Eureqaモデル¶
| タブ | 説明 |
|---|---|
| 詳細 | View the results of the proprietary Eureqa machine learning algorithm, which constructs models that balance predictive accuracy against complexity. |
From the Eureqa tab, view details for a Eureqa model. Eureqaモデリングアルゴリズムは、「ノイズ」を扱う際に堅牢であり、非常に柔軟で、さまざまなデータセットで優れたパフォーマンスを発揮します。 一般的に、Eureqaでは、データに適したエクスポート可能な式で容易に解釈できるシンプルなモデルが検索されます。
Specialized model blueprints for Eureqa are available for generalized additive models (Eureqa GAM), Eureqa regression, and Eureqa classification models. Eureqa GAMブループリント(Eureqa/XGBoostハイブリッド)は、連続値プロジェクトと分類プロジェクトの両方で使用できます。
DataRobotでEureqaブループリントを実行すると、Eureqaアルゴリズムで数百万の対象モデルが試行され、データに最も適した(さまざまな複雑さの)いくつかのモデルが選択されます。 Eureqa モデルのインサイトから、これらのモデルを検証および比較し、複雑さと予測精度に関する要件のバランスが最も良いモデルを選択できます。

1つまたは複数のEureqa GAMモデルを選択して将来のデプロイを目的としてリーダーボードに追加することができます。 さらに、Eureqaモデルを再作成できるので、その予測をDataRobotの外部で完全に再現できます。 この機能は、規制のある業界の要件を満たす場合、および運用ソフトウェアにモデルを埋め込むステップをシンプルにする場合に有用です。 Eureqaモデルの再作成は、モデル式をターゲットデータベースや運用環境にコピーして貼り付けるのと同様にシンプルです。 (また、GAMモデルのみ、 パラメーターをエクスポートしてモデルを再作成できます。)
詳細については、Eureqaの高度なチューニングガイドおよび機能に関する注意事項を参照してください。
Eureqaモデルのメリット¶
Eureqaモデルを使用する利点は多数あります。
-
人に判読可能かつ解釈可能な分析式を返してくれるので、専門家によるレビューも容易です。
-
モデル構築の過程で複雑さを減らすことを余儀なくされているため、特徴量選択が非常に得意です。 たとえば、データにターゲット特徴量を予測するために20個の異なる列が使用されている場合、シンプルな式の検索は、最強の予測実行のみを使用する式を生成します。
-
小規模なデータセットにうまく対応するため、大量のデータを生成しない物理実験のデータを収集する科学研究者に人気があります。
-
ドメイン知識に統合する簡単な方法を提供します。 モデリングしているシステムの基本的な関係性がわかっていれば、Eureqaに「ヒント」(たとえば、熱伝導の公式や特定の地域での住宅価格の仕組みなど)を与えて、ビルディングブロックや学習の出発点とすることができます。 Eureqaは、そこから機械学習修正を構築します。
Eureqaモデルの構築¶
Eureqaモデルは包括的なオートパイロットの一部として実行されますが、クイックオートパイロットでは実行されません。 モデルのブループリントリポジトリからアクセスすることもできます。 手動モードで開始されたサポート対象のエクスペリメントや、既存のエクスペリメントに追加できます。 各モードでモデルを実行するための条件については、使用可能なモデルの表を参照してください。
Eureqaモデルタブ¶
Eureqaモデルの詳細を表示するには、リーダーボードからモデルを開いてから、詳細 > Eureqaモデルタブを選択します。
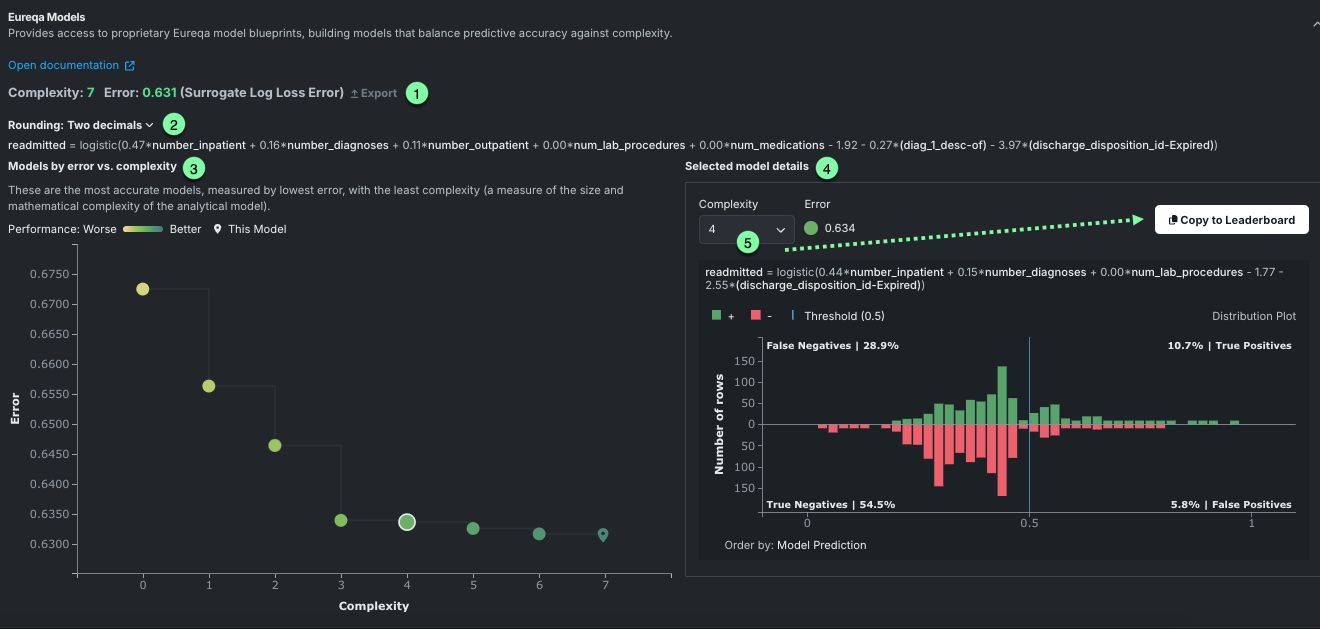
次の表は、サンプルの分類プロジェクトにおけるEureqaモデルの要素を説明したものです。
| ディスプレイ要素 | 説明 |
|---|---|
| 1 Eureqaモデルのサマリー | モデルにおけるEureqaの複雑さと誤差を表示します。 Eureqa GAMのみを表示する場合は、モデルの前処理とパラメーターの情報をCSVに保存するエクスポートオプションを利用できます。 |
| 2 10進数の丸め処理 | モデル式を表示する際に、Eureqa定数の四捨五入で表示する小数点以下の桁数を設定します。 |
| 3 誤差と複雑さの比較でモデルをみるグラフ | モデルの複雑さに対するモデルのエラーをプロットします。 |
| 4 選択されたモデルの詳細 | 選択されたモデルの数式とプロットを表示します。 |
| 5 複雑さセレクター | 選択されたモデルの詳細グラフで利用できます。モデルに異なる複雑さのレベルを設定し、グラフを更新して新しいレベルを反映させます。 |
Eureqaモデルのサマリー¶
上のセクションのモデルサマリー情報には、選択したモデルの複雑さと誤差のスコアが表示されます。 また、モデルのエクスポートも利用でき、Eureqa GAMモデルのモデル前処理とパラメーターのデータをダウンロードするためのダイアログが開きます。

複雑さスコアは、誤差と複雑さの比較でモデルをみるグラフで表される、選択されたモデルの複雑さを報告します。 選択されたモデルの詳細グラフの複雑さドロップダウンを使用して、グラフビューとこの値を更新します。 誤差値は、Eureqaモデルを比較するためのメカニズムを提供します。
小数の四捨五入処理¶
読みやすさを向上させるために、DataRobotはデフォルトで定数を小数点以下2桁の精度で表示します。 表示される精度は、四捨五入ドロップダウンで変更できます。 表示の変更は、ベースモデルには影響せず、表示されるモデル表現、つまりモデルを表す数学的関数にのみ影響します。

デフォルトでは、小数点以下2桁まで表示されます。

より正確さを求めるなら、4、8、またはすべてを選択します。

誤差と複雑さの比較でモデルをみるグラフ¶
Eureqaモデルの左側のパネルには、モデルの複雑さに対するプロットモデルエラーが表示されます。 結果として得られるグラフ( パレートフロントと呼ばれる)は、Eureqaによって作成された別のモデルを表します。 各点の色の範囲は、最も単純で精度の低いモデルを示す黄色から、最も複雑で精度の高いモデルを示す緑色までさまざまです。
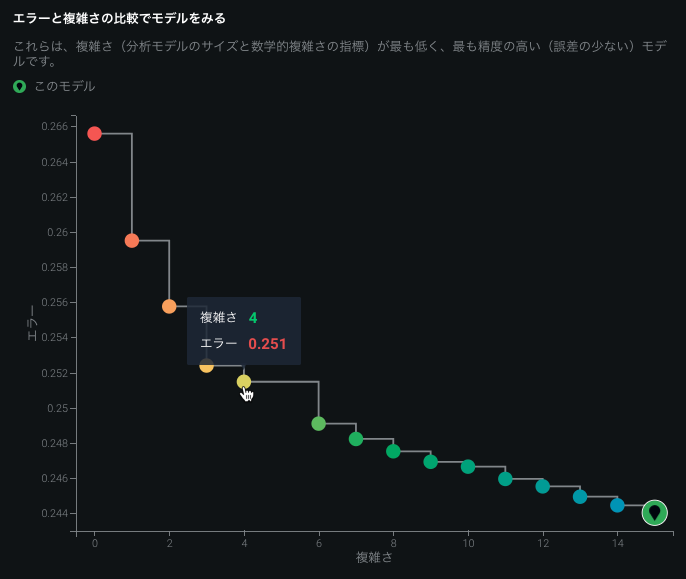
リーダーボードエントリー(「現在のモデル」)の場所がグラフに示されます(![]() )。 その他のポイントの上にマウスを置くと、モデルのEureqa複雑さとEureqaエラーを示すツールチップが表示されます。 モデル(点)をクリックすると、右側の選択されたモデルの詳細グラフがそのモデルの詳細で更新されます。
)。 その他のポイントの上にマウスを置くと、モデルのEureqa複雑さとEureqaエラーを示すツールチップが表示されます。 モデル(点)をクリックすると、右側の選択されたモデルの詳細グラフがそのモデルの詳細で更新されます。
選択されたモデルの詳細グラフ¶
選択されたモデルの詳細グラフは、選択したモデルについて、複雑さと誤差のスコア、およびモデルの数学的表現を報告します。 以下の操作を行うと、グラフが更新されます。
- 誤差と複雑さの比較でモデルをみるグラフのモデル(点)をクリックします。
- 複雑さドロップダウンを使用して複雑さを変更します。
別のモデルを選択すると、リーダーボードに移動ボタンが有効になります。 ボタンをクリックすると、選択したモデルの新しい追加のリーダーボードエントリーが作成されます。 モデルは既に構築されているので、新しい計算は必要ありません。
グラフに表示される部分の内容は、連続値問題で作業しているか分類問題で作業しているかに応じて異なります。
連続値プロジェクトの場合¶
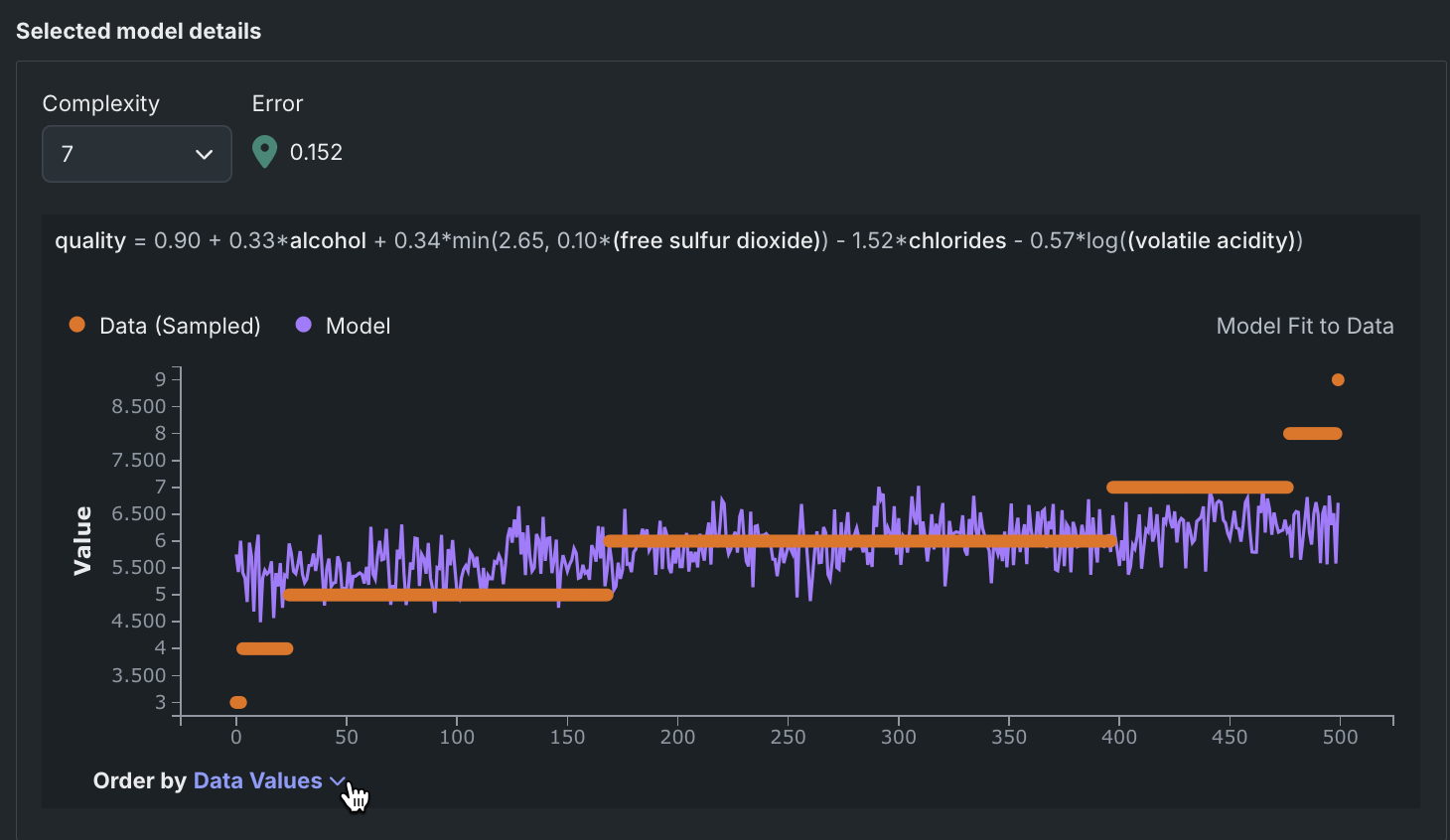
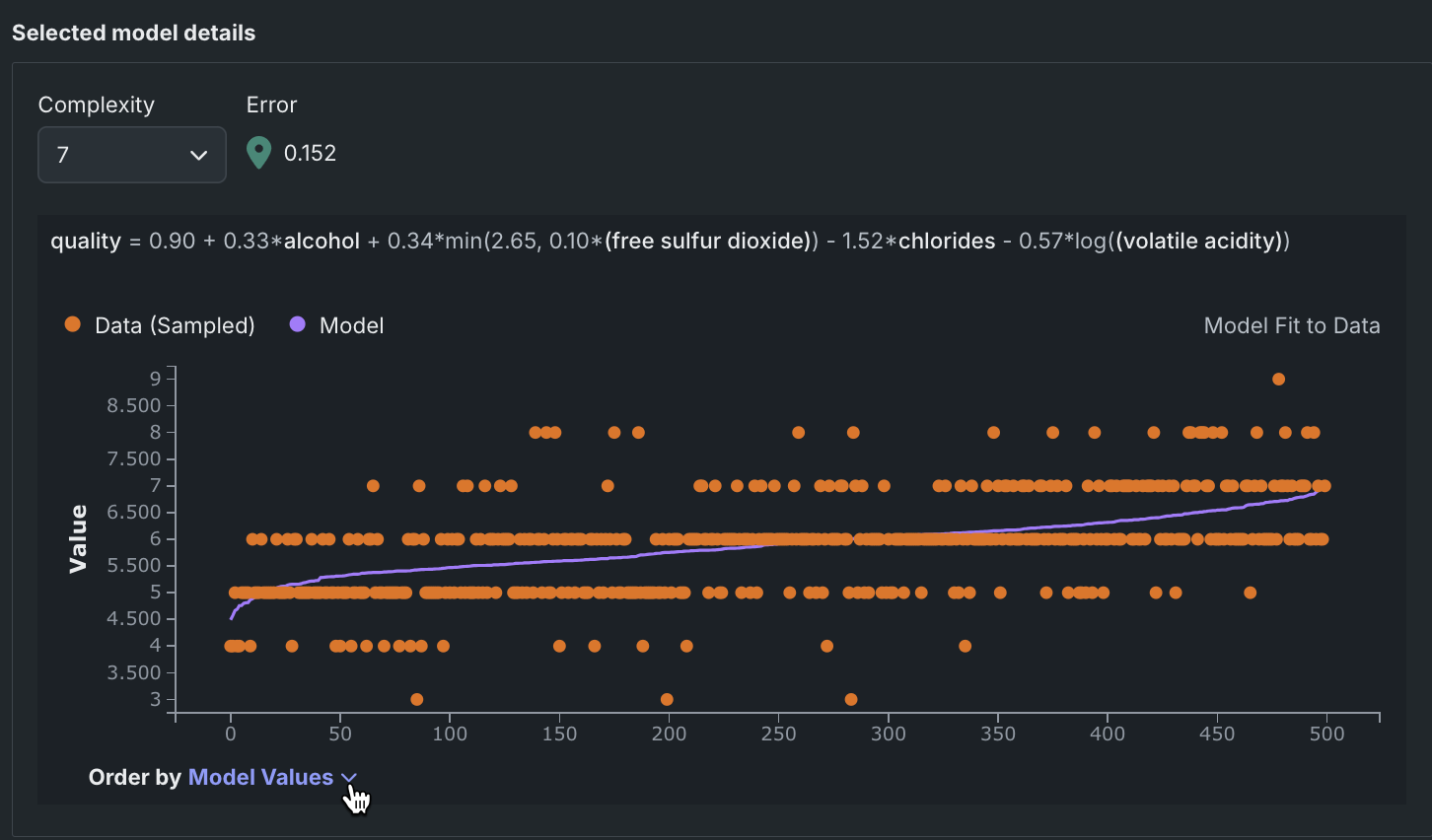
連続値問題の選択されたモデルの詳細グラフには、選択したモデルのデータに合った散布図が表示されます。 リフトチャートと同様に、選択されたモデルの詳細グラフのオレンジ色の点は、データ全体のターゲット値を示し、紫色の線はモデルの予測値をグラフ化しています。 別のモデルの出力を確認するには、誤差と複雑さの比較でモデルをみるグラフで新しいモデルを選択するか、新しい複雑さのレベルを選択します。

グラフは次のように解釈します。
| コンポーネント | 説明 |
|---|---|
| 1 | 選択されたモデルの複雑さの値、エラーの値、およびモデル式 |
| 2 | 選択されたモデルをリーダーボードに送るアクション。 使用可能なすべてのEureqaモデルは最初の実行時に構築されるため、追加の処理は必要ありません。 |
| 3 | サンプリングされたデータとモデル予測のターゲット値を表示するツールチップ。 |
| 4 | X軸に沿った行の順番を制御するドロップダウン。 |
並べ替え基準ドロップダウンは、選択に基づいてグラフを更新します。
行は元のデータと同じ順番で表示されます。

行はターゲット値(実測値)を基準に表示されます。
行はモデルの予測値を基準に表示されます。
分類プロジェクトの場合¶
分類問題の選択されたモデルの詳細グラフには、選択したモデルの分布ヒストグラム(混同行列)が表示されます。 したがって、モデル予測の範囲全体で均等に分割されたn番目のバケットに含まれるモデル予測のパーセンテージを示します。 混同行列の解釈の詳細については、ROC曲線に関する全般的な説明を参照してください。
ヒストグラムには、選択されたモデルに適用されるすべての予測値が表示されます。 別のモデルの出力を確認するには、複雑さドロップダウンを使用するか、誤差と複雑さの比較でモデルをみるグラフで新しいモデル(別の点)を選択します。

グラフは次のように解釈します。
| コンポーネント | 説明 |
|---|---|
| 1 | 選択されたモデルの複雑さの値、エラーの値、およびモデル式 |
| 2 | 合計値、値の範囲、True/Falseのカウントの内訳など、バケットの内容を説明するツールチップ。 |
| 3 | モデルの予測値によるX軸に沿って、行の値による順序を示すインジケーター。 |
| 4 | 選択されたモデルをリーダーボードに送るアクション。 使用可能なすべてのEureqaモデルは最初の実行時に構築されるため、追加の処理は必要ありません。 |
ヒストグラムには、プロットを4つの領域に分割する垂直のしきい線(上の例では0.5のすぐ下)が表示されます。 プロットの上部には、ターゲット値が1であったすべての行が表示され、下部にはターゲット値が0であったすべての行が含まれます。 しきい線の左側のすべての予測は False (陰性)予測で、左下は正しい予測を表し、左上は間違った予測を表します。 しきい線の右側の値は、Trueと予測された値です。 ヒストグラムの数は、トレーニングデータセット全体で計算されます。
モデルパラメーターのエクスポート¶
備考
GAMモデルはエクスポートボタンを使って再作成できますが、GAMまたは非GAM Eureqaモデルを再作成するもう1つの簡単な方法は、モデル式をコピーしてターゲット環境(SQLクエリー、Python、Javaなど)に直接貼り付けることです。
エクスポートボタンをクリックするとウィンドウが開き、選択したリーダーボードエントリーのEureqa前処理およびパラメーターテーブルをダウンロードできます。 このエクスポートでは、DataRobotの外部でGAMモデルを再作成するために必要なすべての情報が提供されます。

出力は、 係数タブからのエクスポートを(ここの GAM固有の情報で)解釈する場合と同様に解釈できますが、以下のような違いがあります。
-
出力の最初のセクションは、Eureqaモデル式を示します。 これは、Eureqaモデルタブの上部に表示される数学方程式で、
Target=...で始まります。 -
2番目のセクションは、モデルで使用された各特徴量のDataRobotの前処理を表示します。これには、1つまたは2つの入力変換(標準化など)のパラメーターが含まれます。 Eureqaモデルでは、テキストおよび高カーディナリティ特徴量がない場合、
Coefficientフィールドは0に設定されます。 「係数」は、列の線形にフィットした係数を示すために線形モデルにおいて使用されます。 -
Eureqaモデルのパラメーターは、.csv形式にのみエクスポートできます(.pngおよび.zipオプションは無効です)。
Eureqaリファレンス¶
従来のDataRobotのモデル構築では、データは、トレーニング、検定、およびホールドアウトのセットに分割されます。 対照的に、Eureqaでは、トレーニングDataRobot分割が使用されますが、Eureqaエラーを計算するために、独自の内部トレーニング/検定分割ロジックを使用して、そのセットがさらに分割されます。
モデルの可用性¶
次の表では、AutoMLおよび時系列のEureqaモデルを包括的オートパイロットおよびリポジトリから利用できる条件について説明します。
| Eureqaモデルタイプ | 包括的オートパイロット | リポジトリ |
|---|---|---|
| AutoMLのエクスペリメント | ||
| リグレッサー/分類器 |
|
|
| GAM |
|
|
| 時系列のエクスペリメント | ||
| リグレッサー/分類器 |
|
制限なし |
| GAM |
|
制限なし |
| 予測距離モデリングを使用したEureqa | N/A |
|
生成回数¶
次の表は、選択したブループリントに基づいて実行された生成回数を示しています。 生成値はブループリント名に反映されます。
| Eureqaモデルタイプ | 包括的オートパイロットでの生成 | リポジトリの生成 |
|---|---|---|
| リグレッサー/分類器 | 250 | 40、250、または3000 |
| GAM | 動的* | 40、動的*、または10,000 |
*生成数の動的オプションは、データセットの行数に基づいています。 値は1000~3000回の生成になります。
Eureqaとスタックされた予測¶
これを行うには計算上「高価」になりすぎるため、Eureqaブループリントは スタックされた予測をサポートしていません。 ほとんどのモデルでは、プロジェクトの作成に使用されたデータでの予測を生成するためにスタッキングが使用されます。 トレーニングデータでEureqa予測を生成する場合、すべての予測は、スタッキングからではなく、単一のEureqaモデルから生成されます。
その結果、Eureqaの誤差は正確にはデータ自体の誤差ではなく、フィルター処理されたバージョンのデータでの誤差です。 これにより、誤差指標が同じ場合、報告されるEureqaの誤差がリーダーボードの誤差よりも小さくなる理由が説明できます。 DataRobotの最適化指標(リーダーボードでのモデルの格付に使用される値)は変更できますが、Eureqaの誤差指標を変更することはできません。
以下に、スタッキング予測がないことによる非Eureqaモデリングとの違いを示します。
- 予測値でトレーニングするアンサンブルモデル(GLMやENETなど)は無効です。 他のブレンダーは利用できます(AVGやMEDなど)。
- 検定および交差検定のスコアは、検定や交差検定のためにトレーニングされたEureqaおよびEureqa GAMモデルでは非表示です。
- トレーニングデータの予測のダウンロードは無効になっています。
モデルトレーニングプロセス¶
Eureqaモデルをトレーニングするとき、DataRobotは新しいソリューション検索または再適合のいずれかを実行します。
- 新しいソリューション検索:Eureqaの進化プロセスは完全な検索を行い、新しいソリューションのセットを探します。 このメカニズムは改良よりも遅くなります。
- 再適合:Eureqaは、線形要素の係数を再適合します。 つまり、既存のソリューションからターゲット式を取得し、線形要素を抽出し、すべてのトレーニングデータを使用してその係数を再適合させます。
次の表は、Eureqaモデルタイプごとに、検証/バックテストのトレーニング動作とフローズン実行を示します。
| モデルタイプ | バックテスト/交差検定 | フローズン実行 |
|---|---|---|
| Eureqaリグレッサー/分類子 | 最初のフォールドでトレーニングされたモデルから既存のソリューションの係数を再適合させます。 | 親モデルから既存のソリューションの係数を再適合させます。 |
| Eureqa GAM* | 最初のフォールドでトレーニングされたモデルから既存のソリューションの係数を再適合させます。 | XGBoostハイパーパラメーターを固定し、Eureqaの第2段階モデルの新しいソリューション検索を実行します。 |
| 予測距離モデリングを使用したEureqa(予測距離(戦略)ごとに最適なソリューションを選択します) | 新しいソリューション検索を実行します。 | 固定されたEureqaビルディングブロックを使用して新しいソリューション検索を実行します。 |
* Eureqa GAMは2つの段階で構成されています。 第1段階はXGBoost、第2段階はEureqaで、XGBoostモデルに似ていますが、トレーニングデータのサブセットでトレーニングされています。
決定論的モデリング¶
他のDataRobotモデルと同様に、Eureqaのモデル生成プロセスは決定論的です。同じデータに対して同じ設定引数でEureqaを2回実行した場合、同じモデル(同じ誤差、同じ複雑さ、同じモデル式)が得られます。 Eureqa独自のモデル生成プロセスのために、その入力にわずかな変更(1つの行の削除やチューニングパラメーターの若干の変更など)を加えた場合でも、非常に異なるモデル式が返される可能性があります。
誤差指標でのチューニング¶
Eureqa GAMブループリントはXGBoostの出力上でEureqaを実行するので、Eureqa GAM(平均絶対誤差)でEureqaが使用する指標は、「代替」エラーです。 これは、EureqaでXGBoostの元の出力がどれだけ正確に再現できるかを測定します。 連続値の場合、高度なオプションでXGBoostで使用される損失関数を変更できますが、Eureqaの誤差指標は変更できません。 また、DataRobotの 最適化指標(リーダーボードでのモデルの格付に使用される値)も変更できます。 このチューニングを行うと、XGBoostのチューニングとXGBoost損失関数のデフォルトの選択に影響が生じ、Eureqa GAMで異なる結果が生成されます。
機能に関する注意事項¶
GAMモデルと一般的なEureqaモデルの両方を使用する場合、以下の注意事項が適用されます。
備考
Eureqaモデルブループリントは、トレーニングおよび検定環境のコアの数が一定に維持される場合、Eureqaモデルブループリントは決定性です。 設定が異なれば、Eureqaブループリントで得られる結果も異なります。
-
多クラス分類モデリングのサポートはありません。
-
交差検定は、リーダーボードからのみ実行できます(リポジトリからは実行できません)。
-
レガシーEureqa SaaS製品ユーザーの場合、コア数が少ないので精度が相対的に低下することがあります。 (レガシーユーザーは、DataRobot担当者に連絡してこの問題の対処オプションを相談できます。)
-
Eureqaのスコアリングコードは、AutoMLと時系列の両方で使用できます。 時系列で使用する場合、スコアリングコードはEureqa連続値とEureqa GAMのみ(分類なし)でサポートされます。