予測の詳細設定を行う¶
デプロイの設定 > 予測タブでは、デプロイの推論(スコアリング)データ(モデルからの予測リクエストと結果を含むデータ)に関する詳細を確認できます。
予測設定ページでは、以下の情報にアクセスすることができます。
| フィールド | 説明 |
|---|---|
| 予測環境 | 予測が生成される環境を表示します。 予測環境を使用すると、アクセス制御および承認ワークフローを確立できます。 |
| 予測のタイムスタンプ | 予測行のタイムスタンプ設定に使用される方法を定義します。 タイムスタンプを定義するには、以下のいずれかを選択します。
|
| バッチ監視 | バッチ対応のデプロイでは、時間単位ではなく、バッチ単位で整理された監視統計を表示できます。 |
時系列デプロイの日付/時刻形式に関する注意事項
時系列デプロイで日付/時刻形式%Y-%m-%d %H:%M:%S.%fを使用している場合、タイムスタンプ形式の前にv2が自動的に入力されます。 予測データで送信される日付/時刻の値には、このv2プレフィックスを含めることはできません。 他のタイムスタンプ形式には影響しません。
DataRobotサーバーレスデプロイの予測自動スケーリングの設定¶
自動スケーリングでは、着信トラフィックに基づいてデプロイ内のレプリカの数が自動的に調整されます。 トラフィックの多い時間帯には、パフォーマンスを維持するためにレプリカが追加されます。 トラフィックの少ない時間帯には、コストを削減するためにレプリカが削除されます。 これにより、手動によるスケーリングが不要になると同時に、デプロイがさまざまな負荷に効率的に対応できるようになります。
自動スケーリングを設定するには、以下の設定を変更します。 DataRobotモデルの場合、しきい値40%のCPU使用率に基づいて自動スケーリングが実行されます。

| フィールド | 説明 |
|---|---|
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
自動スケーリングを設定するには、スケーリングのトリガーとなる指標を選択します。
-
CPU使用率:アクティブなレプリカ全体の平均CPU使用率のしきい値を設定します。 CPU使用率がこのしきい値を超えると、レプリカが自動的に追加され、処理能力が向上します。
-
HTTPリクエストの同時実行:処理される同時リクエスト数のしきい値を設定します。 たとえば、しきい値が5の場合、処理中の同時リクエストが5つ検出されると、レプリカが追加されます。
選択したしきい値を超えると、現在の負荷を処理するために必要な追加のレプリカ数が計算されます。 選択された指標が継続的に監視され、リソース使用量を最小限に抑えながら最適なパフォーマンスを維持するようにレプリカ数が調整されます。
CPU使用率の設定は以下のとおりです。
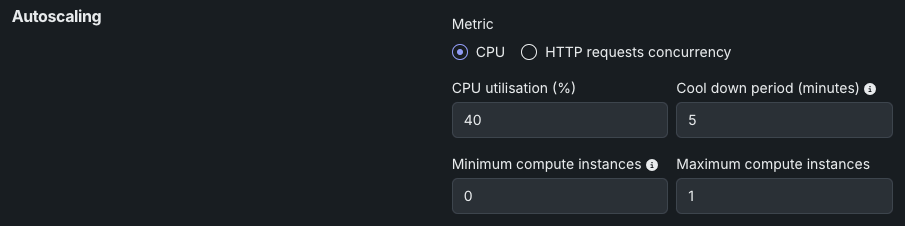
| フィールド | 説明 |
|---|---|
| CPU使用率(%) | スケーリングのトリガーとなるCPU使用率の目標値を設定します。 CPU使用率がこのしきい値に達すると、さらにレプリカが追加されます。 |
| クールダウン期間(分) | スケールダウンイベント後、次のスケールダウンが発生するまでの待機時間を設定します。 これにより、指標が不安定な場合の急激なスケーリングの変動を防ぐことができます。 |
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
HTTPリクエストの同時実行に関する設定は以下のとおりです。
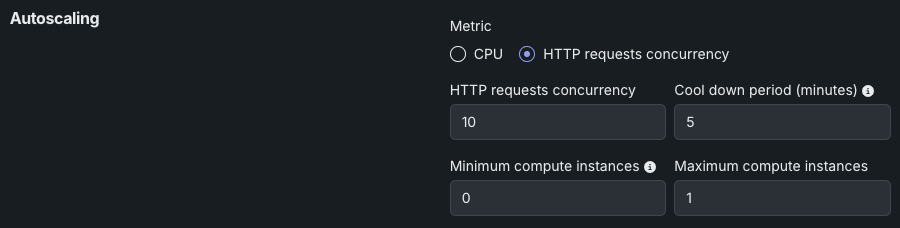
| フィールド | 説明 |
|---|---|
| HTTPリクエストの同時実行 | スケーリングのトリガーに必要な同時リクエスト数を設定します。 同時リクエストがこのしきい値に達すると、さらにレプリカが追加されます。 |
| クールダウン期間(分) | スケールダウンイベント後、次のスケールダウンが発生するまでの待機時間を設定します。 これにより、指標が不安定な場合の急激なスケーリングの変動を防ぐことができます。 |
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
プレミアム機能:常時予測
常時予測はプレミアム機能です。 最小のコンピューティングインスタンスを設定するには、デプロイの自動スケーリング管理が必要です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ: デプロイの自動スケーリング管理を有効にする
コンピューティングインスタンスの設定
DataRobotモデルデプロイの場合:
- デフォルトの最小値は0で、最大値は3です。
- 最小値と最大値は、組織の
max_compute_serverless_prediction_api設定から取得されます。
カスタムモデルデプロイの場合:
- デフォルトの最小値は0で、最大値は1です。
- 最小値と最大値は、組織の
max_custom_model_replicas_per_deployment設定から取得されます。 - GPU(LLMの場合)で実行する場合、最小値は常に1よりも大きくなります。
さらに、高可用性のシナリオの場合:
- 最小コンピューティングインスタンス数の設定は2以上である必要があります。
- これには、ビジネスクリティカルまたは消費ベースの価格設定が必要です。
特徴量探索のセカンダリーデータセットの変更¶
特徴量探索は、多数のデータセットから新しい特徴量を識別し生成します。このため、多数のデータセットを1つに統合するために手動で特徴量エンジニアリングを実行する必要がなくなります。 この処理は、データセットとそのデータセット内の特徴量の関係性に基づきます。 DataRobotは、このような関係性を構築および視覚化できる直感的な関係性エディターを提供します。 グラフとそこに含まれるデータセットが特徴量探索エンジンによって分析され、特徴量エンジニアリングの「レシピ」が決定します。そのレシピから、トレーニングおよび予測のためのセカンダリー特徴量が生成されます。 デプロイの設定中に、選択されたセカンダリーデータセットの設定を変更できます。

| 設定 | 説明 |
|---|---|
| セカンダリーデータセットの設定 | データセット設定をプレビューするか、データセット設定を変更するオプションが存在します。 デフォルトでは、プロジェクトを構築する際に使用された関係性で定義されたセカンダリーデータセット設定を使用して予測が作成されます。 他の設定を選択するには、新しいプライマリーデータセットをアップロードする前に変更をクリックします。 |