スライスされたインサイト¶
スライスされたインサイトは、特徴量値(元の値または派生値)に基づいてモデルのデータの部分母集団を表示するオプションを提供します。 スライスは、事実上、カテゴリー、数値、または両方のタイプの特徴量のフィルターです。 スライスは、インサイトに応じて、トレーニング、検定、交差検定、またはホールドアウトのパーティションに適用されます。
プロジェクトのデータのセグメントに基づいてインサイトを表示および比較すると、モデルがさまざまな部分母集団でどのように動作するかを理解することができます。 スライスされたインサイトから取得したセグメントベースの精度情報を使用するか、セグメントを「グローバル」スライス(すべてのデータ)と比較して、トレーニングデータを改善、セグメントごとに個別モデルを作成、またはデプロイ後の予測を補強します。
スライスされたインサイトの一般的な用途:
ある銀行は、ローンの債務不履行リスクを予測するモデルを構築しており、モデルのパフォーマンスが多かれ少なかれ正確であるデータ(人口統計情報、場所など)のセグメントがあるかどうかを理解したいと考えています。データを「スライスすること」で、一部のセグメントが期待どおりのパフォーマンスであることを示していることがわかった場合、セグメントごとに個別のプロジェクトを作成することを選択するかもしれません。
ある広告会社が、誰かが広告をクリックするかどうかを予測しようとしています。データには複数のウェブサイトが含まれていて、ポートフォリオのWebサイト間でドライバーが異なるかどうかを理解したいと考えています。各グループはいくつかの異なる値で構成され、最終的に各サイトのさまざまな方法でユーザーの行動に影響を与える比較グループの作成に関心を持っています。
モデルのトレーニング後にデータのセグメントのインサイトを表示するには、スライスドロップダウンから事前設定されたスライスを選択します。 選択したインサイトに対してスライスが計算されている場合、インサイトが読み込まれます。 それ以外の場合は、さらなる計算を開始するためのボタンが使用可能になります。
サポートされているインサイト¶
スライスされたインサイトは、二値分類および連続値プロジェクトの以下のインサイト(該当する場合)で使用できます。
DataRobot Classic: * 特徴量ごとの作用 * 特徴量のインパクト * リフトチャート * 残差(時間認識プロジェクトでは使用できません) * ROC曲線
NextGen: * 特徴量ごとの作用 * 特徴量のインパクト * 個々の予測の説明 * リフトチャート * 残差 * ROC曲線
スライスされたインサイトに関する注意事項も参照してください。
スライスの作成¶
スライスを作成して、サポート対象の リーダーボードインサイトからインサイトに適用できます。 各スライスは、最大3つの フィルター(必要に応じてAND演算子で接続)で構成されています。
備考
フィルターの作成に使用できる特徴量は、すべての特徴量に基づきます。データタブに現在表示されているものや、その特徴量を含まないセットを使用してモデルを構築したかどうかに関係ありません。 これは、特徴量セットは列に基づく一方で、スライスは行に基づくためです。 つまり、選択した特徴量の値は、特徴量セットの個々の特徴量によって識別される行に表示されます。
リーダーボードからスライスを作成するには、次の操作を実行します。
-
モデルを選択し、 サポートされているインサイトを開きます。 選択したパーティションのすべてのデータを使用してインサイトがロードされます。
-
スライスドロップダウン(デフォルトは
All Data)から、スライスの管理を選択することで、新規スライスを設定します。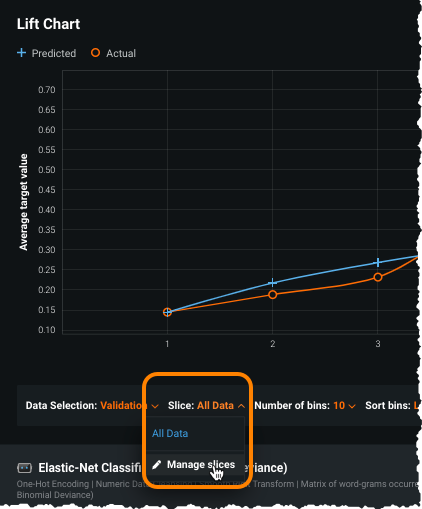
-
スライスの追加をクリックして、フィルター設定ウィンドウを開きます。 フィールドについては、 フィルターリファレンスを参照してください。
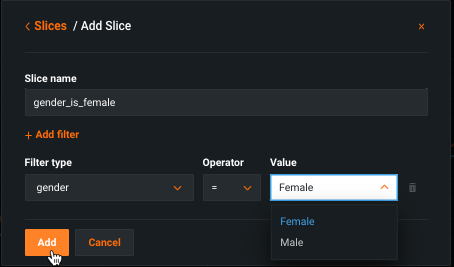
-
追加をクリックして終了し、スライスウィンドウを表示します( データセクションで説明)。 スライスウィンドウが表示され、設定済みのすべてのスライスが一覧表示され、スライスを定義するフィルターのサマリーテキストが表示されます。
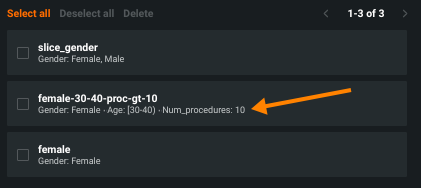
ここから、新規スライスを追加したり、または設定された複数のスライスを削除できます。 完了をクリックして設定ウィンドウを閉じます。
フィルター設定リファレンス¶
次の表にフィルターオプションを示します。
| フィルターフィールド | 説明 |
|---|---|
| スライス名 | フィルターの名前を入力してください。 これは、サポートされているインサイトのスライスドロップダウンに表示される名前です。 |
| フィルタータイプ | フィルターの基準となるカテゴリー特徴量または数値特徴量を選択します。 特徴量の型別にドロップダウンにグループ化されます。 ターゲットをフィルタータイプとして設定することはできません。 |
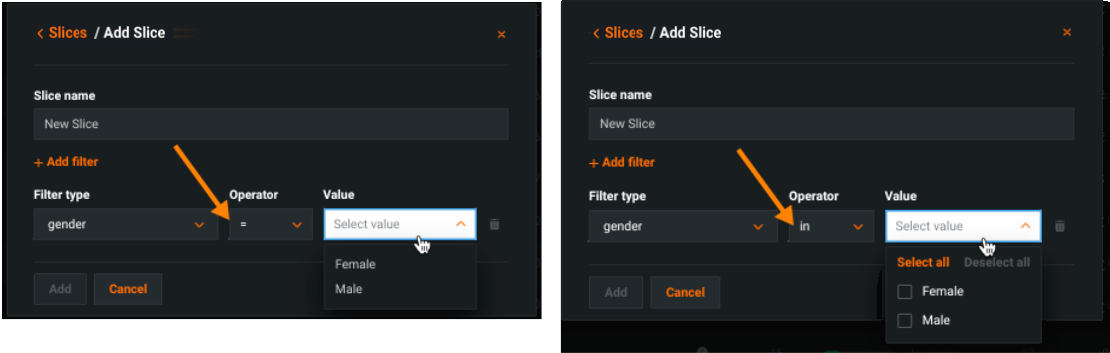
| オペレーター | フィルター演算子を設定して、部分母集団を構成する要素を定義します。 つまり、特徴量の値が以下のような行です。in:定義された値の範囲内にある(カテゴリーおよびブール値)。 =*:定義された値と等しい(以下を参照)。 >:定義された値より大きい(数値のみ)。<:定義された値より小さい(数値のみ)。 between:指定された2つの値の間にある(数値のみ、両端を含む)。 not between:指定された2つの値の間にない(数値のみ、両端を含む)。 |
| 値 | フィルタータイプの一致条件を設定します。 カテゴリー特徴量の場合、使用可能なすべての値がドロップダウンにリストされます。 数値の場合、値を手動で入力します。 |
* 演算子として=を選択した場合、値は完全に一致する必要があり、1つの値のみを選択できます。 inを設定した場合、複数の値を選択できます。
結合条件を追加する¶
フィルターの追加を使用して、複数の条件を含むスライスを構築します。 以下の点に注意してください。
- カテゴリー特徴量と数値特徴量を1つのスライスで混在させることができます。
-
すべての条件は
AND演算子で処理されます。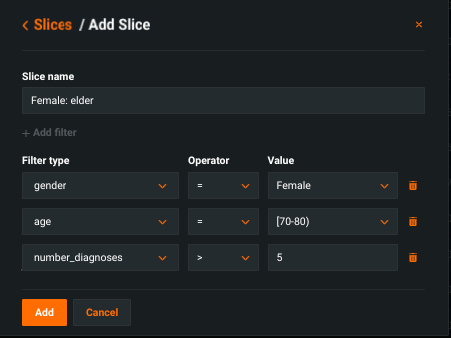
スライスされたインサイトを生成¶
インサイトを最初にロードすると、DataRobotは適切なパーティション内のすべてのデータについての結果を表示します(追加の計算が必要な場合を除く)。 これは、グローバルスライス、またはドロップダウンで参照されているものすべてのデータと同等です。 リフトチャート、ROC曲線、および残差については、最初のスライスに対して予測計算が実行されると、DataRobotは、(同じデータパーティションを想定して)、再利用できるようにそれらを保存します。 特徴量のインパクトおよび特徴量ごとの作用は、特殊な 計算プロセスを使用するため、キャッシュによるメリットはなく、各スライスの予測を再計算します。
所定のモデルについてスライスされたデータを表示する場合、選択したパーティション(検定、交差検定、または計算された場合、ホールドアウト)について予測を1回だけ生成する必要があります。 この計算は、プロジェクトのモデルをフィッティングするときにDataRobotが実行した元の計算に追加されることに注意してください。
備考
特徴量のインパクトには、計算用のサンプルサイズを制御する クイックコンピューティングオプションがあります。
スライスされたインサイトの再計算¶
特徴量ごとの作用または特徴量のインパクトのいずれかでスライスを使用する場合、インサイトのスライスバージョンを計算するには、計算を手動で開始する必要があります。 その理由は、計算リソースを節約することです。関連するジョブを自動的に起動せずに、スライスされたインサイトが作成されているかどうかを判断できるようになります。 操作の順序は次のとおりです。
-
リクエストに応じて、DataRobotはすべてのデータの特徴量のインパクトを計算します。 その後、設定されたスライスの計算を開始できます。
-
特徴量のインパクトの前に特徴量ごとの作用をリクエストすると、すべてのデータで特徴量のインパクトが計算され、特徴量ごとの作用の結果が返されます。 最初の特徴量のインパクトジョブが完了するまで、スライスを選択するオプションは提供されません。
-
オフの場合、行数は、100,000行またはスライス適用後に使用できる行数のいずれか小さい方を使用します。
スライスされていない特徴量のインパクトの場合、クイック計算トグルは、 サンプルサイズを調整するオプションを置き換えます。 その場合、以下のような結果が得られます。
-
オンの場合、DataRobotは、2500行またはモデルトレーニングサンプルサイズの行数のいずれか小さい方を使用します。
-
オフの場合、行数は、100,000行またはモデルトレーニングサンプルサイズの行数を使用します。
このオプションは、精度と安定性が高い結果を取得するために、例えば、デフォルトの2500行よりも大きいサンプルサイズ(またはダウンサンプリングした場合はより小さいサンプルサイズ)で、特徴量のインパクトをトレーニングする際に使用します。
スライスされたインサイトを表示¶
スライスされたインサイトを表示するには、スライスドロップダウンから適切なスライスを選択します。 スライスが表示されてもフィルター条件がわからない場合は、スライスを編集をクリックしてスライス設定ウィンドウを開きます。このウィンドウは、スライスを定義するフィルターのサマリーテキストを提供します。
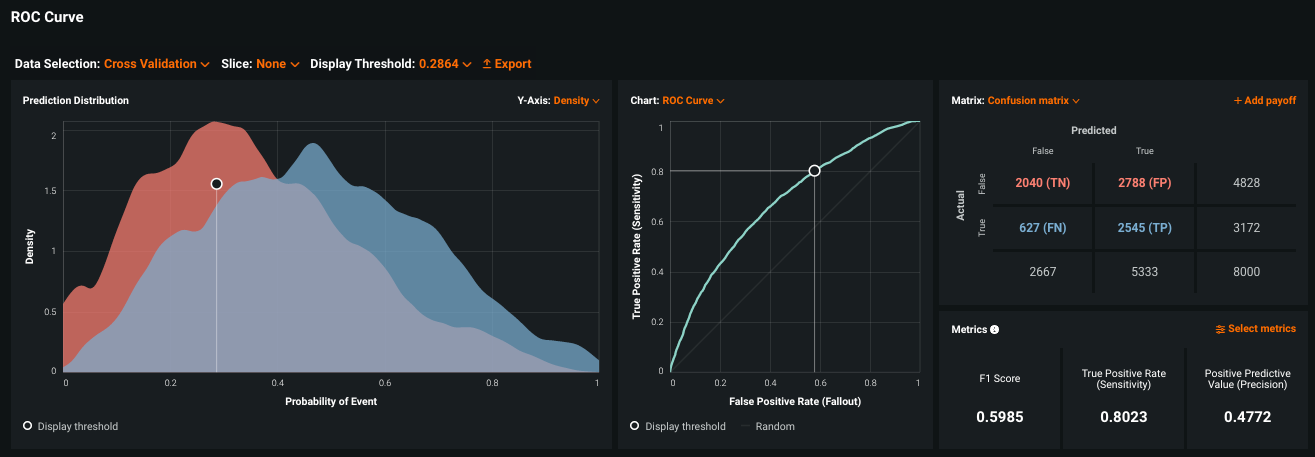
次の例は、スライスが適用されていないROC曲線タブを示します。
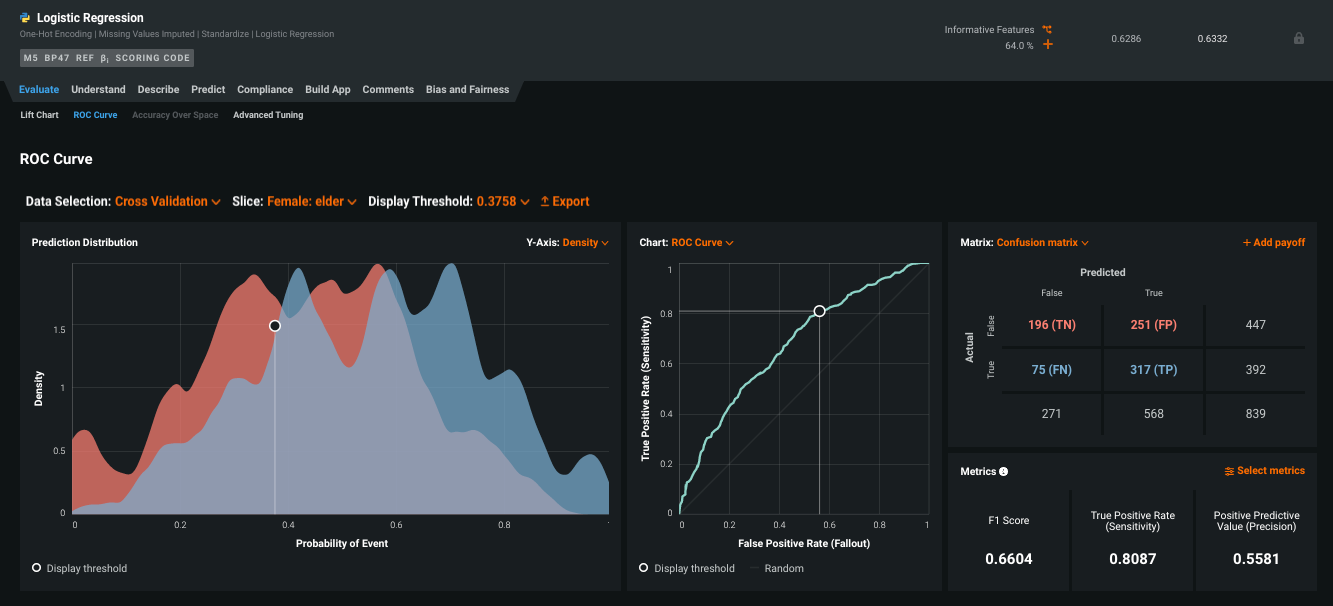
5つ以上の診断を受けた70~80歳の女性のデータをセグメント化するスライスが適用された同じモデルを考慮してください。
備考
スライスの結果、すべてがPositiveまたはすべてNegativeの予測が発生した場合、ROC曲線は直線になります。 混同行列は、同じ結果を表形式で報告します。
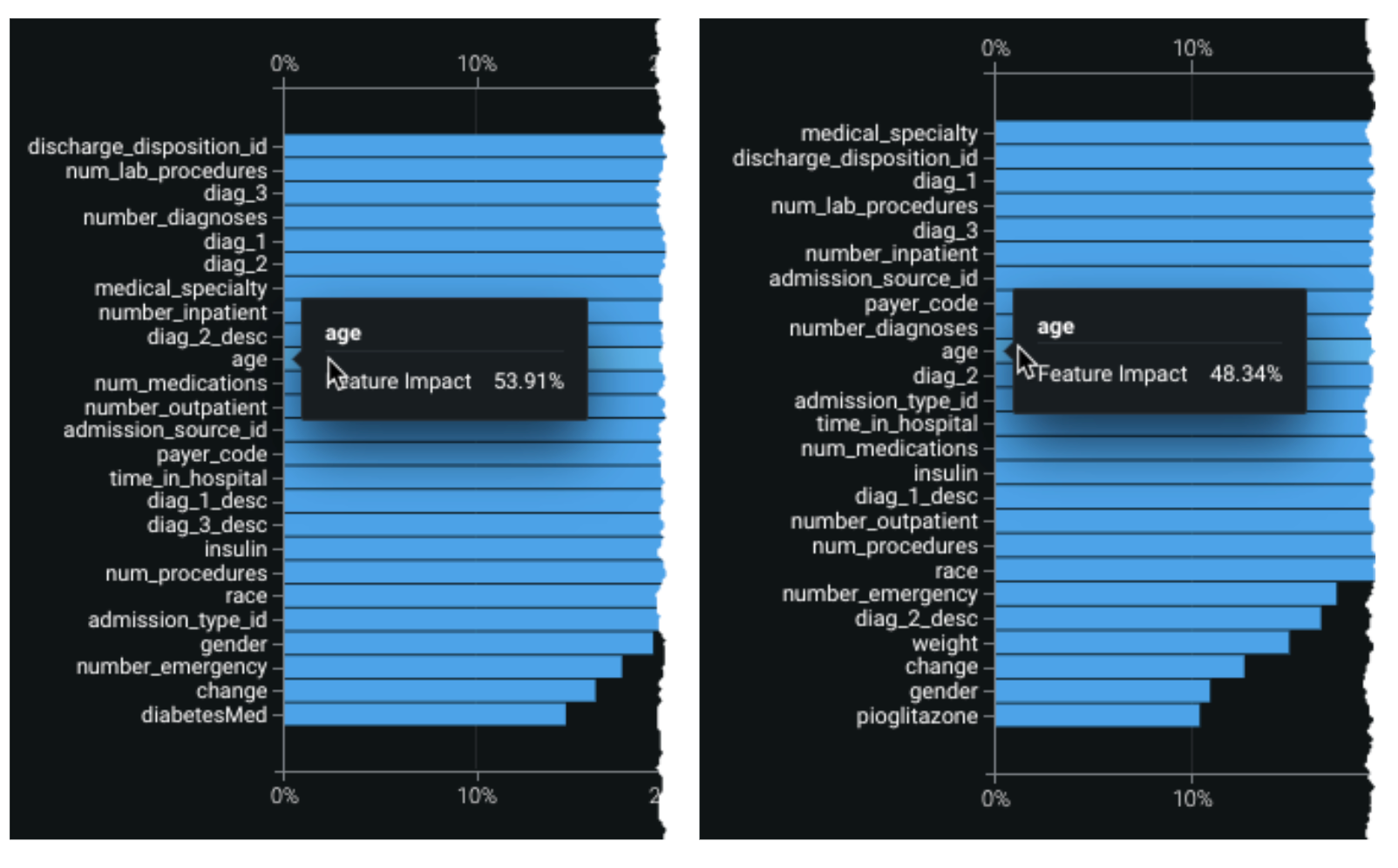
以下の画像は、特徴量のインパクトを示しています。まずグローバルスライス、次に設定済みのスライスが示されます。
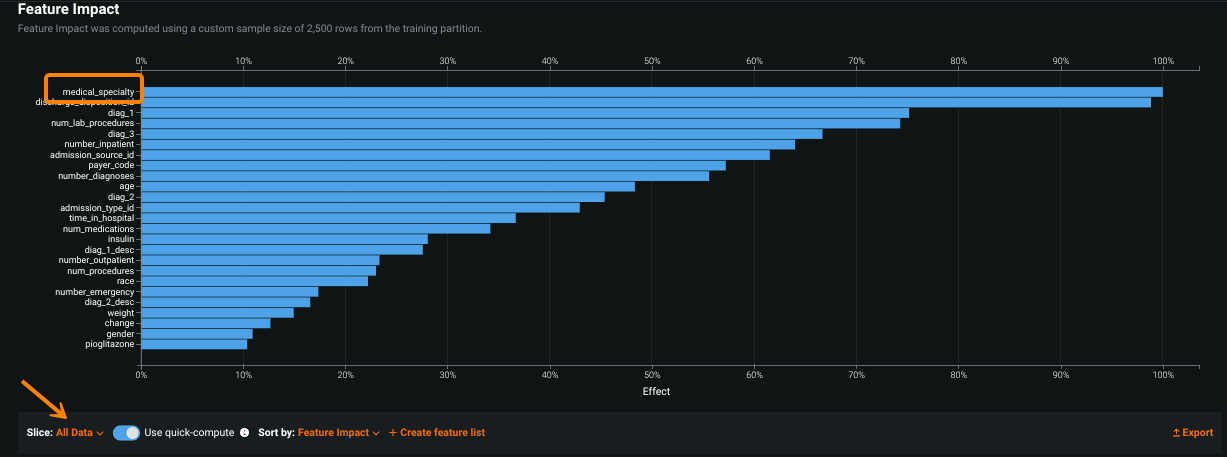
次に、設定されたスライスを以下に記します。
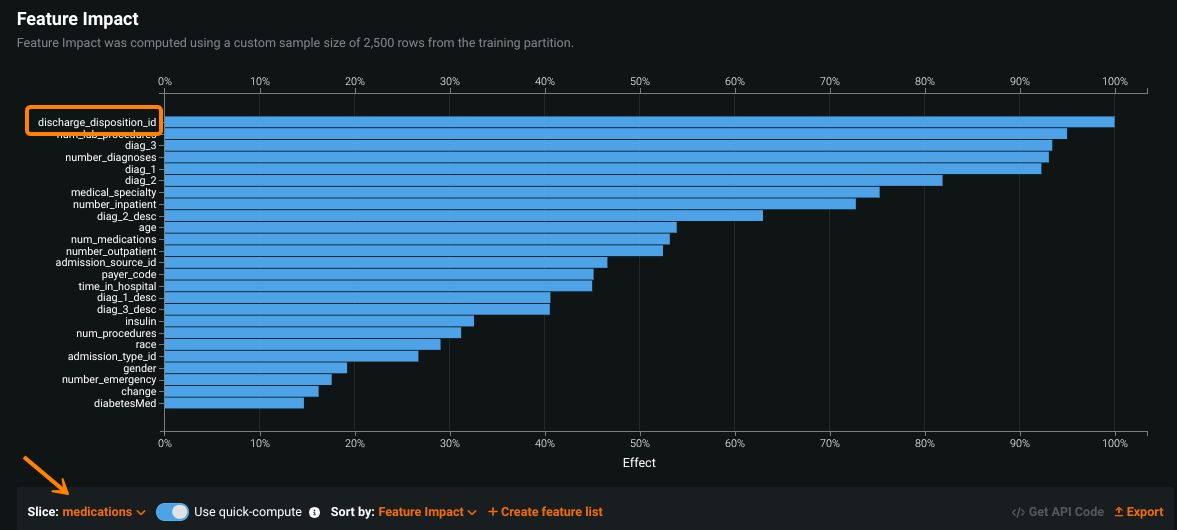
特徴量にカーソルを合わせると、スライスされたビュー間で計算されたインパクトを比較できます。
一歩進んだ操作:スライス計算¶
リフトチャート、ROC曲線、および残差については、最初のスライスに対して予測計算が実行されると、DataRobotは、同じデータパーティションを想定して、再利用できるようにそれらを保存します。 以下に具体例を示します。
-
同じインサイト内で初めて新しいスライスを選択すると、インサイトが生成されますが、予測を再実行する必要はありません(パーティションの予測はすでに計算されているため)。
-
サポートされている別のインサイト(特徴量のインパクト以外)に変更すると、予測が使用可能になり、インサイト自体のみを生成する必要があります(パーティションの予測はサポートされている別のインサイトによって既に計算されているため)。
特徴量のインパクトおよび特徴量ごとの作用の場合、DataRobotは、最初にモデルに適合するように選択されたトレーニングサンプルについて予測を実行します。 次に、DataRobotは、スライスベースの合成予測データセットを作成し、それぞれのインサイトで使用する予測を生成します。 各インサイトにより、独自の合成データセットが生成されます。
機能に関する注意事項¶
-
スライスされたインサイトは、予測および時間認識エクスペリメントの二値分類プロジェクトや連続値プロジェクトで取得できます。
-
スライスは、 特徴量探索を使用するプロジェクトでは使用できません。
-
スライスは、SHAP特徴量の有用性およびSHAPベースの予測の説明を使用して作成されたプロジェクトでは使用できません。
-
スライスは編集できません。 代わりに、(必要に応じて)既存のスライスを削除し、目的の条件を使用して新しいスライスを作成します。
-
単一のスライスに最大3つのフィルター条件を追加できます。
-
無効なスライスを作成すると、スライスは作成されますが、サポートされているインサイトに適用するとエラーになります。 これは、たとえば、スライスされたデータにインサイトを計算するのに十分な行がない場合や、フィルターが無効である場合などに発生する可能性があります。 たとえば、
num_procedures > 10と設定し、行の最大数が6である場合、DataRobotはスライスを作成しますが、スライスが選択されている場合、インサイトの計算時にエラーが発生します。 -
行の要件:
- クイック計算での特徴量のインパクト:最小2500行またはスライス適用後に使用できる行数のいずれか小さい方。 最小10行、最大100,000行
- その他のインサイト:最小1行(スライス内に含まれる必要がある)で、最大は ファイルサイズ制限によってのみ設定されます
-
特徴量のインパクトの場合:
-
スライスは、トレーニングデータのすべての行で計算されてから、要求された行数に対してスライスされます。 以前は、特徴量のインパクトは、行数でリクエストされた正確な行数について計算されていました。
-
個々のスライスを計算する前に、すべてのデータに対して特徴量のインパクトを計算することをお勧めします。
-