レジストリのグローバルモデルにアクセスする¶
プレミアム機能
グローバルモデルとツールはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
レジストリから、予測、生成、またはエージェントユースケースのためのグローバルモデルとツールをデプロイできます。 これらの高品質のオープンソースモデルとツールは、すぐにデプロイできます。 LLMのユースケースには、プロンプトインジェクション、毒性、センチメントを識別する分類器や、拒否スコアを出力するリグレッサーが用意されています。 エージェントユースケースでは、エージェントワークフローをデプロイして接続するための一連のツールにアクセスできます。
グローバルモデルの利用可能性
DataRobotが作成したグローバルモデルは、すべてのユーザーが利用できます。 管理者が作成したグローバルモデルは、以下のルールに基づいて使用できます。
- 組織管理者がグローバルモデルまたはツールを作成した場合、そのアセットは組織内のすべてのユーザーが利用できます。
- プラットフォーム管理者がグローバルモデルまたはツールを作成した場合、そのDataRobotプラットフォームインスタンスのすべてのユーザーが利用できます。
グローバルモデルとツールの編集権限があるのは管理者のみです。 デプロイされたグローバルモデルとツールは、デプロイの共有ルールに従います。
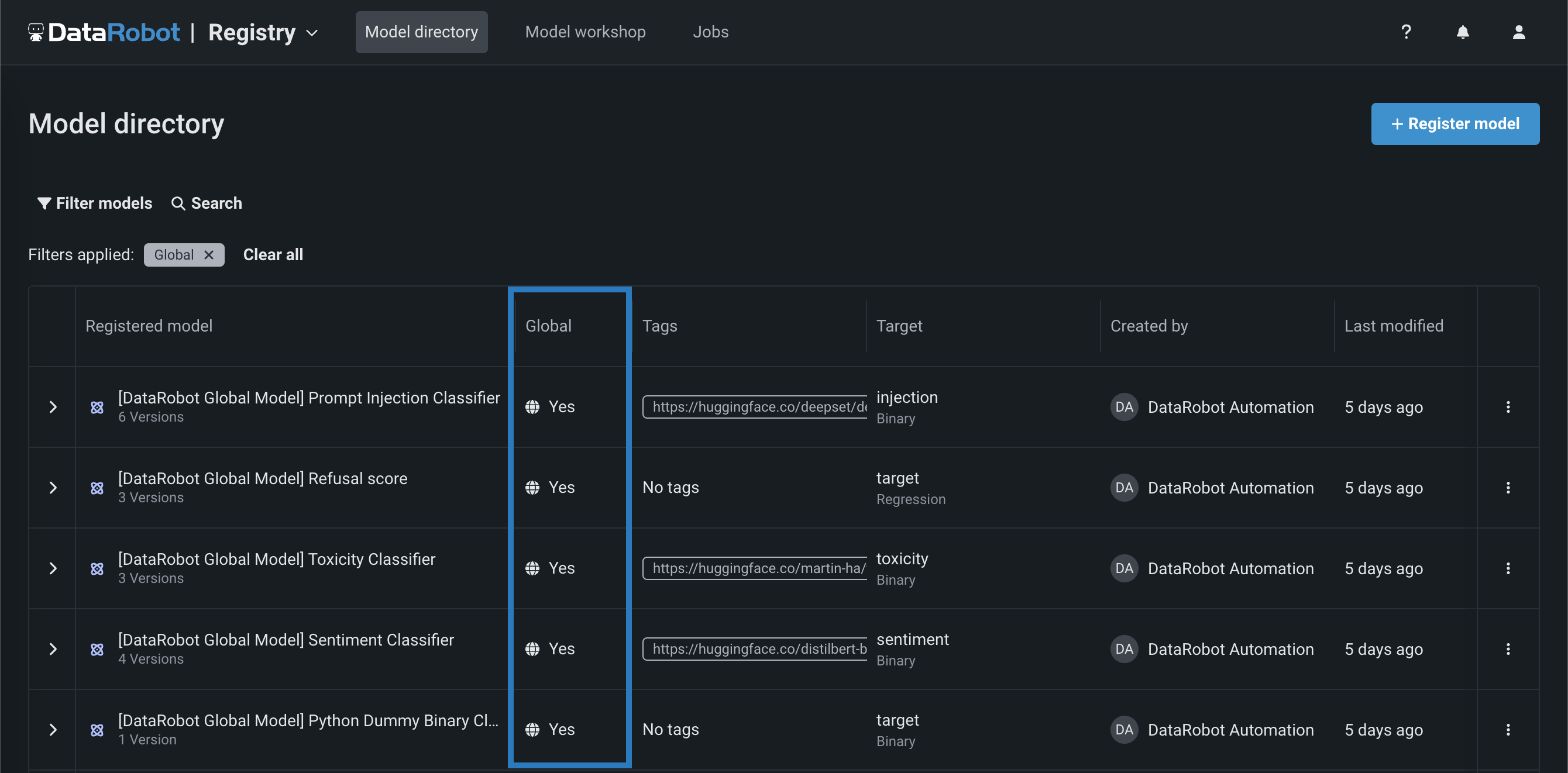
レジストリ > モデルタブでグローバルモデルを識別するには、グローバル列を見つけて、 はいが付いているモデルを探します。
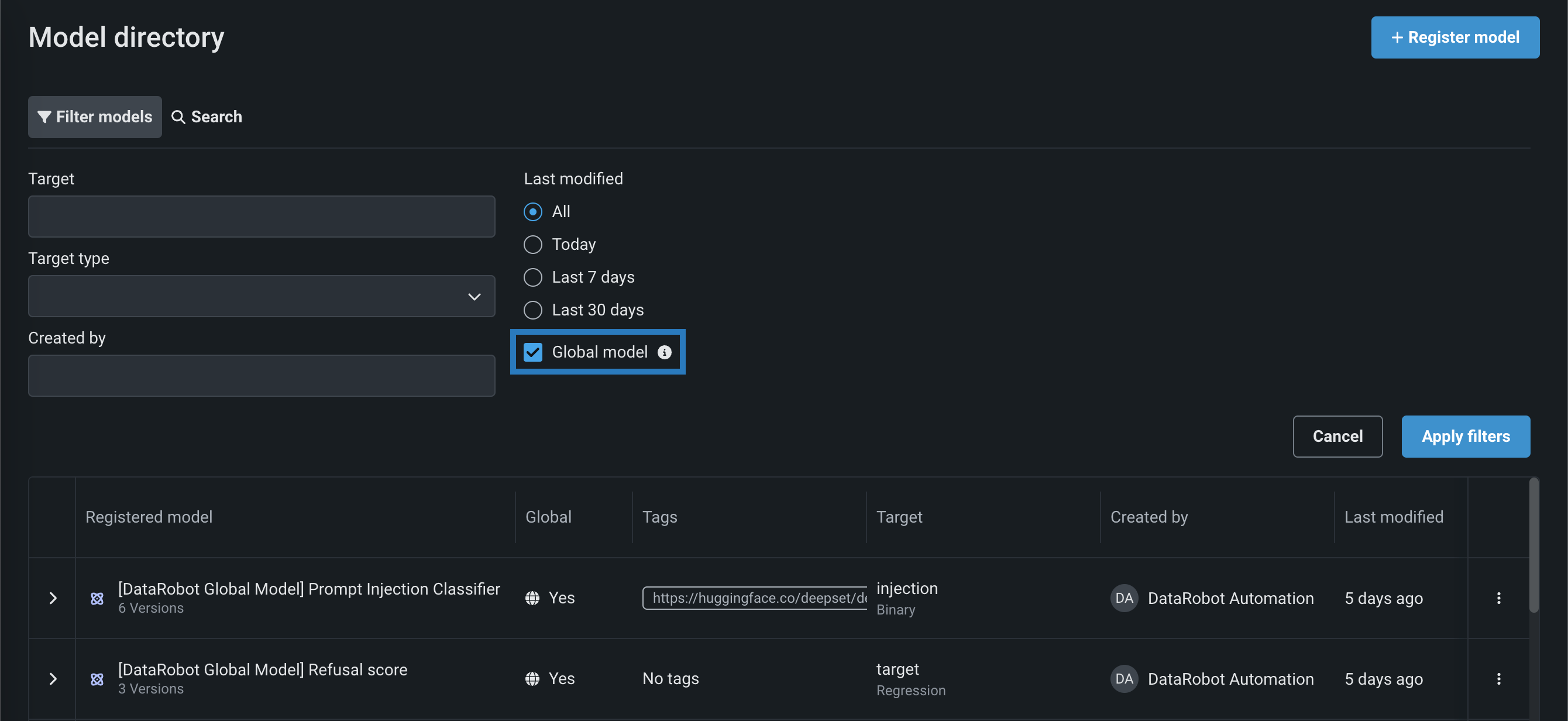
レジストリ > モデルタブをフィルターして、グローバルモデルのみをリストすることができます。 全体をクリックし
グローバルモデル¶
予測ユースケースや生成ユースケースで、事前にトレーニングされたグローバルモデルをデプロイします。 これらの高品質でオープンソースのモデルは、トレーニング済みですぐにデプロイできるため、DataRobotのインストール後すぐに予測を行うことができます。
コンソールへのデプロイでは、以下のグローバルモデルを使用できます。
| モデル | タイプ | ターゲット | 説明 |
|---|---|---|---|
| プロンプトインジェクション分類器 | 二値 | テキストをプロンプトインジェクションまたは正当なものとして分類します。 このガードモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 deberta-v3-base-injectionモデルの詳細を参照してください。 |
|
| 毒性分類器 | 二値 | テキストを有毒か無毒に分類します。 このガードモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 toxic-comment-modelの詳細を参照してください。 |
|
| センチメント分類器 | 二値 | テキストのセンチメントを肯定的か否定的に分類します。 このモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 distilbert-base-uncased-finetuned-sst-2-englishモデルの詳細を参照してください。 |
|
| 感情分類器 | 多クラス | テキストを感情で分類します。 これは多ラベルモデルです。つまり、複数の感情をテキストに適用できます。 このモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 詳しくは、 roberta-base-go_emotions-onnxモデルの詳細を参照してください。 |
|
| 拒否スコア | 連続値 | プロンプトがモデルに設定されている回答範囲を超えているために、LLMがクエリーへの回答を拒否したケースのリストと、入力を比較して、最大類似度スコアを出力します。 | |
| PresidioのPII検出 | 二値 | テキスト内の個人を特定できる情報(PII)を検出して置き換えます。 このガードモデルには、分類するテキストを含むtextという名前の列が1つ必要です。 必要に応じて、検出するPIIのタイプをコンマ区切りの文字列として列'entities'に指定できます。 この列が指定されていない場合は、サポートされているすべてのエンティティが検出されます。 エンティティのタイプは、PresidioがサポートするPIIエンティティのドキュメントに記載されています。 検出結果に加えて、モデルは anonymized_text列を返します。この列には、検出されたPIIがプレースホルダーに置き換えられた更新バージョンの入力が含まれています。 詳細については、Presidio: Data Protection and De-identification SDKのドキュメントを参照してください。 |
|
| ゼロショット分類器 | 二値 | ユーザー指定のラベルを持つテキストに対してゼロショット分類を実行します。 このモデルでは、textという名前の列に分類されたテキストが必要であり、labelsという名前の列にコンマ区切りの文字列としてクラスラベルが必要です。 すべての行に同じラベルセットが必要であるため、最初の行にあるラベルが使用されます。 詳しくは、 deberta-v3-large-zeroshot-v1モデルの詳細を参照してください。 |
|
| Pythonダミー二値分類 | 二値 | Positiveクラスでは、常に0.75となります。 詳しくは、 python3_dummy_binaryモデルの詳細を参照してください。 |
グローバルモデルフィルターをクリアするには、適用されたフィルター行で、グローバルフィルターバッジのxをクリックします。 すべてクリアをクリックして、適用されたすべてのフィルターを削除することもできます。
エージェントワークフローのツール¶
エージェントを構築する際に、エージェントのワークフローに不可欠なタスクを処理するためのツールを統合する必要がよくあります。これは、通常、外部サービスとの通信を伴う複雑なユースケースで必要になります。 エージェントワークフローのコードに直接埋め込まれているツールもあれば、外部にデプロイされてエージェントプロセスによって呼び出されるツールもあります。 外部にデプロイされたツールは個別に拡張できるため、リソースを大量に消費するツール、I/O制限のあるツール、または再利用可能なツールに最適です。 ツールを外部にデプロイすると、コンソールで本番環境対応の監視、リスク軽減、およびモデレーション機能も有効になります。
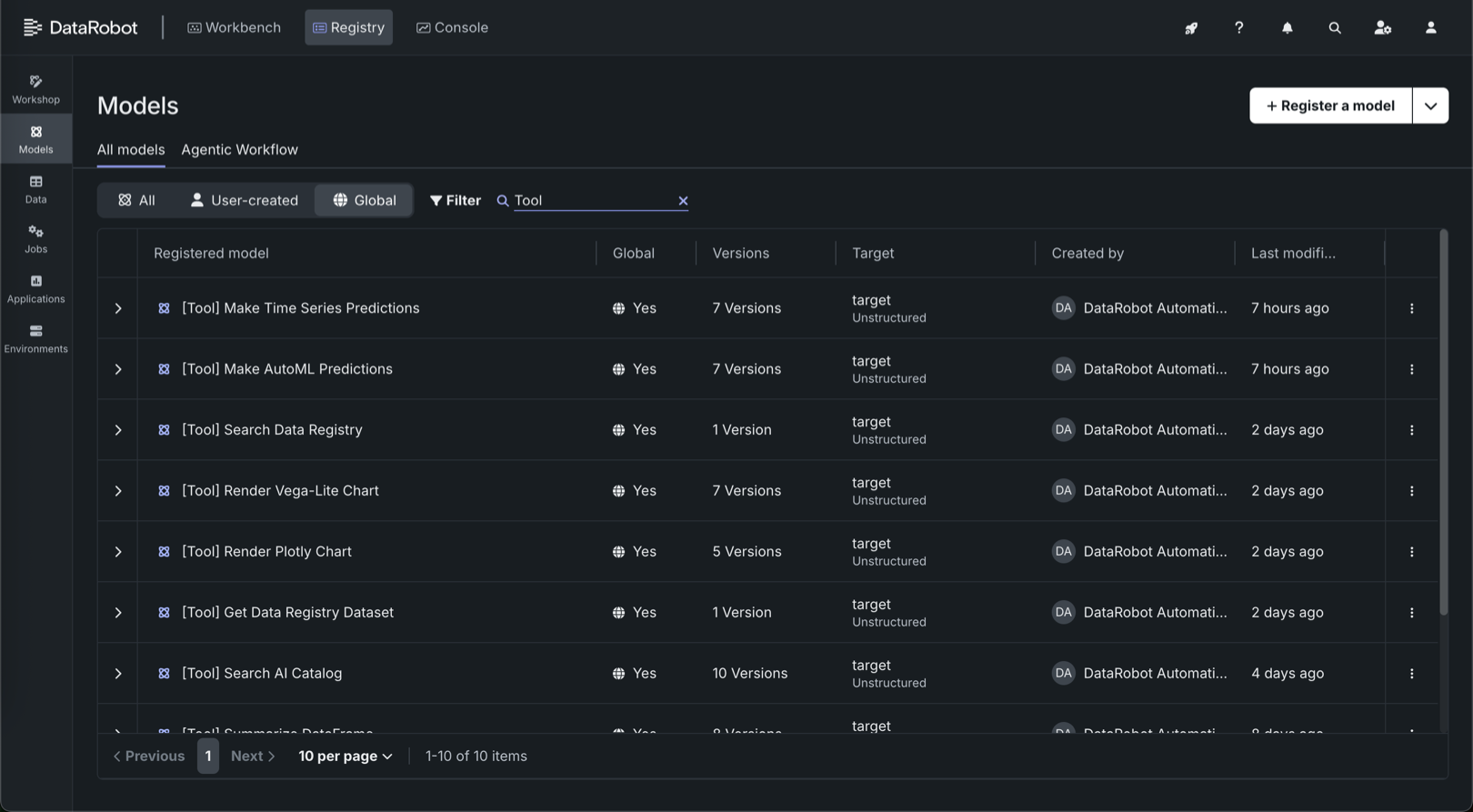
コンソールへのデプロイでは、以下のグローバルツールを利用できます。
ツールの識別
すべてのグローバルツールには、[Tool]識別子がプレフィックスとして付けられます。 この識別子を使用して、グローバルモデルとツールリストをフィルターし、ツールのみを表示します。
| ツール | 説明 | 備考 |
|---|---|---|
| Get Data Registry Dataset | dataset_idを使用してDataRobotのデータレジストリからデータセットを取得し、CSV形式でrawバイトとしてそのデータセットを返します。 |
N/A |
| Make AutoML Predictions | pandas.DataFrameを受け取り、そのデータを使用して、指定された予測モデルから予測を返します。 |
引数columns_to_return_with_predictionsは、入力データセットから列を返すようにツールに指示します。 これは、予測を確実に解釈できるようにするために使用します。 たとえば、予測値のインデックスや順序に依存できないため、どの予測がどれであるかを確認できるように、IDやその他の識別列を返したい場合があります。 |
| Make Text Generation Predictions | 文字列を受け取り、指定されたDataRobotテキスト生成モデル(LLM)から予測を返します。 | 要約やテキスト補完などの作業に適しています。 このツールは、TextGenerationのデプロイにのみ使用し、連続値、分類、その他のターゲットタイプには使用しないでください。 |
| Make Time Series Predictions | 時系列モデルから予測を返します。 | このツールを使用する前に、必要なデータがすべて揃っていることを確認してください。 時系列モデルには予測ポイントが必要です。 また、入力データにも特定の要件があります。 |
| Render Plotly Chart | 指定された仕様とデータセットIDに基づいて生成およびレンダリングされたPlotlyチャートオブジェクトを含むJSONオブジェクトを返します。 | Plotlyチャートを生成する際、仕様内のプレースホルダー(列名を二重の波括弧で囲んだもの、例:{{ column_name }})は、データレジストリのデータセット内の指定された列の対応する値に置き換えられます。 データレジストリのデータセットはdataset_id入力パラメーターで識別されます。 |
| Render Vega-Lite Chart | Vega-Lite仕様をJSON形式で渡すことによってVega-Liteチャートを生成し、チャートのBase64エンコードされたイメージをJSONで返します。 | チャートのデータを指定するには、データレジストリにチャート化するデータセットのdataset_idを渡します。 |
| Search Data Registry | 検索語を使ってDataRobotのデータレジストリ内のデータセットを検索します。 一致するデータセットをpandas.DataFrameとして返します。 |
データレジストリでは、部分一致はサポートされていません。 このツールで期待どおりの結果が得られない場合は、より具体的な検索クエリーで再試行してください。 |
| Summarize DataFrame | 統計やデータインサイトなど、pandas.DataFrameの詳細なサマリーをMarkdown形式で提供します。 |
N/A |
エージェントツールのターゲットタイプ
すべてのグローバルツールのターゲットタイプは非構造化で、ターゲットはtargetです。
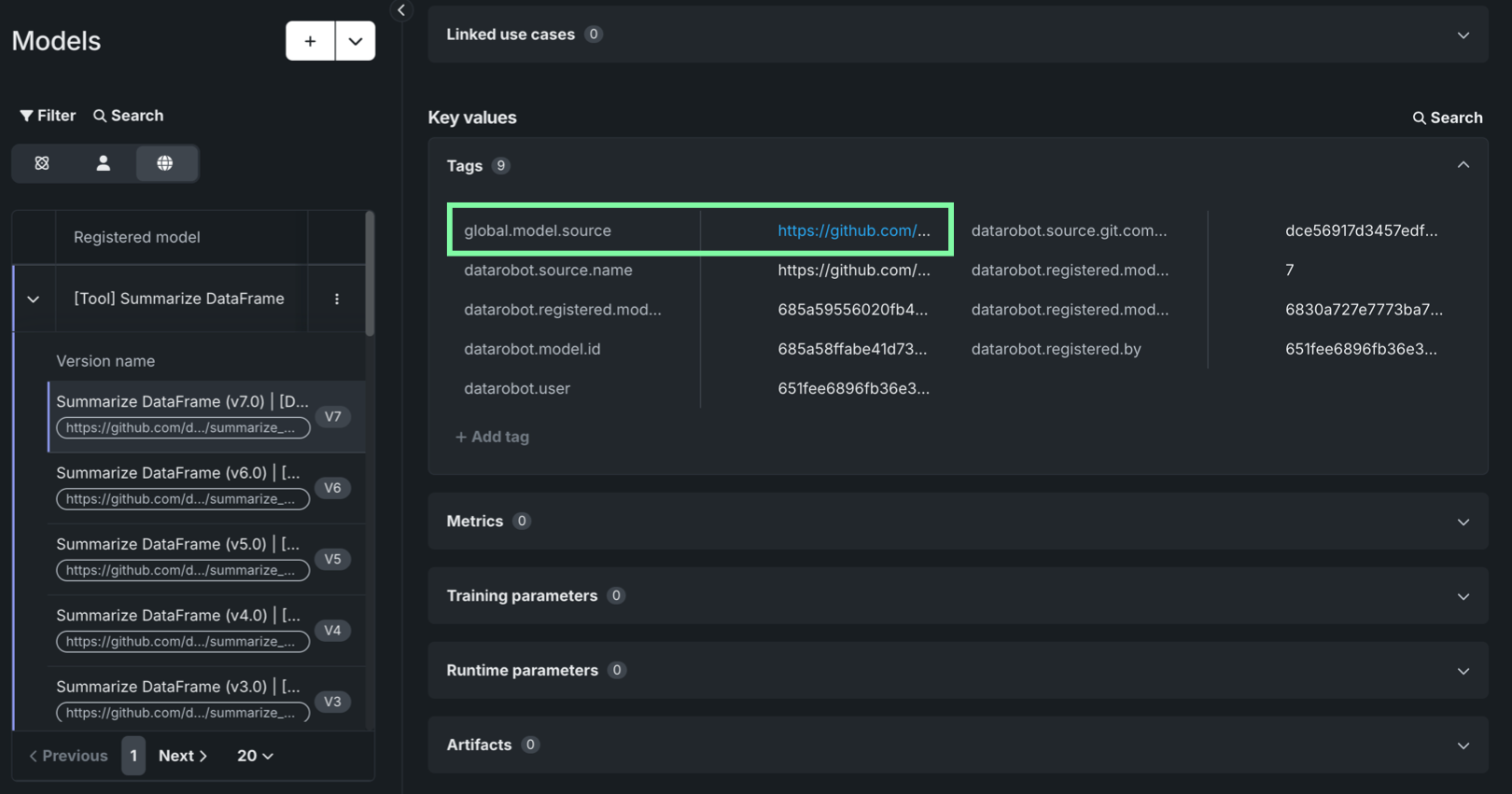
ツールの詳細については、公開されているagent-tool-templatesリポジトリのソースコードにアクセスしてください。 各ツールにはglobal.model.sourceタグが付けられ、そのツールのソースファイルを含むディレクトリにリンクしています。 これにより、その内容を調べてモデルの詳細を確認したり、その入出力スキーマを確認したり、カスタマイズされたツールを構築するためのテンプレートとしてコードを使用したりできます。 リポジトリのリンクを見つけるには:
-
グローバルフィルターを適用し、リストで[ツール]を探します。
-
バージョンを開き、そのバージョンでキー値セクションまで下にスクロールします。
-
タグパネルを開き、
global.model.sourceタグを見つけます。 -
タグの値にカーソルを合わせると、完全なURLが表示されます。また、リンクをクリックすると、そのツールのディレクトリのリポジトリが開きます。