Unsupervised predictive modeling¶
Unsupervised learning uses unlabeled data to surface insights about patterns in your data. Supervised learning, by contrast, uses the other features of your dataset to make predictions. The unsupervised learning setup is described below.
基本を作成¶
ユースケース内から新しいエクスペリメントを作成するには、次の手順に従います。
備考
モデリングを開始ボタンをクリックして、データセットから直接モデリングを開始することもできます。 新しいエクスペリメントの設定ページが開きます。 ここから、以下の手順に従ってください。
特徴量セットを作成¶
Before modeling, you can create a custom feature list from the data explore page. You can then select that list during modeling setup to create the modeling data using only the features in that list. Learn more about feature lists post-modeling here.
エクスペリメントを追加¶
ユースケース内から追加をクリックし、エクスペリメントを選択します。 新しいエクスペリメントの設定ページが開き、ユースケースにロード済みのすべてのデータが一覧表示されます。
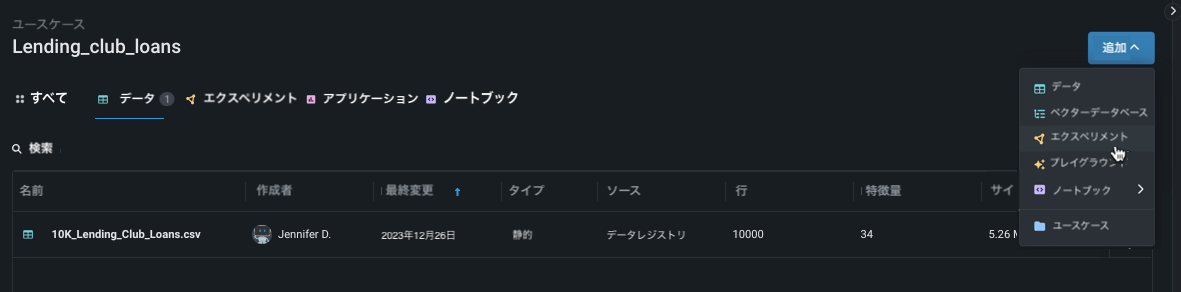
データを追加¶
新しいデータを追加 する(1)か、ユースケースに既にロードされているデータセットを選択する(2)ことにより、エクスペリメントにデータを追加します。
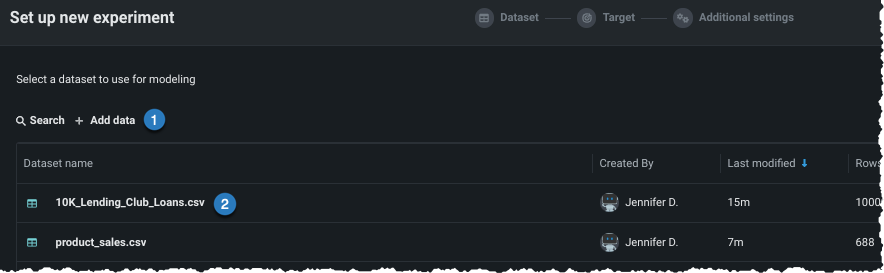
データがユースケースにロードされたら(上記のオプション2と同様)、エクスペリメントで使用するデータセットをクリックして選択します。 ワークベンチは、データのプレビューを開きます。
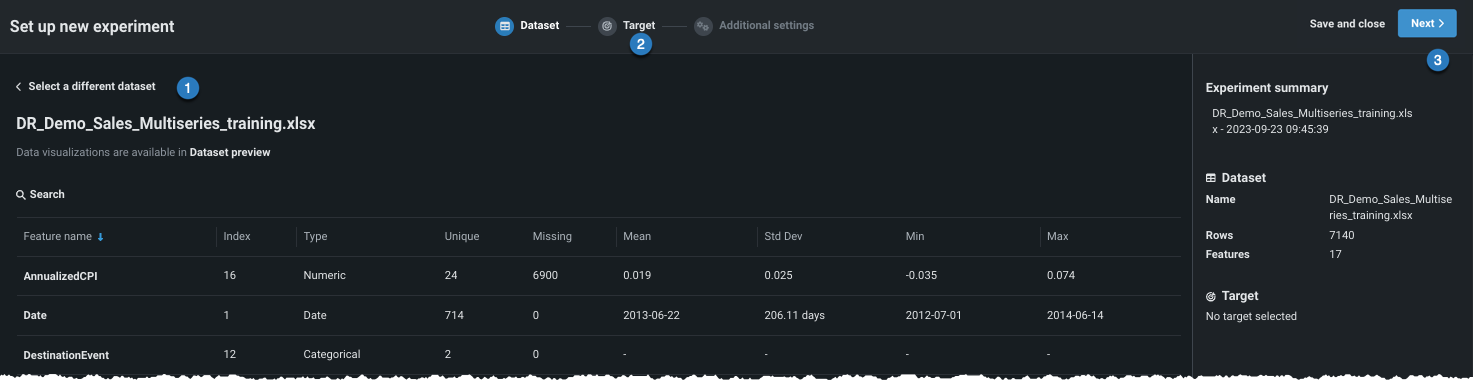
ここから、次のことができます。
| オプション | |
|---|---|
| 1 | クリックして、データリストに戻り、別のデータセットを選択します。 |
| 2 | Click the icon to proceed and set the learning type and target. |
| 3 | Click Next to proceed and set the learning type and target. |
Start modeling setup¶
Once you have proceeded, Workbench prepares the dataset for modeling (EDA 1).
備考
これ以降のエクスペリメントの作成では、エクスペリメントの設定を続行しても(次へ)、終了してもかまいません。 終了を選択すると、変更を破棄するか、すべての進捗をドラフトとして保存するよう促されます。 どちらの場合でも、終了時にはエクスペリメントのセットアップを開始した時点に戻り、EDA1の処理は失われます。 終了してドラフトを保存を選択すると、ドラフトはユースケースディレクトリで利用できます。

ワークベンチで作成したドラフトをDataRobot Classicで開き、ワークベンチでサポートされていない機能を導入する変更を加えた場合、そのドラフトはユースケースにリストされますが、Classicインターフェイス以外からはアクセスできません。
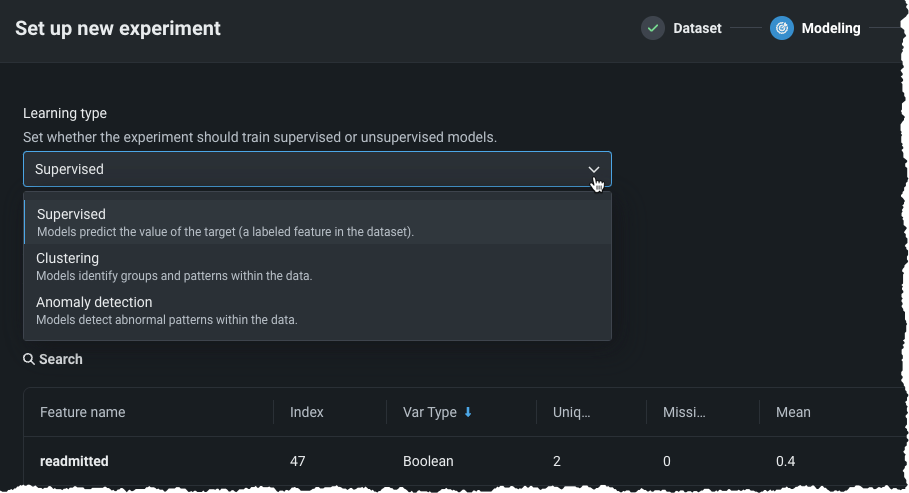
Set learning type¶
一般的にDataRobotはラベル付けされたデータを使用し、モデルを構築するために教師あり学習法が使用されます。 教師あり学習では、ターゲットを指定すると、データセットのその他の特徴量を使用してそのターゲットを予測することができるモデルが構築されます。
In unsupervised learning, no target is specified and the data is unlabeled. 教師あり学習としての予測を生成する代わりに、教師なし学習はデータ内のパターンについてインサイトし、「データに異常がないか?」 「自然クラスターがあるか?」といった質問に答えます。
To create an unsupervised learning experiment after EDA1 completes, from the Learning type dropdown, choose one of:
| 学習タイプ | 説明 |
|---|---|
| 教師あり | Builds models using the other features of your dataset to make predictions; this is the default learning type. |
| クラスタリング(教師なし) | Using no target and unlabeled data, builds models that group similar data and identify segments. |
| 異常検知(教師なし) | Using no target and unlabeled data, builds that detect abnormalities in the dataset. |
See the feature considerations for things to know when working with unsupervised modeling.
クラスタリング¶
Clustering lets you explore your data by grouping and identifying natural segments from many types of data—numeric, categorical, text, image, and geospatial data—independently or combined. クラスタリングモードでは、DataRobotは、データセット内の列で明示的にキャプチャされていない潜在動作をキャプチャします。 クラスタリングは、データに明示的なラベルが付いておらず、データがどういった形であるかを判断する必要がある場合に有用です。 クラスタリングの例には次のようなものが考えられます:
-
テキストコレクションにおける、トピック、タイプ、分類、および言語の検出。 クラスタリングは、テキスト特徴量と他の特徴量の型が混在するデータセットにも、トピックモデリングのための単一のテキスト特徴量にも適用できます。
-
予測マーケティングキャンペーンを実行する前の、カスタマーベースのセグメント化。 顧客の主要グループを識別し、各グループにさまざまなメッセージを送信します。
-
画像のコレクションにおいて潜在的なカテゴリーを把握します。
クラスタリングの設定¶
To set up a clustering experiment, set the Learning type to Clustering. Because unsupervised experiments do not specify a target, the Target feature field is removed and the other basic settings become available.
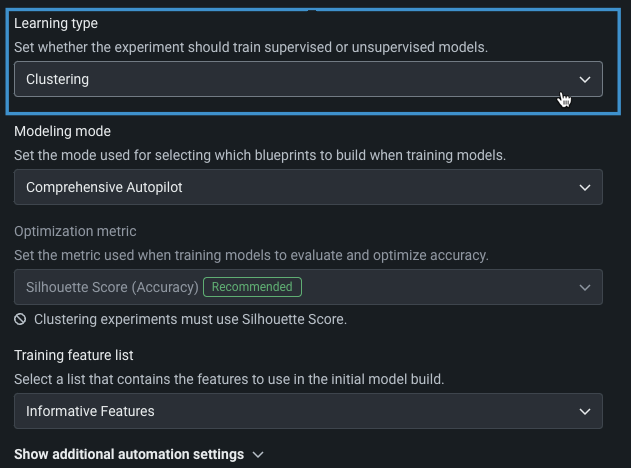
The table below describes each field:
| フィールド | 説明 |
|---|---|
| モデリングモード | モデリングモード。DataRobotがトレーニングするブループリントに影響します。 Comprehensive Autopilot, the default, runs all repository blueprints on the maximum Autopilot sample size to provide the most accurate similarity groupings. |
| 最適化指標 | Defines how DataRobot scores clustering models. For clustering experiments, Silhouette score is the only supported metric. |
| トレーニング特徴量セット | Defines the subset of features that DataRobot uses to build models. |
Set the number of clusters¶
DataRobotは固定数のクラスターの設定をサポートする各アルゴリズムの1つのモデルをトレーニングします(K平均法またはGaussian混合モデルなど)。 The number trained is based on what is specified in Number of clusters, with default values based on the number of rows in the dataset.
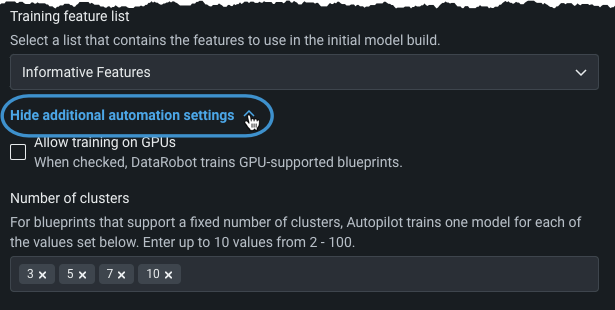
For example, if the numbers are set as in the image above, DataRobot runs clustering algorithms using 3, 5, 7, 10 clusters.
To customize the number of clusters that DataRobot trains, expand Show additional automation settings and enter values within the provided range.
When settings are complete, click Next and Start modeling.
異常検知¶
異常検知(外れ値検知または新規性検知とも呼ばれます)は、教師なし学習の応用の一種です。 異常検知は、ネットワークとサイバーセキュリティ、保険詐欺、クレジットカード詐欺など、多くの通常のトランザクションと少量の異常トランザクションが存在する場合に使用できます。 教師ありの方法は、このような少数の異常ケースの予測において優れていますが、関連データにラベルを設定するにはコストと時間がかかります。 See the feature considerations for important information about working with anomaly detection.
異常検知の設定¶
To set up an anomaly detection experiment, set the Learning type to Anomaly detection. パーティション特徴量が必要です。
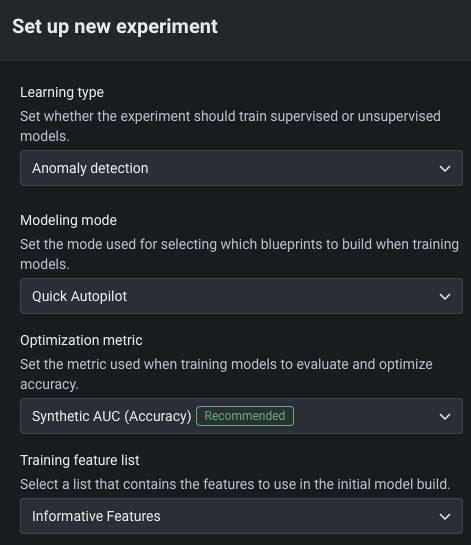
| フィールド | 説明 |
|---|---|
| モデリングモード | モデリングモード。DataRobotがトレーニングするブループリントに影響します。 Quick Autopilot, the default, provide a base set of models that build and provide insights quickly. |
| 最適化指標 | Defines how DataRobot scores clustering models. For anomaly detection experiments, Synthetic AUC is the default, and recommended, metric. |
| トレーニング特徴量セット | Defines the subset of features that DataRobot uses to build models. |
When settings are complete, click Next and Start modeling.
Unsupervised insights¶
モデリングを開始すると、DataRobotでリーダーボードにモデルが入力されます。 The following table describes the insights available for unsupervised anomaly detection (AD) and clustering for predictive experiments.
| インサイト | 異常検知 | クラスタリング |
|---|---|---|
| ブループリント | はい | はい |
| 特徴量ごとの作用 | はい | はい |
| 特徴量のインパクト | はい | はい |
| 予測の説明* | はい | いいえ |
| クラスターインサイト** | いいえ | はい |
* XEMP only and Classic only
** 時間認識のみ
機能に関する注意事項¶
Unsupervised learning availability is license-dependent:
| 特徴量 | 予測 | 日付/時刻のパーティション | 時系列 |
|---|---|---|---|
| 異常検知 | 一般提供 | 一般提供 | プレミアム( )(系列ライセンス) |
| クラスタリング | Premium (Clustering license) | 使用できません | プレミアム( )(系列ライセンス) |
クラスタリングに関する注意事項¶
クラスタリングを使用する場合、以下の点を考慮してください。
- クラスタリングプロジェクトのデータセットは、5GB未満である必要があります。
-
以下はサポートされていません。
- リレーショナルデータ(集計されたカテゴリー特徴量など)
- ワードクラウド
- 特徴量探索プロジェクト
- 予測の説明
- スコアリングコード
- Composable ML
-
クラスタリングモデルは、専用の予測サーバーにデプロイできますが、ポータブル予測サーバー(PPS)および監視エージェントはサポートされていません。
- クラスターの最大数は100です。
異常検知に関する注意事項¶
異常検知プロジェクトに従事する場合は、次の点にご注意ください:
-
数値が欠損している場合、DataRobotは、中央値(定義上異常ではない値)で補完します。
-
データセットの特徴量数が多いほど、DataRobotは異常検知するのに時間がかかり、結果を解釈することがより困難になります。 特徴量が1000以上の場合は、異常スコアの解釈が難しくなり、異常の根本原因を特定することが困難になる可能性があることに注意してください。
-
1000を超える特徴量で異常検知モデルをトレーニングした場合、解釈タブのインサイトは使用できません。 これには、特徴量のインパクト、特徴量ごとの作用、予測の説明、ワードクラウド、ドキュメントのインサイト(該当する場合)が含まれます。
-
異常スコアは正規化されるので、DataRobotでは、正常からあまり離れていない場合でも一部の行が異常値としてラベル付けされます。 トレーニングデータの場合、最も異常な行のスコアは1になります。一部のモデルでは、テストデータや外部データは、その行がトレーニングデータの他の行よりも異常である場合に、異常スコアの予測値が1よりも大きくなることがあります。
-
合成AUCは、トレーニングデータの合成異常やインライアの作成に基づく近似です。
-
合成AUCのスコアは、画像特徴量を含むアンサンブルでは使用できません。
-
DataRobotブループリントからトレーニングされた異常検知モデルの特徴量のインパクトは、常にSHAPを使用して計算されます。 ユーザーブループリントからの異常検知モデルの場合、特徴量のインパクトは、Permutationベースのアプローチを使用して計算されます。
-
時系列の異常検知は、ピュアテキストデータの異常に対してまだ最適化されていないため、データにはいくつかの数値列またはカテゴリー列を含める必要があります。
-
以下の方法が実装されていて、チューニング可能です。
| 方法 | 詳細 |
|---|---|
| Isolation Forest |
|
| 平均絶対偏差(MAD) |
|
| 1クラスのSupport Vector Machine(SVM) |
|
| Local Outlier Factor(LOF) |
|
| Mahalanobis Distance |
|
-
以下はサポートされていません。
-
スマートダウンサンプリングなどの、加重またはオフセットを含むプロジェクト
-
スコアリングコード
-
異常検知では地理空間データは考慮されません(モデルは構築されますが、これらのデータ型はブループリントに含まれません)。
さらに、時系列プロジェクトの場合は、次のチェックも実行されます。
- ミリ秒データは、データのきめ細かさの下限です。
- データセットは1GB未満である必要があります。
- いくつかのブループリントは、純粋なカテゴリーデータには実行できません。
- 一部のブループリントは特徴量セットに関連付けられており、特定の特徴量を想定しています(たとえば、ボリンジャーバンドローリングは、ロバストZスコア特徴量だけを含む特徴量セットに対して実行する必要があります)。
- For time series projects with periodicity, because applying periodicity affects feature reduction/processing priorities, if there are too many features then seasonal features are also not included in Time Series Extracted and Time Series Informative Features lists.
また、時系列の注意事項が適用されます。