データサイエンス¶
一般的なデータサイエンス¶
ご想像のとおり、一般的な質問が多数寄せられます。
サイドカーモデルとは?¶
ELI5:たとえば、道で見えるものだけを頼りに走行しているオートバイのドライバーがいるとします。 時には、ドライバーが少し混乱してしまい、正しい判断を下すには手助けが必要になることもあります。 そこでサイドカーが登場します。 サイドカーは、乗客がオートバイのドライバーの横に座っているようなものです。 この乗客は異なる視点(または地図)を持ち、ドライバーにアドバイスまたはガイダンスを提供できます。 (道路などの)穴、近道、またはプロンプトインジェクション攻撃など、ドライバーに見えないことに気づくかもしれません。
ガードモデルも一種のサイドカーモデルと考えられると思いますが、社内でそのように例えられるかどうかはわかりません。
DataRobotがホストするカスタム指標では、サイドカーモデルは、実際のレスポンスを返すLLMとは異なるモデルですが、プロンプトが有害なインジェクション攻撃であったかどうかなどについて判断できます。
格付表とGAMとは?¶
格付表とは、「運転経験や事故回数がこの範囲にあれば、この保険料を設定する」というように、保険契約で保険料の設定に適用できる既成のルールセットのことです。
GAMモデル(一般化加法モデル)は、「この特徴があれば100ドル追加、これがあればさらに50ドル追加」というようなことをモデル化するので、アクチュアリーが解釈できるのです。
GAMを使用すると、格付表の範囲を自動的に学習できます。
格付表の詳細を参照してください。
責任準備金モデリング vs. 損失コストモデリング¶
保険における損失準備とは、(保険料にかかわらず)すでに販売した保険の最終的なコストを見積もることです。 今年販売した1000件の保険契約について、50件の保険金請求があったものの、保険金は4万ドルしか支払われていないことが年末にわかったとします。 しかし、今から50年後、100年後に振り返ったときに、支払総額は9万5千ドルになると見積もっているため、さらに5万5千ドルの「責任準備金」を積み立てています。 保険会社のバランスシートにおいて、責任準備金は圧倒的に大きな負担です。 数十億ドル規模の保険会社であれば、数十億ドルとは言わないまでも、数億ドルの準備金がバランスシートに計上されているはずです。 こうした準備金は、予測に大きく左右されます。
ELI5:給料をもらったばかりで銀行に1000ドルあっても、10日後に住宅ローンの返済(800ドル)が待っているとします。 1000ドル使うと住宅ローンを返済できなくなるので、返済のための準備金として800ドル置いておきます。
アルゴリズム vs. モデル¶
ELI5:モデルをサンドイッチに例えて説明します。ご存知のとおり、サンドイッチは、肉やソーセージといった具材に野菜やチーズ、マヨネーズなどを加え、パンではさんで作ります。 このモデルを使用すると、食べ物を簡単に説明でき(すべての食べ物を「サンドイッチである」または「サンドイッチではない」として分類できます)、サンドイッチを作るための新しい材料を予測できます。
Robot 1
「サンドイッチかどうか」の議論ではありません
サンドイッチを作るためのアルゴリズムは、一連の命令で構成されます。
- 食パン1斤から2枚を切り分ける。
- 食パン1枚の片面にピーナツバターを塗る。
- もう1枚の片面にラズベリージャムを塗る。
- ピーナツバターを塗った面とジャムを塗った面が向かい合うように、パンを重ねる。
PCAおよびK-meansクラスタリング¶
Robot 1
K-meansクラスタリングに対する主成分分析(PCA)の影響はどんなものですか?
こんにちは、チームの皆さん。ある顧客が、モデリング中にPCA > k平均が正確にどのように使用されているかを質問しています。 変換されたデータセットにCLUSTER_ID特徴量が作成されていることがわかり、私はそれがk平均からのものであると仮定しています。 私の質問は、この特徴量を作成した場合に、たとえば特徴量のインパクトなどでそれを追跡しない理由です。
Robot 2
特徴量のインパクトは、派生した特徴量ではなく、データセットの特徴量レベルで機能します。 カテゴリー特徴量CAT1についてOne-hot encodingがある場合、CAT1-Value1、CAT1-Value2、...ではなく、CAT1のみの特徴量のインパクトも計算されます。
元の特徴量のPermutationにより、K平均の結果にもPermutationが生じます。そのため、モデリング結果にとって重要な特徴量の場合、その影響は元の列に割り当てられます。
Robot 3
一部のブループリントでは、One-hot encodingされたクラスターIDが特徴量として使用され、その他のブループリントではクラスター確率が特徴量として使用されます。
モデルの結果に対するK平均ステップの影響を評価する場合は、Compposable MLのK平均ブランチを削除し、リーダーボードを使用してモデルがどのように変更されたかを評価します。
Robot 2によると、特徴量のインパクトはRAWデータ上で動作し、前処理とモデリングの両方が含まれます。
単調とは?¶
例
たとえば、マンガを集めているとします。 お金をかければかけるほど、コレクションの価値が上がる(価値とかけたお金の関係性が単調に高まる)ことを期待しています。 しかし、この関係性には他の要因もあるかもしれません。たとえば、破損したことで、お金をかけたのにコレクションの価値が下がってしまったというようなことです。 お金をかけると価値が下がるということをモデルに学習させたくありません。なぜなら、実際には、破損などの考慮していない要因で価値が下がるからです。 そこで、単調な関係性を強制的に学習させます。
車にスピードメーターを取り付けた人には保険料を割り引く保険会社があるとします。 走行速度を基準にして、より安全な運転をする人にはより大きな割引を提供したいものです。 しかし、運用中のモデルは、無事故でも信じられないほどの速度(たとえば、時速200km以上)で運転する人達を少数ながら発見し、そうした顧客にも割引を提供することを決定しました。 その後、毎月時速200kmで運転しても、保険料が大きく割り引かれることが他の顧客に知れ渡ってしまったため、保険会社は倒産してしまいました。 単調性は、「車の最高速度が上がると、保険料も必ず上がる」 ことをモデルに伝えるための方法です。
正規化するかどうかが問題である。
Robot 1
- 属性に単調増加および単調減少の制約を適用すると、DataRobotは何らかの正規化(キャッピングとフロアリング、ビニングなど)を行いますか?
try only monotonicモデルを適用すると、GBM、XGBOOST、RFなどで試行されますか?
Robot 2
自分が知っている正規化はなく、xgboostとgamだけです。 xgboostモデルのデータを正規化する必要はありません。
Robot 3
ドキュメントの場合、 特徴量の制約を設定する方法と、 それらを構築するワークフローを確認できます。
Ridge回帰とは?¶
ペナルティ付き回帰には2種類あります。1つは、モデルにすべての特徴量を保持させますが、重要でない特徴量に費やす時間を減らし、重要な特徴量により多く費やすようにするものです。 これはRidgeです。 もう1つは、重要でない特徴量をモデルから完全に除外してしまうものです。 これをLassoと呼びます。
ELI5の例
もし、友人達が部屋で「どのチームが試合に勝つか」という話をしていたら、複数の意見を聞いて、1人の友人に会話を独占されたくないでしょう。 そのため、話が止まらない友人には「シーッ」と言い、それでも話を続ければ、どんどん大きな声で「シーッ」と言い続けます。 同様に、Ridge回帰は、モデルを支配する1つの変数にペナルティを課し、より多くの変数にシグナルを広めます。
XGBoost確率の較正¶
Robot 1
私は顧客から非常に難しい質問を受けました。 顧客は、二値分類器のXGBoost確率が完全に間違っていることがあり、「較正」する必要があると述べていました。 正直言って私には難しすぎて理解できないのですが、これはXGBoost損失関数だけですか?
Robot 2
確率を適切に較正することは重要ですか、またはしたほうが良いですか? ユースケースとは何ですか?
損失関数に関する技術的回答をほぼ確実に知っているRobot 3にCCします。
Robot 1
90/10の不均衡であり、何らかの医療装置の故障や良くない結果が生じる可能性があります。
Robot 3
XGBoostモデルにはLoglossを使用します。これは通常、十分に較正されたモデルになります。
別の損失関数を使用した場合は較正する必要があるでしょう(しかし、較正しません)。
調査の結果、Loglossの使用が適切なソリューションであると判断されました。
Robot 2
DRリンクで「私たちはこれについて考え、こう回答します」と説明すべきでしょうか?
Robot 1
このようにしてはどうでしょう:
今朝、XGBoostモデルの確率の較正について素晴らしい質問がありました。この件について、コアモデリングを担当する数人のデータサイエンティストと話し合いました。この問題に関する彼らの研究によると、LogLossの損失関数を使用すると、一般的に適切に較正された確率が生成され、これは不均衡な二値分類データセットのデフォルト関数です。
その他の最適化指標については較正が必要な場合がありますが、現時点ではDataRobotで実行されません。
Robot 4
必要な場合には、次のようにブループリントに較正ステップを追加できます。
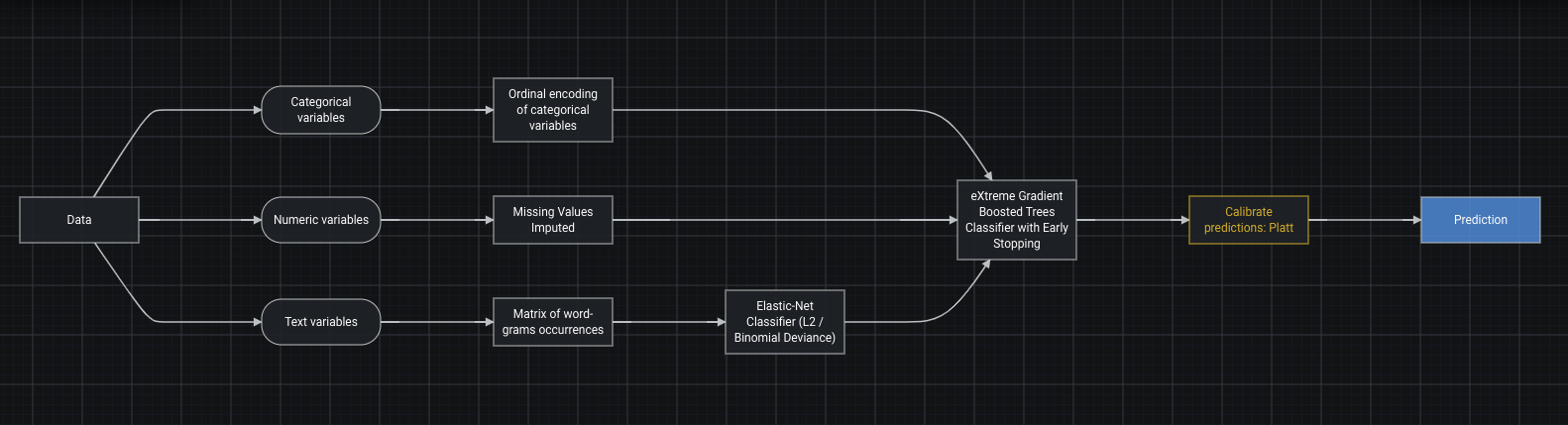
Robot 5
較正を確認するもう1つの簡単な方法は、リフトチャートを確認することかもしれません。 100%の答えではありませんが、それでも役に立ちます。
チューニングパラメーターとハイパーパラメーターとは?¶
チューニングパラメーターとハイパーパラメーターは、モデルの動作を変えるために調整できるノブやダイヤルのようなものです。 DataRobotはこのプロセスを自動化することで、モデルのデータへの適合性を高めています。
エレキギターで曲を演奏しているとします。 コード進行はお手本通りなのですが、友人はロック調のディストーションでアンプをチューニングしたり、あなたは低音を強調したりと、ギターにさまざまなエフェクトをかけて演奏します。 それによって、同じ曲でも聞こえ方が変わってきます。 それがハイパーパラメーターチューニングです。
チューニングがほとんどできない車もありますが。 他の車、たとえばレーシングカーでは、チューニングできることがたくさんあります。 サーキットによって、車のチューニング方法を変えることもあります。
DataRobotのNPS¶
Robot 1
こんにちは、NLPチームの皆さん。 誰かがDataRobotにNPS(ネットプロモータースコア)ソリューションを実装しているかどうか疑問に思っています。 良い、悪い、中立のラベル付けだけでなく、悪い / 良いレビューの原因もタグ付けするような、多ラベルプロジェクトの使用を希望する顧客があります。 たとえば、誰かが次のような反応をするとします。
「製品が大好きでしたが、サービスはひどいものでした。」
悪いコメントが「サービス」に割り当てられ、良いコメントが「製品」に割り当てられているような、良いコメントと悪いコメントの両方を含んでいることを教えてくれるように、DataRobotを使用するにはどうすればよいでしょうか?
Robot 2
good_product、bad_product、good_serviceなどのクラスでの多ラベル?
Robot 3
元の1~10スコアをターゲットとして使用することにします。 優れたモデルでは、次のようなことを学習できるべきです。
ターゲット: 7 テキスト:「製品が大好きでしたが、サービスはひどいものでした。」
係数: * intercept: +5.0 * 「製品を愛用」:+4.0 * 「サービスがひどかった」:-1.0
予測: 5 + 4 - 1 = 7
Robot 3
NPSを取得するのにデータを集計してから、ラベル付けとビニングを試みないでください 元の調査スコアを直接使用して、ワードクラウドの単語 / フレーズがスコアを上下させる方法を確認します。 多ラベル(および多クラス)は両方とも問題を過度に複雑にする感があります。他の問題では優れていますが、ここでは必要ありません。
Robot 1
「NPSを取得するのにデータを集計せず、ラベル付けとビニングを試みます」
この^^文についてもう少し詳しく説明してください
Robot 3
したがって、「ネットプロモータースコア」は集計された数値です。 個々の調査には存在しません。 これは、それに関する 素晴らしい記事です。
一般的に、ネットプロモータースコア調査には2つの質問があります。
- 1~10のスケールで、この製品を友人に勧める可能性はどの程度ありますか?
- 自由形式のテキスト:なぜでしょうか?
Robot 1
了解、どんな意味かわかりました。
Robot 3
ELI5の例
100件の調査があるとすると、スコアの分布は次のようになります。
- 1: 1名の回答者
- 2: 3名の回答者
- 3: 5名の回答者
- 4: 7名の回答者
- 5: 15名の回答者
- 6: 25名の回答者
- 7: 15名の回答者
- 8: 15名の回答者
- 9: 10名の回答者
- 10: 4名の回答者
また、ネットプロモーター方式によって、これらがビニングされます。
- 批判者:1-6
- 中立者:7-8
- 推奨者:9-10
Robot 3
その場合、次のようになります。
- 批判者:1+3+5+7+15+25 = 56
- 中立者:15+15 = 30
- 推奨者:10+4 = 14
%に変換すると、次のようになります。
- 批判者:56%
- 中立者:30%
- 推奨者:14%
ネットプロモータースコアは(Promotors %) - (Detractors %)であり、つまりこのケースでは14~56です。
したがって、この調査のNPSは-42で、よくありません。
Robot 3
では、なぜそれが悪いのですか。コンサルタントを雇って調査を解釈して報告してもらうことも、代わりにDataRobotを使用して調査を解釈することもできます。
そのレベルでのネットプロモータースコアの概念は適用されません。1人の人を見て、NPSを計算することはできません。 NPSはユーザーのグループのプロパティです。 ユーザーレベルでは、人を多クラス「detractor」、「passive」および「promotor」にビニングできますが、特にdetractorクラスでは情報が失われます。
個人的には、6は1とはまったく違います。1は製品が嫌いで、6はかなりのところ中立者です。
したがって、ターゲットが1~10の直接的な元のスコアであり、また予測が応答のテキストである個別レベルのモデルを構築することが有用です。 上記で指摘したように、DataRobotのワードクラウドと係数によって、ユーザーのスコアを高めるテキストの断片とスコアを下げるテキストの断片がわかり、ユーザーの話に基づいて予測された合計スコアを合計してくれます。
Robot 2
テキスト予測の説明を使用して、個別のレビューを確認することもできます。
Robot 3
その通りです!これにより、各レビューについて単語レベルのPositive/Negative/Neutalが表示されます。
ありがとう、Robot 2とRobot 3!どれも素晴らしい情報です。 これから何を思いつくことができるかがわかりますが、この テキスト予測の説明は必ず活用したいと思います。
データのスコアリング vs. モデルのスコアリング¶
料理コンクールに出場するため、自宅でさまざまなレシピを練習しているとします。 まず食材(トレーニングデータ)を用意し、友人を相手にいろいろなレシピを試して、それぞれのレシピを最適化します(モデルのトレーニング)。 その後、友人以外で信頼でき、ある程度バイアスのない人にも試食してもらい(検定)、最終的にコンクールに出すレシピを選びます。 これがスコアリングに使用するモデルです。
そして、コンクールに参加し、そこでたくさんの食材を渡されます。これはスコアリングデータ (見たことのない新しいデータ) です。 これらの食材をレシピに取り入れ、審査員向けの料理を作ります。つまり、モデルを使って予測やスコアリングを行います。
同じ食材で多くのレシピを試したかもしれません。つまり、同じスコアリングデータを使用して、さまざまなモデルから予測を生成できます。
バイアス vs. 分散¶
ワインの試飲会に行くことになり、2人の友人のうち1人を誘おうと考えているとします。
- 友人1: あらゆる種類のワインを楽しむが、来ないかもしれない(低バイアス/高分散)。
- 友人2: 安価なワインしか飲まないが、必ず来ると期待できる(高バイアス/低分散)。
最高のシナリオ:あらゆる種類のワインを楽しみ、信頼できる人(低バイアス/低分散)を見つける。 しかし、これを実現するのは難しいので、友人1に対して参加を促すか、友人2に対して他のワインを試すように説得する(ハイパーパラメーターのチューニング)とよいでしょう。 安価なワインしか飲まず、必ず来るとは限らない友人(高バイアス/高分散)は避けます。
対数スケール vs. 線形スケール¶
対数スケールでは、値は一定の係数(1、10、100、1000、10000)で乗算され続けます。 線形スケールでは、値は一定量(1、2、3、4、5)ずつ加算され続けます。
マグニチュードの値が1増えると、地震の規模は約30倍になります。 つまり、マグニチュード7は6の30倍、8は7の30倍なので、8は6の900(30×30)倍となります。
オクターブ数は直線的に増加しますが、音の周波数は指数関数的に増加します。 つまり、「ラ」の音の第3オクターブは220Hz、第4オクターブは440Hz、第5オクターブは880Hz、第6オクターブは1760Hzです。
注目すべき情報:
- 経済や金融の世界では、変化率に換算するのが簡単なため、対数スケールが使われます。
- 対数スケールが存在する理由は、自然界の多くの事象が線形ではなく指数関数的な法則に従っているからという可能性もありますが、線形の方が理解しやすく視覚化しやすいのです。
- 線形の数値が大きく、グラフの見栄えが悪くなる場合は、数値を対数化して縮小することで、グラフの見栄えを良くすることができます。
Gamma分布でのオフセット/エクスポージャー¶
Robot 1
DataRobotでは、ターゲットがGamma分布に従うモデルトレーニングで、エクスポージャーとオフセットをどのように処理しますか?
ターゲットは総請求コストであり、exposure = claim count(請求件数)です。 したがって、DataRobotでは、エクスポージャーを「請求件数」に等しい値に設定することも、offset = ln(“claim count”)を設定することもできます。 どちらのシナリオも数学的に等価であると考えるのが妥当でしょうか?
ありがとう
Robot 2
はい。それらは数学的に等価です。 エクスポージャーを乗算するか、ln(exposure)を加算します。
Robot 1
ありがとう、私の印象もそうでした。 ただし、同じ特徴量セットを持つ2つのアプローチを使用して、プロジェクトの設定と実験を行いました。 1つのプロジェクトはターゲットを過大予測し、もう1つのプロジェクトでは過小予測しているようです。 数学的に等しい場合、不一致の原因は何でしょうか?
Robot 2
おかしいですね。 両方のケースで同じエラー指標を使用していますか?
Robot 1
はい。どちらのプロジェクトでも推奨指標のGamma Devianceを使用しました。
Robot 2
検定またはホールドアウトセットの予測をダウンロードすると、予測値と実測値を手動で比較できますか?
Robot 1
さらに確認すると、プロジェクト内のエクスポージャー設定で間違った特徴量名(エクスポージャー特徴量)が使用されたことがわかりました。 これを修正すると、両方のプロジェクトの予測が一致します([予測]タブからダウンロードして)。
ただし、リフトチャートが異なることに気づきました。
Robot 2
これはおそらく、リフトのオフセットとエクスポージャーの計算方法の違いです。 ノートブックで独自のリフトチャートを作成することをお勧めします。 その後、リフトチャートでの加重、オフセット、エクスポージャーの処理に任意の方法を使用できます。
Robot 3
リフトチャートをカスタマイズするための優れたAIアクセラレーターがあります。
Robot 1
驚くべき。 ありがとうございます
ターゲット変換¶
Robot 1
ターゲットを変換すること(log(target)、target^2など)は、MLモデルにどのように役立ち、それぞれどのような場合に使うべきでしょうか?
Robot 2
これは、ELI5の回答ではありませんが、ここにターゲットを対数変換する 理由があります。
TL;DR: 線形回帰を実行する場合、一連のポイントを通る線を引いて、その線がそれらのポイントの応答変数に可能な限り近くなるようにすることで、応答変数(ターゲットなど)の近似を試みます。 しかし、これらのポイントは直線に沿っていない場合があります。 曲線に従う場合があります。その場合、そのポイントを通る単純な線は、ターゲットはあまりよく近似されません。 これらのシナリオの一部では、ターゲットを対数変換して、これらのポイントと応答変数の間の関係性を直線的なものにすることができます。 コードアカデミーにある次の画像は、悪いことを示しています。
![]()
そして優れた点:
![]()
Robot 3
これは、直線に適合する線形モデルに固有なものです。 XGBoostのようなツリーベースのモデルの場合、ターゲット(またはその他の特徴量)を変換する必要はありません。
Robot 4
はい、対数変換は、特に線形回帰の仮定(違反した場合)をよりよく満たすために生まれました。 予測パフォーマンスの観点から対数変換が役立つ場合があります。 (つまり、ターゲットのテールが非常に長い場合、対数変換によってこのテールが小さくなり、モデルがターゲットをよりよく理解するのに役立ちます。)
Robot 5
Robot 3
Robot 4、XGBoostと多くの線形回帰ソルバーの両方で、対数リンク損失関数(poisson lossなど)を使用することもできます。 私は対数変換よりもそれを好みます。対数変換は予測された平均にバイアスをかけ、元のターゲットのスケールでは、リフトチャートが変に見えるようになります。
しかし、それは問題と何をモデル化しようとしているかに依存します。
Robot 4
あるいは、逆双曲線正弦関数アミライトを使用するとか? 😂
Robot 1
いろいろとありがとう!非常に役に立ちます。 Robot 4 hyperbolic sine amiriteは、私の好きなメタルバンドの名前です。
ターゲットエンコーディングとは?¶
機械学習モデルはカテゴリーデータを理解できないため、カテゴリーを数値に変換して計算できるようにする必要があります。 ターゲットエンコーディングを行う方法の例には、次のようなものがあります。
-
One-hot encoding とは、カテゴリーを0と1の非常に広い行列としてエンコードすることによって、カテゴリーを数値に変換する方法です。 これは線形モデルに最適です。
-
ターゲットエンコーディング は、各カテゴリーをそのカテゴリーターゲットの平均に置き換えることで、カテゴリーを数値に変換する別の方法です。 この方法では、結果が1列しかないため、非常に狭い行列になります(one-hot encodingではカテゴリーごとに1列)。
より複雑ですが、ターゲットエンコーディングの使用時に 過学習を回避することもできます。これは、DataRobotでは _信頼値エンコーディング_と呼ばれています。
信頼性の重み付けとは?¶
信頼性の重み付けは、カテゴリーラベル(たとえば、運転している車のモデル)を持つデータにおいて結果の確実性を説明する方法です。
2018年に米国で最も売れたフォードFシリーズなど、人気のある車種カテゴリーの場合、データに含まれる人数が多くなり、過去の結果が信頼できるものであることがより確実になります。 2017年に米国で最も希少なモデルにランクインしたSmart Fortwoなど、人気のない車種カテゴリーの場合、データに含まれる人数が1~2人しかおらず、過去の結果が将来への信頼できる指針になるかどうかは定かでないでしょう。 そのため、より広範な母集団統計を判断材料にすることになります。
コイントスで表か裏かを確実に予測することはできませんが、1000回コインを投げたら、表が何回出るか(正しくやっていれば500回近く)、より確実に予測できるようになることはご存じでしょう。
過学習とは?¶
読書好きが利用するサイトで「アガサ・クリスティーの本が好きで、他の殺人ミステリーも気に入るかどうかを知りたい。」と書き込んだとします。 サイトからの回答は「いいえ」でした。アガサ・クリスティーが書いたものではないからです。
過学習とは、本の内容だけを覚えていて、そこから結論を導き出さない悪い生徒のようなものです。 彼らは、本の中で特に言及されていないことに対しては無力です。 しかし、本に書かれている内容だけで試験を行う場合は、好成績を収めることができます (ですから、トレーニングデータでスコアリングすべきではありません) 。
オフセットとは?¶
あなたが線形モデルを理解している5歳児だとしましょう。 線形回帰では、βが誤差を最小限に抑えることはわかりますが、βの一部が事前にわかっている場合があります。 そこで、こうしたβの値をモデルに提供し、誤差を最小限に抑える他のβの値を見つけるように指示します。 事前にわかっている作用をモデルに提供すると、モデルにオフセットを与えることになります。
SVMとは?¶
たとえば、良い借り手の家と悪い借り手の家を通りの両側に建て、その道路の幅ができるだけ広くなるようにします。 この通りに新しい人が引っ越してきたら、その人が道路のどちら側にいるかを見て、良い借り手かどうかを判断することができます。 SVMは、陽性の例と陰性の例の間にこの 「道」 を引く方法を学習します。
SVMは「最大マージン」分類器とも呼ばれます。 センターラインと両側の縁石で道路を定義し、可能な限り幅の広い道路を探します。 道路脇の縁石が「サポートベクター」です。
関連性の高い用語:カーネルトリック。
当初の設計では、SVMは直線の道路しか学習できませんでしたが、カーネルという数学のトリックを使うことで、曲線の道路を学習できるようになりました。カーネルは、点をより高い次元の空間に投影します。 この空間では、点は引き続き線形の「道路」によって分離されますが、元の空間では直線ではなくなります。
ロジスティック回帰で多項式特徴量を手動で作成するのと比べて、カーネルの優れた点は、カーネルは常に点のペアに適用され、座標ではなくドット積を返すだけでよいため、こうした高次元の座標を事前に計算する必要はありません。 そのため、計算効率が非常に高いです。
注目すべきリンク:
- Stack Exchangeの"Help me understand Support Vector Machines"
粒子群最適化 vs. グリッドサーチ¶
グリッドサーチには一定の時間がかかりますが、良い結果が得られない場合があります。
粒子群最適化にかかる時間は予測不可能で、無限にかかる可能性もありますが、より良い結果が得られます。
友人3人とトランシーバーを持って、家電量販店のセールに行きました。 セールの新聞広告を見るのを忘れていましたが、大丈夫でした。 手分けして店内を1分間歩き回り、最高のお買い得品を見つけたら友人達に連絡することにしました。 最高のお買い得品を見つけた友人がアンカーとなり、全員がその方向への移動を開始します。これを1分ごとに繰り返すと、(2時間後には)全員が同じ場所にいました。そこでお買い得品を確認することで、達成感を持ち、買い物上手になったと感じました。
友人3人と家電量販店のセールに行きました。 セールの新聞広告を見るのを忘れ、トランシーバーも持ってきませんでしたが、大丈夫でした。 店内を2×2に区切り、手分けして各エリアで最高のお買い得品を見つけることにしました。その後、レジで友人達と待ち合わせて、誰が見つけた商品が一番お得か競います。 (5分後に)レジで会い、できる限りのことをしなかったと思いながらも、家に帰り、前夜の残り物を食べ、スポーツ中継を見ることに喜びを感じました。
グリッドサーチが重要である理由
たとえば、クッキーを焼くとき、できるだけおいしく焼きたいと思うでしょう。 ここではわかりやすくするために、小麦粉と砂糖の2つの材料で作るとします(本当はもっと材料が必要ですが、とりあえずこれで行きましょう)。
小麦粉はどれくらい入れますか?砂糖はどれくらい入れますか?ネットでレシピを調べても、どれも違うことを言っているのかもしれませんね。 小麦粉と砂糖の量については、ネットで調べられるような魔法のような完璧な配合はないんです。
では、どうすることにしますか?小麦粉と砂糖の分量をいろいろ変えてみて、どの味が一番おいしいか、試しに作ってみるのです。
- 1カップ、2カップ、3カップの砂糖を入れてみるのもいいかもしれません。
- また、3カップ、4カップ、5カップの小麦粉を入れてみるのもいいかもしれません。
どのレシピが一番おいしいかは、砂糖と小麦粉の配合で試行錯誤を重ねなければなりません。 つまり、次のようなことです。
- 配合A:砂糖1カップ、小麦粉3カップ
- 配合B:砂糖1カップ、小麦粉4カップ
- 配合C:砂糖1カップ、小麦粉5カップ
- 配合D:砂糖2カップ、小麦粉3カップ
- 配合E:砂糖2カップ、小麦粉4カップ
- 配合F:砂糖2カップ、小麦粉5カップ
- 配合G:砂糖3カップ、小麦粉3カップ
- 配合H:砂糖3カップ、小麦粉4カップ
- 配合I:砂糖3カップ、小麦粉5カップ
必要であれば、三目並べをしているような感じで、紙に書いてみてください。
| 砂糖1カップ | 砂糖2カップ | 砂糖3カップ | |
|---|---|---|---|
| 砂糖1カップ | 砂糖1カップ、 小麦粉3カップ |
砂糖1カップ、 小麦粉4カップ |
砂糖1カップ、 小麦粉5カップ |
| 砂糖2カップ | 砂糖2カップ、 小麦粉3カップ |
砂糖2カップ、 小麦粉4カップ |
砂糖2カップ、 小麦粉5カップ |
| 砂糖3カップ | 砂糖3カップ、 小麦粉3カップ |
砂糖3カップ、 小麦粉4カップ |
砂糖3カップ、 小麦粉5カップ |
これがグリッドのように見えることに注目してください。 このグリッドで、砂糖と小麦粉の最適な組み合わせを探します。 最もおいしいクッキーを作る唯一の方法は、これらの組み合わせでクッキーを焼き、それぞれの配合を味見して、どの配合が一番おいしいかを判断することです。いくつかの組み合わせを省略すると、最もおいしいクッキーを見逃す可能性があります。
さて、現実の世界で、材料が3つ以上ある場合はどうなるのでしょうか?たとえば、卵を何個入れるかも決めなければなりません。 これで「グリッド」は3次元になりました。 卵2個と卵3個のどちらにするか決めたら、砂糖と小麦粉の9通りの組み合わせをすべて試す必要があります。
材料が多ければ多いほど、組み合わせが多くなります。 また、材料の分量 (3カップ、4カップ、5カップなど) が多ければ多いほど、より多くの組み合わせを選ばなければなりません。
**機械学習への応用:** モデルを構築する際、たくさんの選択肢があります。 これらの選択肢の一部はハイパーパラメーターと呼ばれます。 たとえば、ランダムフォレストを構築する場合、以下のような選択が必要です。
- ランダムフォレストに含める決定木の本数は?
- 個々の決定木の深さは?
- 各決定木の最終「ノード」に最低限必要なサンプル数は?
このテストの方法は、材料の配合を変えて焼いたクッキーを試食するのと同じです。
1. 検索するハイパーパラメーターを選択する(3つとも上にリストアップされています)。
2. 各ハイパーパラメーターのどの値を検索するかを選択する。
3. 次に、ハイパーパラメーター値の組み合わせごとに別々にモデルをフィッティングする。
4. そして、各モデルのパフォーマンスを測定する(精度や二乗平均平方根誤差などの指標を使用します)。
5. 最も良いパフォーマンスを示したモデルのハイパーパラメーターのセットを選択する。 (自分のレシピが、一番おいしいクッキーを作るレシピになるように。)
材料と同じように、ハイパーパラメーターの数と検索するレベルの数が重要です。
- 2つのハイパーパラメーター(材料)をそれぞれ3つのレベルで試す → テストするモデル(クッキー)の組み合わせは3 * 3 = 9通り
- 2つのハイパーパラメーター(材料)をそれぞれ3つのレベルで試し、(卵を加えた場合)3つ目のハイパーパラメーターを2つのレベルで試す → 3 * 3 * 2 = テストするモデル(クッキー)の組み合わせは3 * 3 * 2 = 18通り
その計算式は、テストしたい各ハイパーパラメーターのレベル数を取り、それを乗算するというものです。 つまり、5つのハイパーパラメーターをそれぞれ4つのレベルで試す場合、4 * 4 * 4 * 4 * 4 = 4^5 = 1,024のモデルを構築することになります。
モデルの構築には時間がかかる場合があります。ハイパーパラメーターの数や各ハイパーパラメーターのレベルが多すぎると、非常に高性能なモデルが得られるかもしれませんが、それを得るにはかなり長い時間がかかるかもしれません。
DataRobotは自動的にグリッドサーチを行い、モデルに最も適したハイパーパラメーターを検索します。 これは、ハイパーパラメーターのあらゆる組み合わせを検索する網羅的な検索ではありません。 こうした検索は、非常に長い時間がかかり、不可能かもしれないからです。
**技術的なことを1行で:** グリッドサーチは機械学習でよく使われる手法で、モデルに最適なハイパーパラメーターのセットを見つけるために使用されます。
**備考:** グリッドサーチに代わるランダムサーチについてお聞きになったことがあるかもしれません。 グリッドを設定してチェックするのではなく、各ハイパーパラメーターの範囲(砂糖1~3カップ、小麦粉3~5カップなど)、コンピューターは、砂糖と小麦粉の組み合わせをランダムに5つ生成します。 たとえば。
- 配合A:砂糖1.2カップ、小麦粉3.5カップ
- 配合B:砂糖1.7カップ、小麦粉3.1カップ
- 配合C:砂糖2.4カップ、小麦粉4.1カップ
- 配合D:砂糖2.9カップ、小麦粉3.9カップ
- 配合E:砂糖2.6カップ、小麦粉4.8カップ
Keras vs. TensorFlow¶
DataRobotでは、“TensorFlow"は実際には“TensorFlow 0.7”、“Keras”は実際には“TensorFlow 1.x"です。
これまで、TensorFlowには多くのインターフェイスがあり、そのほとんどがKerasより低レベルでした。また、Kerasは複数のバックエンド(Theano、TensorFlowなど)をサポートしていました。 しかし、TensorFlowはこれらのインターフェイスを統合し、KerasはTensorFlowで実行するコードのみをサポートするようになったため、TensorFlow 2.xの時点で、KerasとTensorFlowは実質的に同じものです。
このような歴史があるため、古いTensorFlowから新しいTensorFlowにアップグレードする方が、TensorFlowからKerasに切り替えるよりも理解しやすいです。
ELI5の例
KerasとTensorflowの比較は、自動コーヒーマシンを使うのと、手作業で豆を挽いてコーヒーを淹れるのを比較するようなものです。
コーヒーを淹れる方法はたくさんあります。つまり、Kerasで使える技術はTensorFlowだけではないのです。 Kerasは、特定の「コーヒー抽出技術」(TensorFlow、CNTK、Theanoなど、Kerasバックエンドと呼ばれるもの)を備えた「ボタン」(インターフェイス)を提供します。
これまで、DataRobotは下位の技術であるTensorFlowを直接使っていました。 しかし、手作業で豆を挽いてコーヒーを淹れるように、これには多くの手間とメンテナンスが必要で、メンテナンスの負担も増えます。そこでDataRobotは、Kerasのような、内部で多くのすばらしい機能を提供する上位の技術に切り替えました。たとえば、TensorFlowで手動実装すると手間がかかるような、より高度なブループリントをより早く製品で提供します。
分位点回帰損失とは?¶
一般的な損失関数:平均的に起こることに関連した値を予測したい。
分位点損失:特定のパーセンタイルで起こることに関連した値を予測したい。
これを行う理由とは?
- 意図的な過大あるいは過小予測: 在庫切れは非常にコストがかかるため、供給を過大予測しても問題ありません。
- ターゲットの両極端な挙動を促す特徴量の理解: NBAで、3ポイントシュートの向上につながる選手追跡指標を知りたいとします。 平均的な3ポイントシューターではなく、最高の3ポイントシューターに関連する指標を明らかにするため、分位点損失を使用できます。
F1スコアとは?¶
たとえば、ある人が病気かどうかを判断する医療検査(機械学習モデル)があるとします。 多くの検査と同様に、この検査も完璧ではなく、ミス(たとえば、健康な人を病気と判断する)が発生する可能性があります。
私達は、モデルが病人と呼ぶ人の中で本当に病人である割合を最大化することに最も関心を持つかもしれませんし (プレシジョン)、母集団における本当の病人の検出率を最大化することに関心を持つかもしれません(リコール)。
残念ながら、1つの指標でチューニングすると、特にターゲットがアンバランスな場合、他の指標が悪化することが多いです。 地球上に1%の病人がいて、モデルでは地球上の全員 (100%) が病人と呼ばれていると仮定します。 その場合、リコールスコアは完璧ですが、プレシジョンスコアは最悪です。 逆に、病人と呼ばれるのが10億人に1人だけでも、それが正解であるような保守的なモデルにすることもあるでしょう。 その場合、プレシジョンは完璧ですが、リコールは最悪です。
F1スコアは、プレシジョンとリコールを同時に考慮する指標で、この2つのバランスをとることができます。
プレシジョンとリコールを同時に考慮するにはどうすればよいでしょうか?2つの平均(算術平均)を取ることもできますが、プレシジョンとリコールは分母が異なる比率であるため、この場合は算術平均はあまりうまくいかず、調和平均の方が適切です。 それがF1スコアであり、プレシジョンとリコールの調和平均です。
注目すべきリンク:
- 調和平均の説明。
学習のタイプ¶
コンテキストバンディット¶
バンディットみたいなもので、コンテキストが付いているだけです(笑)。 まず、バンディットとは何か、正確には多腕バンディットとは何であるか知る必要があります。 これは、 強化学習で解決できる一般的な問題です。 2つ以上のレバーを備えたマシンがあるとします。 レバーを引くたびにランダムな報酬が得られます。 各レバーの平均報酬は異なる場合があり、もちろんノイズもあるため、明らかではありません。 あなたのタスクは、引くべき最適なレバーを見つけること、そして探しているときに間違ったレバーを引きすぎないようにすること(後悔を最小限に抑えること)です。
どうすればよいかはこの答えの範囲外ですが、勝つための戦略は「不確実性に直面したときの楽観主義」で、私はこれが好きです!コンテキストバンディットも同じ問題で、レバーを引くたびに追加情報が与えられるだけです。
しまった。 ロボット1に先を越されました。
多腕バンディット:選択肢はたくさんありますが、選択できるのは1つだけです。
何度も何度も試していれば、好き嫌いは判断できます。 しかし、すべての選択肢を何億回も試すことはできません。誰もそんな暇はないのですから。
選択するための一定予算が与えられた場合、最高の総収益を得るために、それぞれを試すかどうか/いつ試すかを、あなたはどの程度把握していますか。
コンテキストバンディット:多腕バンディットと同じです。 しかし、まったく同じ選択を繰り返しているわけではありません。 その代わりに、状況に関する情報が得られ、その情報は決断ごとに異なります。 そして、どのような状況でどのような選択をするかというルールが必要です。
Robot 3
コンテキスト バンディットは、現在のステップを終えたら、次のステップをどうするか決断するために立ち止まるということでしょうか? 標準的な 多腕バンディットは、最初に計画されたパスをたどるのでしょうか?
Robot 2
どちらも必ずしも最初からパスが計画されているわけではありません。 各設定では、物事がどのように進んでいるかを確認できます。先ほど試したオプションが期待通りでないかを判断し、何かに変更を加えます。 コンテキストバンディットでは、各決定について、以前の決定とは異なる追加情報があるという違いがあります。 例を挙げてみましょう。
ELI5の例
その典型的な例がスロットマシーンです。 100台のマシンがあります。 10,000回プレイする時間があります。 できるだけ多くの賞金を獲得したいでしょう。 そして決定的なのは、あるマシンが他のマシンよりも優れていると考えていることです。 一般的にどのマシンが一番稼いでいるのかはわかりません。
これは、多腕バンディットのようです。 戦略の例としては、常にマシン1をプレイすることです。または、常にランダムに選択します。 あるいは、各マシンを10回ずつプレイして、残りのターンを勝利数の多い方に使うこともできます。 戦略はいろいろありますが、問題の設定が、これを多腕バンディット問題にしているのです。
多腕バンディット問題でも、やりながら学べます。
さて、ある従業員が、カジノでは多くの客が見ているときに、各マシンが利益を上げるようにマシンをセットアップすると言ったら、それはコンテキストバンディット問題になります。
10,000ターンごとに、どのマシンの傍に多くの客が立っているか、周囲を見回して確認します。 そのため、各スピンは少しずつ異なります。 以前は、どのマシンがベストなのかを見極め、そのマシンをプレイし続けるのが優れた戦略でした。 しかし、ここでは、どのマシンがベストであるか(たとえ、あなたの推測が変わったとしても、スピンごとに変わることはありません)だけでなく、大勢の客がどこに立っているかという別の要素も考慮したいのです。
Robot 3
つまり、コンテキストバンディットには、1. 実行中の選択や、2. 以前のすべての選択の結果以外のコンテキストが含まれます。一方で、コンテキストを考慮しない多腕バンディットは、内部でこれらの要素のみにフォーカスしますか?
Robot 2
そうですね。 まさにそのとおりです。
Robot 1
そもそも、このバンディットというのは、強化学習の戦略を考えるための理論的な単純化であることに注意してください。 現実世界がこれほど単純なことはめったにありません。 次にベストなアクションタイプのユースケースは、多腕バンディットによって近似できます。 しかし、ユーザーの情報、行動、現在の状況、直近の状況をある程度知っているなら、それはコンテキストバンディットですが、多くの人は、教師付きのMLを使う方がよいと考えています。
強化学習¶
強化学習では、問題の定義と学習のプロセス(報酬シグナルを伝達できる環境が必要)にアプローチする方法が重要になります。
たとえば、街で一番おいしいレストランを見つけたいとします。 そのためには、実際に行って食べてみて、好きか嫌いかを判断しなければなりません。 さて、新しいレストランに行くたびに、そのレストランがすでに行ったことのある他のすべてのレストランよりもおいしいかどうかを見極める必要がありますが、もしかしたら食べた料理がそのレストランで出されている他の料理と比べておいしかった、あるいはまずかったかもしれないので、自分の判断に自信が持てないでしょう。 強化学習は、最適な件数のレストランを訪問するか、レストランを再訪して別の料理を試すことで、最高においしいレストランを継続的に見つけることができるようにする、的を絞ったアプローチです。 強化学習は、訪れたことのないレストランの潜在的なクオリティと引き換えに、特定のレストランに対する不安感を和らげてくれます。
強化学習は犬の訓練に似ています。モデルが実行する動作ごとに、「いい子だ」、「悪い子だ」と言うようなものです。 時間とともに、試行錯誤を重ねながら、モデルは動作を学習して、一番大きなご褒美がもらえるようにします。 あなたの仕事は、エージェント(犬)の動作に対して数値化したご褒美で応える環境を提供することです。 強化学習のアルゴリズムは、このような環境で動作し、ポリシーを学習します。
これは、いくつかのタスクを正常に行うたびに報酬が付与されるGoTでのArya Starkのトレーニングに似ています。 さもなければ、無表情な男からペナルティが与えられます。 最終的に彼女は、このプロセスを何度か繰り返すうちに技を習得します(そして、Brienneを打ち負かすのです)。
注目すべき情報
-
DataRobotは、ニューラルネットワークや高度な数学の理解を深めることを必要としない、基本的な形式を示す 強化学習のAIアクセラレータを提供しています。
-
強化学習は、トレーニングデータを無制限に生成できるほうがうまくいきます。トレーニング環境をエミュレートする必要があります。 これにより、モデルは、さまざまなアプローチを何度も試すことで、メカニズムを学習できます。
-
強化学習のフレームワークとしては、OpenAI Gymが良いです。 そこでは、モデルに何らかの目標を設定し、ある環境に置いて、何かを学習するまでトレーニングを続けます。
-
人間が通常「簡単だ」と思うようなタスクが、実際は解決するのが最も難しい問題の1つです。 現在、ロボット工学が機械学習の後塵を拝している理由の1つです。 立ち上がる、歩く、動くといった動作をスムーズに行う方法を学習するのは、2,500万行、200の特徴量を持つ教師ありの多クラス予測を行うよりはるかに難しいのです。
ディープラーニング¶
たとえば、自分の祖母が、以前作っていたスープのレシピを忘れてしまったとします。 あなたはそれを再現したくて、家族や親戚を集め、そのスープを作ってみました。
祖母が作っていたのとは全然違う味になりましたが、みんなに試食してもらいました。 いとこからは 「塩を入れすぎ」 、母親からは「卵が足りない」 、おじさんからは 「にんじんが柔らかすぎる」という感想をもらいました。それで、もう1回作ったら、また感想が返ってきて、みんなが「おばあちゃんの味だ」と納得するまでスープを作り続けました。
それがニューラルネットワークのトレーニング方法です。バックプロパゲーションと呼ばれます。誤差がネットワーク経由で返されるので、小さな変更を加えながら、正解に近づけていきます。
転移学習¶
手短に言えば:誰かに犬と猫の見分け方を教えれば、その方法を使ってキツネとオオカミを見分けることができます。
例
あなたは5歳の子供で、親からテニスを習うように言われ、「テニス」って誰だろうと思っているとします。
毎日、親から「テニスを習いに行け。今日、何も習わずに帰ってきたら、飯は食えないぞ。」と家から追い出されます。
飢え死にするのではないかと心配になり、「テニス」 を探し始めました。数日かかってやっと、テニスがスポーツであり、どこでできるかがわかりました。 ラケットの持ち方やボールの打ち方を理解するには、さらに数日かかりました。 最後に、テニスについて完全に理解したときには、すでに6歳になっていました。
親はあなたを町一番のテニスクラブに連れて行き、ロジャー・フェデラーにコーチを頼みました。 彼はすぐにレッスンを始めることができました。テニスに関するあらゆることを教えてくれて、たった1週間でテニスができるようになりました。 フェデラーは試合経験が豊富なので、彼の言うことをすべて聞いて、数か月後にはもう街で一番のプレーヤーになっていました。
シナリオ1は、通常の機械学習アルゴリズムが学習を開始する方法に似ています。 罰を受けることを恐れて、教えられたことを学ぶ方法を探し始め、徐々にゼロから何かを学び始めます。 一方、転移学習を利用すると、同じ機械学習アルゴリズムがより優れたガイダンス/出発点を持つことになります。言い換えれば、同じようなデータでトレーニングされた機械学習アルゴリズムをスタートポイントとして用いることで、新しいデータをすばやく学習できますが、その速度ははるかに速く、場合によってはより高い精度での学習が可能です。
連合機械学習¶
中心となるモデルを構築したら、さまざまなエッジデバイスで使用するためにモデルを再トレーニングできます。
あるハンバーガーチェーンでは、自社のメニュー(中心となるモデル)を用意し、それを各フランチャイズに自由に使わせています。 たとえば、インドの店舗では、そのレシピを使い、手を加えて、インド人の口に合うハンバーガーを作っています。 その際、インド支社は、本社に連絡する必要はなく、現地での意思決定がいつでも可能です。 常にどこか中央の場所にデータを送る必要がなく、モデルの更新が速いというメリットがあります。 このモデルでは、中央のトレーニングデータストレージに保存しなくても、デバイスのローカルデータ(スマートフォンの利用状況など)を使用できます。これはプライバシーにも役立ちます。
Googleが挙げる一例は、スマートフォンのスマートキーボードです。 スマートフォンの利用状況に応じて更新される共有モデルがあります。 処理はすべてスマートフォン上で行われ、利用データを中央のクラウドに保存する必要はありません。