データドリフト¶
モデルの実際の入力データの分布が時間の経過に伴い変化し、トレーニングデータセットのデータ分布から乖離すると、デプロイされたモデルは予測力を失います。 モデルを取り巻くデータはドリフトしていると言われ、モデルは実世界の状況の変化に適応するのに苦労する場合があります。 モニタリング > データドリフトダッシュボードは、デプロイに追加されたトレーニングデータと予測データ(推論データとも呼ばれます)を活用することで、実稼働環境でのドリフトによるパフォーマンス低下の可能性について、モデルを監視するのに役立ちます。
DataRobotでのドリフトの追跡方法
DataRobotは2種類のドリフトを追跡します。
-
ターゲットドリフト:DataRobotは予測に関する統計情報を蓄積しているため、時間の経過と共にターゲットの分布と値がどのように変化するかを監視することができます。 ターゲット分布の比較の基準として、DataRobotではホールドアウトの予測値の分布を使用します。
-
特徴量ドリフト:DataRobotは予測に関する統計情報を蓄積しているため、時間の経過と共に特徴量の分布と値がどのように変化するかを監視することができます。 サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。 特徴量の分布を比較するためのベースラインとして:
-
500MBより大きいトレーニングデータセットでは、DataRobotはトレーニングデータのランダムサンプルの分布を使用します。
-
500MBより小さいトレーニングデータセットでは、DataRobotはトレーニングデータの100%の分布を使用します。
-
DataRobotでは特徴量を何個まで追跡できますか?
DataRobotでは、特徴量の追跡と受け取りに以下の制限が適用されます。
-
マネージドAIプラットフォーム(SaaS):デフォルトでは、DataRobotは最大25個の特徴量を追跡します。
-
セルフマネージドAIプラットフォーム ():デフォルトでは、DataRobotは最大25個の特徴量を追跡します。ただし、セルフマネージド環境では、DataRobotの設定で
PREDICTION_API_MONITOR_RAW_MAX_FEATUREを使用することで、上限を200個に引き上げることができます。 さらに、DataRobotが受け取れる特徴量の最大数はPREDICTION_API_POST_MAX_FEATURESを使用して設定され、DataRobotが受け取れる特徴量の絶対最大数は300です。_エージェントが監視するデプロイ_では、MLOPS_MAX_FEATURES_TO_MONITORを使用して300を超える特徴量を送信するようにエージェントを設定しても、300個の上限が適用されます。
ターゲットと特徴量のドリフト追跡はデフォルトで有効になっています。 これらのドリフト追跡機能を制御するには、デプロイの設定 > データドリフトタブに移動します。 特徴量ドリフト追跡がオフになっている場合、特徴量ドリフト追跡を有効にするようデータドリフトタブにメッセージが表示されます。
データドリフトステータスに関するEメール通知を受信するには、通知の設定、監視のスケジュール、データドリフト監視の設定を行います。
データドリフトダッシュボードのセクション¶
データドリフトダッシュボードには、デプロイされたモデルの正常性を指定の時間間隔で確認するのに役立つ、インタラクティブでエクスポート可能な表示内容が用意されています。
備考
エクスポートボタンをクリックして、PNG、CSV、またはZIPファイルとしてデータドリフトダッシュボードの各チャートをダウンロードします。
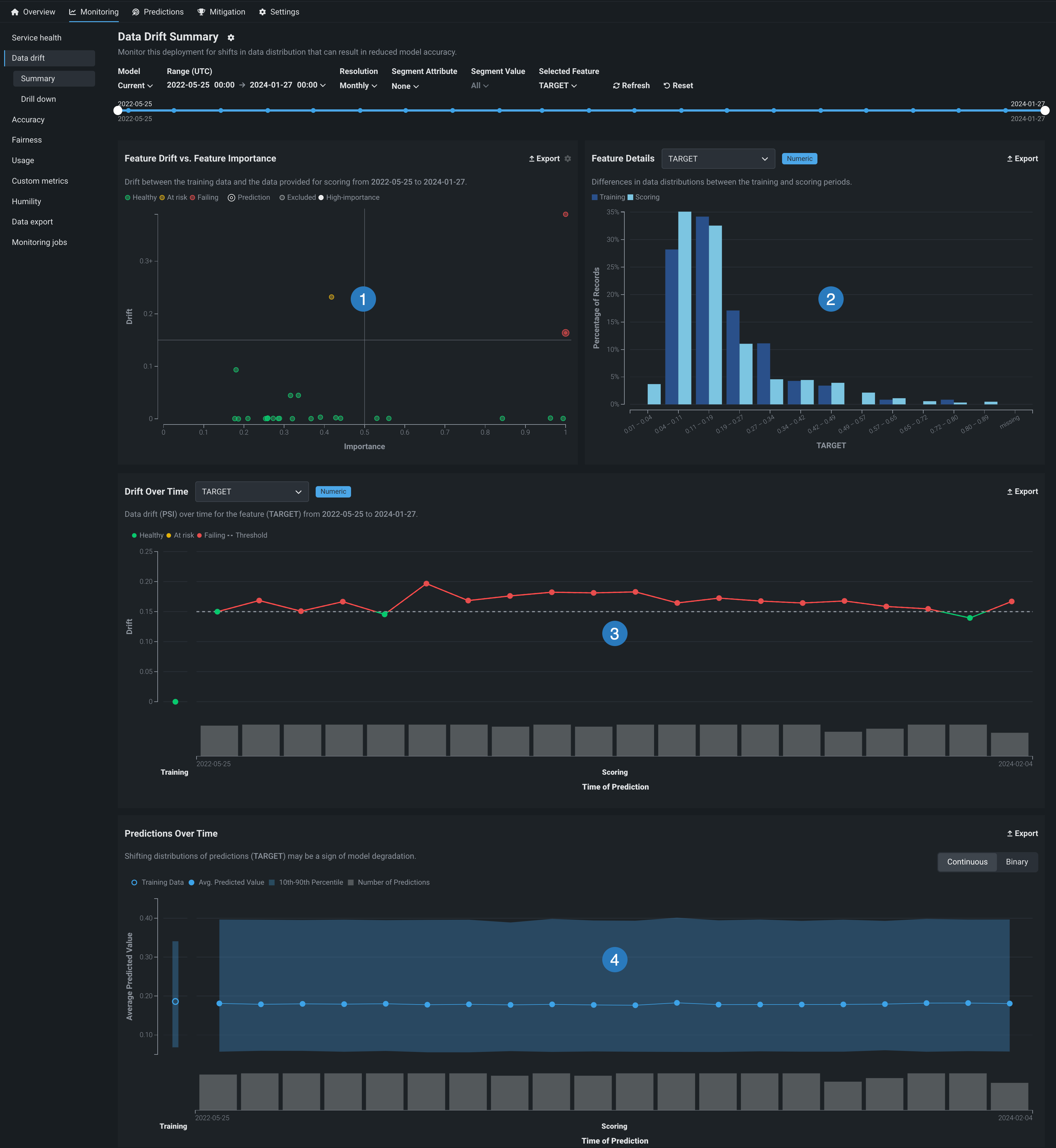
| チャート | 説明 | |
|---|---|---|
| 1 | ドリフトと有用性の比較 | ある時点から別の時点の特徴量値 の分布がどれだけ変化したかに対して、その特徴量のそのモデルでの有用性をプロットします。 |
| 2 | 特徴量の詳細 | トレーニングデータで選択された特徴量のレコードの予測データに対するパーセンテージ(分布)をプロットします。 |
| 3 | 時間経過に伴うドリフト | デプロイされたモデルのトレーニングデータセットと、本番環境での予測生成に使用されるデータセットの間の、時間経過に伴う分布の差異を示します。 このチャートは、データドリフトの指標であるPSI(Population Stability Index)の変化を追跡します。 |
| 4 | 時間経過に伴う予測 | 時間の経過に伴うモデルの予測の分布の変化(ターゲットドリフト)を示します。 この表示は、プロジェクトが連続値、二値分類、位置のどれであるかによって異なります。 |
位置特徴量およびプロジェクトでのドリフトの可視化¶
プレミアム機能
地理空間の監視はプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
地理空間特徴量の監視サポート
地理空間特徴量の監視は、二値分類、多クラス、連続値、位置のターゲットタイプでサポートされています。
DataRobotのLocation AI が地理空間特徴量を検出して取り込むと、H3インデックスとセグメント化された分析によって、地図がセルのグリッドに分割されます。 データドリフトタブでは、これらのセルによって、各位置セルにおける特徴量およびターゲットドリフトの変化を特定できるほか、トレーニングデータのベースライン計算とスコアリングデータにおけるサンプルサイズの違いも確認できます。 セグメント化された監視で使われる位置特徴量を含むデプロイでは、さらに以下のチャートにアクセスできます。
| チャート | 説明 | ターゲットタイプ |
|---|---|---|
| 位置ごとの指標チャート | デプロイされたモデルのトレーニングデータセットと、本番環境での予測生成に使用されるデータセットの間の、位置ごとの分布の差異を示し、データドリフトの指標である人口安定性指数(PSI)の変化を追跡します。 さらに、連続値デプロイの場合、このチャートは平均予測値を追跡します。 | 二値分類、多クラス、連続値(位置特徴量の場合) |
| 時間経過に伴う予測チャート | 位置モデルの予測が時間とともに変化していく様子を示します。 | 位置 |
| 位置ごとの予測値チャート | 位置モデルによって予測された位置と、予測された位置のセルに含まれるサンプルサイズを示します。 | 位置 |
ドリフトのドリルダウンの可視化¶
上記の視覚化に加えて、 データドリフト > ドリルダウンタブを使用して、ドリフト傾向を特定し、特徴量全体でのデータドリフトのヒートマップを比較することができます。
データドリフトダッシュボードを設定¶
設定 > データドリフトページでドリフトと有用性のしきい値および追加の定義を設定することで、デプロイでのデータドリフトステータスの計算方法をカスタマイズできます。 次のコントロールを使用して、必要に応じてデータドリフトダッシュボードを設定することもできます。

| コントロール | 説明 | |
|---|---|---|
| 1 | モデルバージョンセレクター | ドロップダウンで選択したモデルを反映するようにダッシュボード表示を更新します。 |
| 2 | 日付スライダー | ダッシュボードで表示するデータの範囲を制限します(特定の期間にズームインするなど)。 |
| 3 | 範囲セレクター(UTC) | デプロイ日付スライダーに表示する日付範囲を設定します。 範囲セレクターで選択できるのは、モデルのデプロイの現在のバージョンの開始日と現在の日付だけです。 |
| 4 | 単位セレクター | デプロイ日付スライダーの時間のきめ細かさを設定します。 選択した範囲に基づいて、次の時間単位が使用可能です。
|
| 5 | セグメント属性 / セグメント値 | セグメント分析で視覚化されるデータドリフトをフィルターするために、個々の属性と値を設定します。 |
| 6 | 選択した特徴量 | 特徴量詳細チャートと 時間経過に伴うドリフトチャートに表示される特徴量を設定します。 |
| 7 | 表示を更新 | 新しいデータを使用してダッシュボードのオンデマンド更新を開始します。 このボタンを使用しなくても、ダッシュボードは15分ごとに自動更新されます。 |
| 8 | リセット | ダッシュボードコントロールをデフォルト設定に戻します。 |
特徴量分析チャート¶
特徴量分析チャートは、選択した特徴量のデータ分布の詳細とともに、選択した期間中のトレーニングデータと予測データの間のドリフトを視覚化します。 サポートされている特徴量データ型は、数値、カテゴリー、およびテキストです。 ダッシュボードのこの領域には、次の視覚化を見ることができます。
特徴量分析チャートを見るには、2つのビューを切り替えることができます。
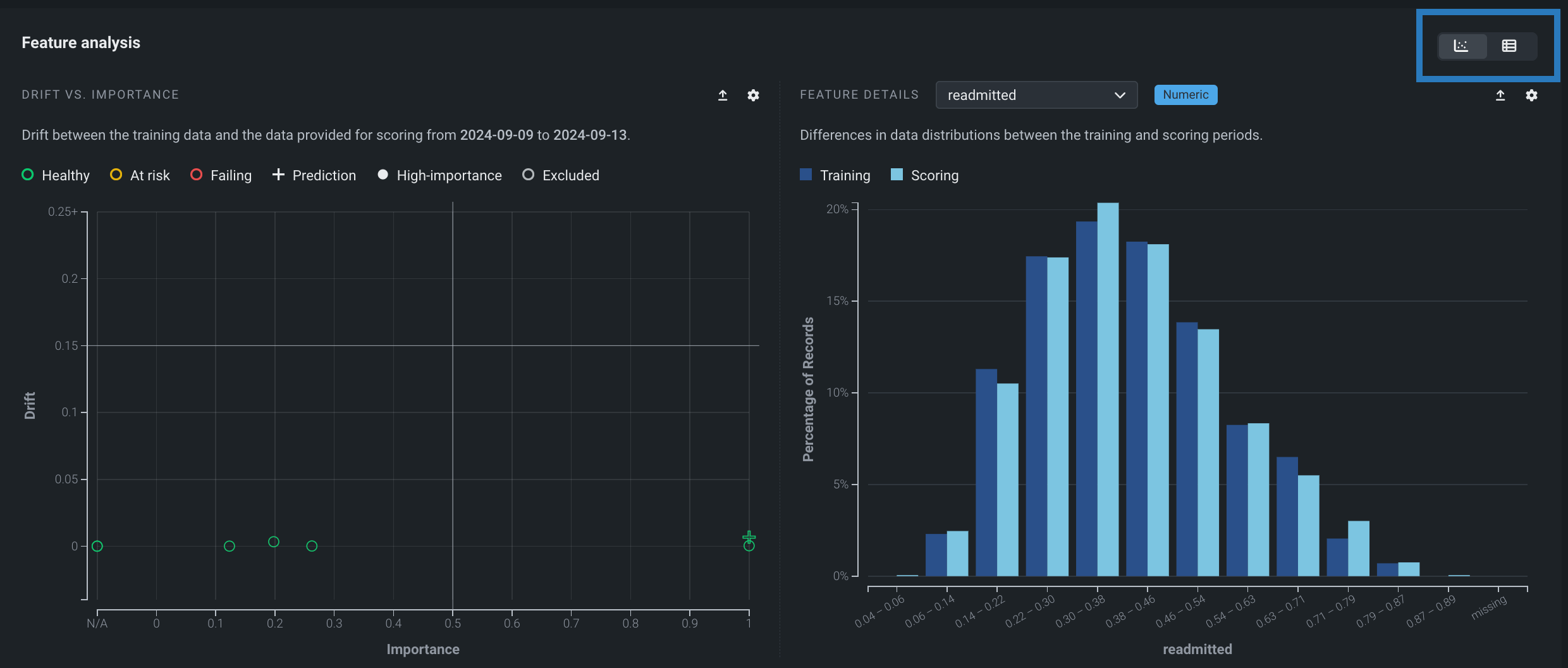
- :ドリフトと有用性の比較および特徴量の詳細チャートを並べて表示します。
- :統合された特徴量の分析テーブルを表示します。
特徴量のインパクトのない特徴量
特徴量を手動で選択すると、特徴量のインパクトスコアのない特徴量を選択した場合(特徴量の選択中に表示される特徴量の有用性スコアと混同しないでください)、これらの特徴量はN/Aが有用性スコアとして表示されます。
ドリフトと有用性の比較¶
特徴量ドリフトと特徴量の有用性の比較チャートでは、データ内で最もインパクトが高い25の数値特徴量、カテゴリー特徴量、およびテキストベース特徴量がモニターされます。 チャートを使用して、1つのポイントのデータが別のポイントのデータと異なるかどうかを確認します。 差異がある場合、モデルまたはデータ自体に問題がある可能性があります。 たとえば、自動車保険の契約者の年齢が時間の経過に伴って低くなる場合、元のモデルの構築に使用されたデータで新しいデータを正確に予測できなくなる可能性があります。 特に、有用性の高い特徴量のドリフトは、モデルの精度に関する注意を示している場合があります。
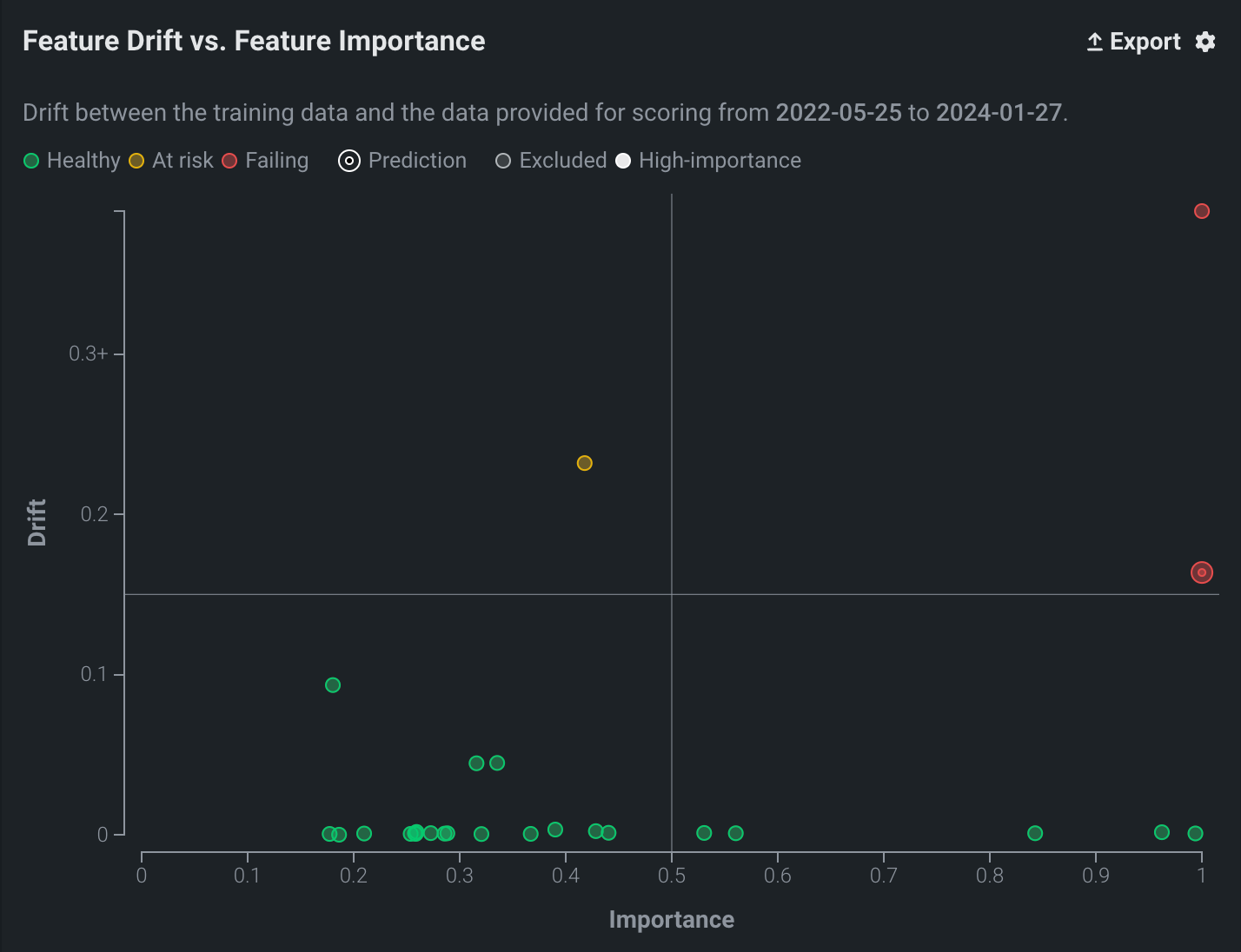
チャートのポイント上にカーソルを置くと、特徴量名が識別され、ドリフト(縦軸)と有用性(横軸)の精密な値が表示されます。 設定アイコン をクリックして、有用性とドリフトのしきい値を調整します。
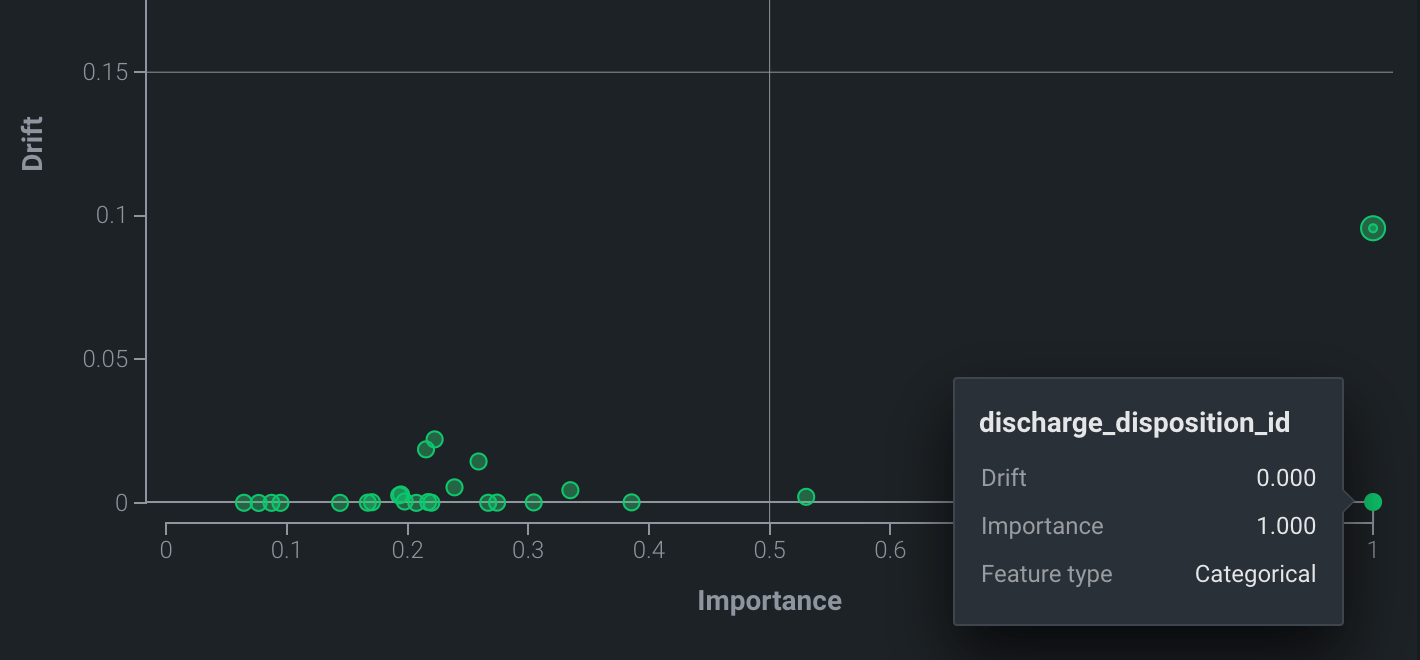
特徴量の詳細チャートと時間経過に伴うドリフトチャートで視覚化された特徴量を選択するには、特徴量ドリフトと特徴量の有用性プロットで、その特徴量のマーカーをクリックします。
特徴量ドリフト¶
Y軸は、特徴量のドリフト値を示します。 この値は、PSI(Population Stability Index)を計算したもので、時間経過に伴う分布の差異を示す指標です。
ドリフト指標のサポート
DataRobotのUIではPSI(Population Stability Index)指標のみがサポートされていますが、DataRobot APIでは、カルバックライブラー情報量、ヘリンガー距離、ヒストグラム交差(ヒストグラムに基づく非類似度)、およびイェンセンシャノン情報量もサポートされています。 さらに、Python APIクライアントを使用すると、 サポート対象の指標のリストを取得できます。
特徴量の有用性¶
X軸は、学習(トレーニング)データを取込むときに計算された特徴量の有用性スコアを示します。 DataRobotは、モデルタイプに応じてそれぞれ特徴量の有用性を計算します。 DataRobotモデルとカスタムモデルの場合、有用性スコアはPermutation Importanceを使用して計算されます。 外部モデルの場合、有用性スコアはACEスコアです。 1の有用性/インパクト値のドットはターゲット予測![]() を示します。 モデル内で有用性が最も高い特徴量も(緑色の点として)1の位置に表示されます。
を示します。 モデル内で有用性が最も高い特徴量も(緑色の点として)1の位置に表示されます。
4象限の解釈¶
チャートで表される4象限は、特徴量の有用性に対してプロットされた特徴量ごとのデータドリフトを視覚化するために役立ちます。 4象限は、大まかには以下のように解釈することができます。
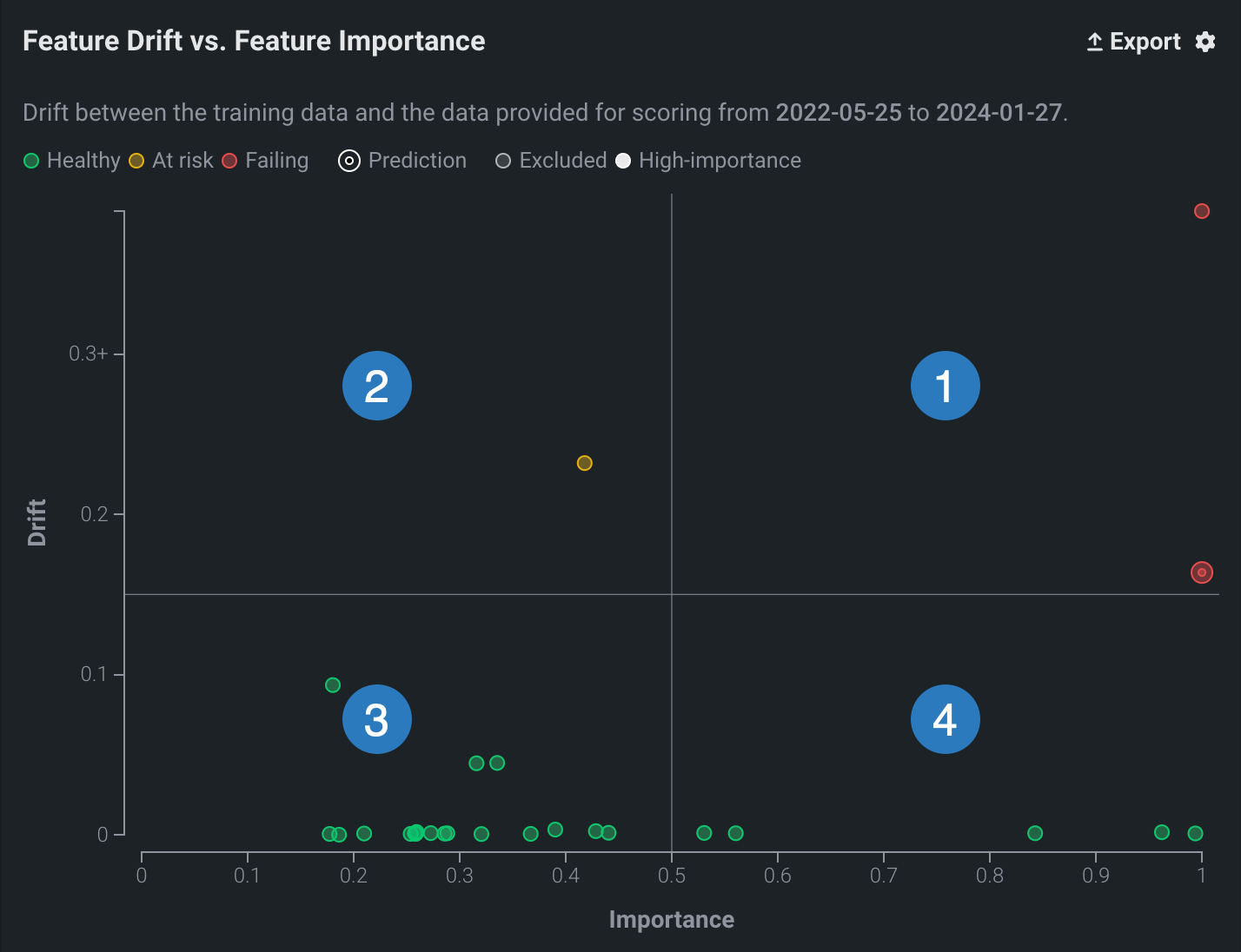
| 象限 | 解釈 | 色インジケーター |
|---|---|---|
| 1 | 高有用性の特徴量で高いドリフトが発生しています。 直ちに調査する必要があります。 | 赤 |
| 2 | 低有用性の特徴量で、設定されたしきい値を超えるドリフトが発生しています。 注意して監視する必要があります。 | 黄 |
| 3 | 低有用性の特徴量で最小のドリフトが発生しています。 必要なアクションはありません。 | 緑 |
| 4 | 高有用性の特徴量で小さなドリフトが発生しています。 必要なアクションはありませんが、しきい値に近づく特徴量は監視する必要があります。 | 緑 |
備考
チャート上のポイントは灰色または白のどちらにもできます。 灰色の円はドリフトステータスの計算から除外された特徴量を表し、白い円は有用性の高い特徴量を表します。
プロジェクトの所有者は、チャートの右上にある設定アイコン をクリックして4分割をリセットできます。 デフォルトでは、ドリフトしきい値のデフォルト値は0.15です。縦軸の範囲は、0から0.25および観測されたドリフト値の最高値までです。 これらの四分円は、ドリフトおよび有用性のしきい値を変更することによりカスタマイズできます。
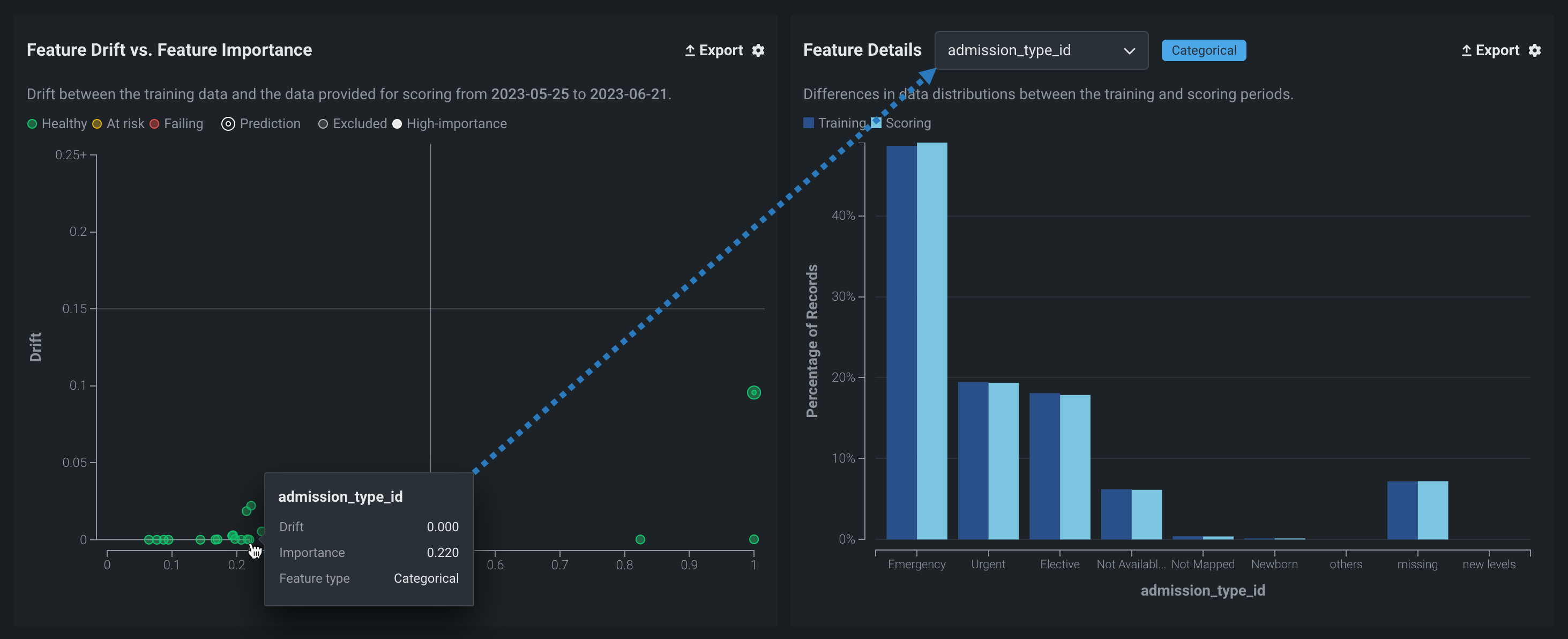
特徴量の詳細チャート¶
特徴量の詳細チャートは、トレーニングデータ内で選択された特徴量の分布と予測データ内のその特徴量の分布を比較するヒストグラムを提供します。 「特徴量の詳細チャート」を使用するには、ドロップダウンから特徴量を選択します。 デフォルトでターゲット特徴量に設定されるリストには、追跡されたすべての特徴量が含まれます。
ヒント
特徴量の詳細チャートの特徴量を選択するには、特徴量ドリフトと特徴量の有用性チャートの特徴量マーカーをクリックして特徴量を選択するか、または、データドリフトサマリーコントロールで選択された特徴量を設定することもできます。
数値特徴量¶
数値データの場合、DataRobotは各特徴量の分布の効率的かつ正確な近似を計算します。 これをもとに、トレーニングデータの正規化されたヒストグラムを、選択したドリフト指標を使用したスコアリングデータと比較することで、ドリフト追跡を行います。
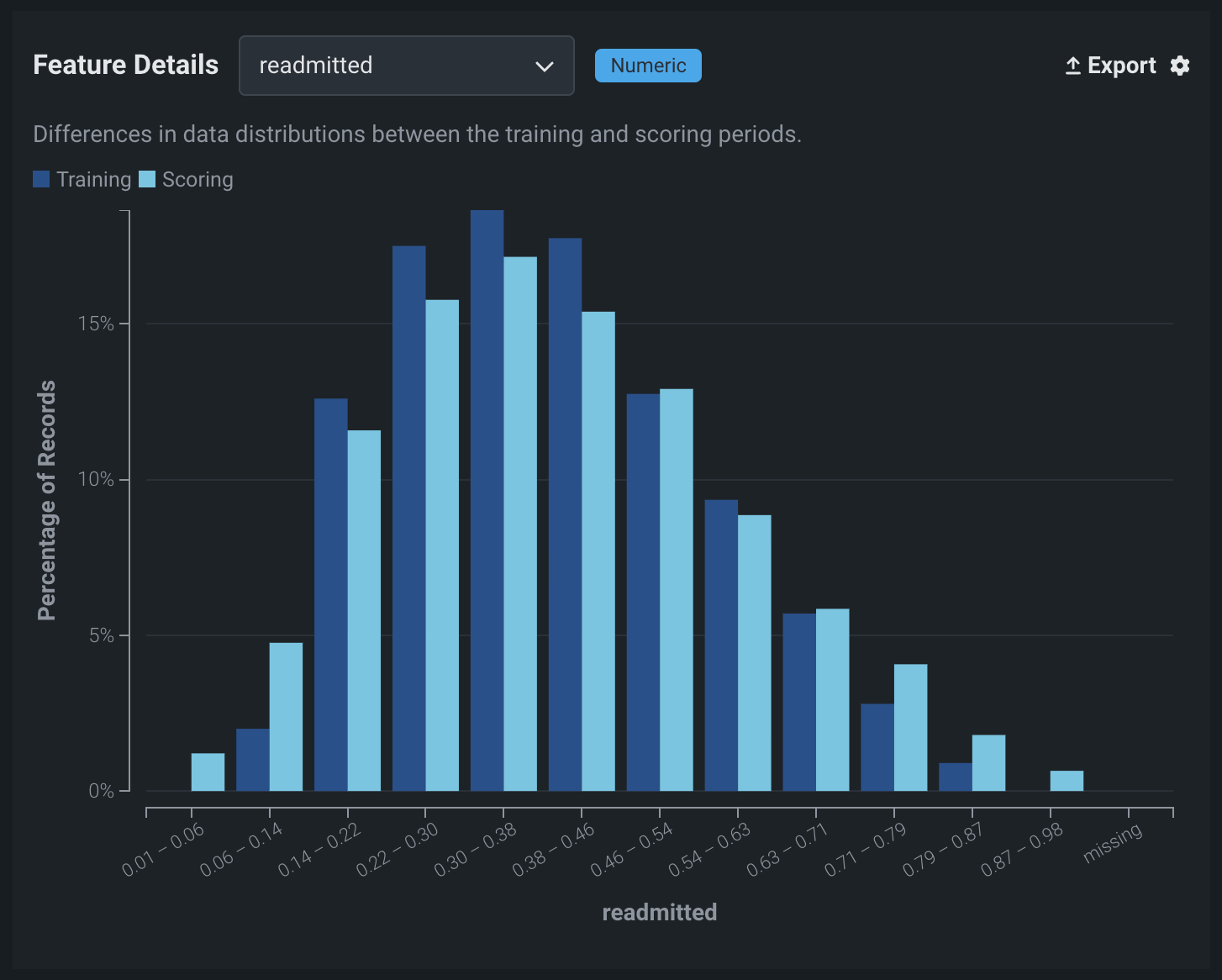
チャートには、数値特徴量の13個のビンが表示されます。
-
10個のビンは、トレーニングデータで観測されたアイテムの範囲をキャプチャします。
-
2つのビンは、非常に高い値と非常に低い値(トレーニングデータの範囲外にあるスコアリングデータの極端な値)を取得します。 たとえば、高い値と低い値のビンを定義するために、値はトレーニングデータの範囲である
min_trainingおよびmax_trainingと比較されます。 低い値のビンにはmin_trainingの範囲を下回る値が含まれ、高い値のビンにはmax_trainingの範囲を上回る値が含まれます。 -
欠損数のための1つのビン。これには、特徴量値が欠落しているすべてのレコードが含まれます。
ヒストグラムのビンには、どのように値が追加されますか?
データドリフトタブでは、Ben-Haim/Tom-Tov Centroidヒストグラムが使われます。
カテゴリー特徴量¶
ヒストグラムのビニングのカットオフがデータ依存の計算から生じる数値データとは異なり、カテゴリーデータは本質的に形式が離散的である(つまり連続的ではない)ため、ビニングは定義されたカテゴリーに基づきます。 さらに、スコアリングデータにカテゴリーレベルが欠落しているか、表示されていない可能性があります。
カテゴリー特徴量のドリフト追跡のプロセスは、トレーニングデータの各カテゴリーレベル(「ビン」)の行の割合を計算することです。 これにより、各レベルのパーセンテージのベクトルが得られます。 最も頻度の高い25のレベルが直接追跡されます—他のすべてのレベルは、その他ビンに集約されます。 このプロセスはスコアリングデータに対して繰り返され、選択したドリフト指標を使用して2つのベクトルが比較されます。
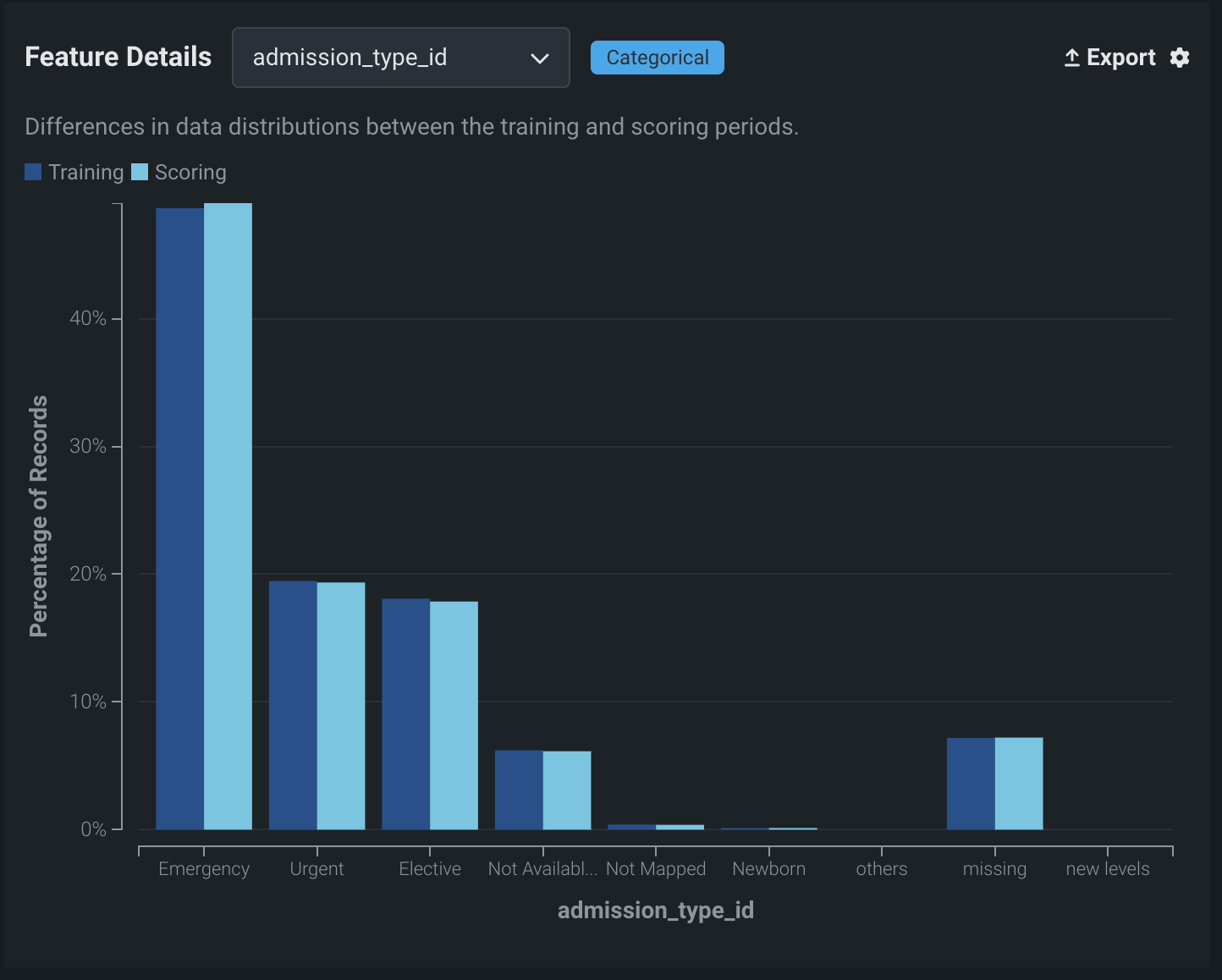
カテゴリー特徴量の場合、チャートには、上位カテゴリーと欠損カテゴリーのビンに加えて、独自のビンが2つ含まれます。
-
その他のビンには、最も頻繁に出現する25個の値以外のすべてのカテゴリー特徴量が含まれます。 この集計は、ドリフト追跡の目的で実行されますが、モデルの動作を表すものではありません。
-
新規レベルビンは、トレーニングデータに含まれない特徴量の新しい値を含むデータで予測を作成した後に表示されます。 たとえば、分類特徴量
Cityのある住宅価格に関するデータセットを例に考えてみます。 予測データに含まれている値Bostonがトレーニングデータに含まれていなかった場合、Bostonという値(およびその他の非表示の都市)は新規レベルビンに表示されます。
テキスト特徴量¶
テキスト特徴量はカーディナリティの高い問題です。つまり、新しい単語を追加しても、たとえばカテゴリーデータで見られるような新しいレベルの影響はありません。 DataRobotが採用している、テキスト特徴量のドリフト追跡を行う方法では、文章は主観的かつ文化的であり、スペルミスがある可能性を考慮しています。 つまり、テキストフィールドのドリフトを識別するには、個々の単語ではなく、言語全体のシフトを識別することがより重要です。
テキスト特徴量のドリフト追跡は、次の方法で実行されます。
- トレーニングデータで見つかった行から最も頻繁に使用される1000個の単語の出現を検出します。
- その特徴量に対して、トレーニングデータとスコアリングデータで別々に、これらの用語を含む行の割合を計算します。
- スコアリングデータの割合をトレーニングデータの割合と比較します。
出現率の2つのベクトル(単語ごとに1エントリ)が、使用可能なドリフト指標と比較されます。 この方法を適用する前に、DataRobotは、テキスト特徴量を単語(日本語や中国語の場合は文字)に分割する基本的なトークン化を行ってます。
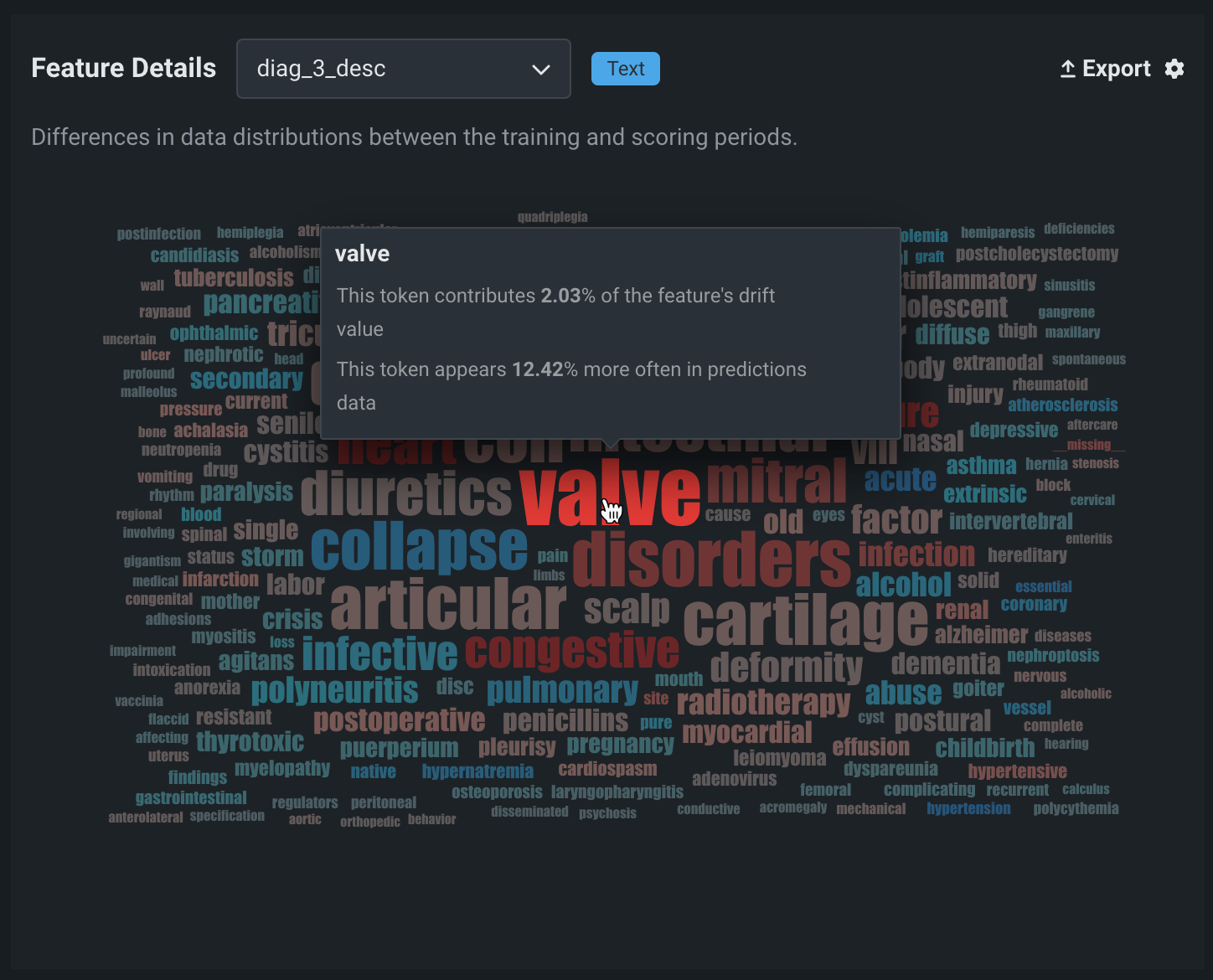
テキスト特徴量については、「特徴量の詳細」の棒グラフがワードクラウドに置き換わりました。これにより、データ分布がトークンごとに可視化され、個々のトークンが特徴量のデータドリフトにどれだけ関与しているかが明らかになります。 特徴量ドリフトワードクラウドにアクセスするには、特徴量の詳細チャートで、ドロップダウンリストからテキスト特徴量を選択します。 データドリフトダッシュボードコントロールで、選択された特徴量ドロップダウンリストからテキスト特徴量を選択することもできます。 テキスト特徴量の特徴量ドリフトのワードクラウドを解釈するには、トークンの上にポインターを置くと、以下の詳細が表示されます。
ヒント
ポインターがワードクラウド上にあるとき、上にスクロールするとズームインして、より小さいトークンのテキストを表示できます。
| チャートの要素 | 説明 |
|---|---|
| トークン | トークン化されたテキスト。 テキストサイズはトークンのドリフト貢献度を表し、テキストの色はデータセットの普及率を表します。 このチャートではストップワードは非表示になります。 |
| ドリフト貢献度 | この特定のトークンが、 特徴量ドリフト対特徴量の有用性および 時間経過に伴うドリフトチャートで報告されている、特徴量のドリフト値にどれだけ貢献しているかを示します。 |
| ターゲット分布 | この特定のトークンがトレーニングデータまたは予測データに表示される頻度がどれだけ増加するか。
|
ワードクラウドビューを無効にする
エクスポートボタンの横にある設定アイコン をクリックして、テキスト特徴量をワードクラウドとして表示チェックボックスをオフにすると、特徴量ドリフトのワードクラウドを無効にして標準チャートを表示できます。
特徴量分析テーブル¶
特徴量の分析セクションがテーブルビュー の場合、特徴量の有用性、ドリフト、ステータス、型、特徴量の詳細がまとめて表示されます。
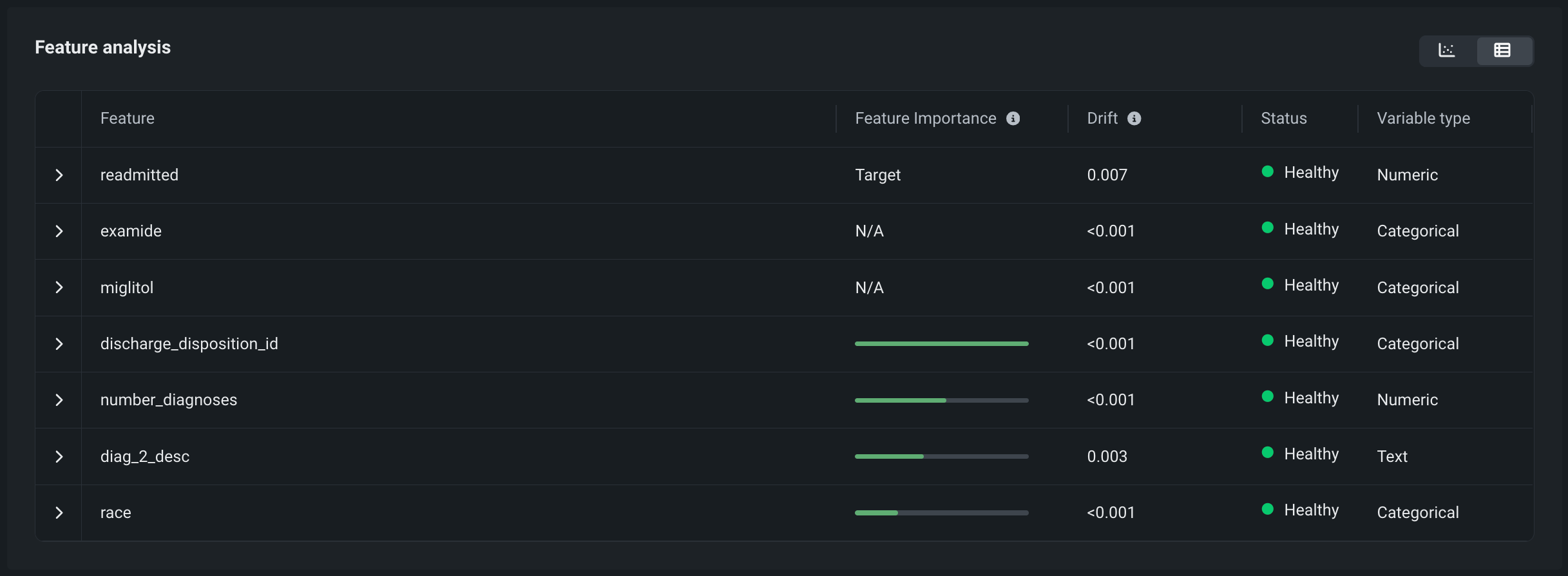
特徴量のインパクトのない特徴量
特徴量を手動で選択すると、特徴量のインパクトスコアのない特徴量を選択した場合(特徴量の選択中に表示される特徴量の有用性スコアと混同しないでください)、これらの特徴量はN/Aが有用性スコアとして表示されます。
特定の特徴量の行をクリックすると、選択した特徴量の詳細チャートが表示されます。
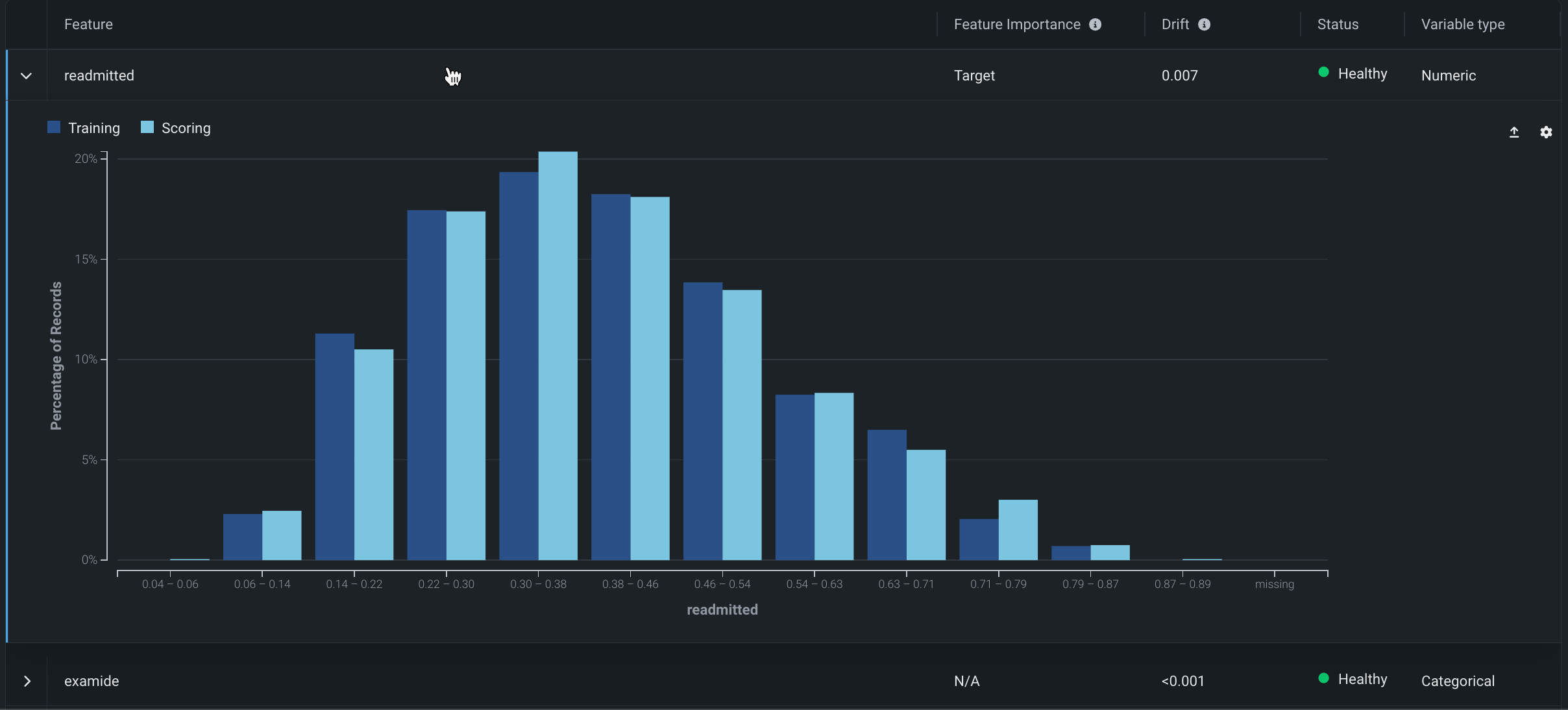
ここで表示されるチャートは、デフォルトのビューの 特徴量の詳細チャートと同様に機能します。
時間経過に伴うドリフトチャート¶
時間経過に伴うドリフトチャートでは、デプロイされたモデルのトレーニングデータセットと、本番環境での予測生成に使用されるデータセットの間の、時間経過に伴う分布の差異が視覚化されます。 トレーニングデータセットで確立されたベースラインからのドリフトは、PSI(Population Stability Index)を用いて測定されます。 モデルが新しいデータで予測を続けると、追跡対象の特徴量ごとにPSIの経時変化が視覚化されるので、データドリフトの傾向を把握することができます。
データドリフトはモデルの予測能力を低下させる可能性があるため、ある特徴量がいつドリフトし始めたかを見極め、(モデルが新しいデータで予測を続ける中で)そのドリフトがどのように変化するかを監視することは、問題の深刻度を推測するのに役立ちます。 これにより、デプロイ内の特徴量間でデータドリフトの傾向を比較し、特定の特徴量間で相関するドリフト傾向を特定することができます。 さらに、このチャートによって季節的な影響(時間認識モデルでは重要)を特定することができます。 この情報は、データ品質の問題、特徴量構成の変化、ターゲット特徴量のコンテキストの変化など、デプロイされたモデルでのデータドリフトの原因を特定するのに役立ちます。 以下の例では、PSIが時間の経過とともに一貫して増加しており、選択した特徴量のデータドリフトが悪化していることを示しています。
時間経過に伴うドリフトチャートには、次の要素とコントロールが含まれています。
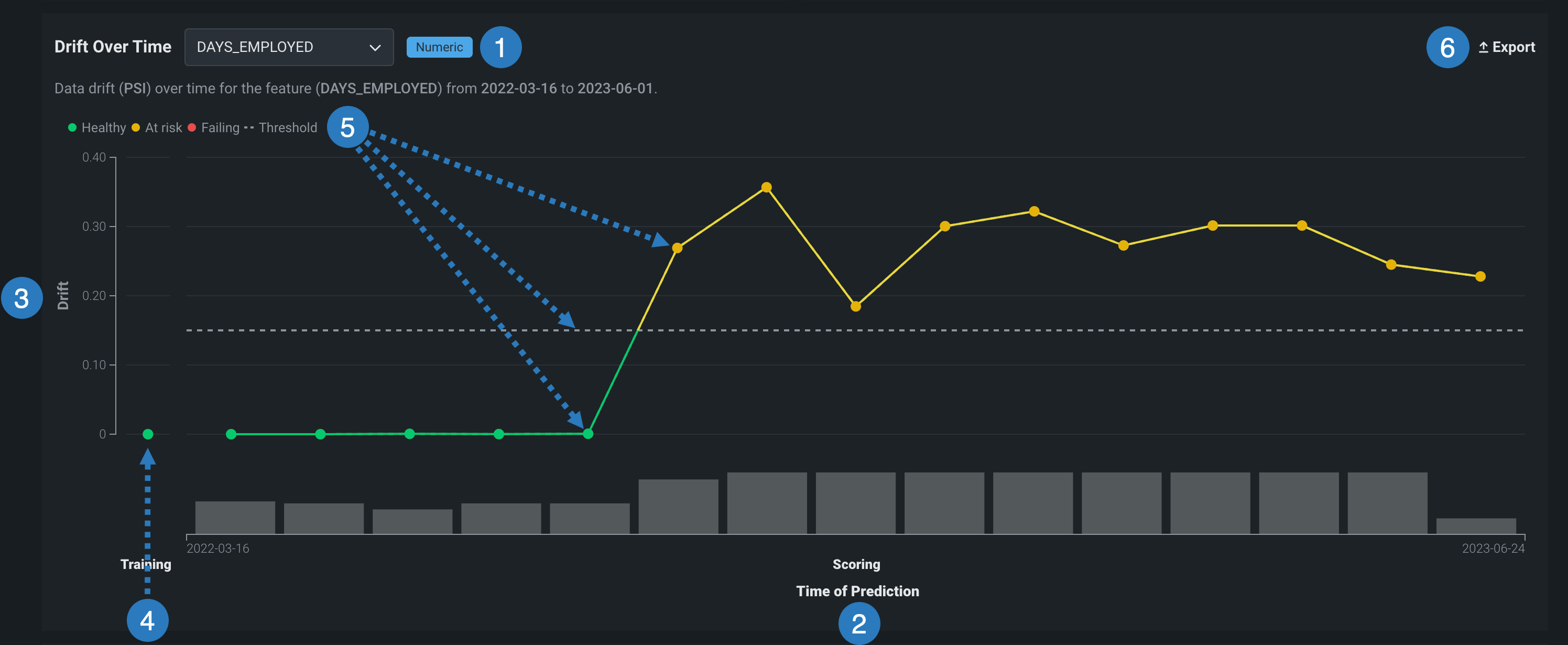
| チャートの要素 | 説明 | |
|---|---|---|
| 1 | 選択した特徴量 | 時間経過に伴うドリフト分析の特徴量を選択します。これは、時間経過に伴うドリフトチャートと 特徴量の詳細チャートで報告されます。 |
| 2 | 予測の時間/サンプルサイズ (X軸) |
対応するドリフト値(PSI)の計算に使用する予測の時間範囲を表します。 X軸の下にある棒グラフは、対応する予測時間中に行われた予測の数を表します。 時系列デプロイでの予測時間の表現方法の詳細については、時系列デプロイの予測時間を参照してください。 |
| 3 | ドリフト (Y軸) |
対応予測時間に対して計算されたドリフト値(PSI)の範囲を表します。 |
| 4 | トレーニングのベースライン | トレーニングベースラインデータセットの0 PSI値を表します。 |
| 5 | ドリフトステータス情報 | 選択した特徴量のドリフトステータスとしきい値情報を表示します。 ドリフトステータスの視覚化は、 デプロイオーナーによって設定された監視設定に基づいています。 デプロイオーナーは、 特徴量ドリフトと特徴量の有用性チャートの比較設定でドリフトと有用性が高いしきい値を設定することもできます。 考えられるドリフトステータスの分類は次のとおりです。
|
| 6 | エクスポート | 時間経過に伴うドリフトチャートをエクスポートします。 |
時系列デプロイでの予測の時間
時系列デプロイのデフォルトの予測タイムスタンプ方法は、予測リクエストの時刻ではなく、予測日(つまり、予測ポイント+予測距離)です。 予測日では、トレーニングデータとデータドリフトおよび精度統計の基準との間で共通の時間軸を使用できます。 たとえば、予測日を使用して、予測データの日付が6月1日から6月10日で、予測ポイントが6月10日に設定され、予測距離が+1 - + 7日に設定されている場合、6月11日~17日の予測値を入手でき、データドリフトもこの期間追跡されます。
モデルをデプロイする際に、以下の予測スタンプオプションから選択できます。
- 日付/時刻特徴量の値を使用:デフォルト。 予測データと共に特徴量として提供される日時(例:予測日)を使用して、タイムスタンプを決定します。
- 予測リクエストの時刻を使用:予測リクエストを送信した日時を使用して、タイムスタンプを決定します。
時間経過に伴うドリフトチャートの追加情報を表示するには、チャート内のマーカーにカーソルを合わせると、予測時間、PSI、サンプルサイズが表示されます。
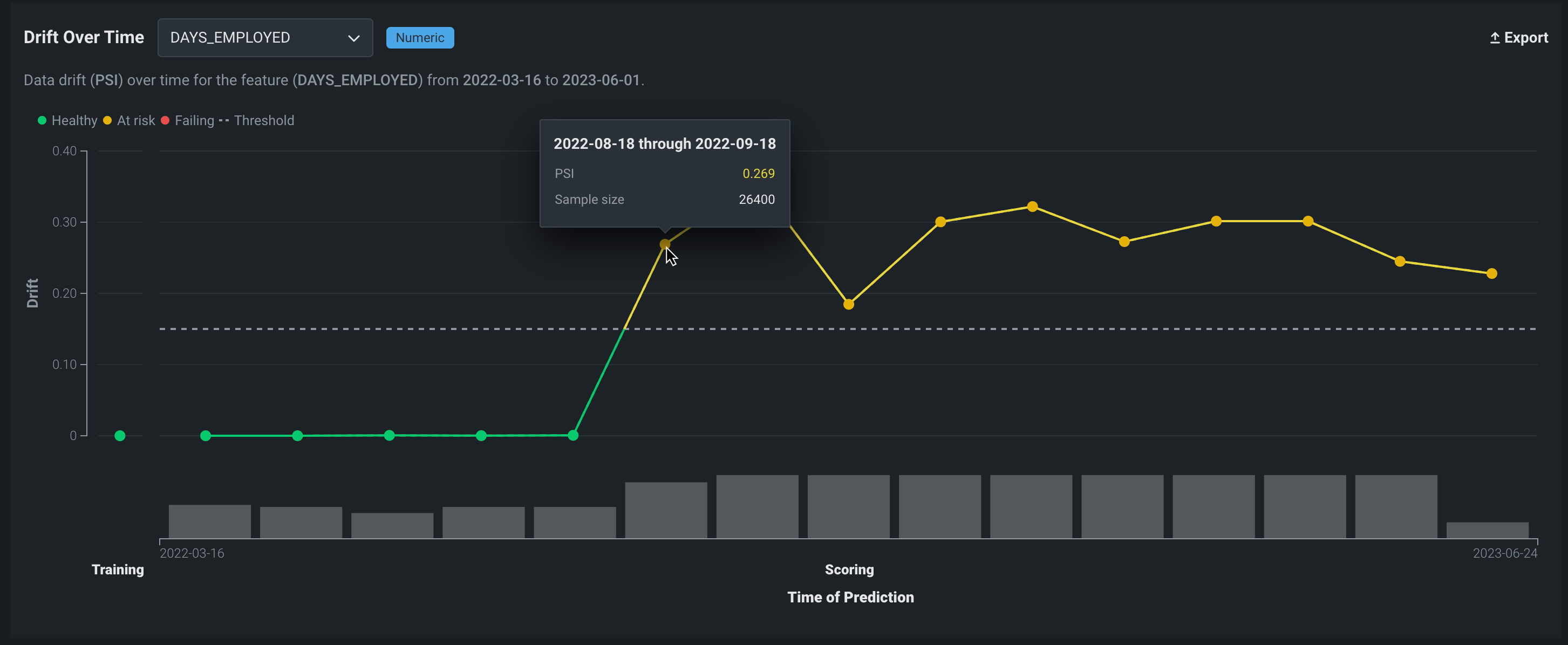
経時ドリフトと経時予測の比較
時間経過に伴うドリフトチャートのX軸は、下の時系列の予測チャートのX軸と一致しており、2つのチャートを簡単に比較できます。 さらに、時間経過に伴うドリフトチャートのサンプルサイズデータは、時系列予測チャートの予測数データに相当します。
時間経過に伴う予測チャート¶
時間経過に伴う予測チャートでは、時間の経過に伴ってモデルの予測がどのように変化したかを一目で把握できます。 例:
Daveは、彼のモデルが過去1か月間について、以前よりも明らかに頻繁に
1(再入院すると)予測されているようだと思っています。彼は対応する再入院の真の分布の変化がわからないので、モデルの精度が低下しているのではないかと疑っています。この情報を基に、Daveは再トレーニングが必要がどうかを調査します。
二値分類のチャートと連続値のチャートは若干異なりますが、得られるものは同じです—プロットは時間の経過に伴って、比較的安定しているでしょうか? 安定していない場合、異常値が生じるビジネス上の理由があるかどうか(暴風雨が発生、など)を確認する必要があります。 ビニングされた期間のポイントが異常に高いあるいは低い場合は下のヒストグラムをチェックして、その期間の予測が十分にあって統計的に信頼できるデータポイントなのかどうかを確認します。
予測の時間
予測の時間の値は、データドリフトタブと精度タブ、およびサービスの正常性タブで異なります。
-
[サービスの正常性]タブの「予測リクエストの日時」は、常に予測サーバーが予測リクエストを受信した日時です。 この予測リクエストの追跡方法は、診断目的で予測サービスの正常性を正確に示しています。
-
データドリフトタブと精度タブについてデフォルトで、「予測リクエストの時間」は、予測リクエストを送信した時刻になります。これは、 予測履歴とサービスの正常性設定で、予測タイムスタンプでオーバーライドできます。
さらに、両方のチャートには横軸にトレーニングおよびスコアリングのラベルがあります。 トレーニングラベルは、モデルのトレーニングデータのホールドアウトセットで作成された予測の分布を示すチャートのセクションを示します。 チャート上には常に1つのポイントがあります。 スコアリングラベルは、デプロイ済みモデルで作成された予測の分布を示すチャートのセクションを示します。 スコアリングは、予測を作成するためにモデルが使用中であることを示します。 チャートには、時間の経過に伴う予測分布の変化を示す複数のポイントがあります。
連続値プロジェクトの場合¶
連続値プロジェクトの時間経過に伴う予測チャートには、トレーニングデータと予測データの両方の平均予測値に加えて、予測値の中央から±80%の範囲を表す視覚的インジケーターもプロットされます。 チャートのポイント上にカーソルを置くと、その詳細が表示されます。
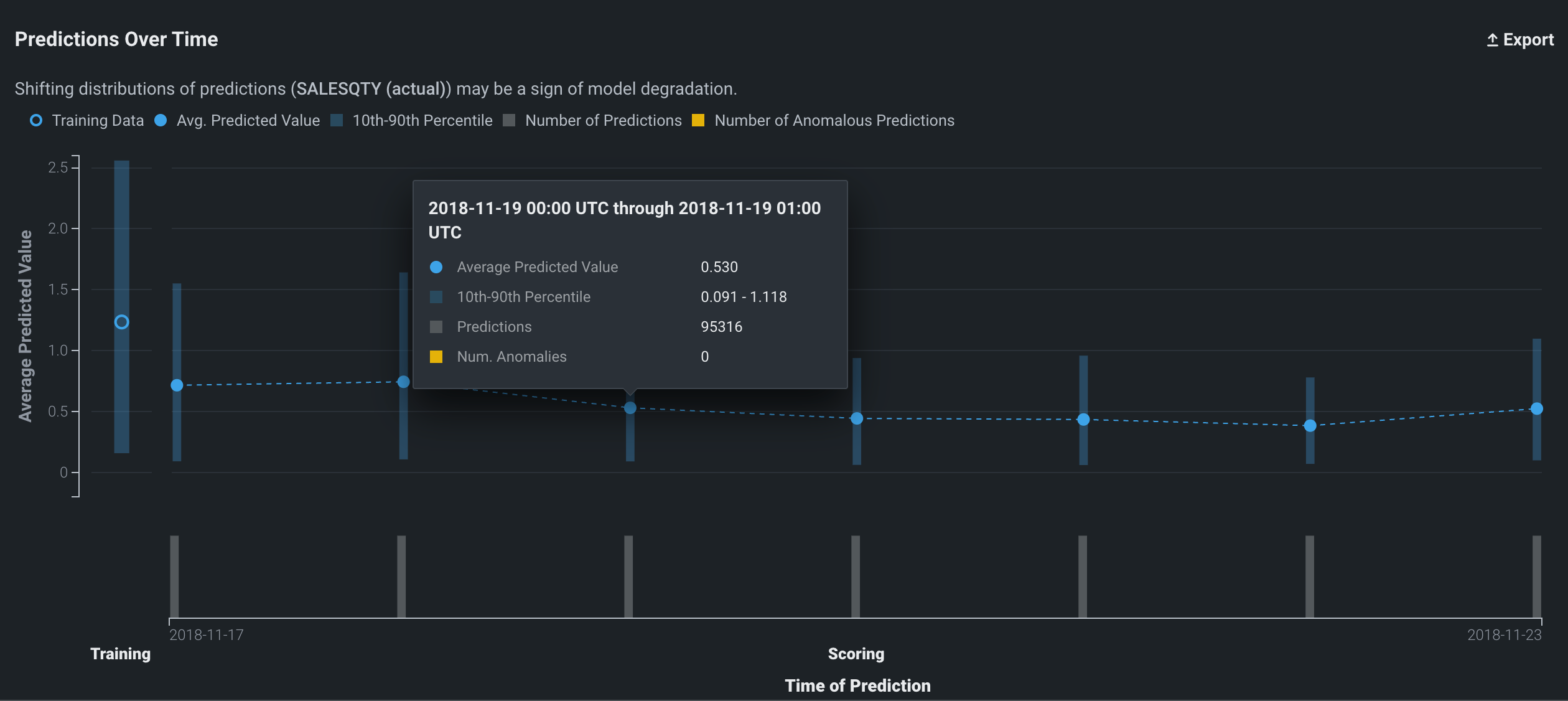
| フィールド | 説明 |
|---|---|
| 日付 | ビンデータの開始日。 表示される値は、この日付からグラフの次のポイントまでの数に基づいています。 たとえば、ポイントAの日付が01-07で、ポイントBの日付が01-14の場合、ポイントAは01-07から01-13までのすべてをカバーします(01-07と01-13を含む)。 |
| 平均予測値 | ビンに含まれるすべてのポイントの値の平均。 |
| 10~90パーセンタイル | その期間の予測のパーセンタイル。 |
| 予測 | ビンに含まれる予測の数。 異常なデータが疑われる場合、この値をその他のポイントと比較します。 |
| 数字 異常 | デプロイの予測警告を有効にした場合、棒グラフの黄色いセクションは、ある時点の異常な予測を表します。 特定の期間の異常な予測の数を表示するには、棒グラフのフラグ付き予測に対応するプロット上のポイントにカーソルを合わせます。 予測警告は連続値モデルデプロイにのみ使用できます。 |
トレーニングデータの詳細
トレーニングデータをアップロードすると、グラフには10番目~90番目のパーセンタイルとターゲットの平均値の両方が表示されます()。 ターゲットの平均値に関するこの情報は、トレーニングデータのポイント上にマウスを置いて表示することもできます。
予測警告の連携¶
予測警告を利用できるモデル
予測警告は連続値モデルを使用するデプロイにのみ使用できます。 この特徴量は分類または時系列モデルに対応していません。
デプロイの予測警告を有効にすると、時間経過に伴う予測棒グラフで、警告をトリガーする異常な予測値にフラグが設定されます。 棒グラフの黄色のセクションは、ある時点における異常な予測を表しています。
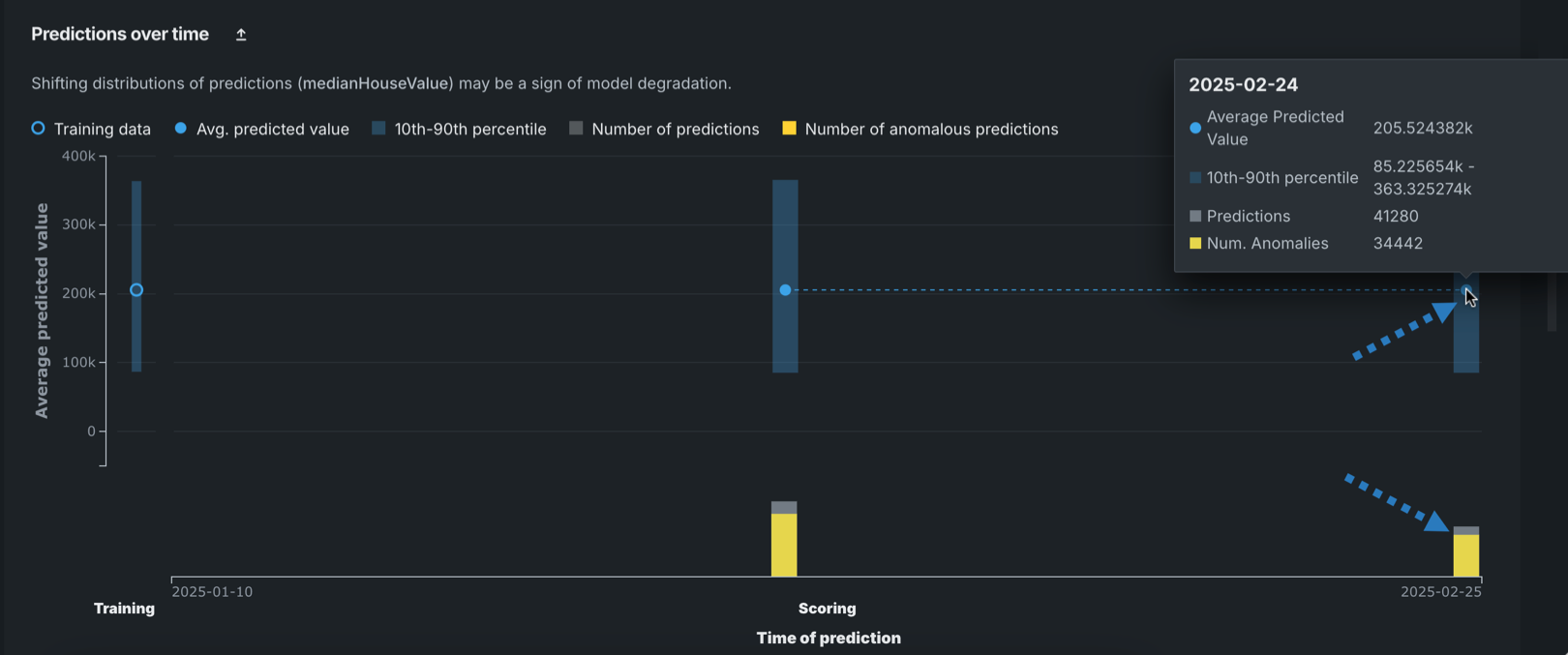
特定の期間の異常な予測の数を表示するには、棒グラフのフラグ付き予測に対応するプロット上のポイントにカーソルを合わせます。
二値分類プロジェクトの場合¶
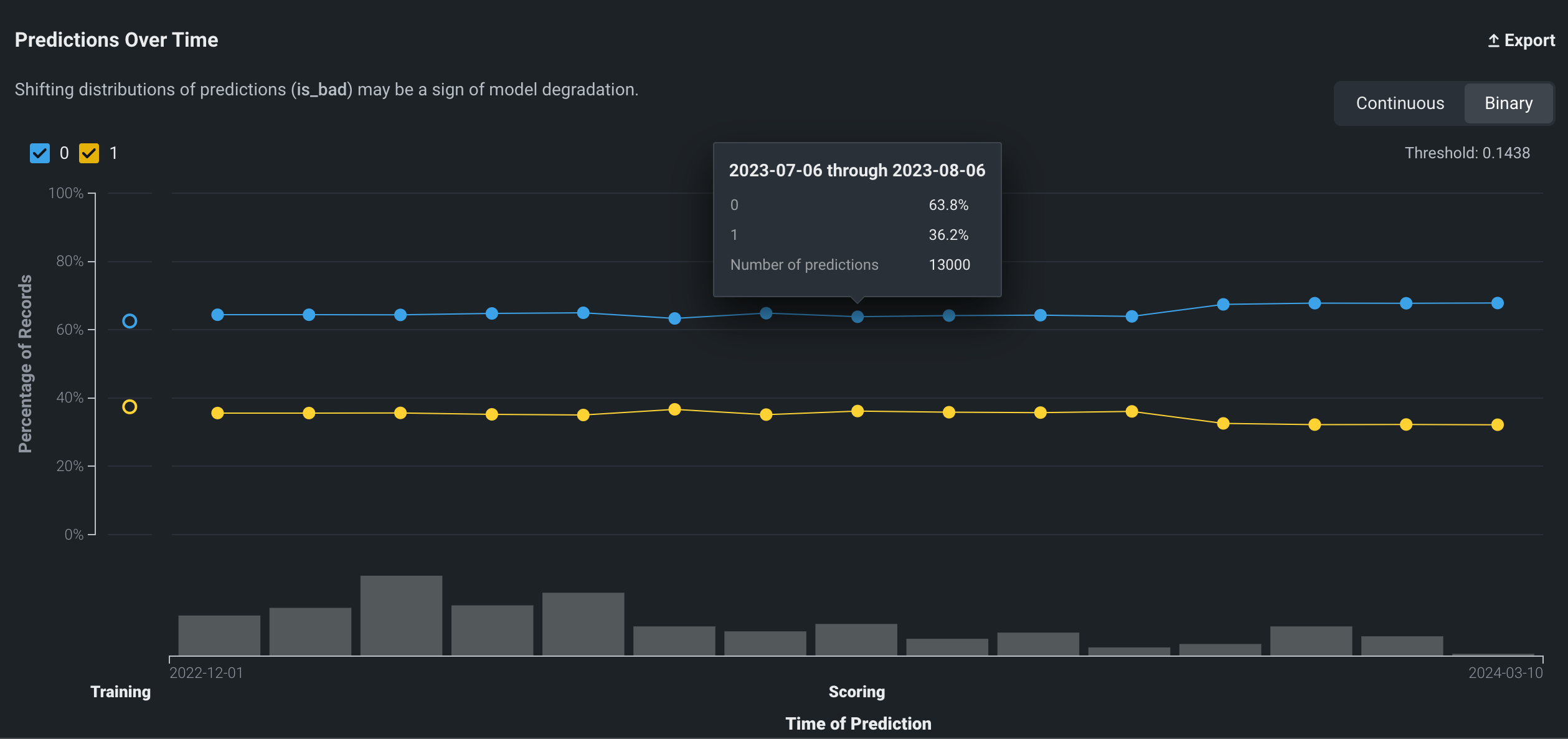
二値分類プロジェクトの時間経過に伴う予測チャートは、デプロイを追加したときに設定したラベルに基づいて、クラスのパーセンテージをプロットします(この例では0と1)。 データポイントにカーソルを合わせると、特定の値が表示されます。
時間経過に伴う予測は、連続モードと二値モードでデータを表示できます。
連続モードでは、予測しきい値を考慮せずに、Positiveクラス予測を0と1の間の確率として示します。
連続モードでは、以下の詳細を使用できます。
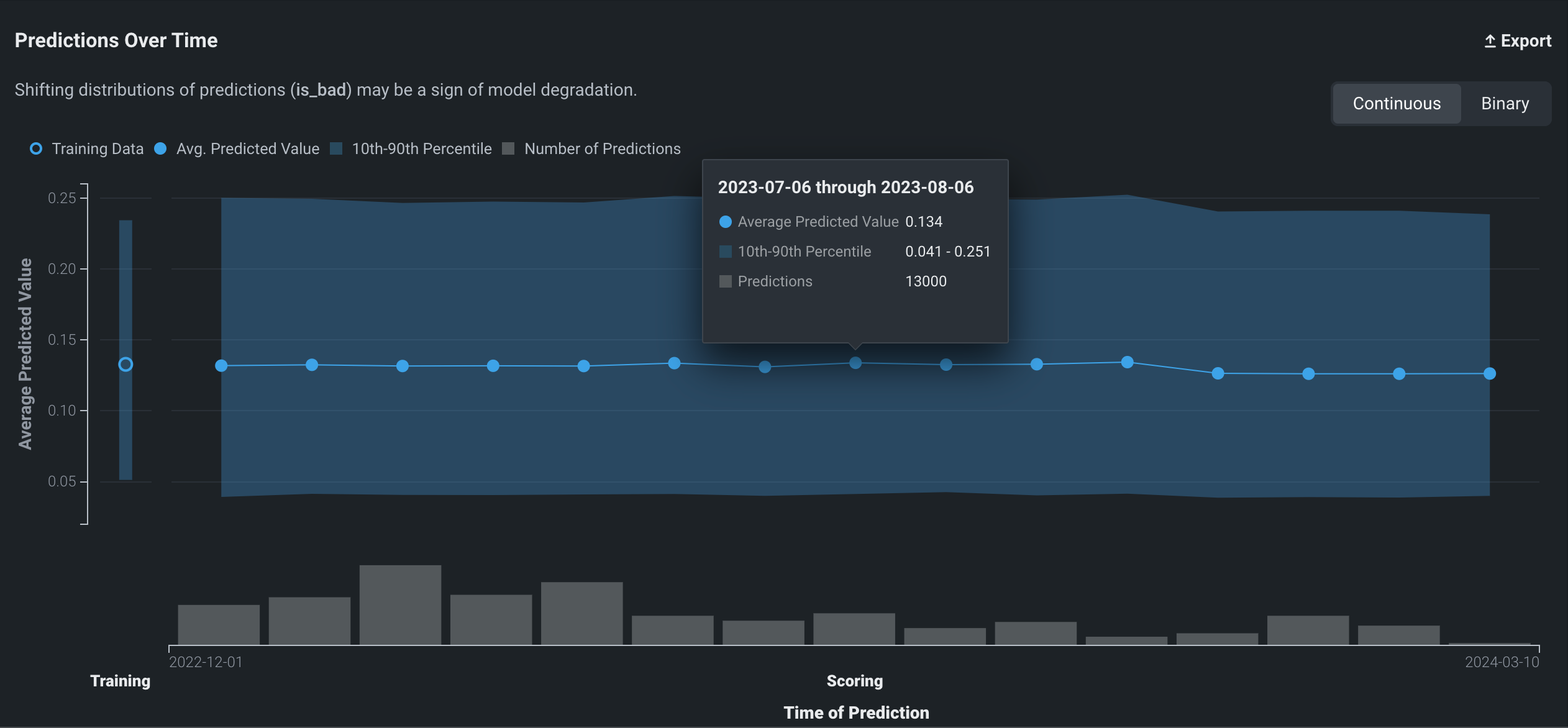
| フィールド | 説明 |
|---|---|
| 日付 | ビンデータの開始日。 表示される値は、この日付からグラフの次のポイントまでの数に基づいています。 たとえば、ポイントAの日付が01-07で、ポイントBの日付が01-14の場合、ポイントAは01-07から01-13までのすべてをカバーします(01-07と01-13を含む)。 |
| 平均予測値 | ビンに含まれるすべてのポイントの値の平均。 |
| 10~90パーセンタイル | その期間の予測のパーセンタイル。 |
| 予測 | ビンに含まれる予測の数。 異常なデータが疑われる場合、この値をその他のポイントと比較します。 |
トレーニングデータの詳細
トレーニングデータをアップロードすると、グラフには10番目~90番目のパーセンタイルとターゲットの平均値の両方が表示されます()。 ターゲットの平均値に関するこの情報は、トレーニングデータのポイント上にマウスを置いて表示することもできます。
二値モードでは、予測しきい値が考慮に入れられ、作成されたすべての予測の各クラスのパーセンテージが示されます。
二値モードの分類モデルの時間経過に伴う予測チャートでは、以下の追加要素を使用できます。
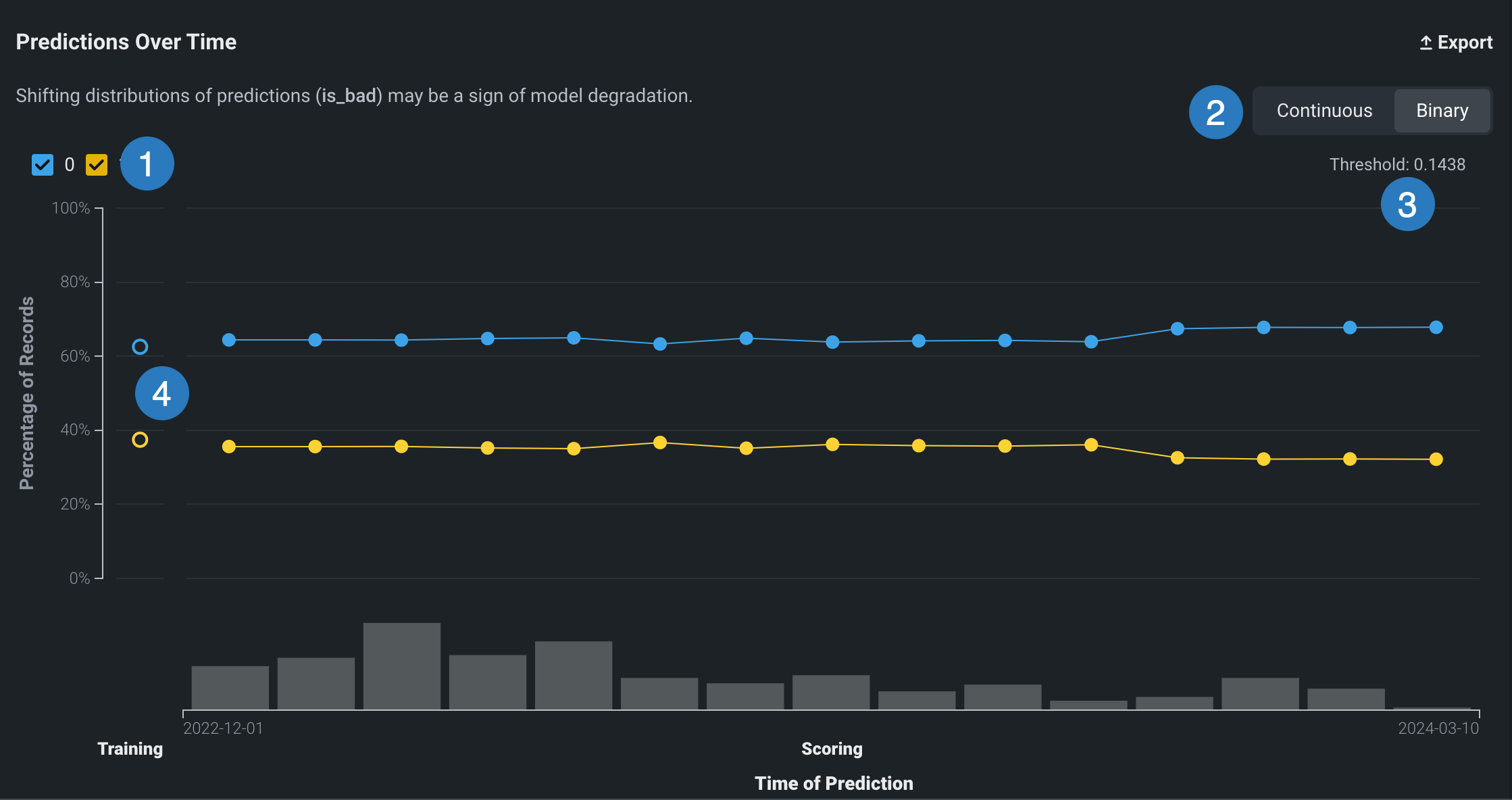
| 要素 | 説明 |
|---|---|
| 1 | 時間経過に伴う予測チャートのクラスラベルのデータを表示または非表示にします。 |
| 2 | 二値分類デプロイの時間経過に伴う予測チャートで、連続モードと二値モードを切り替えます。 チャートのポイント上にカーソルを置くと、その詳細が表示されます。 |
| 3 | 予測の出力結果に対して設定されたしきい値を表示します。 しきい値はデプロイをインベントリに追加したときに設定され、変更することはできません。 |
| 4 | トレーニングデータのターゲットの平均値を表示します( と )。 |
二値モードでは、以下の詳細を使用できます。
| フィールド | 説明 |
|---|---|
| 日付 | ビンデータの開始日。 表示される値は、この日付からグラフの次のポイントまでの数に基づいています。 たとえば、ポイントAの日付が01-07で、ポイントBの日付が01-14の場合、ポイントAは01-07から01-13までのすべてをカバーします(01-07と01-13を含む)。 |
| クラスラベル1 | ビンに含まれるすべてのポイントに対する「Positive」クラスのポイントのパーセンテージ(この例では0)。 |
| クラスラベル2 | ビンに含まれるすべてのポイントに対する「Negative」クラスのポイントのパーセンテージ(この例では1)。 |
| 予測の数 | ビンに含まれる予測の数。 異常なデータが疑われる場合、この値をその他のポイントと比較します。 |
位置データのドリフトチャート¶
プレミアム機能
地理空間の監視はプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
地理空間特徴量の監視サポート
地理空間特徴量の監視は、二値分類、多クラス、連続値、位置のターゲットタイプでサポートされています。
DataRobotの Location AIが地理空間特徴量を検出して取り込むと、 H3インデックスと セグメント化された分析を使用して、世界がセルのグリッドに分割されます。 データドリフトタブでは、H3セルが「位置ごとの指標」分析の基礎となり、各位置セルにおける特徴量およびターゲットドリフトの変化を特定できるほか、トレーニングデータのベースライン計算とスコアリングデータにおけるサンプルサイズの違いも確認できます。
デプロイの地理空間監視の有効化¶
トレーニングデータセット内の位置データを使用して構築し、デプロイした二値分類、連続値、多クラス、または位置モデルでは、DataRobotのLocation AIを活用して、デプロイでの地理空間の監視ができます。 プロイで地理空間分析を有効にするには、セグメント化された分析を有効化し、位置データの取込み中に生成される位置特徴量geometryのセグメントを定義します。 このgeometryセグメントには、世界を H3セル(通常は六角形のセル)のグリッドに分割する際に使われる識別子が含まれています。
位置セグメントの定義
地理空間の監視に必要なH3セル識別子を含む列を指定する場合、セグメント値としてgeometryを使用する必要はありません。 セグメント値として提供される列には、必要な識別子が含まれている限り、任意の名前を付けることができます(下記参照)。 位置ターゲットタイプのカスタムモデルまたは外部モデルの場合、 位置セグメントDataRobot-Geo-Targetが自動的に作成されます。ただし、デプロイでは引き続きセグメント化された分析を有効にする必要があります。
Location AIは、以下のネイティブの地理空間データ形式の取込みをサポートしています。
- ESRIシェープファイル
- GeoJSON
- ESRIファイルジオデータベース
- Well Known Text(テーブルの列に埋め込み)
- PostGISデータベース
Location AIは、ネイティブの地理空間データの取込みに加えて、データセットの列がlatitudeやlongitudeという名前で、次の形式の値が含まれている場合、位置変数を認識することで、非地理空間形式内の位置データを自動的に検出できます。
- 小数度
- 度分秒
- -46° 37′ 59.988″ および -23° 33′
- 46.63333W および 23.55S
- 46*37′59.98"W および 23*33′S
- W 46D 37m 59.988s および S 23D 33m
Location AIが位置特徴量を認識すると、位置データは H3インデックスを使用して集計され、各位置がセルにグループ化されます。 セルは、16進数形式で記述された64ビットの整数で表されます(852a3067fffffffなど)。 その結果、多くの場合、近接する位置は同じセルにグループ化されます。 これらの16進値はgeometry特徴量に保存されます。
生成されるセルのサイズは、 解像度パラメーターによって決まり、解像度の値が大きいほど、生成されるセルの数が多くなります。 解像度は、トレーニングデータのベースライン生成中に計算され、デプロイの監視で使用するために保存されます。
予測を行う場合、各予測行には、他の予測行とともに、必要な位置情報が含まれているようにします。
位置ごとの指標チャート¶
位置ごとの指標の監視サポート
位置ごとの指標は、二値分類、多クラス、連続値のターゲットタイプで表示できます。
位置ごとの指標チャートにアクセスするには、位置ごとのドリフト分析向けに設定されたデプロイで、位置ごとをクリックして、時間経過に伴うドリフトチャートを位置ごとの精度チャートに切り替えます。

位置ごとのドリフトチャートに表示される指標を設定するには、指標: メニューをクリックし、以下のいずれかのオプションを選択します。
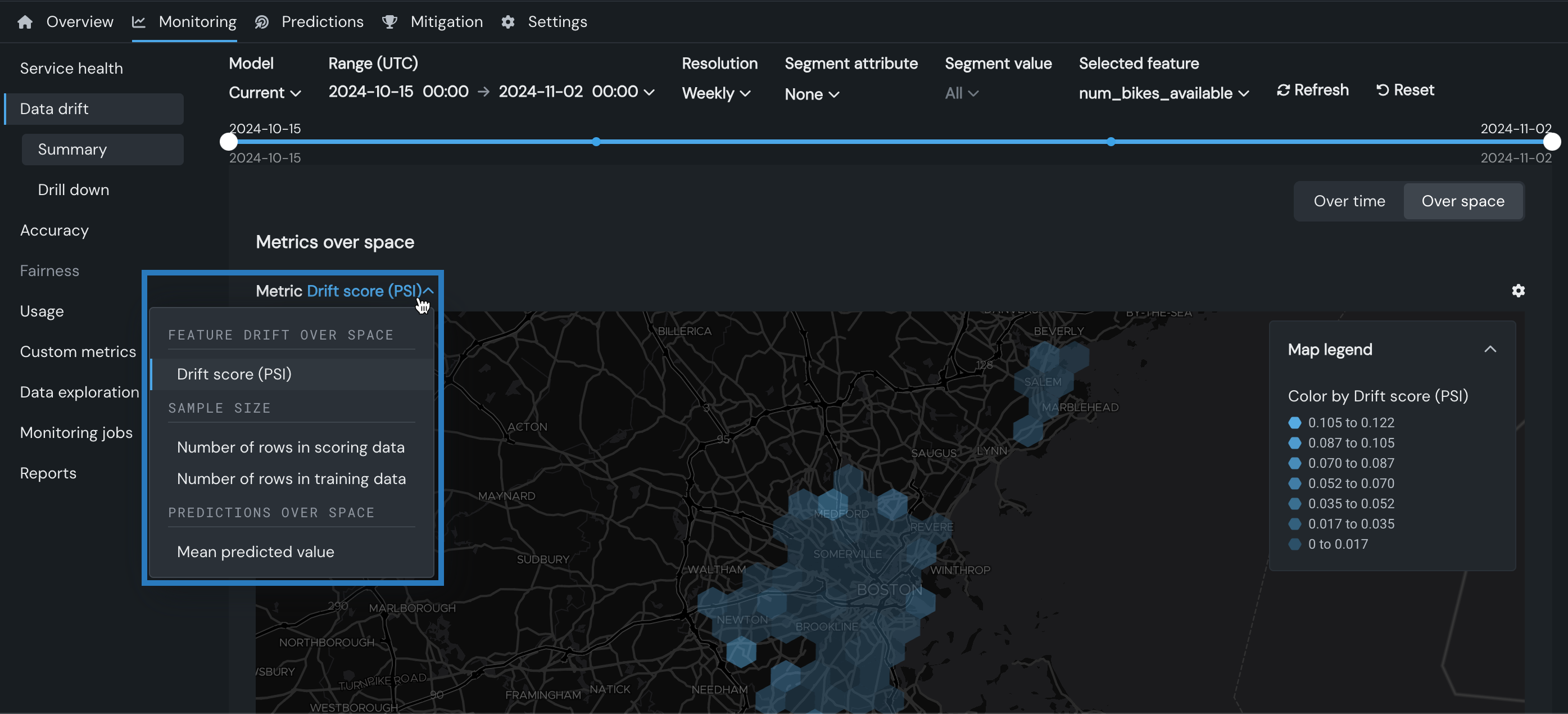
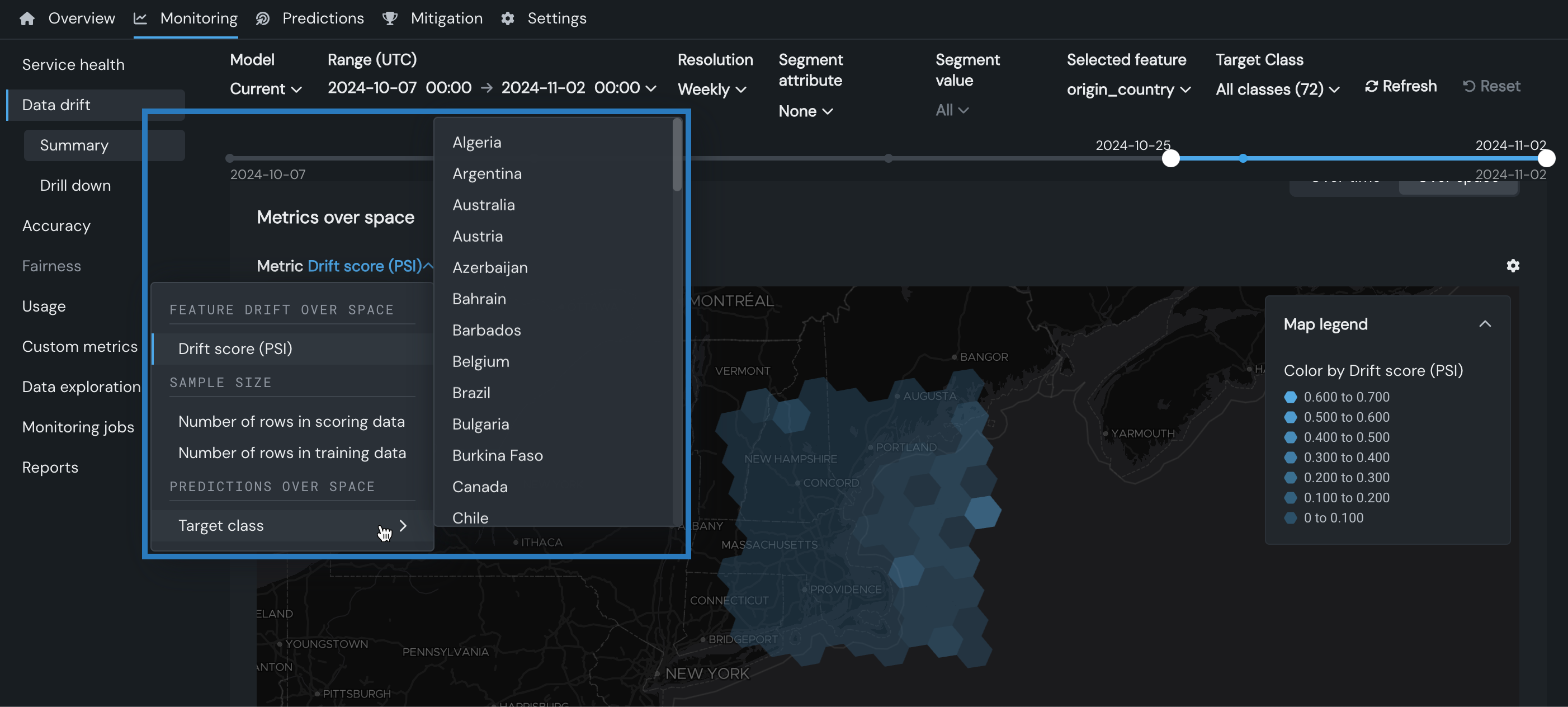
| 指標 | 説明 |
|---|---|
| 位置ごとの特徴量ドリフト | |
| ドリフトスコア(PSI) | セルにグループ化された予測に対して計算された 個体群安定性指数(PSI) PSIは、トレーニングデータと予測データの間の時間の経過に伴うデータ分布の違いを示す指標です。 |
| サンプルサイズ | |
| スコアリングデータの行数 | スコアリングデータセットのセルに含まれるサンプルサイズ |
| トレーニングデータの行数 | トレーニングベースラインの生成に使用されるトレーニングデータセットのセルに含まれるサンプルサイズ |
| 位置ごとの予測値 | |
| 平均予測値 | 連続値デプロイの場合、セルの平均予測値 |
| ターゲットクラス | 二値および多クラスデプロイの場合、選択したターゲットクラスのドリフト |
位置に関する時間経過に伴う予測チャート¶
時間経過に伴う予測の監視サポート
時間経過に伴う予測の可視化は、位置ターゲットタイプで可能です。
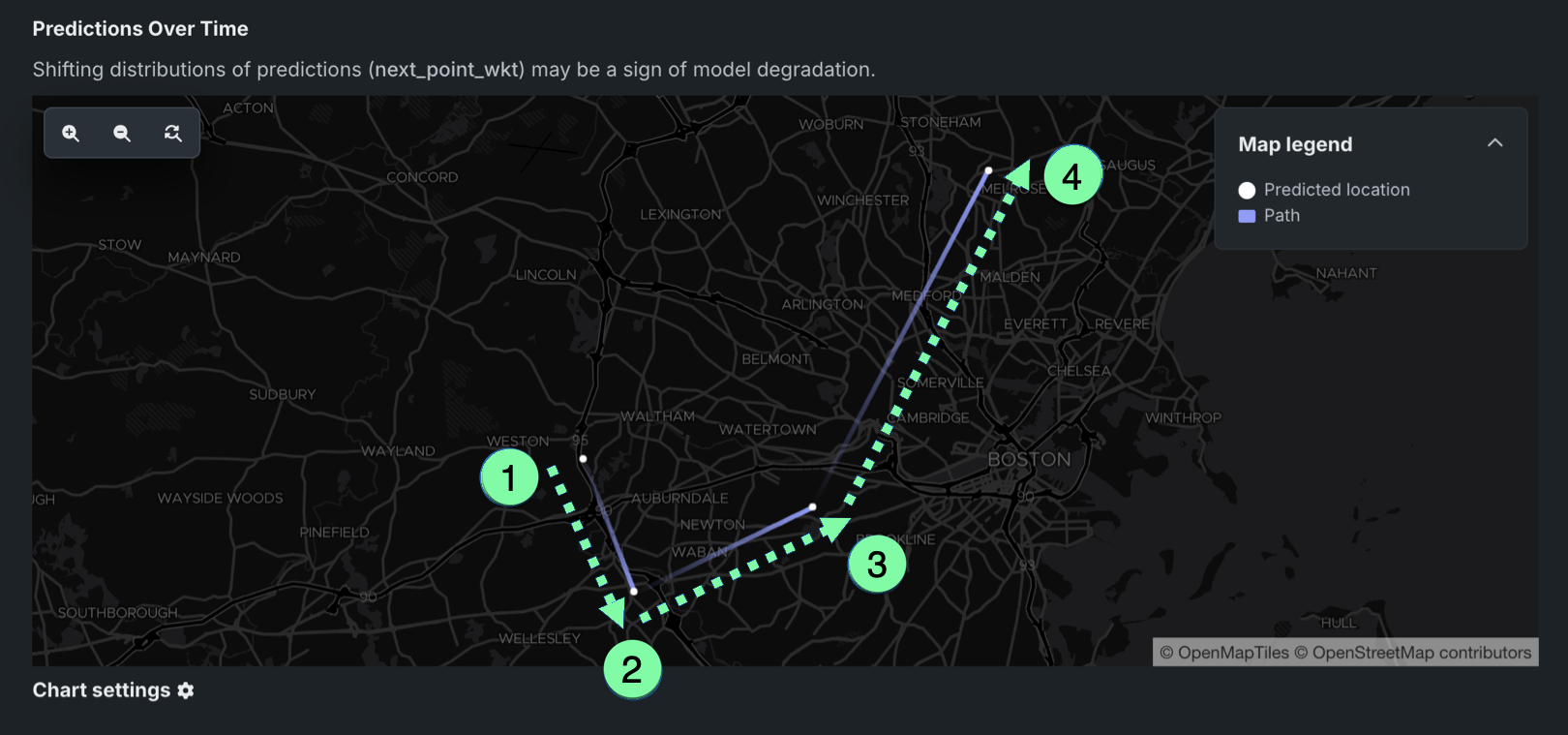
位置ターゲットタイプのデプロイでは、時間経過タブで、位置プロジェクトに固有の時間経過に伴う予測チャートを表示できます。 このチャートは、予測された位置とパスを表示し、予測位置の経時変化を追跡します。 それぞれの予測位置は、時間範囲内のすべての予測における平均値を表します。
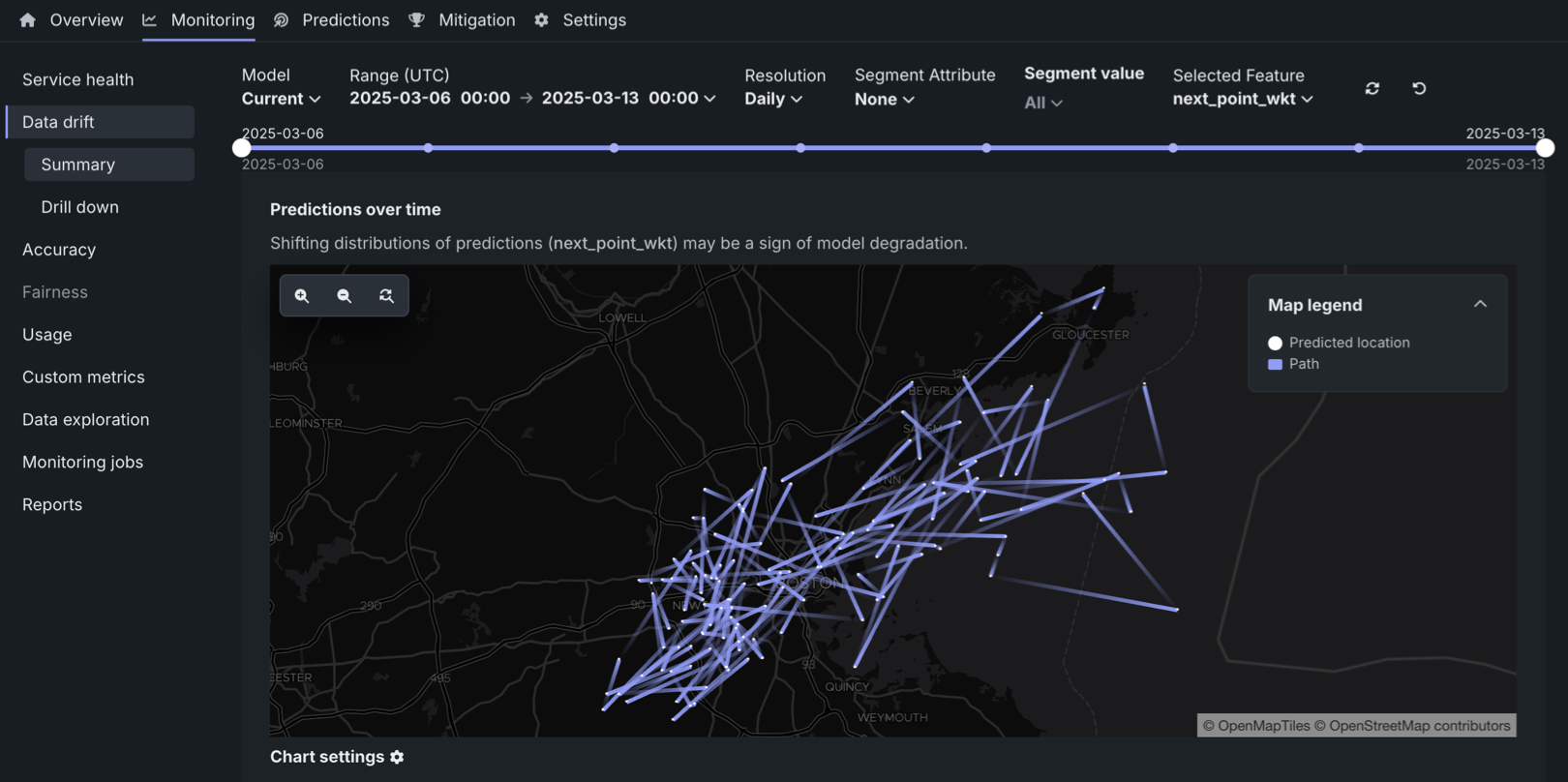
データをセグメント化して、より明確なインサイトを得る
特定の予測位置のセットにプロットを集中させるために、セグメント化された分析を活用できます。 たとえば、上のプロットでは、航空会社、コールサイン、または出発国によってフライトデータをセグメント化して、特定のセグメントに焦点を当て、予測された位置の経路をトレースできます。
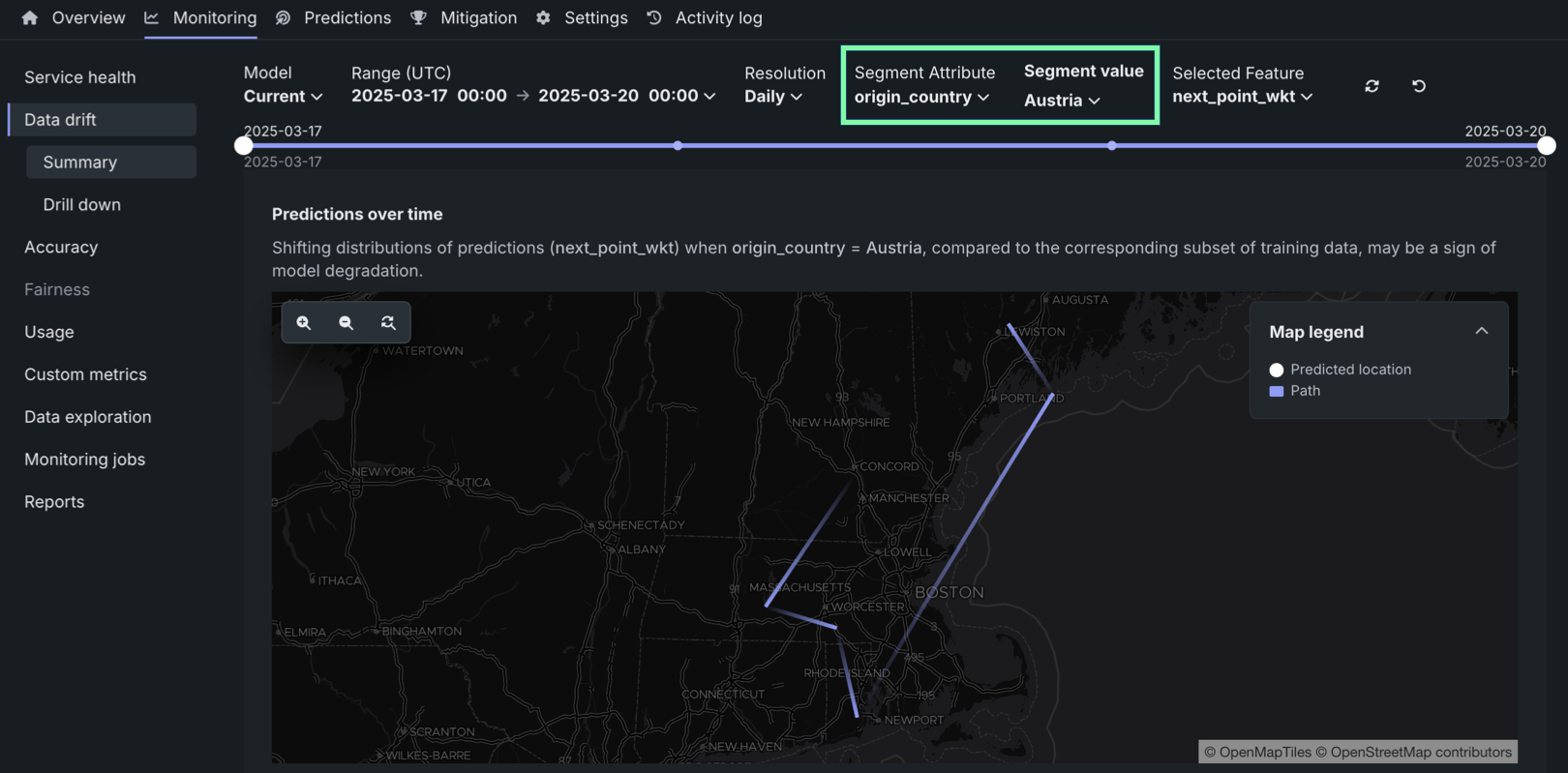
各経路と予測位置のペアは時間範囲に対応し、経路はある平均予測位置から別の平均予測位置への方向の変化を表します。 たとえば、以下の図では、位置モデルの最初の平均予測位置から4番目の平均予測位置までの経路をトレースすることができます。
位置ごとの予測値チャート¶
位置ごとの予測値の監視サポート
位置ターゲットタイプでは、位置ごとの予測値を可視化できます。
位置ターゲットタイプのデプロイでは、位置ごとタブで、位置ごとの予測値チャートを表示できます。 このチャートでは、各セル内の予測位置に加え、位置間のスコアリングデータのサンプルサイズの違いを特定するH3セルのグリッドを表示できます。
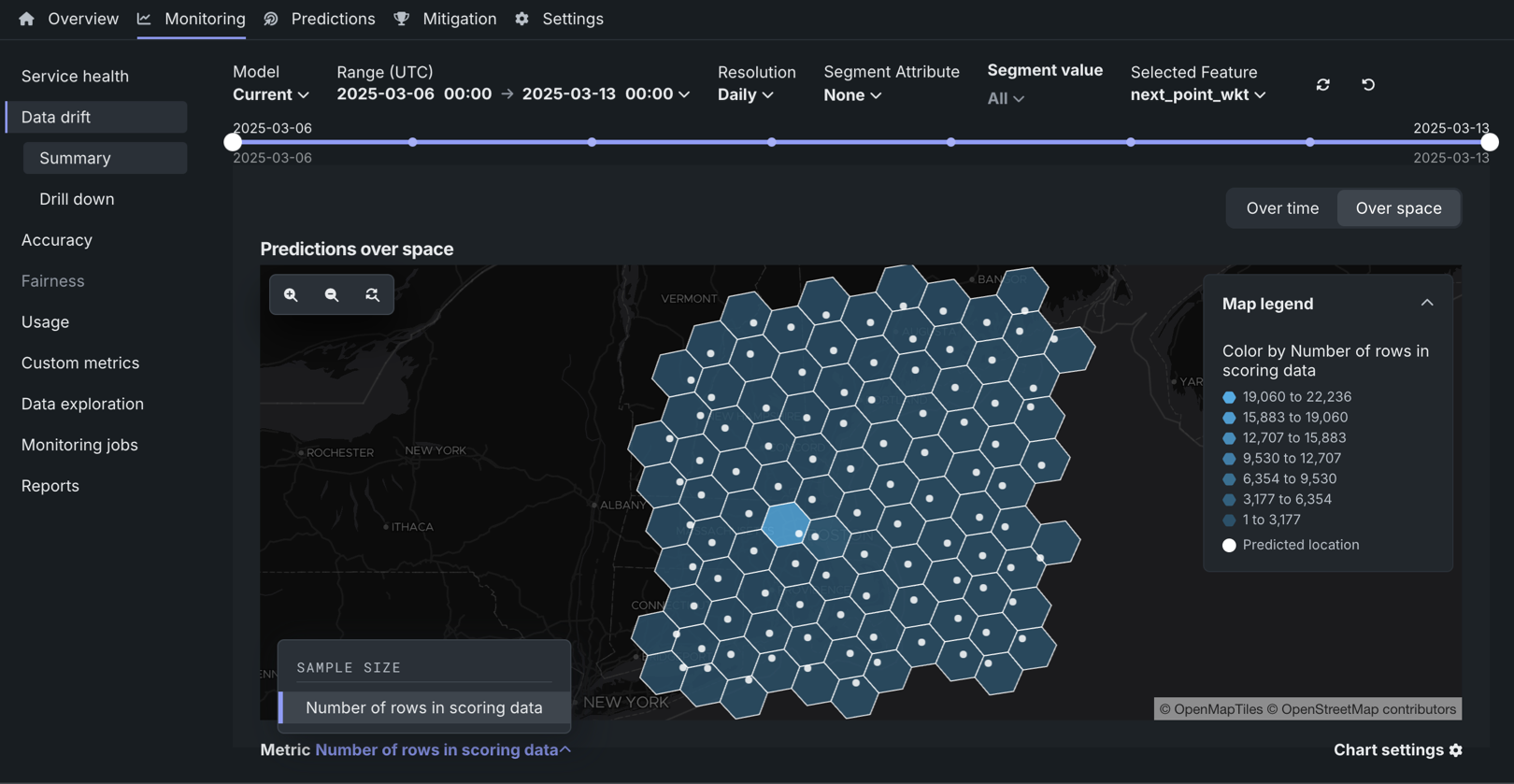
位置ごとの予測値チャートに表示される指標は以下のとおりです。
| 指標 | 説明 |
|---|---|
| サンプルサイズ | |
| スコアリングデータの行数 | スコアリングデータセットのセルに含まれるサンプルサイズ |
地図ベースのチャートの操作¶
位置ごとのドリフト、位置ごとの予測値、時間経過に伴う予測のチャートを使用するには、以下の操作を行います。
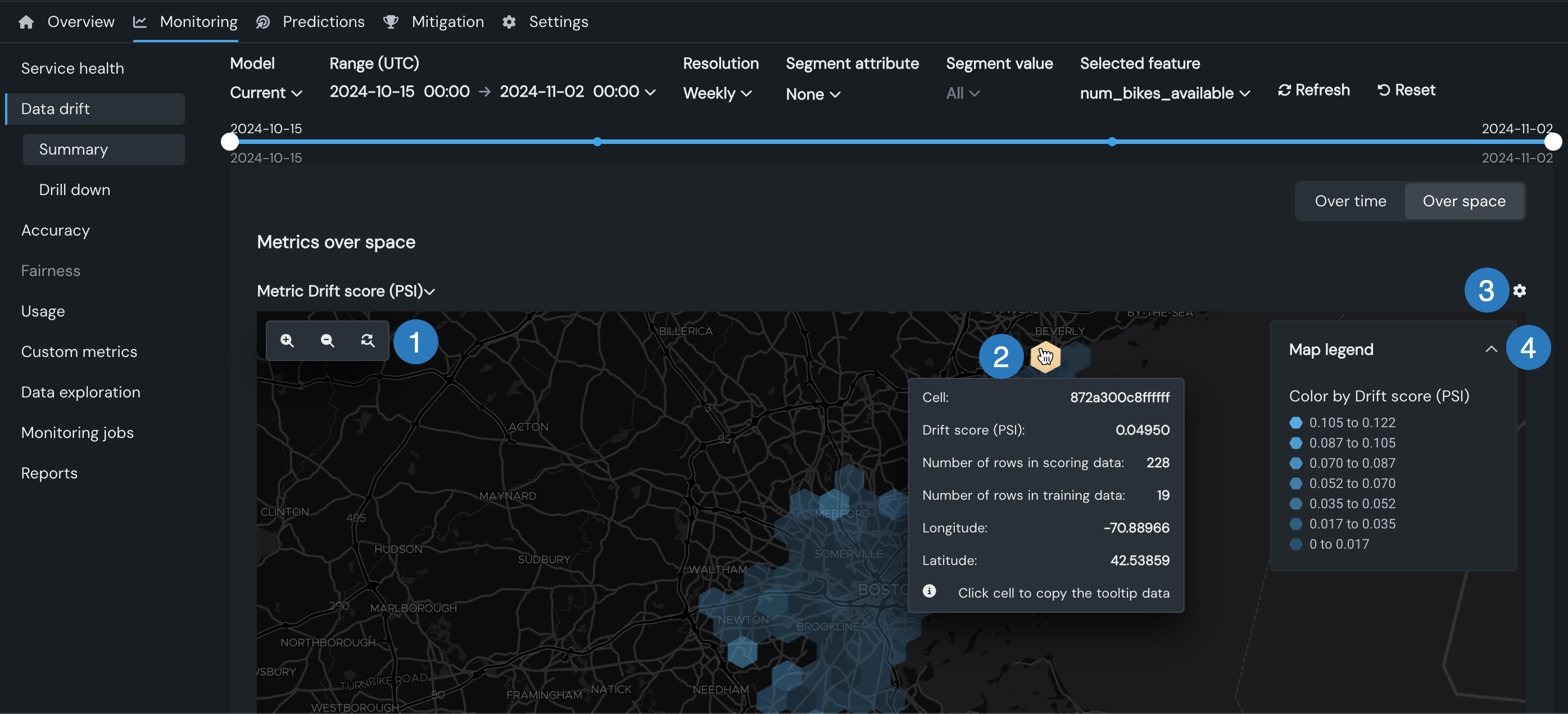
| アクション | 説明 |
|---|---|
| 1 | ズーム設定:
|
| 2 | マップ/マウスアクション:
|
| 3 | 開く および閉じる をクリックして、グラデーションの各色に関連付けられた指標値の範囲を示す凡例を表示または非表示にします。 |
| 4 | 設定アイコン をクリックして、セルの不透明度を調整します。 |
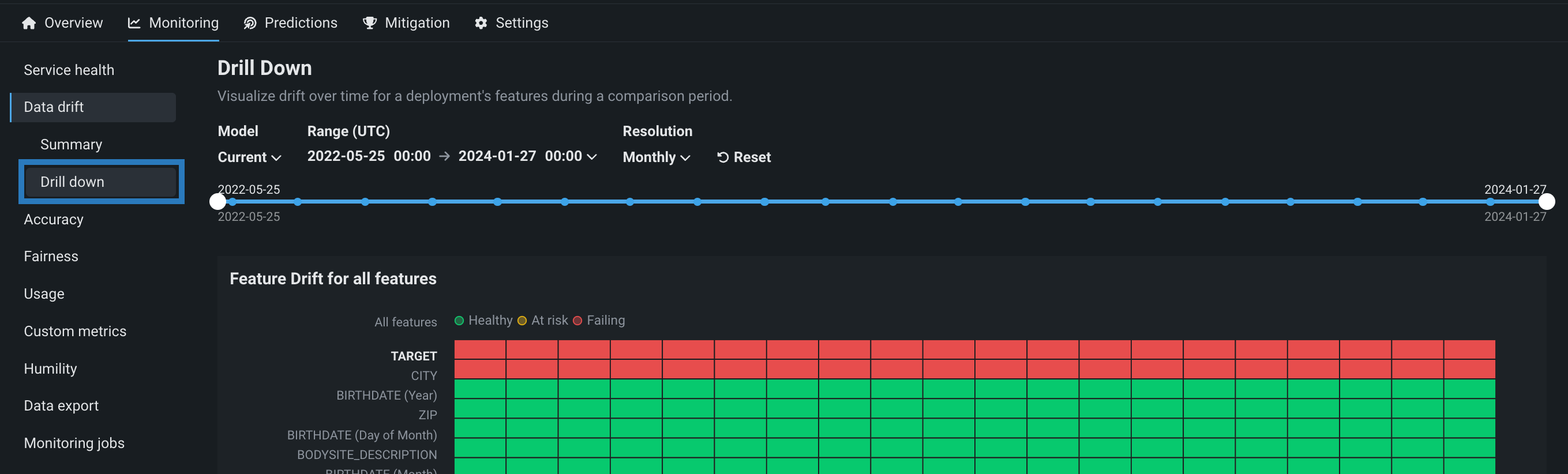
データドリフトタブでのドリルダウン¶
データドリフト > ドリルダウンチャートでは、デプロイされたモデルのトレーニングデータセットと、本番環境での予測生成に使用されるデータセットの間の、時間経過に伴う分布の差異が視覚化されます。 トレーニングデータセットで確立されたベースラインからのドリフトは、PSI(Population Stability Index)を用いて測定されます。 モデルが新しいデータを予測し続けると、時間経過に伴うドリフトステータスの変化が、追跡された各特徴量のヒートマップとして視覚化され、データドリフトの傾向を特定できるようになります。
ドリルダウンタブを使用して、デプロイ内の特徴量全体でデータドリフトのヒートマップを比較して、相関するドリフト傾向を特定できます。 さらに、ヒートマップから1つ以上の特徴量を選択して、特徴量ドリフトの比較チャートを表示できます。このチャートでは、基準期間と比較期間の間で特徴量のデータ分布の変化を比較して、ドリフトを視覚化できます。 この情報は、データ品質の問題、特徴量構成の変化、ターゲット特徴量のコンテキストの変化など、デプロイされたモデルでのデータドリフトの原因を特定するのに役立ちます。
ドリルダウン表示設定の設定¶
ドリルダウンタブには、次の表示コントロールが含まれています。
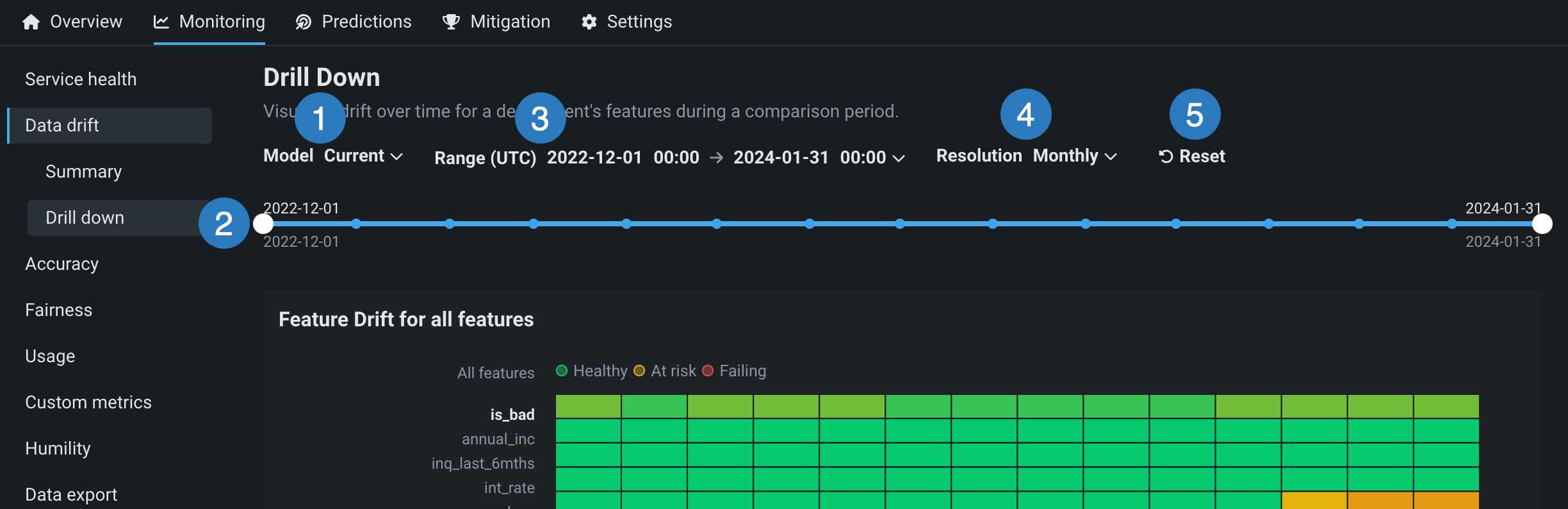
| コントロール | 説明 | |
|---|---|---|
| 1 | モデル | ヒートマップを更新して、ドロップダウンから選択したモデルを表示します。 |
| 2 | 日付スライダー | ダッシュボードで表示するデータの範囲を制限します(特定の期間にズームインするなど)。 |
| 3 | 範囲 (UTC) | デプロイ日付スライダーに表示する日付範囲を設定します。 範囲セレクターで選択できるのは、モデルのデプロイの現在のバージョンの開始日と現在の日付だけです。 |
| 4 | 単位 | デプロイ日付スライダーの時間のきめ細かさを設定します。 選択した範囲に基づいて、次の時間単位が使用可能です。
|
| 5 | リセット | ダッシュボードコントロールをデフォルト設定に戻します。 |
特徴量ドリフトヒートマップの使用¶
すべての特徴量の特徴量ドリフトヒートマップには、次の要素とコントロールが含まれています。
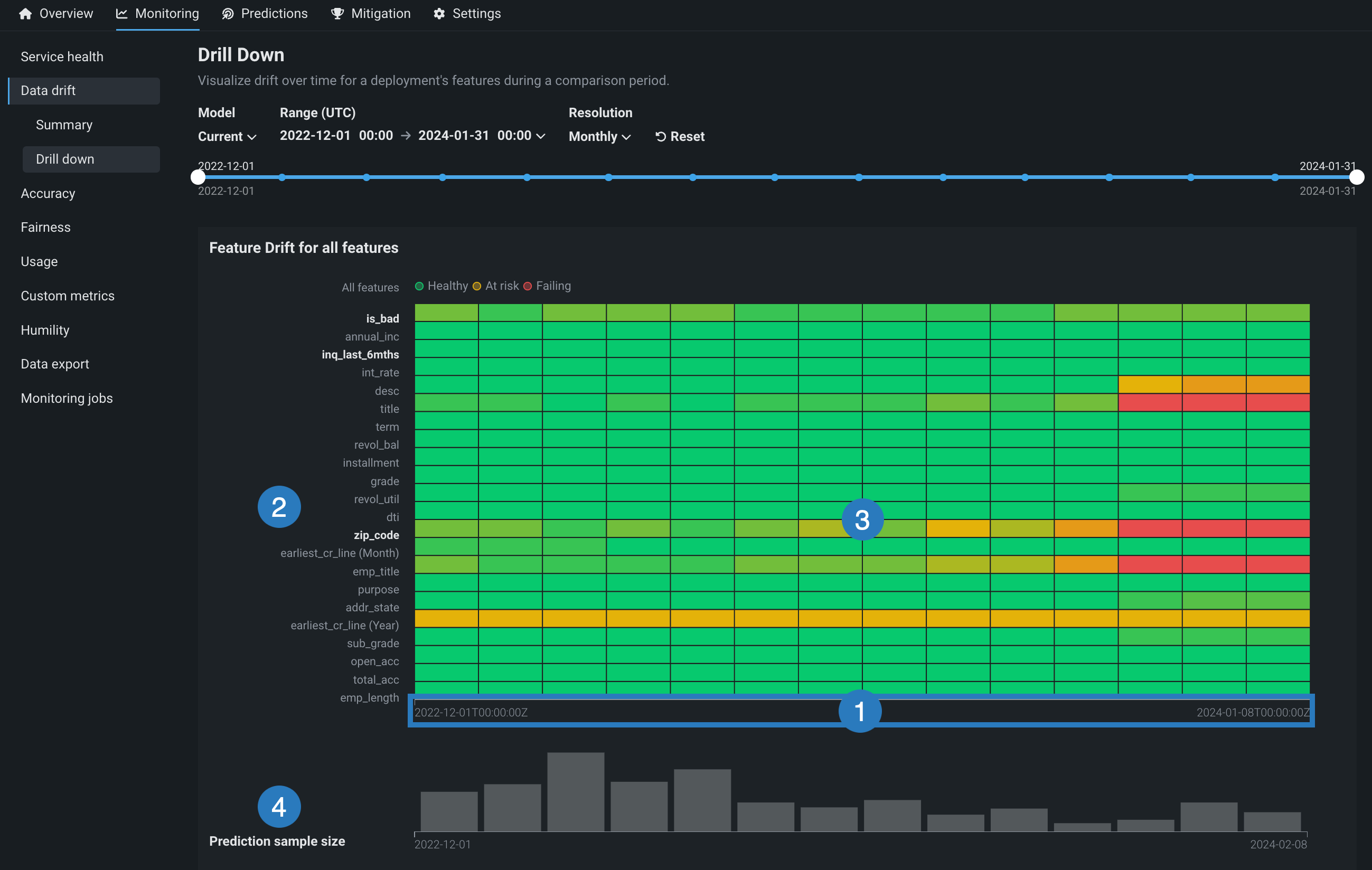
| 要素 | 説明 | |
|---|---|---|
| 1 | 予測時間 (X軸) |
対応するドリフト値(PSI)の計算に使用する予測の時間範囲を表します。 X軸の下にある予測サンプルサイズの棒グラフは、対応する予測時間範囲中に行われた予測の数を表します。 |
| 2 | 特徴量 (Y軸) |
デプロイのデータセット内の特徴量を表します。 特徴量名をクリックして、以下の 特徴ドリフト比較を生成します。 |
| 3 | ステータスのヒートマップ | デプロイの各特徴量について、時間経過に伴うドリフトステータスを表示します。 ドリフトステータスの視覚化は、 データドリフト設定に基づいています。 デプロイオーナーは、 特徴量ドリフトと特徴量の有用性チャートの比較設定でドリフトと有用性が高いしきい値を設定することもできます。 考えられるドリフトステータスの分類は次のとおりです。
|
| 4 | 予測サンプルサイズ | 特定の期間のデータドリフトの計算に使用される予測データの行数を表示します。 予測サンプルサイズに関する追加情報を表示するには、チャート内のビンにカーソルを合わせて、予測範囲の時間とサンプルサイズの値を確認します。 |
特徴量のドリフト比較チャートの使用¶
特徴量ドリフトの比較セクションには、次の要素とコントロールが含まれています。
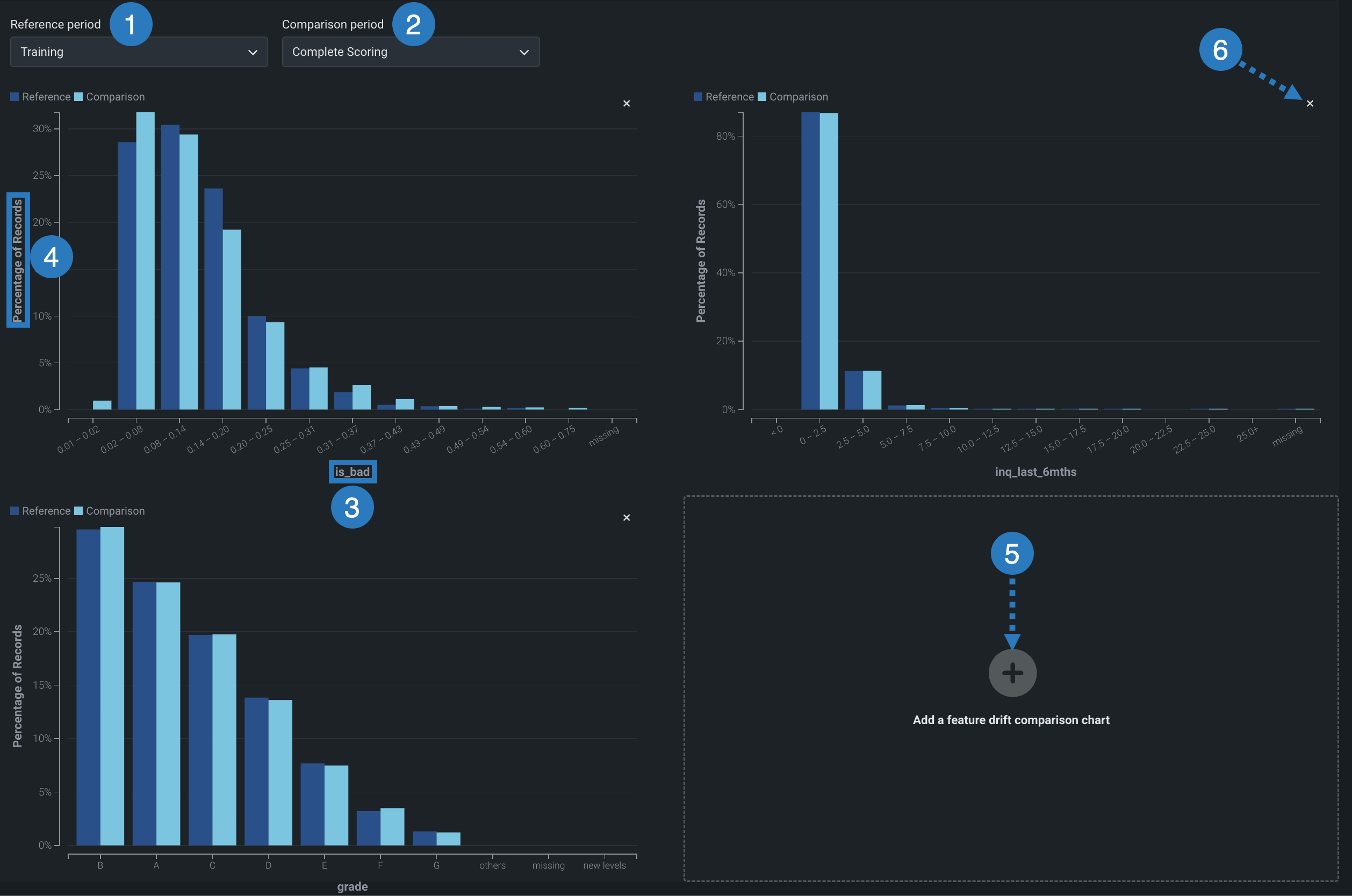
| 要素 | 説明 | |
|---|---|---|
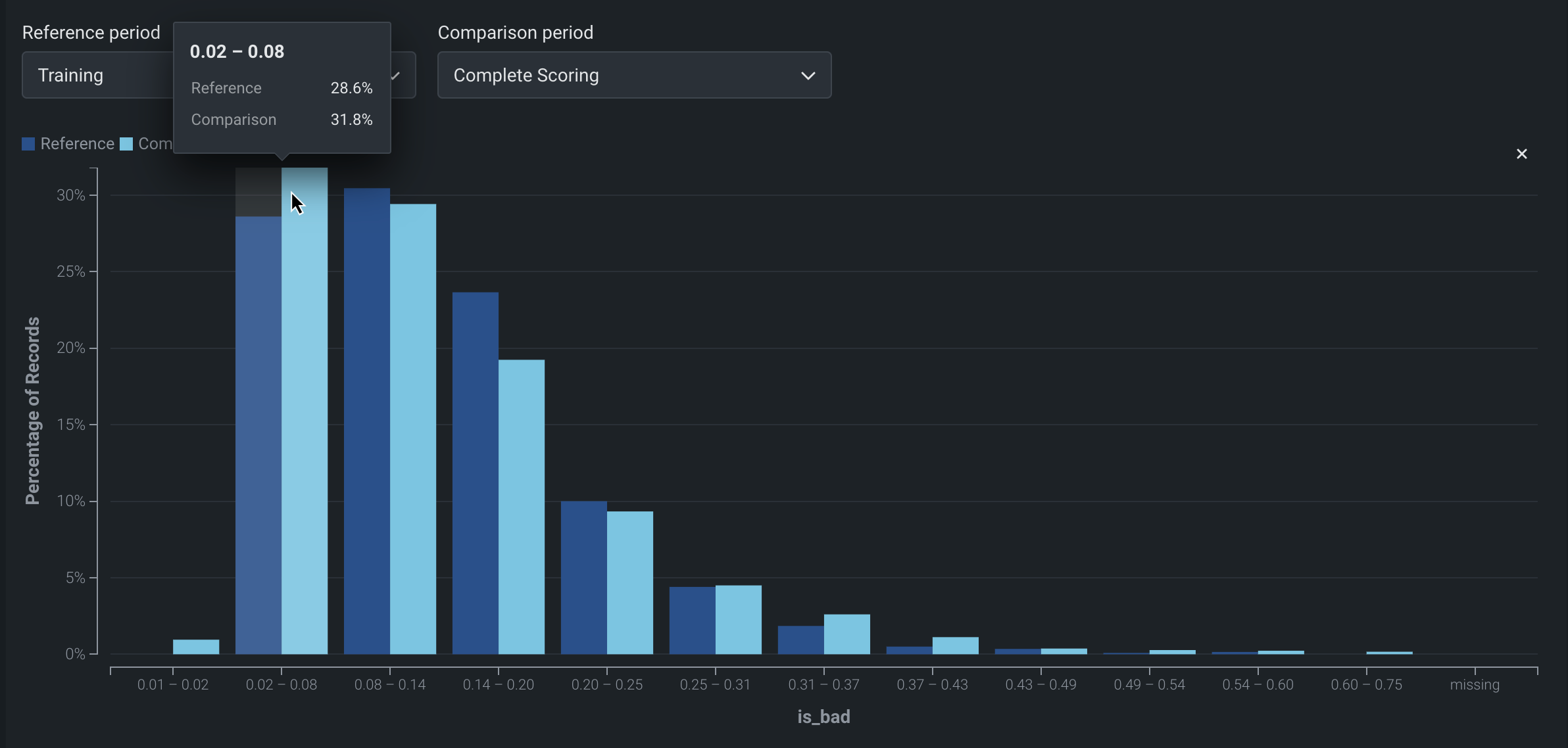
| 1 | リファレンス期間 | ドリフト比較チャートのベースラインとして使用する期間の日付範囲を設定します。 |
| 2 | 比較期間 | リファレンス期間と比較するデータ配信期間の日付範囲を設定します。 ヒートマップ上の対象エリアを選択して、比較期間として使用することもできます。 |
| 3 | 特徴量値 (X軸) |
特徴量ドリフト比較チャートの特徴量データセット内の値の範囲を表します。 |
| 4 | レコードのパーセンテージ (Y軸) |
値の範囲で表されるデータセット全体の割合を表し、選択した参照期間と比較期間を視覚的に比較できます。 |
| 5 | 特徴量のドリフト比較チャートを追加 | 選択した特徴量の特徴量ドリフト比較チャートを生成します。 |
| 6 | このチャートを削除 | 特徴量のドリフト比較チャートの削除 |
ヒント" "特徴量ドリフトヒートマップでの比較期間の設定
比較期間として機能するヒートマップ上の対象領域を選択するには、クリックアンドドラッグして、特徴量ドリフト比較の対象期間を選択します。
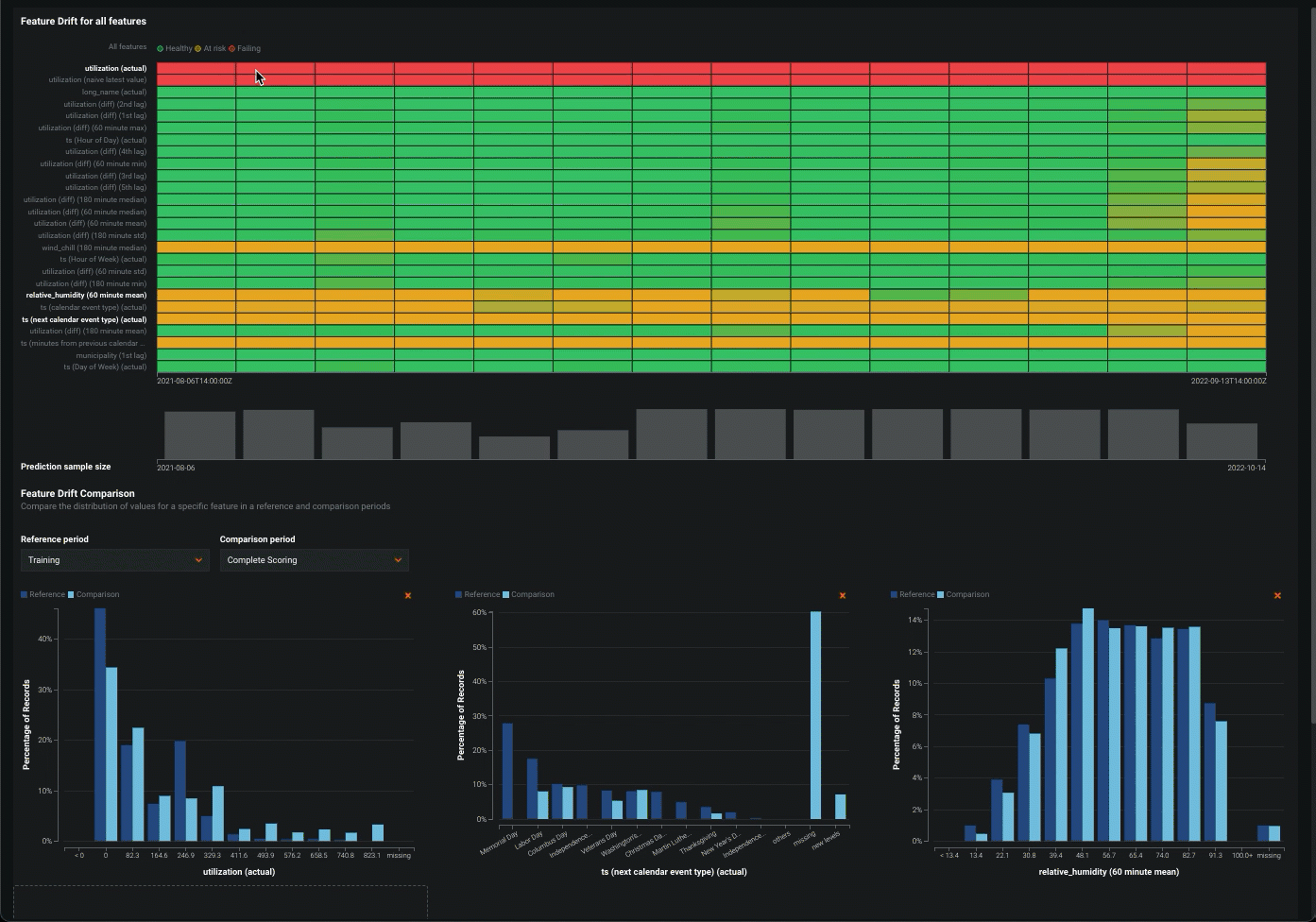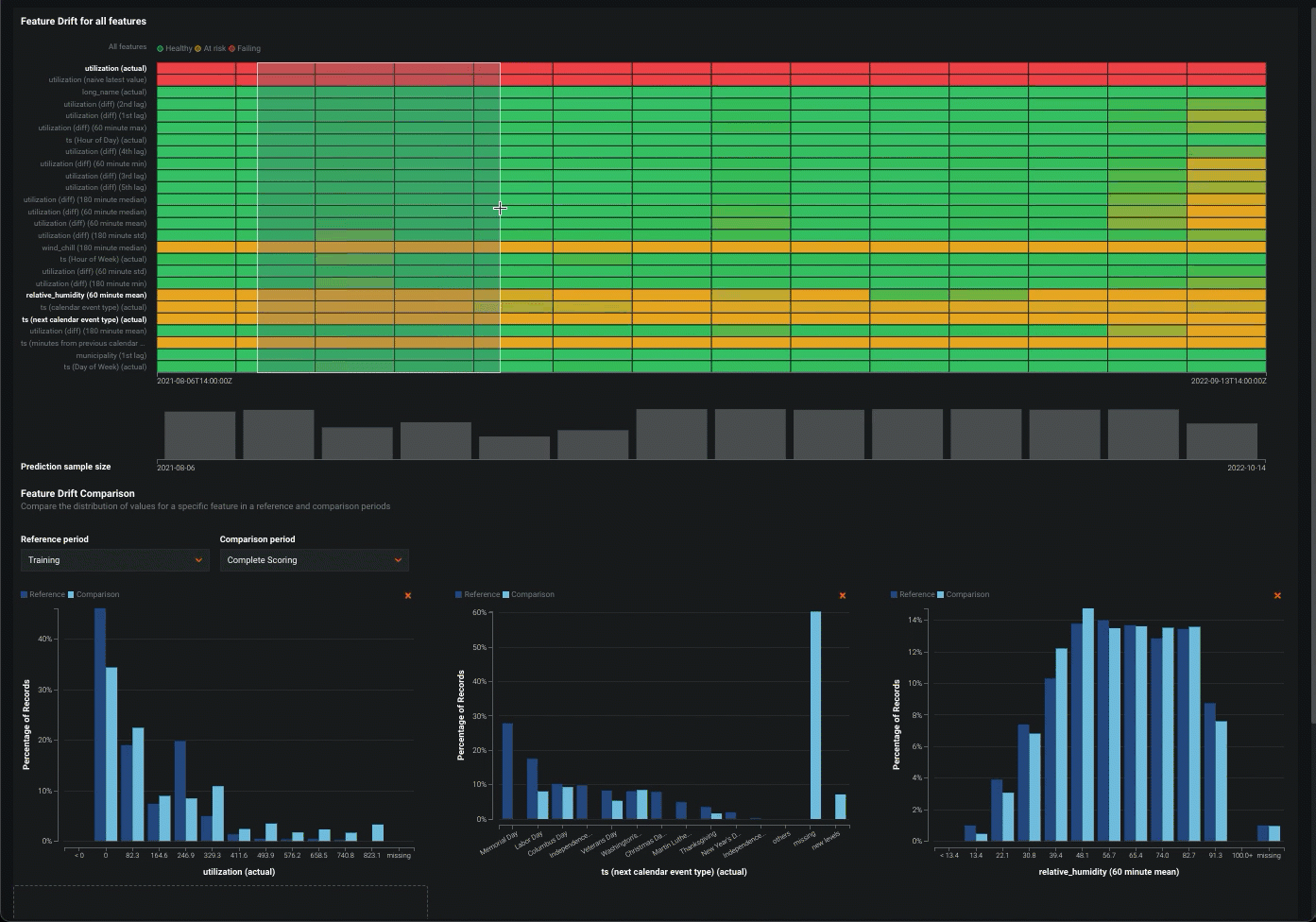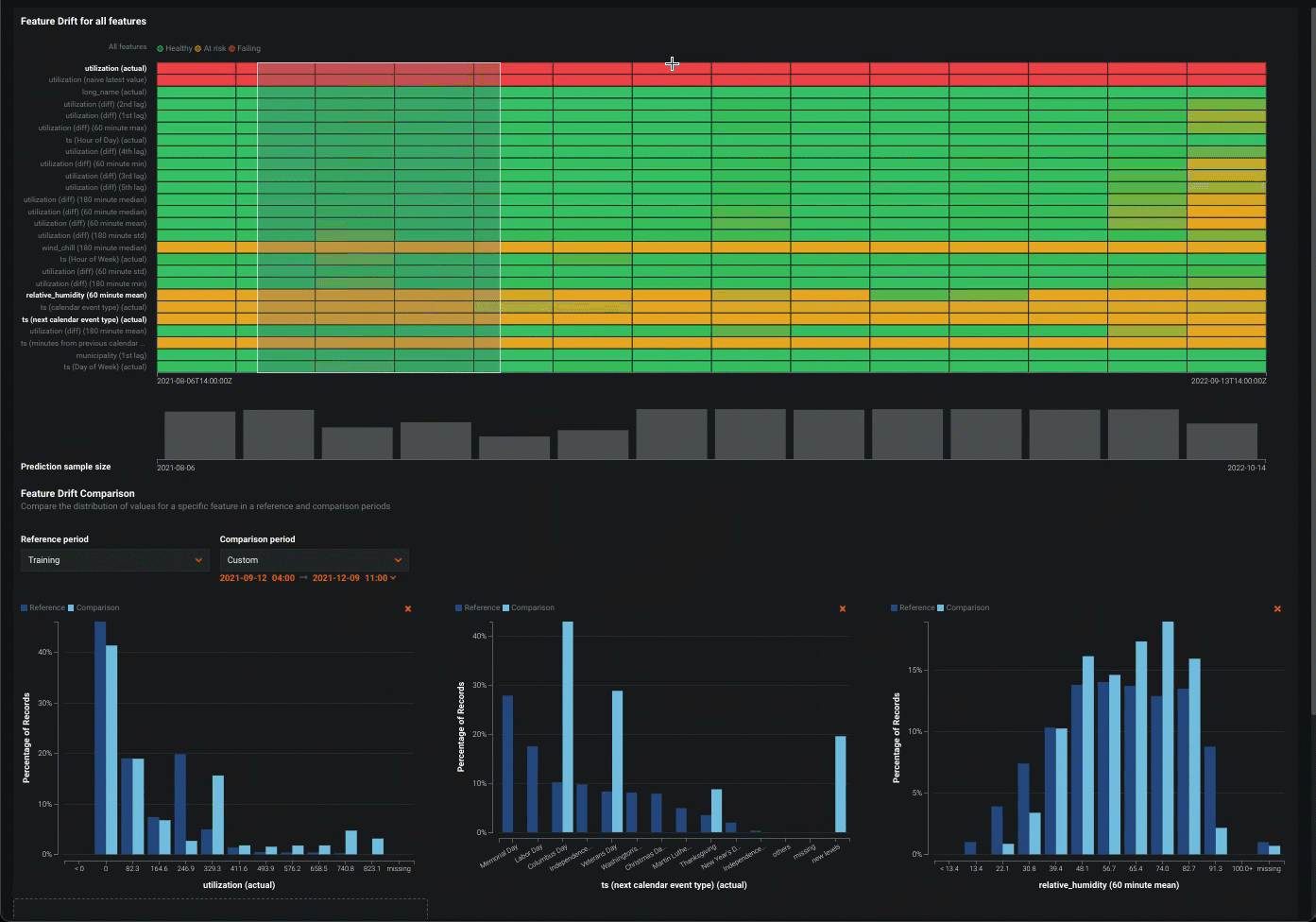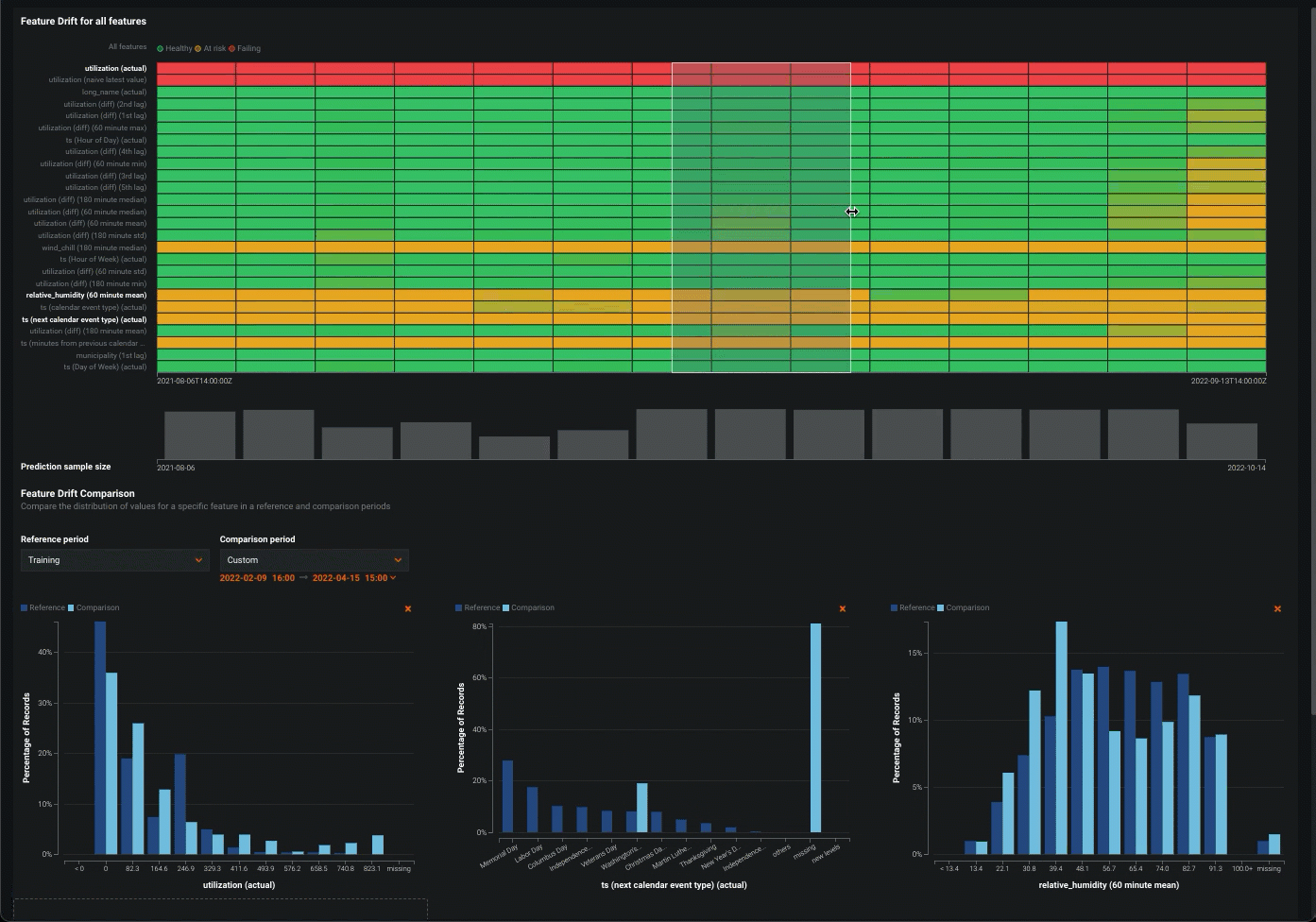
特徴量のドリフト比較チャートの追加情報を表示するには、チャートのバーにカーソルを合わせると、そのバーに含まれる値の範囲、それらの値が参照期間で表すデータセット全体に占める割合、および比較期間でのデータセット全体の割合が表示されます。