再トレーニング¶
DataRobotは、大規模な手作業を行うことなくデプロイ後のモデルのパフォーマンスを維持するために、デプロイに対して自動再トレーニング機能を提供しています。 リスク軽減策 > 再トレーニングタブで、データレジストリに登録された再トレーニングデータセットを指定すると、1つのデプロイに対して最大5つの再トレーニングポリシーを定義できます。 各ポリシーは、トリガー、モデリング戦略、モデリング設定、および置換アクションで構成されます。 トリガーされると、再トレーニングによりこれらの設定に基づいて新しいモデルが作成され、そのモデルのプロモーションを検討するように通知されます。
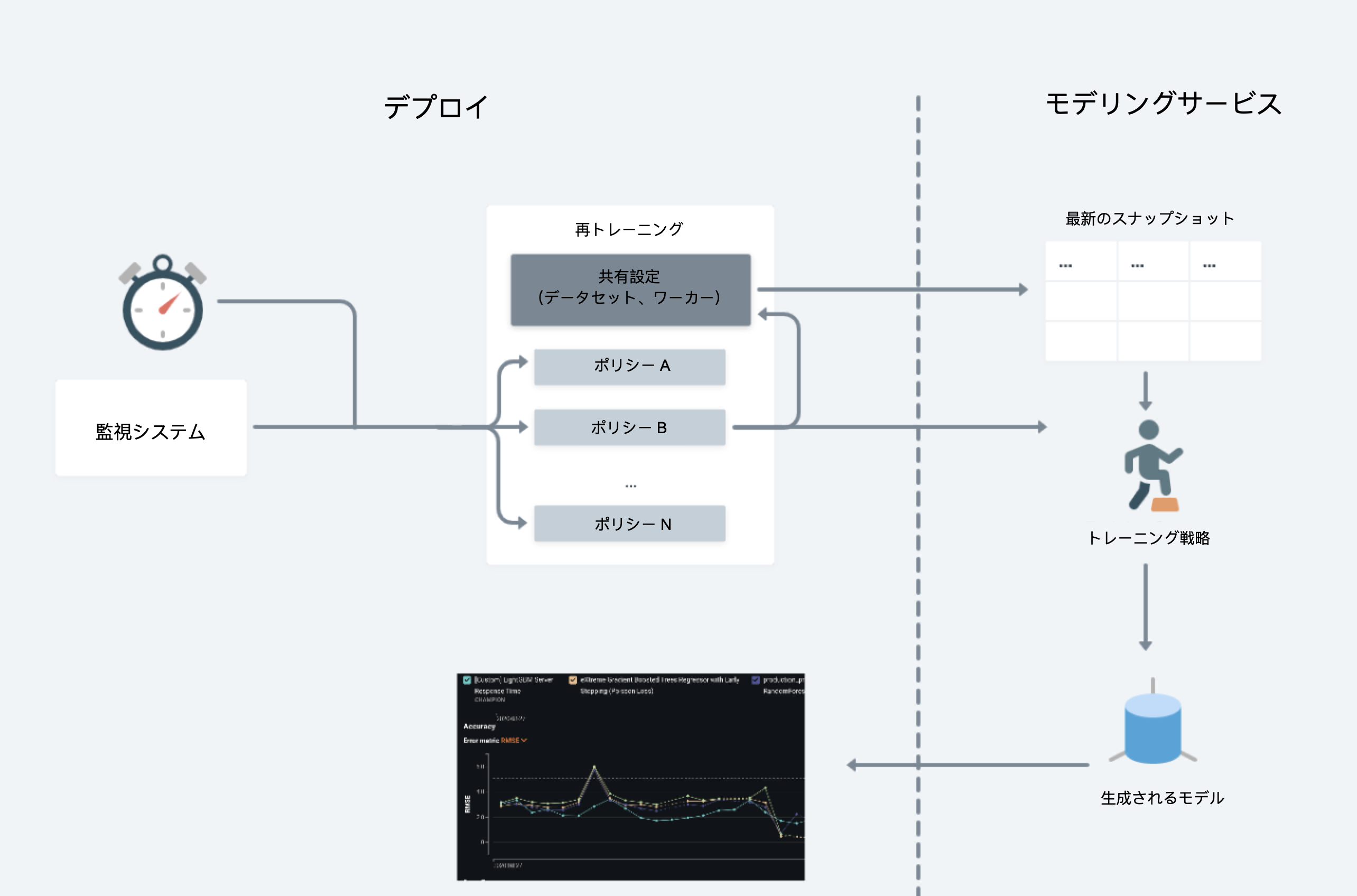
再トレーニングの設定
自動再トレーニングのポリシーを設定するには、デプロイの再トレーニング設定を行う必要があります。
自動再トレーニングポリシーの作成¶
デプロイの再トレーニングポリシーを作成して定義するには、デプロイのリスク軽減策 > 再トレーニングタブに移動します。
-
再トレーニングのサマリータブで、+ 再トレーニングポリシーの追加をクリックします。
再トレーニングを設定していない場合は、再トレーニングの設定をクリックし、再トレーニングの設定を行います。
-
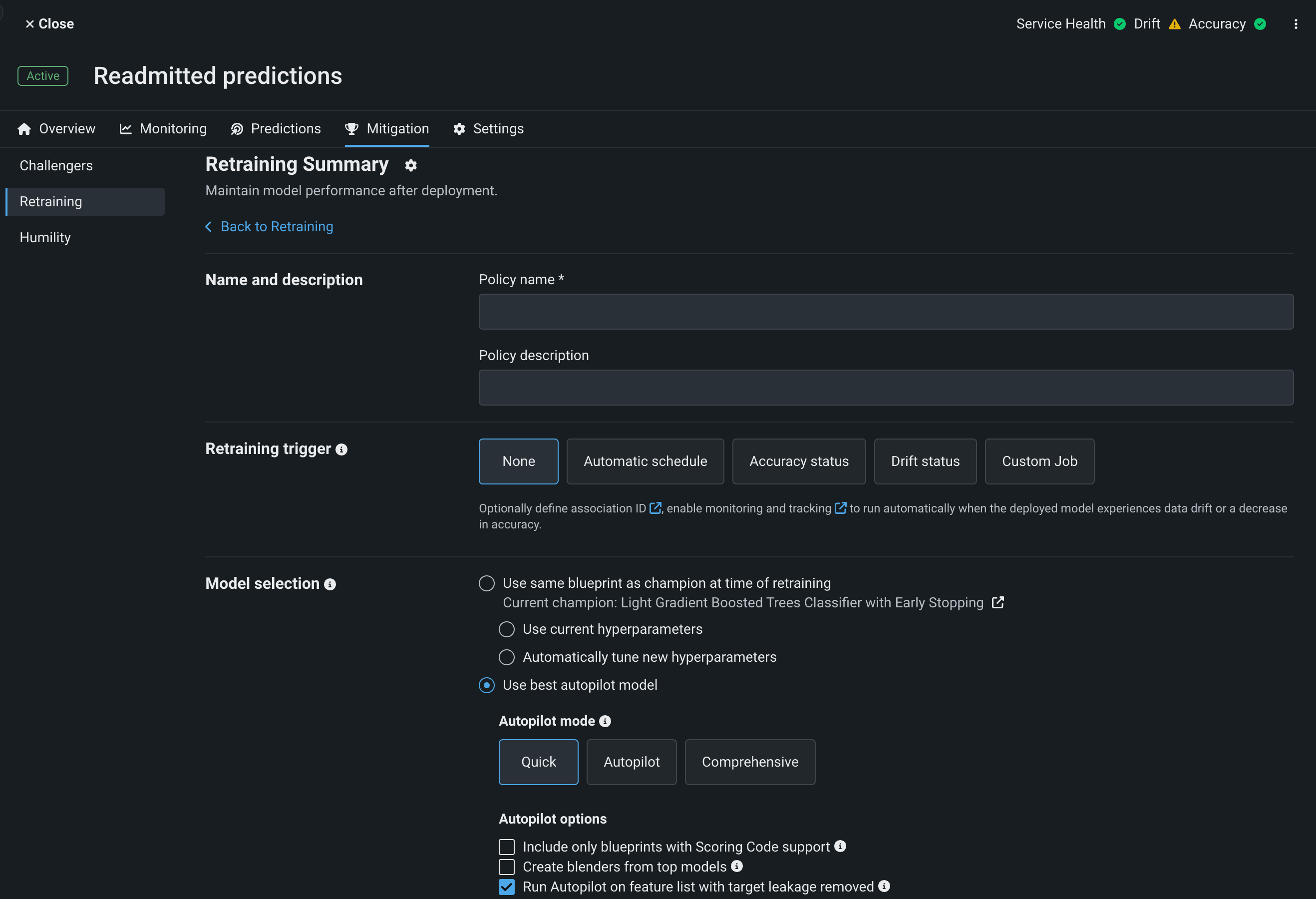
ポリシー名と、オプションでポリシーの説明を入力します。
-
以下の再トレーニングポリシー設定を行います。
-
再トレーニングのトリガー:DataRobotがいつ再トレーニングを実行するかを決定するために使用する時間またはデプロイステータスイベントを選択します。
-
モデルの選択:更新されたデータで新しいモデルを構築するために、DataRobotが使用すべき方法を設定します。
-
モデルのアクション:再トレーニングポリシーの正常な実行時にトレーニングされたモデルに対して、DataRobotが使用すべき置換戦略を選択します。
-
モデリング戦略:DataRobotでの新しいオートパイロットプロジェクトのセットアップ方法を設定します。
-
-
ポリシーを保存するをクリックします。
再トレーニングのトリガー¶
再トレーニングポリシーを手動でまたは3種類の条件に応じてトリガーできます。

-
自動スケジュール:再トレーニングポリシーが自動的にトリガーされる時間を選択します。 3か月に1回から毎日までの範囲で選択することができます。 DataRobotはローカルタイムゾーンを使用します。
-
精度ステータス:デプロイの精度ステータスが良好な状態から選択したレベル(緑色から黄色、黄色から赤色など)に変化した場合、再トレーニングを開始します。 ステータス変更の設定を行った後、ステータスの頻度オプションを設定し、精度ステータスが「注意」または「失敗」のままの場合に、DataRobotが(ISO文字列で定義された間隔で)通知を送信し続けるかどうかを決定することもできます。
-
ドリフトステータス:デプロイのデータドリフトステータスが選択したレベルまで低下すると、再トレーニングを開始します。(緑色から黄色、黄色から赤色など) ステータス変更の設定を行った後、ステータスの頻度オプションを設定し、ドリフトステータスが「注意」または「失敗」のままの場合に、DataRobotが(ISO文字列で定義された間隔で)通知を送信し続けるかどうかを決定することもできます。
ドリフトと精度のトリガー定義
データドリフトと精度のトリガーは、設定 > データドリフトタブと設定 > 精度タブで行われた定義に基づいています。
一度開始された再トレーニングポリシーは、完了するまで再トリガーできません。 たとえば、再トレーニングポリシーを1時間ごとに実行する設定で、完了に1時間以上かかる場合、次にスケジュールされているトリガーでやり直したり、キューに入れたりするのではなく、最初の実行を完了させます。 各再トレーニングポリシーで選択できるトリガー条件は1つだけです。
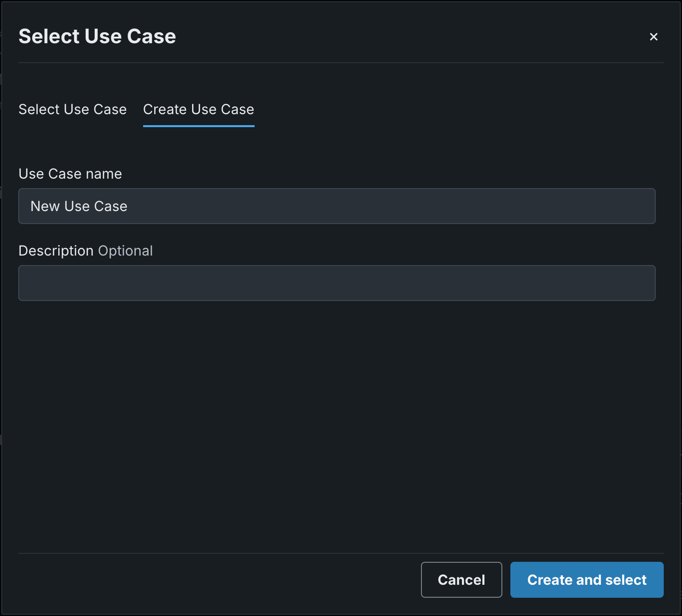
ユースケース¶
再トレーニングポリシーをワークベンチのユースケースにリンクするには、既存のユースケースを選択するか、新しいユースケースを作成します。 再トレーニングポリシーがユースケースにリンクされると、登録済みの再トレーニングモデルは、ユースケースのアセットで詳細 > 登録済みのモデル の下にリストされます。
ユースケースに再トレーニングポリシーをリンクするには、ユースケースセクションで+ ユースケースを選択をクリックします。
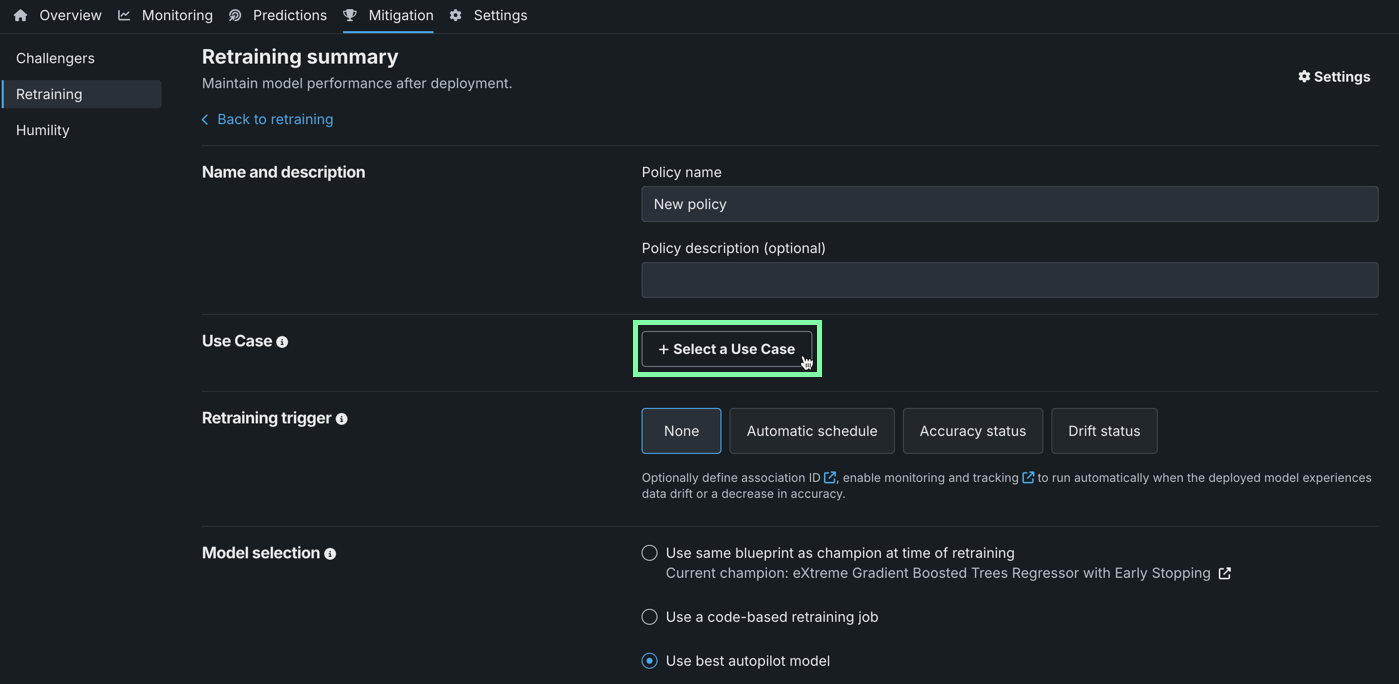
ユースケースを選択モーダルで、ユースケースを選択またはユースケースの作成をクリックします。
デフォルトのユースケースのリンク
デプロイがユースケースにリンクされている場合、そのデプロイの再トレーニングポリシーと結果として再トレーニングされたモデルは、そのユースケースに自動的にリンクされます。ただし、各ポリシーのデフォルトのユースケースを上書きできます。
ユースケース名リストから既存のユースケースを選択し、ユースケースを選択をクリックします。
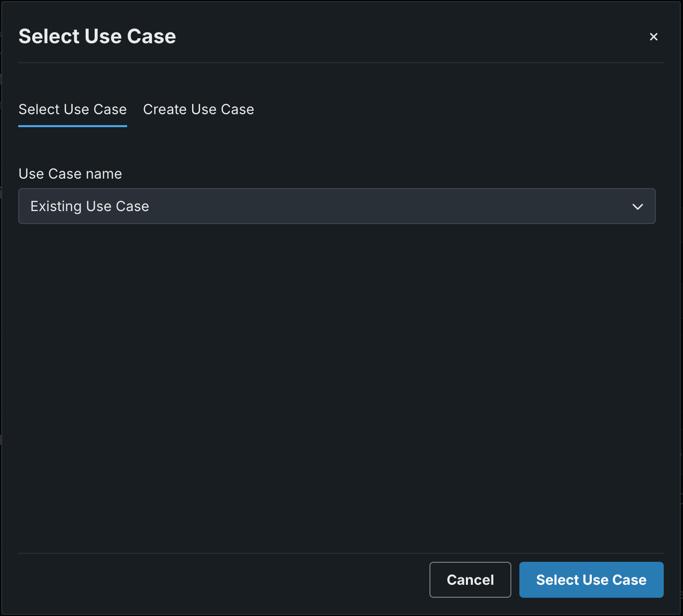
ユースケース名および必要に応じて説明を入力し、作成と選択をクリックします。
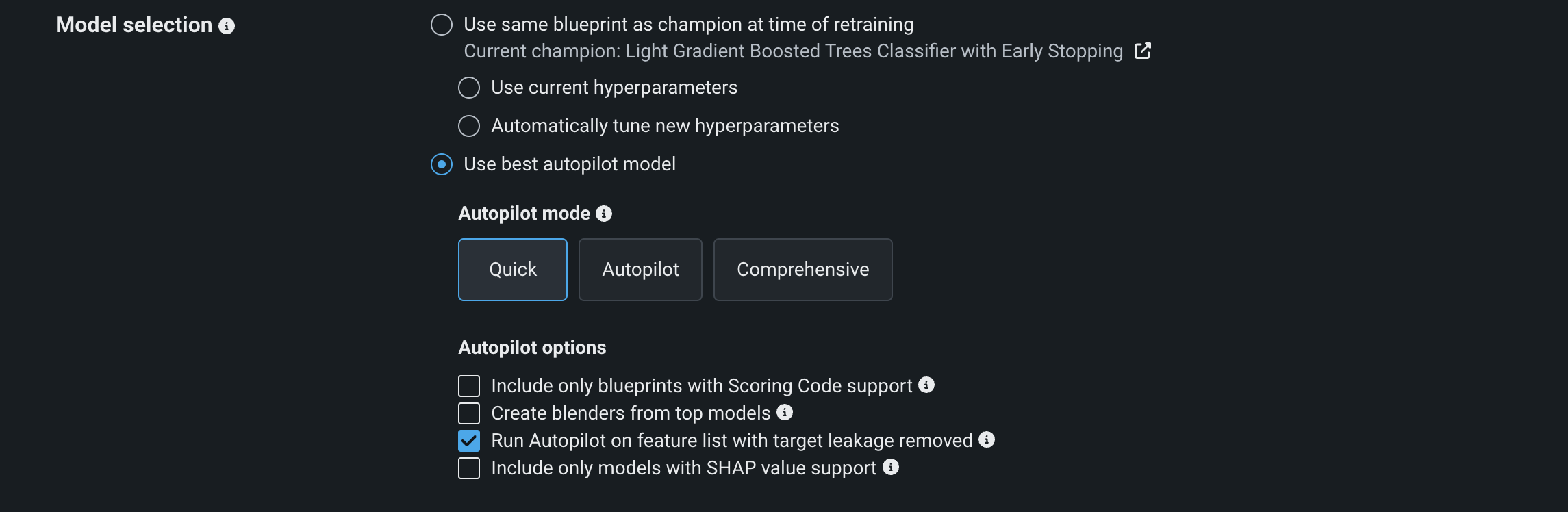
モデルの選択¶
再トレーニングポリシーのモデリング戦略を選択します。DataRobotが更新されたデータで新しいモデルを構築する方法を制御します。
-
再トレーニング時にチャンピオンと同じブループリントを使用:新しいデータスナップショットでのトリガー時に、チャンピオンモデルと同じブループリントに適合します。 次のいずれかのオプションを選択:
-
現在のハイパーパラメーターを使用:チャンピオンモデルと同じハイパーパラメーターとブループリントを使用します。 ブループリントの各タスクには、チャンピオンのハイパーパラメーター検索および戦略を使用します。 このオプションを選択すると、チャンピオンモデルの特徴量セットが再トレーニングに使用されることに注意してください。 有用な特徴量セットは使用できません。
-
ハイパーパラメーターを自動的に調整:同じブループリントを使用しますが、再トレーニング用にハイパーパラメーターを最適化します。
-
-
コードベースの再トレーニングジョブの使用:選択したカスタム再トレーニングジョブのコードで定義された再トレーニングプロセスを実行します。
-
カスタム再トレーニングジョブを作成済みの場合、カスタム再トレーニングジョブを選択ドロップダウンリストで、使用する再トレーニングタイプのカスタムジョブをクリックします。
-
カスタム再トレーニングジョブを作成していない場合は、+ 新しい再トレーニングジョブを追加をクリックして、ジョブワークショップの再トレーニングタブを開き、 新しいカスタム再トレーニングジョブを定義します。 再トレーニングジョブを作成した後、再トレーニングポリシーに戻って新しいジョブをポリシーに関連付けることができます。
コードベースの再トレーニングジョブのスケジュールに関する注意事項
コードベースの再トレーニングジョブに基づいて再トレーニングポリシーを設定する場合は、次の点を考慮してください。
- 再トレーニングポリシーのスケジュールを更新すると、接続されたコードベースの再トレーニングジョブのスケジュールも更新されます。
- 再トレーニングポリシー設定でデータドリフトまたは精度トリガーを定義すると、_ スケジュール _に加えて、選択したトリガーがスケジュールされたコードベースの再トレーニングジョブに適用されます。
- 再トレーニングポリシーを削除しても再トレーニングジョブは削除されず、コードベースの再トレーニングジョブで定義されたスケジュールで引き続き実行できます。
- 再トレーニングポリシーとジョブをリンクするには、
DEPLOYMENTとRETRAINING_POLICY_IDのランタイムパラメーターを含む既存のmetadata.yamlが必要です。 - 再トレーニングジョブにリンクした後に再トレーニングポリシーを保存すると、再トレーニングジョブの
DEPLOYMENTとRETRAINING_POLICY_IDのランタイムパラメーターが設定されます。ただし、再トレーニングジョブには既に指定されたDEPLOYMENTパラメーターがあり、現在のポリシーのデプロイと異なる場合は、ランタイムパラメーターは更新されません。 以前のデプロイのリンクを解除して、現在のデプロイにジョブをリンクするようにプロンプトするメッセージが表示されます。
-
-
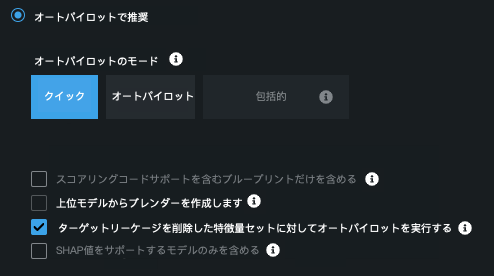
最適なオートパイロットモデルを使用(推奨):新しいデータスナップショットでオートパイロットを実行し、結果として得られる推奨モデルを使用します。 クイックまたはオートパイロットモデリングモードから選択します。 選択すると、オートパイロットのその他のオプションを切り替えることもできます。
- スコアリングコードをサポートするブループリントのみを含める。
- パフォーマンスが上位のモデルからアンサンブルを作成。
- ターゲットリーケージを削除した特徴量セットに対してオートパイロットを実行する。
- SHAP値をサポートするモデルのみ含める。
備考
コンソールのUIを使用してモデルを再トレーニングする場合、包括モードは有効になりません。 再トレーニングポリシーを包括モードに設定するには、APIを使用します。
モデルのアクション¶
モデルアクションにより、再トレーニングポリシーの実行が成功したときに生成されるモデルの処理が決定されます。 すべてのシナリオで、デプロイオーナーに新しいモデルの作成について通知され、レジストリにモデルパッケージとして新しいモデルが追加されます。 各ポリシーに対して次の3つのアクションのいずれかを適用します。

-
チャレンジャーモデルとして新しいモデルを追加:デプロイの5つのチャレンジャーモデルスロットに空きがある場合、このアクション(デフォルト)は、新しいモデルをチャレンジャーモデルとして追加します。 このポリシーによって以前に追加されたモデルが置き換えられます。 利用可能なスロットがなく、このポリシーによってチャレンジャーモデルが追加されたことがない場合、モデルはレジストリにのみ保存されます。 さらに、モデルをチャレンジャーとして追加できないため、再トレーニングポリシーの実行が失敗します。 再トレーニングポリシーによって追加されたチャレンジャーは、トレーニングデータがスコアリングデータにリークすることを防ぐために、過去のデータで再スコアリングされることはありません。
-
新しいモデルとの置換を開始:このオプションは高頻度(毎日など)の置換に適しており、新しいモデルが作成されるとすぐに、モデルの置換を自動的に要求します。 この置換は、オーナーと重要度に応じて、定義済みの承認ポリシー、および特定のデプロイへのそれらポリシーの適用に従います。 その承認ポリシーによっては、置換が行われる前に、レビュアーが手動で承認する必要があります。
-
モデルを保存:この場合、モデルをレジストリに追加する以外の操作は実行されません。
コードベースの再トレーニングによるモデルアクション
モデル選択設定でコードベースの再トレーニングを選択した場合、 再トレーニングジョブのコードで選択したモデルアクションを上書きできます。
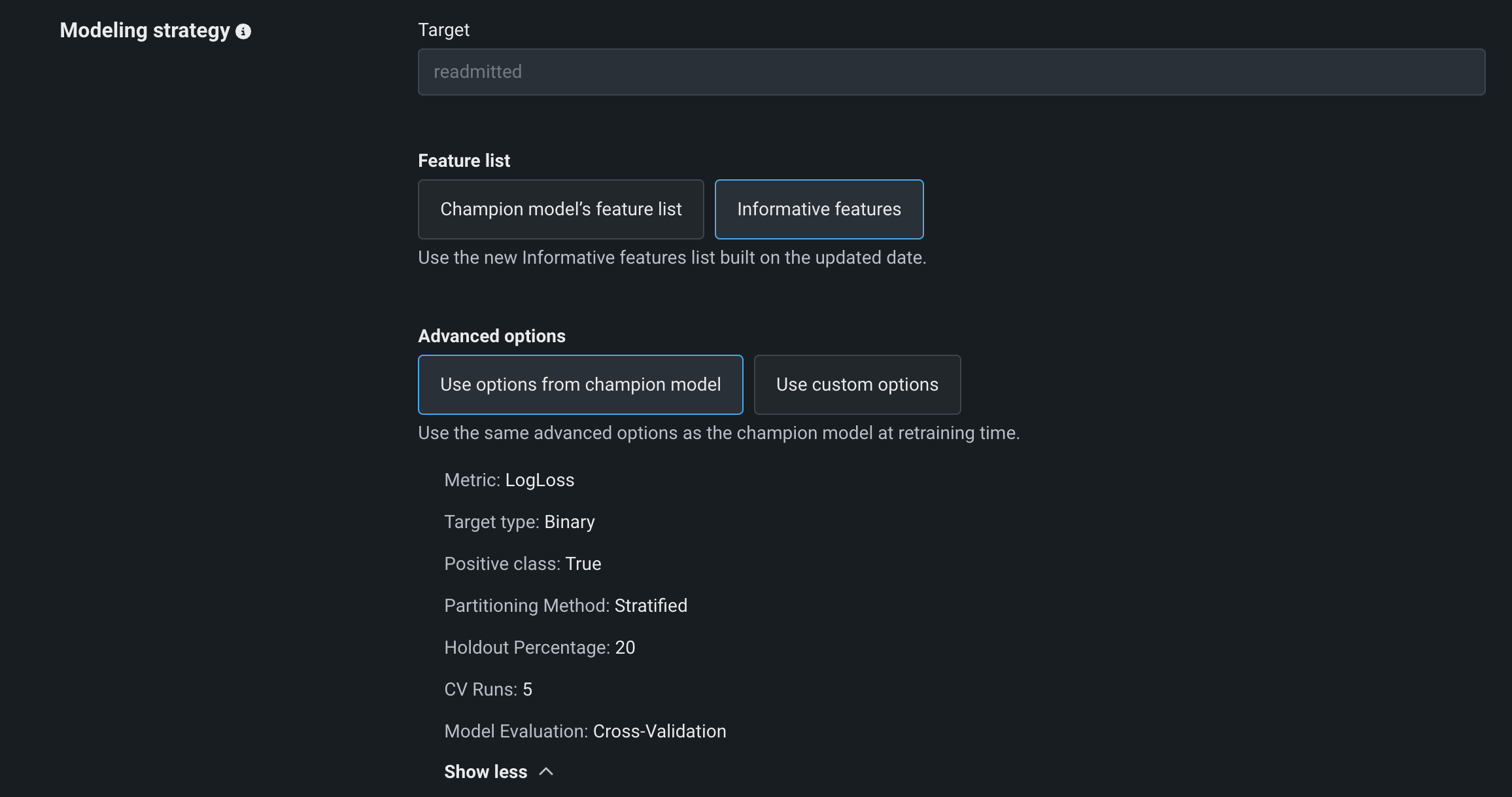
モデリング戦略¶
再トレーニングモデリング戦略は、DataRobotで新しいモデリングの実行を設定する方法を定義します。 特徴量、最適化指標、パーティショニング戦略、サンプリング戦略、加重などの 詳細設定 を定義して、特定の問題に対するモデルの構築方法をDataRobotに指示します。
(トリガーが開始されたときに)チャンピオンモデルが使用するのと同じ特徴量を再利用することも、DataRobotが新しいデータから有益な特徴量を識別できるようにすることもできます。
デフォルトでは、DataRobotは、チャンピオンモデル(トリガー開始時)と同じ設定を再利用します。 あるいは、新しいエクスペリメントを構築する場合に利用可能なオプションのサブセットから選択して、新しいパーティション設定を定義することもできます。
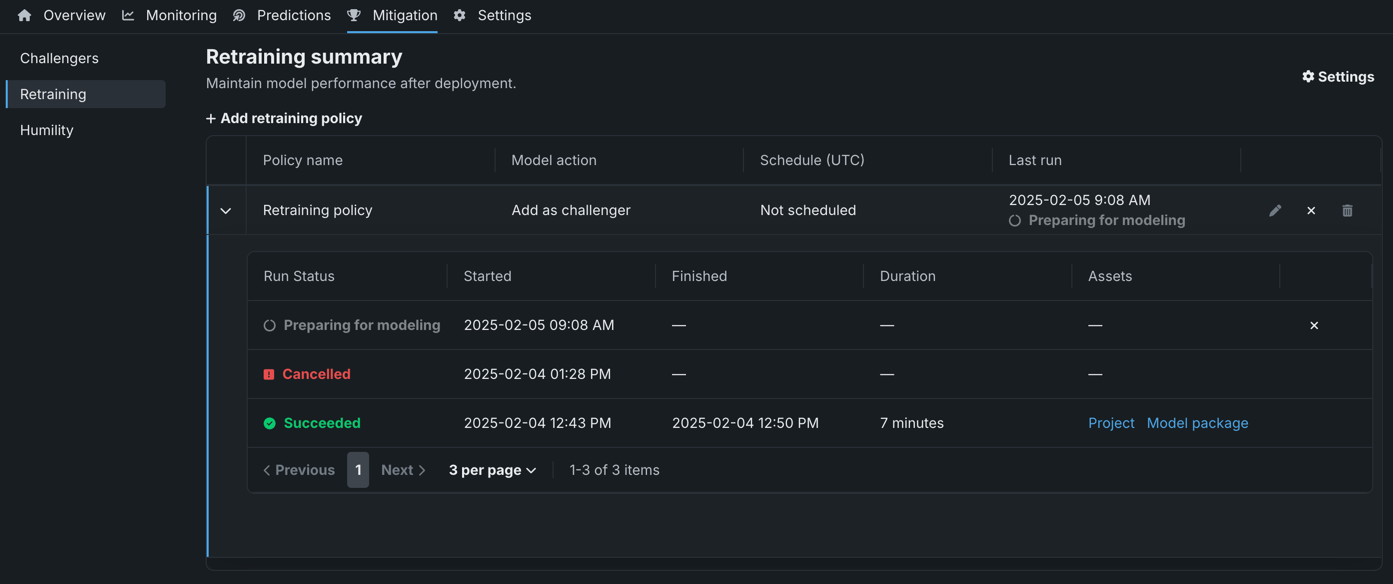
再トレーニングポリシーの管理¶
再トレーニングポリシーを作成したら、次の表で説明するように、手動で開始、キャンセル、または更新できます。

| 要素 | 定義 | |
|---|---|---|
| 1 | ポリシー | 再トレーニングポリシー行をクリックすると、開始時間、終了時間、期間、および実行が成功したかどうかを含む、成功または失敗したトレーニングポリシーのすべての以前の実行に関する情報が表示されます。 |
| 2 | 編集 | 編集ボタン をクリックして、ポリシー定義を編集します。 |
| 3 | 実行 | 実行ボタン をクリックしてポリシーを手動で開始します。 または、ポリシー行をクリックし、再トレーニングトリガーを使用して実行をスケジュールすることにより、ポリシーを編集します。 |
| 4 | 削除 | 削除ボタン をクリックしてポリシーを削除します。 確認ウィンドウの削除をクリックします。 実行中のポリシーは削除できません。 |
| 5 | キャンセル | キャンセルボタン をクリックして、進行中または実行がスケジュールされているポリシーをキャンセルします。 ポリシーが正常に終了した場合、「チャレンジャーの作成」または「モデルの交換」の手順に到達した場合、失敗した場合、またはすでにキャンセルされている場合は、ポリシーをキャンセルすることはできません。 |
再トレーニング履歴の表示¶
成功または失敗にかかわらず、トレーニングポリシーの過去の実行をすべて表示できます。 各実行には、開始日時、終了日時、実行時間、および(実行が成功した場合は)結果のプロジェクトとモデルパッケージへのリンクが含まれます。
実行中のポリシー
実行中のポリシーは削除や編集ができません。最初にキャンセルする必要があります。 再トレーニングワーカーと組織に十分なワーカーがある場合、同じデプロイで複数のポリシーを同時に実行することができます。
再トレーニング戦略¶
[チャレンジャーと再トレーニング]タブでは、パフォーマンスを簡単に比較できるようにし、再トレーニング戦略を経験的に評価し、さまざまなユースケースに合わせてカスタマイズできます。 「同じブループリント」とオートパイロット戦略に対して、最初はさまざまな時間枠で実験を行うとよいでしょう。 たとえば、夜間と毎週の両方のパターンを使用して「同じブループリント」の再トレーニング戦略を実行し、結果を比較してみてください。
デプロイに自動再トレーニングポリシーを実装するための一般的な戦略は次のとおりです。
- 高頻度の自動スケジュール:現在デプロイされているブループリントを最新のデータで、頻繁に(毎日など)再トレーニングして、デプロイ済みのモデルの選択を安定させます。
- 低頻度の自動スケジュール:オートパイロットを定期的に(毎週や毎月など)実行して、代替のモデリング手法を試してみると、潜在的にパフォーマンスが最適化されます。 このプロセスをスコアリングコード対応モデルのみに限定してデプロイすることも可能です。 詳細については、スコアリングコード対応のブループリントのみを含める 高度なオプションを参照してください。
- ドリフトステータスの変化によるトリガー:データドリフトを監視し、オートパイロットをトリガーすると、状況の変化によりチャンピオンモデルがデータドリフトを示したときに代替モデルを準備します。
- 精度ステータスの変化によるトリガー:精度のドリフトを監視し、オートパイロットをトリガーして、チャンピオンモデルが精度の低下を示すと、よりパフォーマンスの高いモデルを検索します。 この戦略は、実測値にすばやくアクセスできるユースケースに最も効果的です。
可用性の再トレーニング¶
二値、多クラス、および連続値のターゲットタイプのみが再トレーニングをサポートします。 デプロイのチャンピオンが多ラベルのターゲットタイプを持っている場合、再トレーニングタブは表示されません。 時系列再トレーニングの処理も参照してください。
サポートされていないモデルとプロジェクト¶
次のDataRobotモデルおよびプロジェクトタイプでは、再トレーニングはサポートされていません。 そのような場合、デプロイのチャンピオンがリストされている機能のいずれかを使用している場合、再トレーニングタブは表示されません。
- 多ラベルモデリングプロジェクト
- 特徴量探索ベースプロジェクト
- 教師なし学習プロジェクト(異常検知とクラスターを含む)
- 非構造化カスタム推論モデル
- 多ラベルモデリングプロジェクト
- 特徴量探索ベースプロジェクト
- 教師なし学習プロジェクト(異常検知とクラスターを含む)
- 非構造化カスタム推論モデル
- モデルパッケージのインポート
部分的にサポートされているモデル¶
次のモデルタイプは、再トレーニングを部分的にサポートしています。 部分的にサポートされているモデルごとに、サポートされている(✔)オプションのみが、再トレーニングタブの再トレーニングポリシーに使用できます。
備考
一部の再トレーニングポリシーオプションのみがモデルに依存します。 以下のサポートマトリックスにモデルタイプが含まれていない場合は、再トレーニングポリシーのすべてのオプションを設定に使用できます。
| モデルタイプ | チャンピオンと同じブループリント | チャンピオンモデルの特徴量セット | チャンピオンモデルからのプロジェクトオプション | カスタムプロジェクトオプション |
|---|---|---|---|---|
| カスタム推論 | ✔ | |||
| 外部(エージェント) | ✔ | |||
| アンサンブル* | ✔ | ✔ | ||
| 時系列 | ✔ | ✔ | ✔ |
* アンサンブルモデルは、ワークベンチでは使用できません。
時系列の再トレーニング¶
時系列のデプロイでは再トレーニングをサポートしていますが、時系列の特徴量派生プロセスにより、ポリシーを設定する際に制限があります。 このプロセスは、ラグや移動平均などの特徴量を生成し、新しいモデリングデータセットを作成します。
時系列モデルの選択¶
チャンピオンと同じブループリント:再トレーニングポリシーは、チャンピオンモデルのブループリントと同じエンジニアリング済みの特徴量を使用します。 新しく派生した特徴量の検索は、チャンピオンのブループリントでキャプチャされない特徴量を生成できる可能性があるため、発生しません。
オートパイロット:同じブループリントの代わりにオートパイロットを使用する場合、時系列特徴量派生プロセスが発生します。 ただし、包括的なオートパイロットモードはサポートされていません。 また、時系列のオートパイロットは、スコアリングコードやSHAP値をサポートするブループリントおよびモデルのみを含めるオプションには対応していません。
時系列のモデリング戦略¶
チャンピオンと同じブループリント:時系列デプロイの「同じブループリント」の再トレーニングポリシーを作成するときは、チャンピオンモデルの特徴量セットと高度なモデリングオプションを使用する必要があります。 オーバーライドできる唯一のオプションは使用済みカレンダーです。これは、たとえば、新しい祝日やイベントが更新されたカレンダーに含まれている場合、再トレーニング時に考慮する必要があるためです。
オートパイロット:時系列デプロイのオートパイロット再トレーニングポリシーを作成するときは、有益な特徴量モデリング戦略を使用する必要があります。 この戦略により、オートパイロットは、新しいデータまたは異なるデータにより生成された有益な特徴量に基づく、一連の新しい特徴量セットを派生できます。 時系列オートパイロットはデフォルトで特徴量抽出および削減プロセスを使用するため、モデルの元の特徴量セットを使用することはできません。 ただし、チャンピオンのプロジェクトから追加モデリングオプションをオーバーライドできます。
| オプション | 説明 |
|---|---|
| 指数トレンドとして扱う | ターゲット特徴量に対数変換を適用します。 |
| 指数加重移動平均(EWMA) | EWMAの平滑化係数を設定します。 |
| 差異を適用 | モデリングの前に差分を適用して、ターゲットを静止させるようにDataRobotを設定します。 |
| カレンダーを追加する | 注意が必要な日付やイベントを指定するイベントファイルのアップロードまたはカタログからの追加、もしくは生成を行います。 |
時間認識の再トレーニング¶
時間認識再トレーニングでは、チャンピオンモデルからオプションを再利用する場合や、チャンピオンモデルのプロジェクトオプションをオーバーライドする場合、以下を考慮してください。
- チャンピオンのプロジェクトがホールドアウト開始日と終了日を使用する場合、再トレーニングプロジェクトはこれらの設定を使用しませんが、ホールドアウト期間(これらの2つの日付の差異)を使用します。
- チャンピオンプロジェクトでホールドアウト期間をホールドアウト開始日または終了日のどちらかと共に使用した場合、ホールドアウト開始/終了日は削除され、ホールドアウト期間が再トレーニングプロジェクトで使用されます。 新しいホールドアウト開始日が計算されます(再トレーニングデータセットの終了日からホールドアウト期間を引く)。
バックテストのカスタマイズは保持されません。ただし、バックテストの数は保持されます。 再トレーニング時間では、トレーニング開始日および終了日は、チャンピオンの開始日および終了日と異なる可能性が高くなります。 再トレーニングに使用するデータがシフトしたため、チャンピオンモデルに対する特定のバックテストからのデータがすべて含まれなくなった可能性があります。