チャレンジャー¶
モデルの開発中、運用環境にデプロイするモデルが選択されるまで多くのモデルを比較することがあります。 リスク軽減策 > チャレンジャータブを使用してデプロイ後のモデル比較を続行できます。 デプロイされたモデルをシャドーイングするチャレンジャーモデルを送信し、デプロイされたモデルで行われた予測を再実行できます。 チャレンジャーモデルによって行われた予測を現在デプロイされているモデル(「チャンピオン」)と比較して、より適切な優れたモデルがあるかどうかを判断できます。
チャレンジャータブを有効化¶
チャレンジャータブを有効化するには、 ターゲット監視と 予測行ごとの履歴保存を有効化する必要があります。 デプロイの作成中、または 設定 > データドリフト 設定 > チャレンジャータブで、これらを設定します。 チャレンジャーモデルを有効にすると、予測行ごとの履歴保存もデプロイに対して自動的に有効になります。予測行ごとの履歴保存はチャレンジャーに必要なのでオフにすることはできません。
サポートされていないモデルのデプロイ
チャレンジャーを有効にし、それらで予測を再実行するには、デプロイ済みモデルがターゲットドリフト追跡をサポートしている必要があり、また、 特徴量探索あるいは 非構造化カスタム推論モデルではないことが条件です。
デプロイへのチャレンジャーの追加¶
チャレンジャーモデルをデプロイに追加するには、リスク軽減策 > チャレンジャータブを選択して+チャレンジャーモデルを追加 > 既存のモデルを選択を選択します。 選択リストには、ターゲットのタイプと名前がチャンピオンモデルと同じであるモデルパッケージしか含まれていません。
備考
チャレンジャーモデルをデプロイに追加する前に、ワークベンチからモデルを選択するか、またはカスタムモデルを登録する必要があります。 チャレンジャーは:
- チャンピオンモデルと同じターゲットタイプである必要があります。
- 既存のチャンピオンやチャレンジャーと同じリーダーボードモデルにすることはできません。各チャレンジャーは一意のモデルである必要があります。 同じリーダーボードモデルから複数のモデルパッケージを作成する場合、それらのモデルを同じデプロイでチャレンジャーとして使用することはできません。
- 特徴量探索プロジェクトからのものであってはなりません。
- チャンピオンモデルと同じ特徴量セットでトレーニングする必要はありませんが、いくつかの特徴量を共有している必要があります。ただし、予測の再実行を正常に行うには、チャンピオンとチャレンジャーに必要なすべての特徴量の和集合を予測として利用する必要があります
- チャンピオンモデルと同じユースケースから構築する必要はありません。
レジストリからモデルバージョンを選択ダイアログボックスで、登録済みモデルをクリックし、チャレンジャーとして追加する登録モデルのバージョンを選択して、モデルのバージョンを選択をクリックします。 各デプロイに最大4つのチャレンジャーモデルを追加できます。 つまり、チャンピオンモデルを含めると、チャレンジャー分析では合計で最大5つのモデルを比較できます。 DataRobotにより、特徴量とターゲットタイプをモデルがチャンピオンモデルと共有していることが検証されます。検証後、チャレンジャーを追加をクリックします。 モデルがチャレンジャーとしてデプロイに追加されます。
予測の再実行¶
チャレンジャーモデルを追加したら、チャンピオンモデルで作成された保存済み予測をすべてのチャレンジャーで再実行できます。これにより、各モデルの予測値、精度、データエラーなどのパフォーマンス指標を比較できます。 予測を再実行するには、 チャレンジャー予測を更新するを選択します。
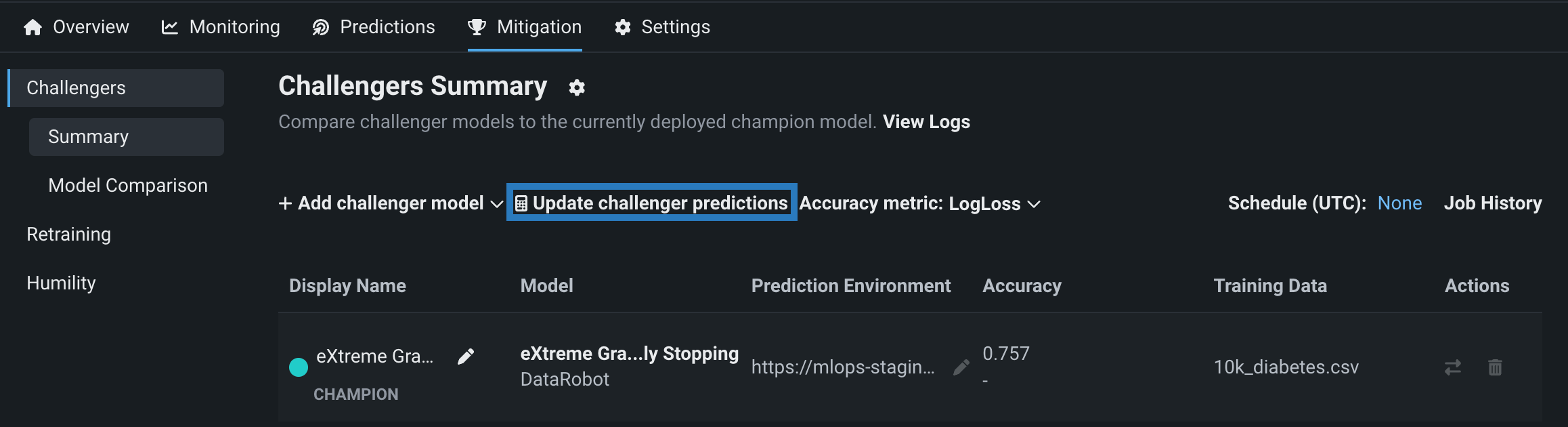
チャンピオンモデルは、1時間あたり最大100,000の予測行を計算して保存します。 日付スライダーで指定した時間範囲内で、1時間ごとに行われた予測リクエストの最初の10,000行がチャレンジャーで再実行されます。 (時系列デプロイの場合、この制限は適用されないことにご注意ください。) すべての予測データは、統計を比較するためにチャレンジャーによって使用されます。 予測が作成された後、日付スライダーで表示を更新をクリックして、チャレンジャーモデルのパフォーマンス指標の更新された表示を表示します。
予測の再実行をスケジュールする¶
チャレンジャーの再実行を手動で行う代わりに、スケジュールを設定できます。 デプロイの設定 > チャレンジャータブに移動し、チャレンジャー予測を自動的に再計算トグルを有効にして、予測の再実行に望ましい頻度と時間を設定します。 有効化すると、予測再実行はデプロイ内のすべてのチャレンジャーに適用されます。
チャレンジャーによる再実行のスケジュールは誰ができますか?
チャレンジャーの予測再実行をスケジュールできるのは、デプロイオーナーだけです。
過去に予測リクエストが作成されたデプロイがあり、チャレンジャーを追加した場合、スケジュールされたジョブは、次の実行サイクルで新しく追加されたチャレンジャーモデルをスコアリングします。
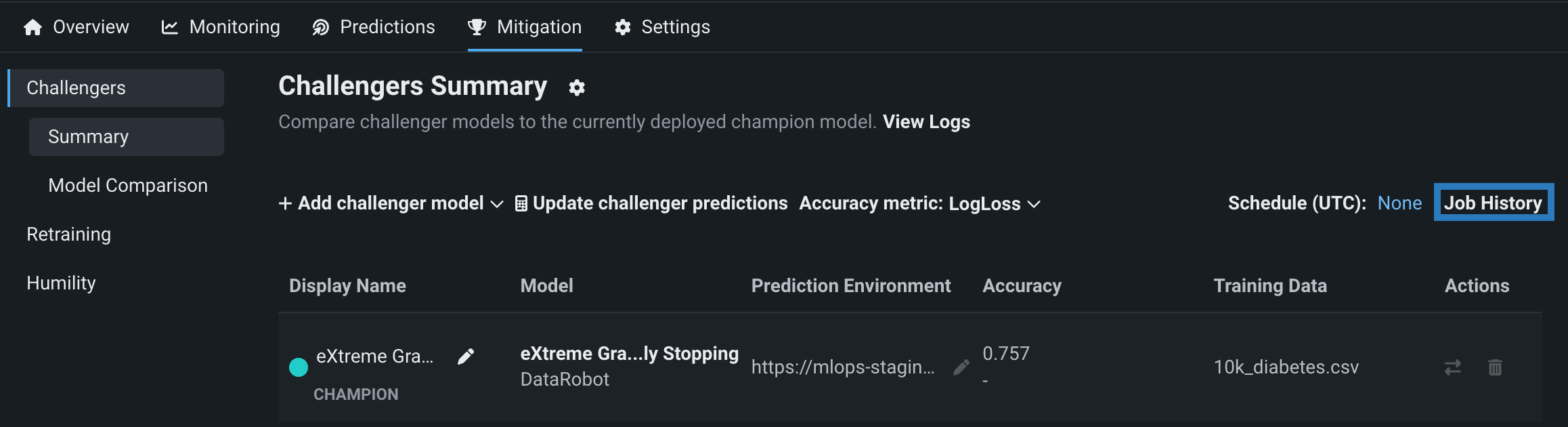
チャレンジャージョブ履歴の表示¶
1つ以上のチャレンジャーモデルを追加して予測を再実行した後、コンソール > バッチジョブページでデプロイのチャレンジャーのチャレンジャー予測ジョブを表示できます。
チャレンジャーモデルの概要¶
チャレンジャータブには、「チャンピオン」バッジの付いたチャンピオンモデルと各チャレンジャーの情報が表示されます。
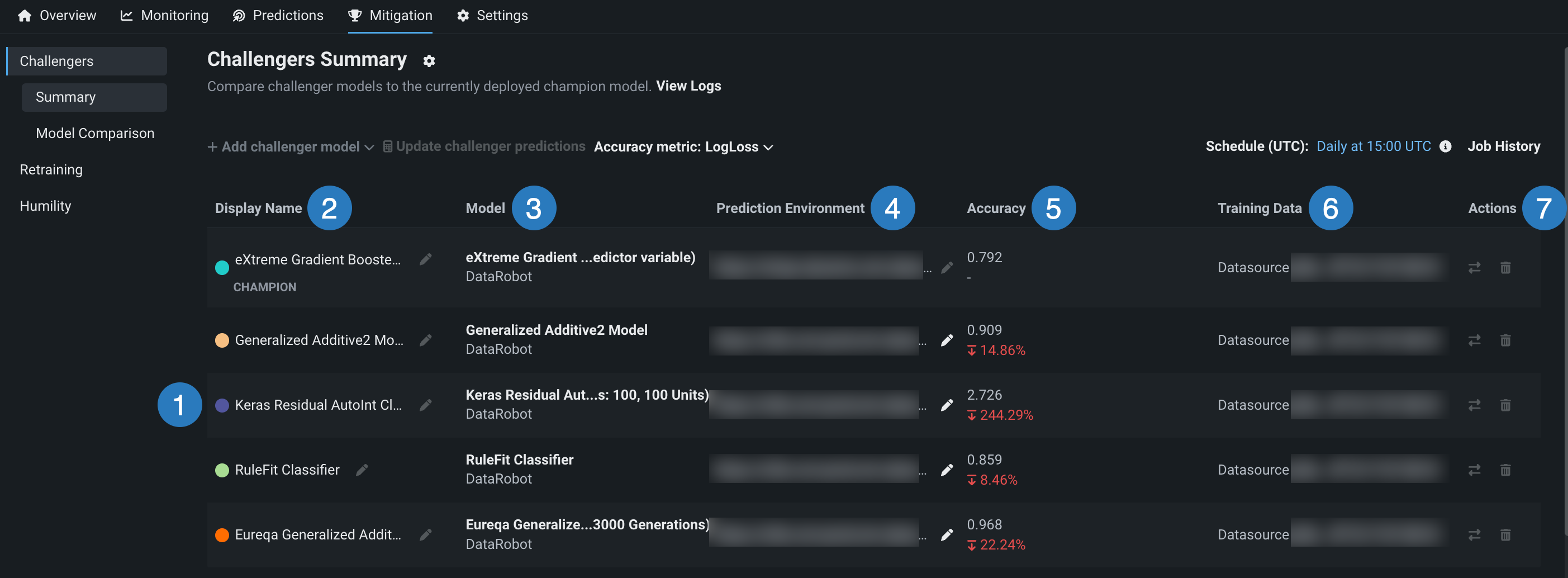
| 要素 | 説明 | |
|---|---|---|
| 1 | チャレンジャーモデル | チャレンジャーモデルのリスト。 各モデルは色で関連付けられています。 これらの色で、視覚化ツールを使用してモデルを比較できます。 |
| 2 | 表示名 | 各モデルの表示名。 鉛筆アイコンを使用して表示名を編集します。 このフィールドは、各チャレンジャーの目的または戦略を説明するのに役立ちます(「リファレンスモデル」、「以前のチャンピオン」、「削減済み特徴量」など)。 |
| 3 | モデル | モデル名と実行環境タイプ。 |
| 4 | 予測環境 | モデルがデプロイの予測に使用する環境。 詳細については、予測環境を参照してください。 |
| 5 | 精度 | 選択した日付範囲のモデルの精度指標計算、およびチャレンジャーの場合は、チャンピオンの精度指標計算との比較。 精度指標ドロップダウンメニューを使用すると、さまざまな指標を比較できます。 モデルの精度の詳細については、精度チャートを参照してください。 |
| 6 | トレーニングデータ | モデルのトレーニングに使用されるデータのファイル名。 |
| 7 | アクション | 各モデルで使用できるアクション:
|
チャレンジャーのパフォーマンス指標¶
チャレンジャーモデルで予測データが再実行されたら、スクロールダウンして、各モデルに記録されたパフォーマンス指標をとらえたさまざまなチャートを確認します。 チャートの表示をカスタマイズするには、表示する範囲、単位、セグメント、およびモデルを設定します。 各モデルは、対応する色でリストされています。 チャートへのモデルのパフォーマンスデータの表示を停止するには、モデルのボックスをオフにします。

| コントロール | 説明 | |
|---|---|---|
| 1 | 範囲セレクター(UTC) | デプロイ日付スライダーに表示する日付範囲を設定します。 範囲セレクターで選択できるのは、モデルのデプロイの現在のバージョンの開始日と現在の日付だけです。 |
| 2 | 日付スライダー | ダッシュボードで表示するデータの範囲を制限します(特定の期間にズームインするなど)。 |
| 3 | 単位セレクター | デプロイ日付スライダーの時間のきめ細かさを設定します。 選択した範囲に基づいて、次の時間単位が使用可能です。
|
| 4 | セグメント属性 / セグメント値 | セグメント分析で視覚化されるデータドリフトをフィルターするために、個々の属性と値を設定します。 |
| 5 | 表示を更新 | 新しいデータを使用してダッシュボードのオンデマンド更新を開始します。 このボタンを使用しなくても、ダッシュボードは15分ごとに自動更新されます。 |
| 6 | リセット | ダッシュボードコントロールをデフォルト設定に戻します。 |
| 7 | モデルセレクター | モデルのチェックボックスを選択またはクリアして、チャートにモデルのパフォーマンスデータを表示するか非表示にします。 |
予測チャート¶
予測チャートは、時間の経過に伴う各モデルのターゲットの平均予測値を記録します。 ポイントにカーソルを合わせると、特定の時点での各モデルの平均値が比較されます。
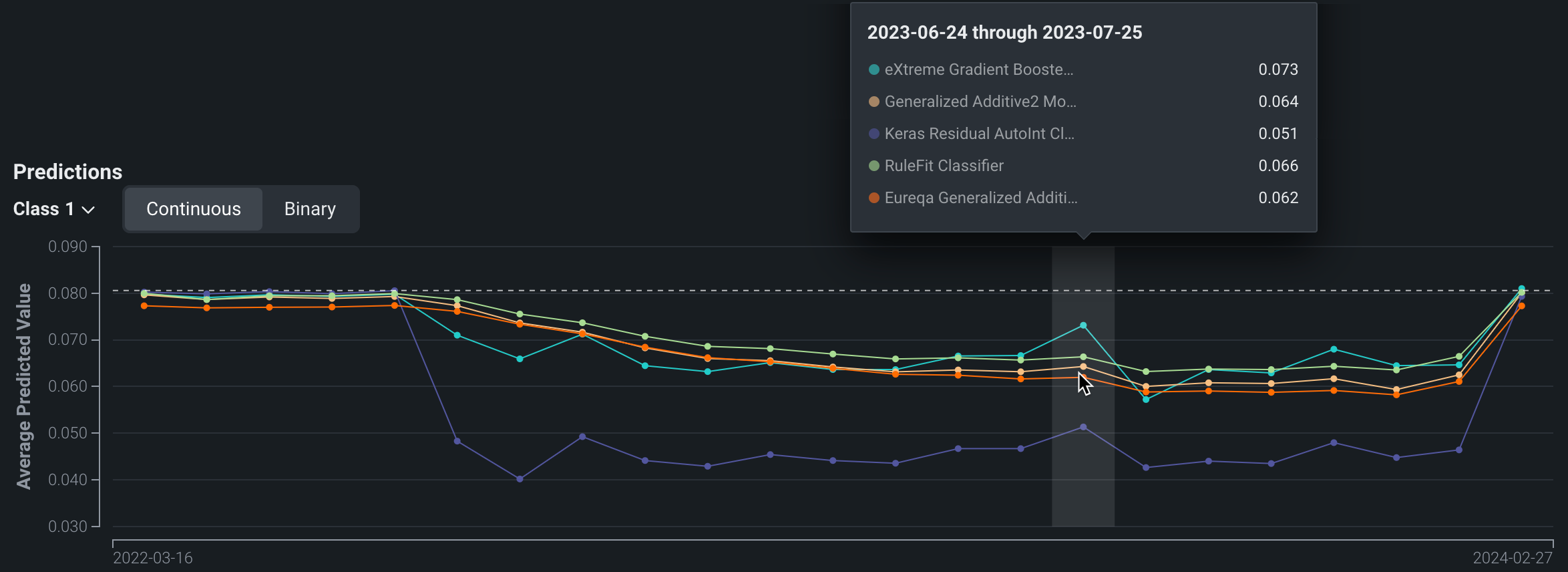
二値分類プロジェクトの場合、クラスドロップダウンを使用して、平均予測値を分析するクラスを選択します。 チャートには、連続モードと二値モードを切り替えるためのトグルも含まれています。 連続モードでは、予測しきい値を考慮せずに、Positiveクラス予測を0と1の間の確率として示します。 予測しきい値は考慮に入れられません。二値モードでは、予測しきい値が考慮に入れられ、作成されたすべての予測では各クラスのパーセンテージが示されます。
精度チャート¶
精度チャートには、選択した精度指標値(この例ではLogLoss)の時間経過に伴う変化が表示されます。 これらの指標は、デプロイ前にモデルの評価に使用される指標と同一です。 精度指標を変更するには、ドロップダウンを使用します。 デプロイのモデリングタイプでサポートされているいずれかの指標を選択できます。
精度追跡には関連付けIDが必要
予測を精度追跡に含めるには、予測を行う前に関連付けIDを設定する必要があります。
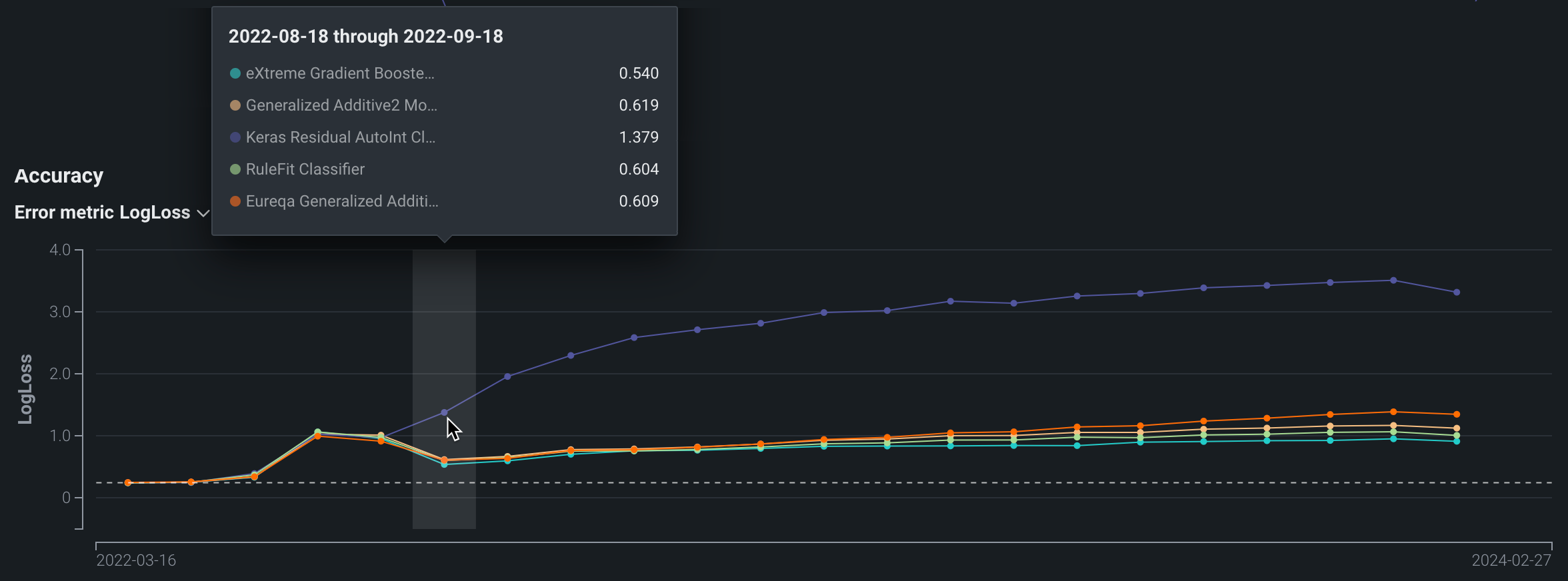
利用可能な指標は、デプロイに使用するモデリングプロジェクトのタイプ(連続値、二値分類または多クラス)によって異なります。
| モデリングタイプ | 使用可能な指標 |
|---|---|
| 連続値 | RMSE、MAE、Gamma Deviance、Tweedie Deviance、R Squared、FVE Gamma、FVE Poisson、FVE Tweedie、Poisson Deviance、MAD、MAPE、RMSLE |
| 二値分類 | LogLoss、AUC、Kolmogorov-Smirnov、Gini-Norm、Rate@Top10%、Rate@Top5%、TNR、TPR、FPR、PPV、NPV、F1、MCC、Accuracy、Balanced Accuracy、FVE Binomial |
| 多クラス | LogLoss、FVE多項式 |
備考
これらの指標の詳細については、 最適化指標のドキュメントを参照してください。
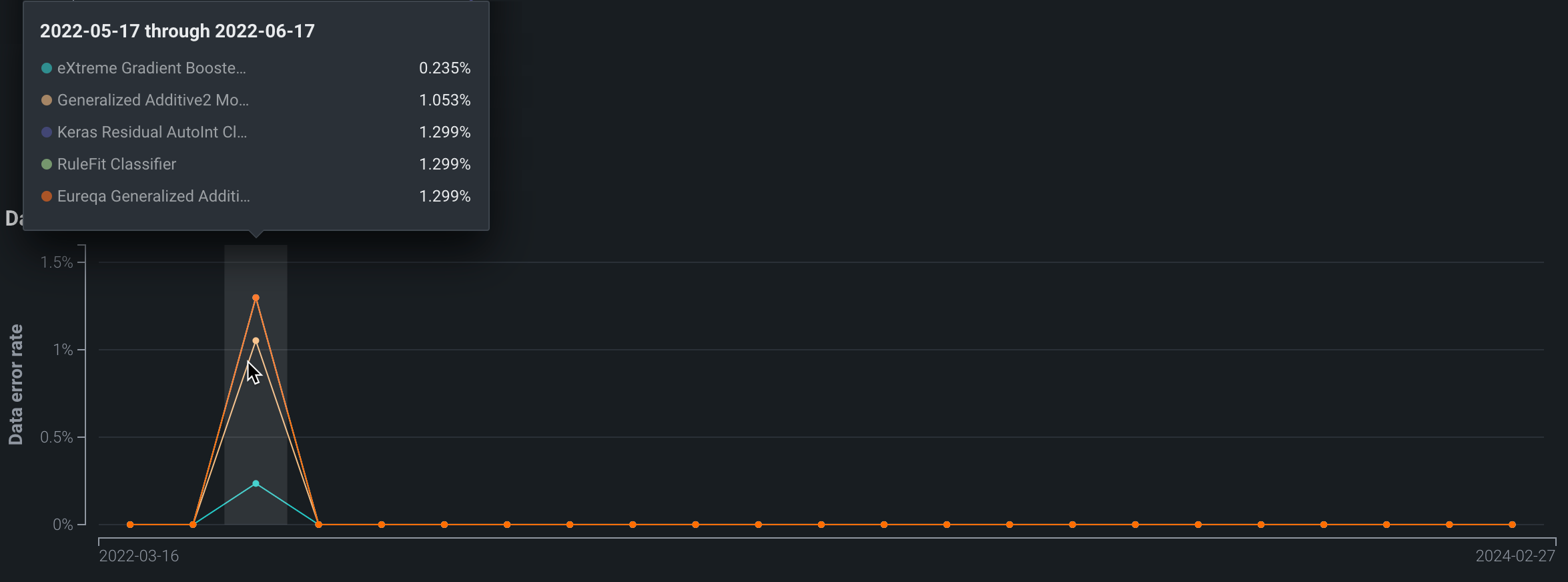
データエラーチャート¶
データエラーチャートは、時間の経過に伴う各モデルのデータエラー率を記録します。 データエラー率は 4xxエラーが発生したリクエストの割合(予測リクエスト送信の問題)を測定します。
カスタムセグメントとデータエラーチャート
ユーザー設定のセグメント属性が選択されている場合、データエラーチャートは利用できません。
チャレンジャーモデルの比較¶
MLOpsは、チャレンジャーモデルを相互に比較したり、現在デプロイされているモデル(「チャンピオン」)と比較したりして、デプロイがお客様のニーズに最適なモデルを使用するようにします。 DataRobotのモデル比較ビジュアライゼーションを評価した後、チャンピオンモデルをよりパフォーマンスの高いチャレンジャーに置き換えることができます。
DataRobotは、選択した専用の比較データセットに基づいてビジュアライゼーションをレンダリングし、同じデータセットとパーティションに基づいて予測を比較しながら、異なるデータセットでチャンピオンモデルとチャレンジャーモデルをトレーニングできるようにします。 たとえば、チャレンジャーモデルでは、チャンピオンに使用されるチャンピオンと同じデータソースの更新済みスナップショットを使用できます。
比較データセットに関する注意事項
比較データセットが、比較対象モデルのアウトオブサンプルであることを確認してください(つまり、比較に含まれるモデルのトレーニングデータが含まれていません)。
モデルの比較を生成する¶
チャレンジャーモデルを有効化し、1つ以上のチャレンジャーをデプロイに追加して予測を再実行すると、比較データと視覚化を生成できます。 コンソールで、比較するチャンピオンモデルとチャレンジャーモデルを含むデプロイのリスク軽減策 > チャレンジャータブで、モデル比較タブをクリックします。 モデルのインサイトセクションが空の場合、最初に以下に示すように インサイトを計算します。
次の表はモデル比較タブの要素を示しています。
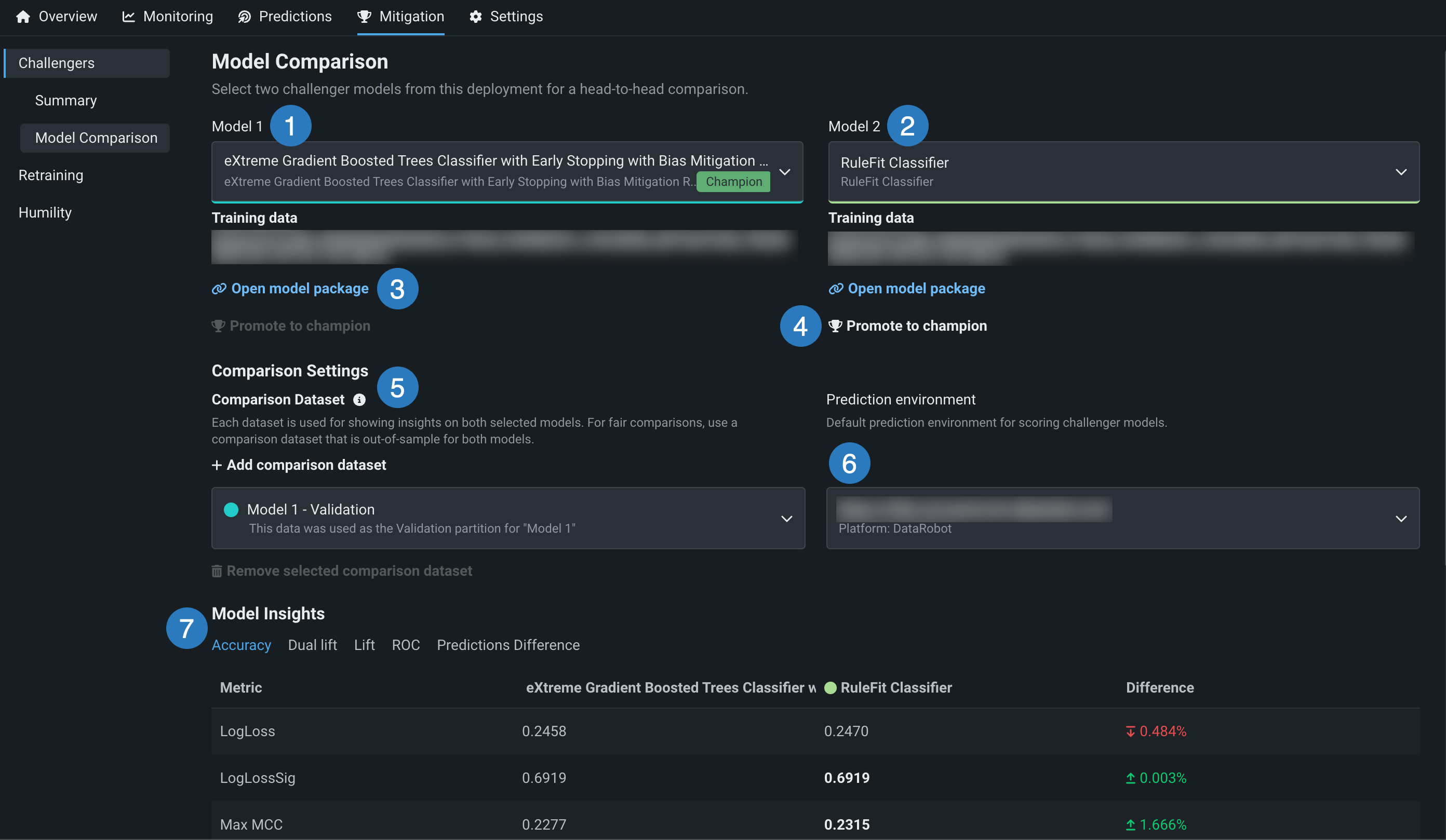
| 要素 | 説明 | |
|---|---|---|
| 1 | モデル1 | デフォルトは、チャンピオンモデル(現在デプロイされているモデル)です。 クリックして比較する別のモデルを選択します。 |
| 2 | モデル2 | デフォルトは、リストの最初のチャレンジャーモデルです。 クリックして比較する別のモデルを選択します。 リストにモデル1と比較するモデルが含まれていない場合は、チャレンジャーサマリータブをクリックして新しいチャレンジャーを追加します。 |
| 3 | モデルパッケージを開く | クリックすると、登録モデルの詳細が、レジストリ > モデルタブに表示されます。 |
| 4 | チャンピオンに昇格 | 比較のチャレンジャーモデルが(チャンピオンやすべてのチャレンジャーの中で)最適なモデルである場合、チャンピオンに昇格をクリックし、デプロイされたモデル(「チャンピオン」)をこのモデルに置き換えます。 |
| 5 | 比較データセットを追加 | 両方のモデルのインサイトを生成するデータセットを選択します。 必ず、両方のモデルのアウトオブサンプルであるデータセットを選択してください(スタックされた予測を参照)。 モデル1とモデル2のホールドアウトおよび検証パーティションは、これらのパーティションが元のモデルに存在する場合、オプションとして使用できます。 デフォルトでは、モデル1のホールドアウトパーティションが選択されています。 別のデータセットを指定するには、+ 比較データセットを追加をクリックし、データタブからローカルファイル、またはスナップショットが作成されたデータセットを選択します。 |
| 6 | 予測環境 | 両方のモデルをスコアリングする予測環境を選択します。 |
| 7 | モデルのインサイト | モデル予測、指標などを比較します。 |
インサイトを計算¶
モデルのインサイトセクションが空の場合は、インサイトを計算をクリックします。 +比較データセットを追加をクリックして、再度インサイトを計算を選択することで、別のデータセットを使用して新しいインサイトを生成できます。
モデル比較を表示¶
モデルのインサイトを計算すると、モデルインサイトページには、モデリングの種類に応じて次のタブが表示されます。
| 精度 | デュアルリフト | リフト | ROC | 予測の違い | |
|---|---|---|---|---|---|
| 連続値 | ✔ | ✔ | ✔ | ✔ | |
| 二値 | ✔ | ✔ | ✔ | ✔ | ✔ |
| 多クラス | ✔ | ||||
| 時系列 | ✔ | ✔ | ✔ | ✔ |
デュアルリフト、リフト、およびROCインサイトでは、2つのモデルの曲線は、(チャンピオンまたはチャレンジャーのいずれかとして)デプロイに追加されたときに割り当てられた色を維持します。
DataRobotがデプロイのモデルインサイトを計算した後、モデルの精度を比較できます。
モデルのインサイトの下で、精度タブをクリックして精度指標を比較します。
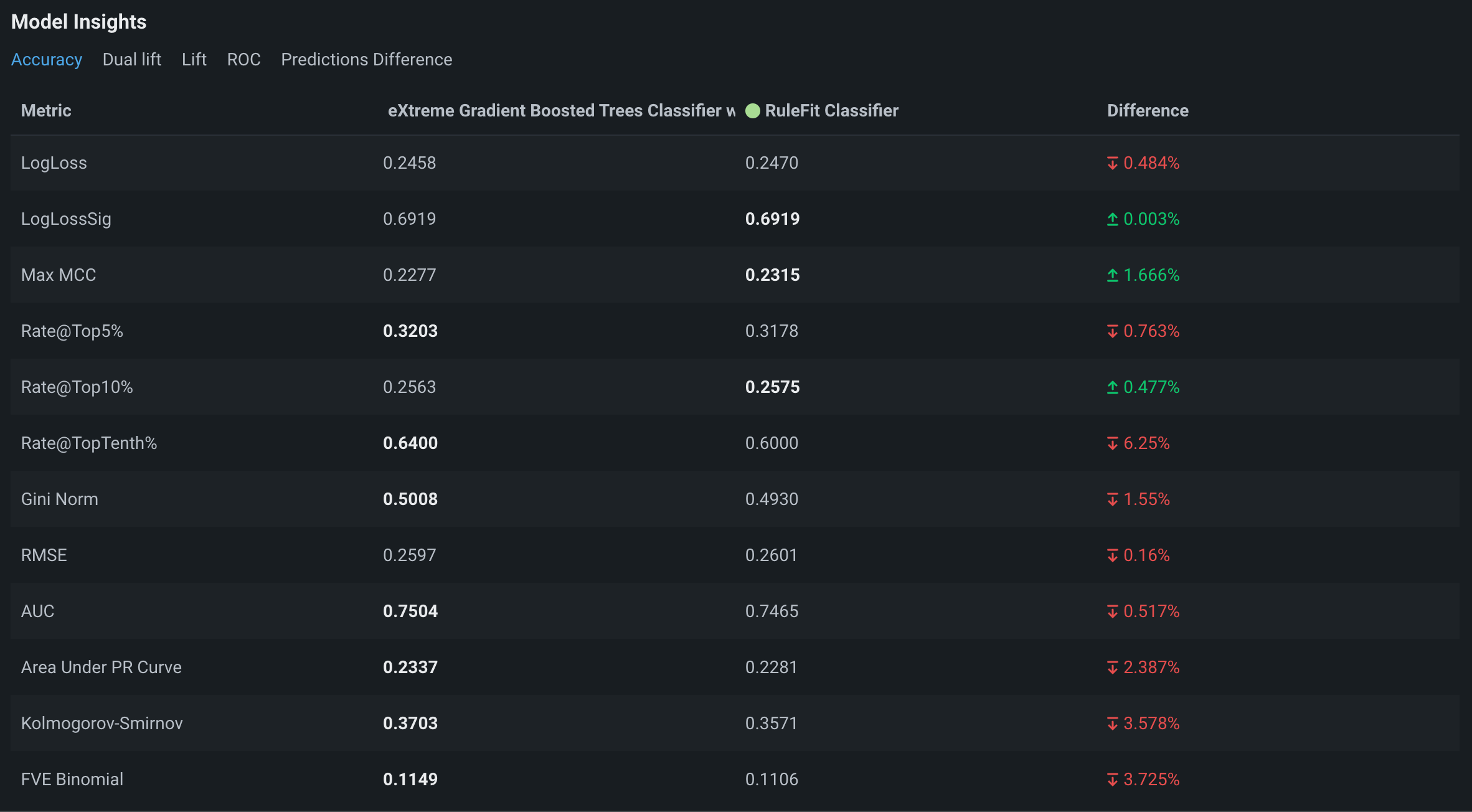
列は、各モデルの指標を示しています。 強調表示された数字は好ましい値を表しています。 この例では、チャンピオンのモデル1は表示されているほとんどの指標でモデル2よりも優れています。
時系列プロジェクトの場合、次のフィルターを適用して精度指標を評価できます。
-
すべてのx系列の場合:指標別の精度スコアを表示します。 このビューは、時系列範囲(x)全体にわたる両方のモデルで利用可能なすべての精度指標のスコアを報告します。
-
系列ごと:複数系列比較データセット内の系列ごとの精度スコアを表示します。 このビューは、両方のモデルのデータセット内の各系列ID(つまり、ストア番号)の単一の精度指標(指標ドロップダウンメニューで選択)のスコアを報告します。
多クラスプロジェクトの場合、次のフィルターを適用して精度指標を評価できます。
デュアルリフトチャート は、選択した2つのモデルを相互に比較するビジュアライゼーションです。 このビジュアライゼーションにより、モデルが予測の分布全体で実測値を過小予測または過大予測する方法を確認できます。 予測データは、昇順で同じサイズのビンに均等に分布されます。
モデルのインサイトの下で比較される2つのモデルのデュアルリフトチャートを表示するには、デュアルリフトタブをクリックします。
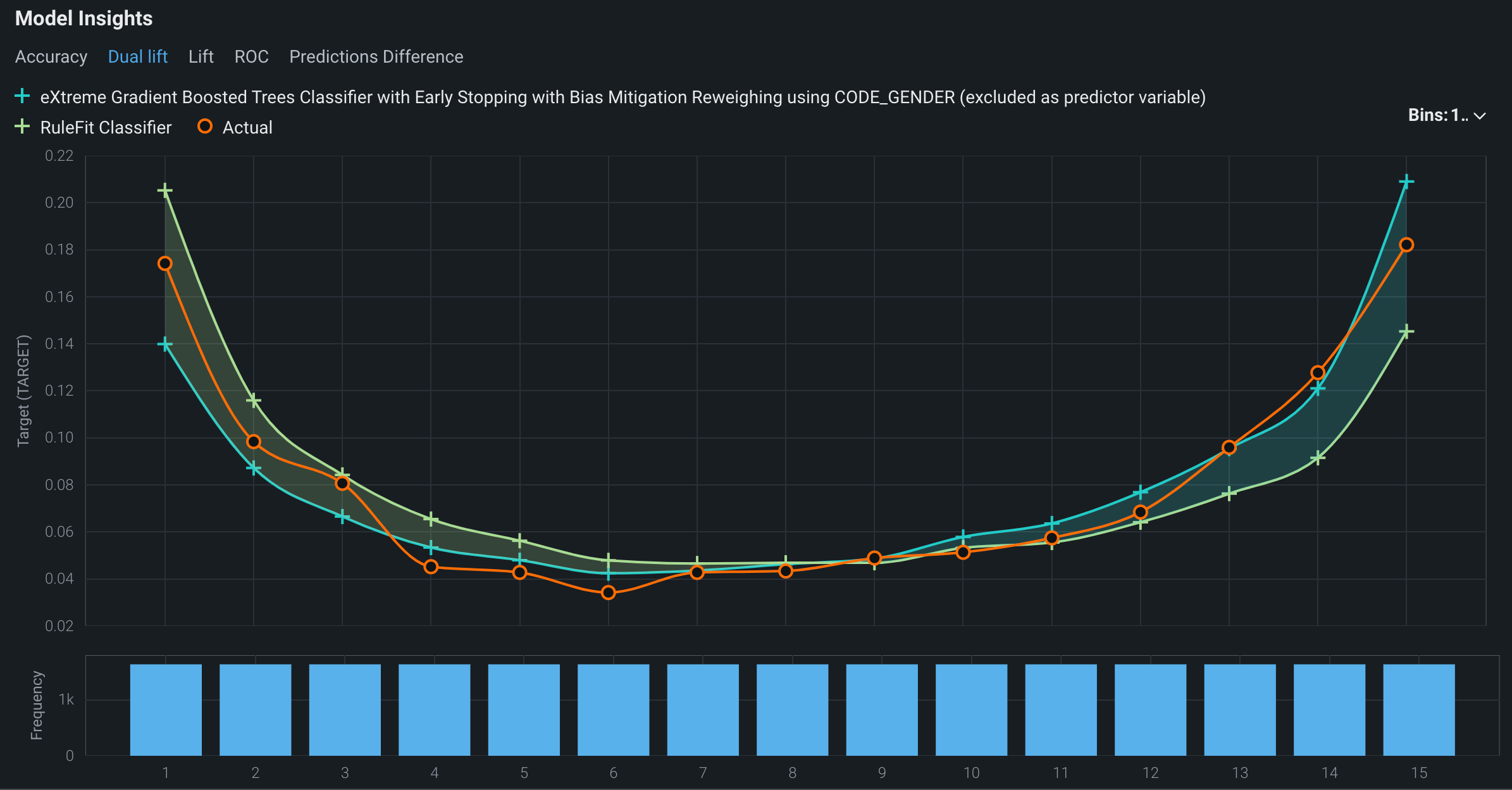
デュアルリフトチャートの曲線は、選択された2つのモデルとデプロイの 実測値を表します。 モデル曲線または実測値曲線のいずれかを非表示にすることができます。
- チャートのプロット領域にある+アイコンは、モデルの予測値を表します。 ヘッダーのモデル名の横にある+アイコンをクリックすると、特定のモデルの曲線の表示/非表示が切り替わります。
- チャートのプロット領域にあるオレンジ色のアイコンは、実測値を表します。 実測値の横にあるオレンジ色のアイコンをクリックすると、実測値を表示する曲線の表示/非表示が切り替わります。
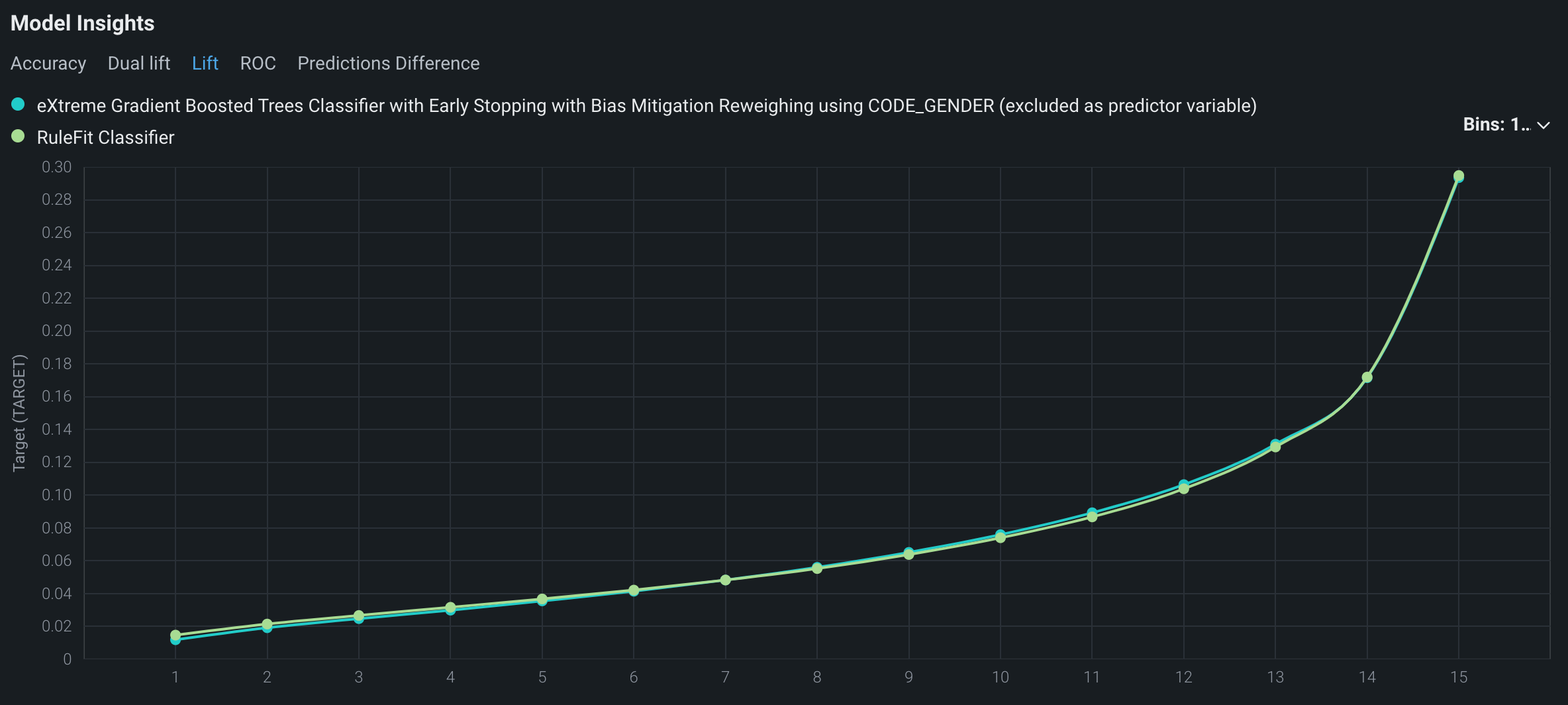
リフトチャートは、モデルがターゲットの母集団をどの程度うまく分割しているか、そしてターゲットを予測することができるかを示し、モデルの有効性を視覚化できます。
比較されるモデルのリフトチャートを表示するには、モデルのインサイトの下でリフトタブをクリックします。
備考
[ROC]タブは二値分類プロジェクトでのみ使用できます。
あるデータソースに基づき、True Positive RateをFalse Positive Rateに対比させる形でプロットしたものがROC曲線です。 ROC曲線を使用して、比較するモデルの分類、パフォーマンス、統計を調査します。
比較されるモデルのROC曲線を表示するには、モデルのインサイトの下でROCタブをクリックします。
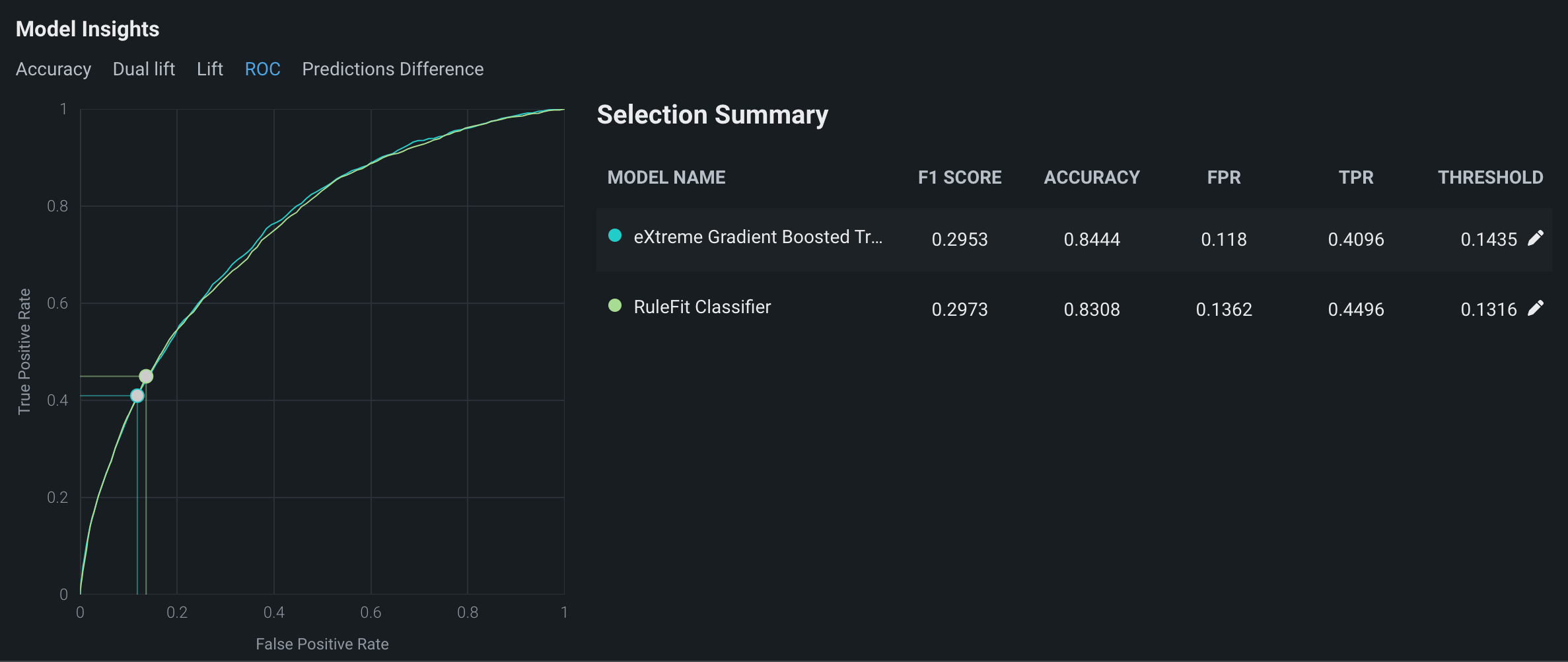
鉛筆アイコンをクリックして、モデルの予測しきい値を更新できます。
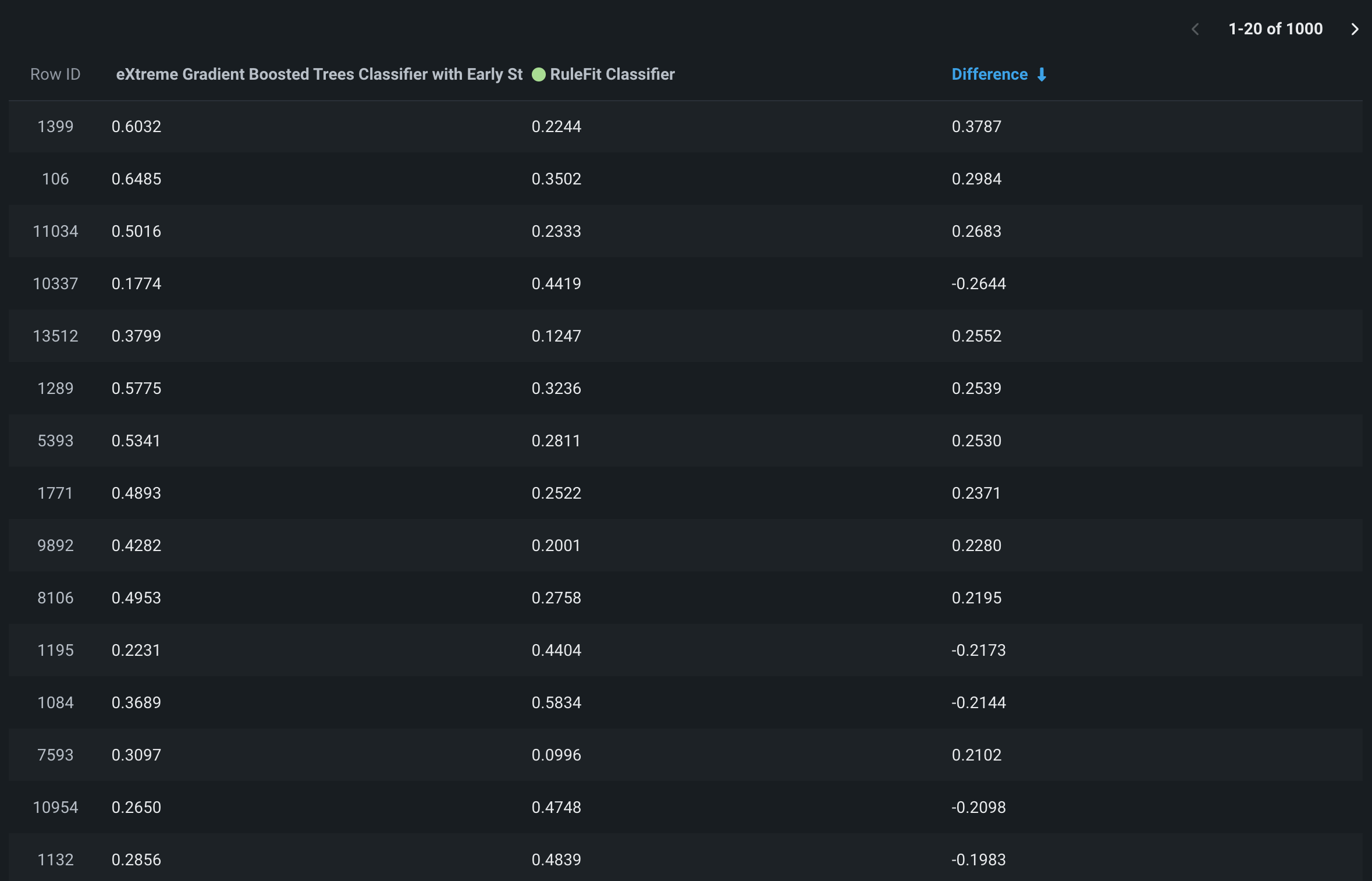
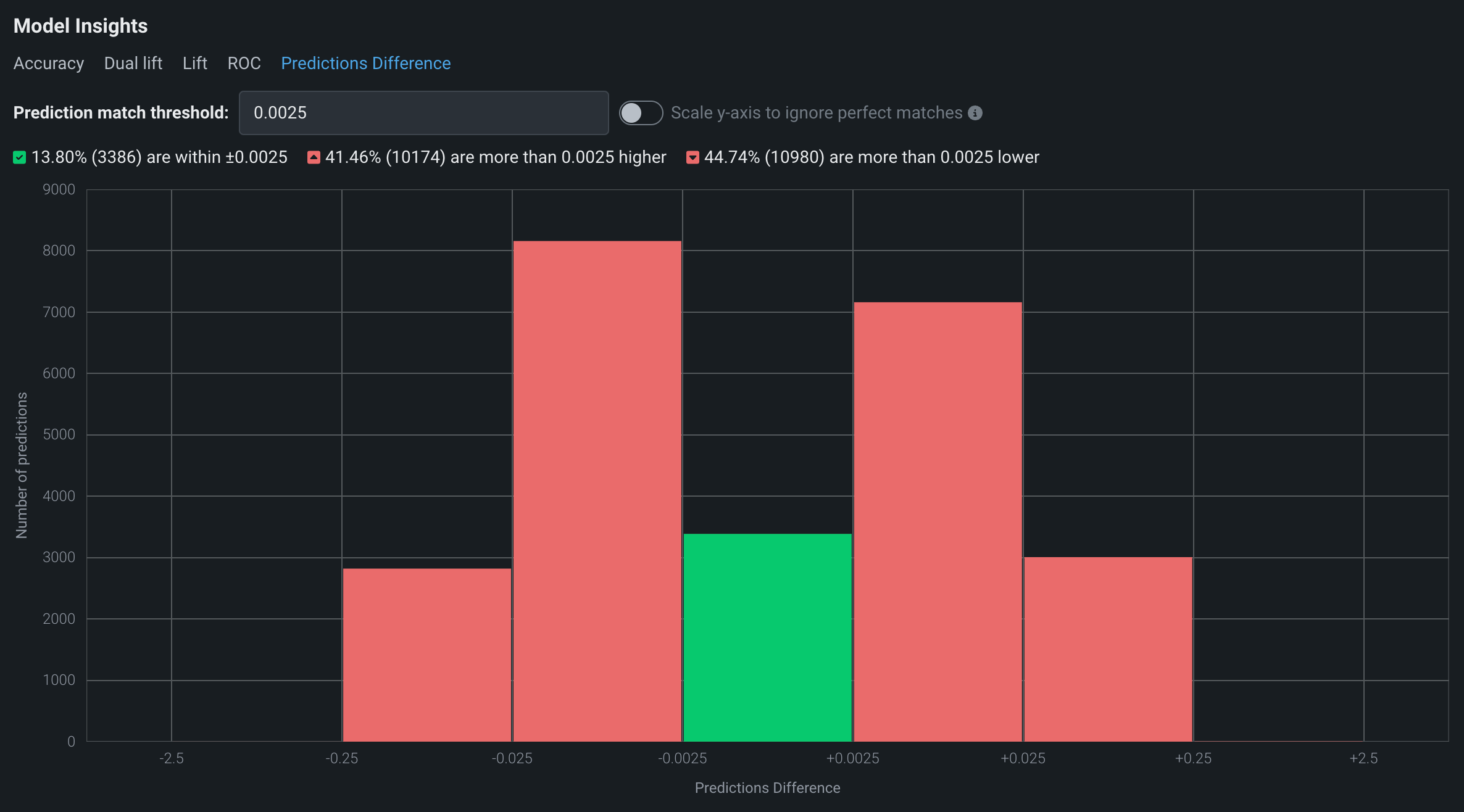
予測の違いタブをクリックして、2つのモデルの予測を1行ごとに比較します。 ヒストグラムには、予測一致しきい値フィールドで指定した一致しきい値内にある予測のパーセンテージが(対応する行数とともに)表示されます。
ヒストグラムのヘッダーには、予測のパーセンテージが表示されます。
- 一致しきい値の正の値と負の値の間(緑色で表示)
- 一致しきい値の上限(正)より大きい(赤で表示)
- 一致しきい値の下限(負)より小さい(赤で表示)
ビンサイズの計算方法
ヒストグラムの予測の違いビンのサイズは、設定した予測一致しきい値によって異なります。 予測一致しきい値ビンの値は、一致しきい値の上限(正)と一致しきい値の下限(負)の差に等しくなります。 デフォルトの予測一致しきい値は0.0025であるため、その値の場合、中央のビンは0.005(0.0025 + | -0.0025 | )。 中央のビンの両側のビンは、前のビンの10倍の大きさです。 両端の最後のビンは、予測の違いの範囲全体に合うように拡大されます。 たとえば、デフォルトの予測一致しきい値に基づくと、ビンのサイズは次のようになります(xは250と最大予測値の違いの差):
| ビン-5 | ビン-4 | ビン-3 | ビン-2 | ビン-1 | ビン0 | ビン1 | ビン2 | ビン3 | ビン4 | ビン5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 範囲 | (−250 + x)~−25 | −25~−2.5 | −2.5~−0.25 | −0.25~−0.025 | −0.025~−0.0025 | −0.0025~+0.0025 | +0.0025~+0.025 | +0.025~+0.25 | +0.25~+2.5 | +2.5~+25 | +25~(+250 + x) |
| 範囲 | 225 + x | 22.5 | 2.25 | 0.225 | 0.0225 | 0.005 | 0.0225 | 0.225 | 2.25 | 22.5 | 225 + x |
ヒストグラムを希釈する一致が多数ある場合は、y軸をスケールして完全一致を無視を切り替えて不一致にフォーカスできます。 予測の違いタブの下部セクションには、1000個の最も異なる予測(絶対値)が示されています。 違い列は予測がどの程度離れているかを示します。