SageMakerでのモデルのデプロイ¶
この記事では、DataRobotのスコアリングコードとMLOpsエージェントを使用して、AWS SageMakerにデプロイされた外部モデルを予測し、監視する方法を説明します。
DataRobotでは、サポートされているモデルであれば、スコアリングコード生成が自動的に実行されます。コードを利用できるかどうかは、リーダーボード上のアイコンによって示されます。 このオプションを使用すると、モデルの検定済みJavaスコアリングコードを近似なしでダウンロードできます。コードは任意の環境に容易にデプロイすることができ、DataRobotアプリケーションに依存しません。
AWS SageMakerにデプロイする理由¶
DataRobotでは、プラットフォームに完全に統合されたスケーラブルな予測サーバーを提供しますが、AWS SageMaker上でのデプロイを行う理由がいくつかあります。
- 会社の方針またはガバナンス上の判断。
- DataRobotモデルの上のカスタム機能。
- API呼び出しのオーバーヘッドなしでの低レイテンシースコアリング。 一般的に、JavaコードはPython APIを介したスコアリングよりも高速です。
- DataRobot APIと通信できない可能性のあるシステムへのモデル統合機能。
MLOpsのエージェントが設定されていない限り、事前定義済みデータのドリフトや精度の追跡は利用できません。
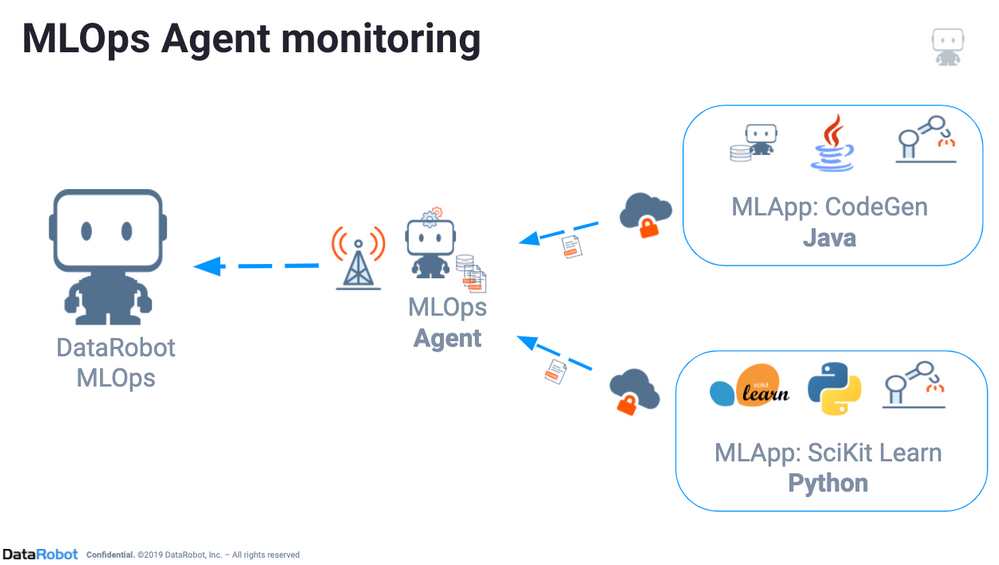
スコアリングコードのデプロイ環境として、AWS SageMakerを活用できます。 AWS SageMakerを使用すると、機械学習モデルを(いくつかの対応形式で)取り込み、APIエンドポイントとして公開できます。 DataRobotは、AWS SageMakerにデプロイされるDockerコンテナ内のモデルとともにMLOpsエージェントをパッケージ化します。
スコアリングコードをダウンロードする¶
DataRobotモデルをAWS Sagemakerにデプロイするための最初のステップは、スコアリングコードJARファイルをリーダーボードから、またはデプロイ(モデルメニュー内の[ダウンロード]タブの下)からダウンロードすることです。
MLOpsエージェントの設定¶
MLOpsライブラリを使用すると、DataRobotモデルと同じように、独自のモデルで同じ監視機能を取得できます。 MLOpsライブラリはインターフェイスを提供し、MLOpsサービスに指標を報告できます。ここでは、デプロイの統計と予測を監視し、特徴量のドリフトを追跡し、モデルのパフォーマンスを分析するためのその他のインサイトを得ることができます。 詳細については、MLOpsエージェントのドキュメントを参照してください。
MLOpsライブラリは、DataRobotからダウンロードしたスコアリングコードモデルを含む、あらゆるタイプのモデルで使用できます。 DataRobotは、JavaまたはPython(Python3)でのMLOpsライブラリのバージョンをサポートしています。
MLOpsエージェントは、DataRobot APIを使用するか、またはDataRobot UIからtarballとしてダウンロードできます。
アプリケーションからユーザーアイコンを選択し、[開発者ツール]ページに移動して、ダウンロード可能なtarballを見つけます。
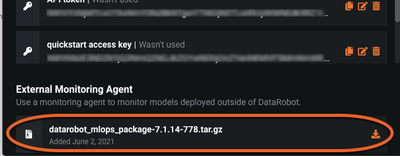
- DataRobot MLOpsエージェントとライブラリをインストールします。
- エージェントを設定
- エージェントサービスを開始します。
- エージェントバッファディレクトリ(設定ファイル内の
MLOPS_SPOOLER_DIR_PATH)が存在することを確認します。 - 指標のレポートに使用するチャネルを設定します。 (MLOpsエージェントはSQS、Google Pub Sub、Spool File、RabbitMQなど、多数のチャネルで動作するように設定できます)。 この例ではSQSを使用します。
- MLOpsライブラリを使用してデプロイからの指標をレポートします。
MLOpsライブラリは、ローカルに指標をバッファ処理するため、デプロイを遅延することなく高スループットを可能にします。 また、MLOpsサービスに指標を転送して、デプロイインベントリを介してモデルのパフォーマンスを監視できるようにします。
デプロイの作成¶
デプロイを作成するためのヘルパースクリプトは、MLOpsエージェントのtarballのサンプルディレクトリにあります。
すべてのサンプルには、関連するデプロイを作成するための独自のスクリプトがあり、そのtools/create_deployment.pyスクリプトを使用して独自のデプロイを作成できます。
デプロイ作成スクリプトはMLOpsサービスと直接やり取りするため、MLOpsサービスに接続できるマシン上で実行する必要があります。
すべてのサンプルには説明ファイル(<name>_deployment_info)と、デプロイを作成するためのスクリプトがあります。
- 説明ファイルを編集して、デプロイを設定します。
- 特徴量のドリフト追跡を有効または無効にする場合は、説明ファイルの
trainingDatasetフィールドを追加または除外に設定します。 - スクリプト
<name>_create_deployment.shを実行して新しいデプロイを作成します。
このスクリプトを実行すると、デプロイの実装に使用できるデプロイIDと初期モデルIDが返されます。 または、DataRobot GUIからデプロイを作成します。
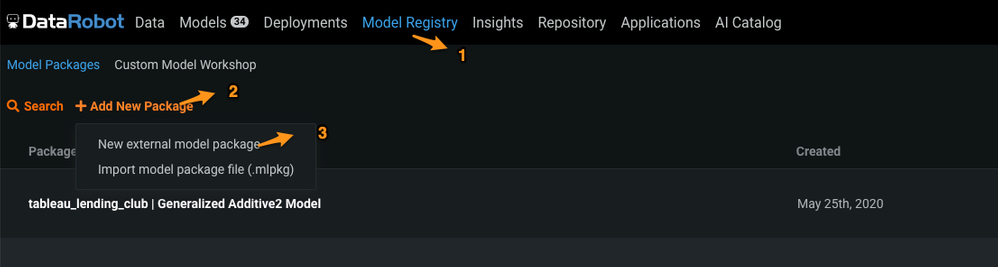
DataRobot GUIからデプロイを作成するには、次の手順を使用します。
- DataRobot GUIにログインします。
- モデルレジストリ(1)を選択し、新しいパッケージを追加(2)をクリックします。
-
ドロップダウンで、新しい外部モデルパッケージ(3)を選択します。
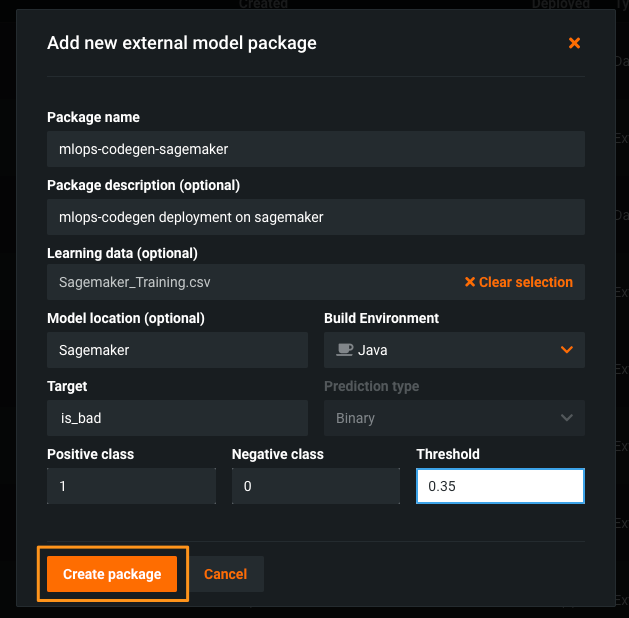
-
デプロイに必要なすべての情報を入力してから、パッケージを作成をクリックします。
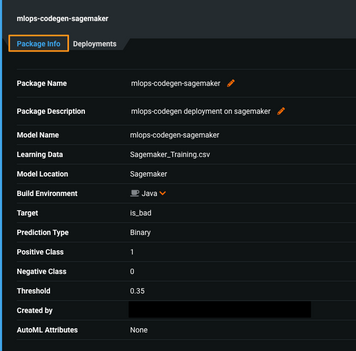
-
デプロイタブを選択しモデルパッケージをデプロイをクリックして、このページの詳細を確認し、デプロイを作成(ページ上部の右側)をクリックします。
-
トグルボタンを使用すると、ドリフト追跡、予測のセグメント分析、その他のデプロイ設定を有効にすることができます。
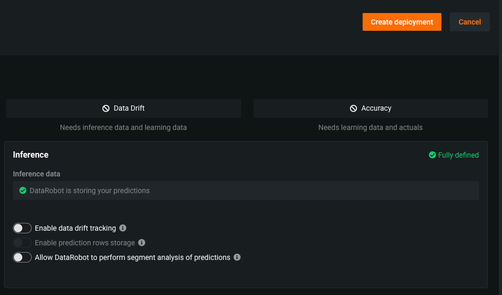
-
必要な詳細を入力してデプロイを作成をクリックすると、次のダイアログボックスが表示されます。
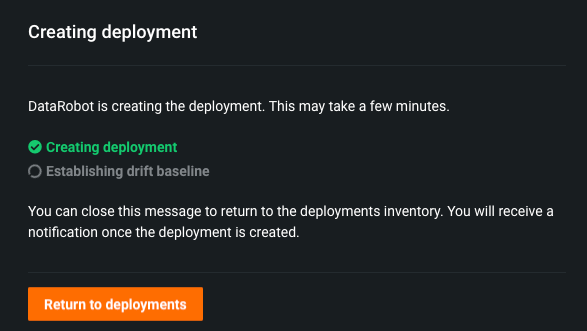
-
新しく作成されたデプロイの詳細を確認できます。
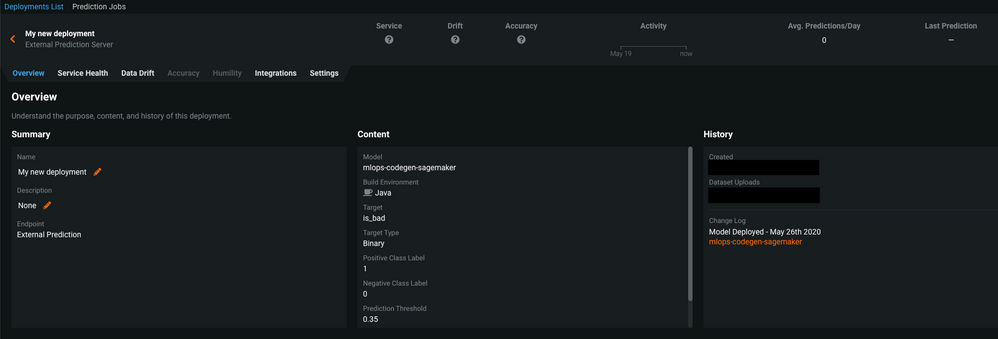
デプロイのインテグレーションタブを選択すると、監視コードを確認できます。
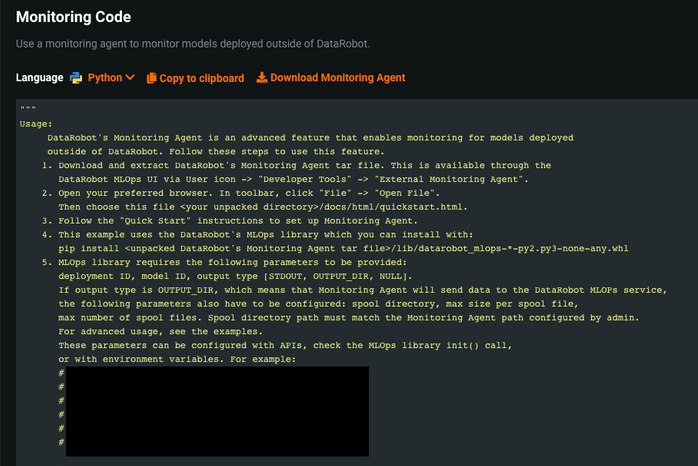
この監視コードを下にスクロールすると、
DEPLOYMENT_IDとMODEL_IDが表示されます。これは特定のモデルデプロイを監視するためにMLOpsライブラリによって使用されます。
スコアリングコードをアップロード¶
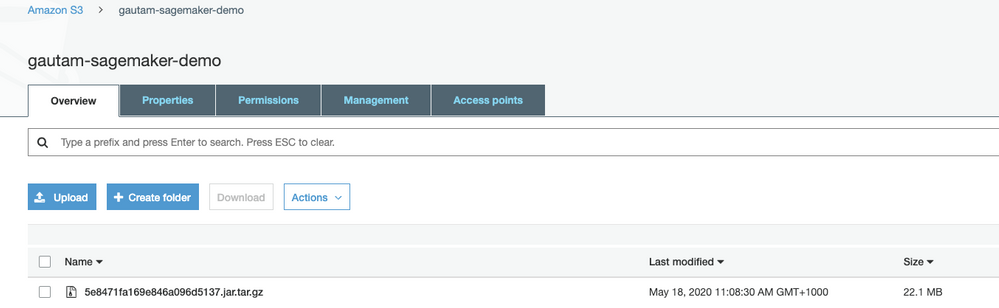
スコアリングコードJARファイルをダウンロードしたら、SageMakerがアクセスできるAWS S3バケットにアップロードします。
SageMakerはtar.gzアーカイブ形式でS3バケットにアップロードされることを想定しています。 次のコマンドを使用して、モデル(スコアリングコードJARファイル)を圧縮します。
tar -czvf 5e8471fa169e846a096d5137.jar.tar.gz 5e8471fa169e846a096d5137.jar
macOSを使用している場合は、tarコマンドはtar.gzパッケージに隠しファイルを追加し、デプロイ中に問題を引き起こします。上記のコマンドの代わりに、以下のコマンドを使用します。
COPYFILE_DISABLE=1 tar -czvf 5e8471fa169e846a096d5137.jar.tar.gz 5e8471fa169e846a096d5137.jar
tar.gzアーカイブを作成したら、S3バケットにアップロードします。
Dockerイメージのカスタマイズ¶
DataRobotには公開されたDockerイメージ(scoring-inference-code-SageMaker:latest)があり、Amazon ECRへの推論コードが含まれています。 このDockerイメージをベースイメージとして使用し、MLOpsエージェントを含むカスタマイズされたDockerコンテナレイヤーを追加できます。
FROM datarobotdev/scoring-inference-code-sagemaker
RUN apk add --no-cache curl tar bash procps
RUN apk add --no-cache --upgrade bash
COPY agent-6.1.0.jar /agent/
COPY stdout.log4j2.properties /conf/
COPY mlops.agent.conf.yaml /conf/
COPY agent-entrypoint.sh /
RUN chmod 755 /agent-entrypoint.sh
ENTRYPOINT sh /agent-entrypoint.sh
シェルスクリプトagent-entrypoint.shはスコアリングコードをJARファイルとして実行し、MLOpsエージェントJARも開始します。
java -Dlog.file=${AGENT_LOG_PATH} \
-Dlog4j.configurationFile=file:${AGENT_LOG_PROPERTIES} \
-cp ${AGENT_JAR_PATH} com.datarobot.mlops.agent.Agent \
--config ${AGENT_CONFIG_YAML} Collapse &
java -jar /opt/scoring/sagemaker-api.jar
MLOps設定ファイルは、デフォルトでAmazon SQSサービスで指標をレポートするように設定されています。 mlops.agent.conf.yamlでSQSにアクセスするためのURLを指定します。
- type: SQS_SPOOL
- details: {name: "sqsSpool", queueUrl: " [https://sqs.us-east-1.amazonaws.com/123456789000/mlops-agent-sqs](https://sqs.us-east-1.amazonaws.com/123456789000/mlops-agent-sqs%C2%A0) "}
次に、DockerfileからDockerイメージを作成します。 Dockerfileを含むディレクトリに移動し、次のコマンドを実行します。
docker build -t codegen-mlops-SageMaker
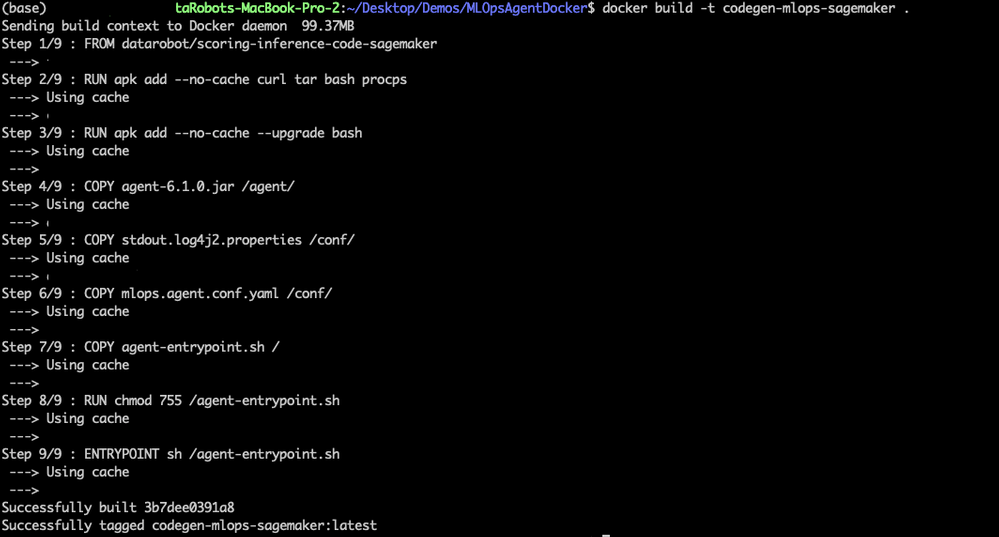
これにより、DockerfileからDockerイメージが作成されます(参照Dockerfileはソースコードと共有されます)。
DockerイメージをAmazon ECRに公開¶
次に、Amazon ECRにDockerイメージを公開します。
-
イメージのプッシュ先のAmazon ECRレジストリに対して、Dockerクライアントを認証します。 使用するレジストリごとに認証トークンを取得する必要があり、トークンは12時間有効です。 この例にリストされているさまざまな認証オプションについては、Amazonのドキュメントを参照してください。
-
この例では、トークンベースの認証を使用します。
TOKEN=$(aws ecr get-authorization-token --output text --query 'authorizationData[].authorizationToken') curl -i -H "Authorization: Basic $TOKEN" <https://123456789000.dkr.ecr.us-east-1.amazonaws.com/v2/SageMakertest/tags/list> -
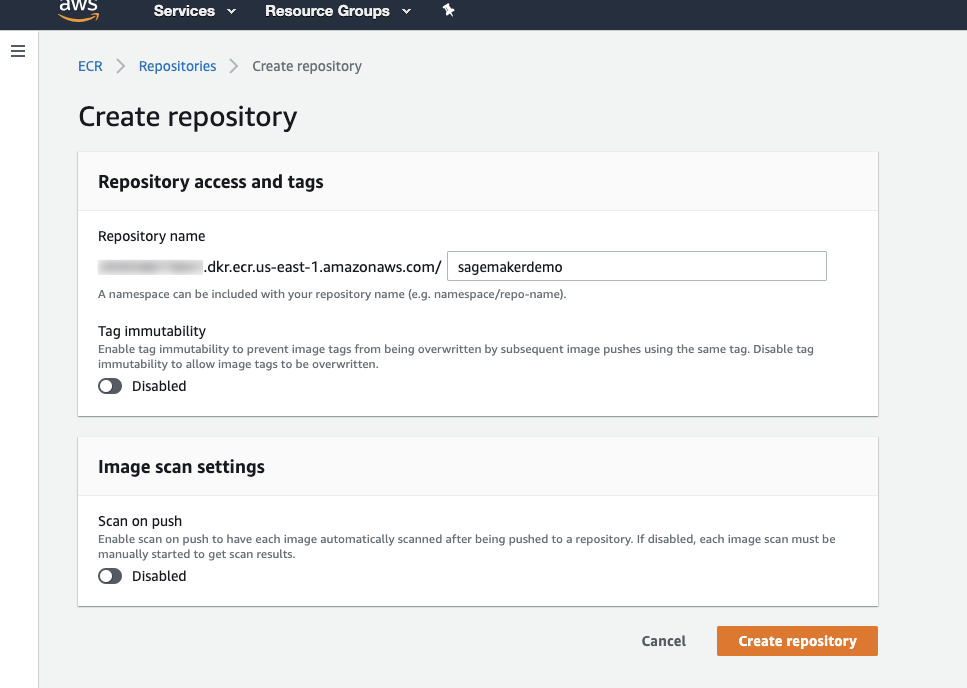
イメージをプッシュできるAmazon ECRレジストリを作成します。
aws ecr create-repository --repository-name SageMakerdemoこれにより、次のような出力結果が得られます。

AWSマネジメントコンソールのECRサービス > リポジトリの作成からレジストリを作成することもできます(リポジトリ名を指定する必要があります)。
-
プッシュするイメージを特定します。 Dockerイメージコマンドを実行して、システム上のイメージを一覧表示します。
docker image ls -
イメージにタグを付けてAWS ECRにプッシュします。 推論コードとMLOpsエージェントを含むDockerイメージのIDを見つけます。
-
Amazon ECRレジストリ、リポジトリ、および使用するオプションのイメージタグ名の組み合わせを使用して、イメージにタグを付けます。 レジストリ形式は
aws_account_id.dkr.ecr.region.amazonaws.comです。 リポジトリ名は、イメージ用に作成したリポジトリと一致する必要があります。 イメージタグを省略すると、DataRobotは最新のタグを使用します。docker tag <image_id> "${account}.dkr.ecr.${region}.amazonaws.com/SageMakerdemo"
-
イメージをプッシュします。
docker push ${account}.dkr.ecr.${region}.amazonaws.com/SageMakermlopsdockerized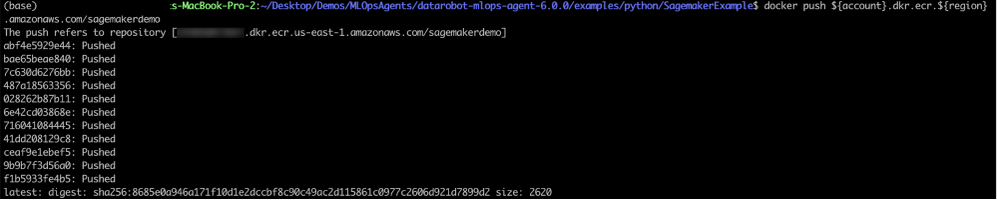
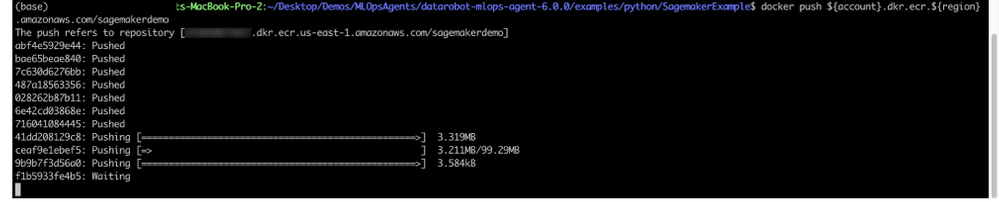
イメージがプッシュされたら、AWSマネジメントコンソールから検証できます。
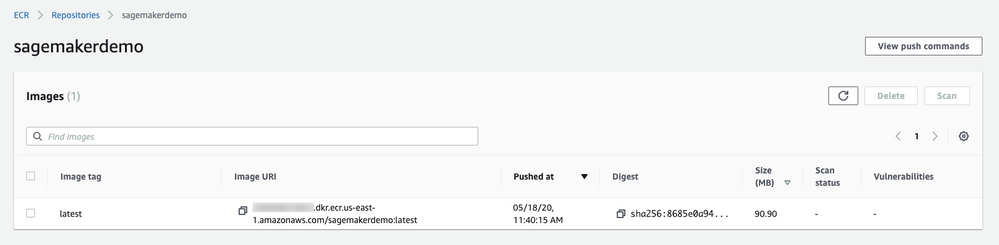
モデルの作成¶
-
AWSにサインインして、検索バーに「SageMaker」と入力します。 最初の結果(Amazon Sagemaker)を選択すると、SageMakerのコンソールに入り、モデルを作成できます。
-
アカウントに既存のロールがない場合、IAMロールフィールドで、ドロップダウンから新しいロールの作成を選択します。 このオプションを選択すると、必要な権限のある役割が作成され、現在のユーザーのインスタンスに割り当てられます。
-
Amazon SageMaker > モデル > モデルの作成を選択します。
-
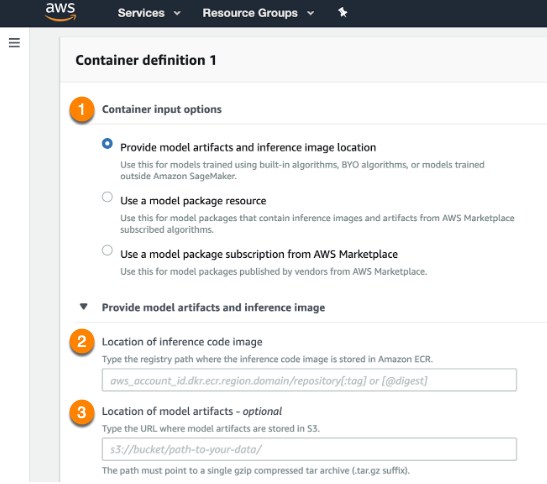
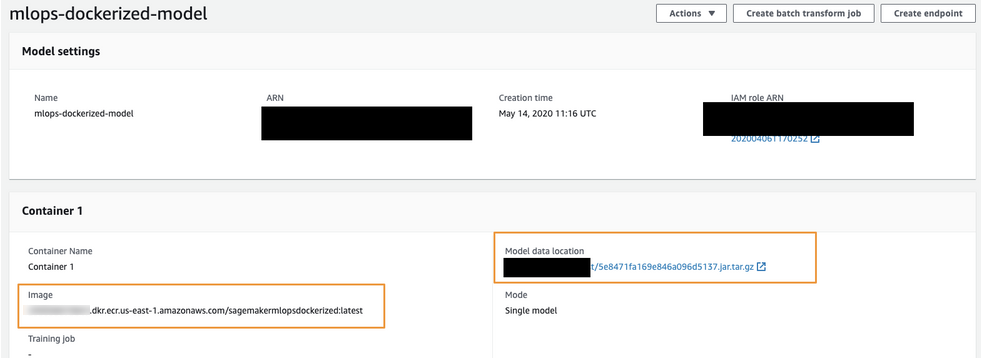
Container input optionsフィールド(1)でProvide model artifacts and inference image location(モデルアーティファクトおよび推論イメージの場所を指定)を選択します。 S3バケット内のスコアリングコードイメージ(モデル)の場所(2)および推論コードを含むDockerイメージのレジストリパス(3)を指定します。
-
完了したら、フィールドの下にあるAdd container(コンテナを追加)をクリックします。
最終的に、モデル設定は次のようになります。
-
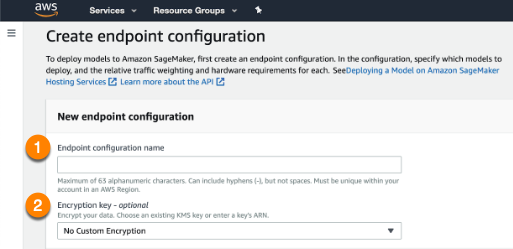
左側のダッシュボードを開き、Endpoint configurations(エンドポイント設定)ページに移動して、新しいエンドポイント設定を作成します。 アップロードしたモデルを選択します。
-
エンドポイント設定に名前を付け(1)、必要に応じて暗号化キーを提供(2)します。 完了したら、ページの下部にあるCreate endpoint configuration(エンドポイント設定を作成)を選択します。
-
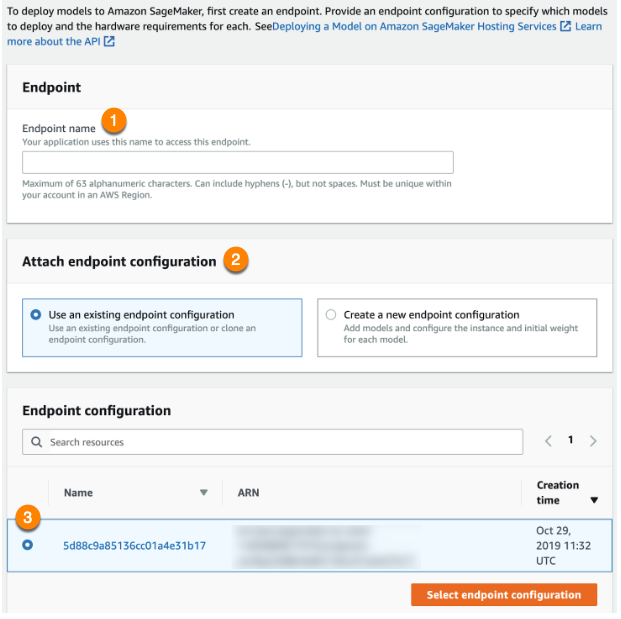
ダッシュボードを使用してEndpoints(エンドポイント)に移動し、新しいエンドポイントを作成します。
-
エンドポイントに名前を付け(1)、既存のエンドポイント設定を使用(2)します。 作成したばかりの設定(3)を選択し、エンドポイント設定を選択します。エンドポイントの作成が完了したら、モデルで予測リクエストを作成できます。 エンドポイントがリクエストを処理する準備ができると、ステータスがInServiceに変わります。
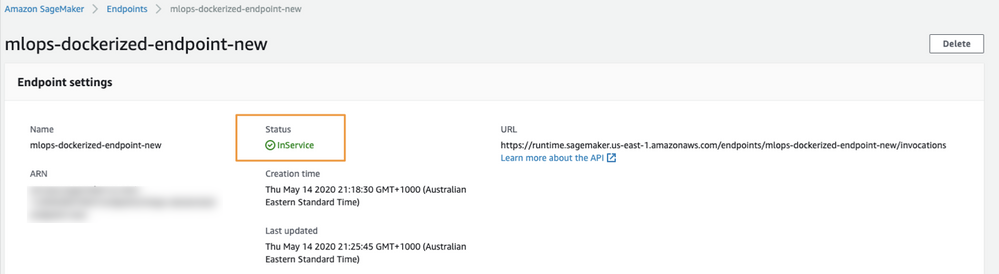
予測を作成する¶
SageMakerエンドポイントのステータスがInServiceに変わると、このエンドポイントに対する予測を開始できます。 この例では、Lending Clubデータを使用して予測をテストします。
コマンドラインからエンドポイントをテストして、エンドポイントが応答していることを確認します。
次のコマンドを使用して、テスト予測を行い、データをCSV文字列の本文に渡します。 使用する前に、AWS CLIがインストールされていることを確認してください。
aws SageMaker-runtime invoke-endpoint --endpoint-name mlops-dockerized-endpoint-new

これで、コードをDataRobotの外部で使用して予測を作成することができます。 このスクリプトは、DataRobot MLOpsライブラリを使用して、作成したデプロイから確認できるDataRobotアプリケーションに、折り返し指標を報告します。
import time
import random
import pandas as pd
import json
import boto3
from botocore.client import Config
import csv
import itertools
from datarobot_mlops.mlops import MLOps
import os
from io import StringIO
"""
This is sample code and may not be production ready
"""
runtime_client = boto3.client('runtime.sagemaker')
endpoint_name = 'mlops-dockerized-endpoint-new'
cur_dir = os.path.dirname(os.path.abspath(__file__))
#dataset_filename = os.path.join(cur_dir, "CSV_10K_Lending_Club_Loans_cust_id.csv")
dataset_filename = os.path.join(cur_dir, "../../data/sagemaker_mlops.csv")
def _feature_df(num_samples):
df = pd.read_csv(dataset_filename)
return pd.DataFrame.from_dict(df)
def _predictions_list(num_samples):
with open(dataset_filename, 'rb') as f:
payload = f.read()
result = runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
Body=payload,
ContentType='text/csv',
Accept='Accept'
)
str_predictions = result['Body'].read().decode()
df_predictions = pd.read_csv(StringIO(str_predictions))
#list_predictions = df_predictions['target_1_PREDICTION'].values.tolist()
list_predictions = df_predictions.values.tolist()
print("number of predictions made are : ",len(list_predictions))
return list_predictions
def main():
num_samples = 10
# MLOPS: initialize mlops library
# If deployment ID is not set, it will be read from MLOPS_DEPLOYMENT_ID environment variable.
# If model ID is not set, it will be ready from MLOPS_MODEL_ID environment variable.
mlops = MLOps().init()
features_df = _feature_df(num_samples)
#print(features_df.info())
start_time = time.time()
predictions_array = _predictions_list(num_samples)
print(len(predictions_array))
end_time = time.time()
# MLOPS: report the number of predictions in the request and the execution time.
mlops.report_deployment_stats(len(predictions_array), (end_time - start_time) * 1000)
# MLOPS: report the prediction results.
mlops.report_predictions_data(features_df=features_df, predictions=predictions_array)
# MLOPS: release MLOps resources when finished.
mlops.shutdown()
if __name__ == "__main__":
main()
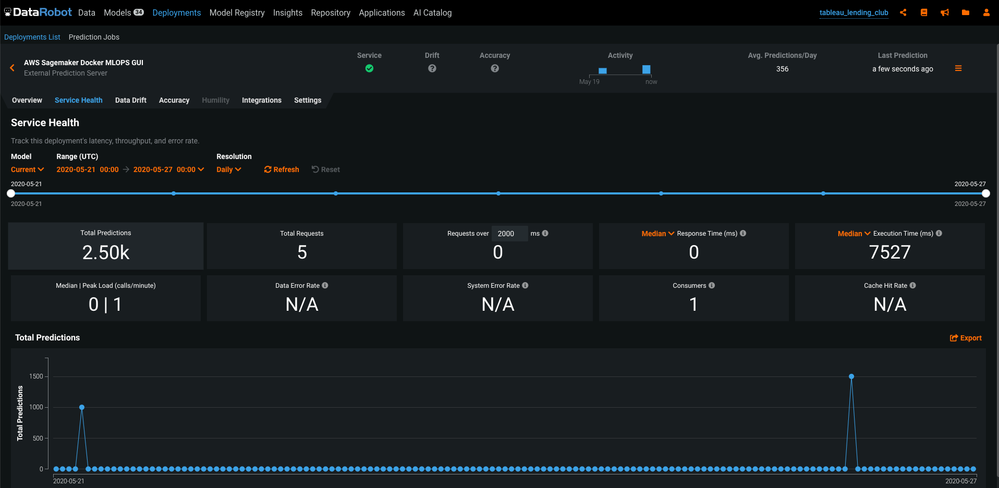
モデル監視¶
デプロイに戻り、サービスの正常性タブをチェックしてモデルを監視します。 この場合、MLOpsライブラリは予測指標をAmazon SQSチャネルに報告しています。 スコアリングコードとともにSageMakerにデプロイされたMLOpsエージェントは、これらの指標をSQSチャネルから読み取り、それらをサービスの正常性タブに報告します。