時系列の詳細オプション¶
時系列タブでは、時系列プロジェクトをカスタマイズするために設定できるさまざまな機能を設定します。
高度なオプション設定を使用すると、DataRobotでの特徴量エンジニアリングとデータのモデリング方法を変更できます。 ほとんどのユーザーにとって、DataRobotのデフォルト設定は最適なモデリングを提供しますが、高度なオプションを使用するべき場合も存在します。 以下は、使用可能なオプションの説明ですが、製品のタイプによって異なります。
| オプション | 説明 |
|---|---|
| 複数の時系列を使用 | 複数系列モデリングの系列IDを設定または変更します。 |
| 予測で部分的な履歴を許可する | 不完全な履歴データを使用して特徴量派生ウィンドウに基づき、予測を許可します。 |
| 交差系列特徴量の生成を有効にする | 連続値プロジェクトの交差系列特徴量の派生を設定します。 |
| 特徴量を事前に既知として追加する(KA) | ラグする必要のない特徴量を追加します。 |
| 特徴量の派生からの除外 | 時間ベースの特徴量エンジニアリングを無効にする特徴量を識別します。 |
| カレンダーを追加する | 注意が必要な日付やイベントを指定するイベントファイルのアップロードまたはカタログからの追加、もしくは生成を行います。 |
| 分割をカスタマイズ | モデルのトレーニングのグループ数を指定します(ワーカーの数に基づきます)。 |
| 指数トレンドとして扱う | ターゲット特徴量に対数変換を適用します。 |
| 指数加重移動平均 | EWMAの平滑化係数を設定します。 |
| 差異を適用 | モデリングの前に差分を適用して、ターゲットを静止させるようにDataRobotを設定します。 |
| ウェイト | 行の相対的な有用性を示すために加重を設定します。 |
| 教師あり特徴量削減を使用する | DataRobotが低インパクトの特徴量を破棄することを防ぎます。 |
高度なオプションを設定した後、ページの一番上までスクロールしてモデリングを開始します。
複数の時系列を使用¶
複数系列モデリング(同じタイムスタンプが複数の行を含む場合は自動的に検出)では最初に、最初のページから系列識別子を設定します。 ただし、そのページで編集するか、高度なオプション > 時系列タブにあるこのセクションで編集することによって、モデリングの前に変更できます。

部分的な履歴を許可する¶
履歴が部分的にしかない場合では準最適な予測となる可能性があるといったように、すべてのブループリントが新しい系列で予測できるように設計されているわけではありません。 これらのブループリントには、特定の予測ポイントの特徴量を派生するために完全な履歴が必要だからです。 「コールドスタート」は、トレーニングデータには見られなかった系列をモデル化する機能です。部分履歴とは、部分的にしか知られていない系列履歴を持つ予測データセットを指します(履歴行は特徴量派生ウィンドウ内で部分的に利用可能です)。 部分的な履歴を許可を選択すると、このオプションはコールドスタートと部分的な履歴モデリングに最適化されたブループリントを実行するようにオートパイロットを指示します。部分的な履歴のサポートに対して精度が低いモデルは削除されます。

交差系列特徴量の生成を有効にする¶
複数系列のデータセットでは、時系列特徴量はデフォルトで各系列の過去の観測値に基づいて個別に派生します。 たとえば、「Sales (7 day mean)」(売上(7日間の平均))という特徴量では、データセットに含まれる各店舗の平均売上が計算されます。 この方法を使用すると、複数の系列にわたる情報がモデルで活用され、最近の市場全体の動向のインサイトをもたらすことにつながります。
データに含まれる微細な兆候を捉えるというリテールや金融市場の予測の一般的なニーズを考えると、複数の系列にわたる過去の観測値を考慮する特徴量を準備することが望ましいと思われます。 この問題に対処するために、連続値プロジェクトのすべての系列にわたる合計ターゲットの移動統計量を抽出できます。 この機能を使用する派生した特徴量の例を以下に示します。
- 「売上(total)(28 day mean)」- 28日間の期間内のすべての店舗にわたる総売上
- 「売上(total)(1st lag)」- すべての店舗にわたる総売上の最新の値
- 「売上(total)(naive 7 day seasonal value)」- 7日前の総売上
- 「売上(total)(7 day diff)(28 day mean)」- 28日の期間における7日間の差分合計売上の平均
備考
交差系列特徴量の生成は高度な機能であり、通常は、階層モデルが必要な場合にのみ使用してください。 有効にすると、予測時にエラーが発生する可能性があるため、注意が必要です。 この機能を使用することを選択した場合、すべての系列が存在し、トレーニング時と予測時の両方で開始日と終了日が同じである必要があります。
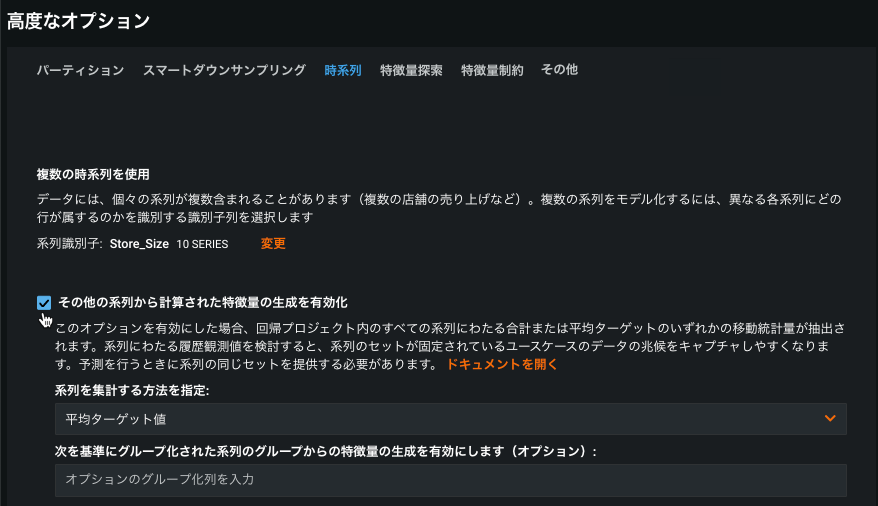
この特徴量を有効にするには、交差系列特徴量の生成を有効にします。 選択した場合:
-
集計方法を合計ターゲット値または平均ターゲット値に設定します。 モデルが構築される際、DataRobotでは、ターゲット自身に生成される差分、ラグ、および統計に加えて、
target (average) ...またはtarget (total) ...というラベルのついた特徴量が生成されます。 -
(オプション)系列IDの他に有益な列がある場合、グループ集計の基になる列を設定します。 たとえば、時間経過に伴う株価を含み、特定の株式の業界のラベル(テクノロジー、ヘルスケア、製造など)を示す列を含むデータセットを考えてみます。 オプションのグループ化列として
industryを入力すると、ターゲット値は業界に加えて、すべての系列の合計または平均で集計されます。交差系列のグループ化特徴量が選択されていないため、グループはすべての系列1つだけです。
構築される特徴量には
target(groupby-feature average)またはtarget (groupby-feature total)の形式で名前が付けられます。 「グループ化」フィールドを空白にした場合、ターゲットはすべての系列にわたって集計されます。 -
全集計を使用して複数系列にまたがる特徴量が生成されると、階層モデルは非Negativeのターゲット値を含むデータセットに対して有効化されます。 これらの2段階モデルでは、最初に複数の系列にわたって集計された合計ターゲットが最初に予測され、その後に合計の一部の予測を行って各系列に割り当てることによって最終的な予測が生成されます。 DataRobotの階層ブループリントでは、結果に調整方法が適用され、予測比率の合計が1にならない結果が修正されます。この目的で新しい階層特徴量セットが作成されます。 オートパイロットを実行すると、階層特徴量セットを使用して階層モデルだけが実行されます。 ユーザーが開始したモデル構築では、任意の特徴量セットを選択して階層モデルを実行することや、その他のモデルタイプで階層特徴量モデルを使用することができます。 しかし、これらのオプションで最良の結果が得られない場合もあるので注意が必要です。
備考
交差系列の集計が有効な場合:
- すべての系列データをトレーニングデータセットに含める必要があります。 つまり、予測時に新しい系列データを導入することはできません。
- すべてのARIMAおよび非ARIMAの交差系列モデルにジョブ定義を作成する機能は無効です。
「事前に既知」(KA)の設定¶
値が事前に既知(KA)であり、ラグ作成の必要がない特徴量は、モデル構築の前に高度なオプションから追加することで、さまざまな処理を行うことができます。 この既知の特徴量リストには、任意の元(親)の特徴量を追加できます(ユーザーが変換した特徴量や派生した特徴量をKAとして処理することはできません)。 一部の変数が事前に既知であることを示し、予測時間を指定することにより、予測精度が大幅に向上します(休日やキャンペーン中の予測精度が向上します)。
特徴量が既知としてフラグが付けられている場合、その将来の値は予測時に提供されなければなりません。 予測ウィンドウ内の予測データのKA特徴量に欠損値があると、予測精度に影響することがあります。 その場合、影響を受けるデータセットの下に注意および情報メッセージが表示されます。
一歩進んだ操作:事前に知り得る
時系列の問題では、元の特徴量に対して、使用可能な履歴からラグ特徴量の付与や移動平均などの各種ローリング統計量の作成が行われます。 しかし、一部の特徴量が事前に既知である場合、その将来値を予測時間で提供して使用することが可能です。 このような特徴量では、ラグとローリング統計量に加えて、DataRobotでは実測値としてモデリングデータが使用されます。
休日がこれを説明する良い例です。 毎年のクリスマスは12月25日ですが、先週がクリスマスだった場合もあります。 そう考えると、12月25日は休日でしょうか(0 = 真、1 = 偽)。この変数の値は、その日付においては常に真なので、既知のリアルタイム実測値を使用できます。 別の例として販売キャンペーンがあります。 翌週にキャンペーンが計画されている場合、キャンペーン変数を「事前に既知」の変数としてフラグを設定することにより、DataRobotでは以下の処理が行われます。
- 過去からの情報が使用されます(先週もキャンペーンを実施した)。
- 翌週の予測を生成するとき、キャンペーンが計画されているという情報が活用されます。
もしその特徴量が事前に既知のものとしてフラグが立てられていなければ、DataRobotはキャンペーンのスケジュール情報を無視し、予測品質に影響を与える可能性があります。
DataRobotはどの変数が事前に既知されているのかを判断できないため、予測(フォーキャスティング)のデフォルトでは、既知とマークされる特徴量はありません。 それに対して、ナウキャスティングは既知のリストにすべての特徴量をデフォルトで追加します(リストは変更できます)。
ヒント
カレンダーイベントファイルを使用するか、手動でカレンダーイベントを追加して事前に既知に設定するかを決定する際の基準については、次のセクションを参照してください。
特徴量の派生からの除外¶
DataRobotの時系列機能では、モデリングデータから新しい特徴量を派生させ、新しいモデリングデータセットを作成できます。 しかし、時間ベースの特徴量の自動作成が望ましくない場合もあります(独自の時間志向の特徴量を抽出しており、その特徴量は追加の派生処理が不要な場合など)。 そのような場合、高度なオプションリンクを使用して派生から特定の特徴量を除外できます。 標準の自動化された変換(EDA1の一部)は引き続き実行されます。
次の例外を除き、任意の特徴量を追加の派生から除外できます。
- 系列識別子
-
プライマリー日付/時刻

すぐ下の、特徴量の追加に関するセクションを参照してください。 また、派生後に特徴量セットをモデリングから除外することを検討してください。
既知の特徴量または除外された特徴量の追加と特定¶
特徴量を追加するには、次のいずれかの操作を実行します。
- ボックスに入力して文字列に一致する特徴量名を検索し、特徴量を選択して追加をクリックします。 目的の各特徴量に対して、この手順を繰り返します。
-
すべての特徴量を追加をクリックしてデータボードのすべての特徴量を追加します。
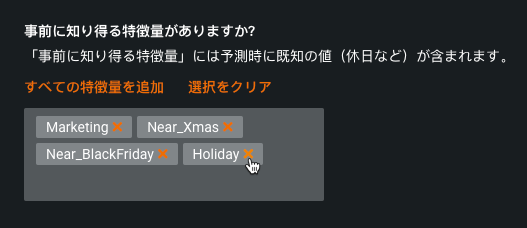
特徴量を削除するには、特徴量名の右側にあるxをクリックします。すべての特徴量をクリアするには、選択をクリアをクリックします。
-
EDA1データテーブル(開始をクリックする前のデータ)から、1つまたは複数の特徴量の左側にあるボックスを選択して、メニューからアクション > x個の特徴量をトグル(事前に既知または派生から除外)を選択します。 1つの特徴量を削除するには、該当するボックスを選択して選択を切り替えます。
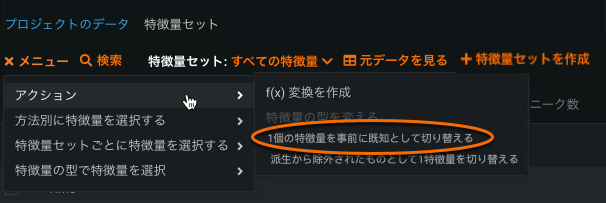
事前に既知の特徴量および派生から除外する特徴量は、個別に設定する必要があります。
事前に既知の特徴量または派生から除外された特徴量は、開始処理の前に元の特徴量セットでそのようにマークされます。
カレンダーファイル¶
カレンダーを使用すると、データセット内で注意が必要な日付またはイベントを指定できます。 カレンダーファイルには、以下に示すようなさまざまな(一意の)日付およびそのラベルがリストされます。次に例を示します。
date,holiday
2019-01-01,New Year's Day
2019-01-21,Martin Luther King, Jr. Day
2019-02-18,Washington's Birthday
2019-05-27,Memorial Day
2019-07-04,Independence Day
2019-09-02,Labor Day
.
.
.
指定した場合、DataRobotでは、カレンダーイベントに基づいて特殊な特徴量が自動的に派生されます(次のイベントまでの時間、最新のイベントへのラベル付けなど)。 時系列の精度チャートには、カレンダーイベントがタイムラインとともに視覚的に表示されるので、予測結果および実測結果のコンテキストを提供するのに役だちます。
複数系列カレンダー(アップロードされたカレンダーでのみサポート)は複数系列プロジェクトの追加機能を提供するので、系列ごとにイベントを追加できます。
ヒント
カレンダーイベントファイルを使用するか、手動でカレンダーイベントを追加してKAに設定するかを決定する際の基準については、次のセクションを参照してください。
カレンダーファイルの指定¶
データセットに関連するイベントのリストを含むカレンダーファイルを次の2つの方法のいずれかで指定できます。
-
独自のファイルを使用する(ローカルファイルをアップロードするか、AIカタログに保存されているカレンダーを使用します)。
-
国コードに基づいたプリロードされたカレンダーを生成する。
使用すると、選択方法に関係なく、すべてのカレンダーがAIカタログに保存されます。 そこから、任意のカレンダーを表示およびダウンロードできます。 完全な情報については、AIカタログを参照してください。
独自のカレンダーファイルのアップロード¶
独自のファイルをアップロードする際、データに最も適した形式(DataRobotの認識された形式とも一致する)でカレンダーイベントを定義したり、オプションとしてISO 8601形式で指定したりできます。
日付/時刻形式は、すべての行で一貫性を維持する必要があります。 以下の表は、サンプル日付と期間を示します。
| 日付 | イベント名 | イベント期間* |
|---|---|---|
| 2017-01-05T09:30:00.000 | トレーディングを開始 | P0Y0M0DT8H0M0S |
| 2017-01-08T00:00:00.003 | センサーオン | PT10H |
| 2017-12-25T00:00:00.000 | クリスマス休日 | |
| 2018-01-01T00:00:00.000 | 元旦 | P1D |
* 具体的には、ISO週間(P5Wなど)のサポートはありません。
イベント期間フィールドはオプションです。 指定されていない場合、DataRobotはアップロードされたデータに含まれる時間単位に基づいて期間を割り当てます。
| アップロードされたデータの検出された時間単位は... | デフォルトの期間が指定されていない場合は次の通りになります... |
|---|---|
| 年、四半期、月、日 | 1日(P1D) |
| 日、時、分、秒、ミリ秒 | 1ミリ秒(PT0.001S) |
詳細については、カレンダーファイル要件を参照してください。
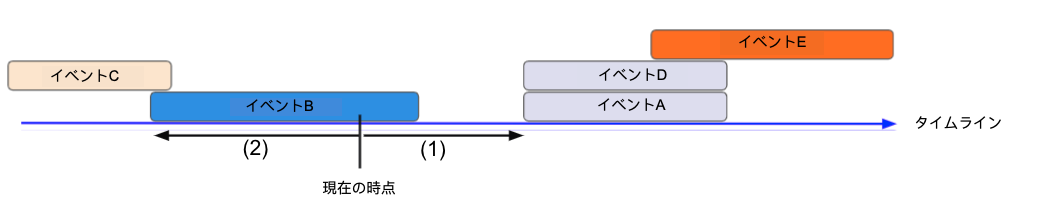
一歩進んだ操作:期間の設定
期間(to/from、next/previous)を決定する際、派生した特徴量は現在の時点を参照します。(1)は次のカレンダーイベントまでの期間、(2)は前/現在のカレンダーイベントからの期間です。
これらの特徴量は次のような情報を提供できます。
- プロモーションが終了してからどれだけの時間が経過したか
- 次の機械の休止時間はいつ予定するべきですか?
精度を確保するために、DataRobotは重複する可能性のあるカレンダーイベントに基づいてカレンダーから派生した特徴量をサポートするガードレールを提供します。 重複が発生した場合、DataRobotは最初に短い期間のイベントを考慮し、次に辞書順を判断基準とします。

以下は、DataRobotがイベント期間と辞書順を使用して、重複するイベントを処理する方法の例です。
(a)を参照する、派生した特徴量:
- (1)次のカレンダーのイベントタイプ = イベントG(期間が最も短いため)。 イベントGが存在しない場合、辞書順によりイベントDよりもイベントAが優先されます。
- (2)前のカレンダーイベントタイプ=イベントB
(b)を参照する、派生した特徴量:
- (3)次のカレンダーイベントタイプ=イベントB
- (4)前のカレンダーイベントタイプ=イベントC
を参照する、派生した特徴量:
- (5)次のカレンダーイベントタイプ=イベントE
- (6)前のカレンダーのイベントタイプ = イベントG(期間が最も短いため)。 イベントGが存在しない場合、辞書順によりイベントDよりもイベントAが優先されます。
カレンダーファイルの要件¶
独自のカレンダーファイルをアップロードするときは、次の点に注意してください。
-
日付列が必要です。
-
日付/時刻形式は、すべての行で同じである必要があります。
-
学習データにおける全体の日付、およびモデルの予測を行うすべての将来の日付の範囲を含める必要があります。
-
ローカルファイルを介して直接アップロードする場合は、ヘッダー行を含むCSVまたはXLSX形式である必要があります。 AIカタログのカレンダーファイルである場合、他のデータ要件を満たし、列に名前が付けられている限り、サポートされている任意のファイル形式のものを使用できます。
-
アクティブなプロジェクトで更新できません。 将来のすべてのカレンダーイベントはプロジェクトの開始時に特定する必要があります。そうでない場合、新しいプロジェクトをトレーニングする必要があります。
-
(オプション)イベントの名前またはタイプを示す2番目の列を含めることができます。
-
オプションで、カレンダーイベントの期間を指定する
Event Durationという列を含めることが可能です。 -
(オプション)イベントが適用される系列を指定する系列ID列を含めることができます。 この列名は系列IDとして設定された列セットの名前に一致する必要があります。
- 複数系列ID列は、さまざまな系列のさまざまなイベントのセット(さまざまな地域の休日など)を指定する機能を追加するために使用されます。
- 特定のイベントでは系列IDの値が存在しない場合があります。 これは、イベントがプロジェクトデータセットのすべての系列で有効であることを意味します(元日はすべての系列で休日であるなど)。
- 複数系列ID列が指定されていない場合、リストされたすべてのイベントはプロジェクトデータセットのすべての系列に適用されます。
カレンダーファイルの形式を要約するインフォグラフィックを表示するには、アプリ内でファイル要件の参照をクリックします。
列順序のベストプラクティス¶
- 単一系列カレンダー:日付/時刻、カレンダーイベント、イベント期間。
- 複数系列カレンダー:日付/時刻、カレンダーイベント、系列ID、イベント期間。
期間列はイベント期間という名前にする必要があります。その他の列には、命名要件がありません。
プリロードされたカレンダーファイルの使用¶
プリロードされたカレンダーを使用するには、ドロップダウンから国コードを選択します。 データセットのスパン(開始日と終了日)をカバーするカレンダーがDataRobotによって自動的に生成されます。
プリロードされたカレンダーは、複数系列プロジェクトでは使用できません。 系列ごとのイベントを含めるには、カレンダーを添付オプションを使用します。
カレンダーファイルまたはKA?¶
日付は、カレンダーイベントファイルをアップロードして処理することも、カレンダーイベントをカテゴリー型特徴量として手動で追加して、KAとして設定することによって処理することもできます。 言い換えると、次の操作を行うことができます。
- カレンダーイベントを列としてデータセットに入力し、KAとして設定する。
- イベントをカレンダーとしてインポートする。
方法を選択する際の考慮事項を以下に示します。
- カレンダーは日単位である必要があります。よりきめ細かい時間ステップが必要な場合、KAを使用する必要があります。
- DataRobotではカレンダーから追加の特徴量が生成されます(「イベントまでの日数」や「イベント後の日数」カレンダーイベントなど)。
- カレンダーイベントは将来にわたりトレーニング時に既知でなければいけません。KA特徴量は将来にわたり予測時に既知でなければいけません。
- KAの場合、予測をデプロイするときは、予測要求ごとにKA特徴量を生成する必要があります。
- マルチシリーズプロジェクトのカレンダーイベントは、特定のシリーズまたはすべてのシリーズに適用できます。
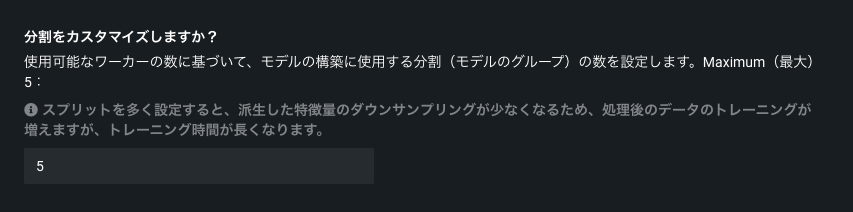
モデル分割のカスタマイズ¶
分割をカスタマイズオプションを使用して、特定のモデルが取得する分割数(トレーニング済みモデルのグループ)を設定します。 この詳細オプションは、組織で利用可能なワーカーの数に基づいて設定します。 ワーカーが少ない場合は、分割を減らして一部のワーカーを他の処理に使用できるようにすることができます。 ワーカーの数が多い場合は、高い値を設定してキュー内のジョブの数を増やすことができます。
備考
分割の最大数は、DataRobotのバージョンによって異なります。 マネージドAIプラットフォームのユーザーは、最大5つの分割を設定できます。セルフマネージドAIプラットフォームユーザーは最大10の分割を設定できます。
分割は、ダウンサンプリングされた派生した特徴量のセットでトレーニングされるモデルのグループです。 分割を多く設定すると、派生した特徴量のダウンサンプリングが少なくなるため、処理後のデータのトレーニングが増えます。 しかし、後処理データが増えるとトレーニング時間が長くなります。
指数トレンドとして扱う¶
ターゲット値が指数的に上下する場合は、指数トレンドを考慮に入れることをお勧めします。 指数トレンドの古典的な例は、人口サイズの予測に見ることができます。次世代の人口は前の世代の人口に比例します。 では、5世代にわたる人口の推移はどのようになるでしょうか?
DataRobotで指数トレンドが検出されると、対数変換がターゲット特徴量に適用されます。 指数トレンドは自動的に検出されて対数変換が適用されますが、必要に応じて設定を行うこともできます。 DataRobotで対数変換(指数トレンドとして検出された変換など)がターゲットに適用されたかどうかを確認するには、派生データ(EDA2後のデータ)をレビューします。 適用されている場合、ターゲットが関与する特徴量には(log)のサフィックスが適用されます(Sales (log) (naive 7 day value)など)。 別の出力が必要な場合は、データを再度読み込んで、指数トレンドをなしに設定します。
指数加重移動平均¶
指数加重移動平均(EWMA)は、最新のデータポイントにより大きな加重と重要性を与え、時間の経過に伴うトレンドの方向を測定する移動平均です。 「指数関数的」な側面は、以前の入力の加重係数が指数関数的に減少することを示します。 そうしないと、非常に新しい値が古い値よりも分散に影響を与えなくなるため、これは重要です。
連続値プロジェクトでは、0~1の間の値を指定すると、平滑化係数(ラムダ)として適用されます。 各値は乗数によって加重されます。加重は、前のタイムステップの加重の定数乗数です。

この値を設定すると、DataRobotは以下を作成します。
ewmaを特徴量名に追加することによって識別される新しい派生した特徴量。- 追加特徴量セット:差分あり(EWMAベースライン)。
差異を適用¶
DataRobotでは、プロジェクトのターゲット値が定常的(静的)であるかどうかが自動的に検出されます。 したがって、ターゲットの統計的プロパティが時間の経過で一定(定常)であるかどうかが検出されます。 ターゲットが定常的でない場合、DataRobotはモデリングの前に差分ストラテジーが適用されてターゲットを定常的にしようとします。 この処理により、基礎となるモデルの精度と頑健性が向上します。
差分設定を強制する場合は、次のいずれかを選択します。
| 設定 | 説明 |
|---|---|
| 自動検出(デフォルト) | DataRobotでデータが定常的でないことが検出された場合、差分が適用されます。 データに基づいて、周期性が検出された場合、シンプルな差分または季節的な差分が適用されます。 |
| シンプル | 特徴量の派生ウィンドウ内の最も最近の使用可能な値からのデルタに基づいて差分が設定されます。 |
| 季節的 | 最新の使用可能な値からのデルタではなく、指定した時間ステップを使用して差分が設定されます。 時間ステップの増分は、データで検出された時間単位に基づきます。 |
| いいえ | このプロジェクトでの差分を無効化します。 |
加重の適用¶
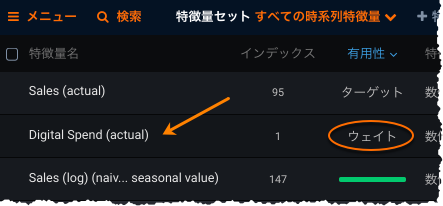
一部の時系列プロジェクトでは、行の加重を定義する機能は、モデルの精度において非常に重要です。 時系列プロジェクトに加重を適用するには、高度なオプションの追加タブを使用します。
設定した加重は、派生した特徴量の作成の一部として含まれます(該当する場合)。 加重が設定された特徴量には(actual)が適用され、有用性列に選択内容が示されます。
実際の行加重は、モデルトレーニング中に発生します。 時間経過に伴って低下する加重のブループリントがある場合、設定した加重で乗算され、最終的なモデリング加重が生成されます。
以下の派生した時系列特徴量では、加重が考慮に入れられます(該当する場合)。
- 移動平均
- 移動標準偏差
以下の時系列特徴量では、加重が無視されて通常通りに派生されます。
- 移動最小値
- 移動最大値
- 移動中央値
- 移動ラグ
- ナイーブ予測
教師あり特徴量削減を使用する¶
デフォルトで有効になっている教師あり特徴量削減は、モデリングの前に低影響の特徴量を除外します。 特定の特徴量が削除される場合、結果として最適化された特徴量セットはより良いランタイムを同様の精度で提供します。 インパクトのある特徴量のみに焦点があるため、モデルの解釈性も改善されています。 無効にすると、特徴量生成プロセスは多くの特徴量を発生させる結果となります。モデル構築時間もより長くなります。 特徴量の削減時に破棄された特徴量の復元に関するセクションも参照してください。