ホストされた指標ジョブの作成¶
ホストされた指標に対して、手動でまたはテンプレートからカスタムジョブを追加し、指標設定を定義して、指標をデプロイに関連付けます。 ホストされた指標ジョブを表示して追加するには、ジョブ > 指標タブに移動してから、次の操作を実行します。
-
ホストされた指標ジョブを新たに手動で追加するには、+ ホストされた指標ジョブを新規追加(またはジョブパネルが開いている場合は最小化された追加ボタン )をクリックします。
-
テンプレートからホストされた指標ジョブを作成するには、追加ボタンの横にある をクリックし、カスタム指標の下にあるテンプレートから新規作成をクリックします。
新しいジョブがアセンブルタブに開きます。 選択した作成オプションに応じて、以下の表でリンクされている設定手順に進みます。
| ホストされた指標のジョブタイプ | 説明 |
|---|---|
| ホストされた指標ジョブを新規追加 | 新しくホストされた指標のジョブを手動で追加し、指標設定を定義して、指標をデプロイに関連付けます。 |
| テンプレートから新規作成 | DataRobotが提供するテンプレートからホストされた指標ジョブを追加し、デプロイに指標を関連付け、ベースラインを設定します。 |
ホストされた指標ジョブを新規作成¶
ホストされた指標ジョブを手動で追加するには:
-
新しいホストされた指標ジョブのアセンブルタブで、ジョブ名(または編集アイコン )をクリックして新しいジョブ名を入力し、確認 をクリックします。
-
環境セクションで、ジョブの基本環境を選択します。
利用可能なドロップイン環境はDataRobotのインストール形態によって異なりますが、一般的に利用可能なパブリックドロップイン環境とDRUMリポジトリのテンプレートを以下の表に示します。 DataRobotのインストール形態によっては、これらの環境のPythonバージョンが異なる場合があり、さらに非公開の環境が利用できる場合もあります。
ドロップイン環境のセキュリティ
2025年3月にリリースされたマネージドAIプラットフォームから、ほとんどの汎用DataRobotカスタムモデルのドロップイン環境は、セキュリティが強化されたコンテナイメージになりました。 カスタムジョブの実行にセキュリティが強化された環境が必要な場合、POSIX-shell標準に準拠したシェルコードのみがサポートされます。 POSIXシェル標準に準拠したセキュリティ強化環境では、限られたシェルユーティリティのみがサポートされています。
ドロップイン環境のセキュリティ
セルフマネージドAIプラットフォームのリリース11.0から、ほとんどの汎用DataRobotカスタムモデルのドロップイン環境は、セキュリティが強化されたコンテナイメージになりました。 カスタムジョブの実行にセキュリティが強化された環境が必要な場合、POSIX-shell標準に準拠したシェルコードのみがサポートされます。 POSIXシェル標準に準拠したセキュリティ強化環境では、限られたシェルユーティリティのみがサポートされています。
環境名と例 互換性とアーティファクトファイルの拡張子 Python 3.X Pythonベースのカスタムモデルとジョブ。 モデルファイルに requirements.txtファイルを含めることで、必要な依存関係をすべてインストールしてください。Python 3.X GenAIエージェント 生成AIモデル( Text GenerationまたはVector Databaseのターゲットタイプ)Python 3.X ONNXドロップイン ONNXモデルとジョブ( .onnx)Python 3.X PMMLドロップイン PMMLモデルとジョブ( .pmml)Python 3.X PyTorchドロップイン PyTorchモデルとジョブ( .pth)Python 3.X Scikit-Learnドロップイン Scikit-Learnモデルとジョブ( .pkl)Python 3.X XGBoostドロップイン ネイティブXGBoostモデルとジョブ( .pkl)Python 3.X Kerasドロップイン TensorFlow(.h5)がサポートするKerasモデルとジョブ Javaドロップイン DataRobotスコアリングコードモデル( .jar)ドロップイン環境 CARET( .rds)を使ってトレーニングされたRモデル
CARETが推奨するすべてのライブラリをインストールするのに時間がかかるため、パッケージ名でもあるモデルタイプのみがインストールされます(例:brnn、glmnet)。 この環境のコピーを作成し、Dockerfileを修正して、必要なパッケージを追加でインストールします。 この環境をカスタマイズする際のビルド回数を減らすために、# Install caret modelsセクションで不要な行を削除して、必要なものだけをインストールすることもできます。 CARETドキュメントを参照して、モデルの手法がパッケージ名と一致しているかどうかを確認してください。 このリンクをクリックする前にGitHubにログインしてください。scikit-learn
すべてのPython環境には、(必要に応じて)前処理を支援するscikit-learnが含まれていますが、
sklearnモデルで予測を行うことができるのはscikit-learnだけです。 -
メタデータセクションで、次のカスタム指標ジョブフィールドを設定します。
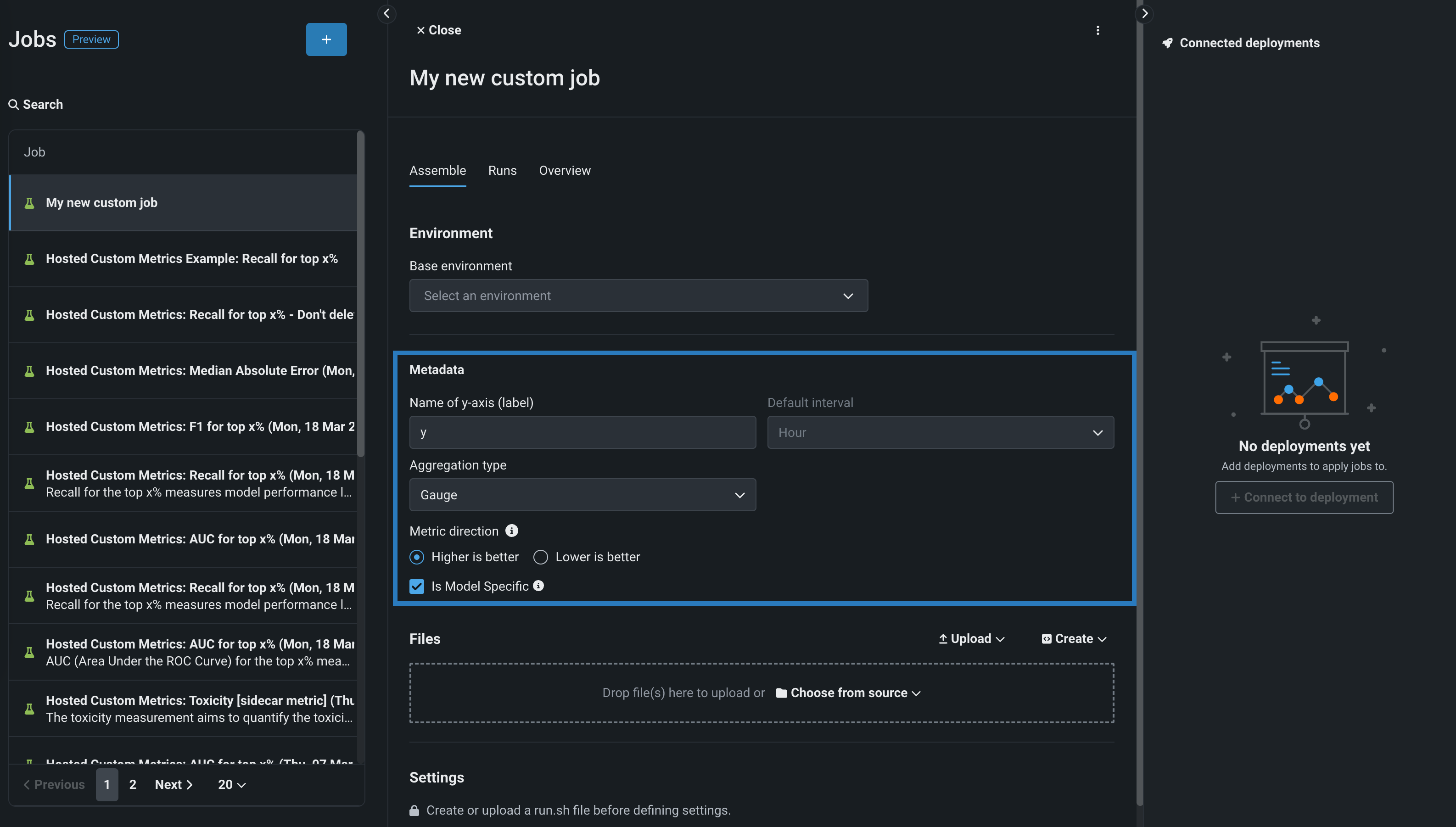
フィールド 説明 Y軸の名前(ラベル) 従属変数のわかりやすい名前。 この名前は、カスタム指標のサマリーダッシュボードのカスタム指標のチャートに表示されます。 デフォルトの間隔 選択した集計タイプで使用されるデフォルトの間隔を決定します。 時間のみサポートされています。 集計タイプ 指標を合計、平均、またはゲージ(単一時点で測定された明確な値を持つ指標)として計算するかどうかを決定します。 指標の方向性 指標の方向性を決定し、指標の変更を視覚化する方法を変更します。 大きいほど良いまたは低いほど良いを選択できます。 たとえば、低いほど良いを選択すると、カスタム指標の計算値が10%減少することが、10%改善とみなされ、緑色で表示されます。 モデル固有 この設定を有効にすると、データセットで提供されたモデルパッケージID(登録されているモデルバージョンID)を使用して、指標をモデルにリンクします。 この設定は、値が集計(またはアップロード)される場合に影響します。 例: - モデル固有(有効):モデルの精度指標はモデル固有であるため、値は完全に個別に集計されます。 モデルを置換すると、カスタム精度指標のチャートには、置換後の日についてのデータだけが表示されます。
- モデル固有ではありません(無効):収益指標はモデル固有ではないため、値は一緒に集計されます。 モデルを置換しても、カスタム収益指標のチャートは変更されません。
地理空間 カスタム指標で地理空間データを使用するかどうかを決定します。 プレミアム機能
地理空間の監視はプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
地理空間特徴量の監視サポート
地理空間特徴量の監視は、二値分類、多クラス、連続値、位置のターゲットタイプでサポートされています。
-
ファイルセクションで、カスタムジョブを構築します。 ボックスにファイルをドラッグするか、このセクションのオプションを使用して、カスタムジョブの構築に必要なファイルを作成またはアップロードします。
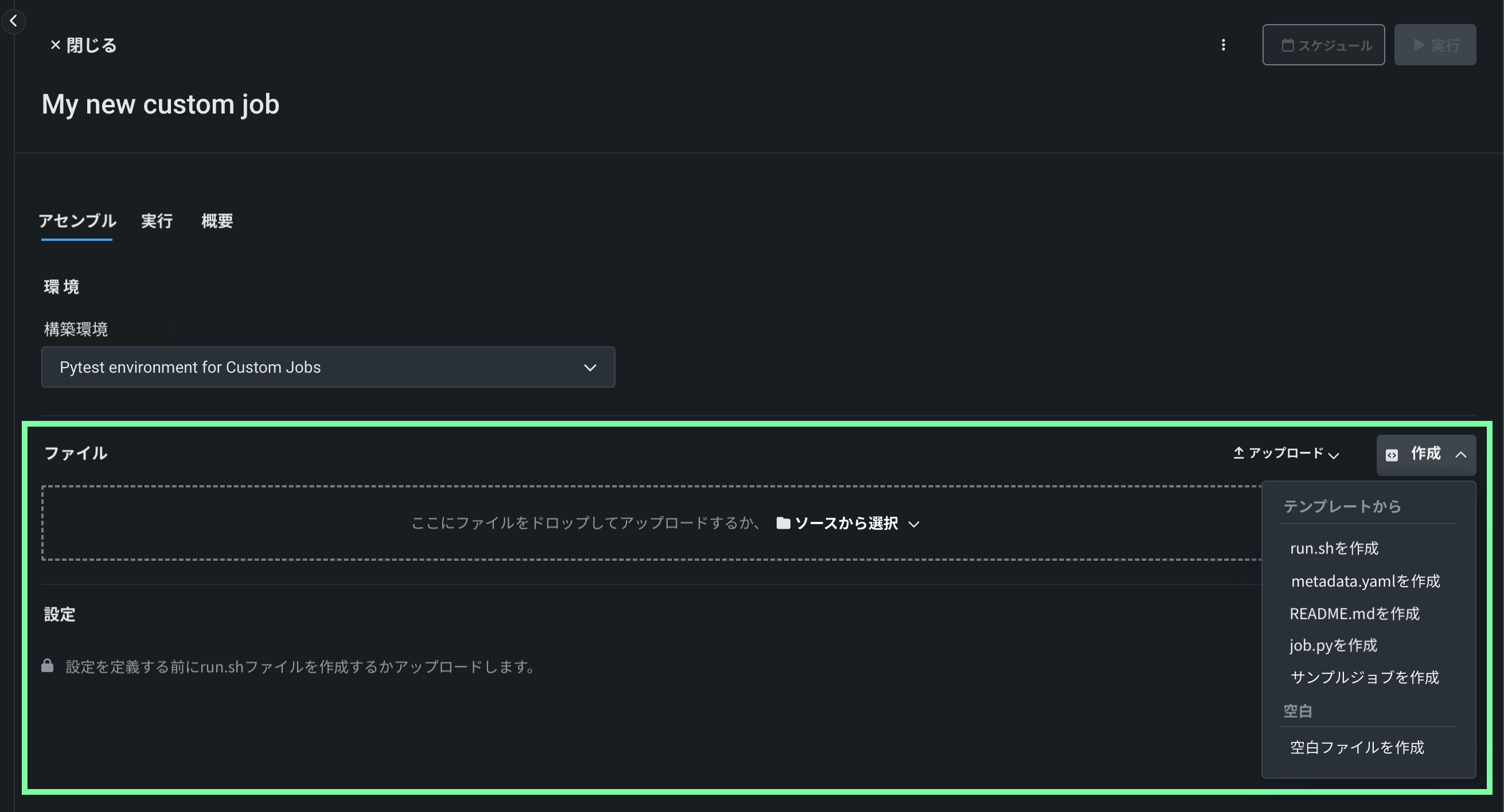
オプション 説明 ソース/アップロードから選択 既存のカスタムジョブファイル( run.sh、metadata.yaml、など)をローカルファイルまたはローカルフォルダーとしてアップロードします。作成 空のファイルまたはテンプレートを含んだファイルとして新しいファイルを作成し、カスタムジョブに保存します。 - run.shを作成:エントリーポイントファイルの基本的で編集可能な例を作成します。
- metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- README.mdを作成:基本的で編集可能なREADMEファイルを作成します。
- job.pyを作成:実行時のパラメーターとデプロイをプリントするための基本的で編集可能なPythonジョブファイルを作成します。
- サンプルジョブを作成:すべてのテンプレートファイルを結合して、基本的で編集可能なカスタムジョブを作成します。 簡単にランタイムパラメーターを設定し、このサンプルジョブを実行できます。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。 次のステップでは、カスタム名とコンテンツを使用して、このように作成されたファイルをエントリーポイントとして識別できます。 新しいファイルを設定したら、保存をクリックします。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
-
設定セクションで、ジョブのエントリーポイントシェル(
.sh)ファイルを設定します。run.shファイルを追加した場合、そのファイルがエントリーポイントになります。それ以外の場合は、ドロップダウンリストからエントリーポイントのシェルファイルを選択する必要があります。 エントリーポイントファイルでは、複数のジョブファイルを調整できます。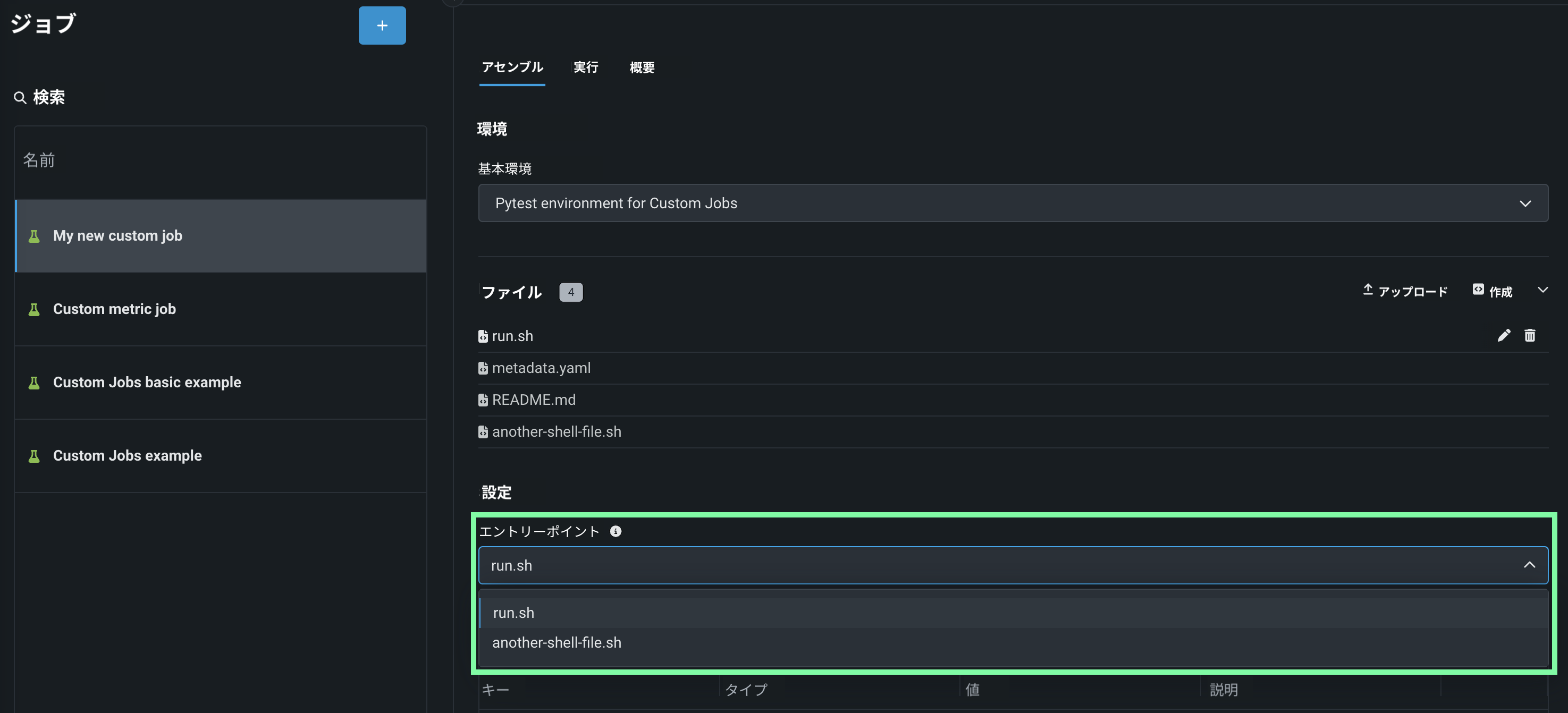
-
リソースセクションのセクションヘッダーの横にある 編集をクリックして、以下を設定します。
プレビュー
カスタムジョブのリソースバンドルは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:リソースのバンドルを有効にする
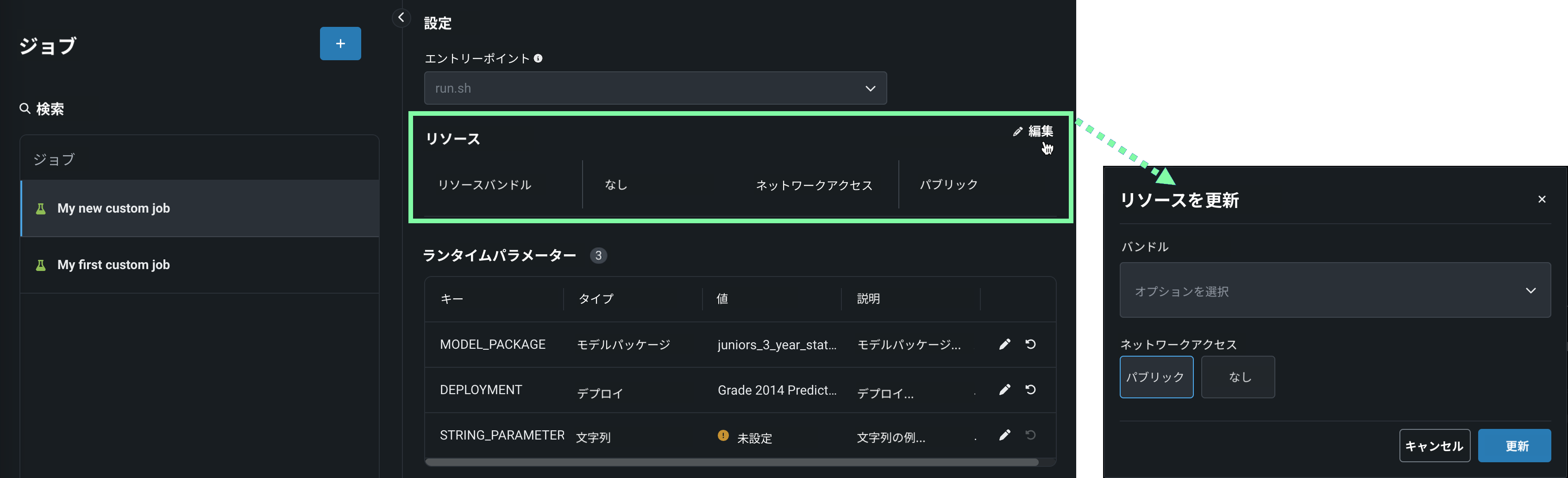
設定 説明 リソースバンドル(プレビュー) カスタムジョブが実行に使用するリソースを設定します。 ネットワークアクセス カスタムジョブのエグレストラフィックを設定します。 ネットワークアクセスで、以下のいずれかを選択します。 - パブリック:デフォルト設定。 カスタムジョブは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムジョブはパブリックネットワークから隔離され、サードパーティのサービスにアクセスできません。
デフォルトのネットワークアクセス
_マネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでパブリックに設定されていますが、変更可能です。 _セルフマネージドAIプラットフォーム_では、ネットワークアクセスはデフォルトでなしに設定されており、制限があります。ただし、管理者は、DataRobotプラットフォームの設定時にこれを変更できます。 詳細については、DataRobotの担当者または管理者にお問い合わせください。
-
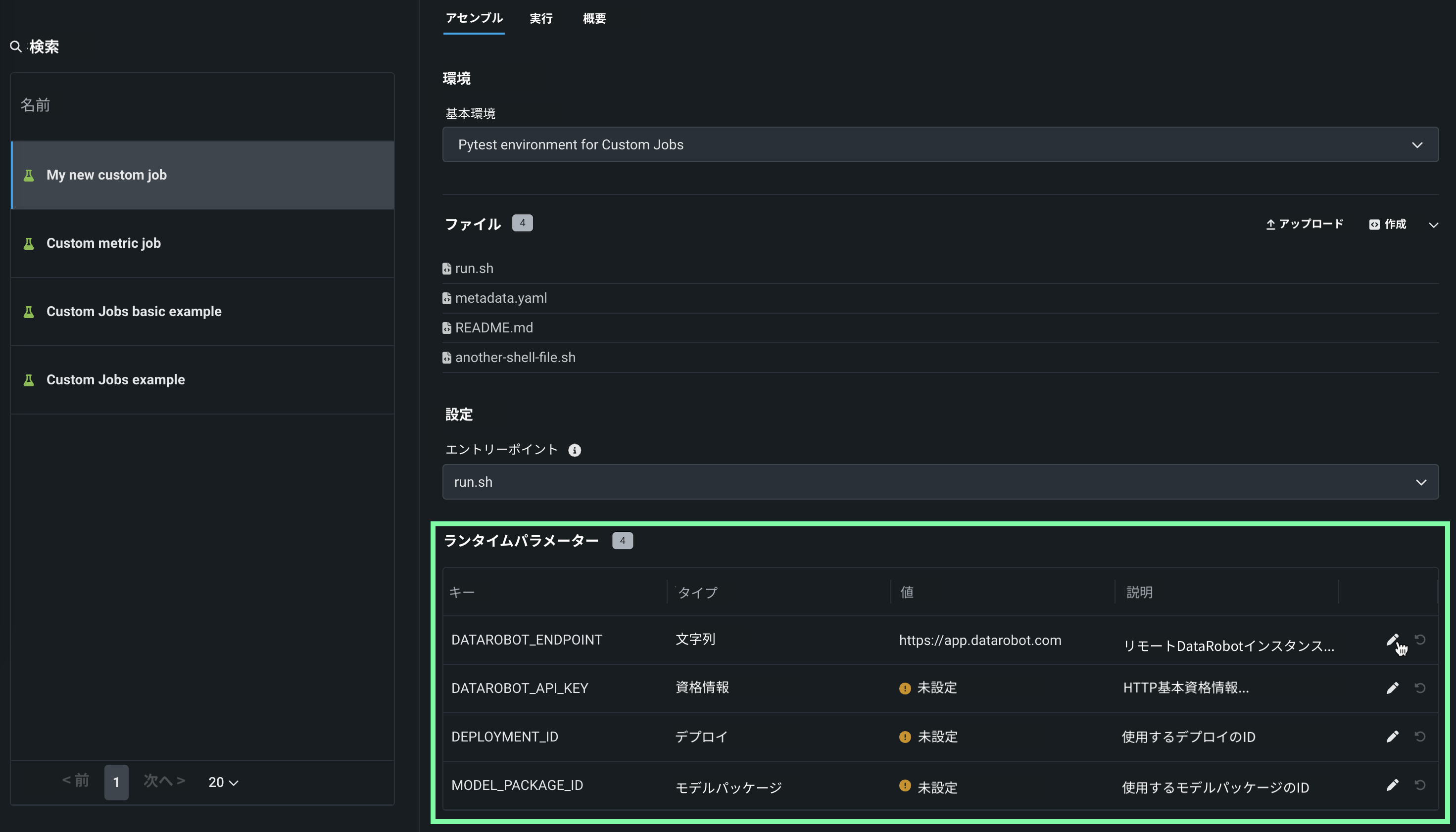
(オプション)ランタイムパラメーターを定義します。 + ランタイムパラメーターを追加をクリックし、名前、タイプ、値、および必要に応じて説明を入力して、新しいランタイムパラメーターを定義します。
または、
metadata.yamlファイルでランタイムパラメーターを定義します。 このファイルのテンプレートは、ファイル > 作成ドロップダウンから入手できます。既存のランタイムパラメーターの場合、 編集をクリックして、パラメーター値の編集、パラメーターの削除、またはパラメーター値のリセットを行います。
-
(オプション)タグ、指標、トレーニングパラメーター、アーティファクトに、追加の キー値を設定します。
-
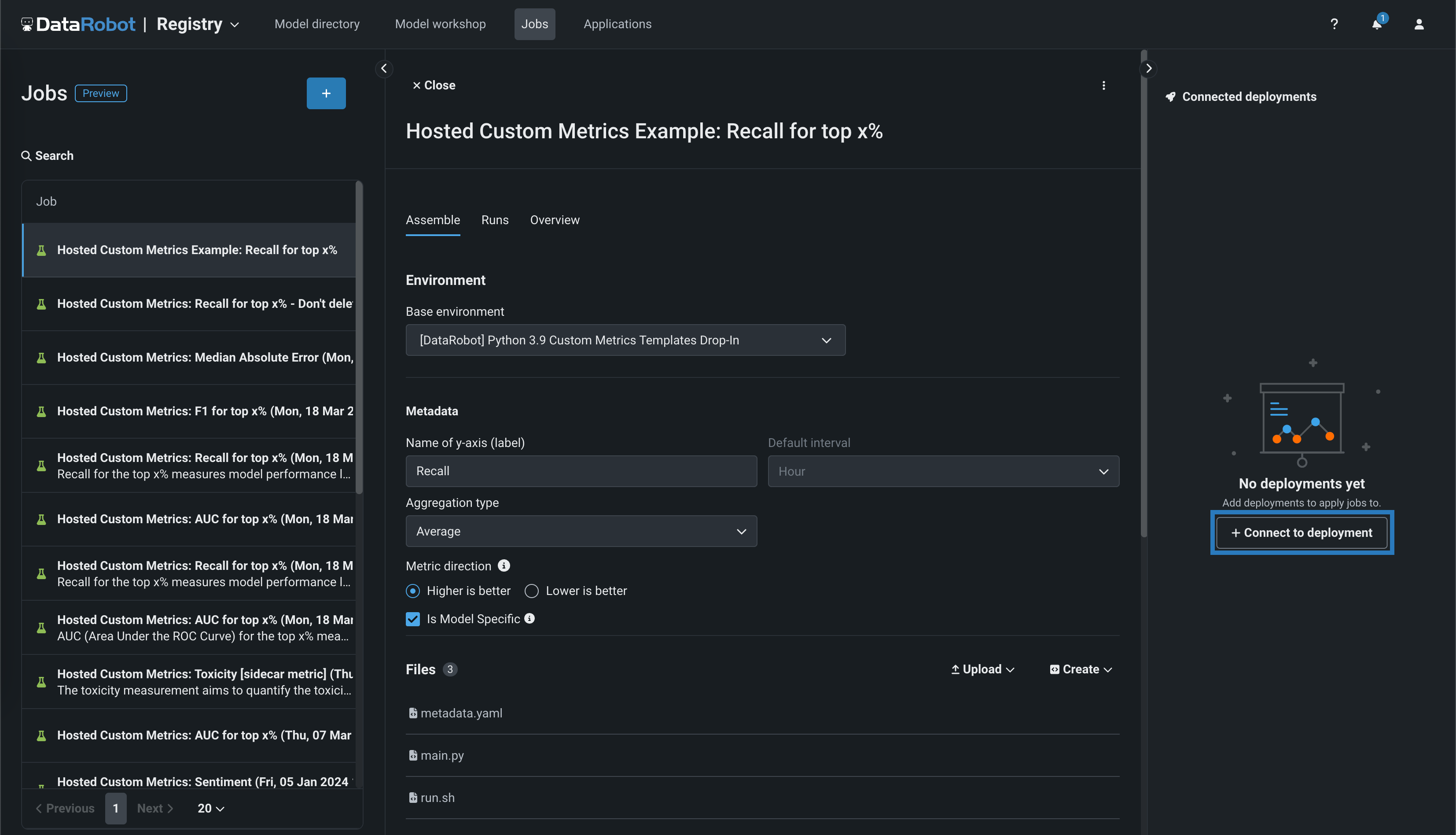
接続されたデプロイパネルで、+ デプロイに接続をクリックして、カスタム指標名を定義し、デプロイIDを選択して、そのデプロイに接続します。
-
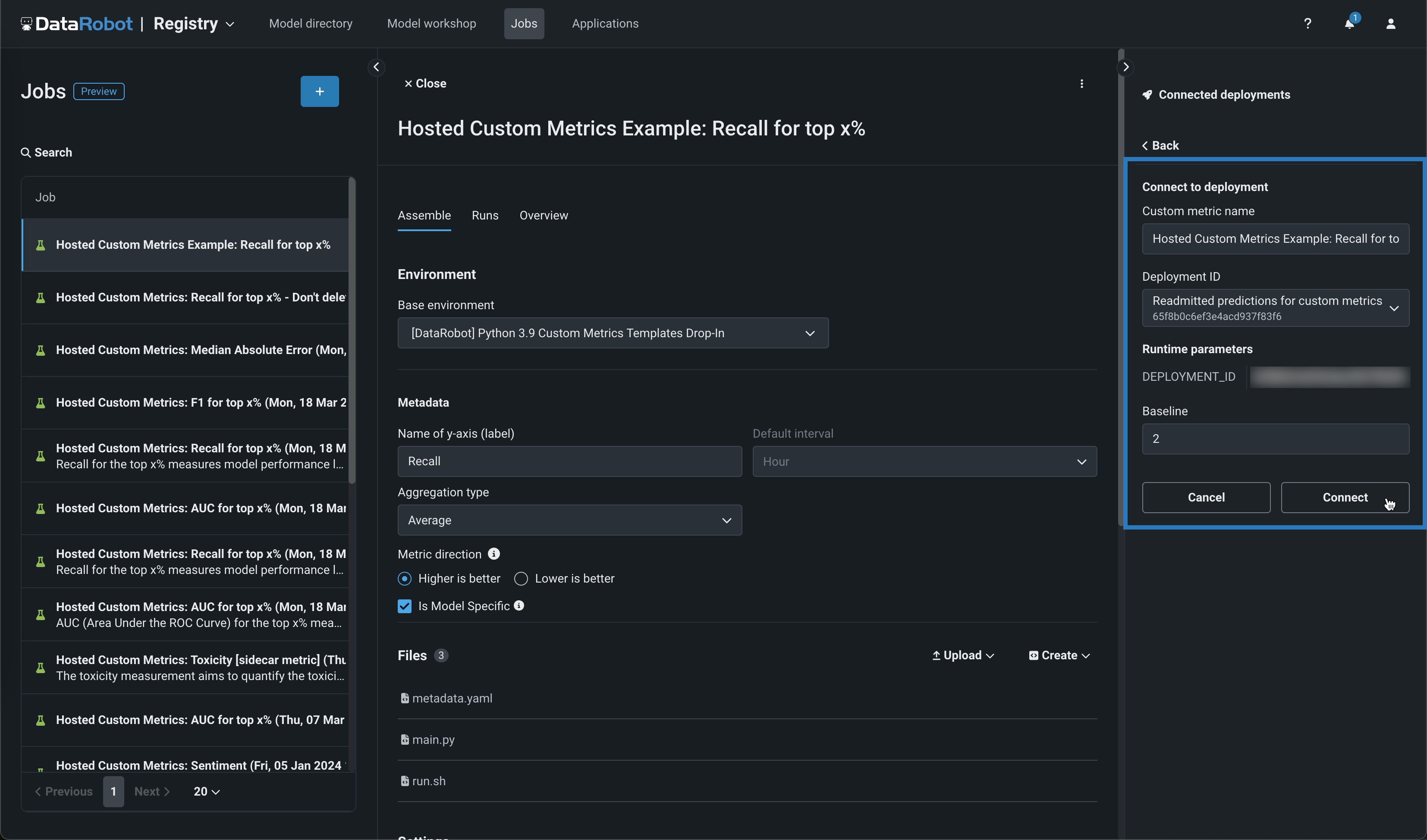
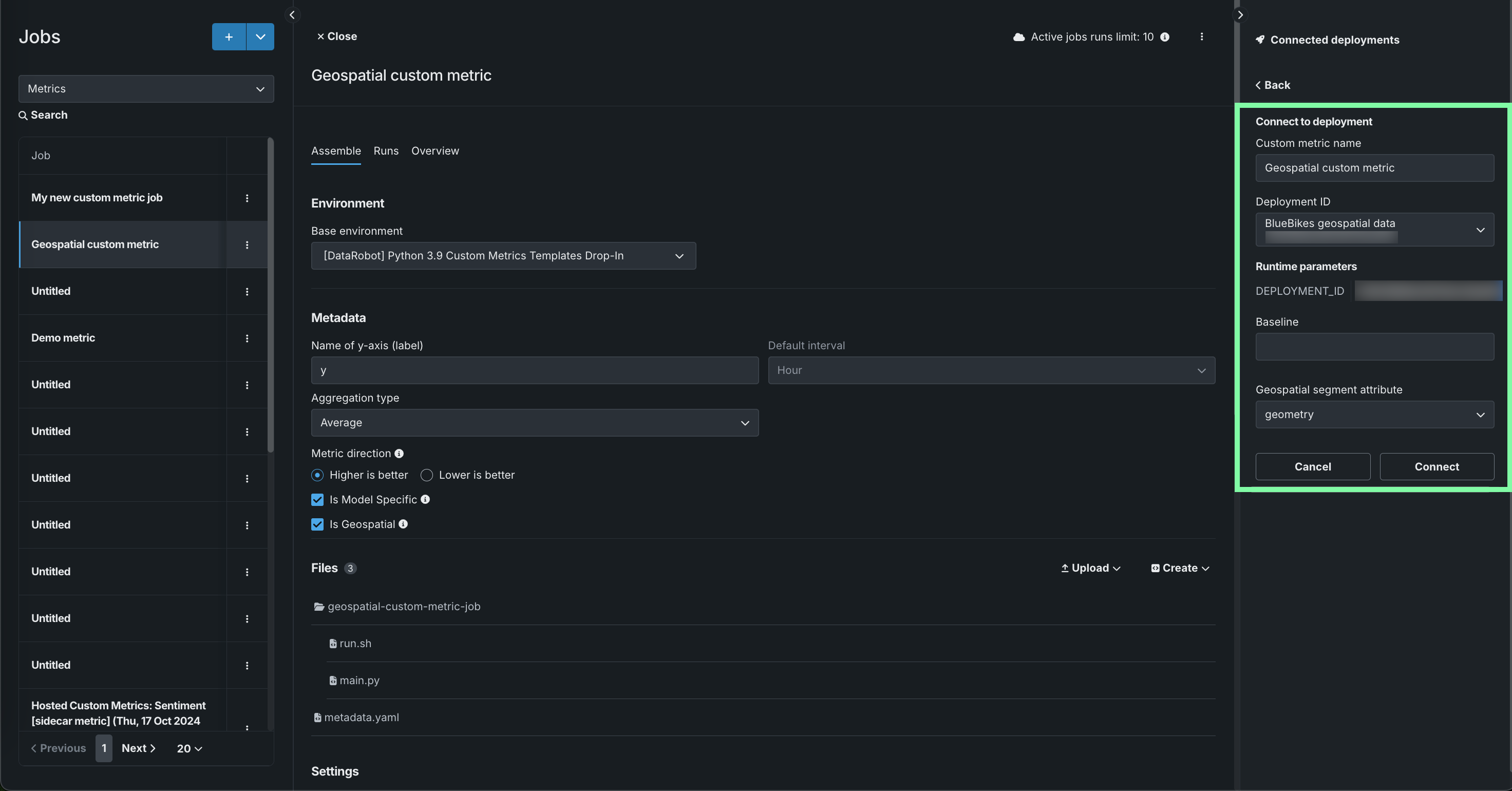
カスタム指標の名前を編集し、デプロイIDを選択して、ベースラインを設定します。ベースラインは、x%良いまたはx%悪化の値を計算する際に比較の基準として使用される値です。 メタデータセクションで地理空間を選択した場合は、少なくとも1つの地理空間/位置特徴量を持つデプロイを選択し、地理空間セグメント属性を定義します。 その上で、接続をクリックします。
地理空間特徴量の監視サポート
地理空間特徴量の監視は、二値分類、多クラス、連続値のターゲットタイプでサポートされています。
ホストされたカスタム指標ジョブにいくつのデプロイを接続できますか?
ホストされたカスタム指標ジョブに、最大10のデプロイを接続できます。
接続されたデプロイとランタイムパラメーター
ホストされているカスタム指標ジョブにデプロイを接続し、実行をスケジュールした後は、
metadata.yamlファイルのランタイムパラメーターを変更できません。metadata.yamlファイルに変更を加えるには、接続されているすべてのデプロイを切断する必要があります。
ホストされた指標ジョブをテンプレートから作成¶
テンプレートから事前に作成された指標を追加するには:
プレビュー
ジョブテンプレートギャラリーは、デフォルトでオンになっています。
機能フラグ:カスタムジョブのテンプレートギャラリーを有効にする
-
ギャラリーからカスタムジョブを追加パネルで、目的のユースケースに適したカスタム指標テンプレートを選択し、指標を作成をクリックします。
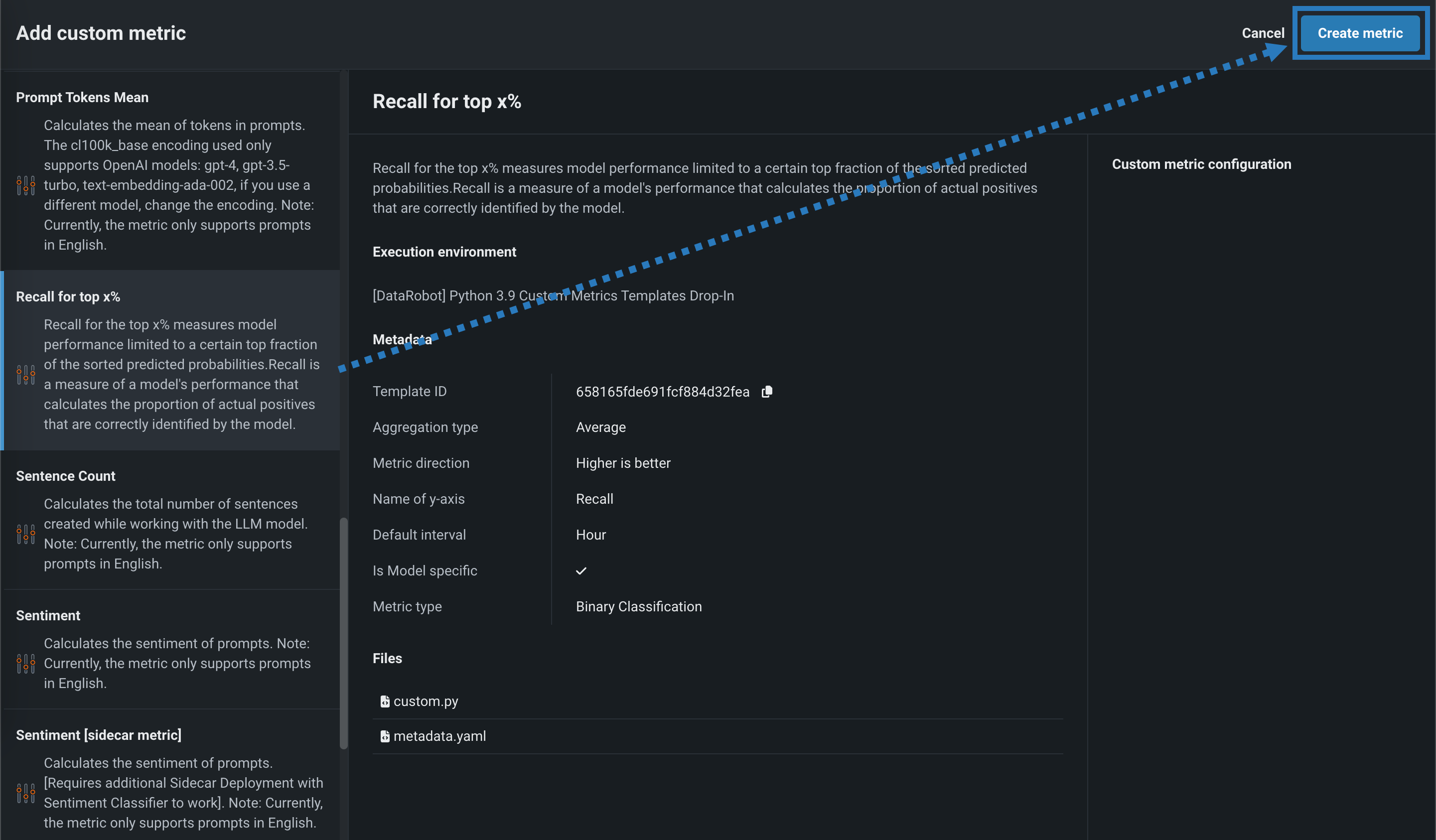
カスタム指標のテンプレート 説明 上位x%のリコール 並べ替えられた予測確率の特定の上位部分に限定して、モデルのパフォーマンスを測定します。 リコールは、モデルによって正しく識別される実際の陽性の割合を計算するモデルのパフォーマンス指標です。 上位x%の陽性的中率 並べ替えられた予測確率の特定の上位部分に限定して、モデルのパフォーマンスを測定します。 陽性的中率は、予測された陽性の合計から正しく予測された陽性の観測値の割合を計算するモデルのパフォーマンス指標です。 上位x%のF1 並べ替えられた予測確率の特定の上位部分に限定して、モデルのパフォーマンスを測定します。 F1スコアは、陽性的中率とリコールの両方を考慮するモデルのパフォーマンス指標です。 上位x%のAUC(ROC曲線下の領域) 並べ替えられた予測確率の特定の上位部分に限定して、モデルのパフォーマンスを測定します。 カスタム指標のテンプレート 説明 平均二乗対数誤差(MSLE) 予測値と実測値の対数の平方差の平均を計算します。 これは、ターゲット値が人口数、期間内の商品の平均売上高などの指数関数的に増加すると予想される場合に、連続値問題で使用される損失関数です。 中央絶対誤差(MedAE) ターゲット値と予測値の間の絶対差の中央値を計算します。 これは、予測の精度を測定するために連続値問題で使用される堅牢な指標です。 カスタム指標のテンプレート 説明 読み終わるまでの時間 LLMが生成したテキストを人が読むのにかかる平均時間を推定します。 出力トークン数の平均 リクエストされた期間の完了時のトークンの平均数を計算します。 使用されるcl100k_baseエンコーディングは、OpenAIモデル(gpt-4、gpt-3.5-turbo、text-embedding-ada-002)のみをサポートします。別のモデルを使用する場合は、エンコーディングを変更してください。 コサイン類似度の平均 各プロンプトベクターと対応するコンテキストベクター間の平均コサイン類似度を計算します。 コサイン類似度の最大値 各プロンプトベクターと対応するコンテキストベクター間の最大のコサイン類似度を計算します。 コサイン類似度の最小値 各プロンプトベクターと対応するコンテキストベクター間の最小のコサイン類似度を計算します。 コスト 入力、出力、および検索されたテキストのトークン数を計算してから、トークンの価格設定を適用することで、LLMを使用する際の財務コストを推定します。 使用されるcl100k_baseエンコーディングは、OpenAIモデル(gpt-4、gpt-3.5-turbo、text-embedding-ada-002)のみをサポートします。別のモデルを使用する場合は、エンコーディングを変更してください。 Dale-Chall 読みやすさ 難解な単語の割合と平均的な文章の長さに基づいて、テキストを理解するのに必要な米国の学年レベルを測定します。 ユークリッド平均 各プロンプトベクターと対応するコンテキストベクター間の平均ユークリッド距離を計算します。 ユークリッド最大値 各プロンプトベクターと対応するコンテキストベクター間の最大ユークリッド距離を計算します。 ユークリッド最小値 各プロンプトベクターと対応するコンテキストベクター間の最小ユークリッド距離を計算します。 フレッシュ読解容易性 テキストの読みやすさを、平均の文章長さと単語あたりの平均音節数に基づいて測定します。 プロンプトインジェクション[サイドカー指標] システムプロンプトの上書きや変更など、モデルの出力を変えることを目的とした入力操作を検出します。 この指標には、プロンプトインジェクション分類器の グローバルモデルを追加でデプロイする必要があります。 プロンプトトークンの平均 リクエストされた期間のプロンプトでの平均トークン数を計算します。 使用されるcl100k_baseエンコーディングは、OpenAIモデル(gpt-4、gpt-3.5-turbo、text-embedding-ada-002)のみをサポートします。別のモデルを使用する場合は、エンコーディングを変更してください。 文章数 LLMによって生成されたユーザープロンプトとテキスト内の文章の総数を計算します。 センチメント テキストのセンチメントを肯定的か否定的に分類します センチメント[サイドカー指標] 事前に学習された感情分類モデルを使用して、テキストの感情を肯定的または否定的に分類します。 この指標には、感情分類器の グローバルモデルを追加でデプロイする必要があります。 音節数 ユーザープロンプトとLLMが生成したテキストに含まれる単語の音節数の合計を計算します。 トークンの平均 プロンプトと補完のトークンの平均を計算します。 使用されるcl100k_baseエンコーディングは、OpenAIモデル(gpt-4、gpt-3.5-turbo、text-embedding-ada-002)のみをサポートします。別のモデルを使用する場合は、エンコーディングを変更してください。 毒性[サイドカー指標] 事前に訓練された差別的発言の分類モデルを使用してテキストの毒性を測定し、有害なコンテンツを防止します。 この指標には、毒性分類器の グローバルモデルを追加でデプロイする必要があります。 ワードカウント ユーザープロンプトとLLMが生成したテキストに含まれる単語数の合計を計算します。 日本語テキストの指標 [日本語] 文字数 LLMでの作業中に生成された文字数の合計を計算します。 [日本語] PII出現数 LLMでの作業中に発生したPIIの総数を計算します。 カスタム指標のテンプレート 説明 エージェントの出力トークン エージェントベースのLLM呼び出しの総出力トークン数を計算します。 エージェントのコスト エージェントベースのLLM呼び出しの総コストを計算します。 指標がトレースからコストを計算できるように、各LLMスパンがトークンの使用状況を報告する必要があります。 エージェントのプロンプトトークン エージェントベースのLLM呼び出しの総プロンプトトークン数を計算します。 -
ジョブの説明、実行環境、メタデータ、およびファイルを確認します。 必要に応じて、カスタム指標の設定を行ってサイドカーのデプロイを選択してから、カスタムジョブを作成をクリックします。

ホストされた指標ジョブがアセンブルタブに開きます。
サイドカー指標
[sidecar metric]を選択した場合は、カスタム指標の設定でサイドカーのデプロイを設定する必要があります。 接続を確認するには、アセンブルタブを開き、ランタイムパラメーターに移動して、SIDECAR_DEPLOYMENT_IDパラメーターが設定されていることを確認し、その指標の計算に必要な接続済みのデプロイにサイドカー指標を関連付けます。 指標を計算するモデルをデプロイしていない場合、これらの指標には、 グローバルモデルとして事前に定義されたモデルがあります。 -
アセンブルタブでは、 標準のカスタム指標ジョブと同様に、テンプレートのデフォルト名、環境、ファイル、設定、リソース、ランタイムパラメーター、またはキー値を必要に応じて変更できます。
-
接続されたデプロイパネルで、+ デプロイに接続をクリックします。
接続されたデプロイとランタイムパラメーター
ホストされているカスタム指標ジョブにデプロイを接続し、実行をスケジュールした後は、
metadata.yamlファイルのランタイムパラメーターを変更できません。metadata.yamlファイルに変更を加えるには、接続されているすべてのデプロイを切断する必要があります。 -
カスタム指標の名前を編集してデプロイIDを選択し、ベースライン(x%良いまたはx%悪化の値を計算する際に比較の基準となる値)を設定してから、接続をクリックします。
ホストされたカスタム指標ジョブにいくつのデプロイを接続できますか?
ホストされたカスタム指標ジョブに、最大10のデプロイを接続できます。