バイアスと公平性のリファレンス¶
このセクションでは、機能全体で共通に使用される用語を定義しています。
保護された特徴量¶
モデル予測の公平性を測定するデータセット列。 つまり、モデルの公平性は、データセットの保護された特徴量に対して計算されます。 「保護された属性」とも呼ばれます。
例:age_group、gender、race、religion
保護された特徴量として指定できるのは、カテゴリー型の特徴量のみです。 保護された特徴量の各カテゴリー値は、その特徴量の保護されたクラスまたは単にクラスと呼ばれます。
保護されたクラス¶
保護された特徴量の1つのカテゴリー値。
例:maleは特徴量genderの保護されたクラス(または単にクラス)である場合があります。
また、asianは特徴量raceの保護されたクラスである場合があります。
好ましい結果¶
モデルにとって好ましい結果として扱われるターゲットの値。 二値分類モデルによる予測は、保護されたクラスにとって好ましい結果(良い/望ましい)であるか、好ましくない結果(悪い/望ましくない)であるかに分類することができます。
例:ローン承認における男女差別をチェックする際、ターゲットis_badはローンが貸し倒れになるかどうかを示すとします。
この場合、予測の好ましい結果はNo(ローンは「正常債権」という意味)なので、Noの値は貸し手にとって好ましい(良い)結果です。
ターゲットの好ましい結果は、割り当てられた正のクラスと常に同じであるとは限りません。 たとえば、一般的な融資のユースケースでは、申請者がローンを返済できなくなる可能性があるかどうかを予測します。 正のクラスは1(「貸し倒れになる」)ですが、ターゲットの好ましい結果は0(「貸し倒れにならない」)です。 ターゲットの好ましい結果とは、保護された個々のクラスにおいて望ましい結果を指します。
公平性スコア¶
保護されたクラスに対するモデルの公平性を、根拠となる公平性指標に基づいて数値計算したもの。
備考:モデルが異なる公平性指標を使用している場合や、異なる予測データで公平性スコアを計算した場合、モデルの公平性スコアは比較できません。
公平性のしきい値¶
公平性のしきい値は、モデルが各保護クラスに対して適切な公平性の範囲内で動作しているかどうかを測定するのに役立ち、どの保護クラスの公平性スコアやパフォーマンスにも影響を与えません。 指定しない場合、しきい値のデフォルトは0.8です。
公平性の値¶
最も好ましい保護クラス(つまり、公平性のスコアが最も高いクラス)に対して正規化された公平性スコア。
公平性の値は常に[0.0, 1.0]の範囲であり、1.0は最も好ましい保護クラスに割り当てられます。
保護された特徴量の特定のクラスについて計算された公平性の値の信頼性を確保するために、ツールは、高い信頼度で公平性の値を計算するのに十分なデータがサンプルにあったかどうかを判断します(Zスコアを参照)。
Zスコア¶
保護された特徴量の特定のクラスが、母集団全体で「統計的に有意」であるかどうかを測定する指標。
例:maleが10,000行あるのに対し、femaleが100行しかないデータセットにおいて、genderに対する公平性を測定するために、femaleクラスにはデータが不十分であるというラベル付けが特徴量で行われます。
この場合、データセットの別のサンプルを使用し、このサンプルに対する公平性指標の信頼性を確保します。
公平性指標¶
公平性指標は、公平性を評価するために使用される平等性制約の統計的尺度です。
各公平性指標の結果は、次の2つの手順で計算されます。
- モデルの保護された特徴量の保護されたクラスごとに公平性スコアを計算する
- 保護された特徴量で最も高い公平性スコアに対して、公平性スコアを正規化する
誤差ごとの公平性を測定する指標では、モデルの誤差率がすべての保護クラスで同等であるかどうかを評価します。 これらの指標は、結果をコントロールできない場合や、グラウンドトゥルースに準拠したい場合、そして単にモデルを各保護グループ間で同等に正しくしたい場合に最適です。
表現ごとの公平性を測定する指標では、モデルの予測がすべての保護クラスで同等であるかどうかを評価します。 これらの指標は、トレーニングデータのターゲット分布に関係なく、モデルの予測が保護されたグループ間でより同等な表現になるように、ターゲット結果をコントロールできる場合、またはグラウンドトゥルースから逸脱することをいとわない場合に最適です。
このセクションでは、特定の公平性指標を適用するための理想的なコンテキスト/ユースケースを理解するのに役立つように、架空の例を用いて各公平性指標について説明します。 これらの例は人材採用のユースケースに基づいており、公平性指標は、ターゲットであるHired(YesまたはNo)を予測するモデルを評価します。
注:この架空の例はDataRobotの見解を反映するものではなく、説明のみを目的としています。
表記¶
d:モデルの意思決定(つまり、YesまたはNo)PF:保護された特徴量s:予測確率スコアY:ターゲット特徴量
個別の公平性指標は全部で8つあります。 一部の指標は、関連する公平性指標と組み合わせて使用するのが最適です。 該当する場合は、以下の説明に記載されています。
比例平等性¶
各保護クラスでは、モデルから好ましい予測を受け取る確率はどれくらいでしょうか? この指標は、保護されたクラス間でモデルのターゲットを同等に表すことを前提としています。 「統計的均一性」、「デモグラフィックパリティ」、「受容率」とも呼ばれ、二値分類モデルの公平性のスコアリングに使用されます。 比例平等性の一般的な使い方としては、人材採用における「従業員選考手順に関する統一ガイドライン」の「5分の4」ルールがあります。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 意思決定が予測されたターゲット(値が
YesまたはNoであるHired)
計算式:
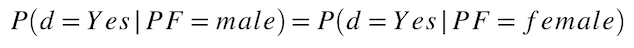
例:
ある会社に100名の応募者がいます。その内訳は次のとおりです。
- 男性の応募者は
70名 - 女性の応募者は
30名 - 男性
60名、女性5名を採用予定
採用される確率(「保護クラスごとの採用率」)を計算します。 手動で計算された公平性スコアは次のとおりです。
male hiring rate = (number of males hired) / (number of males) = 60/70 = 0.857 = 85.7%
female hiring rate = (number of females hired) / (number of females) = 5/30 = 0.167 = 16.7%
女性に対する格差の影響(公平性の値)を、次のように計算します。
disparate impact = (female hiring rate) / (male hiring rate) = 0.167/0.857 = 0.195 = 19.5%
この相対的な公平性スコア(19.5%)を、公平性のしきい値0.8(つまり、4/5 = 0.8 = 80%)と比較します。
結果(19.5% < 80%)は、このモデルが5分の4ルールを満たしていないため、採用において女性を不当に扱っていることになります。
ユースケースの例:
米国における人事規制の「5分の4ルール」によると、求職者を選考する場合、選考率は、保護されたクラス間でしきい値0.8以内で平等でなければなりません(比例平等性)。男性の80%に面接しても、女性の40%にしか面接しなければ、この法律に違反することになります。 こうしたバイアスを是正するためには、少なくとも64%の女性に面接する必要があります(男性の選考率80% * 公平性のしきい値)。
等価平等性¶
各保護クラスでは、モデルから好ましい予測を得たレコードの総数はどれくらいでしょうか? この指標は、保護されたクラス間でモデルのターゲットを同等に表すことを前提としています。 二値分類モデルでは、公平性のスコアリングに使用されます。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 意思決定が予測されたターゲット(値が
YesまたはNoであるHired)
計算式:
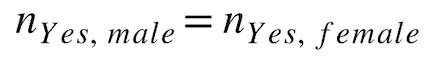
例:
先ほどの例で言うと、男女別に予測された採用者数の公平性スコアは次のとおりです。
males hired = 60
females hired = 5
ユースケースの例:
ヨーロッパでは、企業の役員が男女同数でなければならない国もあります。
予測バランス¶
予測バランスという公平性指標のセットには、以下で説明するように、好ましいクラスのバランスと好ましくないクラスのバランスが含まれています。
好ましいクラスのバランス¶
好ましい結果となった全実測値について、各保護クラスでの平均予測確率はどれくらいでしょうか? この指標は、各保護クラスでモデルの元のスコアの平均を同等に表すことを前提としており、予測バランスという公平性指標セットの一部です。 好ましいクラスのバランスの一般的な使い方として、モデルの元のスコアで採用候補者をランク付けし、よりスコアの高い候補者を選考します。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 予測確率スコアを持つターゲット(値の範囲が
[0.0, 1.0]であるHired) - 実際の結果を持つターゲット(値が
YesまたはNoであるHired_actual)
計算式:
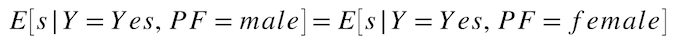
例:
ある会社に100名の応募者がいます。その内訳は次のとおりです。
- 男性の応募者は
70名 - 女性の応募者は
30名 - 実際に採用されたのは男性
50名、女性20名 - 男性の予測確率スコアの範囲:
[0.7, 0.9] - 女性の予測確率スコアの範囲:
[0.2, 0.4]
モデルの予測確率スコアに基づいて、保護された各クラスの平均を次のように計算します。
hired males average score = sum(hired male predicted probability scores) / 50 = 0.838
hired females average score = sum(hired female predicted probability scores) / 20 = 0.35
ユースケースの例:
採用の場面では、採用担当者の審査を通過する確率で候補者をランク付けし、モデルが採用すべきと予測した候補者であっても、モデルの元のスコアを利用して、スコアの低い候補者を除外することが可能です。
好ましくないクラスのバランス¶
好ましくない結果となった全実測値について、各保護クラスでの平均予測確率はどれくらいでしょうか? この指標は、各保護クラスでモデルの元のスコアの平均を同等に表すことを前提としており、予測バランスという公平性指標セットの一部です。 好ましくないクラスのバランスの一般的な使い方として、モデルの元のスコアで採用候補者をランク付けし、スコアの低い候補者を除外します。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 予測確率スコアを持つターゲット(値の範囲が
[0.0, 1.0]であるHired) - 実際の結果を持つターゲット(値が
YesまたはNoであるHired_actual)
計算式:
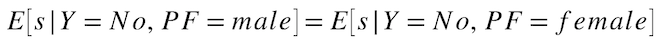
例:
ある会社に100名の応募者がいます。その内訳は次のとおりです。
- 男性の応募者は
70名 - 女性の応募者は
30名 - 実際に不採用となったのは男性
20名、女性10名 - 男性の予測確率スコアの範囲:
[0.7, 0.9] - 女性の予測確率スコアの範囲:
[0.2, 0.4]
モデルの予測確率スコアに基づいて、保護された各クラスの平均を次のように計算します。
non-hired males average score = sum(non-hired male predicted probability scores) / 20 = 0.70
non-hired females average score = sum(non-hired female predicted probability scores) / 10 = 0.20
好ましいクラスの再現率の平等性¶
各保護クラスでは、好ましい結果をもたらす全実測値に対して、モデルが好ましい結果を予測する確率はどれくらいでしょうか? この指標(「真陽性率の平等性」とも呼ばれます)は、誤差の均一性に基づいており、好ましいクラスの再現率と好ましくないクラスの再現率の平等性という公平性指標セットの一部です。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 意思決定が予測されたターゲット(値が
YesまたはNoであるHired) - 実際の結果を持つターゲット(値が
YesまたはNoであるHired_actual)
計算式:
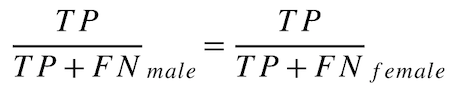
例:
ある会社に100名の応募者がいます。その内訳は次のとおりです。
- 男性の応募者は
70名 - 女性の応募者は
30名 50名の男性が採用されると正しく予測された10名の男性が 採用されない と誤って予測された8名の女性が採用されると正しく予測された12名の女性が 採用されない と誤って予測された
保護された各クラスでの好ましいクラスの再現率を、次のように計算します。
male favorable rate = TP / (TP + FN) = 50 / (50 + 10) = 0.8333
female favorable rate = TP / (TP + FN) = 8 / (8 + 12) = 0.4
ユースケースの例:
ヘルスケアの分野では、モデルを使用して、患者にどの薬を投与すべきかを予測することができます。 すべての患者が同じ投薬治療を確実に受けられるようにするには、どの保護クラスにおいても、間違った薬を投与することは避けるべきです。各保護クラスに適切な薬を投与し、どのグループに対しても極端に多くのミスをしないモデルが必要です。
好ましくないクラスの再現率の平等性¶
各保護クラスでは、好ましくない結果をもたらす全実測値に対して、モデルが好ましくない結果を予測する確率はどれくらいでしょうか?
この指標(「真陰性率の平等性」とも呼ばれます)は、誤差の均一性に基づいており、好ましいクラスの再現率と好ましくないクラスの再現率の平等性という公平性指標セットの一部です。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 意思決定が予測されたターゲット(値が
YesまたはNoであるHired) - 実際の結果を持つターゲット(値が
YesまたはNoであるHired_actual)
計算式:
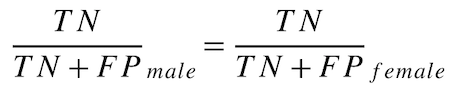
例:
ある会社に100名の応募者がいます。その内訳は次のとおりです。
- 男性の応募者は
70名 - 女性の応募者は
30名 5名の男性が 採用されない と正しく予測された5名の男性が採用されると誤って予測された8名の女性が 採用されない と正しく予測された2名の女性が採用されると誤って予測された
保護された各クラスでの好ましくないクラスの再現率を、次のように計算します。
male unfavorable rate = TN / (TN + FP) = 5 / (5 + 5) = 0.5
female unfavorable rate = TN / (TN + FP) = 8 / (8 + 2) = 0.8
好ましいクラスの適合率の平等性¶
モデルが正しい(実際の結果が好ましい)確率はどれくらいでしょうか? この指標(「陽性的中率の平等性」とも呼ばれます)は、誤差の均一性に基づいており、好ましいクラスの適合率と好ましくないクラスの適合率の平等性という公平性指標セットの一部です。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 意思決定が予測されたターゲット(値が
YesまたはNoであるHired) - 実際の結果を持つターゲット(値が
YesまたはNoであるHired_actual)
計算式:
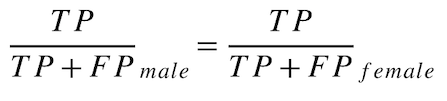
例:
ある会社に100名の応募者がいます。その内訳は次のとおりです。
- 男性の応募者は
70名 - 女性の応募者は
30名 50名の男性が採用されると正しく予測された5名の男性が採用されると誤って予測された8名の女性が採用されると正しく予測された2名の女性が採用されると誤って予測された
保護された各クラスでの好ましいクラスの適合率の平等性を、次のように計算します。
male favorable predictive value = TP / (TP + FP) = 50 / (50 + 5) = 0.9091
female favorable predictive value = TP / (TP + FP) = 8 / (8 + 2) = 0.8
ユースケースの例:
男性は女性よりもかなり無謀な運転をしていると考えられているため、保険会社は、女性よりも男性に多く請求することが倫理上正しいと考えています。 この場合、女性とは金額が違っても、男性には実際のリスクに見合った保険料を請求するようなモデルが必要です。
好ましくないクラスの適合率の平等性¶
モデルが正しい(実際の結果が好ましくない)確率はどれくらいでしょうか?
この指標(「陰性的中率の平等性」とも呼ばれます)は、誤差の均一性に基づいており、好ましいクラスの適合率と好ましくないクラスの適合率の平等性という公平性指標セットの一部です。
必要なデータ:
- 保護された特徴量(値が
maleまたはfemaleであるgender) - 意思決定が予測されたターゲット(値が
YesまたはNoであるHired) - 実際の結果を持つターゲット(値が
YesまたはNoであるHired_actual)
計算式:
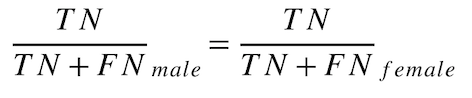
例:
ある会社に100名の応募者がいます。その内訳は次のとおりです。
- 男性の応募者は
70名 - 女性の応募者は
30名 5名の男性が 採用されない と正しく予測された10名の男性が 採用されない と誤って予測された8名の女性が 採用されない と正しく予測された12名の女性が 採用されない と誤って予測された
保護された各クラスでの好ましくないクラスの適合率の平等性を、次のように計算します。
male unfavorable predictive value = TN / (TN + FN) = 5 / (5 + 10) = 0.333
female unfavorable predictive value = TN / (TN + FN) = 8 / (8 + 12) = 0.4