DataRobotサーバーレス予測環境の追加¶
予測環境ページで、利用可能なDataRobot予測環境を確認し、DataRobotサーバーレス予測環境を作成して、設定可能なコンピューティングインスタンス設定でスケーラブルな予測を行うことができます。
事前にプロビジョニングされたDataRobotサーバーレス環境
2024年11月以降に設立された組織は、予測環境ページに事前にプロビジョニングされたDataRobotサーバーレス予測環境にアクセスできます。
事前にプロビジョニングされたDataRobotサーバーレス環境
トライアルアカウントをお持ちの場合、予測環境ページに事前にプロビジョニングされたDataRobotサーバーレス予測環境にアクセスできます。
事前にプロビジョニングされたDataRobotサーバーレス環境
DataRobot 10.2以上のセルフマネージド環境を利用している組織は、予測環境ページで事前にプロビジョニングされたDataRobotサーバーレス予測環境にアクセスできます。
DataRobotサーバーレス予測環境における予測間隔
DataRobotサーバーレス予測環境において、時系列予測間隔を含む予測を作成するには、 モデルパッケージを登録する際に、事前に計算された予測間隔を含める必要があります。 予測間隔を事前に計算しない場合、登録されたモデルから得られるデプロイは、 予測間隔の有効化をサポートしません。
DataRobotサーバーレス予測環境を追加するには:
-
コンソールで、予測環境、+ 予測環境を追加の順にクリックします。
-
予測環境を追加ダイアログボックスで、次のフィールドに入力します。
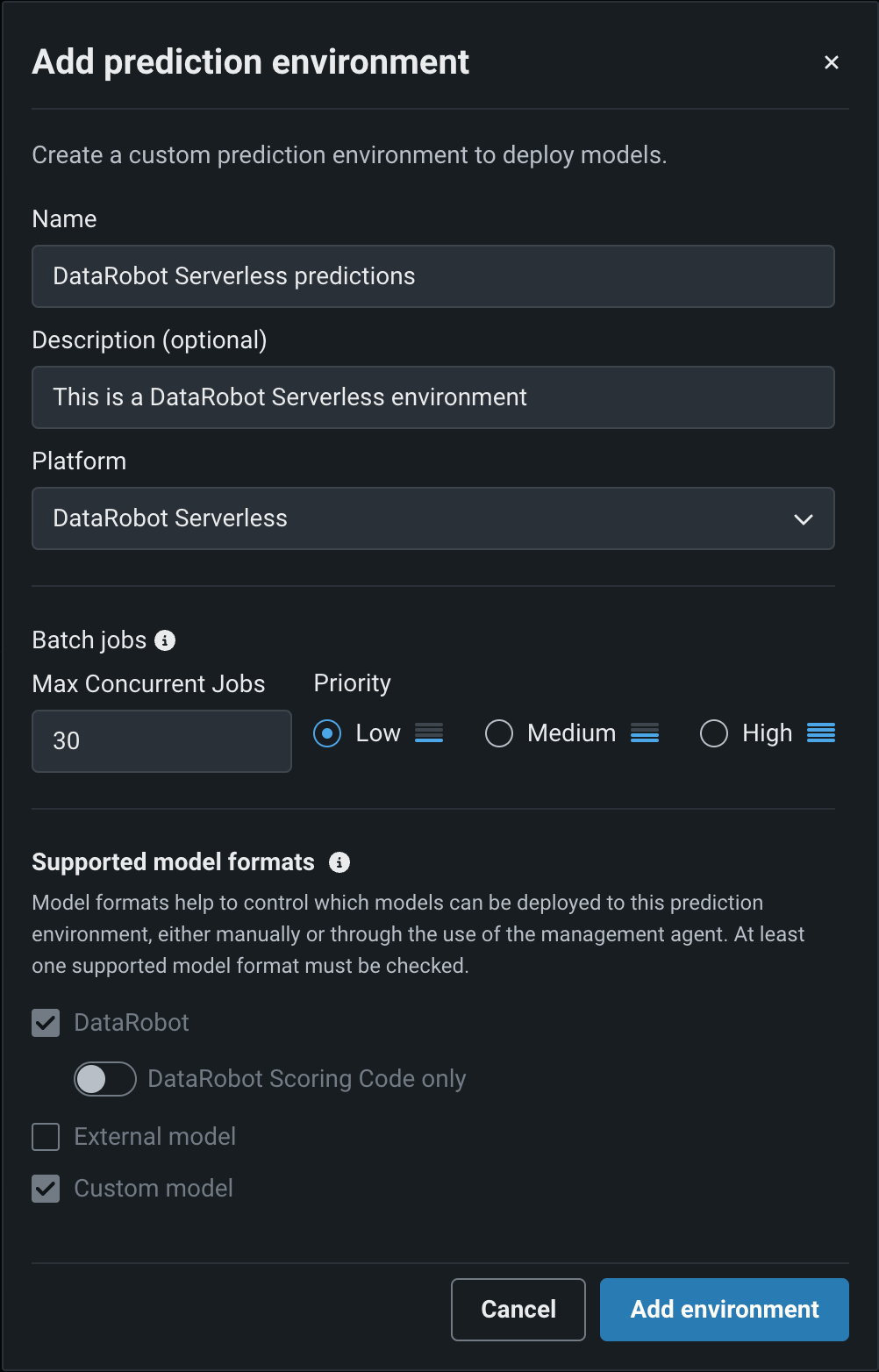
フィールド 説明 名前 予測環境にわかりやすい名前を入力します。 説明 (オプション)外部予測環境の説明を入力します。 プラットフォーム DataRobot Serverlessを選択します。 バッチジョブ 同時実行可能な最大ジョブ数 このサーバーレス環境の最大同時実行ジョブ数を、組織で定義されている最大数から減らします。 優先度 この環境でのバッチジョブの有用性を設定します。 メンテナンスウィンドウ 毎週のメンテナンスウィンドウを有効にする 毎週4時間のメンテナンスウィンドウを有効にします。 開始時刻 (UTC)と日を入力して、環境のメンテナンスウィンドウを定義します。 同時に実行できるジョブの最大数はどのように定義されていますか?
同時に実行できるジョブ数には2つの上限があり、これらの上限はDataRobotがインストールされている環境によって異なります。 各バッチジョブには両方の上限が適用されます。つまり、予測環境でバッチジョブを実行するには、両方の条件を満たす必要があります。 最初の上限は、組織の管理者によって定義される_組織レベル_の上限(デフォルトは、_セルフマネージド_版では
30、SaaS版では10)です。この上限は、2つ目の上限より高くする必要があります。 2つ目の上限は、予測環境の作成者によってここで定義された_環境レベル_の上限です。この上限は、組織レベルの上限より低くする必要があります。 -
環境設定を行ったら、環境を追加をクリックします。
これで、予測環境ページから環境を利用できるようになりました。
DataRobotサーバーレス予測環境にモデルをデプロイする¶
事前にプロビジョニングされたDataRobotサーバーレス環境、または作成したサーバーレス環境を使用して、予測を行うモデルをデプロイできます。
DataRobotサーバーレス予測環境にモデルをデプロイするには:
-
プラットフォーム行の予測環境ページで、DataRobotサーバーレス予測環境を見つけ、モデルをデプロイする環境をクリックします。
-
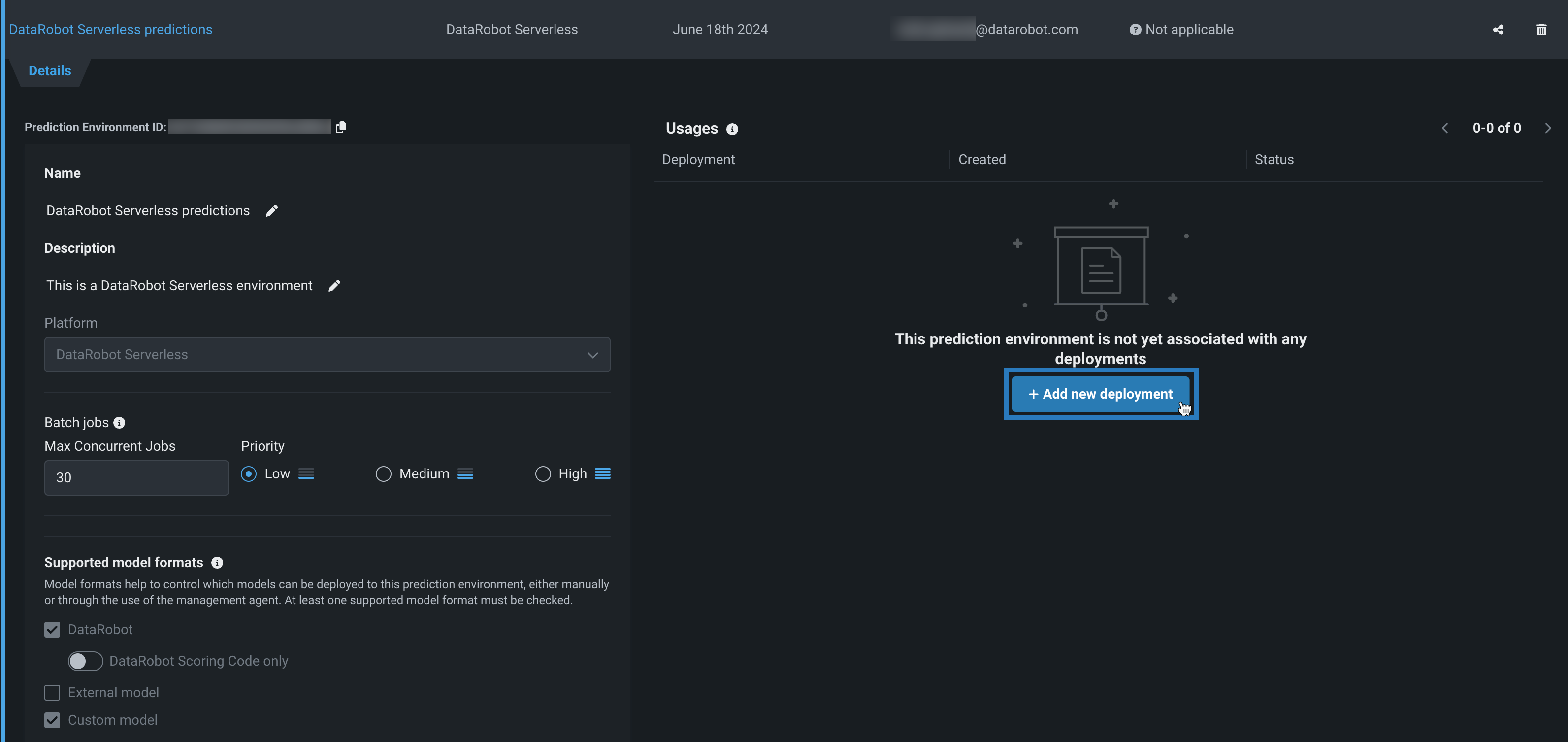
詳細タブの使用状況の下のデプロイ列で、+ 新規デプロイを追加をクリックします。
-
互換性を有しデプロイするモデルパッケージを選択ダイアログボックスで、デプロイしたいモデルの名前を検索ボックスに入力し、モデルをクリックしてから、デプロイしたい_DataRobot_モデルのバージョンをクリックします。
-
モデルのバージョンを選択をクリックして、 デプロイ設定を構築します。
-
この環境でオンデマンド予測を設定するには、高度なオプションを表示をクリックし、高度な予測設定までスクロールダウンして、以下の自動スケーリングオプションを設定してから、モデルをデプロイをクリックします。
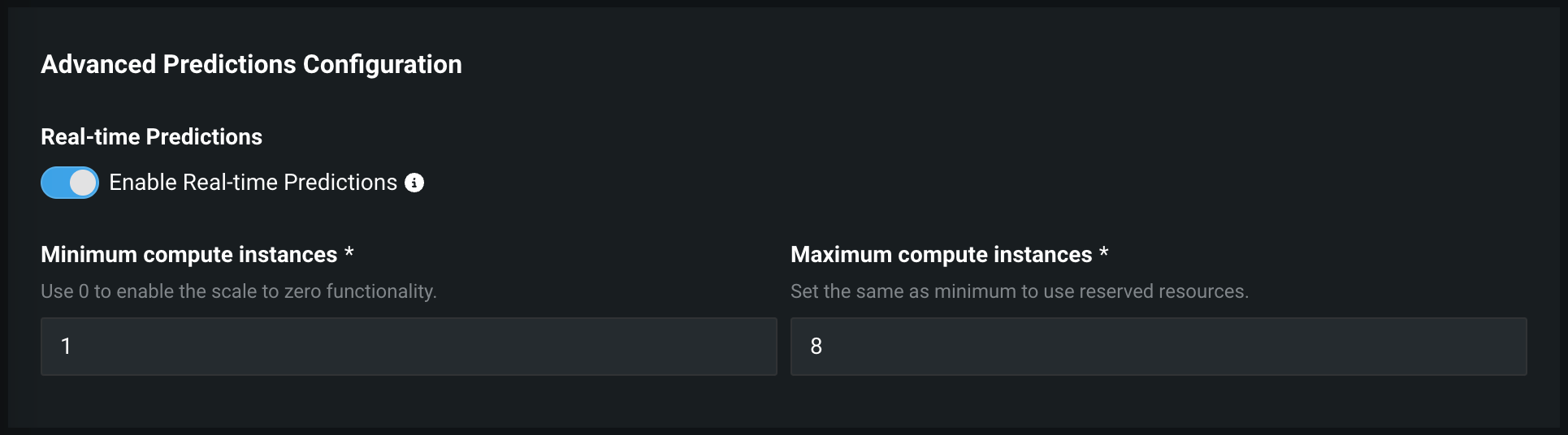
自動スケーリングでは、着信トラフィックに基づいてデプロイ内のレプリカの数が自動的に調整されます。 トラフィックの多い時間帯には、パフォーマンスを維持するためにレプリカが追加されます。 トラフィックの少ない時間帯には、コストを削減するためにレプリカが削除されます。 これにより、手動によるスケーリングが不要になると同時に、デプロイがさまざまな負荷に効率的に対応できるようになります。
自動スケーリングを設定するには、以下の設定を変更します。 DataRobotモデルの場合、しきい値40%のCPU使用率に基づいて自動スケーリングが実行されます。

| フィールド | 説明 |
|---|---|
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
自動スケーリングを設定するには、スケーリングのトリガーとなる指標を選択します。
-
CPU使用率:アクティブなレプリカ全体の平均CPU使用率のしきい値を設定します。 CPU使用率がこのしきい値を超えると、レプリカが自動的に追加され、処理能力が向上します。
-
HTTPリクエストの同時実行:処理される同時リクエスト数のしきい値を設定します。 たとえば、しきい値が5の場合、処理中の同時リクエストが5つ検出されると、レプリカが追加されます。
選択したしきい値を超えると、現在の負荷を処理するために必要な追加のレプリカ数が計算されます。 選択された指標が継続的に監視され、リソース使用量を最小限に抑えながら最適なパフォーマンスを維持するようにレプリカ数が調整されます。
CPU使用率の設定は以下のとおりです。
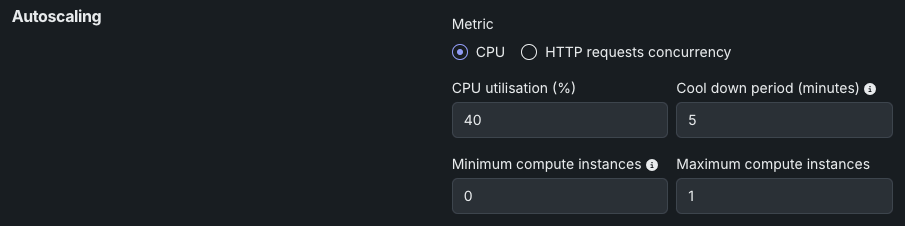
| フィールド | 説明 |
|---|---|
| CPU使用率(%) | スケーリングのトリガーとなるCPU使用率の目標値を設定します。 CPU使用率がこのしきい値に達すると、さらにレプリカが追加されます。 |
| クールダウン期間(分) | スケールダウンイベント後、次のスケールダウンが発生するまでの待機時間を設定します。 これにより、指標が不安定な場合の急激なスケーリングの変動を防ぐことができます。 |
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
HTTPリクエストの同時実行に関する設定は以下のとおりです。
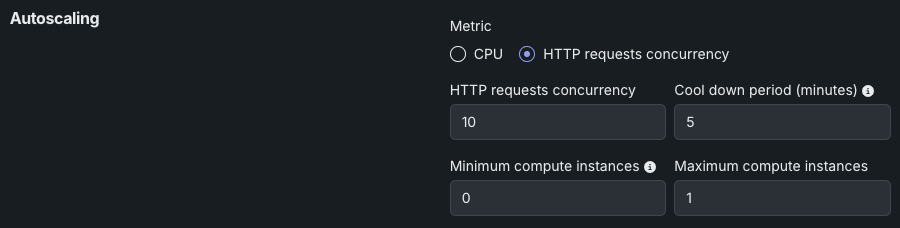
| フィールド | 説明 |
|---|---|
| HTTPリクエストの同時実行 | スケーリングのトリガーに必要な同時リクエスト数を設定します。 同時リクエストがこのしきい値に達すると、さらにレプリカが追加されます。 |
| クールダウン期間(分) | スケールダウンイベント後、次のスケールダウンが発生するまでの待機時間を設定します。 これにより、指標が不安定な場合の急激なスケーリングの変動を防ぐことができます。 |
| 最小コンピューティングインスタンス数 | (プレミアム機能)モデルデプロイの最小コンピューティングインスタンスを設定します。 組織が「常時」予測を利用できない場合、これは0に設定され、変更できません。 最小コンピューティングインスタンス数を0に設定すると、推論サーバーは、7日間の非アクティブ期間の後に停止します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
| 最大コンピューティングインスタンス数 | モデルデプロイの最大コンピューティングインスタンスを、現在設定されている最小値を超える値に設定します。 コンピューティングリソースの使用を制限するには、最大値を最小値と同じに設定します。 最小および最大のコンピューティングインスタンスは、モデルタイプによって異なります。 詳細については、 コンピューティングインスタンスの設定に関する注記を参照してください。 |
プレミアム機能:常時予測
常時予測はプレミアム機能です。 最小のコンピューティングインスタンスを設定するには、デプロイの自動スケーリング管理が必要です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ: デプロイの自動スケーリング管理を有効にする
コンピューティングインスタンスの設定
DataRobotモデルデプロイの場合:
- デフォルトの最小値は0で、最大値は3です。
- 最小値と最大値は、組織の
max_compute_serverless_prediction_api設定から取得されます。
カスタムモデルデプロイの場合:
- デフォルトの最小値は0で、最大値は1です。
- 最小値と最大値は、組織の
max_custom_model_replicas_per_deployment設定から取得されます。 - GPU(LLMの場合)で実行する場合、最小値は常に1よりも大きくなります。
さらに、高可用性のシナリオの場合:
- 最小コンピューティングインスタンス数の設定は2以上である必要があります。
- これには、ビジネスクリティカルまたは消費ベースの価格設定が必要です。
コンピューティングリソースの可用性によっては、予測環境を予測で使用できるようになるには、デプロイ後数分かかることがあります。
コンピューティングインスタンスの設定を更新する
デプロイ後にモデルで使用可能なコンピューティングインスタンスの数を更新する必要がある場合は、設定 > 予測タブでこれらの設定を変更できます。
予測の作成¶
DataRobotサーバーレス環境を作成し、その環境にモデルをデプロイしたら、リアルタイム予測やバッチ予測を行うことができます。
ペイロードサイズの上限
サーバーレス予測環境でのリアルタイムデプロイ予測の最大ペイロードサイズは50MBです。 バッチ予測については、バッチ予測の制限を参照してください。
DataRobotサーバーレス予測環境でリアルタイム予測を行うには:
-
デプロイインベントリで、DataRobotサーバーレス環境に関連付けられたデプロイを見つけて開きます。 これを行うには、 フィルターをクリックし、DataRobotサーバーレスを選択して、フィルターを適用をクリックします。
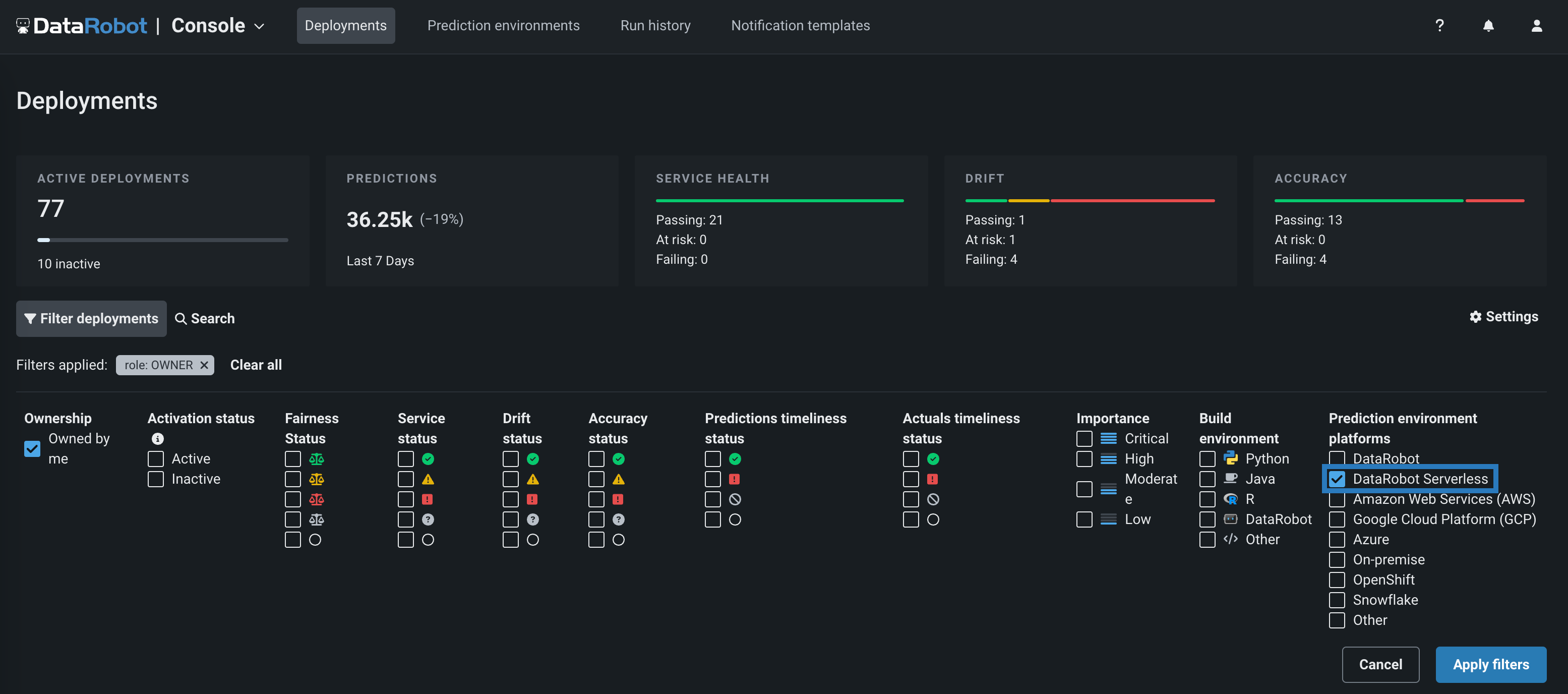
-
DataRobotサーバーレス予測環境に関連付けられたデプロイで、予測 > 予測APIをクリックします。
-
予測APIスクリプトコードページの予測タイプで、リアルタイムをクリックします。
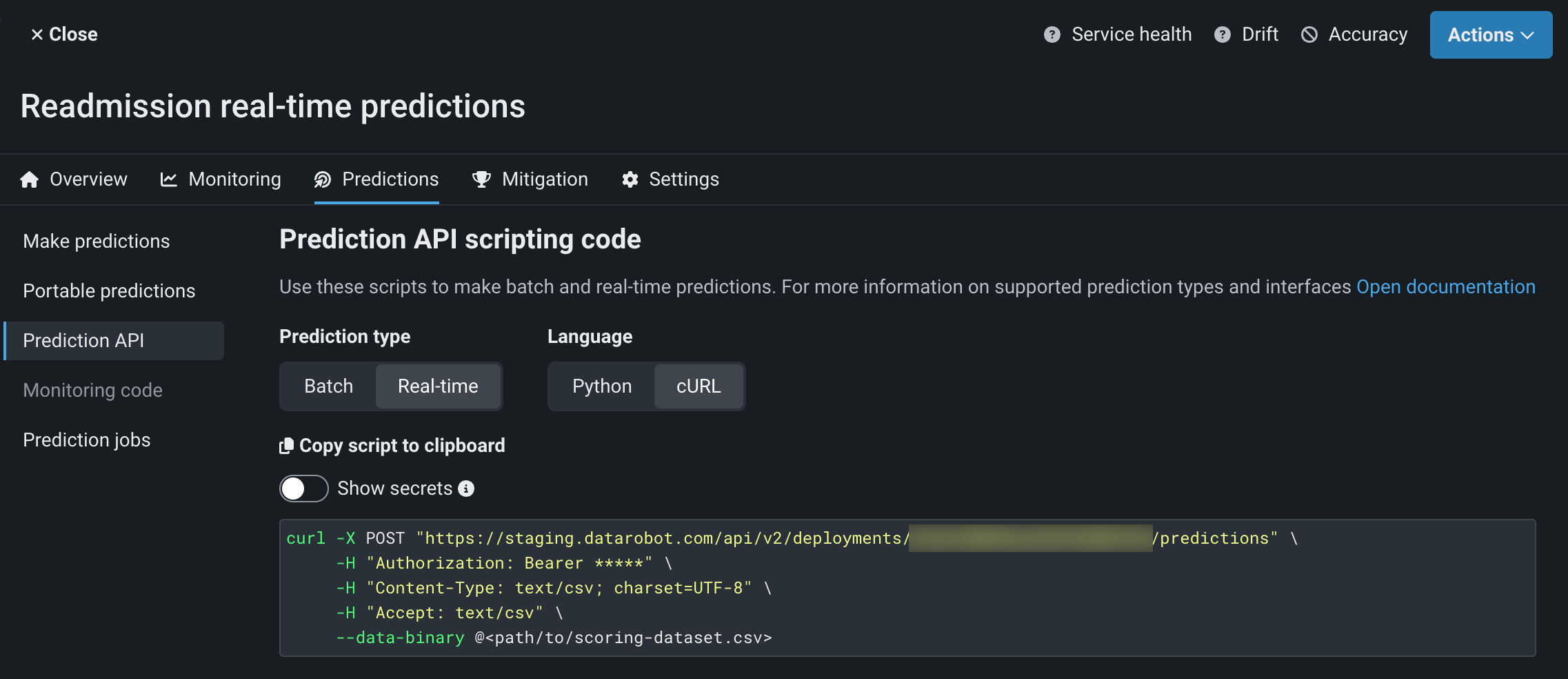
-
言語で、PythonまたはcURLを選択し、オプションでシークレットを表示を有効にして、スクリプトをクリップボードにコピーをクリックします。
-
PythonまたはcURLスニペットを実行して、DataRobotサーバーレスデプロイに予測リクエストを行います。
DataRobotサーバーレス予測環境でバッチ予測を行うには、UIでのバッチ予測または予測APIスクリプトでの予測の標準プロセスに従ってください。