時系列特徴量セット¶
データの特性(定常性と予測)に基づいて時系列特徴量が自動的に構築されます。 複数の周期性があると、特徴量の作成時にいくつかの可能性が生じます。たとえば、「売上(7日間の差分)(第1ラグ)」と「売上(24時間の差分)(第1ラグ)」はどちらも意味があります。 場合によっては、差分によるターゲットの変換を実行しない方が望ましいことがあります。 最適な精度を生み出すオプションはデータに依存することがあります。
時系列特徴量が構築されると、複数の特徴量セットが作成されます(ターゲットはそれぞれに自動的に含まれる)。 プロジェクトの開始時に、複数の特徴量セットを使用してブループリントが自動的に実行され、モデルタイプに最も適したセットが選択されます。 一方、非時系列プロジェクトの場合、ブループリントは単一の特徴量セット(一般的に有用な特徴量)で実行します。
時系列特徴量セットは、データ > 派生したモデリングデータページなどから表示できます。
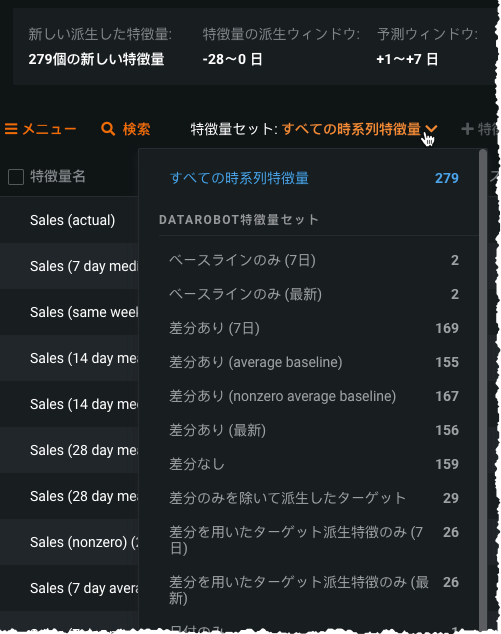
これらのセットは、非時系列プロジェクトによって作成されたセットとは異なり、ターゲットがより絞られています。
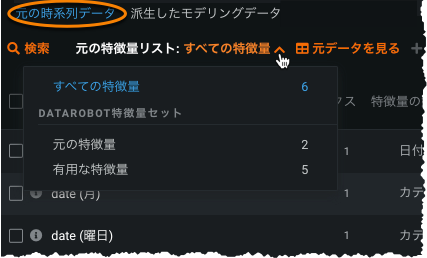
特徴量セットからの特徴量の除外¶
その他の特徴量が依存するので、派生から特徴量を除外できないことがあります。 そのような特徴量は、特徴量セットから除外することができます。 この場合、該当する特徴量は最初の特徴量の派生で使用されますが、モデリングからは除外されます。
特徴量セットから特定の特殊な特徴量を除外した場合に生じる以下のような動作に注意してください。
-
ターゲット列:ターゲットから派生した特徴量は派生しません。
-
プライマリ日付/時刻列:カレンダー特徴量と期間特徴量は派生しません。 また、日付 / 時刻列のない特徴量セットはモデリングには使用できません。
注意
単調なモデリングで使用するプライマリー日付 / 時刻特徴量を除外したセットを作成することもできます。
-
系列ID列:系列ごと、系列レベルの効果、または階層モデルを始めとする系列IDに依存するモデルは生成されません。
MASEおよびベースラインモデル¶
ベースラインモデルは、最長の周期性に一致する最新の値を使用するモデルです。 プロジェクトには異なる周期性のある複数のナイーブ予測がある場合がありますが、DataRobotは最長のナイーブ予測を使用してMASEスコアを計算します。 MASEは予測の精度の指標で、ナイーブベースラインモデルに対する1つのモデルの比較(ベースラインモデルに対するモデルのMAEのシンプルな比率)です。
リーダーボードでは、DataRobotはBASELINEインジケーターを使用して、ベースラインモデルとして使用されているモデルを識別します。
リーダーボードにベースラインモデルがない場合
デフォルトでベースラインモデルを生成するには、包括的なオートパイロットモードを使用します。 クイックオートパイロットモードで実行した場合 、リーダーボードにベースラインモデルは表示されません。ただし、DataRobotはバックグラウンドでベースラインモデルのブループリントを生成します。 リポジトリからベースラインモデルを構築するには、Baseline Predictions Using Most Recent Valueを検索し、最長の季節性を有するBaseline Only特徴量セットでトレーニングします。

自動作成された特徴量セット¶
特徴量セットドロップダウンから使用できる時系列モデリングに対して自動的に作成される特徴量セットを次の表に示します。
| 特徴量セット | 説明 |
|---|---|
| すべての時系列特徴量 | これは特徴量セットではなく、すべての派生した特徴量すべてを表示するドロップダウン設定です。 |
| ベースラインのみ(<period>) | 期間に一致するナイーブ予測列。ベースライン予測ブループリントに使用します。 |
| 日付のみ | 日付型のすべての特徴量。日付のみに依存するトレンドモデルに使用します。 |
| 差分なし |
|
| 差分のみで派生したターゲット |
|
| 差分なしで派生したターゲット(<period>) |
|
| 時系列で抽出された特徴量 | All Time Series Featuresの特徴量セットバージョン。すべての派生した特徴量。 |
| 時系列で有用な特徴量* | 有用と思われる全ての時系列特徴量(すべての差分期間に基づく特徴量を含む)。 |
| 時系列の再トレーニング特徴量 | 再トレーニングされたモデルが可能な限り元のモデルに近いことを確保するために、元のモデルによって使用される特徴量セットのコピーです。 |
| 有用性上位の選抜 | 選択したターゲットとの非線形相関の特定のしきい値を満たす特徴量。非時系列プロジェクトと同じです。 |
| 差分の適用(<period>) |
|
| 差分あり(平均値ベースライン) |
|
| 差分あり(EWMAベースライン) |
|
| 差分あり(月内の季節性の検出) | 検出された季節性を活用する複数の特徴量セットオプション(以下を参照)。 |
| 差分の適用(非ゼロ平均ベースライン) |
|
* 時系列の有用な特徴量セットは最適ではありません。 「差分あり」または「差分なし」の特徴量セットを選択することが推奨されます。
教師なし時系列プロジェクトの特徴量セット¶
次の表は、教師なしモデル(異常検知)を使用する時系列プロジェクト用に自動的に作成される特徴量セットを示します。 ポイント異常および異常ウィンドウ検知のためにこれらのリストを管理する方法の詳細については、参照セクションを参照してください。
| 特徴量セット | 説明 |
|---|---|
| 時系列で抽出された特徴量 | All Time Series Featuresの特徴量セットバージョン。すべての派生した特徴量。 |
| 時系列で有用な特徴量 | 時系列の異常検知で有益と見なされるすべての時系列特徴量。 たとえば、低情報または冗長(重複列や空の値を含む列など)であると判断された特徴量は除外されます。 |
| 実測値と移動統計量 | データセットの実測値、および対応する特徴量の派生ウィンドウの派生統計情報(平均値、中央値など)。 これらの特徴量は時系列異常検知から選択され、ポイント異常と異常ウィンドウの両方に適用されます。 |
| 堅牢なZスコアのみ | 時系列で派生した特徴量から選択され、派生した堅牢なzスコア値だけが含まれるローリング統計。 これらの特徴量はポイント異常の評価に役立ちます。 |
| SHAPベースの削減済み特徴量 | Isolation Forest SHAP値スコアに基づく特徴量のサブセット。 |
| 実測値のみ | データセットから選択された実測値。 これらの特徴量はポイント異常の評価に役立ちます。 |
| ローリング統計のみ | 時系列で派生した特徴量から選択されたローリング統計。 これらの特徴量は、異常ウィンドウの評価に役立ちます。 |
リポジトリブループリントの特徴量セット¶
リポジトリからモデルを構築するとき、実行する特定の特徴量セット—(デフォルトリストまたはユーザーが作成したリスト)を選択できます。 しかし、いくつかのブループリントでは、特徴量セットに特定の特徴量が存在する必要があるので、これらの特徴量なしで特徴量セットを使用するとモデル構築が失敗することがあります。 これは、モデルタイプから独立して特徴量セットを作成した場合などに発生します。 この種の失敗を防止するために、DataRobotでは、モデル構築を開始する前に特徴量セットおよびブループリントの互換性がチェックされ、適切な場合はエラーメッセージが返されます。
また、DataRobotではいくつかのブループリントの優先特徴量セットの種類を識別できるので、そのリストがデフォルトで推奨されます。 該当するブループリントのリストについては、時系列に関する注意事項を参照してください。
ゼロ過剰モデル¶
プロジェクトターゲットがPositiveで、少なくとも1つのゼロ値が含まれる場合、DataRobotでは常に非ゼロ平均値ベースラインの特徴量セットが作成されます。この特徴量セットは、最適化されたゼロ過剰モデルの構築に使用されてデータが反映されます。 これらのモデルでは、特化されたアルゴリズムによってゼロがモデル化され、分布が個別にカウントされるので精度が向上します。
差分ありの非ゼロ平均値ベースラインの特徴量セットでは、ターゲット名に(nonzero)または(is zero)が追加されます。 以下に具体例を示します。
- (nonzero)の場合:ゼロターゲット値を欠損値のインスタンスとして処理することによって特徴量が派生します。
- (is zero)の場合:ターゲット値をブーリアン型フラグ(ターゲットがゼロ または ゼロでない)で置換することによって特徴量が派生します。
変換されたターゲット値(「<target>(nonzero)」および「<target>(is zero)」)はモデリングでは使用されません。 モデリング中のターゲットリーケージを回避するために、DataRobotでは、派生した変換済みターゲット値(ラグと統計量)だけが使用されます。 さらに、「差分あり(非ゼロ平均値ベースライン)」特徴量セットは、ゼロ過剰モデルブループリントに対してのみ使用されます。この特徴量セットの名前には、「Zero-Inflated」という接頭辞が追加されます(Zero-Inflated eXtreme Gradient Boosted Trees Regressorなど)。 必ずしもすべてのモデルタイプにゼロ過剰のカウンターパートがあるわけではありません。
ゼロ過剰モデリングに関する注意事項¶
ゼロ過剰モデルおよび特徴量セットで作業する場合、以下の点に注意してください。
-
ゼロ過剰特徴量セットを使用して、非ゼロ過剰モデルをトレーニングして(最適でないにしても)正常なパフォーマンスを期待することができます。
-
別の特徴量セットを使用してゼロ過剰モデルをトレーニングした場合、モデルでは対数スケールでターゲットの派生した特徴量が予期されるので、モデルのパフォーマンスが低下することがあります。
月内の季節性の検出¶
月内の季節性は、毎月、同じ日/週番号または曜日/週番号で繰り返す定期変動です。 季節性のパターンを検出することは、正確なモデルを作成するために重要です(前月の必要なデータをどのように定義するか、月の最初からカウントするか、最後からカウントするか)。
次にいくつかの例を示します。
| 繰り返されるパターン | 時間単位 | 例 |
|---|---|---|
| 月の同じ日 | Day | 月の特定の日が期日の支払い(毎月15日)。 |
| 月の同じ週と曜日 | Day | 月の特定の日の給料日(第2金曜日)。 |
| 月の週 | 週 | 各月の最終週の小売りデータセットでの好調な売上—「各月の販売割当は最終日に計算」 |
季節性の処理を向上させるために、DataRobotでは適切な特徴量セットの検出および生成が行われ、特徴量が取得されます。 これらの追加は、モデリングデータセットを作成する特徴量エンジニアリングを実行するときにDataRobotで月内の季節性が検出されるかどうか、および特徴量の派生ウィンドウが特定のしきい値よりも大きいかどうかに基づきます。 次の表に示すように、オートパイロットで実行される特徴量セットはデータの特性に基づきます。
備考
「FDW covers at least X days」(FDWが少なくともX日をカバー)はfdw_end - fdw_start >= Xと表されます。
| 条件 | 説明 | 例 |
|---|---|---|
| 差分あり(毎月) | ||
| 検出された月内の季節性および特徴量の派生ウィンドウが少なくとも31日間をカバー |
|
前月のターゲット値の最初のN日目を今月の最初のN日目の予測として使用します(3月5日では2月5日のターゲット値が使用されます)。 3月30日の場合、2月28日(2月末日)の値が使用されます。 |
| 差分あり(毎月、同じ日から末日まで) | ||
| 検出された月内の季節性および最小の特徴量の派生ウィンドウが少なくとも31日間をカバー |
|
|
| 差分あり(毎月、同じ曜日、月初からの同じ週) | ||
| 検出された月内の季節性、FDW start ≥ 35、FDW end ≤ 21、FDWウィンドウは少なくとも29日間をカバー |
|
最後の月の最初のX日X日のターゲットを今月の最初のX日の予測として使用します(3月5日月曜日の場合、2月1日~7日の期間の月曜日のターゲット値が使用されます)。 |
| 差分あり(毎月、同じ曜日、月末からの同じ週) | ||
| 検出された月内の季節性、FDW start ≥ 35、FDW end ≤ 21、FDWウィンドウは少なくとも29日間をカバー |
|
最後の月の最後のX日のターゲットを今月の最後のX日の予測として使用します(3月31日火曜日の場合、2月22日~28日の期間の火曜日のターゲット値が使用されます)。 |
| 差分あり(毎月、前月の平均) | ||
| 検出された月内の季節性、FDW start ≥ 62、FDW end ≤ 21、FDWウィンドウは少なくとも29日間をカバー |
|
前月の平均ターゲット値を翌月のナイーブ予測として使用します(6月7日の場合、5月1日~30日、または2月の平均ターゲット値が3月のナイーブ予測として使用されます)。 (より長いFDWが必要です。) |
| 差分あり(毎月、前月の同じ週の平均) | ||
| 検出された月内の季節性、FDW start ≥ 37、FDW end ≤ 21、FDWウィンドウは少なくとも29日間をカバー |
|
最後の月の最初の週の平均を今月の最初の週の予測として使用します(--see詳細については、以下を参照してください)。 |
| 差分あり(毎月、前月の非ゼロ値の平均) | ||
| 検出された月内の季節性、FDW start ≥ 62、FDW end ≤ 21、FDWウィンドウは0の最小ターゲット値で少なくとも29日間をカバー |
|
2月の平均非ゼロターゲット値を3月のナイーブ予測として使用します。 |
| 差分あり(月の前週の非ゼロ値の平均ベースライン) | ||
| 検出された月内の季節性、最小FDW start ≥ 37、最大FDW end ≤ 21、FDWウィンドウは0の最小ターゲット値で少なくとも29日間をカバー |
|
前月の毎週の非ゼロ平均を使用します(--see詳細については、以下を参照してください)。 |
毎月、前月の月初からの同じ週の平均¶
3月のナイーブ予測の計算を以下に示します。
-
月初からの毎週の平均を計算します。
- 3月1日~7日は2月1日~7日の平均値を使用し、3月22日~31日(月末)は2月22日~28日の平均値を使用します。この特徴量に次の名前が付けられます
y (last month weekly average)。
- 3月1日~7日は2月1日~7日の平均値を使用し、3月22日~31日(月末)は2月22日~28日の平均値を使用します。この特徴量に次の名前が付けられます
-
月末からの毎週の平均を計算します。
- 3月25日~31日は2月22日~28日の平均値を使用し、3月1日~10日は2月1日~7日の平均値を使用します。この特徴量に次の名前が付けられます
y (match end of the month) (last month weekly average)。
- 3月25日~31日は2月22日~28日の平均値を使用し、3月1日~10日は2月1日~7日の平均値を使用します。この特徴量に次の名前が付けられます
-
上記の2つの特徴量の平均を計算して、現在の月のナイーブ予測を計算します。
- 0.5 *
y (last month weekly average)+ 0.5 *y (match end of the month) (last month weekly average)
- 0.5 *
毎月、月初からの同じ週の平均非ゼロ値¶
非ゼロ値の3月のナイーブ予測の計算を以下に示します。
-
月初からの毎週の非ゼロ平均を計算します。
- 3月1日~7日は2月1日~7日の非ゼロ平均値を使用し、3月22日~31日(月末)は2月22日~28日の非ゼロ平均値を使用します。この特徴量に次の名前が付けられます
y (nonzero)(last month weekly average)。
- 3月1日~7日は2月1日~7日の非ゼロ平均値を使用し、3月22日~31日(月末)は2月22日~28日の非ゼロ平均値を使用します。この特徴量に次の名前が付けられます
-
月末からの毎週の非ゼロ平均を計算します。
- 3月25日~31日は2月22日~28日の非ゼロ平均値を使用し、3月1日~10日は2月1日~7日の非ゼロ平均値を使用します。この特徴量に次の名前が付けられます
y (nonzero)(match end of the month) (last month weekly average)。
- 3月25日~31日は2月22日~28日の非ゼロ平均値を使用し、3月1日~10日は2月1日~7日の非ゼロ平均値を使用します。この特徴量に次の名前が付けられます
-
上記の2つの特徴量の平均を計算して、現在の月のナイーブ予測を計算します。
- 0.5 *
y (nonzero)(last month weekly average)+ 0.5 *y (nonzero)(match end of the month) (last month weekly average)
- 0.5 *