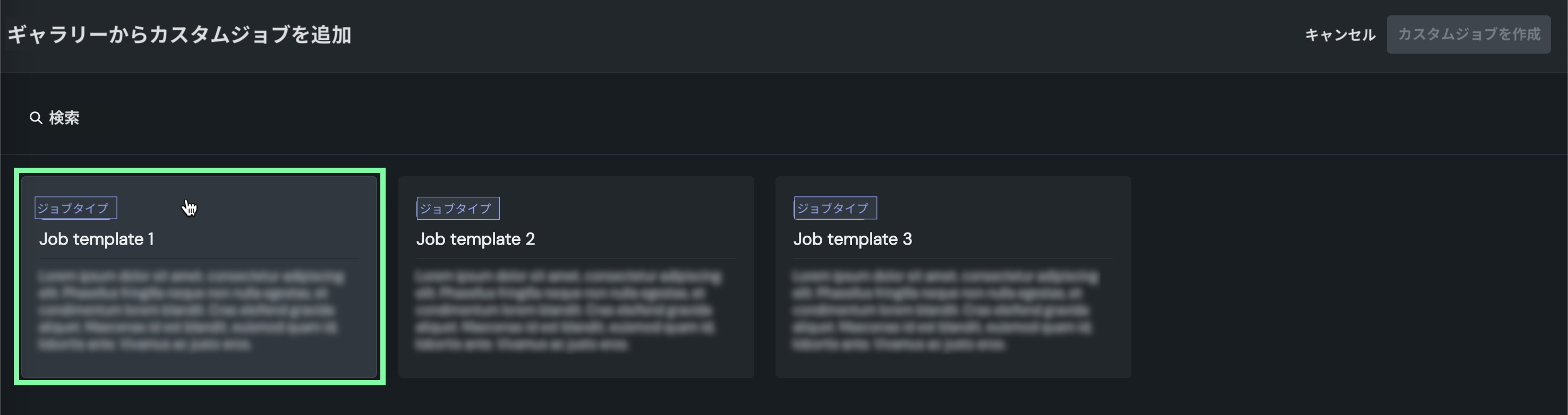
ギャラリーからカスタムジョブを追加パネルで、ジョブの作成に使用するテンプレートをクリックします。
-
ジョブの説明、実行環境、メタデータ、およびファイルを確認してから、カスタムジョブを作成をクリックします。
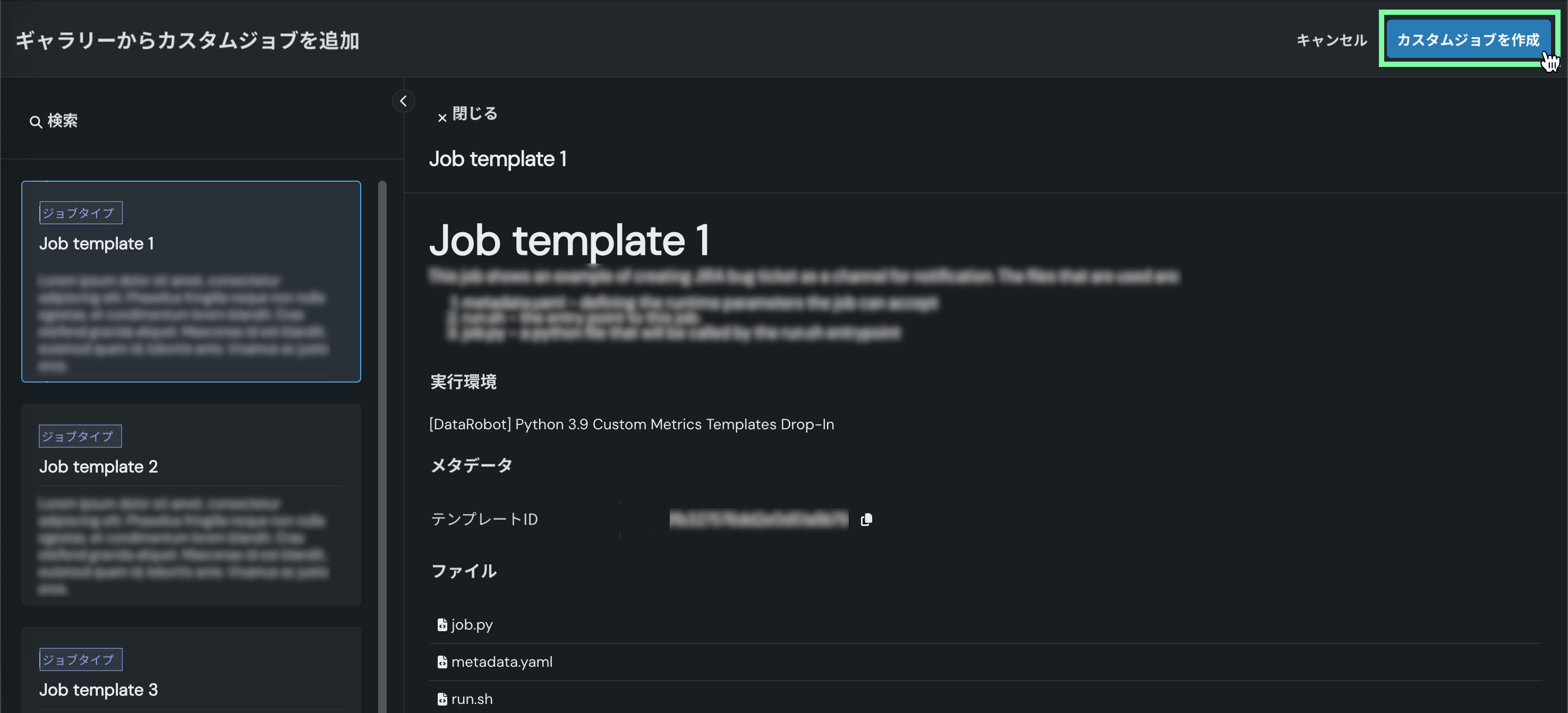
アセンブルタブにジョブが開きます。
-
新しいジョブのアセンブルタブで、ジョブ名(または編集アイコン())をクリックして新しいジョブ名を入力し、確認 をクリックします。
-
環境セクションで、テンプレートで設定されたジョブの基本環境を確認します。
-
ファイルセクションで、テンプレートによってジョブに追加されたファイルを確認します。
-
編集アイコン をクリックすると、テンプレートによって追加されたファイルを変更できます。
-
削除アイコン をクリックすると、テンプレートによって追加されたファイルを削除できます。
-
-
新しいファイルを追加する必要がある場合は、このセクションのオプションを使用して、カスタムジョブの構築に必要なファイルを作成またはアップロードします。
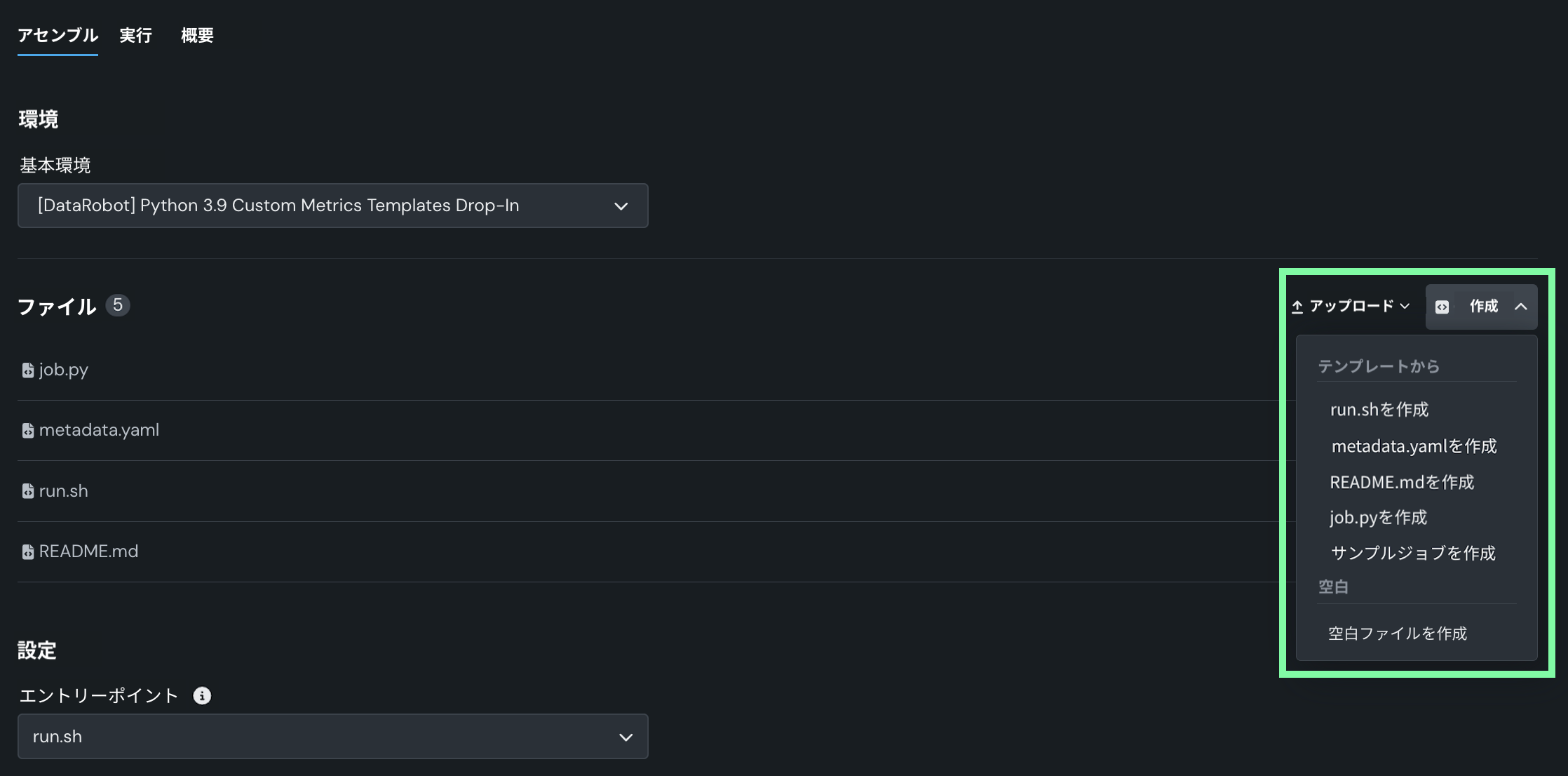
オプション 説明 アップロード 既存のカスタムジョブファイル( run.sh、metadata.yaml、など)をローカルファイルまたはローカルフォルダーとしてアップロードします。作成 空のファイルまたはテンプレートを含んだファイルとして新しいファイルを作成し、カスタムジョブに保存します。 - run.shを作成:エントリーポイントファイルの基本的で編集可能な例を作成します。
- metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- README.mdを作成:基本的で編集可能なREADMEファイルを作成します。
- job.pyを作成:実行時のパラメーターとデプロイをプリントするための基本的で編集可能なPythonジョブファイルを作成します。
- サンプルジョブを作成:すべてのテンプレートファイルを結合して、基本的で編集可能なカスタムジョブを作成します。 簡単にランタイムパラメーターを設定し、このサンプルジョブを実行できます。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。 次のステップでは、カスタム名とコンテンツを使用して、このように作成されたファイルをエントリーポイントとして識別できます。 新しいファイルを設定したら、保存をクリックします。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
-
設定セクションで、テンプレート(通常
.sh)によって追加されたジョブのエントリーポイントシェル(run.sh)ファイルを確認します。 エントリーポイントファイルでは、複数のジョブファイルを調整できます。 -
リソースセクションで、ジョブのデフォルトのリソース設定を確認します。 設定を変更するには、セクションヘッダーの横にある 編集をクリックし、以下のように設定します。
本機能の提供について
カスタムジョブのリソースバンドルは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする
設定 説明 リソースバンドル プレビュー機能 カスタムジョブが実行に使用するリソースを設定します。 ネットワークアクセス カスタムジョブのエグレストラフィックを設定します。 ネットワークアクセスで、以下のいずれかを選択します。 - パブリック:デフォルト設定。 カスタムジョブは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムジョブはパブリックネットワークから隔離され、サードパーティのサービスにアクセスできません。
デフォルトのネットワークアクセス
_マネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでパブリックに設定されていますが、変更可能です。 _セルフマネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでなしに設定されており、制限があります。ただし、管理者は、DataRobotプラットフォームの設定時にこれを変更できます。 詳細については、DataRobotの担当者または管理者にお問い合わせください。
-
(オプション)ランタイムパラメーターを定義します。 + ランタイムパラメーターを追加をクリックし、名前、タイプ、値、および必要に応じて説明を入力して、新しいランタイムパラメーターを定義します。
または、
metadata.yamlファイルでランタイムパラメーターを定義します。 このファイルのテンプレートは、ファイル > 作成ドロップダウンから入手できます。既存のランタイムパラメーターの場合、 編集をクリックして、パラメーター値の編集、パラメーターの削除、またはパラメーター値のリセットを行います。
-
タグ、指標、トレーニングパラメーター、アーティファクトに、追加の キー値を設定します。
再トレーニングジョブを作成した後、そのジョブを 再トレーニングポリシーとしてデプロイに追加できます。