生成モデルの監視¶
本機能の提供について
生成モデルの監視サポートはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
カスタムモデルと外部モデルのテキスト生成ターゲットタイプを使用した、LLMOpsのプレミアム機能では、生成LLM(大規模言語モデル)をデプロイして、予測の実行、サービス、使用状況、データドリフト統計の監視、カスタム指標の作成を行います。 DataRobotは、次の2つのデプロイ方法でLLMに対応しています。
| 方法 | 説明 |
|---|---|
| DataRobotでカスタムモデルとしてテキスト生成モデルを作成する | ワークショップを使用してテキスト生成モデルを作成およびデプロイし、LLMのAPIを呼び出してテキストを生成し、MLOpsがLLMの入力および出力にアクセスして監視できるようにします。 LLMのAPIを呼び出すには、カスタムモデルのパブリックネットワークアクセスを有効にする必要があります。 |
| 外部で実行されているテキスト生成モデルを監視する | インフラストラクチャ(ローカルまたはクラウド)にテキスト生成モデルを作成してデプロイし、監視エージェントを使用して、LLMの入出力を監視のためにDataRobotに通信します。 |
評価とモデレーションのカスタム指標には関連付けIDが必要
評価とモデレーションを設定するときに追加された指標について、カスタム指標タブでデータを表示するには、デプロイされたLLMを介して予測を開始する前に、関連付けIDを設定して予測ストレージを有効にします。 関連付けIDを設定せず、LLMの予測とともに関連付けIDを指定した場合、モデレーションの指標は カスタム指標タブでは計算されません。 この設定は、デプロイ 中やデプロイ 後に有効化できます。
生成型カスタムモデルの作成とデプロイ¶
カスタム推論モデルは、ユーザーが作成した事前トレーニング済みのモデルであり、ワークショップを通じてDataRobotに(ファイル群として)アップロードできます。 次に、モデルアーティファクトをアップロードして、DataRobotの一元化されたデプロイハブにカスタム推論モデルを作成、テスト、およびデプロイすることができます。
生成型カスタムモデルの追加¶
ワークショップに生成モデルを追加するには:
-
レジストリ > ワークショップをクリックします。 このタブには、作成したモデルが一覧表示されます。
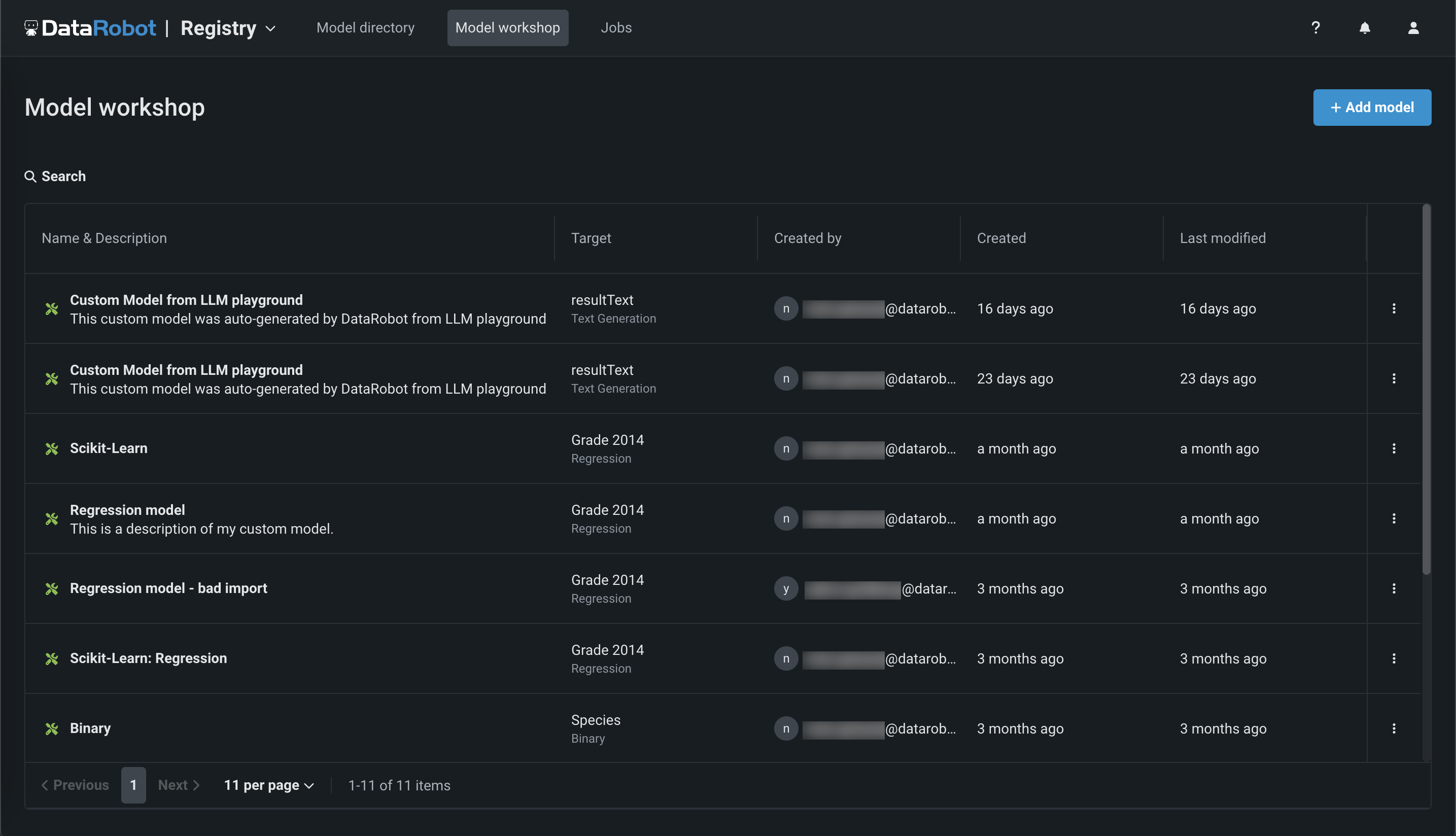
-
+ モデルを追加(またはカスタムモデルパネルが開いている場合は ボタン)をクリックします。
-
モデルを追加ページで、次に示すモデルの設定の下にあるフィールドを定義します。
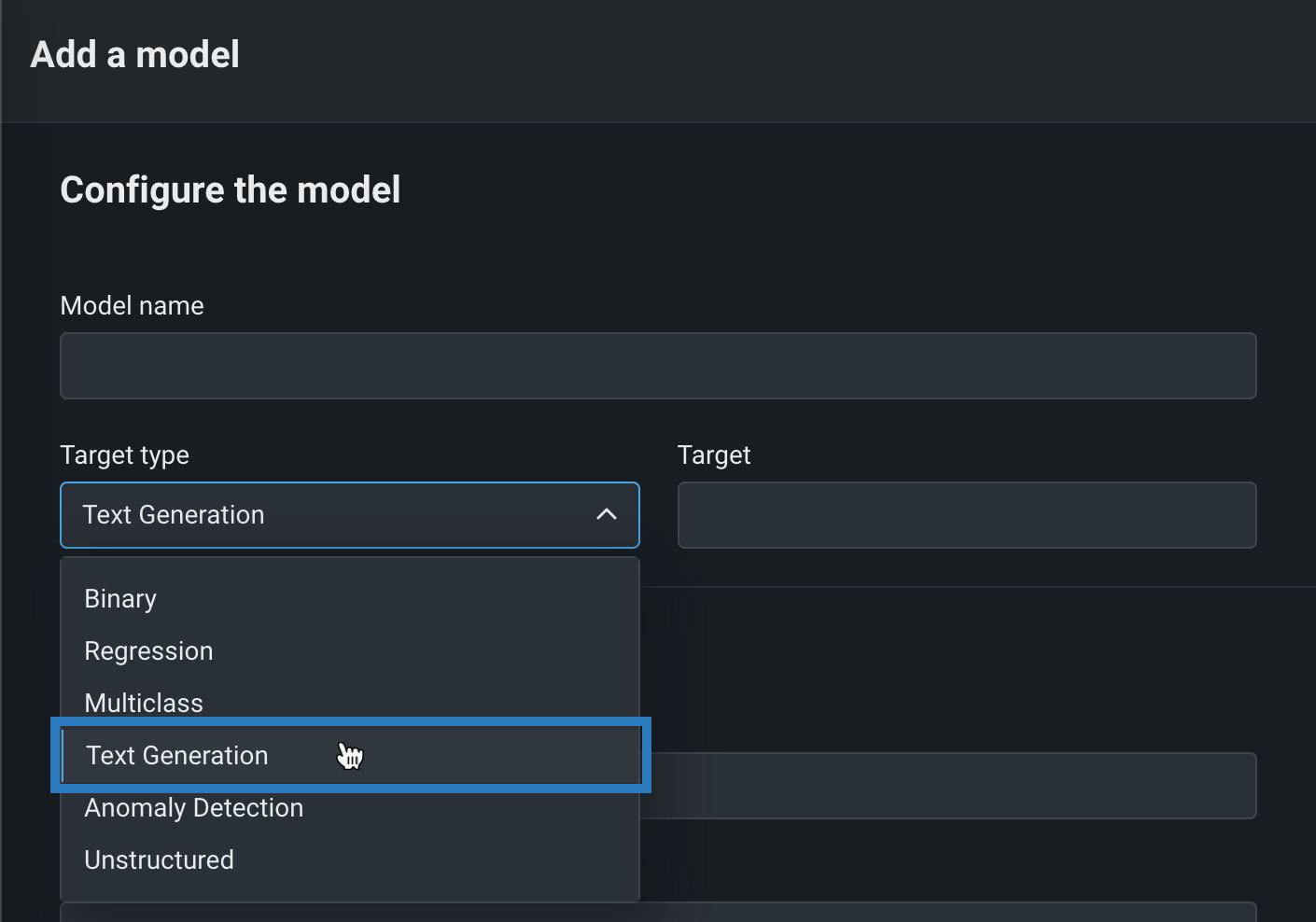
フィールド 説明 モデル名 カスタムモデルにわかりやすい名前を入力します。 ターゲットタイプ テキスト生成を選択します。 ターゲット名 生成AIモデルの出力を含めるデータセット列の名前( resultTextなど)を入力します。高度な設定 言語 生成AIモデルの構築に使用されるプログラミング言語を入力します。 説明 モデルのコンテンツと目的の説明を入力します。 -
フィールドに入力したら、モデルを追加をクリックします。
カスタムモデルがアセンブルタブで開きます。
生成型カスタムモデルの構築とデプロイ¶
ワークショップから生成モデルを構築して、テストし、デプロイするには:
-
アセンブルタブの上部にある環境の下で、基本環境リストからGenAIモデル環境を選択します。 モデル環境は、カスタムモデルの テストと 登録済みカスタムモデルの デプロイに使用されます。
-
依存関係セクションに入力するために、ファイルセクションで
requirements.txtファイルをアップロードし、DataRobotが最適なイメージを構築できるようにします。 -
ファイルセクションで、必要なカスタムモデルファイルを追加します。 モデルと ドロップイン環境をペアリングしていない場合、これにはカスタムモデル環境要件と
start_server.shファイルが含まれます。 ファイルの追加方法はいくつかあります。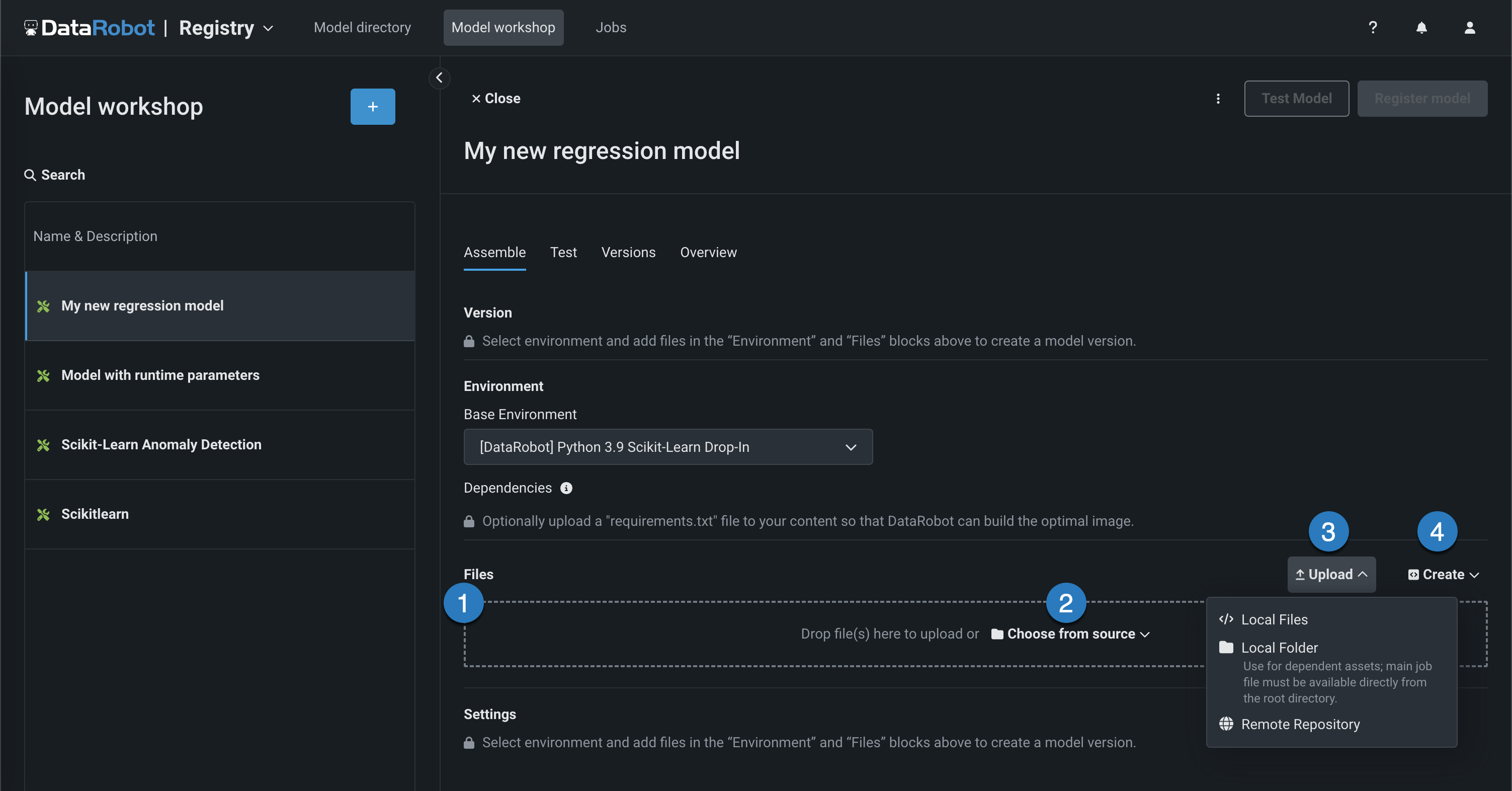
要素 説明 1 ファイル ファイルをグループボックスにドラッグしてアップロードします。 2 ソースから選択 クリックしてローカルファイルまたはローカルフォルダーを参照します。 3 アップロード クリックしてローカルファイルまたはローカルフォルダーを参照するか、リモートリポジトリからファイルを取得します。 4 作成 空のファイルまたはテンプレートとして新しいファイルを作成し、カスタムモデルに保存します。 - model-metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。
ワークショップで構築された基本LLMには、少なくとも次のファイルが含まれている必要があります。
ファイル 内容 custom.pyカスタムモデルコード( カスタムモデルのパブリックネットワークアクセスを介してLLMサービスのAPIを呼び出します)。 model-metadata.yaml生成モデルに必要なカスタムモデルのメタデータと ランタイムパラメーター。 requirements.txt生成モデルに必要な ライブラリ(およびバージョン)。 -
必要なモデルファイルを追加したら、 トレーニングデータを追加します。 ドリフト監視のトレーニングベースラインを提供するには、生成モデルが質問に回答することを想定しているトピックに関連したプロンプトと回答を少なくとも20行含むデータセットをアップロードします。 これらのプロンプトとレスポンスは、ドキュメントから取得することも、手動で作成することも、生成することもできます。
-
次に、テストタブ、新しいテストを実行、実行を順にクリックして、起動テストおよび予測エラーテスト(テキスト生成ターゲットタイプではこれらのテストのみサポート)を実行します。
-
Click Register a model, provide the model information, and click Register model.
登録済みのモデルがモデルディレクトリタブで開きます。
-
登録されているモデルバージョンヘッダーで、デプロイをクリックし、 デプロイ設定を行います。
他のDataRobotモデルと同様に 予測を作成できるようになりました。
外部生成モデルの作成とデプロイ¶
外部モデルパッケージを使用すると、外部生成モデルを登録およびデプロイできます。 監視エージェントを使用して、これらのモデルタイプでMLOps監視機能にアクセスできます。
監視エージェントが監視する外部生成モデルを生成してデプロイするには、レジストリから外部モデルを登録モデルまたはバージョンとして追加します。
-
On the Registry > Models tab, click + Register a model (or the button when the registered model or version info panel is open):
モデルの登録パネルが開き、外部モデルタブが表示されます。
-
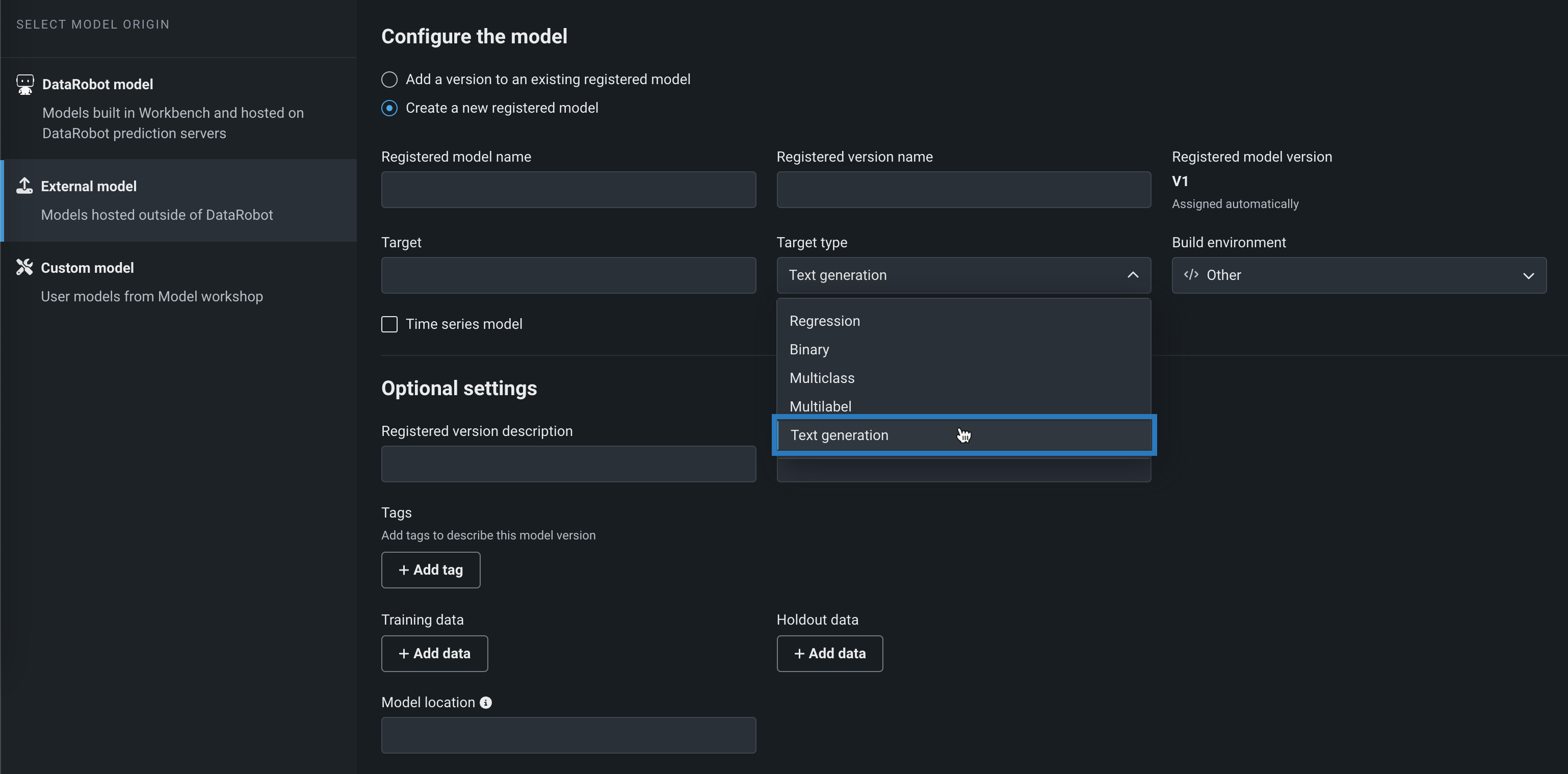
外部モデルタブのモデルの設定で、既存の登録モデルにバージョンを追加または新しい登録モデルを作成を選択します。
-
ターゲットタイプリストからテキスト生成をクリックし、エージェントで監視する生成モデルに関する 必要な情報を追加します。
-
オプション設定で、ドリフト監視のトレーニングベースラインを指定します。 トレーニングデータの下で+ データを追加をクリックし、生成モデルが質問に回答することを意図したトピックに関連するプロンプトと回答を 少なくとも 20行含むデータセットをアップロードします。 これらのプロンプトとレスポンスは、ドキュメントから取得することも、手動で作成することも、生成することもできます。
-
すべての必須フィールドを設定したら、モデルの登録をクリックします。
モデルのバージョンが、レジストリ > モデルタブで開きます。
-
登録されているモデルバージョンヘッダーで、デプロイをクリックし、 デプロイ設定を行います。
デプロイされた生成モデルの監視¶
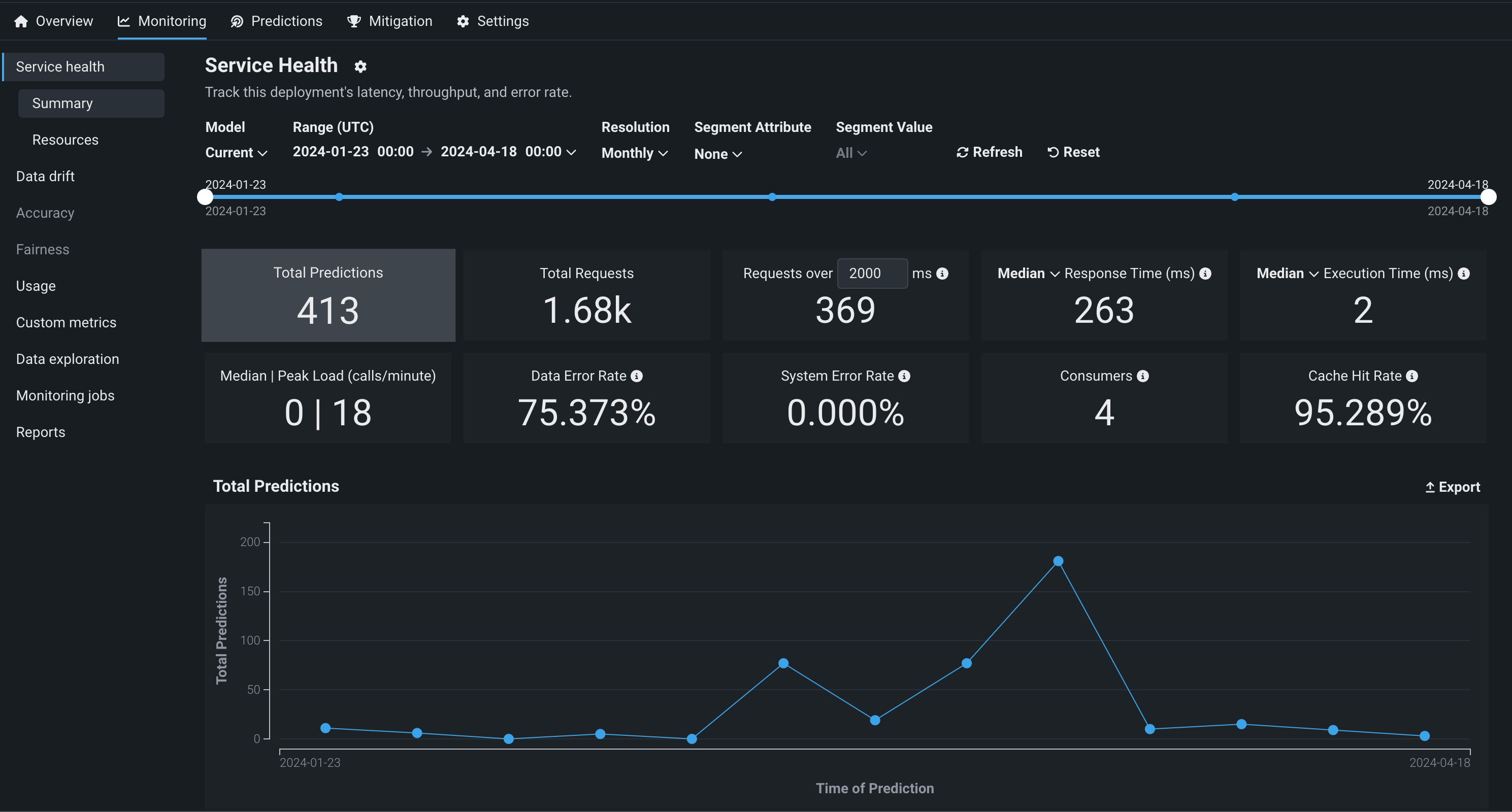
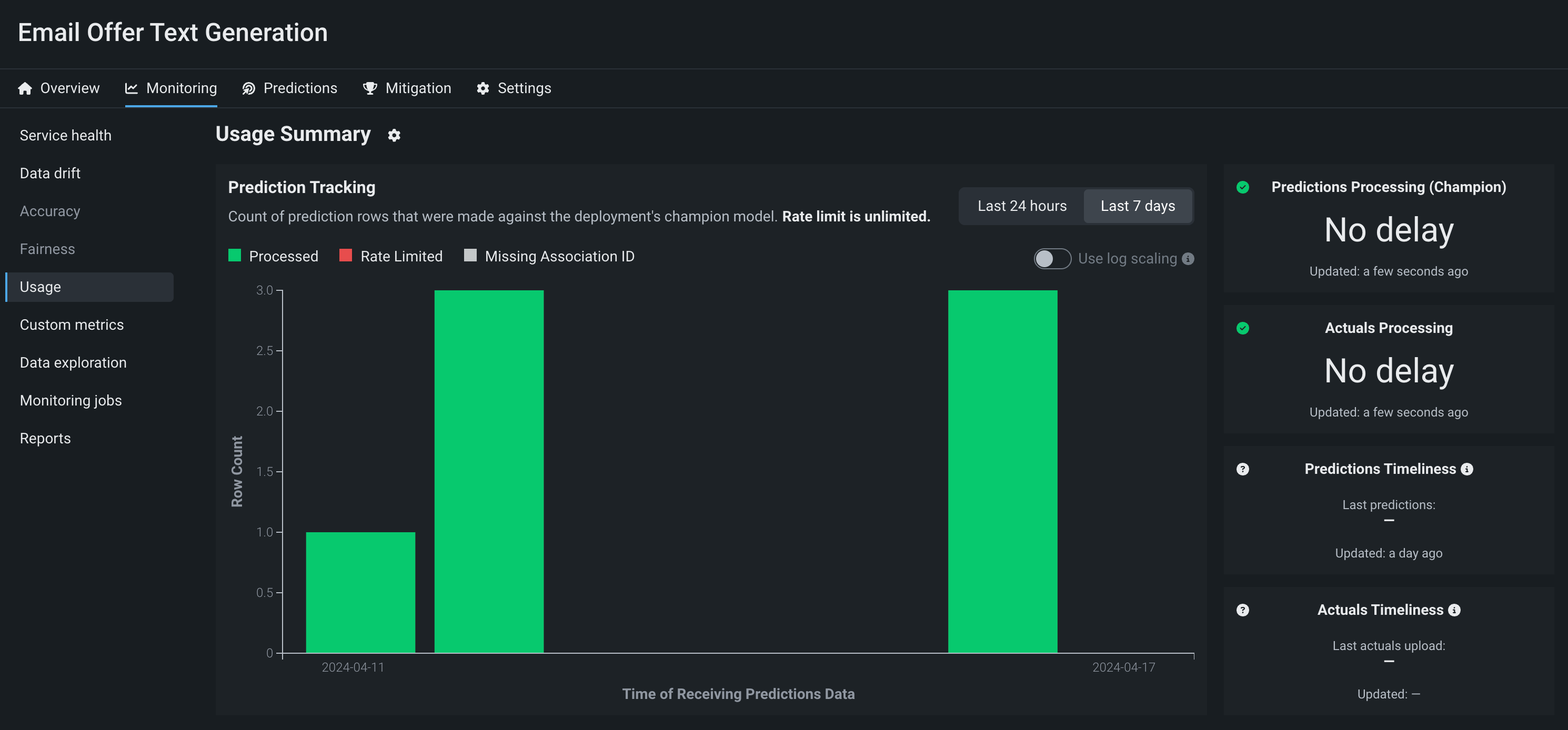
本番環境で生成モデルを監視するために、 サービスの正常性と 使用状況の統計の表示、 デプロイデータの探索、 カスタム指標の作成、 データドリフトの識別を行うことができます。
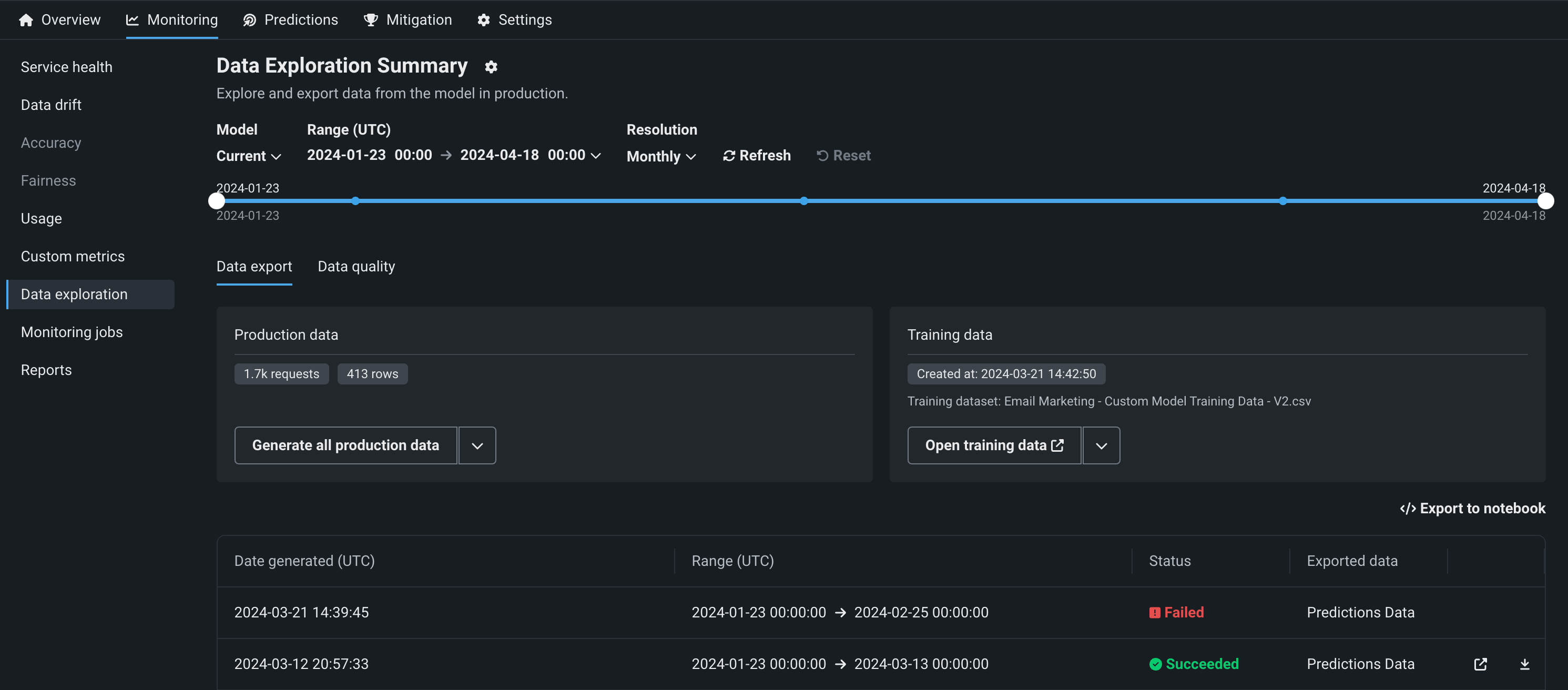
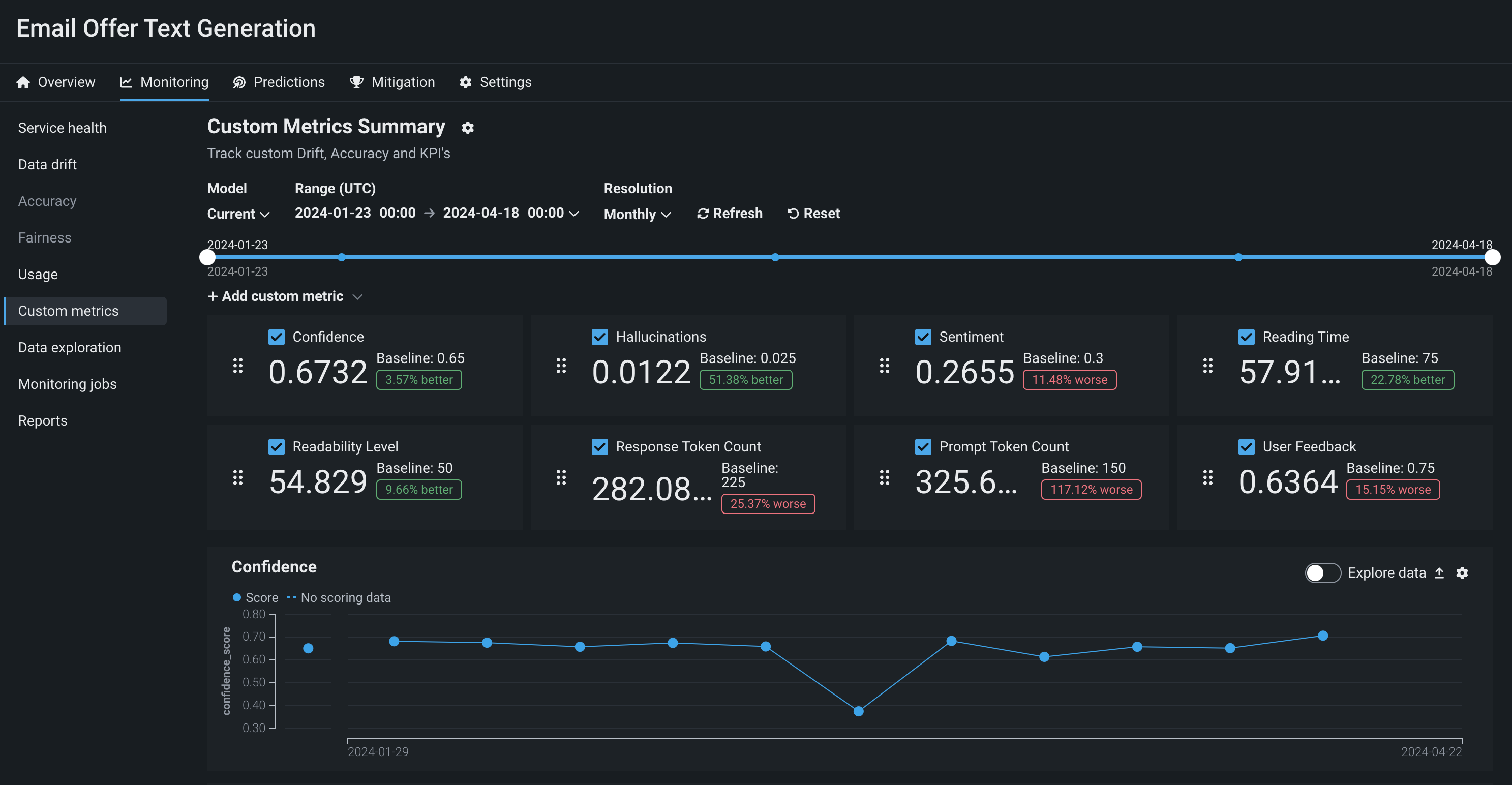
生成モデルのデータドリフト¶
生成モデルの予測データでドリフトを監視するために、DataRobotは新しいプロンプトとレスポンスを、モデル作成時にアップロードしたトレーニングデータのプロンプトおよびレスポンスと比較します。 比較に適切なトレーニングベースラインを提供するには、アップロードされたトレーニングデータセットに、モデルが質問に回答することを想定しているトピックに関連したプロンプトとレスポンスが20行 以上 含まれている必要があります。 これらのプロンプトとレスポンスは、ドキュメントから取得することも、手動で作成することも、生成することもできます。
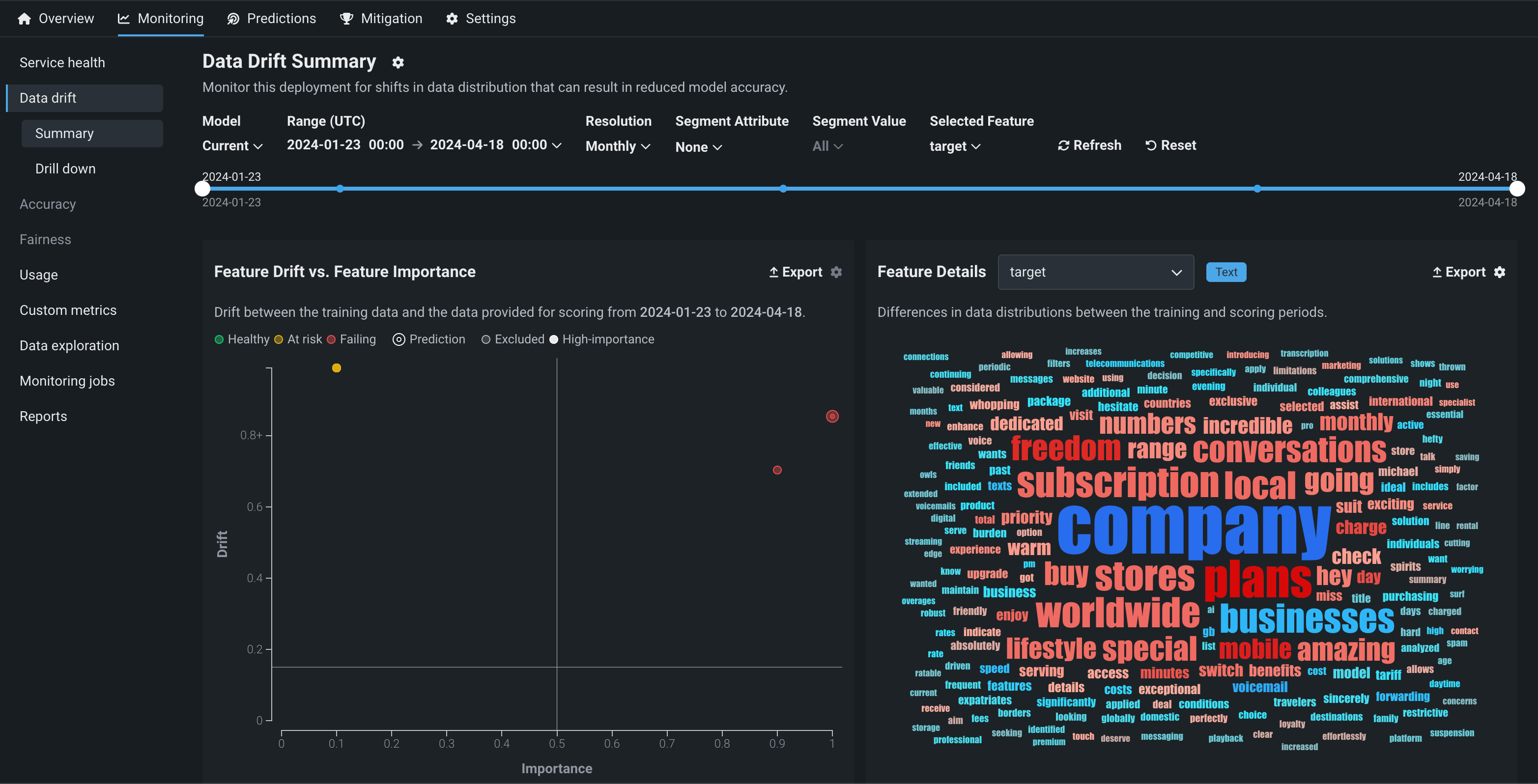
生成モデルのモニタリング > データドリフトタブでは、 特徴量ドリフトと特徴量の有用性の比較、 特徴量の詳細、 時間経過に伴うドリフトのチャートを表示できます。 さらに、 ドリルダウンタブを生成モデルに使用できます。 特定のモデル、期間、または特徴量にフォーカスするようにデータドリフトダッシュボードを調整する方法については、 データドリフトダッシュボードの設定ドキュメントを参照してください。
生成モデルの特徴量の詳細¶
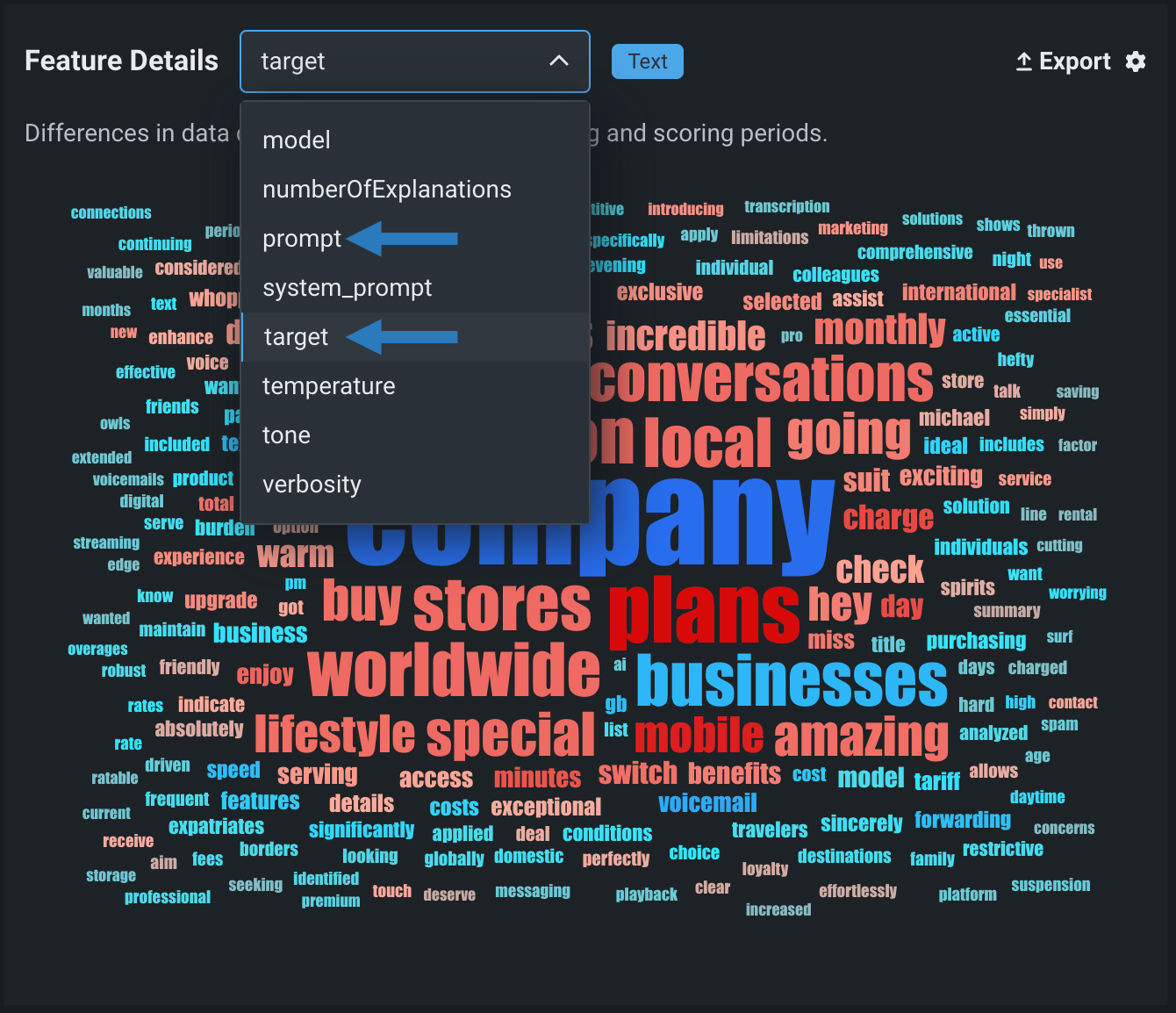
特徴量の詳細チャートには、テキスト生成モデルのための新機能が含まれており、トレーニング期間とスコアリング期間におけるデータセット内の各トークンのデータ分布の違いを視覚化するワードクラウドを提供します。 デフォルトでは、特徴量の詳細チャートには、 質問 (プロンプト)と 答え (ターゲット、モデル完了、出力、または回答)に関する情報が含まれます。 これらはテキスト特徴量です。以下の例では、質問の特徴量は プロンプト で、回答の特徴量は _ターゲット_です。
| 特徴量 | 説明 |
|---|---|
| プロンプト | トレーニング期間とスコアリング期間における各 ユーザープロンプト または 質問 トークンのデータ分布の違いを視覚化し、各トークンがユーザープロンプトデータのデータドリフトにどの程度関与しているかを明らかにするワードクラウド。 |
| ターゲット | トレーニング期間とスコアリング期間における各 モデル出力 または 回答 トークンのデータ分布の違いを視覚化し、各トークンがモデル出力データのデータドリフトにどの程度関与しているかを明らかにするワードクラウド。 |
特徴量の詳細チャートの特徴量
生成モデルの入出力の特徴量名は、モデルのデータ内にある特徴量名に依存します。したがって、上記の例の プロンプト 特徴量と ターゲット 特徴量は、モデルのデータ内の入力列と出力列の名前で置き換えられます。 これらの特徴量名は、生成モデルの 概要タブにあるターゲット列名フィールドとプロンプト列名フィールドに表示されます。
データドリフト追跡の他の特徴量を指定することもできます。たとえば、モデルの _温度_を追跡し、生成モデルのレスポンスの創造性レベルを高い(1)から低い(0)まで監視することができます。
プロンプト や _ターゲット_などのテキスト特徴量の特徴量ドリフトワードクラウドを解釈するには、ユーザープロンプトまたはモデル出力トークンにカーソルを合わせて以下の詳細を表示します。
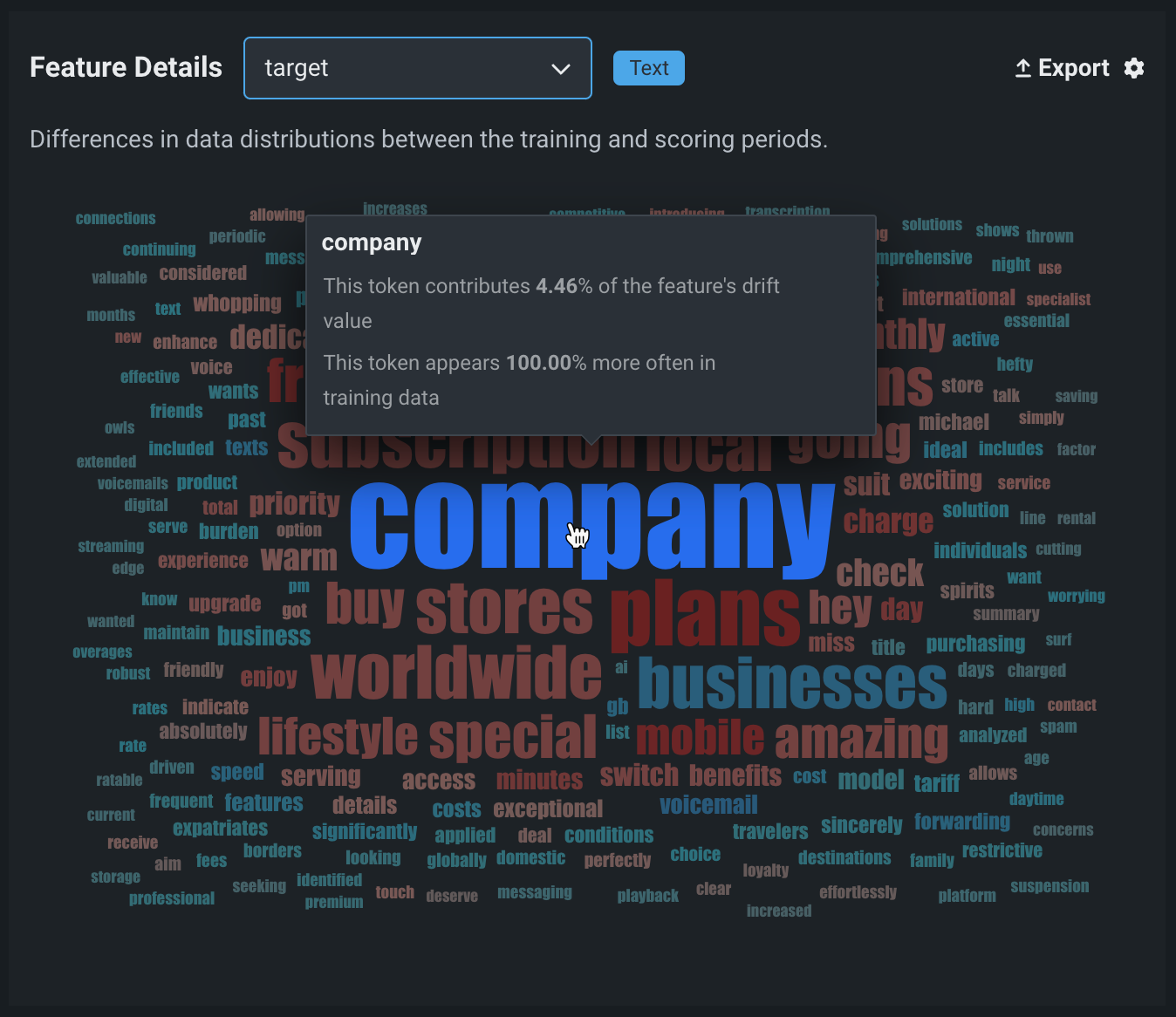
| チャートの要素 | 説明 |
|---|---|
| トークン | ワードクラウド内のワードで表されるトークン化されたテキスト。 テキストサイズはトークンのドリフト貢献度を表し、テキストの色はデータセットの普及率を表します。 このチャートではストップワードは非表示になります。 |
| ドリフト貢献度 | この特定のトークンが、特徴量ドリフト対特徴量の有用性チャートで報告されている、特徴量のドリフト値にどれだけ貢献しているかを示します。 |
| ターゲット分布 | この特定のトークンがトレーニングデータまたは予測データに表示される頻度がどれだけ増加するか。
|
ヒント
ポインターがワードクラウド上にあるとき、上にスクロールするとズームインして、より小さいトークンのテキストを表示できます。